|
中国本土的程序员用近十年的时间开发了数据库软件“万能数据库查询分析器”,后又开发了彻底删除文件(File Delete Absolutely),撰写了几十篇技术论文。马根峰(博客),硕士,研究方向:数据库应用。他开发了万能数据库查询分析器,中文版本《DB查询分析器》、英文版本《DB Query Analyzer》,该软件具有强大的功能、友好的操作界面、良好的操作性、跨越各种数据库平台乃至于EXCEL和文本文件。同时,他还开发了彻底删除文件(File Delete Absolutely),用以将Windows系统上的文件彻底删除,不会被其它软件恢复。

多学习,多思考,多实践
CSDN:请和大家介绍下你和目前所从事的工作。
马根峰:大家好,我是马根峰,我是一名程序员。2002年硕士毕业于重庆邮电大学,本科与硕士都是攻读计算机应用技术专业,曾获得过2002年重庆市优秀毕业硕士生、1991年河南省化学奥林匹克竞赛一等奖、国家乒乓球业余一级运动员和重庆市信合杯大中专院校乒乓球男单季军。
2002年到2005年在中国电信股份有限公司广东分公司担任资深数据分析师,负责为企业的经营分析提供数据支撑、电信相关业务系统的研究与开发、参与全球10大数据仓库应用系统――广东电信经营分析系统(TMAS)涉及到公话业务的需求制定与中期的测试评估工作。
2005年至今就职于广东联合电子服务股份有限公司,主要负责海量数据处理与分析、结算系统的运行维护。
个人开发了大型商业软件“万能数据库查询分析器”,撰写了关于“万能数据库查询分析器”的65篇技术文章,发表在国内的计算机刊物、百度文库、CSDN资源和本人的4大博客上。
CSDN:你是如何一步步走上软件开发之路的?
马根峰:从1996年大学毕业,近20年自己始终从事着计算机软件方面的工作,因为本科和硕士学的都是计算机应用技术专业,所以从感情上特别喜欢它。因为自己高中时期最喜欢的是化学,特别喜欢做化学实验。而计算机编程在我看来就是在做着“计算机程序设计的实验”,为了实现一个实际目标,将多种计算机程序开发语言语句去实现,有时候还要对多种算法进行分析。
在大学学习中,受益最深的一句话就是“多学习,多思考,多实践”;在工作中,我依然如此,争取做到举一反三;在职业上,我深信“专注于干一件事超过1万个小时才能成为专家”。
2002年到2005年在中国电信股份有限公司广东分公司工作期间,开发过“基于数据仓库和维度转换技术的广东电信公话200专用话机话务动态分析系统”。该技术成果“广东电信公话200专用话机话务动态分析系统的构建”发表在《电信科学》2003年11期;开发了“广东电信公话201亲情月卡用户重复购买率模型的计算”系统,该成果“广东电信公话201亲情月卡用户重复购买率模型的研究”发布在《世界电信》2006年1期。
2005年至今在广东联合电子服务股份有限公司工作期间,开发了“广东省高速公路节假日车辆通行数据统计”系统、“粤通卡超时车数据分析与统计”系统,对高速公路主管部门和高速公路业主提供数据支撑;开发了“基于数据仓库星形模式的广东省高速公路一张网资金结算情况分析系统”,技术成果发表于个人的博客上。
另外,从2003年我开始“万能数据库查询分析器”的构思、研究与开发,最终通过4年的努力,于2006年底发布1.0版本,从此以后,8年来不断对万能数据库查询分析器进行功能完善与升级,2014年7月发布5.05版本。
CSDN:在你的博客中有着大量中英对照文章,以及个人所开发的软件也有英文版的,你的英文水平是如何练就的?你认为英语在编程和软件开发中起着怎样的作用?
马根峰:学习英语就不怕少,就怕断。从1987年初中一年级开始学习英语起,一直到2013年,我一直没有怎么间断过英语的学习,英语写作与阅读还过得去,但听力与口语一直是弱项。
于是在2013年9月,参加了一个英语机构的培训班,开始了听、说、读写的强化学习,四个月时间雅思考到6分,听力最厉害的一次考到7.5分。
因为目前流行的编程语言都是以英语为基础的,国此,对于软件编程人员来说,英语的作用体现在阅读英文文档,适应国际化的编程环境,如果你想查看一些国外的文档,那最好还是要学习好英文,因为好多文档是没有翻译成中文的。
CSDN:你是一名程序员/软件开发者,却在几年内撰写了关于“万能数据库查询分析器”的65篇技术文章,很多程序员很讨厌写这样的学术类技术文章,你是怎样处理类似这些枯燥无味的事呢?
