|
ǰ��
��Mahout�������Ƽ�ϵͳ����һ���ȼ������ѵ����顣������ΪMahout�����ط�װ�ˡ�Эͬ���ˡ��㷨����ʵ���˲��л����ṩ�dz���API�ӿڣ���������Ϊ���Dz��˽��㷨ϸ�ڣ�����ȥ����ҵ��ij��������㷨���ú͵��š�
���Ľ������㷨APIȥ����Mahout�Ƽ��㷨�ײ��һЩ�¡�
1. Mahout�Ƽ��㷨����
Mahoutt�Ƽ��㷨�������ݴ��������ϣ����Ի���Ϊ2�ࣺ
�����ڴ��㷨ʵ��
����Hadoop�ķֲ�ʽ�㷨ʵ��
1). �����ڴ��㷨ʵ��
�����ڴ��㷨ʵ�֣������ڵ��������е��㷨������cf.taste��Ŀʵ�ֵģ����ҵ�����Ϥ��UserCF,ItemCF��֧�ֵ����ڴ����У����Ҳ�������������á������㷨�Ļ���ʵ������ο����£���Maven����Mahout��Ŀ
�����ڴ��㷨���������ڣ������ڵ�������Դ�������еȹ�ģ�����ݣ���1G,10G�������������������м��㣬���dz���100G�������������ڵ�����˵�Dz�������ɵ�����
2). ����Hadoop�ķֲ�ʽ�㷨ʵ��
����Hadoop�ķֲ�ʽ�㷨ʵ�֣����ǰѵ����ڴ��㷨���л����������ɢ����̨�����һ�����С�Mahout�ṩ��ItemCF����Hadoop���л��㷨ʵ�֡�����Hadoop�ķֲ�ʽ�㷨ʵ�֣���ο����£�
Mahout�ֲ�ʽ���� ������Ʒ��Эͬ����ItemCF
�ֲ�ʽ�����㷨���������ڣ�����õ����㷨���л����ڵ����㷨�У�����ֻ��Ҫ�����㷨�����ݽṹ���ڴ棬CPU���ˣ����Ƿֲ�ʽ�㷨��Ҫ���⿼�Ǻܶ������������ڵ�����ݺϲ�������������·ͨ�ŵ�Ч�ʣ��ڵ�崻����㣬���ݷֲ�ʽ�洢�ȵȵĺܶ����⡣
2. �㷨���б����ٻ���(recall)�����(precision)
Mahout�ṩ��2�������Ƽ�����ָ�꣬���ʺ��ٻ��ʣ���ȫ�ʣ���������ָ�������������о���Ķ���������
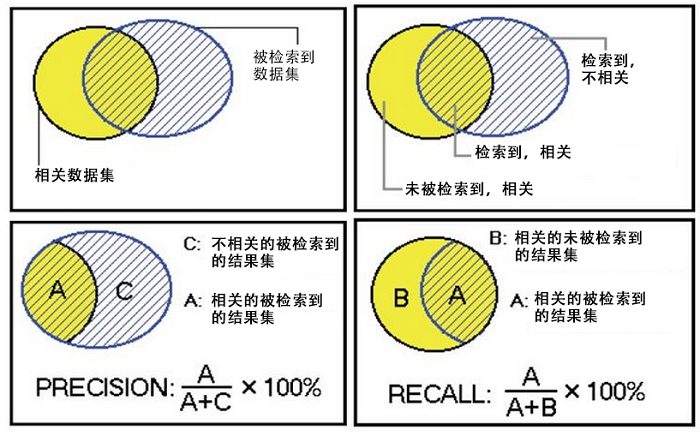
A���������ģ���ص� ���ѵ���Ҳ��Ҫ�ģ�
B��δ�������ģ�������ص� ��û�ѵ���Ȼ��ʵ������Ҫ�ģ�
C���������ģ����Dz���ص� ���ѵ��ĵ�û�õģ�
D��δ�������ģ�Ҳ����ص� ��û�ѵ�Ҳû�õģ�
����������Խ��Խ�ã�������ȫ�ʡ�����A/(A+B)��Խ��Խ�á�
���������ģ�Խ��ص�Խ��Խ�ã�����ص�Խ��Խ�ã��������ʡ�����A/(A+C)��Խ��Խ�á�
�ڴ��ģ���ݼ����У�������ָ�������Լ�ġ���ϣ����������������ݵ�ʱ���ʾͻ��½�����ϣ��������ȷ��ʱ���������ٵ����ݡ�
3. Recommender��API�ӿ�
1). ϵͳ����:
Win7 64bit
Java 1.6.0_45
Maven 3
Eclipse Juno Service Release 2
Mahout 0.8
Hadoop 1.1.2 |
2). Recommender�ӿ��ļ���
org.apache.mahout.cf.taste.recommender.Recommender.java

�ӿ��з����Ľ��ͣ�
recommend(long userID, int howMany):
����Ƽ��������userID�Ƽ�howMany��Item
recommend(long userID, int howMany,
IDRescorer rescorer): ����Ƽ��������userID�Ƽ�howMany��Item�����Ը���rescorer�Խṹ��������
estimatePreference(long userID, long
itemID): �����Ϊ�գ������û�����Ʒ�Ĵ��
setPreference(long userID, long itemID,
float value): ��ֵ�û�����Ʒ�����
removePreference(long userID, long itemID):
ɾ���û�����Ʒ�Ĵ��
getDataModel(): ��ȡ�Ƽ�����
ͨ��Recommender�ӿڣ��ҿ��Բ³������㷨��Ӧ�û��������estimatePreference()�����н���ʵ�֡�
3). ͨ���̳й�ϵ��Recommender�ӿڵ����ࣺ

�Ƽ��㷨ʵ���ࣺ
GenericUserBasedRecommender: �����û����Ƽ��㷨
GenericItemBasedRecommender: ������Ʒ���Ƽ��㷨
KnnItemBasedRecommender: ������Ʒ��KNN�Ƽ��㷨
SlopeOneRecommender: Slope�Ƽ��㷨
