在继续分析NameNode启动之前,先看看DateNode与NameNode的目录构成与类继承结构,NameNode与DataNode的启动过程与这些目录结构和类继承结构相关,在启动的过程中会检查目录的状态。这里所分析的类的继承结构是与存储文件相关的类,与数据交换有关的类暂不考虑。
DataNode的文件目录结构
DataNode目录就是数据节点上存放与数据块相关数据的目录,由${dfs.data.dir}属性指定,这个属性可以指定多个值,值之间使用逗号隔开,如“/data1/datanode,/data2/datanode”指定类两个目录来存放数据节点。如果不指定${data.data.dir}数据块将会放在一个名为tmp的临时目录中,下文中就用${dfs.data.dir}代表数据节点的存储目录。DataNode启动之后${dfs.data.dir}目录中有四个目录和两个文件,如下图所示。
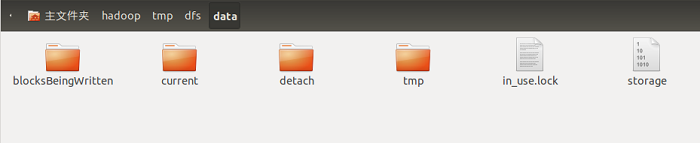
其中in_use.lock文件是在DataNode节点启动之后产生的,其中各个目录的作用如下:
blocksBeingWritten:该文件夹保存着当前正在”写“的数据块。
current:保存着HDFS文件系统中的数据块,这些数据块是成功提交到HDFS中的数据块。detach:用于配合数据节点升级,共数据块分离操作保存临时工作文件。
tmp:该文件夹保存着当前正在”写“的数据块,和blockBeingWritten文件夹的区别是,blockBeingWritten中的数据块写操作由客户端发起,tmp中的写操作由数据块复制引发,另一个数据节点正在发送数据到数据块中。
storage:0.13版本以前的Hadoop使用storage文件作为数据块的保存目录,和现在的目录结构不兼容,这个文件用于防止过旧的Hadoop版本在新的目录结构上启动,损坏系统。
in_use.lock:表明目录已经被使用,停止数据节点,该文件会消失,通过in_use.lock文件,数据节点可以保证独自占用该目录,防止两个数据节点示例共享一个目录,造成混乱。
current目录是数据节点中最重要的一个目录,它用于存放数据块,该目录中既包含目录,也包含文件,其中文件有两种类型:
HDFS数据块,保存着HDFS文件的内容;
用于保存数据块的校验信息的校验信息文件,以meta后缀名标识;
VERSION文件是一个Java属性文件,包含了HDFS的版本信息。
current目录如下图所示:
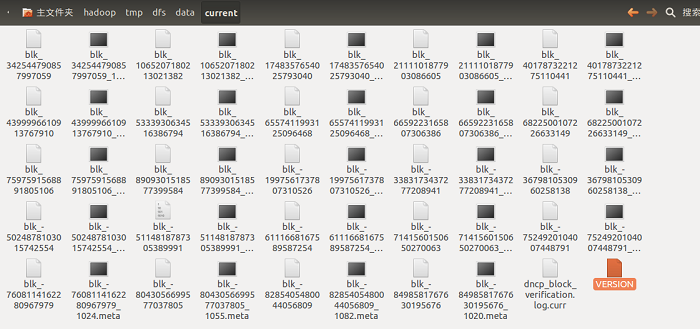
在这个图片中,没有目录,是因为当前的数据节点中的文件块的数量较少,只有当目录中存储的数据块增加到一定规模时,子目录名以subdir为前缀,然后后面加上目录编号,数据节点会创建一个新目录,用于保存新的块及元数据。目录中的数据块数达到64时,便会创建子目录,并形成一个更宽的目录结构,同时\统一父目录下最多会创建64个子目录,所以在默认配置下,一个目录下最多只有64个文件块和64个子目录。这种目录管理方式既保证了目录深度不会太深,而影响检索文件性能,同时也避免了目录保存大量数据块,确保每个目录中的文件块是可控的。
DataNode中类的继承结构
在HDFS中,与上面的目录和文件对应的类有多个,这些类组成一个继承结构,根类是StorageInfo类,继承结构如下图所示:
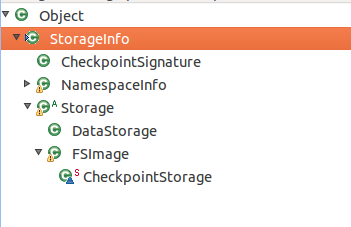
其中NamespaceInfo包含HDFS集群的一些信息,CheckpointSignature则用于标识名字节点元数据的检查,这两个类出现在HDFS节点间通信的远程接口中,分别应用于DataNode节点和NameNode节点通信的DatanodeProtocol接口和SecondNameNode节点和NameNode节点通信的NamespaceProtocol。StorageInfo包含了三个成员变量,类的定义和成员变量的代码如下:
public class StorageInfo {
/**是一个负整数,保存了HDFS存储系统信息结构的版本号**/
public int layoutVersion; // Version read from the stored file.
/**存储系统的唯一标识符**/
public int namespaceID; // namespace id of the storage
/**该信息的创建时间**/
public long cTime; // creation timestamp
} |
这三个成员变量分别对应这VERSION文件中的内容,在上文中说过VERSION文件是一个Java属性文件,包含了HDFS的版本信息。DataNode节点的current目录中有一个VERSION文件,来标识当前DataNode节点的版本信息,NameNode节点同样有一个VERSION节点,来标识NameNode节点的版本信息,但是DataNode节点目录中的VERSION文件比NameNode节点目录中的VERSION文件多一个storageID属性,它表示一个数据节点在集群中的唯一标识,VERSION文件中的属性及其意义如下:
namespaceID:存储系统的标识
layoutVersion:HDFS存储系统信息结构的版本号
ctime:存储系统创建时间
storageType:表示节点类型
StorageInfo类中的三个成员变量分别对应上述的namespaceID、layoutVersion和ctime。
StorageInfo的子类Storage是一个抽象类,它为数据节点、名字节点等提供通用的存储服务,在Storage类中有一个内部类StorageDirectory类,一个Storage对象管理着多个StorageDirectory对象,在Storage中用成员变量storageDirs表示,它是一个ArrayList<StorageDirectory>类型的变量。Storage类提供类大量的常量和方法用于为HDFS提供存储服务,它还有一个内部类DirIterator,用于对storageDirs进行迭代,来处理每一个SotrageDirectory对象。Storage类还有一个成员变量storageType,用于标识当前的节点类型,是NameNode还是DataNode。
关于Storage重点要分析的是StorageDirectory类,它提供了存储目录上的一些通用操作,其定义和成员变量代码如下:
public class StorageDirectory {
/**存储目录的根**/
File root; // root directory
/**使用的是独用文件锁**/
FileLock lock; // storage lock
/**目录对应的类型,即存储空间的类型**/
StorageDirType dirType; // storage dir type
} |
root标识保存存储目录的根目录,dirType标识目录的类型,StorageDirType是一个枚举类型有四个值,分别是UNDEFINED、IMAGE、EDITS、IMAGE_AND_EDITS,其意义分别是:
UNDEFINED:为定义;
IMAGE:存储fsimage
EDITS:存储edits
IMAGE_AND_EDITS:存储fsimage和edits
fsimage和edits是NameNode节点的镜像和编辑日志文件,由于NameNode节点在运行时必须记录下其每个时刻的一个状态,然后存储在一个镜像文件中,以便出故障之后可以从镜像中恢复,但是每个时刻都生成一个镜像文件就会得不偿失,导致NameNode节点大量的资源用于生成镜像文件,所以引入编辑日志(edits),记录生成镜像文件之后的一段时间对NameNode节点所做的更改,当生成一定量的编辑日志之后,再利用SecondNameNode节点生成镜像文件。所以就有了上面的几个枚举值的定义,IMAGE标识这个目录只存储镜像(fsimage),EDITS标识这个目录值存储编辑日志(edits),IMAGE_AND_EDITS表示存储镜像和编辑日志。StorageDirectory类中的lock成员变量用于对目录进行加锁,上面分析数据节点的目录结构时,有一个in_use.lock文件,这个文件就是在数据节点运行时,由tryLock()方法创建的,并且lock表示的锁是一个独占锁。
Storage类的子类DataStorage类对DataNode节点的存储空间的生存期进行管理,它有三个常量和一个变量,其类定义代码为:
public class DataStorage extends Storage {
// Constants
final static String BLOCK_SUBDIR_PREFIX = "subdir";
final static String BLOCK_FILE_PREFIX = "blk_";
final static String COPY_FILE_PREFIX = "dncp_";
private String storageID;
} |
由上面的代码可以看出subdir即为目录的前缀,blk是文件块的前缀,dncp是数据节点进行数据块扫描时用到的文件名前缀。storageID则对应DataNode节点的VERSION文件中的storageID属性,标识当前DataNode节点在HDFS中的唯一标识。在DataStorage类中有一个format()方法,数据节点在第一次启动时调用这个方法创建存储目录。
与数据节点相关的类基本上就是上面分析的几个类,下面结合DataStorage类中的方法doUpgrade,doRollback,doFinalize来分析数据节点中的目录的几个状态。
数据节点的升级、回滚与提交
在Storage类中使用枚举类StorageState定义类目录的10中状态,其定义代码如下:
/**
* 定义了存储空间的可能状态,升级,升级提交或升级回滚等状态
*
*/
public enum StorageState {
/**以非FORMAT选项启动时,目录不存在,或者目录不可写,
或者配置项对应的路径是个文件,而非目录等,都可以认为存储空间不存在**/
NON_EXISTENT,
/**以FORMAT选项启动,同时目录不存在,这是存储空间状态为没有格式化**/
NOT_FORMATTED,
/**“previous.tmp”目录存在,同时“current”目录下的"VERSION"存在,可完成升级状态**/
COMPLETE_UPGRADE,
/**“previous.tmp”目录存在,“current/VERSION”文件不存在,存储空间应该从升级过程中恢复**/
RECOVER_UPGRADE,
/**存在“finalized.tmp”目录,存储空间可以继续执行提交升级**/
COMPLETE_FINALIZE,
/**存在“previous.tmp”目录,同时“current/VERSION”文件存在,可以继续执行提交回滚**/
COMPLETE_ROLLBACK,
/**存在“previsous.tmp”目录,“current”目录下“VERSION”文件不存在,
需要中断升级提交,恢复到上一个状态**/
RECOVER_ROLLBACK,
/**应用于名字节点,用于导入元数据检查,存储空间可完成检查点导入**/
COMPLETE_CHECKPOINT,
/**应用与名字节点,用于导入元数据检查,需要恢复导入检查点前状态**/
RECOVER_CHECKPOINT,
/**目录处于正常工作状态**/
NORMAL;
} |
枚举值在代码中已经注释了,不再重复。在文章Hadoop源码分析之NameNode的启动与停止中已经分析到了HDFS的启动参数,这些启动参数都定义在枚举类StartupOption中,如果HDFS以参数update启动,那么会执行到DataStorage.doUpgrade()方法,对HDFS的数据节点进行升级,先来看DataStorage.doUpgrade()方法,方法代码如下:
/**
* Move current storage into a backup directory,
* and hardlink all its blocks into the new current directory.
* 数据节点升级
* @param sd storage directory
* @throws IOException
*/
void doUpgrade(StorageDirectory sd,
NamespaceInfo nsInfo
) throws IOException {
LOG.info("Upgrading storage directory " + sd.getRoot()
+ ".\n old LV = " + this.getLayoutVersion()
+ "; old CTime = " + this.getCTime()
+ ".\n new LV = " + nsInfo.getLayoutVersion()
+ "; new CTime = " + nsInfo.getCTime());
// enable hardlink stats via hardLink object instance
HardLink hardLink = new HardLink();
File curDir = sd.getCurrentDir();//获取当前版本目录
File prevDir = sd.getPreviousDir();//上一版本目录,目录名为“previous”
//检查current目录是否存在,如果不存在就不需要升级
assert curDir.exists() : "Current directory must exist.";
// delete previous dir before upgrading,删除该目录相当于提交了上一次升级,
同时保证了HDFS最多保留前一版本的数据要求
if (prevDir.exists())
deleteDir(prevDir);
//tempDir目录不应该存在,tempDir表示上一版本的临时目录,目录名为“previous.tmp”
File tmpDir = sd.getPreviousTmp();
assert !tmpDir.exists() : "previous.tmp directory must not exist.";
// rename current to tmp,目录改名,current->previous.tmp
rename(curDir, tmpDir);
// hardlink blocks,为数据块和数据块校验信息文件建立硬链接
linkBlocks(tmpDir, curDir, this.getLayoutVersion(), hardLink);
// write version file,写新的VERSION文件
this.layoutVersion = FSConstants.LAYOUT_VERSION;
assert this.namespaceID == nsInfo.getNamespaceID() :
"Data-node and name-node layout versions must be the same.";
this.cTime = nsInfo.getCTime();
sd.write();//将数据写入VERSION文件
// rename tmp to previous,目录改名,previous.tmp->previous
rename(tmpDir, prevDir);
LOG.info( hardLink.linkStats.report());
LOG.info("Upgrade of " + sd.getRoot()+ " is complete");
}
|
枚举值在代码中已经注释了,不再重复。在文章Hadoop源码分析之NameNode的启动与停止中已经分析到了HDFS的启动参数,这些启动参数都定义在枚举类StartupOption中,如果HDFS以参数update启动,那么会执行到DataStorage.doUpgrade()方法,对HDFS的数据节点进行升级,先来看DataStorage.doUpgrade()方法,方法代码如下:
/**
* Move current storage into a backup directory,
* and hardlink all its blocks into the new current directory.
* 数据节点升级
* @param sd storage directory
* @throws IOException
*/
void doUpgrade(StorageDirectory sd,
NamespaceInfo nsInfo
) throws IOException {
LOG.info("Upgrading storage directory " + sd.getRoot()
+ ".\n old LV = " + this.getLayoutVersion()
+ "; old CTime = " + this.getCTime()
+ ".\n new LV = " + nsInfo.getLayoutVersion()
+ "; new CTime = " + nsInfo.getCTime());
// enable hardlink stats via hardLink object instance
HardLink hardLink = new HardLink();
File curDir = sd.getCurrentDir();//获取当前版本目录
File prevDir = sd.getPreviousDir();//上一版本目录,目录名为“previous”
//检查current目录是否存在,如果不存在就不需要升级
assert curDir.exists() : "Current directory must exist.";
// delete previous dir before upgrading,删除该目录相当于提交了上一次升级,
同时保证了HDFS最多保留前一版本的数据要求
if (prevDir.exists())
deleteDir(prevDir);
//tempDir目录不应该存在,tempDir表示上一版本的临时目录,目录名为“previous.tmp”
File tmpDir = sd.getPreviousTmp();
assert !tmpDir.exists() : "previous.tmp directory must not exist.";
// rename current to tmp,目录改名,current->previous.tmp
rename(curDir, tmpDir);
// hardlink blocks,为数据块和数据块校验信息文件建立硬链接
linkBlocks(tmpDir, curDir, this.getLayoutVersion(), hardLink);
// write version file,写新的VERSION文件
this.layoutVersion = FSConstants.LAYOUT_VERSION;
assert this.namespaceID == nsInfo.getNamespaceID() :
"Data-node and name-node layout versions must be the same.";
this.cTime = nsInfo.getCTime();
sd.write();//将数据写入VERSION文件
// rename tmp to previous,目录改名,previous.tmp->previous
rename(tmpDir, prevDir);
LOG.info( hardLink.linkStats.report());
LOG.info("Upgrade of " + sd.getRoot()+ " is complete");
}
|
在doUpgrade()方法中,先获取到当前的current目录,然后获取名为previous的上一个版本的目录,如果previous目录存在,则进行删除,因为HDFS最多保存两个版本的文件系统,升级成功之后,当前的current目录就变成previous目录,并且会生成新版本的current目录。然后将当前的current目录改名为preivious.tmp目录,创建current目录,为current将previous.tmp目录中的文件通过硬链接添加到current目录中,保存当前的版本信息以便生成VERSION文件,最后将previous.tmp目录改名为previous目录。在这个过程中有一个previous.tmp,先将当前的current目录改名为previous.tmp目录,再同过硬链接为新创建的current目录添加文件,最后将previous.tmp目录改名为previous,既然这样为什么不将前一版本的current目录直接改名为previous,还要在中间加一个previous.tmp目录的过程?因为在doUpgrade()方法执行的过程中节点可能会出故障,假设节点出故障的时刻,已经将当前版本的current目录改名为previous.tmp目录,生成current目录,但是没有将previous.tmp目录,那么当数据节点再次启动时它就可以根据previous.tmp目录来知道当前的状态是在升级的过程中出故障,这样就可以确定当前节点的状态。但是如果没有previous.tmp目录的过程,直接将current目录改名为previous,即使数据节点出故障了,数据节点下次启动时,也不能确定数据节点的停止的是由于出故障了还是正常停止的。
doRollback()方法主要用于对HDFS的升级进行回滚。进行升级回滚时,节点中有previous目录和current目录,假设回滚过程不出故障,那么可以直接删除current目录,再将previous目录直接改名为current目录,但是考虑到出故障的情况,类似doUpgrade()方法中采取的方式,先将current目录改名为removed.tmp目录,再将previous目录改名为current目录,最后删除removed.tmp目录。
doFinalize()方法对HDFS的升级进行提交,提交之后,HDFS中只有一个最新版本。假设提交过程不出故障,那么直接删除previous目录即可,但是考虑到出故障的情况,类似doUpgrade()方法中采取的方式,先将previous目录改名为finalized.tmp目录,然后删除finalized.tmp目录。
在Storage类中有一个方法analyzeStorage,它的作用是检查文件目录的状态,即确定当前给定的目录是StorageState枚举类中中定义了目录的十种状态中的哪一种状态,该方法就是根据这些状态之间的转换关系判断当前目录所处的状态,方法代码如下:
/**
* Check consistency of the storage directory.
* 检查文件目录的状态,在{@link StorageState}中定义了目录的十种状态,该方法可以根据这些状态之间的转换
* 关系判断当前目录所处的状态
* @param startOpt a startup option.
*
* @return state {@link StorageState} of the storage directory
* @throws InconsistentFSStateException if directory state is not
* consistent and cannot be recovered.
* @throws IOException
*/
public StorageState analyzeStorage(StartupOption startOpt) throws IOException {
assert root != null : "root is null";
String rootPath = root.getCanonicalPath();
try { // check that storage exists
//以非FORMAT选项启动时,目录不存在,或者目录不可写,或
者配置项对应路径是个文件,而非目录,都可以认为存储空间不存在
if (!root.exists()) {//如果根目录不存在
// storage directory does not exist
if (startOpt != StartupOption.FORMAT) {
LOG.info("Storage directory " + rootPath + " does not exist");
return StorageState.NON_EXISTENT;
}
LOG.info(rootPath + " does not exist. Creating...");
if (!root.mkdirs())//创建根目录
throw new IOException("Cannot create directory " + rootPath);
}
// or is inaccessible,访问不了
if (!root.isDirectory()) {
LOG.info(rootPath + "is not a directory");
return StorageState.NON_EXISTENT;
}
//不可写
if (!root.canWrite()) {
LOG.info("Cannot access storage directory " + rootPath);
return StorageState.NON_EXISTENT;
}
} catch(SecurityException ex) {
LOG.info("Cannot access storage directory " + rootPath, ex);
return StorageState.NON_EXISTENT;
}
this.lock(); // lock storage if it exists
//只要是以FORMAT启动,都认为是NOT_FORMATE状态
if (startOpt == HdfsConstants.StartupOption.FORMAT)
return StorageState.NOT_FORMATTED;
if (startOpt != HdfsConstants.StartupOption.IMPORT) {
//make sure no conversion is required
checkConversionNeeded(this);//检查hadoop的版本,如果是hadoop0.13版本,
那么在根目录下会存在image目录,否则这个目录无用
}
// check whether current directory is valid
File versionFile = getVersionFile();//获取VERSION文件
boolean hasCurrent = versionFile.exists();
// check which directories exist
boolean hasPrevious = getPreviousDir().exists();//“previous”文件夹
boolean hasPreviousTmp = getPreviousTmp().exists();//“previous.tmp”文件夹
boolean hasRemovedTmp = getRemovedTmp().exists();//"removed.mp"文件夹
boolean hasFinalizedTmp = getFinalizedTmp().exists();//“finalized.tmp”文件夹
boolean hasCheckpointTmp = getLastCheckpointTmp().exists();//checkpo
if (!(hasPreviousTmp || hasRemovedTmp
|| hasFinalizedTmp || hasCheckpointTmp)) {//没有tmp文件夹
// no temp dirs - no recovery
if (hasCurrent)//没有tmp文件夹,那么就处于NORMAL状态
return StorageState.NORMAL;
if (hasPrevious)//有previous文件夹,没有current文件夹
throw new InconsistentFSStateException(root,
"version file in current directory is missing.");
return StorageState.NOT_FORMATTED;//current目录不存在,
没有*.tmp目录,且没有previous目录,则是NOT_FORMAT状态
}
//同时存在着至少两个tmp文件夹,则出现错误
if ((hasPreviousTmp?1:0) + (hasRemovedTmp?1:0)
+ (hasFinalizedTmp?1:0) + (hasCheckpointTmp?1:0) > 1)
// more than one temp dirs
throw new InconsistentFSStateException(root,
"too many temporary directories.");
// # of temp dirs == 1 should either recover or complete a transition
if (hasCheckpointTmp) {//名字节点元数据检查点
return hasCurrent ? StorageState.COMPLETE_CHECKPOINT
//如果有lastcheckpoint.tmp目录,且有current目录,完成检查点导入
: StorageState.RECOVER_CHECKPOINT;
//如果有lastcheckpoint.tmp目录,且没有current目录,就是没有完成检查点导入
}
if (hasFinalizedTmp) {//有finalized.tmp文件夹
if (hasPrevious)//有previous文件夹,但是finalized.tmp文件夹是previous在提交过程中改名的文件夹,
这两个文件夹同时存在说明出现问题
throw new InconsistentFSStateException(root,
STORAGE_DIR_PREVIOUS + " and " + STORAGE_TMP_FINALIZED
+ "cannot exist together.");
return StorageState.COMPLETE_FINALIZE;//有finalized.tmp文件夹,
没有previous文件夹,说明升级完成并且提交
}
if (hasPreviousTmp) {//有previous.tmp文件夹
if (hasPrevious)
throw new InconsistentFSStateException(root,
STORAGE_DIR_PREVIOUS + " and " + STORAGE_TMP_PREVIOUS
+ " cannot exist together.");
if (hasCurrent)//有previous.tmp文件夹和current文件夹,则就是完成升级状态
return StorageState.COMPLETE_UPGRADE;
return StorageState.RECOVER_UPGRADE;
//有previous.tmp文件夹没有current文件夹,说明升级过程中出现问题而中断
}
//没有执行if (!(hasPreviousTmp || hasRemovedTmp
// || hasFinalizedTmp || hasCheckpointTmp)) {
这行代码说明至少存在一个tmp文件夹,如果存在一个finalized.tmp或者
//previous.tmp文件夹或者checkpoint.tmp文件夹那么在上面已经返回,
执行到这里说明只存在removed.tmp文件夹,说明是回滚过
//程中出现问题,所以removed.tmp文集夹一定存在
assert hasRemovedTmp : "hasRemovedTmp must be true";
if (!(hasCurrent ^ hasPrevious))
throw new InconsistentFSStateException(root,
"one and only one directory " + STORAGE_DIR_CURRENT
+ " or " + STORAGE_DIR_PREVIOUS
+ " must be present when " + STORAGE_TMP_REMOVED
+ " exists.");
if (hasCurrent)//有removed.tmp和current文件夹,回滚已经完成,tmp文件还没删除
return StorageState.COMPLETE_ROLLBACK;
return StorageState.RECOVER_ROLLBACK;//回滚过程没有完成
} |
方法代码比较常,代码执行过程的在注释中已经给出,比较好理解,就不再分析了。
总结
在上面的分析中简单的分析了数据节点中目录结构组成,类的继承结构,和数据节点的目录所处的状态,其中类和方法只是简单的涉及到了,具体的代码分析,将在以后用到的时候分析,这篇文章的分析主要是为了引出目录的状态及其代表的意义。
|