马根峰:大部分的软件开发人员喜欢开发程序,不喜欢写文档,尤其是学术类的技术文章。但这并不能否认它的好处。一方面,它可以让你的知识形成一定的沉淀,另一方面,同样会督促你去不断的学习新的知识。对于我来说,还有一个重要的原因,我要向更多的人介绍自己的产品的优势和使用技巧,帮助用户充分享受万能数据库查询分析器的便捷性。
万能数据库查询分析器的亮剑
CSDN:万能数据库查询分析器是一款怎样的数据软件?和其它同类软件的区别是什么?
马根峰:万能数据库查询分析器是一种支持对各种ODBC数据源(包括Oracle、Sybase、DB2、Informix、MS SQL SERVER、MYSQL、MS ACCESS、Paradox、FoxPro及SQLite等关系数据库,以及EXCEL和TXT/CSV)进行访问和操作的通用UDA工具。
它提供了一种通用的事务管理处理机制,允许用户自己来管理用户会话中的事务;允许用户随时中断正在执行的SQL语句,不会在数据库服务产生任何僵尸进程;允许提交多条DML语句乃至存贮过程,结果会以你设定的表格、文本框、文件来返回;从数据库导出千万条数据时,效率与DBMS没有什么区别;提供了数据库对象浏览器,使用户更方便地了解数据库的数据字典。
万能数据库查询分析器的强大功能、友好的操作界面、良好的操作性、跨越数据库平台,使得它成为世界上无以伦比的万能数据库查询分析器。
CSDN:当初你开发这样一款数据库软件的原因是什么?其中又经历了哪些困难?
马根峰:从大学开始接触计算机软件开发的20年时间内,从最早在内存为16MB、主频为133的586 PC上安装使用MS SQL Server 7.0到后来在高档服务器上使用DB2和Sybase,使用到过Oracle、MS SQL Server、Sybase、DB2大型数据库和桌面数据库ACCESS。我在饱偿了熟悉多种数据库客户端工具的痛苦的同时,也熟悉了常见大型数据库客户端工具各自的优势。这为我开发出具有强大功能、友好的操作界面、良好的操作性、跨越数据库平台的万能数据库查询分析器打下了坚实的基础。所以我非常希望"万能数据库查询分析器"能够帮助世界上更多的数据库应用人员从学习各种数据库的客户端工具的繁琐与复杂的工作之中解脱出来,充分享受它的便捷性,让程序员更多的专注于SQL语句的分析设计、SQL语句的优化上去,这也是中国本土程序员马根峰的梦想。
作为个人,要开发这样的一个近6万行代码的大开应用系统,并且使用了哈希技术、链地址法解决哈希冲突的方法、排序算法、多线程技术、API数据库访问技术、ADO数据库访问技术、Windows消息技术等等,必然会经历许许多的困难,包括开发的策略、系统功能的界定、程序的模块设计与代码设计、程序的测试方案。
程序代码设计中,因为涉及到了许多的算法和数据结构、强大的数据展现功能、EXE文件切分与加密、EXE壳文件的引导与加载、软件安全保护所用到的3DES算法的实现等等,所以遇到了非常大的挑战。每天晚上都是到了凌晨两点钟,才会洗刷睡觉,有时还搞上个通宵。节假日,别人都出去旅游了,他还在查阅资料、写代码,2006年国庆节哪都没出去,还熬了几次通宵。在整个代码编写过程中,解决了太多的代码错误与编辑错误,有时一个错误一个月都解决不了,没办法就先实现其它能够实现的功能,最后再努力回头找出原来的问题所在。
还有,最开始做系统原型的时候,采用了ADO数据库访问技术,但到最后,要实现中断SQL语句的执行时,尝试了许多ADO数据库控件的方法,都无法实现。这简直是给了我当头一棒,写了那么多的代码就这么废了。没办法,为了实现自己设想的具有强大功能的“万能数据库查询分析器”,必须重新寻找一种另外的数据库访问方法,重头开始。不过一旦实现了这一功能,也就使用“万能数据库查询分析器”更为脱颖而出。
而对于英文版本来说,另外存在的困难就是50多页白皮书的翻译与编写了。
“万能数据库查询分析器”的成功推出,离不开先进的开发策略、扎实的计算机程序的开发能力、扎实的计算机多个学科地理论基础与实践经验以及坚持不懈的毅力。
CSDN:在数据库软件开发方面,你认为需要掌握哪些基础技术知识和工具?在学习这些技术时,你有什么心得和体会可分享?
