| ��ν�������ݣ���ָ���ݵĹ�ģ���Ѿ�����ʹ�ô�ͳ�ķ�ʽ�������������������������������������棬�������ữ���磬�ƶ��绰�����ִ������Ϳ�ѧ����ÿ����������PB�Ƶ����ݡ�
Χ��Google�����ⷽ��Ĺ�����Yahoo��Haoop�ж�MapReduce��ʵ�֣�������һ���������ݴ������ߵ���̬ϵͳ��
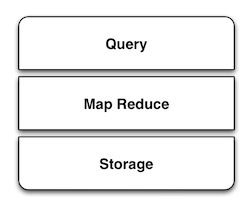
����MapReduceԽ��Խ��Ϊ��֪������ĺ�������ϵͳ��ʼӿ�֣������˴洢��MapReduce�Ͳ�ѯ�Ȳ�ͬ�������е�SMAQ���Կ�Դ���ֲ�ʽ�Լ���������ͨӲ����Ϊ������
����LAMP��webӦ�ÿ���������Ӱ�죬SMAQʹ�ú������ݴ���Խ��Խ���ס�LAMP�ƶ���Web2.0��SMAQ����ͬ���ķ�ʽ����һ�����������IJ�Ʒ�ͷ����µ���ʱ����
��SMAQ��ռ����������λ���ǻ���Hadoop�ļܹ�������֮���������Ҫ��NoSQL���ݿ⡣��ƪ����������SMAQ��ϵ���ҽ�����һЩ�������ݹ��߹�����SMAQ��ϵ�еĺ���λ�á�
MapReduce
��Google������Ϊ�˴��������������������⣬MapReduce ��������Ĵ�����������ݴ����а�������Ҫ���á�����ؼ��ķ����ǰ�һ�����ݲ�ѯ�ֽ��ڶ���ڵ��ϲ��н��С����ֲַ������������̫����̨�����ļ������������⡣
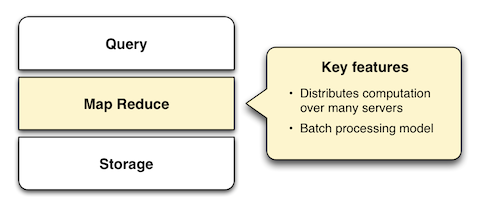
Ϊ������MapReduce����ι����ĵģ��������������������Ρ���map�Σ��������ݱ�����������Ȼ���γ�һ���м����ݡ���reduce�Σ��м����ݱ������γ�������Ҫ�Ľ����
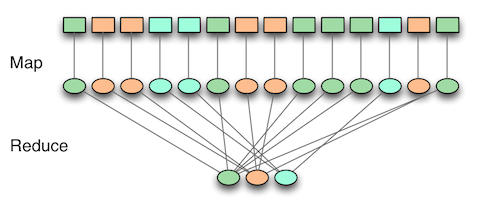
MapReduce��һ����������ͳ��һƪ�ĵ��еĵ���Ƶ�ʡ���map�Σ�ÿ���ʱ�����1����reduce�Σ�ͬһ���ʵļ������Ӻ�������
���������ӿ���ȥ�������⣬������Ϊ��ȷʵ��ˡ�Ϊ��ʹ��MapReduce���������ܣ�map��reduce�ζ����������ض���Լ��������������ܲ���ִ�С���һ����ѯת��Ϊһ������MapReduce������һ��ֱ�۵Ĺ��̣�Ӧ����һ���߲�εij���������һ���裬���Ѹ������ڸ��ڲ�ѯ֮�¡�
����MapReduce��ϵͳ��ͬ�ڴ�ͳ���ݿ��һ���Ƕ������ݵĴ��������������еģ������ڶ������Ŷ�ִ�У�ÿ���������Ҫ��ȥ������������Сʱ��
��MapReduce�������ݵ��������������
�������� �C������������ݲֿ�������ͨ����֮Ϊ��ȡ��ת���ͼ��أ�ETL�������ݱ���ԭʼԴ�г�ȡ�������ṹ���Ա�������Ȼ����ؽ���MapReduceʹ�õĴ洢��ʩ��
MapReduce �C ��һ�δӴ洢��ʩ�л�����ݣ�������Ȼ��ѽ����д��洢��ʩ��
��ȡ��� �C һ��������ɣ��Ϳ��ԴӴ洢�л�ý������Ϊ�����Ķ�����ʽ��
����SMAQϵͳ��Ϊ����Щ���̶�����ר����ơ�
Hadoop MapReduce
Yahoo֧�ֵ�Hadoop����֪���Ŀ�ԴMapReduceʵ�֡�����Doug
Cutting��2006�괴��������2008�����ʱ��߱������缶����������� Hadoop������Apache�йܣ�Ŀǰ�Ѿ���չΪһ�������ж������Ŀ��SMAQ������ϵ��
����MapReduce������Ҫд��������װMap��Reduce�Ρ��������ݱ����ȷ�����Hadoop�ļ�ϵͳ�С�
��Ȼ������ĵ���ͳ������Ϊ���ӣ�map����Ӧ����������ôд����ȡ��Hadoop MapReduce�ĵ����ؼ������Ժ����ǣ�
public static class Map extends Mapper (LongWritable, Text, Text, IntWritable) {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
} |
ͬ����Reduce�ж�ÿ�����ʵļ����Ӻ�.
public static class Reduce extends Reducer (Text, IntWritable, Text, IntWritable) {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) { sum += val.get(); }
context.write(key, new IntWritable(sum));
}
} |
����һ��Hadoop MapReduce����������¼���:
1.дJava����������map��reduce�θ���������
2.���ļ�ϵͳ�м�������
3.�ύ����ִ��
4.���ļ�ϵͳ�л�ȡ���
��ͨ��Java API��ʹ��Hadoop MapReduce�DZȽϸ��ӵģ�������ר�ŵij���Գ��д���롣����Χ����Hadoop�Ѿ�������һ�������̬ϵͳ��ʹ�����ݵļ��غʹ������Ӽ�
����ʵ�� MapReduceҲ��һЩ����������Ե�ʵ�֣���Wikipedia���ϵ�MapReduce������һ���б�������Ȥ��ͬѧ���Կ�һ�¡��ر�Ҫ�ἰ����һЩNoSQL���ݿ�ϵͳҲ������MapReduce��������ڱ��ĵĺ����ἰ��
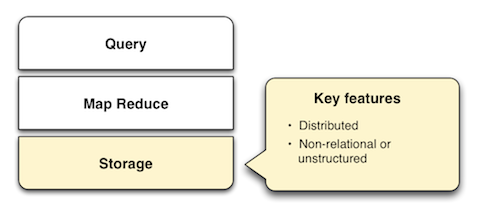
�洢
��Ҫ���ʵĴ洢����ȡ���ݺͷ��ü���������ͳ�Ĺ�ϵ���ݿⲻ�Ǹ������⡣���ݱ��ֿ�洢�ڶ���ڵ��ϲ��Լ�ֵ�Ե���ʽ�ṩ��Map����Щ�����Ƿǽṹ���ģ�����Ҫ��ѭ�̶������ݽṹ�淶�����Ƕ�ÿ��MapReduce�ڵ����ݶ������ǿ��õġ�
�洢�����ƺͽṹ�dz���Ҫ���������MapReduce�ӿڣ�����Ϊ��Ӱ�쵽���ݼ��غͼ�������ȡ�Ͳ��ҵ������ԡ�
Hadoop �ֲ�ʽ�ļ�ϵͳ
Hadoop ʹ��Hadoop �ֲ�ʽ�ļ�ϵͳ,��HDFS����Ϊ�����洢���ƣ�����Hadoop�ĺ��������
HDFS ��������һЩ�ص�, ���˽����ϸ�Ŀ���ȥ�� HDFS ����ĵ�.
�����ݴ� �C HDFS����������Ӳ���ϲ�����Ӳ�����Ͼ�������.
��ʽ���ݷ��� �C HDFS ��������������˼�������, ǿ�����ݵĸ����¶���������ʡ�
���˿����� �C HDFS ���ԴﵽPB��ģ�����ݵĴ�������; ������Ӧ�ó�������FaceBook��Ϊ��ʵ.
����ֲ�� �C HDFS ����װ�ڲ�ͬ����ϵͳ��.
һ��д �C HDFS ����һ���ļ�һ��д��֮��Ͳ��ٸı䣬�Ӷ��������ݸ��Ʋ��Ҽ�������������.
�ڲ�ͬλ�ü��� �C �ƶ������������ڵĵط�ͨ��Ҫ���ƶ����ݸ��죬HDFS��������һ�ص㡣
DFS�ṩ��һ����ͨ���ļ�ϵͳ�����ƵĽӿڡ��������ݿ⣬HDFSֻ�ܴ�ȡ���ݣ������ܶ�������������
�����ݵ���������Dz�֧�ֵġ� ��������HBase�����Ĺ����ڸ��߲���ṩ�˸��ӷḻ�Ĺ��ܡ�
HBase, the Hadoop Database
HBaseʹ��Hadoop�������á� HBase ģ�� Google ��
BigTable ��ƣ���һ�������е��ʺϴ洢�������ݵ����ݿ⡣ ������NoSQL���ݿ�����Cassandra
�� Hypertable ������ͬ��.
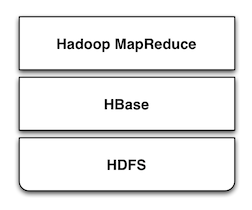
HBase ʹ�� HDFS ��Ϊ�洢, �ܹ��ڿ��ݴ��Ķ���ڵ��ϴ洢�������ݡ����������Ƶ��д洢���ݿ�һ����
HBase �ṩ�� REST �� Thrift ���ʽӿ�. ��Ϊ��������HBase������һЩ�IJ�ѯ�����п��ٵ�������ʡ����ڸ����ӵIJ�����HBase�ȿ�����Ϊ
Hadoop MapReduce ������ԴҲ������Ϊ���������ݵ�Ŀ�ĵء�HBase�ṩ�˽ӿ�ʹ��Hadoop���Խ�����Ϊ���ݴ洢װ�ã�������ʹ�ø��ײ��HDFS��
Hive
���ݲֿ���SMAQϵͳ��һ����ҪӦ�����������ݴ洢��ʽʹ�ñ������ɺͷ����������ס�Facebook
������ Hive �ǹ�����Hadoop֮�ϵ�һ�����ݲֿ��ܡ��� HBase ��ͬ, Hive Ҳ��Hadoop
֮���ṩ��һ�����ڱ��ij��� ������˽ṹ�����ݵļ��ء� �� HBase ���, Hive ֻ������ MapReduce
jobs����ֻ�ʺ�������������Hive �ṩ����SQL��ѯ������ִ�� MapReduce ��������������Queryһ��������
Cassandra and Hypertable
Cassandra �� Hypertable Ҳ���� HBase ���Ƶ�
BigTable ģʽ�Ŀ���չ���д洢���ݿ⡣ Cassandra ��Ϊһ��Apache ��Ŀ�����Facebook
�����������Ѿ���������վ�õ���Ӧ��, ���� Twitter, Facebook, Reddit �� Digg.
Hypertable �� Zvents �������ոտ�Դ���á�
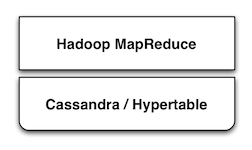
���������ݿⶼ�ṩ����� Hadoop �Ľӿڣ�Hadoop����ʹ��������Ϊ����Դ���ߴ�����������ݡ�
�ڸ��ߵIJ��, Cassandra �ṩ�� �� Pig ��ѯ���Ե����� (�������� Query �½�),
Hypertable �Ѿ� ��Hive���ϡ�
NoSQL ���ݿ�ʵ�ֵ� MapReduce
�����ᵽ�ļ����洢ȫ��������Hadoop �� MapReduce������һЩ NoSQL ���ݿ��ڽ���
MapReduce ���ܣ� �����Ϳ��ԶԴ洢�����ݽ��в��м��㡣�����Hadoop �Ļ�� SMAQ �ܹ���ȣ������ṩ��һ�廯�Ĵ洢��MapReduce
�Ͳ�ѯ���ܡ� ����Hadoop ��ϵͳͨ������������������NoSQLͨ������֧��ʵʱӦ�ã���Щ NoSQL
���ݿ��ṩ�� MapReduce ������һ��Ϊ�˼�ǿ��ѯ�Ĵ�Ҫ���ܡ����� Riak���� MapReduce
�����Ĭ���ӳ�ʱ����60��, �� Hadoop �Ĵ�������ͨ����Ҫ��ʱ������������Сʱ�� ��Щ NoSQL
databases �ṩ�� MapReduce ����:
CouchDB ��һ���ֲ�ʽ���ݿ�, �ṩ��ṹ���Ļ����ĵ��Ĵ洢��������Ҫ���ܰ���ǿ��ĸ���֧�ֺͷֲ�ʽ���¡�
CouchDB �IJ�ѯʹ�� JavaScript ����� map�� reduce ��ʵ�֡�
MongoDB �������� CouchDB �dz����ƣ� ������ǿ������,
�����˷ֲ�ʽ���� , ���ݸ����Ͱ汾���ظ��� MongoDB MapReduce operations
Ҳʹ�� JavaScript ����.
Riak ��һ�������� CouchDB�� MongoDB �����ݿ⣬ �����������ظ߿����ԡ�
MapReduce operations in Riak ����ʹ�� JavaScript ���� Erlang
����.
�� SQL ���ݿ������
������Ӧ�ó����£����ݵ���Ҫ��Դ���� MySQL ���� Oracle �����Ĵ�ͳ��ϵ���ݿ⣬MapReduce
�����ֵ��͵ķ�ʽ��ʹ���������ݣ�
�ù�ϵ���ݿ���Ϊ������Դ��������������е������б�����
�� MapReduce ��������д���ϵ���ݿ� (�������������Ȥ�IJ�Ʒ�Ƽ�).
��ˣ����� MapReduce �� ��ϵ���ݿ�֮������ô�����ľͺ���Ҫ�����������ʹ�ù̶��ָ����ı��ļ���ʹ��
SQL ������ Hadoop ��������ɵ��뵼��������������һЩ���Ӹ��ӵĹ�����ʵ�����Ŀ�ġ� Sqoop
����һ���ɹ�ϵ���ݿ��еĹ��ߵ��뵽 Hadoop �Ĺ��ߡ� �� Cloudera ����,����ά����һ����ҵ��Hadoop
ƽ̨�� Sqoop ʹ����JDBC API �������������ݿ��ء�����ȫ���������ű������ݣ�Ҳ����ʹ����������ѡ��ļ�����Ҫ������
Sqoop Ҳ���� MapReduce �Ľ���� HDFS ���ص����ݿ⡣ ��Ϊ HDFS��һ���ļ�ϵͳ,
Sqoop ��Ҫ�����Ա�ʶ�ָ����ı��ļ�������Ҫ������ת���� SQL �����뵽 ���ݿ⡣ �� Hadoop
��ϵ���� Cascading API �� (�������� Query �½�) cascading.jdbc
�� cascading-dbmigrate ���߿������� Sqoop ���Ƶ����顣
����ʽ����Դ������
�������Թ�ϵ���ݿ�����ݣ�����վ��������־�Լ������������������ʽ����, �����˺ܶຣ������ϵͳ��������Դ��Cloudera
�� Flume ��ĿΪ Hadoop �� ��ʽ����Դ֮��������ṩ��һ��������Flume ͨ������ӱ鲼��Ⱥ�Ļ������ļ���
�ռ����� ��Ȼ��������ϵ�д�뵽 HDFS�� FaceBook ������ Scribe Ҳ�ṩ��ͬ���Ĺ��ܡ�
���� SMAQ �������
һЩ���ģ���д��� (MPP) ���ݿ��Ʒ�Ѿ��ڽ��� MapReduce ���ܡ� MPP ���ݿ�ͨ����һ�����ڵ㲢�����еķֲ�ʽ�ܹ���������ҪӦ�������ݲֿ�ͷ�����ͨ��ͨ��
SQL ��ʹ�á�
Greenplum ���ݿ���ڿ�Դ�� PostreSQL ���ݿ�, ������һ���ֲ�ʽ��Ⱥ�ϡ�Greenplum�������
SQL �ӿ����Ӽ���MapReduce ���ܣ������Ϳ��Ը���ķ��������ģ�����ݣ����ĵ�ʱ����Խ��ͺü�����������Greenplum
MapReduce ���Խ��ⲿ���������ݿ��ڲ����ݻ�ϴ�����������Python ���� Perl ��ִ��
MapReduce ������
Aster Data��s nCluster ���ݲֿ�ϵͳҲ�ṩ�� MapReduce
���ܡ��� Aster Data��s SQL-MapReduce ���������á�
SQL-MapReduce ���Ի�� SQL ����� ������Զ���� MapReduce
����֧�� C#, C++, Java, R �� Python ���ԡ�
����һЩ���ݲֿ��Ʒѡ������ Hadoop �� MapReduce �������Լ�ʵ�֡�
Vertica, Farmville ����Ӫ��˾ Zynga ��ʹ�õģ�һ��
���ģ���д�����MPP�� �����е����ݿ⣬ �ṩ�� Hadoop �ӿڡ�
Netezza ��һ���İ���Ӳ�������ݲֿ�ͷ����豸�� ����ոձ� IBM
�չ��� Netezza �� Cloudera ���� ��ǿ�����Ʒ�� Hadoop ֮��Ļ������ԡ� ��Ȼ�������һ�������⣬
����Netezza ����̫�������ǵ� SMAQ ���塣 ���Ȳ��ǿ�Դ��Ҳ�������������۵�ͨ��Ӳ���ϡ�
���ܿ���ʹ�ÿ�Դ�����齨һ������Hadoop��ϵͳ��������Ȼ��Ҫ������������ϸ��������Cloudera
������ʹ Hadoop ��Ϊ��ҵ��Ӧ�ã����� Cloudera Distribution for Hadoop
(CDH) ���ṩ��һ��ͳһ�� Hadoop ��ϵ������Ubuntu �� Red Hat �ṩ�� ���ϰ汾
Linux �����塣CDH �ṩһ����Ѱ���ܸ���� ��ҵ�汾��CDH ��һ�������������û���ѯ�Ͳ����ӿڵ�������
SMAQ ������ ��Щ�����ش�Ĺ����� Hadoop ��̬Ȧ�����Ĵ�
Query
ʹ���������Java ���� �����ı�����Զ��� map �� reduce
��������װ MapReducre ������ֱ�۵��Dz���ġ�Ϊ�˽��������⣬SMAQ ������һ�����߲����ϵIJ�ѯ������
MapReduce ����ͻ�ȡ������ݡ�
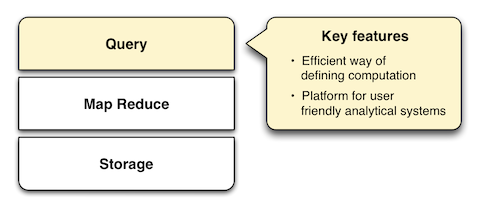
����ʹ�� Hadoop �Ļ����Ѿ����� MapReduce API ֮�Ͽ������Լ��IJ�ѯ����������������һЩ�Ѿ���Դ��������ҵ����
��ѯ��һ�㲻ֻ�ṩ������̵��ƶ�����Ҫ����������ݡ��������Լ��ڼ�Ⱥ�з��� MapReduce �����͵���������ͨ��������ʵ�ּ�������һ��Ҳ�����ؽ�����û���
Pig
�� Yahoo �����������Ѿ���Ϊ Hadoop ��Ŀ��һ���֡� Pig
�����һ�����ڶ�������� Hadoop MapReduce ����ĸ߲������, Pig Latin�� ��ʵ�����ṩ��һ��Java
API֮��Ľӿڣ�ʹ��Щ��Ϥ SQL �Ŀ�����Ա�����������ó��ķ�ʽ��ʹ�� Hadoop��Pig Ҳ��������
Cassandra �� HBase �� ������ʾ��ʹ�� Pig ����Ƶͳ�Ƶ����ӡ����������ݵļ��غͽ���洢��
(���� $0 ��ʾÿ����¼�ĵ�һ���ֶ� )��
input = LOAD 'input/sentences.txt' USING TextLoader();
<strong>words = FOREACH input GENERATE FLATTEN(TOKENIZE($0)); </strong>
<strong>grouped = GROUP words BY $0; counts = FOREACH grouped GENERATE group, COUNT(words);</strong>
ordered = ORDER counts BY $0;
STORE ordered INTO 'output/wordCount' USING PigStorage(); |
Pig �Ĺ��ܺ�ǿ�����߿���ʹ�� User Defined Functions
(UDFs) �������Լ��IJ�������������SQL ���ݿ�Ҳ֧���Զ��庯�� ���� Pig �������Java
���������� UDF�� ��ȻҪ�� MapReduce API ���������������ʹ�ã��� ʹ�� Pig ��ȻҪȥѧϰһ���µ����ԡ���ν��SQL���ԱϾ���
SQL ����������ͬ����ʹ����Щ��Ϥ SQL �Ŀ�����Ա�����ܹ���ȫ�������ǵļ��ܡ�
Hive
��������ܹ��ģ�Hive ��һ�� Facebook �����ģ������� Hadoop ֮�ϵĿ�Դ���ݲֿⷽ�������ṩ��һ�ָ�
SQL ������IJ�ѯ���Ժ�һ��������棬��������������������������ѯ����ˣ���Щ�� SQL�˽ⲻ�Ǻ������Ҳ����ʹ������
��Pig �� Cascading ������Ҫ����Ĺ�����ȣ�Hive ��ǿ�ĵط����ṩ�����ݵļ�ʱ��ѯ������ѳ�Ϊһ�����ܸ�ȫ�����ҵ����ϵͳ��ΪĿ�ģ�
�ԷǼ�����Ա�Ѻõ� Hive ��һ���dz��õ���㡣 CDH ������ Hive,������ͨ�� HUE �ṩ��һ�����߲�εĽӿڣ�ͨ������ӿ��û������ύ��ѯ���Ҽ��Hadoop
�����ִ�С�
Cascading, the API Approach
Cascading ��Ŀ�� Hadoop MapReduce API ���˰�װ��ʹ���� Java Ӧ����ʹ�ø����㡣���Ǻܱ���һ�㣬����Ŀ��ֻ��Ϊ�˽�����һ���Ƚϴ��ϵͳ������
MapReduce �ĸ����ԡ�Cascading �������¹��ܣ�
һ���� MapReduce ��������ݴ��� API��
һ������ Hadoop ��Ⱥ�� MapReduce ����ִ�е� API��
֧�ֻ��� JVM �Ľű����Է��ʣ��� Jython, Groovy, or
JRuby��
������ HDFS ֮�������Դ�� ���� Amazon S3 �� web
servers��
���� MapReduce ���̵���֤���ơ�
Cascading��s key feature is that it lets
developers assemble MapReduce operations as a flow,joining
together a selection of ��pipes��. Cascading �ĺ��Ĺ��������������߽�MapReduce
������ϳ�һ������һ�����һ���ܵ���ѡ����dz��ʺ�����Ҫ�� Hadoop ���Ͻ�һ����ϵͳ�ij����� Cascading
����û���ṩ����ѯ���ԣ���һ������ Cascalog ����Ŀ���ṩ������ܡ� Cascalogʹ�� ����JVM��
Clojure ����ʵ����һ���� Datalog ���ƵIJ�ѯ���ԡ������������Ա���ǿ������ʵ�ʵ�λ�����Σ�
��Ϊ���Ȳ���Hive ���� SQL �������������������е�֪ʶ���ֲ���Pig �����ṩһ�����̻��ı������Ĵ�������
Cascalog д�Ĵ�Ƶͳ�Ƶ����� : ����ȥ�ܼ�࣬���Dz�̫������
(defmapcatop split [sentence]
(seq (.split sentence "\\s+")))
(?<- (stdout) [?word ?count]
(sentence ?s) (split ?s :> ?word)
<strong>(c/count ?count)</strong>) |
�������ݿ����е�һ����Ҫ��ɲ��������ݼ����ͻ��ܡ��� HBase ���������ݿ⸽�Ӳ�������ݷ��ʣ����Dz����ܹ��ṩ���ӵ�������
Ϊ���������⣬ͨ��ʹ�ÿ�Դ����������ƽ̨ Solr ����Ϊ NoSQL ���ݿ�ĸ�����Solr ʹ��
��Դ�������� Lucene �ṩ�������ܡ� ���磬������һ������������ݿ⣬MapReduce ����ij���㷨����ÿ���˵�Ӱ��������������õ����ֽ���������ݿ⡣��
Solr ��������������Ȼ��Ϳ����ҵ�Ӱ���������ڸ�����Ϣ���������ֻ��� ��Щ�ˡ� Solr ������
CNET �����������Ѿ���Ϊ��һ�� Apache ��Ŀ�����Ѿ���һ���ı����������������֧�ֶ��浼���ͽ������Ĺ��ߡ�
���⣬ Solr ���Թ����ֲ��ڶ���������ϵĴ����ݡ���ʹ���dz��ʺ��ڴ������ݼ��ϵĽ���������Ӷ���Ϊ������ҵ����ϵͳ����Ҫ�����
�ܽ�
MapReduce, �ر��� Hadoop �ṩ��һ���ڶ�̨��ͨ�������Ͻ��зֲ�ʽ�������Ч������ �ٽ�Ϸֲ�ʽ�洢�Ͷ��û��ѺõIJ�ѯ���ƣ����γ�����ν
SMAQ �ܹ������ּܹ�ʹС�����Ŷ�Ҳ���Խ��к������ݴ����� ��Щ���������˴�Χ�ڵ����ݵ���ͽ����ڸ����㷨�ϵ����ݲ�Ʒ�ijɱ���
���DZ�ը�ԵĽ�������Զ�ı��˶�ά���������ݲֿ⣬�������²�Ʒ�������ż���Mike Loukides�� ��What
is Data Science?���ἰ�����ƻ��������ҡ�
Linux �ij��ָ�����Щ�д����뷨�Ŀ������Ǿ��֧�֣����ǿ��Խ��Լ��Ĺ����������ó�Linux��������SMAQ
���ڴ����������ľ�����ͬ�����壬�������˴�������������ҵ��ijɱ��� |


