|
�˽��������
������������һ������ɻָ��ԣ��ز����ٵ�������
�������û�����ͬһ���ݿ���Դʱ���Է��ʵ��Ⱥ����Ȩ������һ�ֻ��ƣ�û���������������һ����Ϳ�����ܱ�֤���ݵİ�ȫ��ȷ��д��
�����������ݿ����ܵ�������ɱ��֮һ��������ȴ�Dz�ͬ����֮����ռ������Դ��ɵġ�
����������ȥ��ͦ����ģ����ĸо����ڳ������������ú����������ǵķ�ɣ���������ǵĿ�ɧ����
��˵����--�������
�û�������е�һ��������ڹ���£�ȥ�����յ㣬�ص�ԭ�㡣
����˵����
��һ�������У���д��2��sql��䣬һ�����Ķ�����״̬,һ�����Ŀ������-1
�� ������Ķ�����״̬��ʱ������������ܹ��ع������ݽ��ָ���û��֮ǰ������״̬��������Ŀ��Ҳ�Ͳ�ִ�У�����ȷ�����ϵ����һ�£���ȫ����
�������������ӣ���Ƣ����Ҫôȫ��ִ�У�Ҫôȫ����ִ�У��ص�ԭ����״̬��
������ͣ��������ԭ���ԣ�һ���ԣ������ԣ��־��ԡ�
ԭ���ԣ����������һ���Զ������ĵ�Ԫ��Ҫôȫ��ִ�У�Ҫôȫ����ִ�С�
һ���ԣ����������ʱ�����е��ڲ����ݶ�����ȷ�ġ�
�����ԣ������������ʱ�������������ڲ����ݣ������Ķ�������һ��������֮ǰ��֮������ݡ�
�־��ԣ������ύ֮�������������Եģ������ٻع���
Ȼ����SQL Server������Ϊ3�ೣ��������
�Զ��ύ������SQL ServerĬ�ϵ�һ������ģʽ��ÿ��Sql��䶼������һ��������д�������Ӧ��û�м�����һ��Update
��2���ֶε���䣬ֻ����1���ֶζ�����һ���ֶ�û���ġ���
��ʽ����T-sql��������Begin Transaction��������ʼ����Commit
Transaction �ύ����Rollback Transaction �ع����������
��ʽ����ʹ��Set IMPLICIT_TRANSACTIONS ON
������ʽ����ģʽ������Begin Transaction��������һ��������������ģʽ���Զ�������һ������ֻ��Commit
Transaction �ύ����Rollback Transaction �ع����ɡ�
��ʽ�����Ӧ��
���������ĸ���
Begin Transaction���������ʼ��
Commit Transaction�������Ѿ��ɹ�ִ�У������Ѿ���������
Rollback Transaction�����ݴ��������г������ع���û�д���֮ǰ������״̬����ع��������ڲ��ı���㡣
Save Transaction�������ڲ����õı���㣬����������Բ�ȫ���ع���ֻ�ع��������֤�����ڲ���������ǰ���¡�
����Ķ����ķ�������ĸ���������ʽ��Ҫ����ϸ����
1 ---��������
2 begin tran
3 --���������ƣ�������������Ҳ�еġ����ҿ���Ƕ�ס�
4 begin try
5 --�����ȷ
6 insert into lives (Eat,Play,Numb) values ('����','����',1)
7 --NumbΪint���ͣ�����
8 insert into lives (Eat,Play,Numb) values ('����','����','abc')
9 --�����ȷ
10 insert into lives (Eat,Play,Numb) values ('����','����',2)
11 end try
12 begin catch
13 select Error_number() as ErrorNumber, --�������
14 Error_severity() as ErrorSeverity, --�������ؼ��𣬼���С��10 try catch ����
15 Error_state() as ErrorState , --����״̬��
16 Error_Procedure() as ErrorProcedure , --���ִ���Ĵ洢���̻��������ơ�
17 Error_line() as ErrorLine, --����������к�
18 Error_message() as ErrorMessage --����ľ�����Ϣ
19 if(@@trancount>0) --ȫ�ֱ���@@trancount����������ֵ+1���������ж����п�������
20 rollback tran ---���ڳ���������ع�����ʼ����һ�����Ҳû�в���ɹ���
21 end catch
22 if(@@trancount>0)
23 commit tran --����ɹ�Lives���У�������3�����ݡ�
24
