1概述
本文档是Hadoop集群的运维文档,提供了Hadoop集群安装方法和部署,
以及对集群的监控。
1.1 背景
Hadoop是开源的、分布式的数据存储和计算基础框架,其核心包含HDFS和MapReduce等。
HBase是基于Hadoop的HDFS之上的分布式列存储数据库, 优势在处理大表。HBase对Hadoop进行了无缝的衔接,使得可以在Hadoop的MapReduce框架中直接访问HBase中的数据。
Hive是基于Hadoop的数据仓库,它提供类SQL的HQL语句,方便对数据的访问。
1.2 名词解释
Hadoop,Apache的开源的分布式的框架
HDFS,Hadoop的分布式文件系统。
NameNode,Hadoop HDFS 元数据主节点服务器,负责保存DataNode文件元数据存储信息。
DataNode,Hadoop HDFS的数据节点,负责存储数据。
JobTracker,Hadoop的MapReduce调度器,负责计算任务的分配和调度,并且跟踪任务的进度。
TaskTracker,Hadoop的MapReduce任务的执行程序,向JobTracker回报任务执行进度。
HBase,Apache的建立在HDFS之上的,面向大表,提供实时、随机读写的开源的分布式数据库。
2 Hadoop集群搭建
2.1 硬件配置
内存16G
硬盘500G
CPU2 Intel(R) Pentium(R) CPU G640 @
2.80GHz 双核
机器数目4台
2.2 规划
我们对着4台机器进行了规划,让JobTracker和NameNode以及SecondaryNameNode运行同一台机器上,TaskTracker和DataNode运行在同一台机器上。并且为每台机器制定了IP和域名映射。如表所示:
127.0.0.1 localhost
192.168.1.164 hadoop.online.master
192.168.1.165 hadoop.online.slave1
192.168.1.166 hadoop.online.slave2
192.168.1.167 hadoop.online.slave3 |
更改每台机器的机器名,如下表所示,让master运行JobTracker和NameNode以及SecondaryNamenode,其他slave运行DataNode和TaskTracker。
[hadoop@hadoop ~]$ hostname
hadoop.online.master |
2.3 Java安装
http://www.oracle.com/technetwork/java/javase/downloads/jdk6downloads-1902814.html处下载java1.6.0_43。
上传程序到四台机器。先卸载机器上默认安装的java程序
[hadoop@hadoop ~]$ rpm -qa |grep java|sudo xargs rpm -e --nodeps |
然后在/opt目录下执行
[hadoop@hadoop opt]$ ./jdk-6u43-linux-x64.bin |
/etc/profile添加java环境变量如下所示:
[hadoop@hadoop ~]$ tail -n 5 /etc/profile
export JAVA_HOME=/opt/jdk1.6.0_43
export ANT_HOME=/opt/apache-ant-1.9.0
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$ANT_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH |
执行Java -version 看java是否安装成功。
[hadoop@hadoop ~]$ java -version
java version "1.6.0_43"
Java(TM) SE Runtime Environment (build 1.6.0_43-b01)
Java HotSpot(TM) 64-Bit Server VM (build 20.14-b01, mixed mode) |
2.4 ssh的免密码登录
四台机器上俊运行ssh-keygen命令生成公钥对
[hadoop@hadoop ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): |
将四台机器的公钥都添加到authorized_keys中:
[hadoop@hadoop ~]$ cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh hadoop.online.slave1 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh hadoop.online.slave2 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh hadoop.online.slave3 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys |
改变authorized_keys读写权限:
[hadoop@hadoop ~]$ chmod 600 ~/.ssh/authorized_keys |
拷贝authorized_keys文件到另外三台机器:
[hadoop@hadoop ~]$ scp ~/.ssh/authorized_keys hadoop.online.slave1:~/.ssh |
最后,在master节点通过SSH对每个节点进行一次访问,以建立连接:
[hadoop@hadoop ~]$ ssh hadoop.online.slave1 date
Tue Sep 24 11:06:10 CST 2013 |
2.5 Hadoop-lzo的安装
安装lzo所需要软件包:gcc、ant、lzo、lzo编码/解码器,另外,还需要lzo-devel依赖
[hadoop@hadoop ~]$ sudo yum -y install lzo lzo-devel lzop |
下载并安装ant程序
http://ant.apache.org/bindownload.cgi,解压到/opt目录下,设置环境变量,如设置java变量处所示。
安装lzo-2.0.6
[hadoop@hadoop ~]$ wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
[hadoop@hadoop ~]$ tar zxvf lzo-2.06.tar.gz
[hadoop@hadoop ~]$ cd lzo-2.06
[hadoop@hadoop ~]$ ./configure --enable-shared
[hadoop@hadoop ~]$ make&&make install |
库文件被默认安装到了/usr/local/lib,我们需要进一步指定lzo库文件的路径,将/usr/local/lib/目录下的所有文件拷到/usr/lib64文件夹下。
安装hadoop-lzo
下载路径:https://github.com/kevinweil/hadoop-lzo,请点击zip下载,如图所示:
编译安装hadoop-lzo
[hadoop@hadoop opt]$ cd hadoop-lzo-master/
[hadoop@hadoop hadoop-lzo-master]$ export CFLAGS=-m64
[hadoop@hadoop hadoop-lzo-master]$ ant compile-native tar |
将hadoop-lzo-0.4.15.jar以及native库添加到hadoop的CLASSPATH中
[hadoop@hadoop hadoop-lzo-master]$ cp build/hadoop-lzo-0.4.15.jar /home/hadoop/hadoop-1.0.2/lib
[hadoop@hadoop hadoop-lzo-master]$ tar -cBf - -C build/native . |
tar -xBvf - -C /home/hadoop/hadoop-1.0.2/lib/native
