����һƪ���¡���߿���MongoDB��Ⱥ��һ����������MongoDB�� �ᵽ�˼������û�н����
1.���ڵ�����ܷ��Զ��л����ӣ�Ŀǰ��Ҫ�ֹ��л���
2.���ڵ�Ķ�дѹ��������ν����
3.�ӽڵ�ÿ����������ݶ��Ƕ����ݿ�ȫ���������ӽڵ�ѹ��������
4.����ѹ������֧�Ų��˵�ʱ���ܷ������Զ���չ��
��ƪ���¿�����Щ����Ϳ��Ը㶨�ˡ�NoSQL�IJ�������Ϊ�˽����������������չ�ԡ������ܡ��������ģ�͡��߿����ԡ����ǹ�ͨ������ģʽ�ļܹ�ԶԶ�ﲻ�����漸�㣬�ɴ�MongoDB����˸������ͷ�Ƭ�Ĺ��ܡ���ƪ������Ҫ���ܸ�������
mongoDB�ٷ��Ѿ�������ʹ������ģʽ�ˣ���������Dz��ø�������ģʽ������鿴����ͼ��

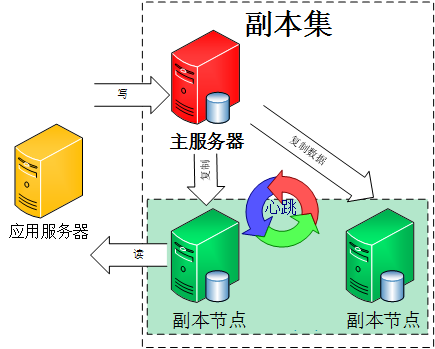
��ʲô�Ǹ������أ���ħ��������˵������ʵ������������һ����˼����Ϸ��ĸ�����ָ��Ҽ����ڸ߷�ʱ��ȥһ��������֣��������ұ�������ٵ��������Ϸ������Ϊ�˱�֤��ҵ�����ȣ���Ϊÿһ����ҵ�������һ��ͬ���Ŀռ�ͬ���������Ĺ����һ�����Ƶij�������һ�������������ж��ٸ���Ҹ����ڸ��Եĸ������治�ụ��Ӱ�졣 mongoDB�ĸ���Ҳ�����������ģʽ��ʵ����һ����������Ӧ�ã�û�кܺõ���չ�Ժ��ݴ��ԡ������������ж��������֤���ݴ��ԣ�����һ�������ҵ��˻��кܶั�����ڣ����ҽ���������һ�����⡰���ڵ�ҵ��ˣ�������Ⱥ�ڻ��Զ��л������ѹ�mongoDB�ٷ��Ƽ�ʹ������ģʽ������������mongoDB�������ļܹ�ͼ��
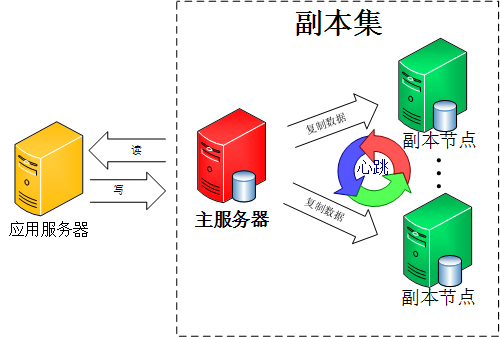
��ͼ���Կ����ͻ������ӵ������������������ľ�����һ̨�����Ƿ�ҵ��������������������������Ķ�д������������ͬ�����ݱ��ݣ�һ�����ڵ�ҵ��������ڵ�ͻ�ѡ��һ���µ�������������һ�ж���Ӧ�÷���������Ҫ���ġ����ǿ�һ�����������ҵ���ļܹ���
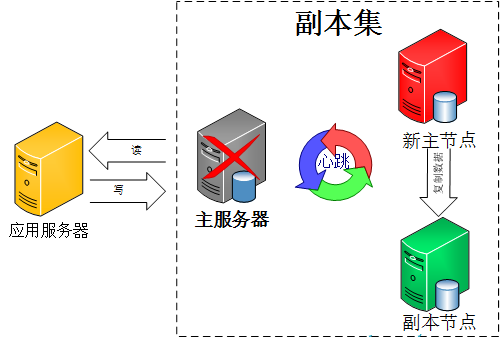
�������еĸ����ڵ������ڵ�ҵ���ͨ���������Ƽ��ͻ��ڼ�Ⱥ�ڷ������ڵ��ѡ�ٻ��ƣ��Զ�ѡ��һλ�µ�������������������ţX�����ӣ����ǸϽ���������һ�£�
�ٷ��Ƽ��ĸ�������������Ϊ����3����������Ҳ��������������ò��ԡ�
1������̨����192.168.1.136��192.168.1.137��192.168.1.138�� 192.168.1.136 �������������ڵ���192.168.1.137��192.168.1.138��Ϊ�����������ڵ㡣
2���ֱ���ÿ̨�����Ͻ���mongodb�����������ļ���

3������mongodb�İ�װ�����

ע��linux�����������ܰ�װ32λ��mongodb����Ϊ32λ�����ڲ���ϵͳ���2G���ļ����ơ�
4���ֱ���ÿ̨����������mongodb

���Կ�������̨����ʾ��������û�����ó�ʼ����Ϣ��

5����ʼ��������
����̨����������һ̨������½mongodb

#���帱�������ñ���������� _id:��repset�� ��������������� �CreplSet repset�� Ҫ����һ����

#���
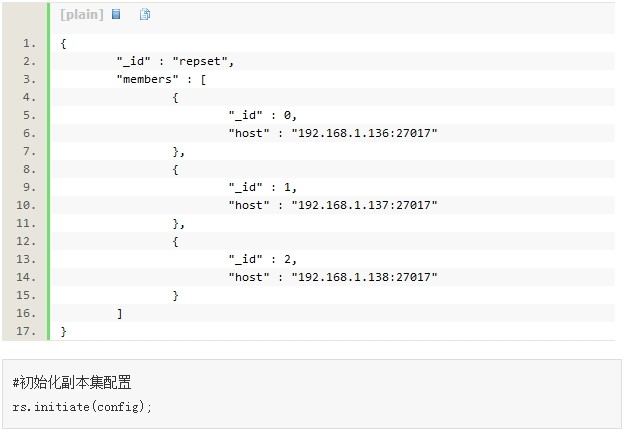
#����ɹ�
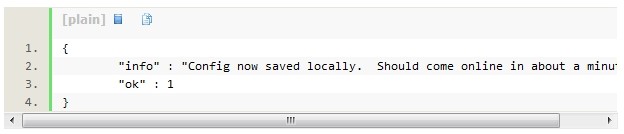
#�鿴��־�������������ɹ���138Ϊ���ڵ�PRIMARY��136��137Ϊ�����ڵ�SECONDARY��
#���

�����������Ѿ���ɹ��ˡ�
6�����Ը��������ݸ��ƹ���

#���

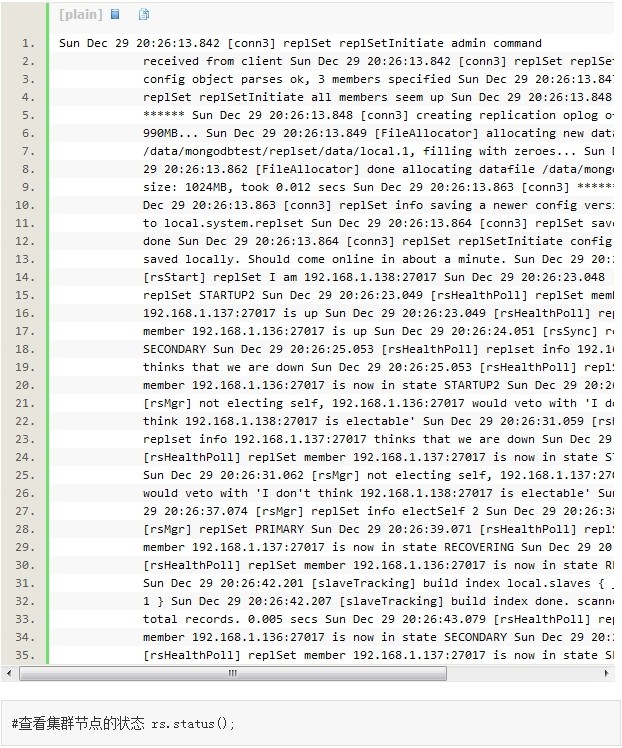
7�����Ը���������ת�ƹ���
��ͣ�����ڵ�mongodb 138���鿴136��137����־���Կ�������һϵ�е�ͶƱѡ�������137 ��ѡ���ڵ㣬136��137ͬ�����ݹ�����
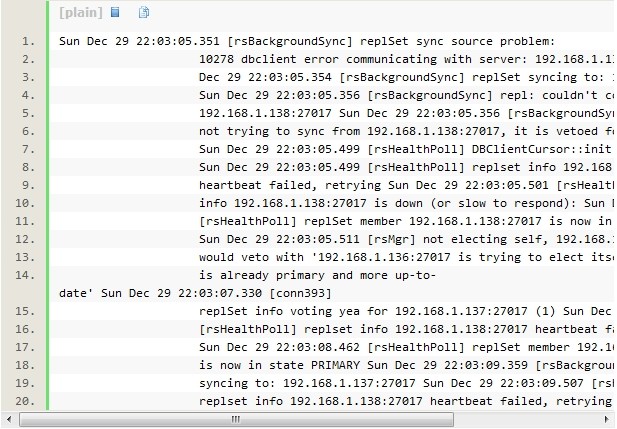
�鿴������Ⱥ��״̬�����Կ���138Ϊ״̬���ɴ