25 --������Ϊ�ձ���ID ,NumbΪint ���ͣ�����Ϊnvarchar����
26 select * from lives |

---��������
begin tran
--���������ƣ�������������Ҳ�еġ����ҿ���Ƕ�ס�
begin try
--�����ȷ
insert into lives (Eat,Play,Numb) values ('����','����',1)
--���뱣���
save tran pigOneIn
--NumbΪint���ͣ�����
insert into lives (Eat,Play,Numb) values ('����','����',2)
--�����ȷ
insert into lives (Eat,Play,Numb) values ('����','����',3)
end try
begin catch
select Error_number() as ErrorNumber, --�������
Error_severity() as ErrorSeverity, --�������ؼ��𣬼���С��10 try catch ����
Error_state() as ErrorState , --����״̬��
Error_Procedure() as ErrorProcedure , --���ִ���Ĵ洢���̻��������ơ�
Error_line() as ErrorLine, --����������к�
Error_message() as ErrorMessage --����ľ�����Ϣ
if(@@trancount>0) --ȫ�ֱ���@@trancount����������ֵ+1���������ж����п�������
rollback tran ---���ڳ���������ع�����ԭ�㣬��һ�����Ҳû�в���ɹ���
end catch
if(@@trancount>0)
rollback tran pigOneIn --����ɹ�Lives���У�������3�����ݡ�
--������Ϊ�ձ���ID ,NumbΪint ���ͣ�����Ϊnvarchar����
select * from lives |

ʹ��set xact_abort
���� xact_abort on/off , ָ���Ƿ�ع���ǰ����Ϊonʱ�����ǰsql�������ع���������Ϊoffʱ���sql�����ع���ǰsql��䣬��������ճ����ж�д���ݿ⡣
��Ҫע���ʱ��xact_abortֻ������ʱ���ֵĴ������ã����sql�����ڱ���ʱ������ô����ʧ������
delete lives --�������
set xact_abort off
begin tran
--�����ȷ
insert into lives (Eat,Play,Numb) values ('����','����',1)
--NumbΪint���ͣ�����,���1234..�Ǹ������ݻ���'132dsaf' xact_abort��ʧЧ
insert into lives (Eat,Play,Numb) values ('����','����',12345646879783213)
--�����ȷ
insert into lives (Eat,Play,Numb) values ('����','����',3)
commit tran
select * from lives
Ϊonʱ�������Ϊ�գ���Ϊ���������ݹ�������������ع���������
�������������������
����������������ѯ���ڣ����������䣬�ֱ����2����ѯ���ڣ���5��������2������ģ�顣
begin tran
update lives set play='���'
waitfor delay '0:0:5'
update dbo.Earth set Animal='�ϻ�'
commit tran
begin tran
update Earth set Animal='�ϻ�'
waitfor delay '0:0:5' --�ȴ�5��ִ����������
update lives set play='���'
commit tran
select * from lives
select * from Earth |

Ϊʲô�أ��������ǿ�������ʲô������
��������ɰܽԹ�������������
�ڶ��û���������ͬʱ����ͬһ��������Դ������£��ͻ�������¼������ݴ���
���¶�ʧ������û�ͬʱ��һ��������Դ���и��£��ض�����������ǵ����ݣ�������ݶ�д�쳣��
�����ظ��������һ���û���һ�������ж�ζ�ȡһ�����ݣ�������һ���û���ͬʱ�������������ݣ���ɵ�һ���û���ζ�ȡ���ݲ�һ�¡�
�������һ�������ȡ�ڶ����������ڸ��µ����ݱ�������ڶ�������û�и�����ɣ���ô��һ�������ȡ�����ݽ���һ��Ϊ���¹��ģ�һ�뻹û���¹������ݣ����������ݺ������塣
�ö�����һ�������ȡһ��������ڶ���������������������ɾ������Ȼ����һ���������ٴζ������������в�ѯʱ�����ݷ��ֶ�ʧ��������
Ȼ������������Ϊ�����Щ���������ģ����Ĵ���ʹ��һ����������Լ������ݿ���в�����ʱ������һ���������ܲ�����Щ���ݿ顣�������ν��������
���������ݿ�ϵͳ�ĽǶȴ��¿��Է�Ϊ6�֣�
��������S���������Խ������������Բ�����ȡ���ݣ������������ݡ�Ҳ����˵��������Դ�ϴ��ڹ�������ʱ�����е������ܶ������Դ�����ģ�ֱ�����ݶ�ȡ��ɣ��������ͷš�
��������X���������Խ�����ռ����д��������������������Դ������ɾ�IJ���ʱ�������������κ�������������Դ��ֱ�����������ͷţ���ֹͬʱ��ͬһ��Դ���ж��ز�����
��������U������ֹ������������ģʽ�����������һ��������Դ�����ȶ�ȡ���ĵ�����£�ʹ�ù���������������ʱ�������������ʹ�ø���������Ա��������ij��֡���Դ�ĸ�����һ��ֻ�ܷ����һ�����������Ҫ����Դ�����ģ������������������������Ϊ��������
��������SQL Server��Ҫ�ڲ�νṹ�еĵײ���Դ�ϣ����У��У���ȡ������������������������������������������������ͱ�ʾ����Ҫ�Ա���ҳ������ʹ�ù��������ڱ���ijһ�����Ϸ��������������Է�ֹ���������ȡ���������ݵĵ���������������������ܣ���Ϊ�������治��Ҫ�����Դ��ÿһ��ÿһ�У������ж��Ƿ���Ի�ȡ������Դ�ļ������������������������ͣ�����������IS����������������IX��������������������SIX����
�ܹ�������ֹ�ı��ṹʱ���������ʵ�����
����������������������߳̽����������ݲ����IJ��뵽ͬһ�����У��ڼ��ص�ͬʱ���������������̷��ʸñ���
��Щ��֮���������ԣ�Ҳ���ǣ��Ƿ����ͬʱ���ڡ�

�������Ծ���μ���http://msdn.microsoft.com/zh-cn/library/ms186396.aspx
�����ȺͲ�νṹ�μ���http://msdn.microsoft.com/zh-cn/library/ms189849(v=sql.105).aspx
����
ʲô��������Ϊʲô��������������� ����������������������� �����µ������������������������Ӧ�û������������㡣
�����������ģ�
��һ������ΪA�����ȸ���lives�� --->>ͣ��5��---->>����earth��
�ڶ�������ΪB�����ȸ���earth��--->>ͣ��5��---->>����lives��
��ִ������A----5��֮��---ִ������B��������������
�����������ӵģ�
A����lives��������lives�����������ɹ���
B����earth��������earth�����������ɹ���
5�����
A����earth������earth��������������Bռ����earth�����������ȴ���
B����lives������lives��������������Aռ����lives�����������ȴ���
������ȴ��Է��ͷ���Դ�������Դ��дӵ��������������ͱ���Ϊ��������Ҳ������������Ϊʲô��������������оٳ�������
Ȼ�����ݿⲢû�г������ȴ������������Ϊ���ݿ���������ᶨ�ڼ������״����һ�����������������ѡ��һ��������Ϊ����Ʒ��������������ع����ݡ��е����������ڹ���ľ�ţ��������Ե��˶���������ľ���м䣬�������ˮ���ض�Ҫ��һ���˸��˻�����������ȴ��Ĺ��̣���һ�ֺ�ʱ����Դ�����������ܱ���ܡ�
�ĸ��˻ᱻ�˻�������Ϊ����Ʒ����������ǿ��Կ��Ƶġ��������
set deadlock_priority <����>
�������������ȼ���Ϊ low<normal<high����ָ���������Ĭ��Ϊnormal������ƷΪ��������ָ��������ƷΪ����͵ġ�
������ʹ��������������ʶ����-10��-5Ϊlow��-5Ϊnormal��-5��10Ϊhigh��
���������ķ�����������ݿ�����
������ʱ����Դ��Ȼ���ڴ������ݿ��У��߲��������������Dz��ɱ���ģ���������ֻ�������ĸ��١�
����ͬһ˳��������ݿ���Դ���������ӾͲ��ᷢ��������
����������ļ�̣�������Ҫ��һ�����������ڸ��ӵĶ�д������������ڸ��ӣ�ռ����Դ�����࣬����ʱ�����������������������ͻ�������������ʡ�
������Ҫ��������Ҫ���û���Ӧ����������������֮�����������������ύ�������ӳ�����ռ����Դ��ʱ�䣬Ҳ�������������ʡ�
�����������ݿ�IJ�������
������ʹ�÷�������������ͼ�������ݷ����ڲ�ͬ�Ĵ��̺��ļ����У���ɢ���ʱ����ڲ�ͬ���������ݣ�������Ϊ���з���������ɵ���������ʱ��ȴ���
����ռ��ʱ��ܳ����ҹ�ϵ�����ӵ����ݲ�����
ʹ�ýϵ͵ĸ��뼶��ʹ�ýϵ͵ĸ��뼶���ʹ�ýϸߵĸ��뼶����й�������ʱ����̡������ͼ����������á�
�ɲο���http://msdn.microsoft.com/zh-cn/library/ms191242(v=sql.105).aspx
�鿴��������
--�鿴������
select * from sys.dm_tran_locks
--�鿴�������
dbcc opentran
�ɲο���http://msdn.microsoft.com/zh-cn/library/ms190345.aspx
Ϊ�������ø��뼶��
��ν������뼶�𣬾��Dz��������ͬһ��Դ�Ķ�ȡ��Ȳ�Ρ���Ϊ5�֡�
read uncommitted��������뼶������������Զ�ȡ��һ���������ڴ��������ݣ�������δ�ύ�����ּ���Ķ�ȡ���������
read committed�����������Ĭ��ѡ�������������ܶ�ȡ�������ڴ���û���ύ�����ݣ������ġ�
repeatable read�����ܶ�ȡ�������ڴ��������ݣ�Ҳ����������������ǰ�����ݡ�
snapshot��ָ�������ڿ�ʼ��ʱ�ͻ�����Ѿ��ύ���ݵĿ��գ���˵�ǰ����ֻ�ܿ�������ʼ֮ǰ�������������ġ�
serializable�����������뼶��ֻ�ܿ���������֮ǰ�����ݡ�
--�
set tran isolation level <����>
read uncommitted���뼶������ӣ�
begin tran
set deadlock_priority low
update Earth set Animal='�ϻ�'
waitfor delay '0:0:5' --�ȴ�5��ִ����������
rollback tran |
������һ����ѯ����ִ���������
set tran isolation level read uncommitted
select * from Earth --��ȡ������Ϊ�����ĵ����� �����
waitfor delay '0:0:5' --5��֮�������Ѿ��ع�
select * from Earth --�ع�֮������� |
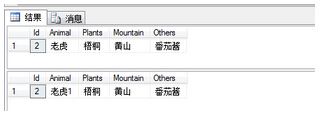
read committed���뼶������ӣ�
begin tran
����update Earth set Animal='�ϻ�'
����waitfor delay '0:0:10' --�ȴ�5��ִ����������
����rollback tran
����set tran isolation level read committed
����select * from Earth ---��ȡ�����ϻ����������
����update Earth set Animal='����1' --������
����waitfor delay '0:0:10' --10��֮����һ�������Ѿ��ع�
����select * from Earth --��֮������ݣ������Ǻ��� |
ʣ�µļ������𣬲�һһ�о������Լ�����ɡ�
��������ʱʱ��
����������ʱ�����ݿ�������Զ����������������⣬Ȼ���������Ǻܱ�����ֻ���ڷ��������ȴ�������
Ȼ������Ҳ����������������������ʱʱ�䣬һ����Դ�������������������õ�����ʱ�䣬��������Զ�ȡ�����ͷ���Դ����1222����
�ö���һ�㶼���������ԣ����ŵ�ͬʱ��Ҳ�����IJ���֮�����Ǿ���һ������ʱ�䣬���ȡ�����ͷ���Դ�����ǵ�ǰ����������ع�����������ݴ�������Ҫ�ڳ����в���1222�����ó�������ǰ���������ʹ������ȷ��
--�鿴��ʱʱ��,Ĭ��Ϊ-1
select @@lock_timeout
--���ó�ʱʱ��
set lock_timeout 0 --Ϊ0ʱ����Ϊһ��������Դ�������������������ڵȴ�����ǰ���ع�������ʱ��������������°�����hold��ס�ġ�
��ϸ�Ķ���ϣ���ܷ�������һ��㶫����лл��over��
|