SVDRecommender: SVD�Ƽ��㷨
TreeClusteringRecommender��TreeCluster�Ƽ��㷨
���潫�ֱ����ÿ���㷨��ʵ�֡�
4. ���Գ���RecommenderTest.java
�������ݼ���item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0 |
���Գ���org.conan.mymahout.recommendation.job.RecommenderTest.java
package org.conan.mymahout.recommendation.job;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.common.RandomUtils;
public class RecommenderTest {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws
TasteException, IOException {
RandomUtils.useTestSeed();
String file = "datafile/item.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
slopeOne(dataModel);
}
public static void userCF(DataModel dataModel)
throws TasteException{}
public static void itemCF(DataModel dataModel)
throws TasteException{}
public static void slopeOne(DataModel dataModel)
throws TasteException{}
... |
ÿ���㷨��һ�������ķ��������㷨���ԣ���userCF(),itemCF(),slopeOne()��.
5. �����û���Эͬ�����㷨UserCF
�����û���Эͬ���ˣ�ͨ����ͬ�û�����Ʒ�������������û�֮��������ԣ������û�֮��������������Ƽ������������ǣ����û��Ƽ�������Ȥ���Ƶ������û�ϲ������Ʒ��
����˵����
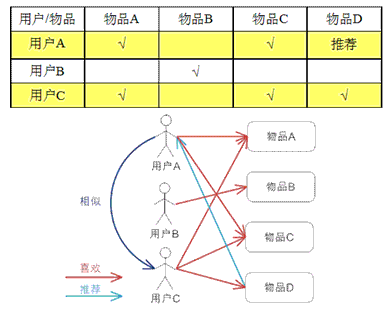
�����û��� CF �Ļ���˼���൱�������û�����Ʒ��ƫ���ҵ������ھ��û���Ȼ���ھ��û�ϲ�����Ƽ�����ǰ�û��������ϣ����ǽ�һ���û���������Ʒ��ƫ����Ϊһ�������������û�֮������ƶȣ��ҵ�
K �ھӺ����ھӵ����ƶ�Ȩ���Լ����Ƕ���Ʒ��ƫ�ã�Ԥ�ǰ�û�û��ƫ�õ�δ�漰��Ʒ������õ�һ���������Ʒ�б���Ϊ�Ƽ���ͼ
2 ������һ�����ӣ������û� A�������û�����ʷƫ�ã�����ֻ����õ�һ���ھ� �C �û� C��Ȼ���û�
C ϲ������Ʒ D �Ƽ����û� A��
������ͼƬ�ͽ������֣�ժ�ԣ� https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
�㷨API: org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
long[] theNeighborhood = neighborhood.getUserNeighborhood(userID);
return doEstimatePreference(userID, theNeighborhood, itemID);
}
protected float doEstimatePreference(long theUserID,
long[] theNeighborhood, long itemID) throws
TasteException {
if (theNeighborhood.length == 0) {
return Float.NaN;
}
DataModel dataModel = getDataModel();
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
for (long userID : theNeighborhood) {
if (userID != theUserID) {
// See GenericItemBasedRecommender.doEstimatePreference()
too
Float pref = dataModel.getPreferenceValue(userID,
itemID);
if (pref != null) {
double theSimilarity = similarity.userSimilarity(theUserID,
userID);
if (!Double.isNaN(theSimilarity)) {
preference += theSimilarity * pref;
totalSimilarity += theSimilarity;
count++;
}
}
}
}
// Throw out the estimate if it was based on no
data points, of course, but also if based on
// just one. This is a bit of a band-aid on the
'stock' item-based algorithm for the moment.
// The reason is that in this case the estimate
is, simply, the user's rating for one item
// that happened to have a defined similarity.
The similarity score doesn't matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
} |
���Գ���:
public static void userCF(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity
(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood
(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder =
RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE,
recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.0
Recommender IR Evaluator: [Precision:0.5,Recall:0.5]
uid:1,(104,4.333333)(106,4.000000)
uid:2,(105,4.049678)
uid:3,(103,3.512787)(102,2.747869)
uid:4,(102,3.000000) |
��R������дUserCF��ʵ�֣���ο����£���R����Mahout�û��Ƽ�Эͬ�����㷨(UserCF)
6. ������Ʒ��Эͬ�����㷨ItemCF
����item��Эͬ���ˣ�ͨ���û��Բ�ͬitem������������item֮��������ԣ�����item֮��������������Ƽ������������ǣ����û��Ƽ�����֮ǰϲ������Ʒ���Ƶ���Ʒ��
����˵����
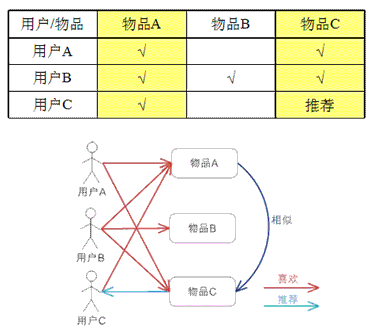
������Ʒ�� CF ��ԭ���ͻ����û��� CF ���ƣ�ֻ���ڼ����ھ�ʱ������Ʒ�����������Ǵ��û��ĽǶȣ��������û�����Ʒ��ƫ���ҵ����Ƶ���Ʒ��Ȼ������û�����ʷƫ�ã��Ƽ����Ƶ���Ʒ�������Ӽ���ĽǶȿ������ǽ������û���ij����Ʒ��ƫ����Ϊһ��������������Ʒ֮������ƶȣ��õ���Ʒ��������Ʒ�����û���ʷ��ƫ��Ԥ�ǰ�û���û�б�ʾƫ�õ���Ʒ������õ�һ���������Ʒ�б���Ϊ�Ƽ���ͼ
3 ������һ�����ӣ�������Ʒ A�����������û�����ʷƫ�ã�ϲ����Ʒ A ���û���ϲ����Ʒ C���ó���Ʒ
A ����Ʒ C �Ƚ����ƣ����û� C ϲ����Ʒ A����ô�����ƶϳ��û� C ����Ҳϲ����Ʒ C��
������ͼƬ�ͽ������֣�ժ�ԣ� https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
�㷨API: org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
PreferenceArray preferencesFromUser = getDataModel().getPreferencesFromUser(userID);
Float actualPref = getPreferenceForItem(preferencesFromUser, itemID);
if (actualPref != null) {
return actualPref;
}
return doEstimatePreference(userID, preferencesFromUser, itemID);
}
protected float doEstimatePreference(long userID,
PreferenceArray preferencesFromUser, long itemID)
throws TasteException {
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
double[] similarities = similarity.itemSimilarities(itemID,
preferencesFromUser.getIDs());
for (int i = 0; i < similarities.length; i++)
{
double theSimilarity = similarities[i];
if (!Double.isNaN(theSimilarity)) {
// Weights can be negative!
preference += theSimilarity * preferencesFromUser.getValue(i);
totalSimilarity += theSimilarity;
count++;
}
}
// Throw out the estimate if it was based on no
data points, of course, but also if based on
// just one. This is a bit of a band-aid on the
'stock' item-based algorithm for the moment.
// The reason is that in this case the estimate
is, simply, the user's rating for one item
// that happened to have a defined similarity.
The similarity score doesn't matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
} |
���Գ���:
public static void itemCF(DataModel dataModel) throws TasteException {
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity
(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE,
recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.8676552772521973
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(105,3.823529)(104,3.722222)(106,3.478261)
uid:2,(106,2.984848)(105,2.537037)(107,2.000000)
uid:3,(106,3.648649)(102,3.380000)(103,3.312500)
uid:4,(107,4.722222)(105,4.313953)(102,4.025000)
uid:5,(107,3.736842) |
7. SlopeOne�㷨
����㷨��mahout-0.8�汾�У��Ѿ���@Deprecated��
SlopeOne��һ�ּ�Ч��Эͬ�����㷨��ͨ���������������֡�SlopeOne��������(PDF)
1). ����˵����
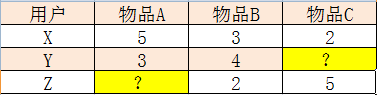
�û�X��Y��Z��������ƷA,B���д�֣����±�����Z��B�Ĵ���Ƕ��٣�
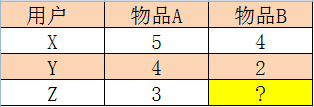
Slope one�㷨��Ϊ��ƽ��ֵ���Դ���ij����δ֪����֮��Ĵ�ֲ��죬����A������B��ƽ�����ǣ�((5
- 4) + (4 - 2)) / 2 = 1.5���͵õ�Z��B�Ĵ���ǣ�3-1.5 = 1.5��
Slope one�㷨���û�������֮��Ĺ�ϵ���������Թ�ϵ��
Y = mX + b
2). ƽ����Ȩ���㣺
�û�X��Y��Z��������ƷA,B,C���д�֣����±�����Z��A�Ĵ���Ƕ��٣�
1. ����A��B��ƽ����, ((5-3)+(3-4))/2=0.5
2. ����A��C��ƽ����, (5-2)/1=3
3. Z��A�����֣�ͨ��AB�õ�, 2+0.5=2.5
4. Z��A�����֣�ͨ��AC�õ���5+3=8
5. ͨ����Ȩƽ������Z��A�����֣�A��B�������۵��û���Ϊ2,A��C�������۵��û���Ϊ1��Ȩ��Ϊ����2��1��
(2*2.5+1*8)/(2+1)=13/3=4.33
ͨ�����ּķ�ʽ�����ǿ��Կ��ټ����һ�����������Ƽ����̣�
�㷨API: org.apache.mahout.cf.taste.impl.recommender.slopeone.SlopeOneRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
return doEstimatePreference(userID, itemID);
}
private float doEstimatePreference(long userID, long itemID) throws TasteException {
double count = 0.0;
double totalPreference = 0.0;
PreferenceArray prefs = getDataModel().getPreferencesFromUser(userID);
RunningAverage[] averages = diffStorage.getDiffs(userID, itemID, prefs);
int size = prefs.length();
for (int i = 0; i < size; i++) {
RunningAverage averageDiff = averages[i];
if (averageDiff != null) {
double averageDiffValue = averageDiff.getAverage();
if (weighted) {
double weight = averageDiff.getCount();
if (stdDevWeighted) {
double stdev = ((RunningAverageAndStdDev) averageDiff).getStandardDeviation();
if (!Double.isNaN(stdev)) {
weight /= 1.0 + stdev;
}
// If stdev is NaN, then it is because count is 1. Because we're weighting by count,
// the weight is already relatively low. We effectively assume stdev is 0.0 here and
// that is reasonable enough. Otherwise, dividing by NaN would yield a weight of NaN
// and disqualify this pref entirely
// (Thanks Daemmon)
}
totalPreference += weight * (prefs.getValue(i) + averageDiffValue);
count += weight;
} else {
totalPreference += prefs.getValue(i) + averageDiffValue;
count += 1.0;
}
}
}
if (count <= 0.0) {
RunningAverage itemAverage = diffStorage.getAverageItemPref(itemID);
return itemAverage == null ? Float.NaN : (float) itemAverage.getAverage();
} else {
return (float) (totalPreference / count);
}
} |
���Գ���:
public static void slopeOne(DataModel dataModel) throws TasteException {
RecommenderBuilder recommenderBuilder = RecommendFactory.slopeOneRecommender();
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE,
recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.3333333333333333
Recommender IR Evaluator: [Precision:0.25,Recall:0.5]
uid:1,(105,5.750000)(104,5.250000)(106,4.500000)
uid:2,(105,2.286115)(106,1.500000)
uid:3,(106,2.000000)(102,1.666667)(103,1.625000)
uid:4,(105,4.976859)(102,3.509071) |
8. KNN Linear interpolation item�Cbased�Ƽ��㷨
����㷨��mahout-0.8�汾�У��Ѿ���@Deprecated��
�㷨�������ģ�This algorithm is based in the
paper of Robert M. Bell and Yehuda Koren in ICDM '07.
(TODO�)
�㷨API: org.apache.mahout.cf.taste.impl.recommender.knn.KnnItemBasedRecommender
@Override
protected float doEstimatePreference(long theUserID, PreferenceArray preferencesFromUser, long itemID)
throws TasteException {
DataModel dataModel = getDataModel();
int size = preferencesFromUser.length();
FastIDSet possibleItemIDs = new FastIDSet(size);
for (int i = 0; i < size; i++) {
possibleItemIDs.add(preferencesFromUser.getItemID(i));
}
possibleItemIDs.remove(itemID);
List mostSimilar = mostSimilarItems(itemID, possibleItemIDs.iterator(),
neighborhoodSize, null);
long[] theNeighborhood = new long[mostSimilar.size() + 1];
theNeighborhood[0] = -1;
List usersRatedNeighborhood = Lists.newArrayList();
int nOffset = 0;
for (RecommendedItem rec : mostSimilar) {
theNeighborhood[nOffset++] = rec.getItemID();
}
if (!mostSimilar.isEmpty()) {
theNeighborhood[mostSimilar.size()] = itemID;
for (int i = 0; i < theNeighborhood.length; i++) {
PreferenceArray usersNeighborhood = dataModel.getPreferencesForItem(theNeighborhood[i]);
int size1 = usersRatedNeighborhood.isEmpty() ? usersNeighborhood.length() : usersRatedNeighborhood.size();
for (int j = 0; j < size1; j++) {
if (i == 0) {
usersRatedNeighborhood.add(usersNeighborhood.getUserID(j));
} else {
if (j >= usersRatedNeighborhood.size()) {
break;
}
long index = usersRatedNeighborhood.get(j);
if (!usersNeighborhood.hasPrefWithUserID(index) || index == theUserID) {
usersRatedNeighborhood.remove(index);
j--;
}
}
}
}
}
double[] weights = null;
if (!mostSimilar.isEmpty()) {
weights = getInterpolations(itemID, theNeighborhood,
usersRatedNeighborhood);
}
int i = 0;
double preference = 0.0;
double totalSimilarity = 0.0;
for (long jitem : theNeighborhood) {
Float pref = dataModel.getPreferenceValue(theUserID,
jitem);
if (pref != null) {
double weight = weights[i];
preference += pref * weight;
totalSimilarity += weight;
}
i++;
}
return totalSimilarity == 0.0 ? Float.NaN : (float)
(preference / totalSimilarity);
}
} |
���Գ���:
public static void itemKNN(DataModel dataModel) throws TasteException {
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity
(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.
itemKNNRecommender(itemSimilarity, new NonNegativeQuadraticOptimizer(), 10);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE,
recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.5
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(107,5.000000)(104,3.501168)(106,3.498198)
uid:2,(105,2.878995)(106,2.878086)(107,2.000000)
uid:3,(103,3.667444)(102,3.667161)(106,3.667019)
uid:4,(107,4.750247)(102,4.122755)(105,4.122709)
uid:5,(107,3.833621) |
9. SVD�Ƽ��㷨
(TODO�)
�㷨API: org.apache.mahout.cf.taste.impl.recommender.svd.SVDRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
double[] userFeatures = factorization.getUserFeatures(userID);
double[] itemFeatures = factorization.getItemFeatures(itemID);
double estimate = 0;
for (int feature = 0; feature < userFeatures.length; feature++) {
estimate += userFeatures[feature] * itemFeatures[feature];
}
return (float) estimate;
} |
���Գ���:
public static void svd(DataModel dataModel) throws TasteException {
RecommenderBuilder recommenderBuilder =
RecommendFactory.svdRecommender(new ALSWRFactorizer(dataModel, 10, 0.05, 10));
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.
AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder,
null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.09990564982096355
Recommender IR Evaluator: [Precision:0.5,Recall:1.0]
uid:1,(104,4.032909)(105,3.390885)(107,1.858541)
uid:2,(105,3.761718)(106,2.951908)(107,1.561116)
uid:3,(103,5.593422)(102,2.458930)(106,-0.091259)
uid:4,(105,4.068329)(102,3.534025)(107,0.206257)
uid:5,(107,0.105169) |
10. Tree Cluster-based �Ƽ��㷨
����㷨��mahout-0.8�汾�У��Ѿ���@Deprecated��
(TODO�)
�㷨API: org.apache.mahout.cf.taste.impl.recommender.TreeClusteringRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
buildClusters();
List topRecsForUser = topRecsByUserID.get(userID);
if (topRecsForUser != null) {
for (RecommendedItem item : topRecsForUser) {
if (itemID == item.getItemID()) {
return item.getValue();
}
}
}
// Hmm, we have no idea. The item is not in the user's cluster
return Float.NaN;
} |
���Գ���:
public static void treeCluster(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity
(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
ClusterSimilarity clusterSimilarity = RecommendFactory.clusterSimilarity
(RecommendFactory.SIMILARITY.FARTHEST_NEIGHBOR_CLUSTER, userSimilarity);
RecommenderBuilder recommenderBuilder = RecommendFactory.
treeClusterRecommender(clusterSimilarity, 10);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE,
recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder,
null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid,
RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
} |
���������
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:NaN
Recommender IR Evaluator: [Precision:NaN,Recall:0.0] |
11. Mahout�Ƽ��㷨�ܽ�
�㷨�����ó�����
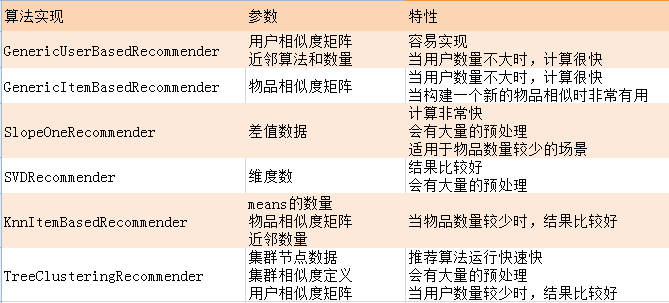
�㷨���ֵĽ����

ͨ�������漸���㷨��һƽ�ֱȽϣ�itemCF,itemKNN,SVD��Rrecision,Recall������ֵ����õģ�����itemCF��
SVD��AVERAGE_ABSOLUTE_DIFFERENCE����͵ģ����ԣ����㷨�ĽǶ�֪���ˣ��ĸ��㷨�Ǹ�ȷ�Ļ�����������������ݼ���
�����һЩ���أ�
1. ��3��ָ�꣬������ֱ�Ӿ���������һ��itemCF,SVD��
2. �����㷨�IJ������Dz�û�е���
3. �����������ݷֲ�����Ӱ���㷨������ |