马根峰:从计算机课程上讲,个人觉得数据结构、算法分析、关系数据库技术对我的影响非常大,也受益非浅。
另外,精通一门开发工具和一种大型数据库系统,对数据库软件开发的程序员来说这是必须的,在此之外,能够学习一下其它的开发工具、其它的数据库系统,则是锦上添花。
CSDN:在开发这款软件中,你采用了什么方法和策略?
马根峰:通常来讲,如果系统的需求比较明确、系统实现的难度不大,那么可以采用“自上而下”或者“自下而上”的开发策略。
反之,当系统的需求不是那么明确时,比如我在开发“万能数据库查询分析器”时,因为对要实现的目标不是很具体,而且系统的开发难度很大,通过反复地思考,最终放弃这两种开发策略,采取最适合于大型应用系统开发的“原型法”开发策略,先开发出一个原型,然后逐渐完善、增加功能。先实现简单的基于DB2数据库系统的访问,然后逐步增加功能。在实现DB2数据库的方便、快捷、高效访问功能之后,然后再将功能扩展至所有数据库、TXT/CSV文件、EXCEL文件。
程序的测试方案,则是严格使用软件工程中的单元测试、模块测试、系统测试。而测试过程中,最困难的就是测试环境的搭建,以实现对每一种关系数据库系统的每一种数据类型的测试(基本上对各种数据类型都设计样本数据来涵盖边界值,来进行完整的测试,然后再用数据库本身的客户端工具进行查询,将二者的结果进行比对)、各种WINDOWS平台的运行测试。最终用了三个月左右在DB2、ORACLE、SYBASE、INFORMIX、MYSQL、MS SQL SERVER、ACCESS、FORPRO和PARADOX上进行了综合测试,后来进行了WIN98、WINDOWS XP、WINDOW NT、WINDOW 2000 SERVER、WINDOWS ADVANCED SERVER(2006年还没出现WIN7)的运行测试。
接着,为了检验算法的执行效率,还进行了压力测试。在PC机上用中文版本《DB?查询分析器》查询IBM?670小型机上安装的生产数据库服务器,并导出1100万条记录,在PC机本地生成了一个大小为2GB的文件,耗时15分钟;另外在生产数据库服务器主机IBM?670(拥有64GB的内存,8个物理CPU,16个逻辑CPU,存贮采取磁盘阵列),在这样的服务器上执行同样的查询脚本,导出同样的数据,耗时近6分钟。乍一看,《DB查询分析器》的“查询结果保存至文件”的导出效率相当于服务器上的40%。但深入地想一下,如果导出的文件要保存至客户端的情况下,是不是还要包括服务器导出的文件用FTP传送到客户端的时间,如果这二者所用时间之和会怎么样?我把IBM?670服务器上用DB2命令Export出来的文件FTP到PC客户上,用了14分36秒钟的时间。这样来看,《DB查询分析器》的“查询结果保存至文件”的导出效率更高。
就是因为,这样充分的测试,保障了“万能数据库查询分析器”的健壮性与高效性。这也充分得到了用户在反馈中表现出的认可。
CSDN:该款软件如今的应用情况如何?
马根峰:自2003年开始研究与开发,2006年底1.0版本发布及获得计算机软件著作权证书,到目前为上近8年时间不断地进行功能的完善,推出最新5.05版本。
自己的努力也得到了广大用户与媒体的支持,《程序员》2007年第2期“新产品&工具点评”栏目特别推荐“万能数据库查询分析器的发布”。
截止到2014年7月31日,在Baidu上搜索关键字"万能数据库查询分析器",搜索结果超过490万。
本人还撰写了关于“万能数据库查询分析器”的65篇技术文章,发表在国内的计算机刊物、百度文库、CSDN资源和本人的4大博客上。
在本人单位,“万能数据库查询分析器”被同事广泛使用,用来进行DB2、SYBASE数据库的访问,进行数据分析与处理。
在太平洋软件,“万能数据库查询分析器”中文版本《DB查询分析器》在数据库类排行榜中居第1位;“万能数据库查询分析器”中文版本《DB查询分析器》在中国最大的软件下载网站中关村在线的数据库类排行榜中居前10位,获得超过100,000次的下载。
CSDN:能否谈一下国内外的数据库软件开发的现状?
