| ACID
����������ʹ����㷺�ļ���֮һ�����ǹ�ϵ���ݿ�Ļ�ʯ������ҵ���м�����ɻ�ȱ�IJ��֣���ͨ��ͨ���ںеķ�ʽ�ṩ����������������£����ֹ��ϵ�����ʽ�Ѿ����ܹ���Ӧ�ִ����ģϵͳ��NoSQL���ݿ����Ҫ�ˣ��ִ�ϵͳҪ����ߵ�����Ҫ����������������ߵĿ����ԡ�����������£���ͳ������ģ�ͱ����Ƶ�������߰�����ģ����ȡ����������Щģ���������Բ������������������ء�
�ڱ��������ǻ�����һ��key-value���ݿ������������������ּ������Թ㷺Ӧ�����κ�һ�����ݿ�ϵͳ����GridDynamics�У����Ǿ������ּ�����Oracle
Coherence��ʵ����һ���������ķDZ���������ơ��ڵ�һ�������ǻ�ͨ��������Ҫ���������˽����ּķ������ڵڶ��������ǻ��о������ͨ�õķ���������˵PostgreSQL��MVCCʵ�֡�
ԭ���Ի����л������ύ����
�����Ǵ�һ��������ʵ�ֵķ�����ʼ��������������ڶ�Զ����д��ϵͳ������˵��������ϵͳ��ÿ��Ҫ���е����ݸ��£�һЩ�����Բ���������Ч��Ʒ�����Լ�������¡�
��������ǰ��������ݶ����ؽ������Ȼ��ͨ��һ�������ӿ���ִ������
get() �� put() �����IJ���������ӿڻ��������������A��B���������������У�ͼ 1����
1.�κ�ʱ��ֻ����һ�����洦�ڿ���״̬�������ӿڻ�����е�����·�ɸ�����ͼ1.1����
2.�������ݵ�ʱ��������ݼ��ص�Ŀǰ�����õĻ����У�ͼ1.2����
3.���½����л���־�ĸ�������õı�ǣ�ͼ1.3���������ӿڿ�ʼ���µĶ�����ַ����±��Ϊ���õĻ��档
4.�����л��ε�����������ݲ��õij־��Ժ�����Ҫ�����ֱ�������������������ظ�����
����ô�л��ܼ������ݻᱻ�������������������ӿڻ�ά��һ����δ�����������б���������������б��е�ÿһ������·�ɵ�ԭ���Ļ����С�ֻ�е��б��е��������ﶼ�ύ���߷���֮�������ݲŻᱻ��ա�
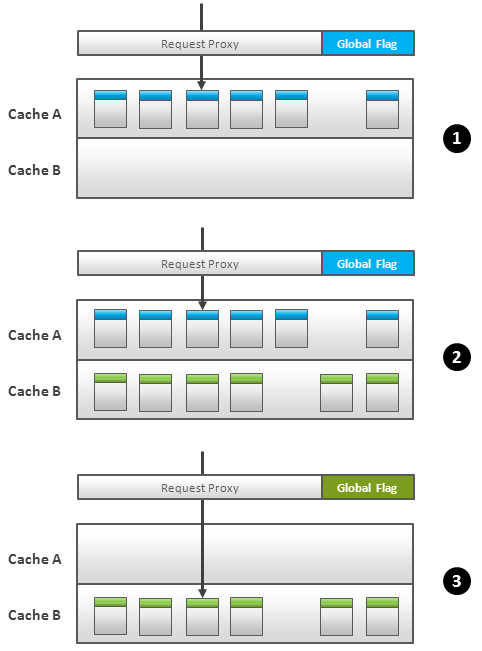
Fig.1 Cache Switch
