����������Ĵ��������Լ������Ӵ���ʱ��Ҳ��������ʽ����Ŀ���ڿ���֮�У����ܴ����ݴ������������������Ҳ����д���µ��뷨���ˡ���������Hadoop�Լ���NO SQL��Ϊ����Mongo��Cassandra�����ݿ⼼����չ�֡��������ݵ�ʵʱ��������������һЩ�����ڼ�Ⱥ��ת����Խ��Խ�ɿ�,20�������ھ��ܹ���ɡ���Ϊ�����ñ���֧��?������Щ�ǽ�����һЩ�Ƚ��µģ�δ�������ŵ�Ͳ�ƽ���Ĵ���ᳬ������Щ����IJ��롣
��֪��ô�������ڵ��г��ϳ���25�����Դ���������ˡ�Χ�����������ߣ���ЩԽ��Խ���ӵ�ϵͳ���������ǿ�����������������ͼ����
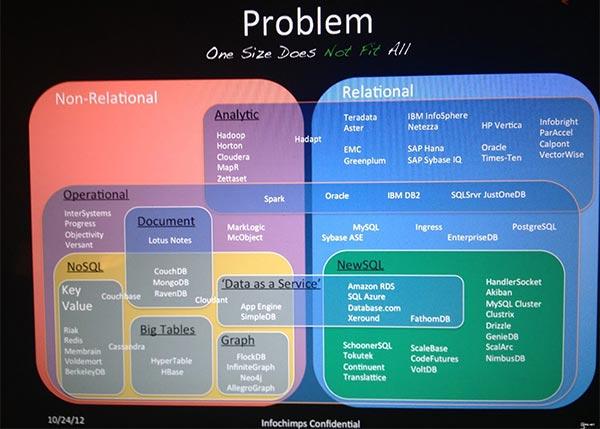
������ѡ�����������ǻ����кܶ�ѡ��Ļ��ᡣ��Щ�����Ŀ��?��Щ��2000�ҹ�˾�������IJƸ�?��Щ��Ŀ�ǿ����������IJ�Ʒ��ʹ�õ���Ϊ�ɿ��ĺ�ѡ?��ЩӦ���ܵ��ر��ע��?����������ϸ���о��Ͳ��ԣ�������һ����5���µĺ��������ݵļ�������Щ�������ļ����µĹ��ߣ�������һ���������ɡ�
Storm �� Kafka ��δ����������������Ҫ��ʽ�������Ѿ���һЩ��˾��ʹ���ʶ������� Groupon,����Ͱͺ�The Weather Channel�ȡ�Storm,������Twitter,��һ���ֲ�ʽʵʱ����ϵͳ��Storm ������ڴ���ʵʱ����,hadoop��Ҫ���ڴ������������㡣
kafka����LinkedIn�з���һ����Ϣϵͳ��Ϊһ�����ݴ����Ĺܵ��������ִ�����ϵͳ�С�����һ��ʹ�����ǣ������ʵʱ�غ����Ե����Ļ�ȡ���ݡ�
��Ϊʲô��Ҫ����?
ʹ��Storm��Kafka,ʹ���������������Եģ�ȷ��ÿ����Ϣ��ȡ����ʵʱ�ģ��ɿ��ġ�ǰ���õ�Storm��Kafka��ÿ�������Ĵ���10000�����ݡ�
��Storm��Kafka��������������������ʹ�úܶ���ҵ�����ע����ﵽ�����ETL(��ȡת��װ��)�����ݼ��ɷ�����Storm �� Kafka Ҳ���ó��ڴ������ʵʱ����֧�֡���ҵʹ������������Hadoop������Ҳ�ѹֶ�ʵʱ��ҵ����������ҵ�Ĵ����ݽ��������ʵʱ������������һ����Ҫ��ģ�飬��Ϊ���������Ĵ����ˡ�3v���Cvolume,velocity �� variety (���������ʺͶ�����)��Storm��Kafka��2�ּ���������(infochimps)���Ƽ��ļ���������Ҳ����Ϊһ����ʽ��ɲ��ִ��������ǵ�ƽ̨�С�Drill��Dremel ʵ���˿��ٵ��صĴ��ģ����ϯ��ѯ���������������ṩ���뼶����P�������ݵĿ��ܣ���Ӧ�Լ�ϯ��ѯ��Ԥ�⣬���ṩǿ������⻯֧�֡�
Drill��Dremel�ṩǿ���ҵ����������������ֻ��Ϊ���ݹ���ʦ�ṩ��ҵ��˵Ĵ�Ҷ���ϲ��Drill��Dremel.Drill ��Google��Dremel�Ŀ�Դ�汾��Dremel��Google�ṩ��֧�ִ����ݲ�ѯ�ļ�������˾�������������Լ��Ĺ��ߣ���Щ�ǵ��´�Ҷ����еĹ�עDrill��ԭ����Ȼ��Щ���������ǿ�Դ����ǿ�ҵ���Ȥʹ������ø����졣
Ϊʲô��Ӧ�ù���?
