| ǰ�찢������ʵ���hadoopƽ̨���˽⣬��Ȼ��ǰ�Ӵ���һ��ʱ�䣬�����������ˣ����Ա����ˡ�������������ϰ�»���֪ʶ�ɣ��Ͼ����ڲ�����hadoop˵����ȥ��
ʲô��Hadoop��
hadoopһ����������ͨӲ������ �Ĵ�Ⱥ������Ӧ�ó���Ŀ�ܡ�Hadoop�������ΪӦ�ó����ṩ�ɿ����������ƶ����ϡ�Hadoopʵ����һ������Ϊ
mapReduce�� ����ģ�ͣ����������ģ����Ӧ�ó���Ϊ�ܶ��С�飬ÿһ�鶼���ڼ�Ⱥ�е�����ڵ���ִ�л�����ִ�С����⣬�����ṩ��һ���ֲ�ʽ�ļ�ϵͳ��HDFS�����ڼ����
���ϴ洢���ݣ�Ϊ��Ⱥ�ṩ�˷dz��ߵľۺϴ������ڱ������������Map/Reduce���Ƿֲ�ʽ�ļ�ϵͳ�������Ϊ�ܹ��Զ��ش����ڵ��ϵĴ���
Hadoop����ɣ�
Hadoop Common �C contains libraries and utilities needed by other Hadoop modules
Hadoop Distributed File System (HDFS) �C a distributed file-system that stores data on commodity machines,
providing very high aggregate bandwidth across the cluster.
Hadoop YARN �C a resource-management platform responsible for managing
compute resources in clusters and using them for scheduling of users' applications.
Hadoop MapReduce �C a programming model for large scale data processing. |
Hadoop���������ĵ���ƾ��ǣ�MapReduce��HDFS��MapReduce��˼������Google��һƪ�������ἰ������Ϊ�����ģ���һ�仰����MapReduce���ǡ�����ķֽ������Ļ��ܡ���HDFS��Hadoop�ֲ�ʽ�ļ�ϵͳ��Hadoop
Distributed File System������д��Ϊ�ֲ�ʽ����洢�ṩ�˵ײ�֧�֡�
MapReduceԭ����
MapReduce���������������ʹ��¿��Կ�����Ե�ɣ���������Map��Reduce����Map��չ���������ǽ�һ������ֽ��Ϊ�������Reduce�����ǽ��ֽ����������Ľ�������������ó����ķ���������ⲻ��ʲô��˼�룬��ʵ��ǰ���ᵽ�Ķ��̣߳����������ƾͿ����ҵ�����˼���Ӱ�ӡ���������ʵ��ᣬ�����ڳ�������У�һ����������Ա���ֳ�Ϊ�����������֮��Ĺ�ϵ���Է�Ϊ���֣�һ���Dz���ص������Բ���ִ�У���һ��������֮��������������Ⱥ�˳���ܹ��ߵ������������������д����ġ��ص���ѧʱ�ڣ������Ͽ�ʱ�ô��ȥ�����ؼ�·�����Ǿ�������ʡʱ������ֽ�ִ�з�ʽ���ڷֲ�ʽϵͳ�У�������Ⱥ�Ϳ��Կ���Ӳ����Դ�أ������е������֣�Ȼ����ÿһ�����л�����Դȥ�������ܹ�����������Ч�ʣ�ͬʱ������Դ���ԣ����ڼ��㼯Ⱥ����չ�����ṩ����õ���Ʊ�֤������ֽ���Ժ��Ǿ���Ҫ�������Ժ�Ľ���ٻ��������������ReduceҪ���Ĺ������ṹͼ���£�
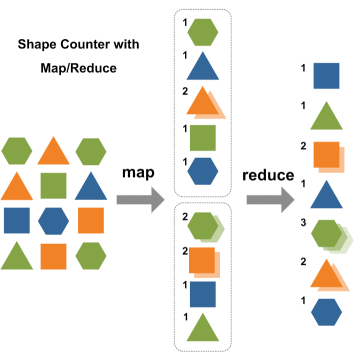
�����и��ı���������MapReduceԭ����
����Ҫ��ͼ����е������顣����1����ܣ�����2����ܡ�����ǡ�Map����������Խ�࣬������졣
�������ǵ�һ�𣬰������˵�ͳ��������һ������ǡ�Reduce����
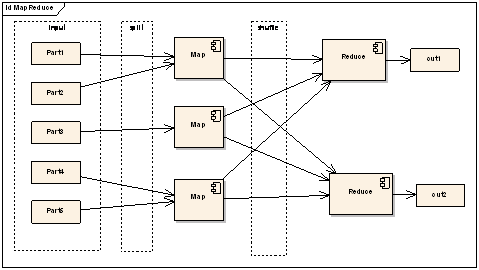
ͼ��MapReduce�ṹʾ��ͼ
��ͼ����MapReduce���µĽṹͼ����Mapǰ�����ܻ�������������Split���ָ�Ĺ��̣���֤������Ч�ʣ���Map֮����Shuffle����ϣ��Ĺ��̣��������Reduce��Ч���Լ���С���ݴ����ѹ���кܴ�İ��������������ἰ��Щ���ֵ�ϸ�ڡ�
1.Map-Reduce��������
����������Ҫ����һ���й����������ݣ����ʽ���£�
1.����ASCII��洢��ÿ��һ����¼
2.ÿһ���ַ���0��ʼ��������15������18���ַ�Ϊ��
3.��25������29���ַ�Ϊ�¶ȣ����е�25λ�Ƿ���+/-
0067011990999991950051507+0000+
0043011990999991950051512+0022+
0043011990999991950051518-0011+
0043012650999991949032412+0111+
0043012650999991949032418+0078+
0067011990999991937051507+0001+
0043011990999991937051512-0002+
0043011990999991945051518+0001+
0043012650999991945032412+0002+
0043012650999991945032418+0078+
|
������Ҫͳ�Ƴ�ÿ�������¶ȡ�
Map-Reduce��Ҫ�����������裺Map��Reduce
ÿһ������key-value����Ϊ����������
1.map�ε�key-value�Եĸ�ʽ��������ĸ�ʽ�������ģ������Ĭ�ϵ�TextInputFormat����ÿ����Ϊһ����¼���̴���������keyΪ���еĿ�ͷ������ļ�����ʼλ�ã�value���Ǵ��е��ַ��ı�
2.map�ε������key-value�Եĸ�ʽ����ͬreduce�ε�����key-value�Եĸ�ʽ���Ӧ
������������ӣ���map���̣������key-value�����£�
(0, 0067011990999991950051507+0000+)
(33, 0043011990999991950051512+0022+)
(66, 0043011990999991950051518-0011+)
(99, 0043012650999991949032412+0111+)
(132, 0043012650999991949032418+0078+)
(165, 0067011990999991937051507+0001+)
(198, 0043011990999991937051512-0002+)
(231, 0043011990999991945051518+0001+)
(264, 0043012650999991945032412+0002+)
(297, 0043012650999991945032418+0078+)
|
��map�����У�ͨ����ÿһ���ַ����Ľ������õ���-�¶ȵ�key-value����Ϊ�����
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
(1937, 1)
(1937, -2)
(1945, 1)
(1945, 2)
(1945, 78)
|
��reduce���̣���map�����е������������ͬ��key��value�ŵ�ͬһ���б�����Ϊreduce������
(1950, [0, 22, �C11])
(1949, [111, 78])
(1937, [1, -2])
(1945, [1, 2, 78])
|
��reduce�����У����б���ѡ��������¶ȣ�����-����¶ȵ�key-value��Ϊ�����
(1950, 22)
(1949, 111)
(1937, 1)
(1945, 78)
|
2����дMap-Reduce����
��дMap-Reduce����һ����Ҫʵ������������mapper�е�map������reducer�е�reduce������
һ����ѭ���¸�ʽ��
1.map: (K1, V1) -> list(K2, V2)
public interface Mapper<K1, V1, K2, V2> extends JobConfigurable, Closeable {
void map(K1 key, V1 value, OutputCollector<K2,
V2> output, Reporter reporter)
throws IOException;
} |
2.reduce: (K2, list(V)) -> list(K3,
V3)
public interface Reducer<K2, V2, K3, V3> extends JobConfigurable, Closeable {
void reduce(K2 key, Iterator<V2> values,
OutputCollector<K3, V3> output, Reporter
reporter)
throws IOException;
} |
������������ӣ���ʵ�ֵ�mapper���£�
public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(25) == '+') {
airTemperature = Integer.parseInt(line.substring(26,
30));
} else {
airTemperature = Integer.parseInt(line.substring(25,
30));
}
output.collect(new Text(year), new IntWritable(airTemperature));
}
} |
ʵ�ֵ�reducer���£�
public class MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable>
values, OutputCollector<Text, IntWritable>
output, Reporter reporter) throws IOException
{
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
} |
����������ʵ�ֵ�Mapper��Reduce������Ҫ����һ��Map-Reduce������(Job)��������������������֣�
1.��������ݣ�Ҳ����Ҫ����������
2.Map-Reduce����Ҳ������ʵ�ֵ�Mapper��Reducer
3.�������������JobConf
������JobConf����Ҫ�����˽�Hadoop����job�Ļ���ԭ����
1.Hadoop��Job�ֳ�task���д�����������task��map task��reduce
task
2.Hadoop������Ľڵ����job�����У�JobTracker��TaskTracker
.JobTrackerЭ������job�����У���task���䵽��ͬ��TaskTracker��
.TaskTracker��������task������������ظ�JobTracker
3.Hadoop���������ݷֳɹ̶���С�Ŀ飬���dz�֮input split
4.HadoopΪÿһ��input split����һ��task���ڴ�task�����δ�����split�е�һ������¼(record)
5.Hadoop�ᾡ�����������ݿ����ڵ�DataNode��task��ִ�е�DataNode(ÿ��DataNode�϶���һ��TaskTracker)Ϊͬһ���������������Ч�ʣ�����input
split�Ĵ�СҲһ����HDFS��block�Ĵ�С��
6.Reduce task������һ��ΪMap Task�������Reduce
Task�����Ϊ����job�������������HDFS�ϡ�
7.��reduce�У���ͬkey�����еļ�¼һ���ᵽͬһ��TaskTracker�������У�Ȼ����ͬ��key�����ڲ�ͬ��TaskTracker�������У����dz�֮Ϊpartition
partition�Ĺ���Ϊ��(K2, V2) �C> Integer��
Ҳ������K2������һ��partition��id��������ͬid��K2�����ͬһ��partition����ͬһ��TaskTracker�ϱ�ͬһ��Reducer���д�����
public interface Partitioner<K2, V2> extends JobConfigurable {
int getPartition(K2 key, V2 value, int numPartitions);
}
|
��ͼ���������Map-Reduce��Job���еĻ���ԭ����

������������JobConf�����кܶ������Խ������ã�
1.setInputFormat������map�������ʽ��Ĭ��ΪTextInputFormat��keyΪLongWritable,
valueΪText
2.setNumMapTasks������map����ĸ�����������ͨ���������ã�map����ĸ���ȡ����������������ֳܷɵ�input
split����
3.setMapperClass������Mapper��Ĭ��ΪIdentityMapper
4.setMapRunnerClass������MapRunner, map
task����MapRunner���еģ�Ĭ��ΪMapRunnable���书��Ϊ��ȡinput split��һ����record�����ε���Mapper��map����
5.setMapOutputKeyClass��setMapOutputValueClass������Mapper�������key-value�Եĸ�ʽ
6.setOutputKeyClass��setOutputValueClass������Reducer�������key-value�Եĸ�ʽ
7.setPartitionerClass��setNumReduceTasks������Partitioner��Ĭ��ΪHashPartitioner�������key��hashֵ�����������ĸ�partition��ÿ��partition��һ��reduce
task����������partition�ĸ�������reduce task�ĸ���
8.setReducerClass������Reducer��Ĭ��ΪIdentityReducer
9.setOutputFormat����������������ʽ��Ĭ��ΪTextOutputFormat
10.FileInputFormat.addInputPath�����������ļ���·��������ʹһ���ļ���һ��·����һ��ͨ��������Ա����ö�����Ӷ��·��
11.FileOutputFormat.setOutputPath����������ļ���·������job����ǰ��·����Ӧ�ô���
��Ȼ�������еĶ����ã�����������ӣ����Ա�дMap-Reduce�������£�
public class MaxTemperature {
public static void main(String[] args) throws
IOException {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature
<input path> <output path>");
System.exit(-1);
}
JobConf conf = new JobConf(MaxTemperature.class);
conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(MaxTemperatureMapper.class);
conf.setReducerClass(MaxTemperatureReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
JobClient.runJob(conf);
}
} |
3��Map-Reduce������(data flow)
Map-Reduce�Ĵ���������Ҫ�漰�����ĸ����֣�
1.�ͻ���Client�������ύMap-reduce����job
2.JobTracker��Э������job�����У���Ϊһ��Java���̣���main
classΪJobTracker
3.TaskTracker�����д�job��task������input split����Ϊһ��Java���̣���main
classΪTaskTracker
4.HDFS��hadoop�ֲ�ʽ�ļ�ϵͳ�������ڸ������̼乲��Job��ص��ļ�
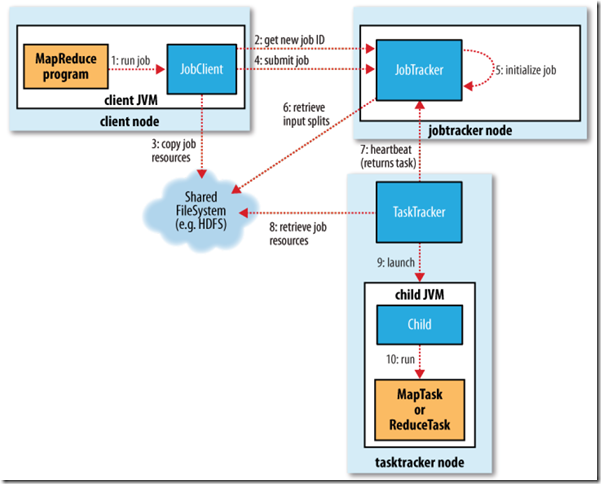
3.1�������ύ
JobClient.runJob()����һ���µ�JobClientʵ����������submitJob()������
��JobTracker����һ���µ�job ID
����job��output����
�����job��input splits
��Job�����������Դ������JobTracker���ļ�ϵͳ�е��ļ����У�����job
jar�ļ���job.xml�����ļ���input splits
֪ͨJobTracker��Job�Ѿ�����������
�ύ�����runJobÿ��һ������ѯһ��job�Ľ��ȣ������ȷ��ص������У�ֱ������������ϡ�
3.2�������ʼ��
��JobTracker�յ�submitJob���õ�ʱ��������ŵ�һ�������У�job���������Ӷ����л�ȡ����ʼ������
��ʼ�����ȴ���һ����������װjob���е�tasks, status�Լ�progress��
�ڴ���task֮ǰ��job���������ȴӹ����ļ�ϵͳ�л��JobClient�������input
splits��
��Ϊÿ��input split����һ��map task��
ÿ��task������һ��ID��
3.3���������
TaskTracker�����Ե���JobTracker����heartbeat��
��heartbeat�У�TaskTracker��֪JobTracker���Ѿ�������һ���µ�task��JobTracker���������һ��task��
��JobTrackerΪTaskTrackerѡ��һ��task֮ǰ��JobTracker�������Ȱ������ȼ�ѡ��һ��Job����������ȼ���Job��ѡ��һ��task��
TaskTracker�й̶�������λ��������map task����reduce
task��
Ĭ�ϵĵ������Դ�map task������reduce task
��ѡ��reduce task��ʱ��JobTracker�����ڶ��task֮�����ѡ����ֱ��ȡ��һ������Ϊreduce
taskû�����ݱ��ػ��ĸ��
3.4������ִ��
TaskTracker��������һ��task�������Ҫ���д�task��
���ȣ�TaskTracker����job��jar�ӹ����ļ�ϵͳ�п�����TaskTracker���ļ�ϵͳ�С�
TaskTracker��distributed cache�н�job��������Ҫ���ļ����������ش��̡�
��Σ���Ϊÿ��task����һ�����صĹ���Ŀ¼����jar��ѹ�����ļ�Ŀ¼�С�
�������䴴��һ��TaskRunner������task��
TaskRunner����һ���µ�JVM������task��
��������child JVM��TaskTrackerͨ�����������н��ȡ�
3.4.1��Map����
MapRunnable��input split�ж�ȡһ������record��Ȼ�����ε���Mapper��map����������������
map�����������ֱ��д��Ӳ�̣����ǽ���д�뻺��memory buffer��
��buffer�����ݵĵ���һ���Ĵ�С��һ�������߳̽����ݿ�ʼд��Ӳ�̡�
��д��Ӳ��֮ǰ���ڴ��е�����ͨ��partitioner�ֳɶ��partition��
��ͬһ��partition�У������̻߳Ὣ���ݰ���key���ڴ�������
ÿ�δ��ڴ���Ӳ��flush���ݣ�������һ���µ�spill�ļ���
����task����֮ǰ�����е�spill�ļ����ϲ�Ϊһ�����ı�partition�Ķ����ź�����ļ���
reducer����ͨ��httpЭ������map������ļ���tracker.http.threads��������http�����߳�����
3.4.2��Reduce����
��map task��������֪ͨTaskTracker��TaskTracker֪ͨJobTracker��
����һ��job��JobTracker֪��TaskTracer��map����Ķ�Ӧ��ϵ��
reducer��һ���߳������Ե���JobTracker����map�����λ�ã�ֱ����ȡ�������е�map�����
reduce task��Ҫ���Ӧ��partition�����е�map�����
reduce task�е�copy���̼���ÿ��map task������ʱ��Ϳ�ʼ�����������Ϊ��ͬ��map
task���ʱ�䲻ͬ��
reduce task���ж��copy�̣߳����Բ��п���map�����
���ܶ�map���������reduce task��һ�������߳̽���ϲ�Ϊһ������ź�����ļ���
�����е�map�����������reduce task����sort���̣������е�map����ϲ�Ϊ����ź�����ļ���
������reduce���̣�����reducer��reduce�����������ź���������ÿ��key�����Ľ��д��HDFS��
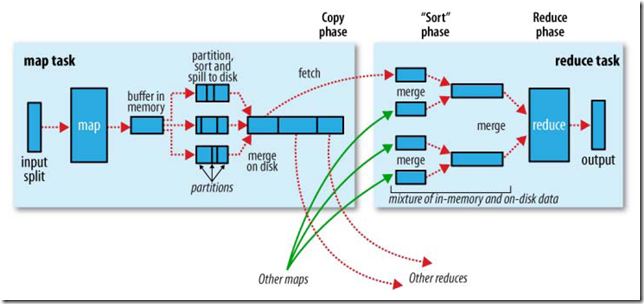
3.5���������
��JobTracker������һ��task�����гɹ��ı����job��״̬��Ϊ�ɹ���
��JobClient��JobTracker��ѯ��ʱ���ִ�job�Ѿ��ɹ������������û���ӡ��Ϣ����runJob�����з��ء�
HdFS�Ļ�������
1.1�����ݿ�(block)
HDFS(Hadoop Distributed File System)Ĭ�ϵ�������Ĵ洢��λ��64M�����ݿ顣
����ͨ�ļ�ϵͳ��ͬ���ǣ�HDFS�е��ļ��DZ��ֳ�64Mһ������ݿ�洢�ġ�
��ͬ����ͨ�ļ�ϵͳ���ǣ�HDFS�У����һ���ļ�С��һ�����ݿ�Ĵ�С������ռ���������ݿ�洢�ռ䡣
1.2��Ԫ���ݽڵ�(Namenode)�����ݽڵ�(datanode)
Ԫ���ݽڵ����������ļ�ϵͳ�������ռ�
�佫���е��ļ����ļ��е�Ԫ���ݱ�����һ���ļ�ϵͳ���С�
��Щ��ϢҲ����Ӳ���ϱ���������ļ��������ռ侵��(namespace image)������־(edit
log)
�仹������һ���ļ�������Щ���ݿ飬�ֲ�����Щ���ݽڵ��ϡ�Ȼ����Щ��Ϣ�����洢��Ӳ���ϣ�������ϵͳ������ʱ������ݽڵ��ռ����ɵġ�
���ݽڵ����ļ�ϵͳ�������洢���ݵĵط���
�ͻ���(client)����Ԫ������Ϣ(namenode)���������ݽڵ�����д����߶������ݿ顣
�������Ե���Ԫ���ݽڵ�ر���洢�����ݿ���Ϣ��
��Ԫ���ݽڵ�(secondary namenode)
��Ԫ���ݽڵ㲢����Ԫ���ݽڵ��������ʱ��ı��ýڵ㣬����Ԫ���ݽڵ㸺��ͬ�����顣
����Ҫ���ܾ��������Խ�Ԫ���ݽڵ�������ռ侵���ļ�������־�ϲ����Է���־�ļ�������������������������
�ϲ�����������ռ侵���ļ�Ҳ�ڴ�Ԫ���ݽڵ㱣����һ�ݣ��Է�Ԫ���ݽڵ�ʧ�ܵ�ʱ���Իָ���
1.2.1��Ԫ���ݽڵ��ļ��нṹ
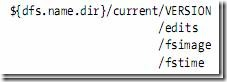
VERSION�ļ���java properties�ļ���������HDFS�İ汾�š�
layoutVersion��һ����������������HDFS�ij�������Ӳ���ϵ����ݽṹ�ĸ�ʽ�汾�š�
namespaceID���ļ�ϵͳ��Ψһ��ʶ���������ļ�ϵͳ���θ�ʽ��ʱ���ɵġ�
cTime�˴�Ϊ0
storageType��ʾ���ļ����б������Ԫ���ݽڵ�����ݽṹ��
namespaceID=1232737062
cTime=0
storageType=NAME_NODE
layoutVersion=-18
|
1.2.2���ļ�ϵͳ�����ռ�ӳ���ļ�������־
1.���ļ�ϵͳ�ͻ���(client)����д����ʱ�����Ȱ�����¼������־��(edit
log)
2.Ԫ���ݽڵ����ڴ��б������ļ�ϵͳ��Ԫ������Ϣ���ڼ�¼������־��Ԫ���ݽڵ������ڴ��е����ݽṹ��
3.ÿ�ε�д�����ɹ�֮ǰ������־����ͬ��(sync)���ļ�ϵͳ��
4.fsimage�ļ���Ҳ�������ռ�ӳ���ļ������ڴ��е�Ԫ������Ӳ���ϵ�checkpoint������һ�����л��ĸ�ʽ�������ܹ���Ӳ����ֱ���ġ�
5.ͬ���ݵĻ������ƣ���Ԫ���ݽڵ�ʧ��ʱ��������checkpoint��Ԫ������Ϣ��fsimage���ص��ڴ��У�Ȼ����һ����ִ������־�еIJ�����
6.��Ԫ���ݽڵ������������Ԫ���ݽڵ㽫�ڴ��е�Ԫ������Ϣcheckpoint��Ӳ���ϵ�
7.checkpoint�Ĺ������£�
��Ԫ���ݽڵ�֪ͨԪ���ݽڵ������µ���־�ļ����Ժ����־��д���µ���־�ļ��С�
��Ԫ���ݽڵ���http get��Ԫ���ݽڵ���fsimage�ļ����ɵ���־�ļ���
��Ԫ���ݽڵ㽫fsimage�ļ����ص��ڴ��У���ִ����־�ļ��еIJ�����Ȼ�������µ�fsimage�ļ���
��Ԫ���ݽڵ㽱�µ�fsimage�ļ���http post����Ԫ���ݽڵ�
Ԫ���ݽڵ���Խ��ɵ�fsimage�ļ����ɵ���־�ļ�����Ϊ�µ�fsimage�ļ����µ���־�ļ�(��һ�����ɵ�)��Ȼ�����fstime�ļ���д��˴�checkpoint��ʱ�䡣
����Ԫ���ݽڵ��е�fsimage�ļ����������µ�checkpoint��Ԫ������Ϣ����־�ļ�Ҳ���¿�ʼ�������ĺܴ��ˡ�
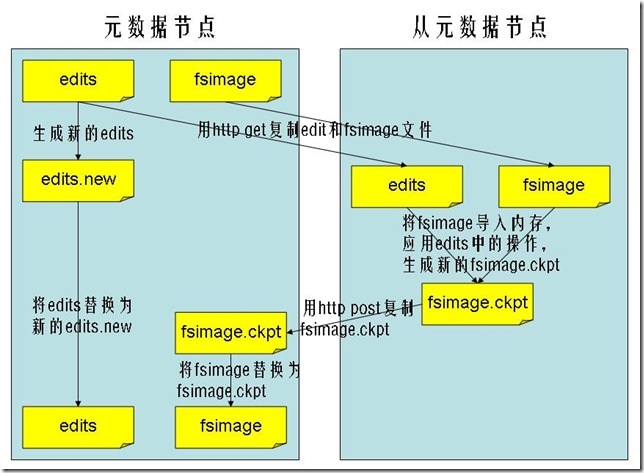
1.2.3����Ԫ���ݽڵ��Ŀ¼�ṹ
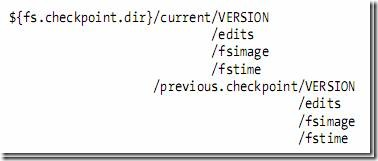
1.2.4�����ݽڵ��Ŀ¼�ṹ

���ݽڵ��VERSION�ļ���ʽ���£�
namespaceID=1232737062
storageID=DS-1640411682-127.0.1.1-50010-1254997319480
cTime=0
storageType=DATA_NODE
layoutVersion=-18 |
blk_<id>�������HDFS�����ݿ飬���б����˾���Ķ��������ݡ�
blk_<id>.meta����������ݿ��������Ϣ���汾��Ϣ��������Ϣ����checksum
��һ��Ŀ¼�е����ݿ鵽��һ��������ʱ�������ļ������������ݿ鼰���ݿ�������Ϣ��
����������(data flow)
2.1�����ļ��Ĺ���
�ͻ���(client)��FileSystem��open()�������ļ�
DistributedFileSystem��RPC����Ԫ���ݽڵ㣬�õ��ļ������ݿ���Ϣ��
����ÿһ�����ݿ飬Ԫ���ݽڵ㷵�ر������ݿ�����ݽڵ�ĵ�ַ��
DistributedFileSystem����FSDataInputStream���ͻ��ˣ�������ȡ���ݡ�
�ͻ��˵���stream��read()������ʼ��ȡ���ݡ�
DFSInputStream���ӱ�����ļ���һ�����ݿ����������ݽڵ㡣
Data�����ݽڵ�����ͻ���(client)
�������ݿ��ȡ���ʱ��DFSInputStream�رպʹ����ݽڵ�����ӣ�Ȼ�����Ӵ��ļ���һ�����ݿ����������ݽڵ㡣
���ͻ��˶�ȡ������ݵ�ʱ����FSDataInputStream��close������
�ڶ�ȡ���ݵĹ����У�����ͻ����������ݽڵ�ͨ�ų��ִ����������Ӱ��������ݿ����һ�����ݽڵ㡣
ʧ�ܵ����ݽڵ㽫����¼���Ժ������ӡ�

2.2��д�ļ��Ĺ���
�ͻ��˵���create()�������ļ�
DistributedFileSystem��RPC����Ԫ���ݽڵ㣬���ļ�ϵͳ�������ռ��д���һ���µ��ļ���
Ԫ���ݽڵ�����ȷ���ļ�ԭ�������ڣ����ҿͻ����д����ļ���Ȩ�ޣ�Ȼ�����ļ���
DistributedFileSystem����DFSOutputStream���ͻ�������д���ݡ�
�ͻ��˿�ʼд�����ݣ�DFSOutputStream�����ݷֳɿ飬д��data
queue��
Data queue��Data Streamer��ȡ����֪ͨԪ���ݽڵ�������ݽڵ㣬�����洢���ݿ�(ÿ��Ĭ�ϸ���3��)����������ݽڵ����һ��pipeline�
Data Streamer�����ݿ�д��pipeline�еĵ�һ�����ݽڵ㡣��һ�����ݽڵ㽫���ݿ鷢���ڶ������ݽڵ㡣�ڶ������ݽڵ㽫���ݷ������������ݽڵ㡣
DFSOutputStreamΪ����ȥ�����ݿ鱣����ack queue���ȴ�pipeline�е����ݽڵ��֪�����Ѿ�д��ɹ���
������ݽڵ���д��Ĺ�����ʧ�ܣ�
�ر�pipeline����ack queue�е����ݿ����data queue�Ŀ�ʼ��
��ǰ�����ݿ����Ѿ�д������ݽڵ��б�Ԫ���ݽڵ㸳���µı�ʾ�������ڵ��������ܹ���������ݿ��ǹ�ʱ�ģ��ᱻɾ����
ʧ�ܵ����ݽڵ��pipeline���Ƴ�����������ݿ���д��pipeline�е������������ݽڵ㡣
Ԫ���ݽڵ���֪ͨ�����ݿ��Ǹ��ƿ������㣬�������ٴ��������ݱ��ݡ�
���ͻ��˽���д�����ݣ������stream��close�������˲��������е����ݿ�д��pipeline�е����ݽڵ㣬���ȴ�ack
queue���سɹ������֪ͨԪ���ݽڵ�д����ϡ�

���������������hadoopƽ̨�Ļ��Ҿ����о���Դ�����ٲ��˵ģ�HadoopԴ����ַ���ٽ���Ȿ��HadoopԴ�������(������)ȥ����
��ʱ��Ļ���Ҳ����ϸȥ�о����������ڻ����Ȳ��������������˿���Щ����Ҫ����Щ������ͼ���һ��Hadoopƽ̨�Ķ����ɡ�
|


