|
近日,Pinterest公开了其大数据平台的打造理念――在重度使用Hadoop和AWS的情况下,Pinterest力争打造一个自服务的平台。而在平台打造的过程中,他们还不得不衡量多个MapReduce解决方案的扩展性等问题。
大数据为Pinterest打造了线上最丰富的兴趣集,在网站的配置和运营中发挥着重要的作用,为了迅速搭建大数据平台,Pinterest将单个集群Hadoop基础设施升级为一个通用的自服务平台。近日,Pinterest在该公司的博客上公布了这个平台的打造过程。
以下为译文:
大数据在Pinterest中扮演着重要的角色。系统中有300多亿Pins,我们打造了线上最丰富的兴趣集。打造个性化搜索引擎的一个挑战是扩展数据基础设施以遍历兴趣图谱,进而提取每一Pin的内容和意图。
目前我们每天更新20TB数据,S3每天会更新大概10TB数据。我们使用Hadoop处理这些数据,Hadoop使得我们可以通过Related Pins、Guided Search及image processing等功能将最相关和最新的内容呈现给Pinners。Hadoop每天可以帮助我们执行数千个度量,探测严格实验条件下的用户变化并进行分析。
为了迅速搭建大数据应用,我们将单个集群Hadoop基础设施升级为一个通用的自服务平台。

为Hadoop搭建一个自服务平台
尽管Hadoop是一个强大的处理和存储系统,但是它还不是一项即插即用的技术。因为Hadoop没有云计算和弹性计算,也不面向非技术用户,所以最初的Hadoop设计无法作为一个自服务系统。好在很多Hadoop库、Hadoop应用和服务提供商针对这些局限提供了解决方案。在选择解决方案前,我们先讨论了我们的Hadoop设置需求。
1.多租户隔离:MapReduce上有许多需求和配置不同应用程序,开发者应该在不影响他人工作的前提下优化自己的工作。
2.弹性:批处理通常需要突发性能来支持实验开发。一个理想的配置中,我们可以扩展至数千个节点集群,然后在不导致任何中断和数据损失的情况下减少规模。
3.多集群支持:尽管我们可以水平扩展单个Hadoop集群,我们发现:很难获得理想的隔离性和弹性;诸如隐私、安全、成本分摊等商业需求使多集群支持更为实用。
4.支持临时集群:用户应当可以在需要使用集群时获得集群,并可以随时退出集群。集群在合理的时间范围内存在,并可以在不需要手动配置的情况下全面支持所有的Hadoop工作。
5.易于软件包部署:从OS和Hadoop层到具体业务脚层面,我们需要为用户提供定制化的接口。
6.共享数据存储:Hadoop也应可以访问其它集群产生的数据。
7.访问控制层:和其它的服务导向的系统一样,我们需要快速添加和修改访问(如非SSH关键词)。理想情况下,我们可以和现有认证(如通过OAUTH)整合。
权衡和实施
总结出需求后,我们在一系列自行开发的、开源的和商业专有的解决方案中寻找符合我们需求的解决方案。
