|
虽然归属NoSQL,但Hamsterdb却是单线程和非分布式的。同时虽然使用了键值类型存储,但其特性却更偏向于列式存储。更重要的是,它还支持read-committed隔离级别的事务。不得不说,Hamsterdb是个典型的非主流数据库。
虽已问世9年之久,但是相较MongoDB,Hamsterdb的知名度仍然有所欠缺,更一度被评为非主流数据库。Hamsterdb是个开源的键值类型数据库。但是区别于其他NoSQL,Hamsterdb是单线程和非分布式的,其特性设计也更像是一个列存储数据库,同时还支持read-committed隔离级别的ACID事务。那么对比LevelDB,Hamsterdb又会有什么优势,这里我们走进项目参与者之一Christoph Rupp的分享。
以下为译文:
在这篇文章中,我想向大家介绍Hamsterdb――一个基于Apache 2-licensed协议的嵌入式分析型键值数据库,类似于谷歌的LevelDB和甲骨文的BerkeleyDB。
Hamsterdb并不是一个新的竞争者。事实上,Hamsterdb已经问世了9年。这一次,它成长得很快,并且专注于键值存储的数据库分析技术,类似于列存储数据库。
Hamsterdb是单线程和非分布式的,它可以直接连接到用户应用程序中。Hamsterdb提供一种独特的事务实现,以及有类似于列存储数据库所具备的特性,非常适合于分析型工作负载。它可以被C/C++原生调用,也面向Erlang、Python、Java、NET、甚至是Ada等编程语言。同时,它还在嵌入式设备和前置应用程序中得到了上千万的部署,以及服务于云端――例如高速缓存和索引,已经有数以百万计的部署。
Hamsterdb在键值存储中有一个独特的功能:它能识别架构信息。尽管大多数数据库无法分析出或关注被插入键类型,但是hamsterdb支持两种类型的键值:binary key(固定长度VS.可变长度)和numerical key键(比如uint32、uint64、real32、real64)。
Hamsterdb的数据库也是被存储在文件或存储器的Btree索引。使用Btree让hamsterdb的分析能力变得强大。Btree索引应用了C++模块,该模块参数取决于键类型和日志的大小(固定长度vs.可变长度),与键是否重复无关,因而每一个Btree节点对于工作负载来说是高可用的。因为键的定长,所以每一个键是零负载的,而且键被排列得像简单数组。在聚焦索引的最底层,uint64键数据库支持 uint64_t类型的C数组。
这种实现减少了I/O并更加有效地利用了CPU缓存。当今的CPU需要对内存性能进行优化处理,这也是Hamsterdb的一大优势。例如,通过搜索叶节点时,二进制搜索在可用内存达到一定阀值时会被跳过,取而代之的是线性搜索。而且,hamsterdb具有等价于SQL commands COUNT、COUNT DISTINCT、SUM 和AVERAGE的API,鉴于直接在Btree上运行,使得它能够快速地工作在固定长度的键上。
Hamsterdb也支持可变长度的键。因此,每个Btree节点有一个非常小的索引提前指向节点的有效负载。这可能导致现有键长度调整或删除后的重组,因此必须对节点做“抽空(vacuumized)”操作,从而避免浪费空间。这个操作会成为一个性能杀手,在速度提升上面临着巨大挑战,因此能少用则少用。
Hamsterdb允许副本键,这意味着某个键可能指向多条记录,键的所有记录都会被组织在一起。他们可用于处理可变长度键的索引结构。(如果一个键有许多备份记录,他们将被从Btree中删除并存储于独立的溢出区)
Hamsterdb支持read-committed隔离级别的ACID事务。事务更新可作为delta-operations存储于存储器中。每个数据库都会有独立的事务索引,这些事务中的更新比BTree中有着更高的优先级。中止事务只意味着放弃事务索引中该事务的更新,并把事务更新交给Btree。
独特的设计选择带来强大的优势。事务升级留在RAM中而不是请求I/O。不再需要事务终止逻辑,因为事务一旦被终止就不会继续执行。恢复逻辑使用了一份简单的逻辑日志,但也存在着一个重要挑战:运行时,两个树必须被合并。想象使用数据库cursor 去完成一个全面扫描,这样的结果是非常复杂的。一些键存在于Btree中,一些在事务树里。在事务树中,Btree里的键可以被重写或者删除,甚至会存在被其他键修改的情况。因此,在涉及到多个键时,这点非常困扰。
Hamsterdb最强力的特性是可测试性。数据库的基本准则是不能丢失数据,这点比性能尤为重要。关键性的Bugs都可被解决的。另外,在九年的开发过程中,为了解决技术负债问题,那些在特定情况下出现的拙劣设计基本上被祛除了,正以敏捷、快速反应的姿态响应用户的需求和新理念,我一直在重写部分代码或者尝试新的想法。高可测试覆盖给了我很大的信心,因为我的更改不会破坏任何东西。
专注于可测试性和高度自动化使我处理好很多事情。在最糟糕时,Hamsterdb debug充斥大量的assert和完整性检查,大约有1800个单元测试和35000个验收测试。那些验收测试中运行着几十个不同的结构,并在BerkeleyDB中并行执行。我们会持续检查两个数据库中数据的一致性,所以任何新进bug都会被马上显示出来。另外,每个测试都会给出一个细节明细表,包括内存消耗、堆分配数目、被分配页数目、Blobs(二进制大对象存储)、btree 的分裂和合并等。
有些测试可以使用valgrind。我们会对比valgrind使用前后的性能,从而快速找出问题发生的地方,并做性能修复。
另外,通过测试模拟数据库崩溃可测试hamsterdb的可恢复性。最后但同样值得关注的是,我可以使用 QuviQ的QuickCheck,一个基于Erlang语言的性能检测工具。QuickCheck让你得知软件的性能情况,然后运行pseudo-randomized指令,不断的核查完整性。
静态代码分析可与Coverity的开源产品和clang的scan-build工具一起使用。他们能发现一些细枝末节问题。
在发布前,所有的测试都是全自动和高性能的。一个完整的发布周期通常要花上几天,且每两个月都要用掉一个硬盘。
总结我学到的知识,测试编写将是一件非常有趣的事情。没有可靠性测试的迭代开发是无法简化的。
我也来介绍下hamsterdb的商业版本 Hamsterdb pro,该版本针对键、记录和日志提供了重度压缩 (zlib、snappy、lzf和lzo),以及AES加密和针对叶节点查找的SIMD优化。还有更多的压缩算法( bitmap compression和prefix compression)正在进行或计划中。网页上有更多的信息。
到目前为止尚不错,但hamsterdb的性能到底如何?我用谷歌的基准测试将Hamsterdb 2.1.8与LevelDB 1.15作了性能对比。压缩被禁用(Hamsterdb?暂未提供压缩,但是Hamsterdb pro提供了)。Fsyncs同样被禁止,它是hamsterdb的一个修复功能(通过预写日志实现)。测试大小范围从较小的键/记录到具有中等大小键和较大的记录,并且插入数据,范围从100K到100M级别。另外,我运行了两个Hamsterdb?的分析函数,LevelDB也是。所有测试运行的缓存大小从4MB到1GB,机器配备一个HDD和一个SSD。
Hamsterdb的配置总是基于定长键――为8字节键hamsterdb存储的uint64 numbers。自从LevelDB需要number转换成string后,这也就成为了hamsterdb的优势之一。
我也还增加了较小记录(size 8)的测试,因为它们含有主键时,通常会被用于辅助索引。两个机器分别使用了不同硬盘:HDD(Core i7-950 8核和8MB缓存)和一个SSD(Core i5-3550 4核和8MB缓存),下面是部分基准测试结果,详情可以看这里。
持续写;键大小:16;日志大小:100(HDD,1 GB缓存)
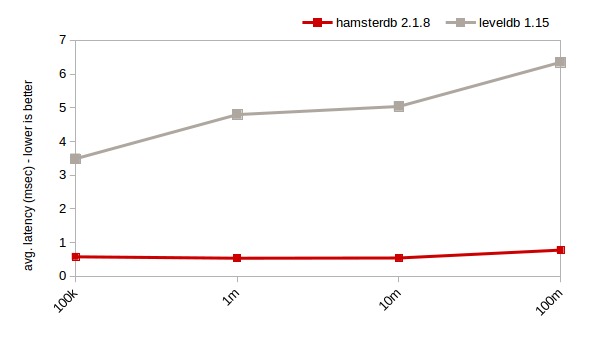
连续读;键大小:16;日志大小:100(HDD,1GB缓存)
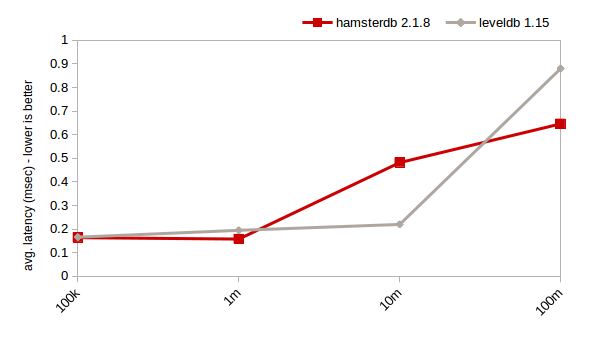
随机写;键大小:16;日志大小:100(HDD,1GB缓存)
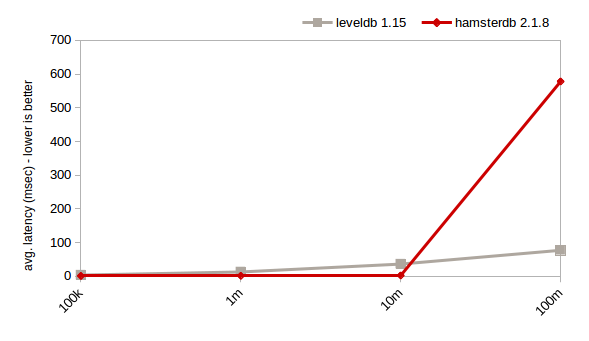
随机读;键大小:16;日志大小:100(HDD,1GB缓存)
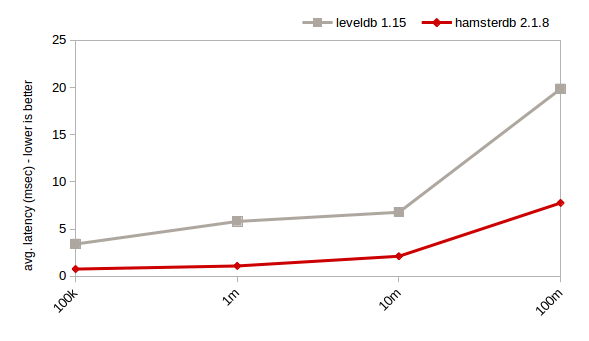
计算所有键的综合(HDD,4MB缓存)
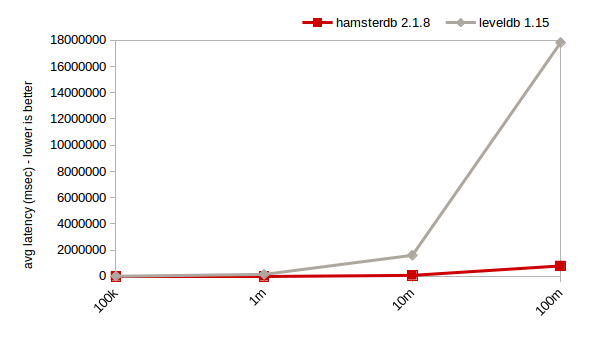
计算末尾是“77”的键(SSD,1GB缓存)
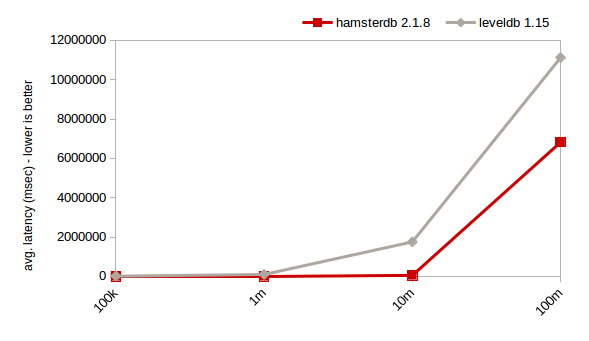
对于随机读,Hamsterdb的性能要好于LevelDB。对于随机写,只要数据量不是太大的时候,Hamsterdb要快于LevelDB。而从1千万键以上开始,hamsterdb就会遭受BTree数据库的传统问题:大量的非序连续I/O的高磁盘寻道延迟。
话虽这么说,这个测试也很好地证明了Hamsterdb的分析能力。尤其是sum和count运算都可以很好地扩展。连续插入和扫描也是Hamsterdb的亮点,且不管数据量多大,它都可以非常快。
未来的工作
这个基准测试让我们发现了很多问题:通过并行hamsterdb,优化随机读/写。这将成为我工作的主要部分,而且我已经草拟一个设计方法,以及在产品发布前进行重构。
|