马根峰:数据库技术是企业信息化的核心,企业规模的大小对数据库开发与应用的需求是不同的。因此大型数据库系统、企业级数据库系统和桌面数据库系统在企业的不同发展阶段都会被使用。这就造成企业的不同应用存在着不同种类的数据库,同时数据库的操作与维护会非常困难,因此国内外都在研究解决这个问题。我开发的万能数据库查询分析器很好的解决这一问题。
CSDN:因数据库软件导致出现网络中断和系统宕机的事件有很多,你认为数据库软件容易出现故障的原因是什么?又该如何防范呢?
马根峰:通常来说,引起系统宕机的原因比较复杂,常见的原因有以下:
A、事务内部的故障;
B、操作系统或者数据库系统故障
C、介质故障
D、计算机病毒
针对以上的几点,在数据库维护或者数据库应用软件的开发时,要避免产生大量日志的事务操作,即避免对大量数据库记录进行操作后一次提交事务,比如向系统提交数据时,可以操作一批记录后提交一次事务;在大量删除数据表记录时,为了避免产生大量的日志,可以先将不删除的数据原导出,再将表清空,最后导入要保留的数据的方式。
- 为了避免操作系统或者数据库系统故障,应及时打上相关补丁。
- 为了避免介质故障所带来的危害,可以用磁盘阵列。根据不同的数据库数据安全要求,采取不同的Raid。
- 而为了避免计算机病毒的入侵,需要实施一定的防病毒策略,在业务机和数据库服务器主机上安装防病毒软件。
海量数据的分析、处理;算法分析、设计与开发
CSDN:大数据如风一样刮遍整个IT界,你认为大数据(Big Data)等同于海量数据(Large- Scale Data或Vast Data)吗?为什么?
马根峰:关于大数据,我个人认为这是一个社会发展的必然。随着人类社会的发展,我们进入了信息时代,一个信息爆炸的时代。互联网以及移动互联网的高速发展、迅速普及,让信息无处不在、无孔不入,同时也在时刻影响着我们的生活习惯和生活方式,比如几年前还不被人认可但现在却非常盛行的网上购物。信息爆炸也代表着巨大的信息量,另外并不是所有的信息都是有益的。
而在另一方面,随着计算机信息技术包括存贮技术与芯片等计算机硬件技术、数据仓库和数据挖掘、分布式处理等软件技术的不断发展,使得“从这些海量的数据中挖掘出有价值的信息,为企业带来巨大的经济效益”成为可能。
正是需求方(特别是一些销售企业和公司)和信息服务提供方(一些大的计算机软硬件公司)存在的这种共同目标,使得大数据的分析与处理成为信息技术中一个引领时代潮流的方向。
关于大数据的特征,仁者见仁、智者见智,但个人认为“数据量巨大”、“数据类型多样”无疑是其中最为重要的两大特征,数据类型不仅包括结构化的数据,还包括非结构化的数据;不仅是文本形式,还有的是图片、视频、音频、地理位置信息等多类型的数据。正是围绕着这两大特征,使得大数据的采集、导入/预处理、挖掘、预测/分析的响应速度与精度成为各个计算机数据处理模型与算法追求的目标,软件商提供的“大数据处理”商业产品也正是在这几点处理上展现自己的卖点。
总之,大数据的数据量不仅是海量,而且不完全像平常处理的海量数据都是结构化的数据,大数据还包括“类型多样”数据如非结构化的数据。
CSDN:在实际工作中接触到海量的数据处理问题时,对其进行处理是一项艰巨而复杂的任务,会随之面临哪些困难?
马根峰:多年来在海量数据的处理中,遇到了不少的困难,如
1.非法数据问题:由于数据量过大,数据中什么情况都可能存在
在中国电信股份有限公司广东分公司工作时,曾经处理过全省IC卡的话单文件,就发现在不同的IC卡话机上传上来的话单文件中,非法字符是千奇百怪,结果为了对话单进行各种数据异常的预处理中就占用了太多的流程处理。
而在广东联合电子服务股份有限公司工作期间,处理“广深高速公路公司的回传流水”的时候,最后在生成了海量数据文件后,发现数据库记录总条数与所有文件的总行数之和不相等。最终为了找出原因,又对这些海量数据文件进行处理,发现有个别字段中含有ASCII值为0AH的字符,而unix文件中行结束符为0AH,因此导致有些数据表记录导出时形成了文件中的多行。
最后,又要对哪些包含0AH的字段进行统计之后,再修改整个数据生成脚本。
2.软硬件要求高,系统资源占用率高
“巧妇难为无米之炊”。在大数据的处理中,即使算法再优化,也必须要加大CPU和内存。海量数据处理中常用的哈希技术与排序算法,都要求有足够的内存;而更快CPU的处理速度,则直接缩短海量数据的总耗时。
3.算法的要求更高。
不同的算法对于少量的数据处理而言,差别也大不到哪儿去。但对于海量数据的处理而言,差的算法在时间上,你都可能无法忍受。
CSDN:海量数据的处理包含哪些内容?海量数据处理涉及哪些算法?在实践时,你有哪些经验和技巧?
马根峰:海量数据的处理包括海量数据文件的处理、海量数据库数据表的数据处理。
海量数据处理中常用的算法有哈希技术、堆排序。
中国电信股份有限公司广东分公司是中国电信集团中最大的分公司,业务收入占全国的近1/6,最厉害的时候几乎相当于浙江、江苏和上海三个分公司的总和。相应的,广东电信的数据也是海量中的海量,2005年前仅公话200业务,一个月的话单就是30多个GB共3亿多条话单,而一个月发生话务的200卡就在1900多万张。
那时候做的最大型的、最复杂算法的处理就是签约分销商售卡的话务统计。计算的目标就是统计出所有分销商销售的卡在本月发生的各个类别的话务。分销商的售卡记录是几千条记录,每条记录包含销售卡的起始200卡流水号、结束200卡流水号等信息,流水号与卡号的对应有1亿条记录,每个月的30多GB的3亿条公话200话单中包含1900多万张卡的话务信息,如何从每条话单中找出对应200卡对应的流水号,然后找出对应的分销商,复杂度为:3亿话单×1亿多条200卡与流水号对应×几千条售卡记录。复杂到什么程度?就是用大型数据库技术是难以实现的,最后决定采用文件的处理,在算法上使用哈希表+二分查找进行算法设计,用DELPHI进行程序的开发,最终在4台PC机上进行分布计算了近1个小时实现整个数据处理过程。该技术已撰写成论文“区间表的快速查找算法”发表在《计算机工程与设计》2005年第4期。
在广东联合电子服务股份有限公司,处理的是整个广东省的高速公路通行数据与结算,广东省珠三角高速公路网的密集程度在世界上排名第二,仅次于日本。所以车辆通行记录也是海量数据级别的,每个月的通行记录近1亿条,拆分数据3亿多条。用的数据库服务器有160GB内存+40个逻辑CPU,数据库系统为IBM的DB2。在这里主要进行的海量数据表的数据处理,主要涉及到SQL语句的优化,最复杂的运算的是处理全省几年来每个月份每条高速公路拆分后降档车减免优惠的计算,每个月的处理SQL脚本就在100多行,涉及多张上亿条数据表关联查询。由于SQL语句太复杂,国家审计署的专家也无法看明白,本人专门画了数据流图与模块分析进行相应功能的讲解。该技术已撰写成论文“软件开发高手须掌握的4大SQL精髓语句(综合篇)”。
CSDN:在海量数据处理中,都有哪些查找算法?效率比较高的是什么算法,有什么特点?
马根峰:在多年的工作中,由于经常进行海量数据的处理及数据分析,因此较为擅长于算法分析、设计与开发(尤其是海量数据分析与处理中的算法分析、设计与开发);设计的算法及研究成果大多已撰写成22篇论文,发表在国内15家刊物(含核心刊物)。
海量数据处理中,常用的查找算法包括折半查找、二叉树查找和B_树查找。
而上述查找算法的查找效率依赖于查找过程中所进行的比较次数。而我们期望的情况是希望不经过任何比较,一次存取便能得到所查记录,那就必须在记录的存储位置和它的关键字之间建立一个确定的关系f,使每个关键字和结构中一个唯一的存储位置相对应。因而在查找时,只要根据这个对应关系f找到给定值K的像f(K)。若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,由此,不需要进行比较便可直接取得所查记录。这个对应关系f就是哈希函数,按这个思想建立的表为哈希表。
A、哈希函数的选定
哈希表的构造方法很多,常用的方法包括直接定址法、数字分析法、平方取中法、折叠法、除数余数法和随机数法。其中除数余数法是种最简单,也最常用的构造哈希函数的方法。在海量话单文件的处理中,我通常选用除数余数法来构造哈希函数,将200话单中的话机号码转换成int64型,这个int64型整数除以一个大质数P即为该话机号码所对应的哈希值。
P值的选择:在使用除数余数法时,对P值的选择很重要。若选的不好,容易产生哈希冲突。根据众人的经验,可以选P为质数或不包含小于20的质因数的合数。在《哈希技术在广东电信200话单统计中的应用》中所采用的是寻找一个大质数P,并且P大致为全省发行的200充值卡的数量。这可以在哈希表类中增加一个函数来构造这个大质数P。
哈希表长度的确定:由于P大致为全省发行的200充值卡的数量,所以可以利用P作为哈希表的长度。
B、处理冲突的方法的选定
通常用的处理冲突的方法有下面几种,开放定址法、再哈希法、链地址法和建立一个公共溢出区法。在本应用中我采用的是链地址法。因为采用链地址法时,查找成功时的平均查找长度Snc和不成功时的长度Unc都比较小,
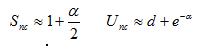
其中α=表中填入的记录数/哈希表的长度,由于哈希表中填入的记录数据为一个分公司发行的200充值卡的数量,所以在这里α<<0.5
该技术已撰写成论文“哈希表在电信公用电话客户流失分析中的应用”发表在《计算机工程与设计》2003年第12期。
数据仓库项目开发
CSDN:数据仓库与数据挖掘有什么异同?前者有什么特点?
马根峰:数据仓库技术是用以更好地支持企业或组织的决策分析处理的,具有面向主题的,集成的,不可更新的、随时间不断变化这四大特征的数据集合。它通过将数据按照不同的综合程度(即粒度)来组织,以满足不同分析的需要。
而数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中寻找其规律的技术。
CSDN:你是怎么理解数据仓库中的面向主题的?
马根峰:主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如《广东省高速公路一张网资金结算情况分析系统》的“资金结算情况的分析”就是一个分析领域,因此这个数据仓库应用的主题就是“资金结算情况的分析”。
数据仓库中的数据是面向主题进行组织的。为了实现“资金结算情况的分析”这一主题,在界定系统边界时,确定管理者最迫切进行的分析目标主要有:
A、从广东全省各高速公路合并成一张网后,到目前为止,各条高速公路的流水上传、流水拆分情况。
B、分析并网后各个高速公路路段公司上传的异常流水(包含异常及拆分异常)、及异常流水的修改情况;
要进行以上的分析,所需数据应包括:
A、OLTP数据库中,各个高速公路路段公司在这段周期内的流水上传、拆分。
B、各个高速公路路段公司上传的异常流水(包含异常及拆分异常)、及上传的异常的流水(包含异常及拆分异常)流水的修改情况;
C、各个高速公路路段公司及他们的软件开发商
D、广东省高速公路所有的路段信息;
接下来,就要对所需要的数据进行逻辑模型设计,最后通过结合OLTP中的数据库表,来生成数据仓库的数据。
CSDN:数据质量问题的表现形式怎样的?以及如何提升数据仓库的数据质量?
马根峰:数据质量问题通常有以下几种表现形式:
A、.数据不完整。
这种情况比较常见,例如记录的缺失、字段信息的缺失、记录不完整等
B、.数据不一致。虽然面向OLAP的数据仓库解决了数据源的“蜘蛛网”问题,但难以避免的是有可能存在着数据的不一致情况。因此,数据仓库中的数据有可能与OLTP中的数据库存在着不一致现象。
C、.数据有错误。这种情况主要是指数据中存在各种不合法的情况,例如数据类型错误、数据范围越界、数据违反业务规则等。
如何提升数据仓库的数据质量?无非是从数据源和数据抽取这两个部分进行控制。
A、数据源。从规章制度上,规范OLTP生产环境下的数据完整性控制,保障输入到系统中的数据是有效的、准确的。
B、数据抽取/提取。1. 在同类的数据有多个数据源时,要对数据源的可信度进行排序,尽量抽取可信度高的数据源中的同类数据。2. 对数据仓库的维表数据源建立定期更新机制,有效地保障OLTP环境与OLAP环境下的数据一致性。
CSDN:开发建设一个灵活有效的数据仓库有哪些步骤?