#���

������ԭ�������ڵ� 138������138 ��Ϊ SECONDARY������137 Ϊ���ڵ� PRIMARY��

8��java�������Ӹ��������ԡ������ڵ���һ���ڵ�ҵ�Ҳ����Ӱ��Ӧ�ó���ͻ��˶������������Ķ�д��
Ŀǰ������֧�������Ĺ���ת���ˣ�����ܹ��Dz��DZȽ������ˣ���ʵ���кܶ�ط������Ż������翪ͷ�ĵڶ������⣺���ڵ�Ķ�дѹ��������ν���������Ľ�������Ƕ�д���룬mongodb�������Ķ�д����������أ�
��ͼ˵����
����д������˵��û�ж������࣬����һ̨���ڵ㸺��д����̨�����ڵ㸺�����
1�����ö�д������Ҫ���ڸ����ڵ�SECONDARY ���� setSlaveOk��
2���ڳ��������ø����ڵ㸺������������´��룺
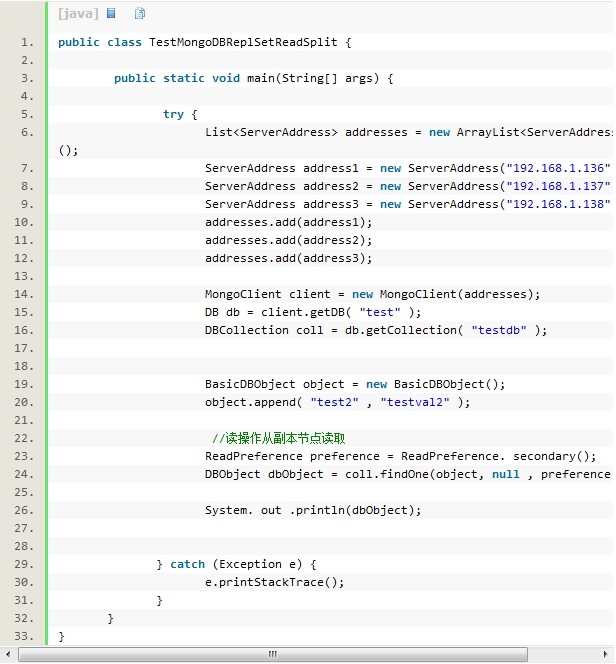
����������secondaryһ���������������primary��primaryPreferred��secondary��secondaryPreferred��nearest��
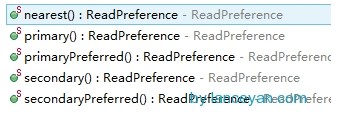
primary:Ĭ�ϲ�����ֻ�����ڵ��Ͻ��ж�ȡ������
primaryPreferred:�ִ����ڵ��϶�ȡ����,ֻ�����ڵ㲻����ʱ��secondary�ڵ��ȡ���ݡ�
secondary:ֻ��secondary�ڵ��Ͻ��ж�ȡ���������ڵ�������secondary�ڵ�����ݻ��primary�ڵ����ݡ��ɡ���
secondaryPreferred:���ȴ�secondary�ڵ���ж�ȡ������secondary�ڵ㲻����ʱ�����ڵ��ȡ���ݣ�
nearest:���������ڵ㡢secondary�ڵ㣬�������ӳ���͵Ľڵ��϶�ȡ���ݡ�
�ã���д�����������ǿ������ݷ���������ѹ������ˡ����ڵ�Ķ�дѹ��������ν������������⡣���������ǵĸ����ڵ�����ʱ�����ڵ�ĸ���ѹ����Ӵ���ʲô�취�����mongodb���������Ӧ�Ľ��������
��ͼ��
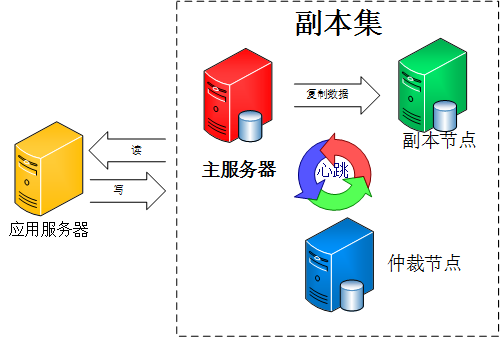
���е��ٲýڵ㲻�洢���ݣ�ֻ�Ǹ������ת�Ƶ�Ⱥ��ͶƱ���������������ݸ��Ƶ�ѹ�����Dz�����ú��ܵ�����һ��mongodb�Ŀ����ֵ���֪�����ݼܹ���ϵ����ʵ��ֻ�����ڵ㡢�����ڵ㡢�ٲýڵ㣬����Secondary-Only��Hidden��Delayed��Non-Voting��
Secondary-Only:���ܳ�Ϊprimary�ڵ㣬ֻ����Ϊsecondary�����ڵ㣬��ֹһЩ���ܲ��ߵĽڵ��Ϊ���ڵ㡣
Hidden:����ڵ��Dz��ܹ����ͻ����ƶ�IP���ã�Ҳ���ܱ�����Ϊ���ڵ㣬���ǿ���ͶƱ��һ�����ڱ������ݡ�
Delayed������ָ��һ��ʱ���ӳٴ�primary�ڵ�ͬ�����ݡ���Ҫ���ڱ������ݣ����ʵʱͬ������ɾ����������ͬ�����ӽڵ㣬�ָ��ָֻ����ˡ�
Non-Voting��û��ѡ��Ȩ��secondary�ڵ㣬����ı������ݽڵ㡣
��������mongodb�������㶨���������⣺
���ڵ�����ܷ��Զ��л����ӣ�Ŀǰ��Ҫ�ֹ��л���
���ڵ�Ķ�дѹ��������ν����
����������������������
�ӽڵ�ÿ����������ݶ��Ƕ����ݿ�ȫ���������ӽڵ�ѹ��������
����ѹ������֧�Ų��˵�ʱ���ܷ������Զ���չ��
���˸�����������һЩ���⣺
����������ת�ƣ����ڵ������ѡ�ٵģ��ܷ��ֶ������¼�ijһ̨���ڵ㡣
�ٷ�˵���������������������Ϊʲô��
mongodb�����������ͬ���ģ����ͬ������ʱ�����ʲô����������ֲ�һ���ԣ�
mongodb�Ĺ���ת�ƻ�����Զ�������ʲô�����ᴥ����Ƶ���������ܻ����ϵͳ���ؼ���


