|
ЮвУЧЩшМЦЙиЯЕЪ§ОнПтSchemaЕФЖМгавЛЬзЭъећЕФЗНАИЃЌЖјNoSQLШДУЛгаетаЉЁЃАыФъЧАБЪепЖССЫБОЁЖSQLЗДФЃЪНЁЗЕФЪщЃЌОѕЕУЗЧГЃКУЁЃОЭПЊЪМСєвтЃЌЖдгкNoSQLЪЧЗёвВгаЗДФЃЪНЃПКУЕФЗДФЃЪНПЩвддкЮвУЧЩшМЦSchemaИцЫпФФРяЪЧЯнкхКЭаќбТЁЃNoSQLаћДЋЕФЪБКђЭљЭљаћГЦЪЧSchemaLessЕФЃЌетЛсШУШЫЮѓНтЦфВЛашвЊЩшМЦSchemaЁЃЕЋШчЙћВЛвтЪЖЕНЩшМЦSchemaЕФБивЊЃЌЯнкхОЭдквЛжБдкКкАЕжаЕШзХЮвУЧЁЃетЦЊЮФеТОЭзмНсвЛаЉБ№ШЫЕФЃЌвВгаздМКЗИЙ§ЕФЩюЭДЕФЩшМЦSchemaДэЮѓЁЃ
NoSQLЪ§ОнПтзюжїСїЕФгаЮФЕЕЪ§ОнПтЃЌСаДцЪ§ОнПтЃЌМќжЕЪ§ОнПтЁЃШ§епЗжБ№гаДњБэзїMongoDBЃЌHBaseКЭRedisЁЃШчЙћНЋNoSQLБШзїБјЦїЕФЛАЃЌПЩвдетбљ(MySQLЪЧЕфаЭЕФЙиЯЕаЭЪ§ОнПтЃЌвЛбљВЮгыБШНЯ)ЃК
MySQLВњЩњФъДњНЯдчЃЌЖјЧвЫцзХLAMPДѓГБЕУвдГЩЪьЁЃОЁЙмЦфУЛгаЪВУДДѓЕФИФНјЃЌЕЋЪЧаТаЫЕФЛЅСЊЭјЪЙгУЕФзюЖрЕФЪ§ОнПтЁЃОЭЯёДЋЭГЕФВЫЕЖЃЌНсЙЙМђЕЅЃЌМИАйФъУЛгаИФНјЁЃЕЋЪЧВЛЗСАВњЩњИїЪНИїбљЕФЕЖЗЈЃЌжЛвЊгавЛАбЃЌОЭФмЪЄШЮГјЗПРяЕФДѓВПЗжЪТЮёЁЃMySQLвВЪЧвЛбљЃЌКЫаФвбОЮШЖЈЁЃЕЋЪЧЧаПтЃЌЗжБэЃЌБИЗнЃЌМрПиЃЌЕШЕШЪжЖЮвЛгІОуШЋЁЃ
- MongoDBЪЧИіаТЩњЪТЮяЃЌЬсЙЉИќСщЛюЕФSchemaЃЌCapped CollectionЃЌвьВНЬсНЛЃЌЕиРэЮЛжУЫїв§ЕШЮхЛЈЪЎЩЋЕФЙІФмЁЃОЭЯёШ№ЪПОќЕЖЃЌВЛЕЋПЩвдЕБЕЖгУЃЌЛЙПЩвдПЊЦПИЧЃЌМєжИМзЁЃЕЋЪЧЫћвВВЛБШMySQLЧПЃЌвђЮЊЛЙШБЗІЪБМфЕФФЅэТЁЃвЛЪЧЯЕЭГБОЩэЕФЮШЖЈадЃЌЖўЪЧПЊЗЂЃЌдЫЮЌашвЊИќЖрОбщВХФмСїааЁЃ
- HBaseЪЧИіеЬЪЦЦлШЫЕФДѓЯѓБјЁЃвРеЬзХHadoopЕФЩњЬЌЛЗОГЃЌПЩвдгаКмКУЕФРЉеЙадЁЃЕЋЪЧОЭЯёЯѓБјвЛбљЃЌЪЙгУепашвЊбјвЛЭЗДѓЯѓ(Hadoop),ВХФмЧ§ЪЙЫћЁЃ
