| 为了保证高效的数据移动,locality是大数据栈以及分布式应用程序所必须保证的性质,这一点在Spark中尤为明显。如果数据集大到不能保证完全放入内存,那就不能贸然使用cache()将数据固化到内存中。如果读取数据不能保证较好的locality性质的话,不论是对即席查询还是迭代计算都将面临输入瓶颈。而作为常用的分布式文件系统,HDFS承担着数据存储、一致性保证等关键问题。HDFS自开发之初就与Google
GFS一脉相承,因此也继承了其无法较好的处理小文件的问题,但大量小文件输入又是分布式计算中常见场景。本文以小文件输入为案例,看看从HDFS到Spark的数据通道中到底发生了什么,并讨论如何设计有效的小文件输入。了解了这些话题,可以更高效的使用Spark。
背景
MLlib进展如火如荼,近期最令人振奋的消息莫过于MLlib对sparse vector的支持,以及随之而来的一系列重构和改进工作。机器学习一般算法的输入是训练集和测试集,通常来说是(label,
key : value)这样的序对。对于这种输入,直接使用SparkContext提供的textFile()接口就好了,MLlib内部会转换成LabeledPoint类。但MLlib还缺少图模型算法,如LDA。LDA
(Latent Allocation Dirichlet)算法常用来获取文档集合的主题,是机器学习中广泛应用的算法,其输入格式和核心组件与常见的机器学习分类、聚类算法不同。
两个月之前,笔者有一份差不多要完成的基于Spark的并行LDA算法准备提交给Spark社区,同时也在准备酝酿已久的学术论文。当笔者完成了LDA算法的核心模块Gibbs
sampling之后,突然发觉要想实现一个“可用的“LDA算法,不仅仅是一个核心功能这么简单,还牵扯到许多零碎的事情。所谓零碎的事情,其实并不简单。机器学习算法就是这样,学起来难,但是真正懂了之后发现核心算法特别简单,预处理又非常难。总之,机器学习算法学起来难的地方做起来简单,但是学起来简单的地方,
并不见得很快就能做好。
大部分的零碎工作在语料库的预处理和后续输出的模型的使用上,这些零碎的工作机器学习者们都不怎么注重,因为书本上很少会讲到这些知识。就拿后者来说,模型后续使用这件事儿看起来小,其实不然,这关系到机器学习算法的实际运用能力。我们做模型的最终目的除了发论文之外还是想让它对现实生活产生影响。学术派关注模型多,但对学术和工业的结合看的相对少一点,线下模型如何轻松部署?模型可否增量训练?模型的训练和使用是否可以同步进行?是否可以做到对模型的在线查询?这都是将机器学习“搬出实验室”的关键问题。这类问题在Strata大会上有很多工业界人士做了很好的讲解,比如这里。
闲言莫谈,回到语料库的预处理工作。关于分词的问题不多谈,笔者学习ScalaNLP的做法,直接在Lucene的分词实现上裹了一层Scala的接口。但是在语料集的输入上花了很多时间。Spark目前所有的标准输入接口是SparkContext类中提供的textFile(path,
miniSplits)接口,但该接口不适合语料库的直接输入,因为这是一个文本行处理函数,每次只能操作其中的一行文本。而LDA更期待的输入格式是Key-Value对,其中key是文件的绝对路径(便于分辨和去重),value是文件的全部内容。由于Spark下层多使用HDFS作为输入,因此笔者打算自己定制InputFormat。
LDA应用场景
首先得说明一些问题。LDA的实际使用场景有二:
第一种是在实验室环境下使用,这是最直观的情况。例如你有一堆小文件存在本地磁盘上,即你的语料库。可能你想直接把它们上传到HDFS,或者在每台机器的磁盘上仍一份,甚至直接放在当前机器的本地磁盘好了(这种情况下不是真正的分布式,所有的Spark
executor只会在你当前机器上启动),之后打开Spark调用其中的LDA算法。如果你只是打算做个实验,这样就足够了。换言之,这是一种offline的训练方式。
第二种情况是工业应用,你可能不会有一堆离线的语料库,而是有一个流式管道,语料文本源源不断地传递过来,如twitter/weibo
feed等。或许你可以把这些数据放到HDFS或HBase上,也有可能直接处理流数据,而不管最终存储。
这是完全不同的应用场景,针对不同的场景要有不同的处理方式。不论是实验室环境下的尝试,还是工业应用,两者都很重要。本文只涉及offline的数据处理方法,因为offline的数据处理才更加需求让数据经过HDFS。
离线LDA训练
离线场景下或许我们不必理会语料集预处理的过程,直接交给最终用户好了。用户将语料集转换成你指定的样式,之后将预处理结果上载到HDFS,这样你的LDA程序可以直接访问这部分数据,而我们要做的只是规定好输入的样式,妙不可言。我们舒服了,用户吃些苦头。例如我们指定用户输入文件的每一行是一个完整的文件内容,开头处以Tab分割作为文件名。这样我们可以直接调用textFile()接口,自己切分一下就可以得到”文件名--文件内容”这个KV对。值得一提的是,这种离线场景下看似不好用的方法,在工业界线上训练过程中反倒可能有好的效果。比如一次记录过来就是一个KV对,这样就省去了这一步输入的处理。
或许我们可以进一步帮帮用户。咱们写一个预处理程序,不论是串行的还是并行的,帮助用户进行预处理,Mahout就是这么做的。这种情况下,可能需要最终用户写一个ad-hoc的shell脚本组织所有的工作流和数据流。Mahout中的dirTosequentialFile就是把本地磁盘或者HDFS上的目录读入,将其中的小文件合并在一起转换成一个sequential
file。
但是,笔者觉得最好的方法还是将预处理过程与LDA训练过程融合起来,不要让用户做这么多工作就能调用Spark上的LDA,用户只需要指定文件路径即可。这时我们必须提供函数将语料库所有的文本和文件名读入。CombineFileInputFormat比较适合处理小文件,因此最初笔者实现了一个CombineFileInputFormat,一个CombineFileRecordReader,一个FileLineWritable以及一个类似于textFile()的接口。
Interface exposed to end-user - SparkContext.scala
def wholeTextFiles(path: String): RDD[(String, String)] = {
newAPIHadoopFile(
path,
classOf[WholeTextFileInputFormat],
classOf[String],
classOf[String])
} |
要注意的是,虽然笔者这么做了,但这并不代表小文件输入的最佳实践。实际上,最佳实践是不要使用小文件。因为将大量的小文件放到HDFS上是比较糟糕的,不仅将block用满率降低,还会占满NameNode上面的索引。这里只是讨论一种可行的方案。
分析几个问题。首先是HDFS中block的大小。我们在这里称之“小文件”的文件究竟有多“小”?是否会超过HDFS的block大小?答案是肯定的。在这种情况下,如果我们按照block位单位读取数据,那么我们就要自己处理同一个文件的block拼接的问题,尤其是文件由多字节字符组成的时候,如UTF编码的字符,很可能在一个字符中间被切断。如果不能正确的拼接各个block,会出现乱码的情况。
重点是,考虑到性能问题,我们不希望有额外的网络传输开销存在,尤其是不必要的网络传输。我们希望同一个文件的block都在同一个节点上,这样在合并这些block的时候就完全不会出现机器之间数据的网络传输。HDFS里面很讨厌的一点是,这里有两套极为相同的API,分别在mapred和mapreduce两个包下,稍不注意用错了API就会有一种很抓狂的感觉。笔者最初为了兼容Spark中HadoopRDD的接口,用了mapred的这套API,其中的CombineFileRecordReader中的isSplitable()函数是不起作用的,因为如果不修改CombineFileRecordReader本身的代码就无法阻止一个文件的多个block分配到不同的split中的情况。一旦这件事情发生,那拼接一个文件的时候就无法阻止shuffle的发生。
在线LDA训练
现在来看看在线训练。注意线上产品不应该使用上述方式运行。当然,如果不顾及线上模型训练,认为模型可以线下训练好的话另当别论。数据处理部门的人是不会把大量原始文本存储到本地磁盘,之后再将数据上传到服务器处理的。在我看来,大数据就应该放到合适的地方去。这种场景下,原始文本或者网页应该存储到一种KV存储中,例如HBase(Facebook在其论文Analysis
of HDFS Under HBase: A Facebook Messages Case Study中详述了HDFS之上的HBase性能问题,值得一看。)。除此之外,HDF5也是种不错的选择。
网络传输来自哪里
笔者一直在讨论避免网络传输开销的问题,那么网络传输到底出现在哪里从而导致的不可避免呢?
首先,文件大小超过单个block大小的文件不免被切分,不论是ASCII编码的文件,还是UTF这种多字节编码的文件,都需要一个join的过程。最好的情况下,我们期望同一个文件所有的block都从同一个机器上读取,这样可以避免网络传输。
第二,出于效率的考量,mapred包中的CombineFileInputFormat不能保证这一点。这是因为每个block都会有副本的存在。为了保证数据读取的高效,同一个文件的不同block可能读取不同机器上的副本。同时由于单个split大小的限制,同一个机器上的block也可能分到不同的split里面。正是由于HDFS多副本容错的特性,导致同个文件不同的block甚至可能在任何一个位置被读取。
自定义Partitioner怎么样
在笔者看来,Spark之所以好用的原因之一就是可以简单地定制partition方法。使用自定制的partitioner来重新安排我们KV对的存储。然而,定制化的partitioner最大的作用是在迭代地进行RDD
join的时候,正如Spark PageRank所展示的那样。如果是一次性的使用,有点得不偿失,因为第一次的shuffle在所难免。
Hadoop locality全揭秘
为了更好的了解Hadoop I/O保持良好locality的秘密,我们要深入看一看mapred包中的InputFormat实现。我们选择FileInputFormat作为突破口,因为这也是spark的“重点使用对象”。首先要记住这些后面会经常用到的概念:rack、node、file、block、replica。数据中心通常由一堆堆rack组成,rack是同一个机架中的机器。由于同个rack之间网络状况通常都是非常好的,因此考虑本地性的时候通常也将同个rack中的数据算作本地数据。一个rack由多个node组成,这里的node特指作为DataNode的机器。HDFS上每个文件包含多个block,每个block有一些副本(通常是三个)。要注意的是Hadoop的worker可能包含所有的DataNode节点,当然也会出现不匹配的现象,即有些机器仅仅是DataNode节点而非Hadoop
worker,反之亦然。同时也要注意,考虑到鲁棒性,每个block的三副本通常都是当前node一个,本rack其他机器一个,其他rack上一个。
把Hadoop worker也考虑进来后,问题稍显复杂。程序可能分布在多个worker上,数据分布在多个DataNode上。因此,问题抽象成如何在worker和DataNode之间做多对一的映射(一个worker会可能处理多个DataNode上的数据,而一份数据通常只要一个worker处理就好了),使得读取HDFS文件时造成的网络开销最小?换句话说,读取文件整体耗时最少。
这件事儿不是很容易,因为应用程序和数据之间还隔着好多层。程序所直接接触的就是文件名。一个文件被分为多个block,每个block可能存在于每一个数据节点上,其副本存在于其他节点上,不同的节点还属于不同的rack。我们先从程序开始看起。以Spark为例,我们调用hadoopRDD
= sc.textFile(path)告诉Spark开始读取path中的数据。这个path可能是一个本地文件路径,更常见的是HDFS路径。为了分布式处理的要求,hadoopRDD通常情况下是被切分的。那么,其partition的信息来自何处呢?答案就是HDFS中的split,更确切的说是FileSplit,其在FileInputFormat中被用到。FileSplit就是这样一种程序和block之间的映射。
每个FileSplit都是一个block集合,里面的block会在同一个worker上的同一个程序读出,因此也理所当然作为一个partition。为了保持同一个split中block的本地性,FileSplit花了大力气把合适的block放到一起。例如贡献度计算,以及node-block、rack-block之间的双向链表等。现在我们把之前的程序-block映射问题退化成split-block的映射问题。
Node/Rack贡献度计算
假设我们有一个split,其中有三个block,这三个block来自8个节点。8个节点属于4个不同的rack,每个block有三个副本。假设这三个block的大小分别为100、150、75。这种情况下怎么安排“最佳地点”?即该split应该在哪个worker上计算?
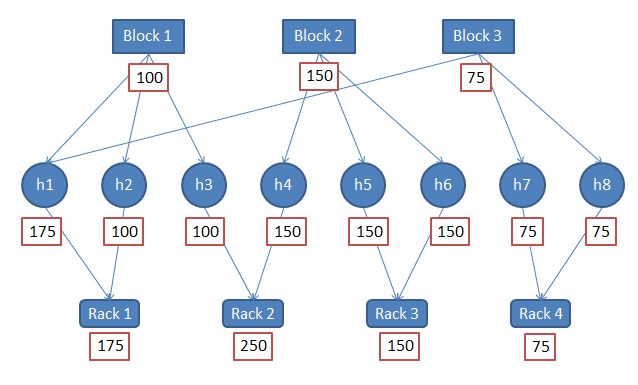
首先,我们一致同意的一点是“最佳地点”应该是所有node的子集。在我们的例子中,这个集合是[h1 ---
h8]这八个节点。怎样对这个集合进行排序,依次找到“最佳地点”、“次佳地点”?
对节点集合进行排序有两种方法,分别是考虑rack的信息和不考虑rack的信息。上文说过,可以将同一个rack中的block也算做本地的block。要想排序,先要确定准则,即什么才是“好”。参照上图,我们定义一个“effective
size”的概念,这是说在本节点上,存在多少比特有效的数据可供读取。同样的,rack的effective
size就是该rack上所有的有效读取的比特。注意,并非是将该节点有的block以及字节数加起来这么简单,这里的“有效”是指的有区分度的字节数。例如,Rack4有两个block,每个block的大小都是75,但Rack4的effective
size只有75,并非150,因为这两个block具有相同的内容,他们互为副本。
考虑到rack的计算方式就是将rack看作跟node同等的位置,计算effective size之后,可得如下顺序:
1. Rack 2 (250)
h4 (150)
h3 (100)
2. Rack 1 (175)
h1 (175)
h2 (100)
3. Rack 3 (150)
h5 (150)
h6 (150)
4. Rack 4 (75)
h7 (75)
h8 (75)
因此,优先顺序是h4 > h3 > h1 > h2 >
h5 > h6 > h7 > h8。
不考虑rack的方法更简单,节点排序的结果为:
h1 (175)
h4 (150)
h5 (150)
h6 (150)
h2 (100)
h3 (100)
h7 (75)
h8 (75)
其优先顺序为 h1 > h4 > h5 > h6 >
h2 > h3 > h7 > h8。
更多细节参见Hadoop的测试用例: https://github.com/apache/hadoop-common/blob/release-1.0.4/src/test/org/apache/hadoop/mapred/TestGetSplitHosts.java
双向链表
CombineFileInputFormat选择了另外的方式保持locality的性质,它使用双向链表将block串在一起,之后先是逐节点扫描block,再次是逐rack扫描node,最后剩下来的“残片”丢到最后一堆处理,这样最大限度的保证locality,并且维持partition的大小尽可能平衡。缺点就是出现跨block的文件的情况下,同一个文件的block很有可能落到不同的partition中。这里的陷阱是,在Hadoop老API中,isSplitable()函数不能起到保持同一个文件内容在同一个partition中的作用,而在新API中反倒有这个功能了。各位使用的时候可要睁大眼睛。顺便说一句,新API虽然加入了这个功能,但是不切分文件的情况下,在保持locality和partition均衡的性质上可就没老API好了。无论如何,这些trade-off总是逃不掉的。
Double linked lists sweep for constructing split - CombineFileInputFormat.java
// mapping from a rack name to the list of blocks it has
HashMap<String, List<OneBlockInfo>> rackToBlocks =
new HashMap<String, List<OneBlockInfo>>();
// mapping from a block to the nodes on which it has replicas
HashMap<OneBlockInfo, String[]> blockToNodes =
new HashMap<OneBlockInfo, String[]>();
// mapping from a node to the list of blocks that it contains
HashMap<String, List<OneBlockInfo>> nodeToBlocks =
new HashMap<String, List<OneBlockInfo>>();
...
// process all nodes and create splits that are local
// to a node.
for (Iterator<Map.Entry<String,
List<OneBlockInfo>>> iter = nodeToBlocks.entrySet().iterator();
iter.hasNext();) { |
如何读取
聊了这么多,我们总算清楚MapReduce类的程序如何在组织split的时候保持良好的block的本地性了。我们很开心的获得其中的“最佳地点”,并将这个信息传递给spark的partition。下一步工作就是Spark根据“最佳地点”,如上例中的节点h4,启动worker上的处理进程/线程开始读取数据了。现在h4启动了spark的executor开始处理split中的block。但是稍等,h4怎么知道从哪个节点上获得每个block呢?要知道,每个block有三个副本呢!具体读取该block的哪个副本这个信息并未传递给partition。
从RecordReader开始,我们再来一步步还原数据读取的过程。有了上面的基础,这次的旅程应该很快了。以笔者写的BatchFileRecordReader为例:
Constructer of BatchFileRecoderReader - BatchFileRecorderReader.java
public BatchFileRecordReader(
CombineFileSplit split,
Configuration conf,
Reporter reporter,
Integer index)
throws IOException {
path = split.getPath(index);
startOffset = split.getOffset(index);
pos = startOffset;
end = startOffset + split.getLength(index);
FileSystem fs = path.getFileSystem(conf);
fileIn = fs.open(path);
fileIn.seek(startOffset);
totalMemory = Runtime.getRuntime().totalMemory();
} |
在上面的代码中,我们从split中拿到了path,注意这里的path是当前文件路径,可不是block路径。有了它,我们可以拿到一个fileIn,其类型为FSDataInputStream。之后我们seek到这个block开始的位置,称作startOffset。等一下,我们根本没用到“最佳地点”的信息,是不是很奇怪呢?我们之前花了大量力气拿到的信息,这里没有用到。
这里需要记住的是,目前为止我们获得的split信息只是为每个block分配了计算节点,仅此而已。如何读取由别的代码控制。那么再来看看FSDataInputStream,这里也没有太多东西,只有一些看上去没啥用的代码。
FSDataInputStream.java
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable, Closeable {
public FSDataInputStream(InputStream in)
throws IOException {
super(in);
if( !(in instanceof Seekable) || !(in instanceof
PositionedReadable) ) {
throw new IllegalArgumentException(
"In is not an instance of Seekable or PositionedReadable");
}
}
public synchronized void seek(long desired)
throws IOException {
((Seekable)in).seek(desired);
}
} |
好吧,我们另觅他途。注意之前fileIn是由fs.open()这个调用获得的,在HDFS的场景下,这个fs其实是DistributedFileSystem,即常说的DFS。结果我们在DFS中找到了由DFSInputStream包装成的FSDataInputStream,前者在DFSClient中实现。我们所期待的函数是blockSeekTo(),这个函数负责给定偏移量之后找到合适的block。之后它会找到最优的DataNode,并从中读取数据。
Find an appropriate block and select a DataNode - DFSClient.java
DatanodeInfo chosenNode = null;
int refetchToken = 1; // only need to get a new access token once
while (true) {
//
// Compute desired block
//
LocatedBlock targetBlock = getBlockAt(target, true);
assert (target==this.pos) : "Wrong postion " + pos + " expect " + target;
long offsetIntoBlock = target - targetBlock.getStartOffset();
DNAddrPair retval = chooseDataNode(targetBlock);
chosenNode = retval.info;
InetSocketAddress targetAddr = retval.addr;
} |
这其中最重要的函数是chooseDataNode(),它非常简单,只是从一个DataNode列表中选择第一个node。如果第一个node连接不上,再找第二个,依次类推。bestNode()函数中的注释说这里的node列表已经按照优先规则排序好的了。很奇怪,这是在什么时候排序的呢?
实际上,在这个文件首次打开的时候就已经排序好了。参见openInfo()函数,它调用callGetBlockLocations()函数进行排序。后者在NameNode中的getBlockLocations()中查询信息。可以看到它调用了clusterMap中的pseudoSortByDistance()进行排序。至此,我们获得了Hadoop为应用保持数据本地性的全景。
Get block locations and sorted in the priority order - FSNamesystem.java
LocatedBlocks getBlockLocations(String clientMachine, String src,
long offset, long length) throws IOException {
LocatedBlocks blocks = getBlockLocations(src, offset, length, true, true);
if (blocks != null) {
//sort the blocks
DatanodeDescriptor client = host2DataNodeMap.getDatanodeByHost(
clientMachine);
for (LocatedBlock b : blocks.getLocatedBlocks()) {
clusterMap.pseudoSortByDistance(client, b.getLocations());
}
}
return blocks;
} |
结语
分布式数据并行环境下,保持数据的本地性是非常重要的内容,事关分布式系统性能高下。要想更好的了解Spark是怎么运作的,输入也许是很重要的一个环节。举一个小例子,你或许有心情在一台不错的机器上使用Spark处理100GB的数据。按理说这不应算作多大的应用场景,但如果不仔细调整一下你的输入的话,你会发现Spark甚至会在这台机器上切分上千个partition来并行处理这份数据。而这上千个partition随便来一个shuffle造成的百万量级的shuffle数据交换会把Spark性能拖死。实际上,调用Hadoop的API访问本地磁盘的默认块大小为32MB,据其分块策略,当然会产生上千个partition。另外,如果你本地是一堆小文件,如LDA的语料库,你会发现Spark甚至会为每个文件分配一个或多个partition!所以,这下你应该知道为什么有时简单的Spark程序也会非常慢了吧。
本文为了解决LDA小文件输入的问题,一步步揭开HDFS与Spark的数据通道的故事。总结来看,为了分布式使用各个机器,HDFS读取的时候将数据分成了各个分块,为了防止straggler的产生,MapReduce的读取模块会尽量保证各个分块在每台机器上的大小和个数均衡。为了保证较好的locality,Spark获取preferredLocation信息,尽量保证在临近的机器上读取所需的数据。为了合理读取小文件,CombineFileInputFormat合理安排小文件分片,既要保证数据在各个分块中均衡,又不能切断单个文件。为了保证HDFS与Spark之间的高效数据通道,正可谓”无所不用其极”。 |