Drill��Dremel���Hadoop���õķ�����ϯ��ѯ��Hadoop�����ṩ���������ݴ�������������ЩҲ��ȱ�㡣
Hadoop��̬Ȧʹ��MapReduce��Ϊһ�������������Ĺ���Ӧ���ڹ���������Sawzall��Pig��Hive,�ܶ�ӿڲ�Ӧ�õĽ���ʹ��Hadoop��Ϊ�Ѻã����ӽ�ҵ���ǣ���SQL��ϵ����Щ��������һ����Ҫ����ʵ�CMapReduce(��Hadoop)��Ϊ��ϵͳ�����ݴ������̶����ڵġ�����㲻�����ܵ���Щ����? ����㲻������Щ�����������ȥѰ��𰸣��Ǿͱ��ֳ�Ĭ,���ֶ�����������ϯ̽���� �� ������Ѿ��е����ݴ���������ô�Ż��������ٶ�?�㲻Ӧ������һ���µ���������ǵȴ�����ʱ���ǵ�ʱ�仹�������ʸ��µ����⡣
�ڶѶԱȵĹ����������ķ������У��ܶ�ҵ��������BI�ͷ�����ѯ���Ǻܻ����ĺ���ʱ�����ģ�����ʱ������дMap/Reduce�������ںܶ�ҵ��������DZ���ֹ�ġ��ȴ������ӵ�Jobs�������ڵȼ���Сʱ��ִ�������Щ���������ݵĽ������飬��Щ�Աȣ������űȽ����ղ����˻������µ���Ұ��һЩ���ݿ�ѧ�����Ѿ��Ʋ�Drill��Dremel������Hadoop������ɹ�ʶ��Ҳ��һЩ���ڿ����У������ٲ��ֵĿ���������ӵ���仯��������Щ����Ҫ���ŵ��ڸ������ѯ�ĺ͵���ʱ������¡���Infochimps����ϲ��ʹ��Elasticsearchȫ������������ʵ�����ݿ��������������������ڴ����ݴ�����������ΪDrill����Ϊ������
R�ǿ�Դ��ǿ���ͳ�Ʊ�����ԡ���1997������������200���ͳ�Ʒ���ʦʹ��R������һ�ŵ����Ա���ʵ���ҵ���ͳ�Ƽ���������ִ����S���Բ�Ѹ�ٵس�Ϊ���µı���ͳ�����ԡ�Rʹ�ø��ӵ����ݿ�ѧ��ø����ۡ�R��SAS��SPASS����Ҫ����ͷ�ߣ�����Ϊ�������ͳ��ʦ����Ҫ���ߡ�
Ϊʲô��Ӧ�ù���?
��Ϊ����һ���Ƿ�ǿ���������֧���ţ�������ҵ����е�R����⣬��������ĸ����͵Ŀ�ѧ���ݶ�������д���롣R֮���������˷�����Ϊά�������˺��µ�ÿ��Ĵ��졣R�����Ǵ��������������˷ܵĵط�֮һ��R�ڴ�����������һ�������IJ����ʱ�ļ�����������ļ��������ǧ�������Ա����湫����֪ʶ����Ϊ���ķ������͵ķ���ʦ�ǽ���.���ң�R��HadoopЭͬ�ĺܺã���Ϊһ�������ݵĴ����IJ����Ѿ���֤���ˡ����ֹ�ע��Julia ����һ����Ȥ��R������ߣ���Ϊ����ϲ��R�����������Ľ�������Julia��������Ȼ����ôǿ�����ڣ���������㲻������ʹ�����Ļ������ǿ��Եȵȵġ�Gremlin �� Giraph ������ǿͼ�η���������ͼ���ݿ���Neo4j��InfiniteGraph�б�ʹ�ã�����HadoopЭͬ������Giraph�б�ʹ�á�Golden Orb����һ���߲������������ͼ��������Ŀ�����ӡ����Կ�����ͼ���ݿ��Ǹ��������ı�Ե�������ݿ⡣���Ǻ�ϵ�����ݿ���ȣ����źܶ���Ȥ�IJ�ͬ�㣬����ǵ����ڿ�ʼ��ʱ����������ͼ���۶����ǹ�ϵ�����ۡ�
��һ�����Ƶ�ͼ������������Google��Pregel,�����˵Gremlin��Giraph����Ŀ�Դ�����ʵ���ϣ���Щ����Google������ɽկʵ�ֵ����ӡ�ͼ�ڼ������罨ģ����ữ���緽�淢������Ҫ���ã��ܹ�������������ݡ�����һ��������Ӧ����ӳ��͵�����Ϣ���㡣��A��B�ĵص㣬������̵ľ��롣ͼ����������������������Ҳ�й㷺��Ӧ�ã����磬�����ܻ��Ʋ�Ѱ���ķ��ӽṹ��������ͼ��ͼ���ݿ�ͷ������ԺͿ�ܶ���һ����ʵ������ʵ�ִ������е�һ���֡�ͼ������������һ��ɱ�ּ���Ӧ�ã�Ϊʲô��ô˵?�κ�һ�������������ڵ����⣬����ͨ���ڵ�ͽڵ�֮���·���������ġ��ܶ�д������Ŀ�ѧ�Һ���ʦ�ǣ�������������ȷ�Ĺ����������Ӧ�����⡣ȷ�����Ƕ������е�Ư�����ܱ��㷺������
SAP Hana ��һ��ȫ�ڴ�ķ���ƽ̨����������һ���ڴ����ݿ��һЩ��صĹ����������������������̺淶��ȷ�ĸ�ʽ���������ݵ����������
ΪʲôӦ�ù���?
SAP ��ʼ����Ϊ�̻�����ҵ�û����ǿ��IJ�Ʒ�����������ʹ�á������������SAP��ʼΪ�������룬����ʹ��Hana��������Ȩ�������������������Щ��Ѱ����������Χ��Hana�Ľ����
Hana ���������ij�����ʱ������Ľ�����������⣬���磬���ڽ�ģ�;���֧�֣���վ���Ի�����ƭ���ȵȡ�Hana����ȱ���ǡ�ȫ�ڴ桰����ζ�ŷ�����״̬���ڴ棬����Ǻ���ȷ���е㣬�������Ҳ����ȴ��̴洢��˵�ܰ���IJ��֡�����֯��˵�����õ��IJ����ɱ���Hana�ǿ��ٵĵ��ӳٵĴ����ݴ������ߡ�
D3 ���������б��У������������иУ���������Ϊ�������ļ�ֵ��D3��һ��javascript�����ĵ��Ŀ��ӻ�����⣬����ǿ��Ĵ����Ե���������ֱ�ӿ�����Ϣ�������ǽ��������Ľ���������������Michael Bostockһ��ŦԼʱ����ͼ�ν������ʦ�����磬�����ʹ��D3�������������������д���H?l��������ʹ����������������������������ȡ�������һ��D3��ʵ�����ӣ�����2013��°��������������ʹ��D3������Ա��֮�䴴�����棬��֯���еĸ������͵����ݡ�
��Ȼ��ƪ���²���������Ҳ������һ��ʵ�������룬���벻��֮��ϣ�����ָ������ʵ������ƪ���µ�ʱ���Ҿͺ������������ϲ�������ˣ�������һ�����ŵĻ���������������IT����������ô�����˾�ϲ����Ȼ����Ҳ�ø����ˡ�
��ʼ��ʽ��ʹ��Hadoop�Ѿ��н�һ���ʱ����ˣ����ڼ�Ӱٶȳ������������ڵ����ڵ�BitWare���ڲ�ͬ�Ĺ�˾���ò�ͬ�ļ���������⡣���DZ���������������������ô��������Ȼ���ںܶ˾Ҳ��ʼ���ʵ�ʹ��Hadoop���ˡ�����Ǵ�����ˣ��������⡣
����˵˵���˶����µ����⣺
Storm��Kafka ��11���𣬾Ϳ�ʼ��ע�ˣ�Storm�ڰ���Ҳ�в��ֶ���Ӧ�ã�����������ԣ��ո���һ���Storm��nathanmarz�����Ĵ�ĥ��Խ��Խ�ȶ��ˣ����в������ϵ�Ӧ���ˡ����Զ����������������ԣ��Ҹ��˻��Ǻܿ��õģ���Ϊ����ʹ��hadoop��ʵ��ʵʱ�Ĵ�����ʹ��HBase��Ϊ��Ҫ�����ݿ���ʹ���ˣ���ʱ�����ܽ�������ǻ����볢����Storm,Kafka�Ĺ�ע���Ǻܶ࣬��������������ʹ�ã���˵���ޣ�û���Լ��ܹ���
Drill�����Apache�Ŀ�Դ��Ŀ��֮ǰҲ����Google Dremel�����ģ����ο����Ǻܶ�������Ҳû�����������Ļ��������������Ÿոջ����������Ի�û�кܶ��ʱ������������ʱ�ȸ����ˡ�
R���ԣ�֮ǰ�ڰٶȵ�ʱ���ڸ�λ���ĸ��Ǿ���ʹ��R���Ըɻ���������ֻ�д�˾�ܹ�������ȥ�������ھ�ķ���ɣ��������ڵ�ҵ���л���û���õ���������R���Ǻ�İ���������Ҹ��������ڲ�ͬ�Ļ�����ʹ�ò�ͬ�ļ����ֶΣ����磬��ʿ����紵���ӣ����Ǽܸ���紵����һ����ʵ�ְɡ�
����ͼ���ݿ����������û����������ϸ��Ӧ�ã���û�л�����������Ĺ�˾�����Ի�����֮�߸�ɡ�
SPA�����˾���������֣�����û�о���ĽӴ����������������������Ҳ���ù���Ū���������������֪���Ȼ��DZ���ġ����ڿ��ϱ���ʱ���Ѿ���ȥ���ˡ�
���һ�����ӻ���JS��⣬��Ȥ����ҵ�����ڲ�ȥ��ǰ�˵��ˣ�����Ҳ���á�


