|
1. hive是针对什么问题提出的? 之前有什么解决方案吗?
超大结构化数据集,超出了一般MPP 的存储能力。
MPP海量并行处理数据库的强项在于CPU,实时处理能力强,但其空间比较紧张;而hadoop的存储能强,但cpu的实时处理能力比较弱。Hive是一个基于hadoop的数据仓库。
所以,二者是一个互补的关系。并且,逐渐的,二者会相互融合。
2. hive在数据类型上与普通的SQL有什么区别?
hive除了支持普通的Integer(从8字节到1字节)、Float(float与double)、String
内置类型外
hive还支持 Map、Structure、List,这些复杂的数据类型。
如 list<map<string, struct<p1:int,
p2:int>>> 一个嵌套多层的复杂数据结构。
3. hive在语法上与标准的SQL有什么区别? 以及原由是什么?
1)多表之间的join操作,只支持 等号 = 条件,且语法格式如下:
SELECT t1.a1 as c1, t2.b1 as c2
FROM t1 JOIN t2 ON (t1.a2 = t2.b2); |
而不是传统的格式:
SELECT t1.a1 as c1, t2.b1 as c2
FROM t1, t2
WHERE t1.a2 = t2.b2
|
2)hive不支持将数据插入现有的表或分区中,仅支持覆盖重写整个表,示例如下:
INSERT OVERWRITE TABLE t1
SELECT * FROM t2; |
3)hive不支持INSERT INTO, UPDATE, DELETE操作,这样的话,就不要很复杂的锁机制来读写数据。
INSERT INTO syntax is only available
starting in version 0.8。INSERT INTO就是在表或分区中追加数据。
4)hive支持嵌入mapreduce程序,来处理复杂的逻辑
如:
FROM (
MAP doctext USING 'python wc_mapper.py' AS (word, cnt)
FROM docs
CLUSTER BY word
) a
REDUCE word, cnt USING 'python wc_reduce.py'; |
--doctext: 是输入
--word, cnt: 是map程序的输出
--CLUSTER BY: 将wordhash后,又作为reduce程序的输入
并且map程序、reduce程序可以单独使用,如:
FROM (
FROM session_table
SELECT sessionid, tstamp, data
DISTRIBUTE BY sessionid SORT BY tstamp
) a
REDUCE sessionid, tstamp, data USING 'session_reducer.sh'; |
--DISTRIBUTE BY: 用于给reduce程序分配行数据
5)hive支持将转换后的数据直接写入不同的表,还能写入分区、hdfs和本地目录。
这样能免除多次扫描输入表的开销。
FROM t1
INSERT OVERWRITE TABLE t2
SELECT t3.c2, count(1)
FROM t3
WHERE t3.c1 <= 20
GROUP BY t3.c2
INSERT OVERWRITE DIRECTORY '/output_dir'
SELECT t3.c2, avg(t3.c1)
FROM t3
WHERE t3.c1 > 20 AND t3.c1 <= 30
GROUP BY t3.c2
INSERT OVERWRITE LOCAL DIRECTORY '/home/dir'
SELECT t3.c2, sum(t3.c1)
FROM t3
WHERE t3.c1 > 30
GROUP BY t3.c2; |
6) FROM与SELECT/MAP/REDUCE关键字的次序可以调换,这样就能比较方便的处理多个INSERT
操作。 示例如上。
4. Hive是如何存放数据的?或者说其数据的组织形式是什么样的?
表是Hive的逻辑数据单元,但是在hdfs的空间内,主要的数据被分为以下三种形式:
1)表:一个表就是hdfs中的一个目录
2)区:表内的一个区就是表的目录下的一个子目录
3)桶:如果有分区,那么桶就是区下的一个单位,如果表内没有区,那么桶直接就是表下的单位,桶一般是文件的形式。
表是否分区,如何添加分区,都可以通过Hive-QL语言完成。通过分区,即目录的存放形式,Hive可以比较容易地完成对分区条件的查询。
桶是Hive的最终的存储形式。在创建表时,用户可以对桶和列进行详细地描述。
并且,Hive支持外部的创建,即将数据存放在hdfs的其他地方。
5. Hive数据的序列化与反序列化,是如何完成的?
1)相关接口:SerDe, LazySerDe,RegexSerDe
2)如何标识一个新行?如何标识一行内列的区分?
这些可以指定简单的ascii字符来完成。这是LazySerDed的方式。
3)对RegexSerDe是采用 正则表达式的方式来解析一行内的列数据。
6. Hive支持哪些文件格式?即Hive数据文件会被存放成什么的格式?
Hadoop支持各种数据格式。而Hive的数据格式,在表创建时就可以指定。
Text,Binary都支持,除此之外,列存储的方式能大大提高查询的性能。
以上形式的接口为:TextInputFormat, BinaryInputFormat,
RCInputFormat.
7. Hive 的架构形式是什么样的?有哪些组件?
Hive的组件总体上可以分为以下几个部分:对外的界面或接口、中间件或服务端部分、底层驱动、元数据(即hive系统参数数据)
1)对外的接口包括以下几种:命令行CLI,Web界面、JDBC/ODBC接口
2)中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hive和其他程序。
3)底层驱动:包括HiveQL编译器,优化器、执行的引擎(执行器)
4)元数据metadata:存放系统参数
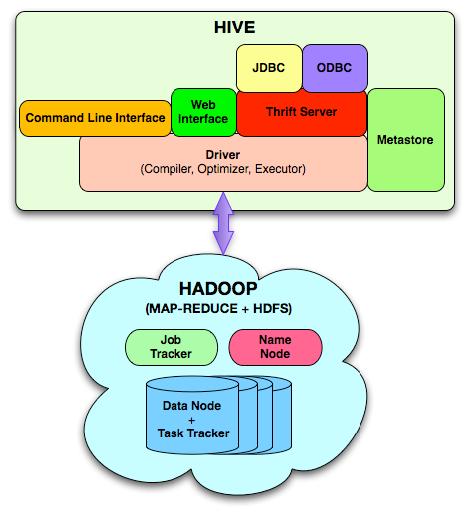
1)MetaStore类似于Hive的目录。它存放了有个表、区、列、类型、规则模型的所有信息。并且它可以通过thrift接口进行修改和查询。它为编译器提供高效的服务,所以,它会存放在一个传统的RDBMS,利用关系模型进行管理。这个信息非常重要,所以需要备份,并且支持查询的可扩展性。
2)查询编译器query compiler: HiveQL语句被处理,同传统的数据库编译器一样,都经历以下步骤:
解析parse --> 类型检查和语法分析type check and
semantic analysis --> 优化optimization --> 生成物理上的、真正的执行步骤
3) 执行引擎execution engine:
根据任务的依赖关系,执行各种mapreduce任务。一个mapreduce任务都被序列化到一个plan.xml文件中,然后加载到
job cache中,并且各部分解析plan.xml(反序列化),并执行相关操作,将结果放入临时的位置,再由DML转移到指定位置。
8. DDL与metadata的关系?
DDL就是Data Define Language,数据定义语言:常用命令包括:CREATE
/ ALTER / DROP. 另外还有 SHOW / DESRIBE. 如
hive> CREATE TABLE pokes (foo INT, bar STRING);
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
hive> DROP TABLE pokes;
|
MetaData是一个嵌入式的Derby数据库,它的位置由hive的 javax.jdo.option.ConnectionURL配置来指定。目前,MetaData默认情况下一次只能对一个用户可见。
MetaData可以是JPOX支持的任何数据库。将来,MetaData将会用一个独立的服务器来管理,这样多个节点Node都可以访问它。
MetaData被存储在一个标准的关系型数据库中,Derby就是一个开源、轻型的嵌入式数据库。
9. Hive的常用操作
Comparison
A = B , A <> B , A < B , A <= B , A > B , A >= B ,
A IS NULL , A IS NOT NULL , A LIKE B , NOT A LIKE B ,
A RLIKE B , A REGEXP B |
Arithmetic
A + B , A - B , A * B , A / B , A % B |
Bit-wise
A & B , A | B , A ^ B, ~A |
Logical
A AND B, A && B, A OR B, A || B, NOT A, !A |
HIVE 语法是不区分大小写的。
Hive还支持大量的函数。
|


