|
����ǰ����QQ����֮����̨3�������Ŷ�֮һ��QQ��Ӫ�飬������������Ѷ�ڲ��ķ���ϵͳ������������ʽ����ϵͳ�ϻ����˴������飬��������Ӧ�õ����ݽ������ADs�����ߡ�
NoSQL�DZ�������Ӵ���������������֪ʶ������ڴ�Ҷ��ڳ�̸Hadoop��Sparkʱ��������Ȼ������NoSQL���ĵ��Ķ�ϰ�ߡ���ż���Ķ�һƪRedis���Ĺ����У����߷�����jacksu>�ĸ��˲��ͣ��������з����˴����ķֲ�ʽϵͳ�������飬�Ӷ�ͨ�����������˽���QQ����֮����̨3�������Ŷ�֮һ��QQ��Ӫ�飬��������һ���߽���

QQ�������Ŷ�
CSDN�����ȣ������һ�������Ŷӣ�
�����������Ŷ����罻������ҵȺ���罻������Ӫ�����������ģ�ƽ̨�������飬ǰ����QQ����֮����̨3�������Ŷ�֮һ��QQ��Ӫ�顣Ŀǰ�Ŷӳ�Ա10�ˣ���Ҫ�����罻������ҵȺ�Ļ��������ھ�ϵͳ�Ͳ�ƷӦ��ϵͳ���з�����Ӫ����Ϊ��Ѷ�ڲ������о���ʹ��Hadoop���Ŷӣ����Hadoop��Spark�ȿ�Դϵͳ���Ƴ�����Ӧ�õ����ݽ������ADs��Aggregate Data services�����������������������ڣ����������ӹ�ϵ�����㣬�з���Ȧ�ӷֲ�ʽ����ϵͳ�ȡ�Ŀǰ����Ȥ�����������ķֲ�ʽ����Ӧ�ÿ�������ϵͳ����R2���Լ����ݿ��ӻ���Ӧ�á�
CSDN�����Ŷ���ADs�����ߣ��ɷ�Ϊ���ǽ���һ�µ���ADs����Ѷ��ʹ�ó̶ȣ�����֧�ŵ�ҵ���������ݼ�����Ⱥ��ģ�ȡ�
������ADs����Ѷ��ʱͨ����ͨ�õģ����������ռ����ַ��Ļ�����ʩ��ADs��һϵ�������ͳ�ƣ���Щ����������Ϊ�����з�����������������֧��ʵʱ�����ߵĶ�����������Ŀǰ��ADs��Ⱥ��700̨���ͷ��������մ���������2300�����ң��洢����10PB+��Ϊ��Ѷ�ڲ�5�����ţ�20���ҵ�����ṩ��Ч��֧�ţ��������ݲ�ѯ�����ݷ�������Ʒͳ�ơ������ھ���û��Ƽ��ȡ���QQ���ֻ�QQ���Լ�����ͨ����ʱͨ�Ź��߽����ҵ����������ݶ�����ADs�����ṩ����
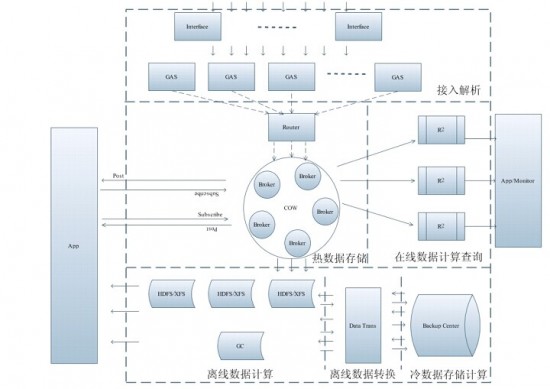
ͼһ ADs�ܹ�ͼ
CSDN��������֪����չ���Ǵ�������ܹ��бز����ٵ�һ����������Ѷ��ʵ��������һЩnode rebalance��ط�����
��������չ�ԣ������ǿ������������ֺ��壺��һ���ǹ��ܵ���չ�ԣ�����һ��������ϵͳ���µ���չ�ԡ�
���ڹ��ܵ���չ����ϵͳ�����ϣ����������Ǹ���ϵͳ���صĹ��ܣ�����ɲ�ͬ�������ͬ���֮��Ľ�ϣ����������չ������³����Ĺ��ܡ����磬ADs�ͳ���������Զ�������GAS��General Analyses Service������������´洢��COW���������ת����DataT�����GAS��COW�����ṩӦ�õ����ݻ�ȡ����GAS��DataT�ṩ������ģ�ͼ���ʹ�á�
��������ϵͳ��������չ��һ�㶼����Ƴ�ȥ���Ļ��Ľṹ��ÿ���ڵ��ṩ�Եȵķ�������������GAS������ˣ�ÿ������������ǶԵȵķ�����������������������������ݣ�ͨ���������ĸ��½ڵ�·�ɣ���֤����һ�£�����һЩ��Ϣ̽��Ļ��ƣ���ʹ��ijЩ���������û�и���·�ɣ�Ҳ���ᶪʧ��Ϣ��
CSDN�����ߴ������ڣ����������з���R2���ɷ����һ���뵱�����м�����Spark��Storm�ĶԱȣ�
���������ȣ�R2 �����п�Դ��Ŀ���IJ�ͬ��������һ��ʼ����Ϊ������ʵʱ�������Ƶģ������������ܺ͵��ӳٺ�ϵͳ������Ҫ���ǿ�����磬���Ƽ�����ҵ���У���Ҫ��200ms�ڷ������ݣ������漰����������ȴ���ܸߴX��MB�������������㽵����ʱ����һ����ս����Σ��Ӽܹ��Ͽ���R2��һ���ԳƵĽṹ��û�е��㡣�ڵ�����������弴�ã��������ݲ�Ӱ�������Դ���һ����Դ���еĴ��ͻ�����˵��������ʱʹ�ÿ�����Դ����ʡ�ɱ����ٴΣ��ӹ����Ͻ���R2��һЩ�ض��ĵ����������˴����Ż���ʹ�úܶ������㷨��ʵ�ֱ�ü�Ч��
CSDN����ADs�У�����ʹ��Hadoop�����ߴ�������ô��˹�ģ�£���Ҫ����ս��ʲô����������Щ�ӣ�����Ҫ����ĵط���
������
1. Ŀǰǰ��Ҫʹ�õĻ���1.0�汾������1.0�汾�ĵ������⣬������ػ�����������ҵ�����ɽϴ��Ӱ�졣
2. ��ģ�ͼ��㣬�漰�������ݵ�Ƶ����д���㣬Ч����ʵ���ߡ����ԣ����ڴ���ҵ����������Ǩ�Ƶ�spark��
3. ���û�ͬʱʹ�ü�Ⱥ��ǧ��Ҫ����ҵ������ʹ�ò�ͬ�ĵ�������
4. ��Hadoop�����ĵ�����������ʱ����Щϸ��ǧ�����뵱Ȼ����Ҫ�����ԡ��������û���hostʱ��hostname���ܴ��»��ߡ�
5. ǧ��Ҫ�ü�Ⱥ�ڵ�Ĵ�����������̫�����ڴ�����д�벢�Ҽ�Ⱥʹ���ʽϴ�ʱ�����׳���дʧ�ܵ����⡣
CSDN���ں������ݴ洢�Ĺ����У��ڶ�д���Ƿ�������Щ���⣿��û�е���ϵͳĬ�ϵ�I/O���Ȳ��Ի������Լ���д��Ӧ���ļ�ϵͳ����˵���Ǻ�Ext3/Ext2һ��������ļ�ϵͳ��
������Ĭ�ϻ���һ���Ƕ�Ӳ����RAID5������RAID5�����RAID0��д����Ҳ�DZȽϲ���ұȽ��˷ѿռ䣨Hadoop�Լ������������֣�������ʹ�õĴ��̶���RAID0����ͬ�ĵ�����������Ӱ��ܴ�ͨ������ʹ�ñȽ��ʺ�ҵ��ĵ�������SSD�ͻ�еӲ�̵IJ��ͱȽϴֱ�ʹ�ò�ͬ�ĵ��Ȳ��ԡ�Ext3��ͬ����־���������Ӱ��ܴ���ؼ�ҵ��������ܲ��ԣ�ʹ���ʺ�ҵ��������־��������ֻ��ʹ�ñȽϳ���ĵ��Ȳ��ԣ��Լ�û�н�����д��
CSDN�����Ŷ������з������ݽ�������GAS���ɷ�Ϊ��ҽ���һ����Ҫ���ԣ���Ϥ������Դ��
������GAS��һ��ͨ�õġ�ʵʱ�ĸ��������ݽ�����ܣ�֧�ְѲ�ͬ��ʽ������Դ���Զ�ת����һ�ָ�ʽ��Ϊ��������ṩ������ʽ���ݷ���Ŀǰ��GAS֧�ֶ�����Э�顢ProtoBufЭ�顢JsonЭ��Ľ�����GAS����Ҫ�ص��У�
- ������������ֵ�ɵ�10w+/s,�ɳ�����û�����Դ
- �ṩͨ�õĽӿڣ�������չ������ͬ���͵�Э��
- �������ݸ�ʽ�ķ��㣬ʵʱ�ģ�ʵʱ��Ч
GASĿǰ�Ѿ��ڹ�˾�ڲ���Դ��Ŀǰ�����������Դ���й����
CSDN��˵����Դ���ɷ�¶һ����Ѷ����ʹ�õĿ�Դ����������ϵͳ�а�����ʲô���Ľ�ɫ��˳������̸̸ʹ�ÿ�Դ�����ľ���ɡ�
��������������������ǻ�ʹ�ÿ�Դ��������һ��������ڽϼǹؼ���Ӧ������ʹ�ÿ�Դ�ļ���������thrift�����������ݲ�ѯ��һЩСϵͳ����ʹ�ã���Դ�������ŵ��Զ��������Խ�Լ�����ɱ��������Ŀ���ʵ�ּ����ڶ��������һЩ�Ʋ���ȥ�ģ��Ƚϳ���ģ���ʹ�ÿ�Դϵͳ������Hadoop��Zookeeper������ϵͳ�У��ײ�ؼ�ģ�鶼���Լ�������������ȫ�ɿء�
��Դ������ݬ���룬һЩ���ŵĻ��߲��������ò�������ʹ�dz���Ŀ�Դ��������ʹ����Ҳ���и��ֿӡ�����������������ŵļ������ô����ڿ������ø���������Դ��Ҳ�г���������������������⣬�ֱ���Ҳ���������������
CSDN��������һֱ�Ƿ�������Ҫ��һ�������������м��ˣ���ʵ��ʹ����ӵ��һ�����õ�������Ŷ�������ЩŬ����
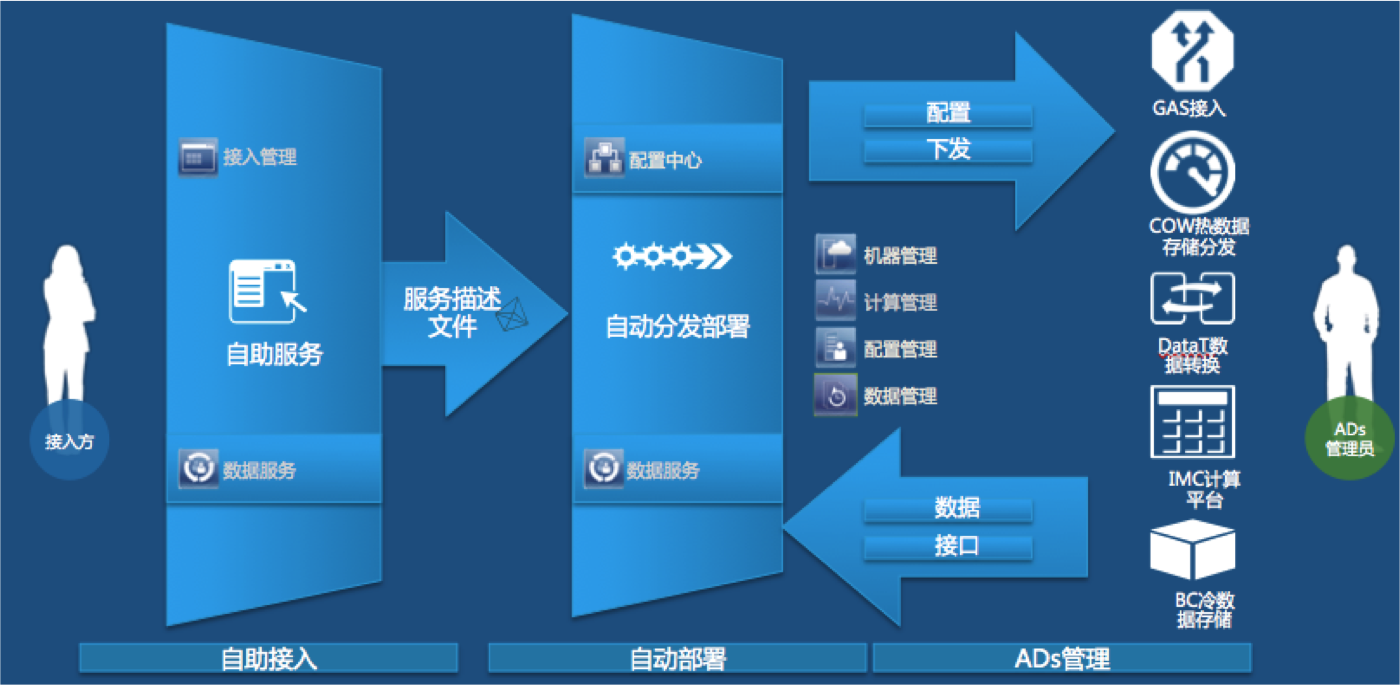
ͼ�� ���ݽ���ͼ
������ADs�����ó�˵˵��ԭ�����ǽ���һ��������Ҫ��Ʒ�����������ݹ���Ա��ι�ͨ����������Լ������������ȷ�ϣ��ſ������һ�����ݵĽ��룬Ч�ʼ��͡�ADs����֮���������ݹ���Ա���ڡ���Ʒͨ��ADsȥ�������������ݣ��������ݲ�Ʒ���ᵥ�������������ԣ�ȷ������������֪���Ʒ�������ݡ�
ADsϵ��֮ͨ�����ݽ�������GAS��������Դ��
��Գɰ���ǧ������ϵͳ�û��������ݽ�����أ����Ƿ������ÿ�λ�е��д���������룿��һ���Խ���������ʱ����Ҫ�Բ�ͬ����������ʱ���������Ƿ���æ���ң�æ�в��ϳ������Ƿ����ݳ������ˣ��õ�ʱ��ŷ��֣������Ѿ���ʧ��룬��Ʒ/�쵼ѹ����һ�쾢���ܶ�λ���⣬�ؼ����´λ��Dz���ʵʱ���֣����ٶ�λ��
��ô�죿GAS��ͨ�ý���������Ϊ�˽���������⣬��ϼ�ͨ�������ݷ���ʵ���������һ�����ݽ���������һ����裬�����꣬������Դ������ݽ������⡣
GAS��ADs�е�λ��
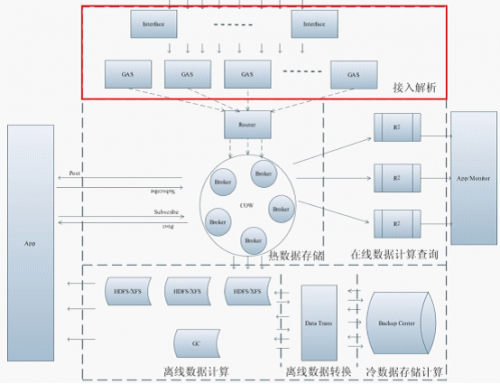
ͼ 1 ADs������
GAS��General Analyses Service��ͨ�����ݽ���������Э���������ԣ�Protocol Description Language �C PDL��ȥ�������ݣ���̬�������ݣ�ʵʱ������ȥ�������ݣ�ʵʱ�������ݣ�ʵʱ�澯����������ϵͳmonitorʹ�ã���������Ϊ�ֲ�ʽ��Ҳ����Ϊ������ʹ�á����������Dz��ʽ�ģ���Բ�ͬ��Э�飬ֻ��Ҫ������Ӧ������ɡ�
GASʵ��ԭ��
GAS��������
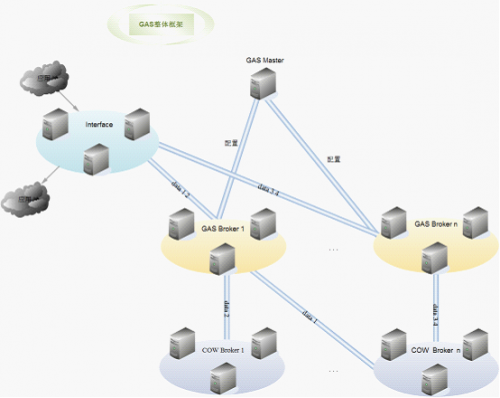
ͼ 2 GAS������
GAS master�������ݷ��������ļ��Ĺ������������ݷ��������ļ������ӡ��Ķ���GAS master������GAS��ܵ���Ҫ�ŵ㣺
- interface��Ҫ�ַ���ͬ���ݵ���ͬGAS broker���ַ���ͬ���ݵ���ͬGAS broker���ַ���ͬЭ������ݵ����в�ͬ���������broker���ַ����ݵ���ͬ�Ķ���Ӧ�ã�interfaceֻ��һ�����㡣
- GAS slaves�ֳɲ�ͬ��broker��ÿ��broker���ղ�ͬ�����ݣ�����һ�����ݿ����ڲ�ͬ��broker���ն�ݣ�broker֮����ȫ��������broker���Էֵȼ���Ӫ���ݣ�������Ӫ�����Ҳ�ͬbroker�������в�ͬ�Ľ�������������Լ���·�ɱ����·�����
- GAS slaves��ȥ���Ļ��ģ�GAS master����ֻ��Ӱ����������ļ��ĸ��£�����Ӱ���������ݵĽ��ա�
- ����֮����������ģ�һ������Э��Ĵ�����Ӱ�쵽�������ݡ�
GAS master
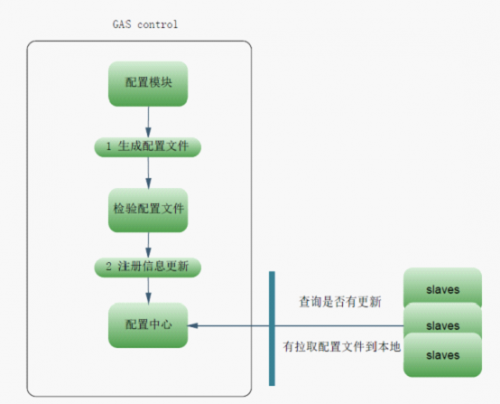
ͼ 3 GAS Master���
1. master�����ϵ�����ģ�飬�������������ݵ�ע����Ϣ�����Ե�¼ads.server.com����д���Э���������Ϳ����Զ�����Э���������Ե������ļ���
ͼ 4 ������������ҳ��
2. ��������ļ�ģ�飬�����µ����ö����ڴ棬�������ݽ���״̬�����Լ���Ƿ����������ɣ����Բ���Э���Ƿ���ȷ��
ͼ 5 Э��ץ��ʵʱ����ҳ��
3. ����ȷ������ע����Ϣ�����ڲ��Ի���������û�ȷ����ȷ����ô���ǿ���һ����������ʽ������
4. slavesÿ���ӷ���һ��master������Ƿ����µ�ע����Ϣ������и��£�����ȡ���������ļ������ء�
GAS Slave
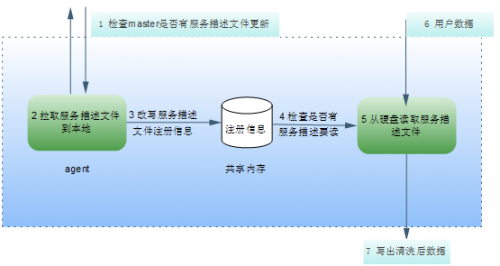
ͼ 6 GAS Slave���
slave��������Ҫ��Ϊ�����֣�agent���̺����ݴ������̣�����ģ����Ҫͨ�������ڴ�head_mem���н������������£�
- agent���̸���ÿ���Ӽ��һ�������ļ��Ƿ��и��£�����и��£�����ȡ�µķ��������ļ������ش��̣���������Ϣд�빲���ڴ�head_mem�У�Ȼ���Ĺ����ڴ���head_mem�İ汾�š�
- ��˵��һ�£�����ÿ�����ݶ���һ��Ψһ�ı�ʶ�����dz�Ϊtopic_id��ÿ�����ݵ������ʽ������Stx+topic_id+stBody+Etx��stBody���û���Ϣ�����������յ�һ�������Ϳ����ж���������Ǹ����ݡ�
���������ļ����¿ɷ�Ϊ3���֣�������Ϣ���ã������ֶ����ã�������Ϣ���á�������Ϣ�����а�����־��ء�����ip���˿ڡ���Ŀ�����˵�һЩȫ�ֵ�������Ϣ�������ֶ��������յ�һ������ʲô˳��������Լ���ʲô��ʽ�����ֶΡ���import_opt_name���������������Ϣ���á����ڽ��������У�����ij���ֶ���import_opt_name������ʱ���������������Ӧ��д�����ڴ������
���ݴ�����Ҫ����������������
- ÿ�ν������ݺ��head_mem�еİ汾���Ƿ�����֪�汾����ͬ������汾�Ų�ͬ��������ж����Ǹ�topic_id�ķ��������ļ������ˣ�������topic_id�ķ��������ļ�����������ô���ݸ�topic_id���������ļ����ɶ�Ӧ�����ݽ���״̬����������ģ�����ݸ�topic_id�����ļ����ɶ�Ӧ�����ݽ���״̬�������سɹ�����ô�ͷŸ�topic_id��Ӧ��ԭ�����ݽ���״̬����
- �յ�һ�����ݰ�������topic_id�жϵ����ĸ����ݽ���״̬�����������ɽṹ�����ݣ�Ȼ�����COW�Ľӿڽ��д洢��
״̬�����ɺ����ݽ���ʵ��
һ�����ݵ�Э��ΪStx+topic_id+dwIP+cFlag+wCount+stUin+Etx��stUin=ddwUin+dwID��wCount��stUin�Ĵ�С��stUinΪһ��UIN��ID�Ľṹ�壬����wCount=2����ôstUin����ddwUin1��dwID1��ddwUin2��dwID2�������ֶ��б�ΪdwIP��short����cFlag��char����stUin�����飩��stUin�����ǵ����ֶ��б�dwIP��cFlag��ddwUin��dwID��
Stx��Etx��Э��Ŀ�ʼ��������־��topic_id��Э���Ψһ��ʶ��
״̬�����ɹ���
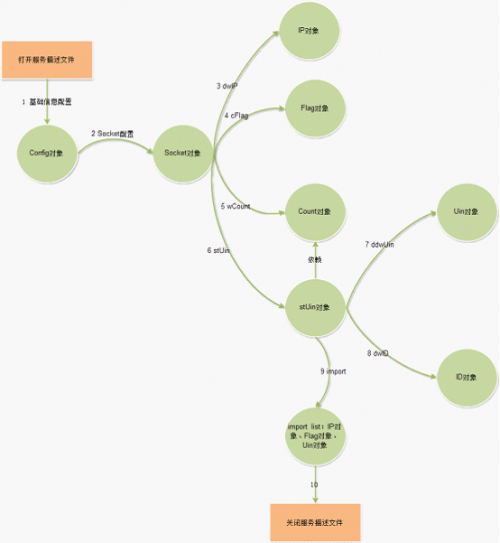
ͼ 7 ״̬�����ɹ���
״̬�����ɵĹ����ǣ���1����ȡ���������ļ�����̬����Config�����ݷ��������ļ��еĻ�����Ϣ���ã����Config�����ԣ�����Socket���ԡ���2�����ݷ��������ļ��еĽ����ֶ����ã���̬����Socket��Field�б�IP����Flag����Count����stUin����stUin��������Count������Uin����ID����3������stUin������import���ã�����stUin�����Import�б���Ϣ��
���ݽ�������
���ݽ���������״̬�����ɹ������ƣ�ͨ��topic_id�ҵ���Ӧ��Config����Ȼ�����IP���������IP��ֵ������Flag���������Flag��ֵ������Count���������Count��ֵΪ2������stUin����stUin�������Uin����ID������ô������Uin��ֵ��ID��ֵ��stUin������import�б����������IP��Flag��Uin��ID��ֵд������ΪCountΪ2���ٽ�����Uin��ID��ֵ���������IP��Flag��Uin��ID��ֵд�������ݽ���״̬����Ԥ�����ɵģ����Ƕ�̬���ɵģ���������������ݽ������ܡ�
���ܲ���
ʹ�ò���ƽ�������Ƚ��в��ԣ����Խ�����1��
�� 1 Э��������ܲ���
��������
cpu 70%�����
�������
B1�ϻ�����Intel(R) Xeon(R) CPU E5405 @ 2.00GHz cache size: 6144 KB 4�ˣ�
8w/s
14w/s
C1�»�����Cpu:Intel(R) Xeon(R) CPU X3440 @ 2.53GHz cache size : 8192 KB 8�ˣ�
18w/s
30w/s
չ��
��������ܣ����ǻ���һЩ������Ҫ����protobufЭ�������Ѿ��ڲ����У�txtЭ���������ڿ����У���ǿЭ����ǰ��ļ����ԡ�
|






