|
1,商城:是单商家,多买家的商城系统。数据库是mysql,语言java。
2,sqoop1.9.33:在mysql和hadoop中交换数据。
3,hadoop2.2.0:这里用于练习的是伪分布模式。
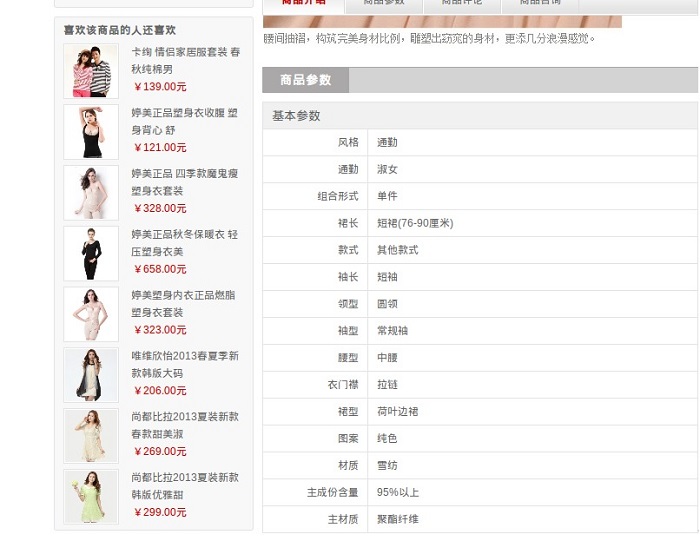
4,完成内容:喜欢该商品的人还喜欢,相同购物喜好的好友推荐。
步骤:
1,通过sqoop从mysql中将 “用户收藏商品” (这里用的是用户收藏商品信息表作为推荐系统业务上的依据,业务依据可以很复杂。这里主要介绍推荐系统的基本原理,所以推荐依据很简单)的表数据导入到hdfs中。
2,用MapReduce实现推荐算法。
3,通过sqoop将推荐系统的结果写回mysql。
4,java商城通过推荐系统的数据实现<喜欢该商品的人还喜欢,相同购物喜好的好友推荐。>两个功能。
实现:
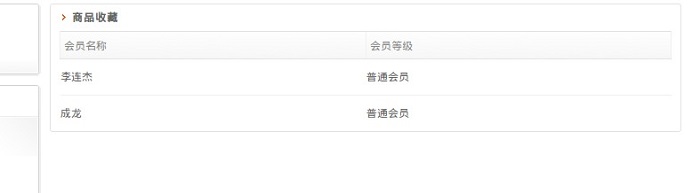
1,推荐系统的数据来源:
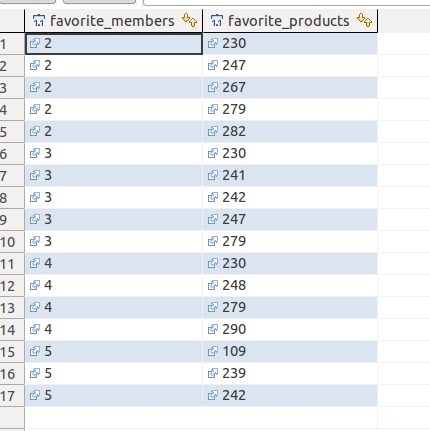
左边是用户,右边是商品。用户每收藏一个商品都会生成一条这样的信息,<喜欢该商品的人还喜欢,相同购物喜好的好友推荐。>的数据来源都是这张表。
sqoop导入数据,这里用的sqoop1.9.33。sqoop1.9.33的资料很少,会出现一些错误,搜索不到的可以发到我的邮箱keepmovingzx@163.com。
创建链接信息
这个比较简单
创建job
信息填对就可以了
导入数据执行 start job --jid 上面创建成功后返回的ID
导入成功后的数据
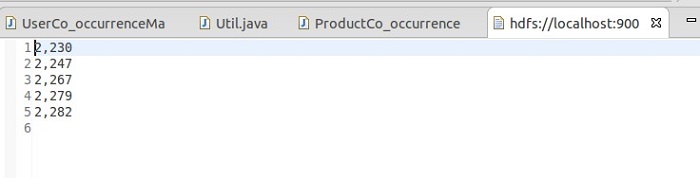
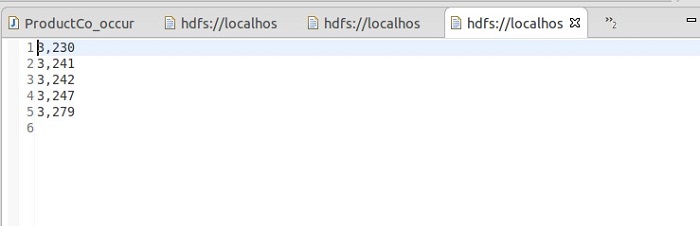
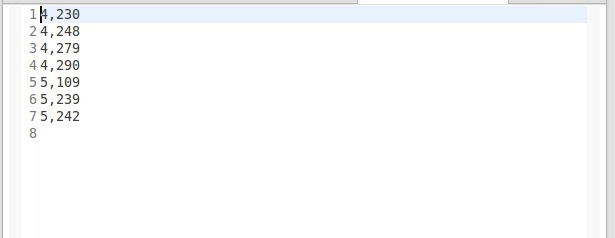
2,eclipse开发MapReduce程序
ShopxxProductRecommend<喜欢该商品的人还喜欢>
整个项目分两部,一,以用户对商品进行分组,二,求出商品的同现矩阵。
一,第1大步的数据为输入参数对商品进行分组
输出参数:
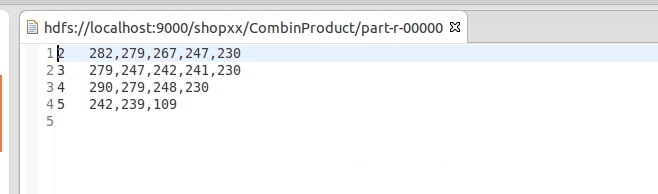
二,以第一步的输出数据为输入求商品的同现矩阵
输出数据

第一列数据为当前商品,第二列为与它相似的商品,第三列为相似率(越高越相似)。
整个过程就完了,下面
package xian.zhang.common;
import java.util.regex.Pattern;
public class Util {
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
}
|
package xian.zhang.core;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 将输入数据 userid1,product1 userid1,product2 userid1,product3
* 合并成 userid1 product1,product2,product3输出
* @author zx
*
*/
public class CombinProductInUser {
public static class CombinProductMapper extends Mapper<LongWritable, Text, IntWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] items = value.toString().split(",");
context.write(new IntWritable(Integer.parseInt(items[0])), new Text(items[1]));
}
}
public static class CombinProductReducer extends Reducer<IntWritable, Text, IntWritable, Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
Iterator<Text> it = values.iterator();
sb.append(it.next().toString());
while(it.hasNext()){
sb.append(",").append(it.next().toString());
}
context.write(key, new Text(sb.toString()));
}
}
@SuppressWarnings("deprecation")
public static boolean run(Path inPath,Path outPath) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf,"CombinProductInUser");
job.setJarByClass(CombinProductInUser.class);
job.setMapperClass(CombinProductMapper.class);
job.setReducerClass(CombinProductReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true);
}
} |
package xian.zhang.core;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 将输入数据 userid1,product1 userid1,product2 userid1,product3
* 合并成 userid1 product1,product2,product3输出
* @author zx
*
*/
public class CombinProductInUser {
public static class CombinProductMapper extends Mapper<LongWritable, Text, IntWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] items = value.toString().split(",");
context.write(new IntWritable(Integer.parseInt(items[0])), new Text(items[1]));
}
}
public static class CombinProductReducer extends Reducer<IntWritable, Text, IntWritable, Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
Iterator<Text> it = values.iterator();
sb.append(it.next().toString());
while(it.hasNext()){
sb.append(",").append(it.next().toString());
}
context.write(key, new Text(sb.toString()));
}
}
@SuppressWarnings("deprecation")
public static boolean run(Path inPath,Path outPath) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf,"CombinProductInUser");
job.setJarByClass(CombinProductInUser.class);
job.setMapperClass(CombinProductMapper.class);
job.setReducerClass(CombinProductReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true);
}
} |
package xian.zhang.core;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
public class Main {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
if(args.length < 2){
throw new IllegalArgumentException("要有两个参数,数据输入的路径和输出路径");
}
Path inPath1 = new Path(args[0]);
Path outPath1 = new Path(inPath1.getParent()+"/CombinProduct");
Path inPath2 = outPath1;
Path outPath2 = new Path(args[1]);
if(CombinProductInUser.run(inPath1, outPath1)){
System.exit(ProductCo_occurrenceMatrix.run(inPath2, outPath2)?0:1);
}
}
}
|
ShopxxUserRecommend<相同购物喜好的好友推荐>
整个项目分两部,一,以商品对用户进行分组,二,求出用户的同现矩阵。
原理和ShopxxProductRecommend一样
下面附上代码
package xian.zhang.common;
import java.util.regex.Pattern;
public class Util {
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
}
|
package xian.zhang.core;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 将输入数据 userid1,product1 userid1,product2 userid1,product3
* 合并成 productid1 user1,user2,user3输出
* @author zx
*
*/
public class CombinUserInProduct {
public static class CombinUserMapper extends Mapper<LongWritable, Text, IntWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] items = value.toString().split(",");
context.write(new IntWritable(Integer.parseInt(items[1])), new Text(items[0]));
}
}
public static class CombinUserReducer extends Reducer<IntWritable, Text, IntWritable, Text>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
Iterator<Text> it = values.iterator();
sb.append(it.next().toString());
while(it.hasNext()){
sb.append(",").append(it.next().toString());
}
context.write(key, new Text(sb.toString()));
}
}
@SuppressWarnings("deprecation")
public static boolean run(Path inPath,Path outPath) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf,"CombinUserInProduct");
job.setJarByClass(CombinUserInProduct.class);
job.setMapperClass(CombinUserMapper.class);
job.setReducerClass(CombinUserReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true);
}
} |
package xian.zhang.core;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import xian.zhang.common.Util;
/**
* 用户的同先矩阵
* @author zx
*
*/
public class UserCo_occurrenceMatrix {
public static class Co_occurrenceMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String[] products = Util.DELIMITER.split(value.toString());
for(int i=1;i<products.length;i++){
for(int j=1;j<products.length;j++){
if(i != j){
context.write(new Text(products[i] + ":" + products[j]), one);
}
}
}
}
}
public static class Co_occurrenceReducer extends Reducer<Text, IntWritable, NullWritable, Text>{
NullWritable nullKey =NullWritable.get();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> it = values.iterator();
while(it.hasNext()){
sum += it.next().get();
}
context.write(nullKey, new Text(key.toString().replace(":", ",") + "," + sum));
}
}
@SuppressWarnings("deprecation")
public static boolean run(Path inPath,Path outPath) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf,"UserCo_occurrenceMatrix");
job.setJarByClass(UserCo_occurrenceMatrix.class);
job.setMapperClass(Co_occurrenceMapper.class);
job.setReducerClass(Co_occurrenceReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true);
}
}
|
package xian.zhang.core;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
public class Main {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
if(args.length < 2){
throw new IllegalArgumentException("要有两个参数,数据输入的路径和输出路径");
}
Path inPath1 = new Path(args[0]);
Path outPath1 = new Path(inPath1.getParent()+"/CombinUser");
Path inPath2 = outPath1;
Path outPath2 = new Path(args[1]);
if(CombinUserInProduct.run(inPath1, outPath1)){
System.exit(UserCo_occurrenceMatrix.run(inPath2, outPath2)?0:1);
}
}
}
|
代码在github上有
git@github.com:chaoku/ShopxxProductRecommend.git
|






