| Data
Blocks
Oracle Database manages the logical
storage space in the data files of a database in units
called data blocks, also called Oracle blocks or pages.
A data block is the minimum unit of database I/O.
Data Blocks and Operating System Blocks
At the physical level, database data
is stored in disk files made up of operating system
blocks. An operating system block is the minimum unit
of data that the operating system can read or write.
In contrast, an Oracle block is a logical storage structure
whose size and structure are not known to the operating
system.
Figure 12�C5 shows that operating system
blocks may differ in size from data blocks. The database
requests data in multiples of data blocks, not operating
system blocks.
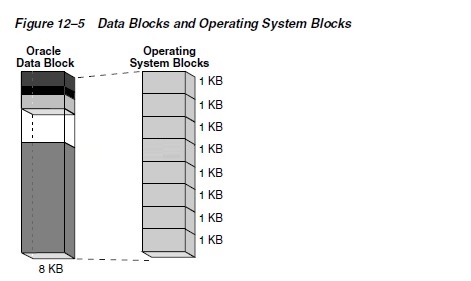
When the database requests a data block,
the operating system translates this operation into
a requests for data in permanent storage. The logical
separation of data blocks from operating system blocks
has the following implications:
Applications do not need to determine
the physical addresses of data on disk.
Database data can be striped or mirrored
on multiple physical disks.
Database Block Size
Every database has a database block
size. The DB_BLOCK_SIZE initialization parameter sets
the data block size for a database when it is created.
The size is set for the SYSTEM and SYSAUX tablespaces
and is the default for all other tablespaces. The database
block size cannot be changed except by re-creating the
database.
If DB_BLOCK_SIZE is not set, then the
default data block size is operating system-specific.
The standard data block size for a database is 4 KB
or 8 KB. If the size differs for data blocks and operating
system blocks, then the data block size must be a multiple
of the operating system block size.
Tablespace Block Size
You can create individual tablespaces
whose block size differs from the DB_BLOCK_SIZE setting.
A nonstandard block size can be useful when moving a
transportable tablespace to a different platform.
Data Block Format
Every data block has a format or internal
structure that enables the database to track the data
and free space in the block. This format is similar
whether the data block contains table, index, or table
cluster data. Figure 12�C6 shows the format of an uncompressed
data block (see "Data Block Compression" on
page 12-11 to learn about compressed blocks).
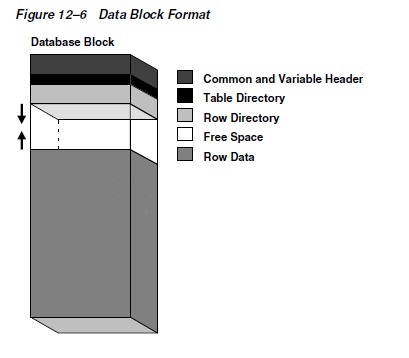
Data Block Overhead
Oracle Database uses the block overhead to manage the
block itself. The block overhead is not available to
store user data. As shown in Figure 12�C6, the block
overhead includes the following parts:
Block header
This part contains general information about the block,
including disk address and segment type. For blocks
that are transaction-managed, the block header contains
active and historical transaction information.
A transaction entry is required for every transaction
that updates the block. Oracle Database initially reserves
space in the block header for transaction entries. In
data blocks allocated to segments that support transactional
changes, free space can also hold transaction entries
when the header space is depleted. The space required
for transaction entries is operating system dependent.
However, transaction entries in most operating systems
require approximately 23 bytes.
Table directory
For a heap-organized table, this directory contains
metadata about tables whose rows are stored in this
block. Multiple tables can store rows in the same block.
Row directory
For a heap-organized table, this directory
describes the location of rows in the data portion of
the block.
After space has been allocated in the
row directory, the database does not reclaim this space
after row deletion. Thus, a block that is currently
empty but formerly had up to 50 rows continues to have
100 bytes allocated for the row directory. The database
reuses this space only when new rows are inserted in
the block.
Some parts of the block overhead are fixed in size,
but the total size is variable. On average, the block
overhead totals 84 to 107 bytes.
Row Format
The row data part of the block contains the actual
data, such as table rows or index key entries. Just
as every data block has an internal format, every row
has a row format that enables the database to track
the data in the row.
Oracle Database stores rows as variable-length records.
A row is contained in one or more row pieces. Each row
piece has a row header and column data.
Figure 12�C7 shows the format of a row.
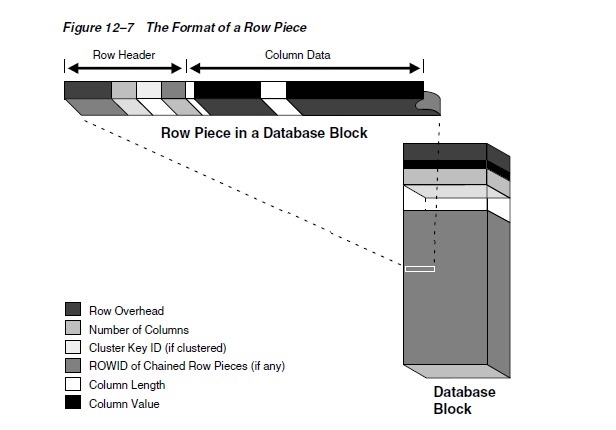
Row Header
Oracle Database uses the row header to manage the row
piece stored in the block. The row header contains information
such as the following:
Columns in the row piece
Pieces of the row located in other data
blocks
If an entire row can be inserted into a single data
block, then Oracle Database stores the row as one row
piece.However, if all of the row data cannot be inserted
into a single block or an update causes an existing
row to outgrow its block, then the database stores the
row in multiple row pieces (see "Chained and Migrated
Rows" on page 12-16). A data block usually contains
only one row piece per row.
Cluster keys for table clusters (see
"Overview of Table Clusters" on page 2-22)
A row fully contained in one block has at least 3 bytes
of row header.
Column Data
After the row header, the column data section stores
the actual data in the row. The row piece usually stores
columns in the order listed in the CREATE TABLE statement,
but this order is not guaranteed. For example, columns
of type LONG are created last.
As shown in Figure 12�C7, for each column in a row piece,
Oracle Database stores the column length and data separately.
The space required depends on the data type. If the
data type of a column is variable length, then the space
required to hold a value can grow and shrink with updates
to the data.
Each row has a slot in the row directory of the data
block header. The slot points to the beginning of the
row.
Rowid Format
Oracle Database uses a rowid to uniquely identify a
row. Internally, the rowid is a structure that holds
information that the database needs to access a row.
A rowid is not physically stored in the database, but
is inferred from the file and block on which the data
is stored.
An extended rowid includes a data object number. This
rowid type uses a base 64 encoding of the physical address
for each row. The encoding characters are A-Z, a-z,
0-9, +, and /.
Example 12�C1 queries the ROWID pseudocolumn to show
the extended rowid of the row in the employees table
for employee 100.
Example 12�C1 ROWID Pseudocolumn
SQL> SELECT ROWID FROM employees WHERE employee_id
= 100;
ROWID
------------------
AAAPecAAFAAAABSAAA

An extended rowid is displayed in a four-piece format,
OOOOOOFFFBBBBBBRRR, with the format divided into the
following components:
OOOOOO
The data object number identifies the segment (data
object AAAPec in Example 12�C1). A data object number
is assigned to every database segment. Schema objects
in the same segment, such as a table cluster, have the
same data object number.
FFF
The tablespace-relative data file number identifies
the data file that contains the row (file AAF in Example
12�C1).
BBBBBB
The data block number identifies the
block that contains the row (block AAAABS in Example
12�C1). Block numbers are relative to their data file,
not their tablespace. Thus, two rows with identical
block numbers could reside in different data files of
the same tablespace.
RRR
The row number identifies the row in the block (row
AAA in Example 12�C1).
Space Management in Data Blocks
As the database fills a data block from the bottom
up, the amount of free space between the row data and
the block header decreases. This free space can also
shrink during updates, as when changing a trailing null
to a nonnull value. The database manages free space
in the data block to optimize performance and avoid
wasted space.
Percentage of Free Space in Data Blocks
The PCTFREE storage parameter is essential to how the
database manages free space. This SQL parameter sets
the minimum percentage of a data block reserved as free
space for updates to existing rows. Thus, PCTFREE is
important for preventing row migration and avoiding
wasted space.
For example, assume that you create a table that will
require only occasional updates, most of which will
not increase the size of the existing data. You specify
the PCTFREE parameter within a CREATE TABLE statement
as follows:
CREATE TABLE test_table (n NUMBER) PCTFREE 20;
Figure 12�C9 shows how a PCTFREE setting of 20 affects
space management. The database adds rows to the block
over time, causing the row data to grow upwards toward
the block header, which is itself expanding downward
toward the row data. The PCTFREE setting ensures that
at least 20% of the data block is free. For example,
the database prevents an INSERT statement from filling
the block so that the row data and header occupy a combined
90% of the total block space, leaving only 10% free.
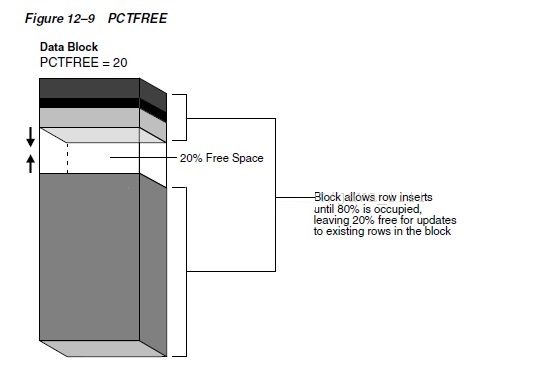
Note:
This discussion does not apply to LOB data types, which
do not use the PCTFREE storage parameter or free lists.
See "Overview of LOBs" on page 19-12.
Optimization of Free Space in Data Blocks
While the percentage of free space cannot be less than
PCTFREE, the amount of free space can be greater. For
example, a PCTFREE setting of 20% prevents the total
amount of free space from dropping to 5% of the block,
but permits 50% of the block to be free space. The following
SQL statements can increase free space:
DELETE statements
UPDATE statements that either update
existing values to smaller values or increase existing
values and force a row to migrate
INSERT statements on a table that uses
OLTP compression
If inserts fill a block with data, then the database
invokes block compression, which may result in the block
having more free space.
The space released is available for INSERT statements
under the following conditions:
If the INSERT statement is in the same
transaction and after the statement that frees space,
then the statement can use the space.
If the INSERT statement is in a separate
transaction from the statement that frees space (perhaps
run by another user), then the statement can use the
space made available only after the other transaction
commits and only if the space is needed.
Coalescing Fragmented Space
Released space may or may not be contiguous
with the main area of free space in a data block, as
shown in Figure 12�C10. Noncontiguous free space is called
fragmented space.
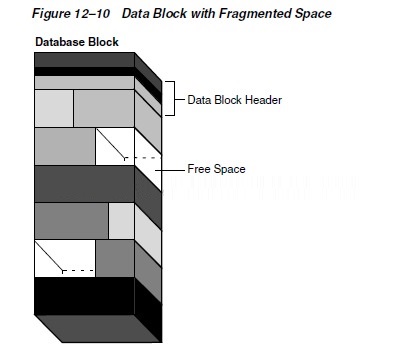
Oracle Database automatically and transparently coalesces
the free space of a data block only when the following
conditions are true:
An INSERT or UPDATE statement attempts
to use a block that contains sufficient free space to
contain a new row piece.
The free space is fragmented so that
the row piece cannot be inserted in a contiguous section
of the block.
After coalescing, the amount of free space is identical
to the amount before the operation, but the space is
now contiguous. Figure 12�C11 shows a data block after
space has been coalesced.

Oracle Database performs coalescing
only in the preceding situations because otherwise performance
would decrease because of the continuous coalescing
of the free space in data blocks.
Reuse of Index Space
The database can reuse space within an index block.
For example, if you insert a value into a column and
delete it, and if an index exists on this column, then
the database can reuse the index slot when a row requires
it.
The database can reuse an index block
itself. Unlike a table block, an index block only becomes
free when it is empty. The database places the empty
block on the free list of the index structure and makes
it eligible for reuse. However, Oracle Database does
not automatically compact the index: an ALTER INDEX
REBUILD or COALESCE statement is required.
Figure 12�C12 represents an index of
the employees.department_id column before the index
is coalesced. The first three leaf blocks are only partially
full, as indicated by the gray fill lines.
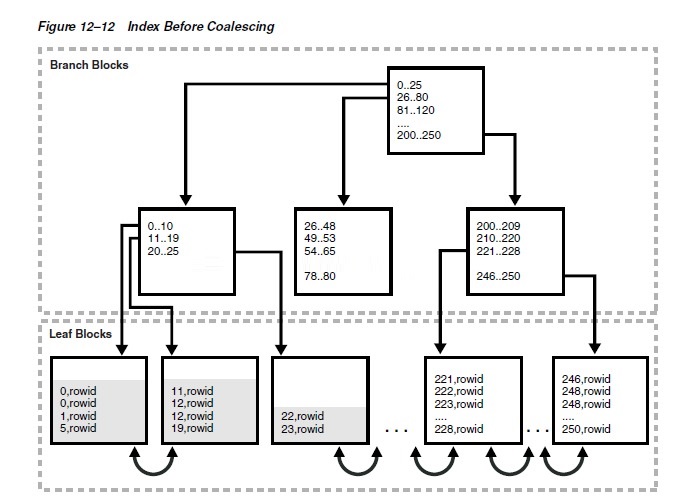
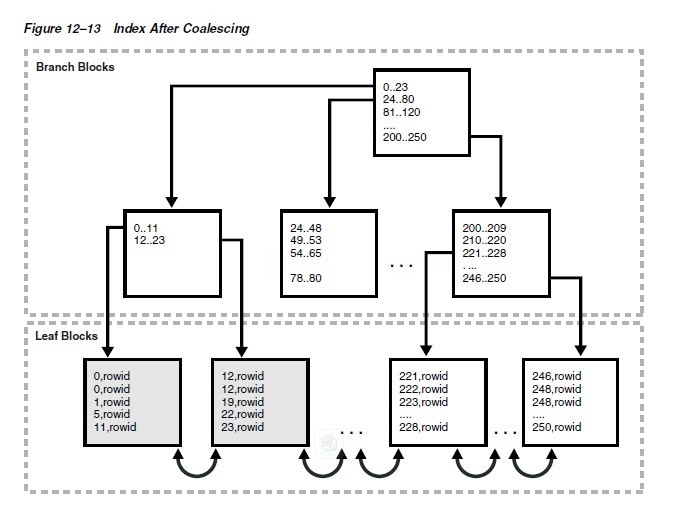
Figure 12�C13 shows the index in Figure
12�C12 after the index has been coalesced. The first
two leaf blocks are now full, as indicated by the gray
fill lines, and the third leaf block has been freed.
Chained and Migrated Rows
Oracle Database must manage rows that
are too large to fit into a single block. The following
situations are possible:
Oracle Database must manage rows that
are too large to fit into a single block. The following
situations are possible:
The row is too large to fit into one
data block when it is first inserted.
In row chaining, Oracle Database stores the data for
the row in a chain of one or more data blocks reserved
for the segment. Row chaining most often occurs with
large rows. Examples include rows that contain a column
of data type LONG or LONG RAW, a VARCHAR2(4000) column
in a 2 KB block, or a row with a huge number of columns.
Row chaining in these cases is unavoidable.
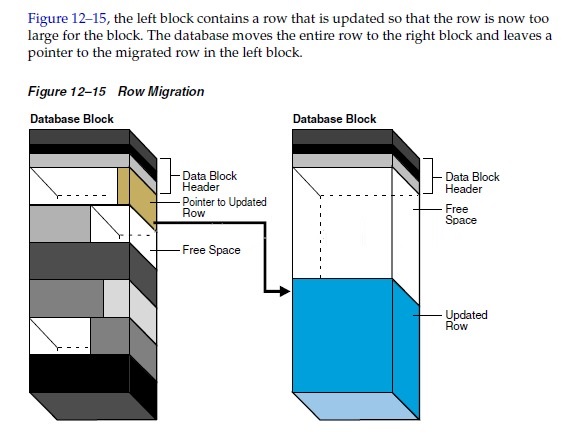
A row that originally fit into one data
block is updated so that the overall row length increases,
but insufficient free space exists to hold the updated
row.
In row migration, Oracle Database moves the entire
row to a new data block, assuming the row can fit in
a new block. The original row piece of a migrated row
contains a pointer or "forwarding address"
to the new block containing the migrated row. The rowid
of a migrated row does not change.
A row has more than 255 columns.
Oracle Database can only store 255 columns in a row
piece. Thus, if you insert a row into a table that has
1000 columns, then the database creates 4 row pieces,
typically chained over multiple blocks.
Figure 12�C14 depicts shows the insertion
of a large row in a data block. The row is too large
for the left block, so the database chains the row by
placing the first row piece in the left block and the
second row piece in the right block.

When a row is chained or migrated, the I/O needed to
retrieve the data increases. This situation results
because Oracle Database must scan multiple blocks to
retrieve the information for the row. For example, if
the database performs one I/O to read an index and one
I/O to read a nonmigrated table row, then an additional
I/O is required to obtain the data for a migrated row.
The Segment Advisor, which can be run both manually
and automatically, is an Oracle Database component that
identifies segments that have space available for reclamation.
The advisor can offer advice about objects that have
significant free space or too many chained rows.
|