��ͬ�ļ���Ҳ�����ڲ��ָ��¡����ݴ洢��ʽ�IJ�ͬҲ�ж���ʵ�ַ�������������һ����������������ӡ���������еĿ������һ�����ƣ����Ǵ����ӿڰ������������У�ͼ
2����
1.�û�����·�ɵ������棨��PRIMARY�����棩��ͼ 2.1��
2.�������ݺ������ݼ��ؽ�2�Ż��棨��NEW�����棩��ɾ�����key����3�Ż��棨��DELETE�����棩��ͼ2.2��
3.�ύ���̣���ָд�����л�ȫ�ֱ�ʾ�������ʾ����ߴ����ӿ���ȥ��NEW���͡�DELETE������ȥ��������������ݣ������������������û�з�����ȥ��PRIMARY��������ң�ͼ2.3�������仰˵������һ�����е��������ɵ��˸��¹��������в��ҡ�
4.�ύ���̽� NEW �� DELETE ����ı仯���ݸ�PRIMARY��Ҳ����PRIMARY�������Է�ԭ�ӵķ�ʽ���¡����ӡ�ɾ�������ͼ2.4����
5.������е��ύ���̰�ȫ�ֱ�ʶ�л����������е�������Ȼ·�ɵ� PRIMARY
��������ͼ2.5����
6.�ڵ�4�������������ݿ�������һ���������������Ϳ���֧�ֻع���������ʹ��ȫ������Ҳ���������ַ�����
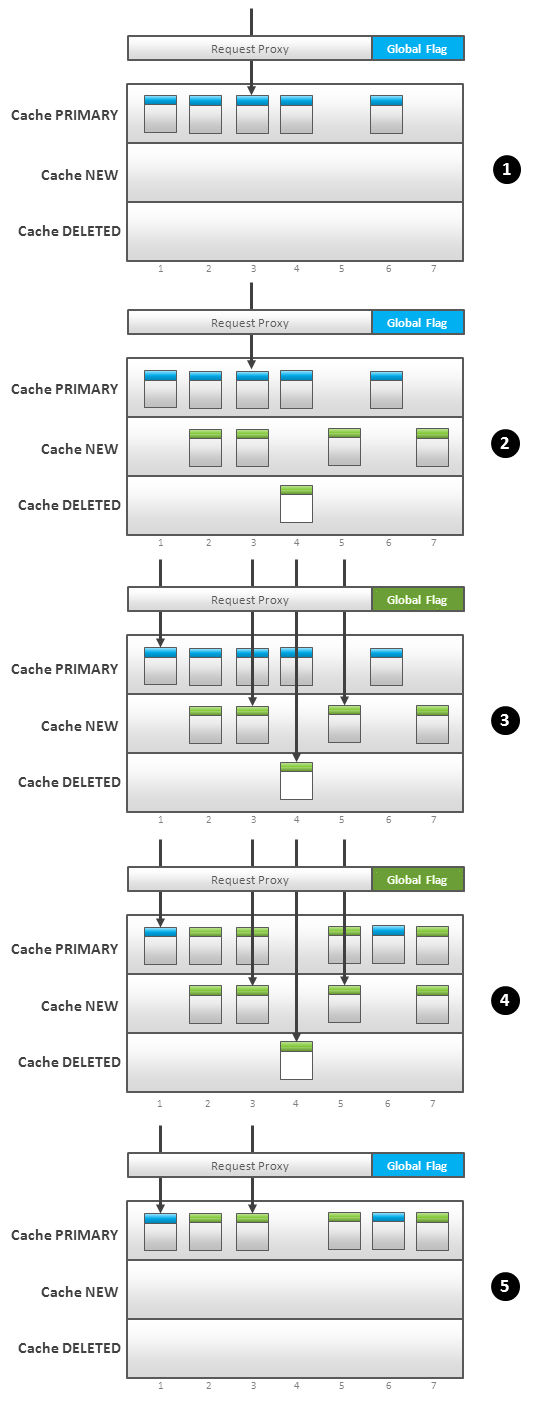
Fig.2 Partial Cache Switch
������������������ǿ��Կ�����ר���ڶ������ݿ��ձ��������ݸ��µĸ��ţ�����˸����ԡ���һ��д�ܼ��͵Ļ����оͲ�����������һ���ˡ�����һ�����ǻ�����һ�ַdz��õķ������������Ľ��������⡣
MVCC �����ظ�������
�����ĸ������ͨ������������ϰ汾����ʵ�֡����������������һ�㣬�������ǻ����һ����PostgreSQL
�������������dz����Ƶİ취��
����ǰ����˵��ÿ��������Զ�Ӧ��һ���������ݿ��ա���ͬһʱ�䣬ÿһ������������Լ����������� �C �Ӽ��뻺�浽�Ƴ�������߱����£����°汾��ȡ���������Կ���ͨ����ÿ�����ݴ�����ʱ�����ʵ�ָ��룬ÿ������ͨ����ʼʱ�䣨����ʱ���֮һ������ע�����ҳ�������ʼʱ���ڿɼ�״̬�����ݡ�����ʵ���г���һ�����������ļ���������ʱ�����
1����������ʼ��ʱ��
1��������һ��ȫ��Ψһ�ҵ�������������ID ��Ҳ�� XID��
2)�����ﱣ�������������XID.