解耦计算和存储:为加快处理速度,传统的MapReduce采用数据本地化。实际中,我们发现网络I/O(我们使用的是S3)并没有比磁盘I/O慢很多。通过支付网络I/O的边际成本和将计算从存储分离,我们很容易的实现我们的自服务Hadoop平台的许多需求。例如,因为我们不再需要考虑加载或同步数据,所以多集群支持变得很容易,任何现有或将来的集群都可以通过一个共享文件系统使用数据。不需要担心数据意味着更简单的操作,这是因为我们可以在不丢失任何工作的情况下进行硬复位或丢弃一个集群,迁移到另一个集群。这也意味着我们可以使用动态的节点,因此我们可以支付低廉的计算机费用,不担心损失任何持久性数据。

集中式Hive元存储作为解决方案:我们大部分的工作都选用Hadoop,这是因为SQL接口很简单,业界对SQL接口也很熟悉。随着时间的推移,我们发现使用元存储作为Hadoop工作的数据目录时,Hive还会带来额外的好处。Hive很像其它的SQL工具,它提供了诸如“show tables”,“describe table”和“show partitions”的功能。这个接口比在目录中决定生成文件的清单文件简洁的多,也快的多,一致性也更好,这是因为MySQL数据库支持着这个接口。S3的清单文件很慢,S3不支持移动,还有一致性的问题。因为我们依赖于S3,所以Hive的这些特性显得更重要。
我们用与现有磁盘数据保持Hive元数据一致性的方式排列工作(是Hive,Cascading,Hadoop Steaming还是其它的)。因此,我们可以在多集群和多工作流更新磁盘数据,无需担心用户可能获得部分数据。
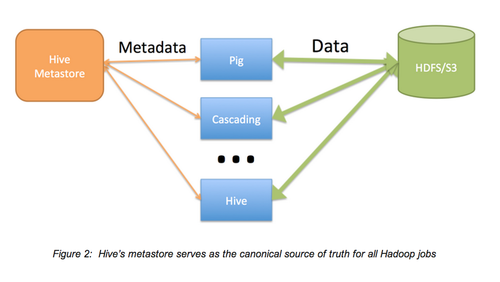
多层包/配置:Hadoop应用间差异很大,每个应用都可能有独特的需求和依赖项。我们需要一种灵活的、可以权衡可定制性和快速配置/速度的方法。
我们采用一种三层的方法来管理依赖项,这种方法可以将产生、调用一个千节点集群的时间从45分钟减到5分钟。
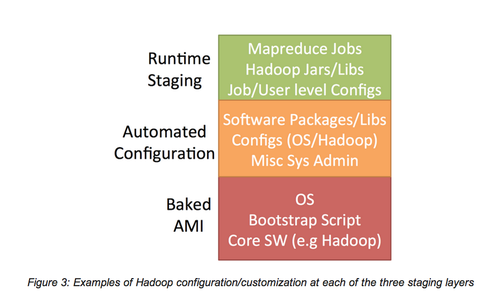
1.Baking AMI
对于那些较大的、需要花一段时间安装的依赖项,我们将他们预安装。其中包括我们为了国际化所采用的Hadoop库和NLP库包。我们将这一过程称为“baking an AMI”。不幸的是,很多Hadoop服务供应商尚不支持这种方法。
2.自动化配置(无管理的Puppet)
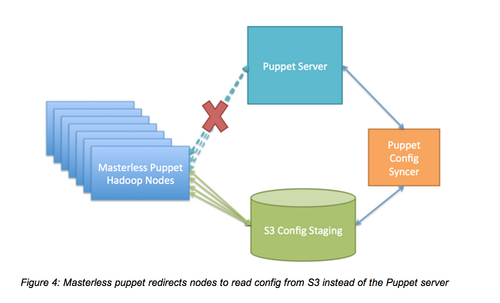
我们大部分的定制化服务是使用Puppet管理的。在引导程序阶段,我们的集群在每个节点都安装和配置Puppet,仅需几分钟的时间,Puppet就可以将我们的节点和Puppet配置指定的依赖项匹配。
目前,Puppet主要的局限性如下:当我们在生产系统添加新节点时,这些新节点会自动联系Puppet管理,推翻新配置,这常常会覆盖主节点,进而导致错误。为了避免这种错误,我们允许Puppet客户端从S3获取配置,设置一个负责同步S3配置和Puppet管理的服务,从而将Puppet客户端设置为“无管理”。
3.运行阶段(在S3上)
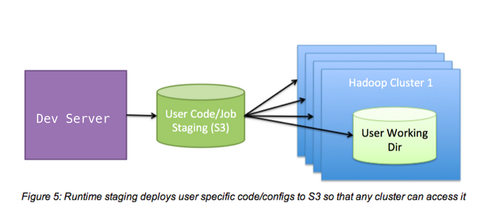
MapReduce工作间发生的大部分定制化服务都涉及jars,工作配置和自定义代码。开发组需要可以在开发环境中修改这些依赖项,并且在不影响其他工作的前提下使这些依赖项在我们的任意一个Hadoop集群中可用。为了权衡灵活性、速度和隔离性,我们为S3上的每个开发者创建了一个隔离的工作目录。现在,当一个工作执行时,一个工作目录面向一个开发者,工作路径的依赖项直接从S3获得。
执行抽象层
先前,我们使用亚马逊的Elastic MapReduce(EMR)运行我们的Hadoop工作。EMR和S3、Spot实例运行的很好,通常也很稳定。但当我们扩展到几百个节点时,EMR变得没那么稳定,我们遇到了EMR的局限。我们在EMR上搭建了很多应用,以至于我们很难迁移到一个新系统。我们也不知道更换到哪种系统,因为EMR的一些细微差异会导致实际工作逻辑差异。为了试验其它类型的Hadoop,我们实施了一个执行接口,将所有的EMR特定逻辑都迁移到EMR执行接口。 这个接口实施了一系列方法,如“run_raw_hive_query(query_str)” 和 “run_java_job(class_path)”。这使得我们具有在几种Hadoop和Hadoop服务供应商上实验的灵活性,并可以以最小的停机时间逐渐迁移。
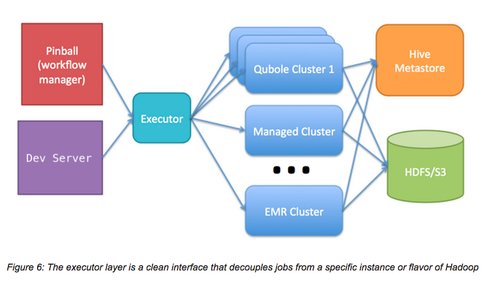
最终采用Qubole
最终我们决定将我们的Hadoop工作迁移到Qubole,Quble是Hadoop服务市场的新秀。考虑到目前我们的规模下EMR不再稳定,我们必须快速迁移到一个良好支持AWS(特别是spot实例)和S3的供应商。Qubole支持AWS/S3,并且起步简单。在审核Qubole,并将其性能和几个候选者(包括管理集群)比较后,我们选择了Qubole,原因如下:
- 单个集群和横向扩展至1000个节点
- 提供24/7的数据基础设施工程服务
- 与Hive紧密集成
- Google“面向非技术用户的OAUTH ACL和Hive Web UI”
- 面向简化的执行抽象层+多集群支持的API
- Baking AMI定制化服务(专业版支持可用)
- 面向spot实例的高级支持―100%支持spot实例集群
- S3最终一致性保护
- 优雅的集群扩展和自动扩展
总的来说,使用Qubole对我们而言是一个正确的决定,Qubole团队的技术和实施工作深深地打动了我们。从去年开始,Qubole证明了其在拍字节规模的稳定性,相比EMR,为我们提高了30%~60%的吞吐量。非技术用户也很容易上手Qubole。
我们目前的状态
在我们当下的配置下,Hadoop是一项应用在多组织、操作费用低的灵活服务。我们有100多个常规Mapreduce用户,他们每天通过Qubole网络接口、ad-hoc工作和计划工作流运行着2000多个工作。
我们有6个Hadoop集群,他们由3000多个节点组成,开发者可以在几分钟内选择创建自己的Hadoop集群。我们每天生成200亿日志信息,处理大概1拍字节的数据。
我们也在试验者管理Hadoop集群,其中包括Hadoop2,不过目前,使用诸如S3和Qubole的云服务对我们而言是正确的选择,因为它们将我们从Hadoop的操作开销中解放出来,使我们可以专注于大数据应用的工程工作。 |