马根峰:数据仓库的设计大体上可以分为以下几个步骤:
A、概念模型设计;
B、技术准备工作;
C、逻辑模型设计;
D、物理模型设计;
E、数据仓库生成;
F、数据仓库运行与维护。
CSDN:进行数据仓库项目开发的时候有哪些注意事项?是否有成功的数据仓库项目的介绍呢?
马根峰:数据仓库项目设计时,本人觉得有两个非常关键的地方,一个是数据仓库的“概念模型设计中的界定系统边界”,这个阶段最重要的是确定管理者最迫切进行的分析,然后根据要进行的分析决定所需数据;另一个是数据仓库的“逻辑模型设计”,目标是确定粒度层次划分。粒度是数据综合级别的程度。在数据仓库中,多重粒度是必不可少的。数据仓库的主要作用是DSS分析,因而其绝大部分查询都基于一定程度的综合数据之上,而只有较少的查询涉及细节。
2002年到2005年本人在中国电信股份有限公司广东分公司担任资深数据分析师时,主要负责为企业的经营分析提供数据支撑,那时开发过“基于数据仓库和维度转换技术的广东电信公话200专用话机话务动态分析系统”。该技术成果“广东电信公话200专用话机话务动态分析系统的构建”发表在《电信科学》2003年11期。
2005年至今就职于广东联合电子服务股份有限公司,主要负责海量数据处理与分析、结算系统的运行维护、进行一些前台数据库程序的开发。开发了“基于数据仓库星形模式的广东省高速公路一张网资金结算情况分析系统”,技术成果发表于个人的4大博客。
CSDN:你对没有经验和职业生涯中期的数据库研究者或从业者有什么建议吗?
马根峰:首先可以深入学习一些关系数据库的理论知识,在实践中多掌握一些数据库SQL语句的优化技术,而后者是数据库维护与应用开发中不可缺少的能力。
然后,可以学习一些数据仓库的理论知识。因为现在的数据仓库基本上都是基于关系数据库系统采用星形模式建立起来的,所以掌握一门流行的大型数据库系统(如Oracle、DB2等)是必须的。
最后,万变不离其宗,无论是数据仓库、大数据、云计算,无非就是数据的组织策略、处理方式有了新的发展,但核心的数据库的理论知识、一些数据处理的算法和数据结构还是几乎没有什么变化。
专注于干一件事超过1万个小时才能成为专家
CSDN:假如你有足够多额外的工作时间去做其它的事,那你会做什么事呢?
马根峰:会将对我开发的彻底删除文件(File Delete Absolutely)进行比较大的改动,当用户选择文件时,只删除他/她选中的文件;则当他/她选中目录的话,将对选中的所有目录以及这些目录下的所有文件进行删除。而目前它只是名副其实的只是彻底删除文件。
另外还会完善我的数据库执行调度程序的完善,将它应用到世面上所有的数据库。实现用户在提交执行脚本(如果有返回结果,则允许输入保存的文件名)和执行时间后,不管数据库服务器期间有没有宕机,只要在执行计划的那一刻数据库服务是起来的,执行计划就照样会执行。
CSDN:作为一个数据库研究人员,如果你能改变你自己,那你将改变什么?
马根峰:我会尽可能地学习一些专业的前沿技术,尽可能地与技术人员相互交流,尽可能地多实践一些算法优化,尽可能地承担一些复杂的具有挑战性的数据分析处理与创新工作。
CSDN:这一路走来,十几年的时间,你自己最大的感悟是什么?
马根峰:在大学学习中,受益最深的一句话就是“多学习,多思考,多实践”。在职业上,我深信“专注于干一件事超过1万个小时才能成为专家”。家庭方面,我相信“家和万事兴”、“成家而立业”。只有家庭和睦,你才有充足的精力去工作。
|






