Tair是由淘宝网自主开发的Key/Value结构数据存储系统,在淘宝网有着大规模的应用。您在登录淘宝、查看商品详情页面或者在淘江湖和好友“捣浆糊”的时候,都在直接或间接地和Tair交互。
Tair的功能
Tair是一个Key/Value结构数据的解决方案,它默认支持基于内存和文件的两种存储方式,分别和我们通常所说的缓存和持久化存储对应。
Tair除了普通Key/Value系统提供的功能,比如get、put、delete以及批量接口外,还有一些附加的实用功能,使得其有更广的适用场景,包括:
1、Version支持>
2、原子计数器
3、Item支持
Version支持
Tair中的每个数据都包含版本号,版本号在每次更新后都会递增。这个特性有助于防止由于数据的并发更新导致的问题。
比如,系统有一个value为“a,b,c”,A和B同时get到这个value。A执行操作,在后面添加一个d,value为“a,b,c,d”。B执行操作添加一个e,value为”a,b,c,e”。如果不加控制,无论A和B谁先更新成功,它的更新都会被后到的更新覆盖。
Tair无法解决这个问题,但是引入了version机制避免这样的问题。还是拿刚才的例子,A和B取到数据,假设版本号为10,A先更新,更新成功后,value为”a,b,c,d”,与此同时,版本号会变为11。当B更新时,由于其基于的版本号是10,服务器会拒绝更新,从而避免A的更新被覆盖。B可以选择get新版本的value,然后在其基础上修改,也可以选择强行更新。
原子计数器
Tair从服务器端支持原子的计数器操作,这使得Tair成为一个简单易用的分布式计数器。
Item支持
Tair还支持将value视为一个item数组,对value中的部分item进行操作。比如有个key的value为[1,2,3,4,5],我们可以只获取前两个item,返回[1,2],也可以删除第一个item,还支持将数据删除,并返回被删除的数据,通过这个接口可以实现一个原子的分布式FIFO的队列。
Tair的内部结构
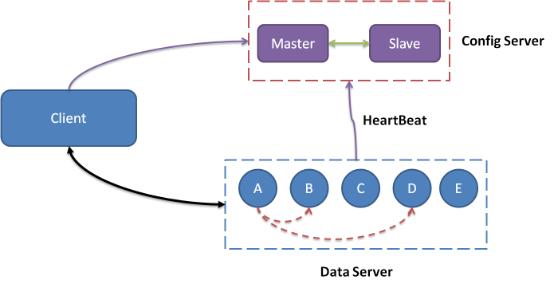
图 1 Tair整体架构图
一个Tair集群主要包括client、configserver和dataserver 3个模块。Configserver通过和dataserver的心跳(HeartBeat)维护集群中可用的节点,并根据可用的节点,构建数据的在集群中的分布信息(见下文的对照表)。Client在初始化时,从configserver处获取数据的分布信息,根据分布信息和相应的dataserver交互完成用户的请求。Dataserver负责数据的存储,并按照configserver的指示完成数据的复制和迁移工作。
数据的分布
分布式系统需要解决的一个重要问题便是决定数据在集群中的分布策略,好的分布策略应该能将数据均衡地分布到所有节点上,并且还应该能适应集群节点的变化。Tair采用的对照表方式较好地满足了这两点。
对照表的行数是一个固定值,这个固定值应该远大于一个集群的物理机器数,由于对照表是需要和每个使用Tair的客户端同步的,所以不能太大,不然同步将带来较大的开销。我们在生产环境中的行数一般为1023
。
对照表简介
下面我们看对照表是怎么完成数据的分布功能的,为了方便,我们这里假设对照表的行数为6。最简单的对照表包含两列,第一列为hash值,第二列为负责该hash值对应数据的dataserver节点信息。比如我们有两个节点192.168.10.1和192.168.10.2,那么对照表类似:
0
192.168.10.1
1
192.168.10.2
2
192.168.10.1
3
192.168.10.2
4
192.168.10.1
5
192.168.10.2 |
当客户端接收到请求后,将key的hash值和6取模,然后根据取模后的结果查找对照表。比如取模后的值为3,客户端将和192.168.10.2通信。
对照表如何适应节点数量的变化
我们假设新增了一个节点――192.168.10.3,当configserver发现新增的节点后,会重新构建对照表。构建依据以下两个原则:
数据在新表中均衡地分布到所有节点上。
尽可能地保持现有的对照关系。
更新之后的对照表如下所示:
0
192.168.10.1
1
192.168.10.2
2
192.168.10.1
3
192.168.10.2
4
192.168.10.3
5
192.168.10.3 |
这里将原本由192.168.10.1负责的4和192.168.10.2负责的5交由新加入的节点192.168.10.3负责。
如果是节点不可用,则相当于上述过程反过来,道理是一样的。
多备份的支持
Tair支持自定义的备份数,比如你可以设置数据备份为2,以提高数据的可靠性。对照表可以很方便地支持这个特性。我们以行数为6,两个节点为例,2个备份的对照表类似:
0
192.168.10.1
192.168.10.2
1
192.168.10.2
192.168.10.1
2
192.168.10.1
192.168.10.2
3
192.168.10.2
192.168.10.1
4
192.168.10.1
192.168.10.2
5
192.168.10.2
192.168.10.1 |
第二列为主节点的信息,第三列为辅节点信息。在Tair中,客户端的读写请求都是和主节点交互,所以如果一个节点不做主节点,那么它就退化成单纯的备份节点。因此,多备份的对照表在构建时需要尽可能保证各个节点作为主节点的个数相近。
当有节点不可用时,如果是辅节点,那么configserver会重新为其指定一个辅节点,如果是持久化存储,还将复制数据到新的辅节点上。如果是主节点,那么configserver首先将辅节点提升为主节点,对外提供服务,并指定一个新的辅节点,确保数据的备份数。
多机架和多数据中心的支持
对照表在构建时,可以配置将数据的备份分散到不同机架或数据中心的节点上。Tair当前通过设置一个IP掩码来判断机器所属的机架和数据中心信息。
比如你配置备份数为3,集群的节点分布在两个不同的数据中心A和B,则Tair会确保每个机房至少有一份数据。假设A数据中心包含两份数据时,Tair会尽可能将这两份数据分布在不同机架的节点上。这可以减少整个数据中心或某个机架发生故障是数据丢失的风险。
轻量级的configserver
从Tair的整体架构图上看,configserver很类似传统分布式集群中的中心节点。整个集群服务都依赖于configserver的正常工作。
但Tair的configserver却是一个轻量级的中心节点,在大部分时候,configserver不可用对集群的服务是不造成影响的。
Tair用户和configserver的交互主要是为了获取数据分布的对照表,当client获取到对照表后,会cache这张表,然后通过查这张表决定数据存储的节点,所以请求不需要和configserver交互,这使得Tair对外的服务不依赖configserver,所以它不是传统意义上的中心节点。
configserver维护的对照表有一个版本号,每次新生成表,该版本号都会增加。当有数据节点状态发生变化(比如新增节点或者有节点不可用了)时,configserver会根据当前可用的节点重新生成对照表,并通过数据节点的心跳,将新表同步给数据节点。
当客户端请求数据节点时,数据节点每次都会将自己的对照表的版本号放入response中返回给客户端,客户端接收到response后,会将数据节点返回的版本号和自己的版本号比较,如果不相同,则主动和configserver通信,请求新的对照表。
所以客户端也不需要和configserver保持心跳,以便及时地更新对照表。这使得在正常的情况下,客户端不需要和configserver通信,即使configserver不可用了,也不会对整个集群的服务造成大的影响。
仅有当configserver不可用,此时有客户端需要初始化,那么客户端将取不到对照表信息,这将使得客户端无法正常工作。
DataServer内部结构
DataServer负责数据的物理存储,并根据configserver构建的对照表完成数据的复制和迁移工作。DataServer具备抽象的存储引擎层,可以很方便地添加新存储引擎。DataServer还有一个插件容器,可以动态地加载/卸载插件。
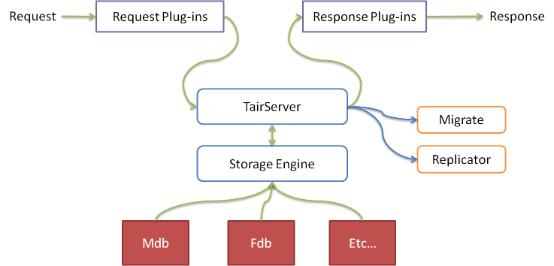
图 2 DataServer的内部结构示意图
抽象的存储引擎层
Tair的存储引擎有一个抽象层,只要满足存储引擎需要的接口,便可以很方便地替换Tair底层的存储引擎。比如你可以很方便地将bdb、tc甚至MySQL作为Tair的存储引擎,而同时使用Tair的分布方式、同步等特性。
Tair默认包含两个存储引擎:mdb和fdb。
mdb是一个高效的缓存存储引擎,它有着和memcached类似的内存管理方式。mdb支持使用share
memory,这使得我们在重启Tair数据节点的进程时不会导致数据的丢失,从而使升级对应用来说更平滑,不会导致命中率的较大波动。
fdb是一个简单高效的持久化存储引擎,使用树的方式根据数据key的hash值索引数据,加快查找速度。索引文件和数据文件分离,尽量保持索引文件在内存中,以便减小IO开销。使用空闲空间池管理被删除的空间。
自动的复制和迁移
为了增强数据的安全性,Tair支持配置数据的备份数。比如你可以配置备份数为3,则每个数据都会写在不同的3台机器上。得益于抽象的存储引擎层,无论是作为cache的mdb,还是持久化的fdb,都支持可配的备份数。
当数据写入一个节点(通常我们称其为主节点)后,主节点会根据对照表自动将数据写入到其他备份节点,整个过程对用户是透明的。
当有新节点加入或者有节点不可用时,configserver会根据当前可用的节点,重新build一张对照表。数据节点同步到新的对照表时,会自动将在新表中不由自己负责的数据迁移到新的目标节点。迁移完成后,客户端可以从configserver同步到新的对照表,完成扩容或者容灾过程。整个过程对用户是透明的,服务不中断。
插件容器
Tair还内置了一个插件容器,可以支持热插拔插件。
插件由configserver配置,configserver会将插件配置同步给各个数据节点,数据节点会负责加载/卸载相应的插件。
插件分为request和response两类,可以分别在request和response时执行相应的操作,比如在put前检查用户的quota信息等。
插件容器也让Tair在功能方便具有更好的灵活性。
Tair的未来
我们将Tair开源,希望有更多的用户能从我们开发的产品中受益,更希望依托社区的力量,使Tair有更广阔的发展空间。
Tair开源后,有很多用户关心我们是否会持续维护这个项目。我们将Tair开源后,淘宝内部已经不再有私有的Tair分支,所有的开发和应用都基于开源分支。Tair在淘宝有非常广的应用,我们内部有一个团队,专门负责Tair的开发和维护,相信我们会和社区一起,将Tair越做越好。
有很多用户在淘宝开源平台上申请加入Tair项目,加入项目在我们的开源平台上意味着成为项目的提交者,可以向代码库直接提交代码。所以我们暂时还没有批准外部用户加入,我们将在大家对Tair有更深入的了解后和社区一起决定是否批准加入项目的申请,在此之前,如果你有对代码的改进,欢迎使用patch的方式提交给我们,我们将在review后决定是否合并到代码库。
希望我们能和社区一起,将Tair做成一个真正对大家都有帮助的项目。 |