[hadoop@hadoop hadoop-lzo-master]$ cp build/native/Linux-amd64-64/lib/*
/home/hadoop/hadoop-1.0.2/lib/native/Linux-amd64-64 |
设置环境变量.bash_profile 如图(hbase和hive后面会用到)所示:
export HADOOP_HOME=/home/hadoop/hadoop-1.0.2
export HBASE_HOME=/home/hadoop/hbase-0.94.0-security
export HIVE_HOME=/home/hadoop/hive-0.9.0
export JAVA_LIBRARY_PATH=/home/hadoop/hadoop-1.0.2/lib/native/Linux-amd64-64
export SQOOP_HOME=/home/hadoop/sqoop-1.4.2.bin__hadoop-1.0.0
PATH=$PATH:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=1
export PATH |
配置core-site.xml 增加:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.
apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.
compression.lzo.LzoCodec</value>
</property> |
配置mapred-site.xml 增加:
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property> |
2.6 安装、配置hadoop1.0.2
安装Hadoop下载hadoop-1.0.2: http://hadoop.apache.org/releases.html#Download将hadoop-1.0.2解压到home/hadoop/hadoop-1.0.2
配置Hadoop的环境变量, 设置hadoop-env.sh
这里主要是指定JAVA_HOME,如图所示:
# The java implementation to use. Required.
export JAVA_HOME=/opt/jdk1.6.0_43 |
设置core-site.xml,如图所示:
<configuration>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.
GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop.online.master:9571</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-1.0.2/datas/hadoop</value>
<description>a base for other temp directories</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.chechpoint.dir</name>
<value>/home/hadoop/hadoop-1.0.2/datas/hdfs/namesecondary</value>
<description>secondary data storage path</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>33554432</value>
</property>
<property>
<name>hadoop.logfile.count</name>
<value>10</value>
</property>
</configuration> |
设置hdfs-site.xml,如果所示:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hadoop-1.0.2/datas/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hadoop-1.0.2/datas/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.block.size</name>
<value>268435456</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.2/conf/excludes</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration> |
设置mapred-site.xml,如图所示:
<configuration>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop.online.master:9572</value>
</property>
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>-1</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>4</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>4</value>
</property>
<property>
<name>io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapred.reduce.parallel.copie</name>
<value>50</value>
</property>
<property>
<name>mapred.reduce.copy.backoff</name>
<value>8</value>
</property>
<property>
<name>mapred.reduce.slowstart.completed.maps</name>
<value>0.85</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xms1024m -Xmx1536m -XX:-UseGCOverheadLimit</value>
</property>
<property>
<name>mapred.min.split.size</name>
<value>536870912</value>
</property>
<property>
<name>io.sort.factor</name>
<value>30</value>
</property> |
设置masters和slaves,如图所示:
[hadoop@hadoop conf]$ more masters
hadoop.online.master
[hadoop@hadoop conf]$ more slaves
hadoop.online.slave1
hadoop.online.slave2
hadoop.online.slave3 |
建议将以上hadoop配置在一台机器上做好,然后scp到另外三台
3 HBASE集群环境搭建
3.1 规划与搭建
我们选择了4台机器来搭建HBase集群,具体是这样规划的:
HMaster:hadoop.online.master
RegionServer: hadoop.online.slave1
hadoop.online.slave2
hadoop.online.slave3
ZooKeeper: hadoop.online.slave1
hadoop.online.slave2 |
下载最新的稳定版本的HBase。http://www.apache.org/dyn/closer.cgi/hbase/,当前最新的稳定版本是hbase-0.94.5。我们开发环境中用了hbase-0.94.0-security。将hbase-0.94.0-security解压到/home/hadoop/hbase-0.94.0-security/
配置HBase环境变量:hbase-env.sh这里我们要设置JAVA_HOME
# The java implementation to use. Required.
export JAVA_HOME=/opt/jdk1.6.0_43 |
其次,由于我们使用的是HBase托管的ZooKeeper,因此要将最后一行的HBASE_MANAGES_ZK设置为true,
如果是使用独立的ZooKeeper,那就将此值设置为false。
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=true |
设置RegionServers,每行一个节点,如:
[hadoop@hadoop conf]$ more regionservers
hadoop.online.slave1
hadoop.online.slave2
hadoop.online.slave3 |
设置hbase-site.xml,如下图所示:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop.online.master:9571/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://hadoop.online.master</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.1.165,192.168.1.166</value>
</property>
<property>
<name>hbase.zookeeper.property.authProvider.1</name>
<value>org.apache.zookeeper.server.auth.SASLAuthenticationProvider</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hbase-0.94.0-security/zookeeper_data</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/hbase-0.94.0-sercurity/hbase_tmp</value>
</property>
<property>
<name>hbase.master.dns.interface</name>
<value>eth0</value>
</property>
<property>
<name>hbase.master.dns.nameserver</name>
<value>192.168.1.164</value>
</property>
<property>
<name>hbase.regionserver.dns.interface</name>
<value>eth0</value>
</property>
<property>
<name>hbase.regionserver.dns.nameserver</name>
<value>192.168.1.164</value>
</property>
</configuration> |
将以上配置复制到所有节点上。
格式化
/home/hadoop/hadoop-1.0.2/bin/hadoop namenode -format |
4 Hive搭建
相对Hadoop,和HBase,Hive的安装相对,简单的多。Hive其实只是Hadoop一个插件,提供了一个以类似SQL的DDL语句――HQL来访问Hadoop。Hive是建立在Hadoop的HDFS之上的,利用Hadoop的MapReduce计算框架进行计算。此外,Hive需要一个地方来存放它的元数据。它可以是默认的./metastore_db(在conf/hive-defualt.xml中指定),也可以是任何支持JPOX的数据库。
由于Hive只是一个访问Hadoop的接口,因此它不需要在所有节点都部署,如我们的开发环境,只在MASTER节点hadoop.online.master上开启了Hive服务。
接下来还是以我们的开发环境为例,进行Hive的部署,我们选择mysql来存储Hive的元数据。
4.1 环境搭建
1、搭建Hadoop集群请先参照“分布式Hadoop集群搭建和配置”这一章,搭建Hadoop集群。
2、下载安装Hivehttp://www.apache.org/dyn/closer.cgi/hive/当前稳定版本的Hive是0.90.0解压到/home/hadoop/hive-0.9.0
3、设置环境变量HIVE_HOME,使HIVE_HOME指向Hive的安装目录cd
//home/hadoop/hive-0.9.0export HIVE_HOME={{pwd}}
4、 然后添加$HIVE_HOME/bin到PATH变量$ export
PATH=$HIVE_HOME/bin:$PATH也可以将HIVE_HOME 和添加到PATH放在~/.bashrc中实现。
5、将Hadoop添加到PATH中
在运行Hive之前,先保证hadoop是在环境变量PATH中,或者执行命令:
export HADOOP_HOME=/home/hadoop/hadoop-1.0.2
6、在HDFS上创建/tmp和/user/hive/warehouse,并且更改为g+w权限
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $$HADOOP_HOME/bin/hadoop
fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop
fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod
g+w /user/hive/warehouse
设置元数据存放位置,我们将它放在运行在slave3上的mysql中。编辑conf/hive-site.sh,如图所示:
<configuration>
<!-- Hive Execution Parameters -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop.online.slave3/hivetest?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepass</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hadoop/hive-0.9.0/logs</value>
</property>
</configuration> |
在hadoop.online.slave3上新建mysql数据库
[hadoop@hadoop ~]$ sudo yum -y install mysql-server |
启动数据库并修改root密码
创建hivetest数据库,并授权,如下图所示
mysql> create database hivetest;
mysql > grant all privileges on hivetest.* to hive@’192.168.1.%’ identified by ‘hivepass’;
mysql > flush privileges; |
添加mysql驱动程序到hive程序lib库
cp mysql-connector-java-5.1.22-bin.jar /home/hadoop/hive-0.9.0/lib/ |
5 管理Hadoop集群
5.1 启动Hadoop集群
启动整个集群
[hadoop@hadoop ~]$ hadoop-1.0.2/bin/start-all.sh |
也可单独启动:
启动NameNode/home/hadoop/hadoop-1.0.2/bin/hadoop-daemon.shstartnamenode
启动JobTracker/home/hadoop/hadoop-1.0.2/bin/hadoop-daemon.sh
start jobtracker
启动SecondaryNameNode/home/hadoop/hadoop-1.0.2/bin/hadoop-daemon.shstart
secondarynamenode
启动DataNode/home/hadoop/hadoop-1.0.2/bin/hadoop-daemon.sh
start datanode
启动TaskTracker/home/hadoop/hadoop-1.0.2/bin/hadoop-daemon.sh
start tasktracker
通过web界面查看:
检查NameNode和DataNode运行是否正常:http://hadoop.online.master:50070
检查JobTracker和TaskTracker是否运行正常 通过example来检查集群是否运行成功
[hadoop@hadoop ~]$ hadoop jar hadoop-1.0.2/hadoop-examples-1.0.2.jar pi 10 100 |
结果如下所示:
13/09/24 13:21:05 INFO mapred.JobClient: Virtual memory (bytes) snapshot=36923928576
13/09/24 13:21:05 INFO mapred.JobClient: Map output records=20
Job Finished in 52.28 seconds
Estimated value of Pi is 3.14800000000000000000 |
通过进程查看
slave上:有TaskTracker和DataNode两个进程(两者跑在同一个节点上)
[hadoop@hadoop ~]$ jps
9616 TaskTracker
9514 DataNode |
在master上,有NameNode、JobTracker两个进程(两者运行在同一个物理节点上)
[hadoop@hadoop ~]$ jps
30199 Jps
10245 NameNode
16955 RunJar
24895 RunJar
10437 SecondaryNameNode
10537 JobTracker |
5.2 Hadoop集群增加删除节点
在新增节点时,注意将防火墙关闭。
5.2.1 新增节点
修改host修改NameNode上的host,添加新增节点的ip,并且将host复制分发到所有节点,
包括新增节点。
修改NameNode的配置文件conf/slaves在slaves上增加新增节点的ip,并且复制分发到所有节点,包括新增节点
在新增节点上开启服务,执行:hadoop-daemon.sh start
datanodehadoop-daemon.sh start tasktracker
均衡start-balancer.sh
5.2.2 删除节点
集群配置如果集群配置conf/hdfs-site.xml中没有配置dfs.hosts.exclude,则添加以下配置:
<property> <name>dfs.hosts.exclude</name><value>/data/soft/hadoop/conf/excludes</value></property> |
确定要下架的机器在dfs.hosts.exclude中指定的文件excludes中,添加要下架的机器,一行一个。如:hadoop.online.slave2hadoop.online.slave3
轻质集群重新加载配置hadoop dfsadmin -refreshNodes
等上上述过程结束时,要下架的机器就可以安全关机了,此时执行report可以看到整个过程已经完成。hadoop
dfsadmin -reportDecommission Status : Decommissioned
如果还在执行下架过程中,那么会显示:Decommission Status : Decommission
in progress
6 启动、停止Hive
启动hive服务hive --service hiveserver 指定端口号
&
启动web 接口hive --service hwi &
默认客户端方式启动hive --service cli
Tips:
Hive的三种启动方式,推荐只启动web和hiveserver即可。
停止Hive,直接kill掉相对应的进程即可。
6.1 验证Hive是否部署成功
6.1.1 通过web查看访问hadoop.online.master:9999/hwi/
如果Hive运行成功,我们可以点击左侧DATABASE中查看到数据库,以及数据库中的表。
7 集群的监控
我们使用Ganglia来对集群进行监控。Ganglia是一个监控服务器、集群的开源软件,能够用曲线图表现最近一个小时,最近一天,最近一周,最近一月,最近一年的服务器或者集群的cpu负载,内存,网络,硬盘等指标。
Ganglia的强大在于:ganglia服务端能够通过一台客户端收集到同一个网段的所有客户端的数据,ganglia集群服务端能够通过一台服务端收集到它下属的所有客户端数据。这个体系设计表示一台服务器能够通过不同的分层能够管理上万台机器。这个功能是其他mrtg,nagios,cacti所不能比拟。
我们把ganglia的服务端安装在 hadoop.online.master上,客户端安装在所有节点上。
7.1 服务器端和客户端安装
依赖包的安装
sudo yum -y install libconfuse-devel pcre-devel rrdtool-devel rrdtool apr-devel |
由于libconfuse-devel包不在仓库中,我们搭建了epel仓库(用过之后可删除)
sudo rpm -ivh epel-release-5-4.noarch.rpm |
Web服务器安装
sudo yum -y install httpd php gd php-gd |
创建ganglia程序
rpmbuild -tb ganglia-web-3.5.0.tar.gz
rpmbuild -tb ganglia-3.5.0.tar.gz |
在/usr/src/redhat/RPMS目录下的x86_64和noarch,程序如图所示:
[root@hadoop x86_64]# ll
total 748
-rw-r--r-- 1 root root 396176 Apr 11 11:38 ganglia-debuginfo-3.5.0-1.x86_64.rpm
-rw-r--r-- 1 root root 49592 Apr 11 11:38 ganglia-devel-3.5.0-1.x86_64.rpm
-rw-r--r-- 1 root root 40172 Apr 11 11:38 ganglia-gmetad-3.5.0-1.x86_64.rpm
-rw-r--r-- 1 root root 115276 Apr 11 11:38 ganglia-gmond-3.5.0-1.x86_64.rpm
-rw-r--r-- 1 root root 107936 Apr 11 11:38 ganglia-gmond-modules-python-3.5.0-1.x86_64.rpm
-rw-r--r-- 1 root root 43076 Apr 11 11:38 libganglia-3.5.0-1.x86_64.rpm |
安装以上所有程序
配置服务器端/etc/ganglia/gmetad.conf
添加数据源,所有的四台机器都加上
data_source "hadooponline" 192.168.1.164:8649 192.168.1.165:8649 192.168.1.166:8649
192.168.1.167:8649 |
修改gridname
gridname "hadoop online status" |
配置客户端/etc/ganglia/gmond.conf
修改online名称,和服务端相同
online {
name = "hadooponline"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
} |
配置acl,只允许和服务器通信
tcp_accept_channel {
port = 8649
acl{
default ="deny"
access{
ip= 192.168.1.164
mask = 32
action = "allow"
}
}
} |
拷贝客户端程序到另三台配置文件同上
修改httpd.conf 文件,如下图所示:
DirectoryIndex index.php index.html index.html.var |
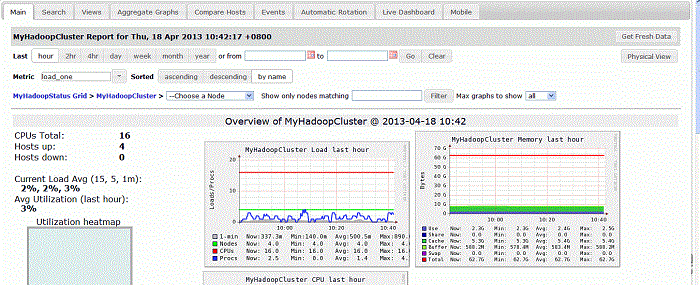
启动ganglia服务器和客户端,以及http服务器
通过页面访问http://192.168.1.164/ganglia如下图所示
|