2���������ÿ�������������������ǣ�xmin �� xmax���������¹���ֵ��
1)�������ij����������ʱ�� xmin ����Ϊ�������XID ��xmax
��ֵ��
2)�����ݱ�ij�������Ƴ���ʱ��xmin ���䣬xmax ����Ϊ�������XID�����ݲ�û����Ĵӻ����������ֻ�DZ����Ϊ��ɾ����
3)�����ݱ�ij��������µ�ʱ����������Ȼ�����ڻ����xmax ����ֵΪ�����XID��ͬʱ����һ���µ����ݣ������ݵ�
xmin Ҳ��ֵΪXID ����xmax Ϊ�ա����仰˵���²�������һ��ɾ����һ�����ӡ�
3�������������������������ô���ݶ���ij�������ǿɼ��ģ�
1)xmin ��ֵ����С�ڻ���ڵ�ǰ����ID��
2)xmax Ϊ�գ����ߵ���δ�ύ�������Ļ���δ��ɵģ���XID
�����ߴ��ڵ�ǰ����ID��
4��xmin �� xmax ���Դ洢����λ��ǣ����������Ƿ���������ύ���������ܽ�������ļ�飨xmax
�Ƿ����δ�ύ�����ID����
������ͼ��ʾ��
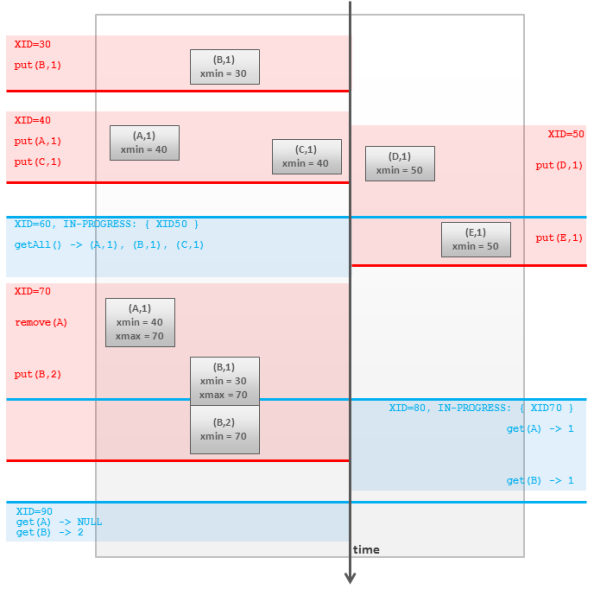
Fig.3 PostgeSQL-like MVCC
���ַ�����ȱ���Ƿ������ݵ��Ƴ���Щ��������Ϊ��ͬ���������ݰ汾��ͬ��������ʱ�����ݱ�Ϊ���ɼ������Ƴ��DZȽϸ��ӵġ�����Ҳ���������ϵķ����ܹ���������һ����PostgreSQL��ʹ�õģ��ڶ�����Oracleʹ�õģ�
���еİ汾���洢��ͬһ��key-value�ռ��У��汾����û�����ƣ�Ҳ�����Դ��������İ汾������ע������һ����̨�����������ϰ汾���ݣ�������տ����ƻ�����ִ��Ҳ�����ٶ�����д��ʱ����
��key-value �ռ�ֻ�������µİ汾��֮ǰ�İ汾����������ĵط����Ҵ����ϰ汾�Ŀռ��С�ǹ̶��ġ�
���µİ汾��ָ��֮ǰ�İ汾������ȴ���ܹ��ɴ����ݵ�֮ǰ������汾�� ��Ϊ�洢�ϰ汾���ݵ������С�ǹ̶��ģ�
̫��İ汾�ᱻ�Ƴ������ij�������ܹ��ҵ�ָ���汾�����ݾͻ�ʧ�ܡ� |