- RedisЪЧМќжЕДцДЂЕФДњБэЃЌЙІФмзюМђЕЅЁЃЬсЙЉЫцЛњЪ§ОнДцДЂЁЃОЭЯёвЛИљАєзгвЛбљЃЌУЛгаЖргрЕФЙЙдьЁЃЕЋЪЧвВе§ЪЧвђДЫЃЌЫћЕФЩьЫѕадЬиБ№КУЁЃОЭЯёЮђПеЪжРяЕФН№ЙПАєЃЌДѓПЩЭБЦЦЬьЃЌаЁФмГЩЫѕГЩеыЁЃ
ЮФЕЕЪ§ОнПтЕФЕУЪЇ
ЙиЯЕФЃаЭЪдЭМНЋЪ§ОнПтФЃаЭКЭЪ§ОнПтЪЕЯжЗжПЊЃЌШУПЊЗЂепПЩвдЭбРыЕзВуКмКУЕФВйзїЪ§ОнЁЃЕЋБЪепвдЮЊЙиЯЕФЃаЭдквЛаЉгІгУГЁОАЯТгаШѕЕуЃЌЯждквбОВЛЕУВЛУцЖдЁЃ
- SQLШѕЕувЛЃКБиаыжЇГжJoinЁЃвђЮЊЪ§ОнВЛФмЙЛгажиИДЁЃЫљвдЪЙгУЗЖЪНЕФЙиЯЕФЃаЭЛсВЛПЩБмУтЕФДѓСПJoinЁЃШчЙћВЮгыJoinЕФЪЧвЛеХБШФкДцаЁЕФБэЛЙКУЁЃЕЋЪЧШчЙћДѓБэJoinЛђепБэЗжВМдкЖрЬЈЛњЦїЩЯЕФЛАЃЌJoinОЭЪЧадФмЕФиЌУЮЁЃ
- SQLШѕЕуЖўЃКМЦЫуКЭДцДЂёюКЯЁЃЙиЯЕФЃаЭзїЮЊЭГвЛЕФЪ§ОнФЃаЭМШПЩвдгУгкЪ§ОнЗжЮіЃЌвВПЩвдгУгкдкЯпвЕЮёЁЃЕЋетСНепвЛИіЧПЕїИпЭЬЭТЃЌвЛИіЧПЕїЕЭбгЪБЃЌвбОбнЛЏГіЭъШЋВЛЭЌЕФМмЙЙЁЃгУЭЌвЛЬзФЃаЭРДГщЯѓЯдШЛЪЧВЛКЯЪЪЕФЁЃHadoopеыЖдЕФОЭЪЧМЦЫуЕФВПЗжЁЃMongoDB,RedisЕШеыЖддкЯпвЕЮёЁЃСНепЖМХзЦњСЫЙиЯЕФЃаЭЁЃ
еыЖдетСНИіУЮїЪЁЃЮФЕЕЪ§ОнПтШчMongoDBЕФЕФжївЊФПЕФЪЧ ЬсЙЉИќЗсИЛЕФЪ§ОнНсЙЙРДХзЦњJoinРДЪЪгІдкЯпвЕЮёЁЃЕБШЛвВВЛЪЧMongoDBЭъШЋВЛФмгУJoinЃЌВЛФмФУРДзіЪ§ОнЗжЮіЃЌЬжТлетИіжЛЪЧМћШЪМћжЧЕФЮЪЬтЁЃЫљвдЮФЕЕЪ§ОнПтВЂВЛБШЙиЯЕЪ§ОнПтЧПДѓЃЌгЩгкЖдJoinЕФШѕжЇГжЃЌЙІФмЛсШѕаэЖрЁЃЩшМЦЙиЯЕФЃаЭЕФЪБКђЃЌЭЈГЃжЛашвЊПМТЧКУЪ§ОнжБНгЕФЙиЯЕЃЌЖЈвхЪ§ОнФЃаЭЁЃЖјЩшМЦЮФЕЕЪ§ОнПтФЃаЭЕФЪБКђЃЌЛЙашвЊПМТЧгІгУШчКЮЪЙгУЁЃвђДЫЩшМЦКУвЛИіЕФЮФЕЕЪ§ОнПтSchemaБШЩшМЦЙиЯЕФЃаЭИќМгЕФРЇФбЁЃГ§ДЫжЎЭтЃЌгЩгкЮФЕЕЪ§ОнПтЪТЮёЕФжЇГжвВЪЧБШНЯШѕЃЌвЛАуNoSQLжЛЛсЬсЙЉвЛИіааЫјЁЃетвВИјЩшМЦSchemaИќМгдіМгСЫФбЖШЁЃЖдгкЮФЕЕЪ§ОнПтЕФЪЙгУгаКмЖрашвЊзЂвтЕФЕиЗНЃЌБОЮФжЛЙизЂФЃаЭЩшМЦЕФВПЗжЁЃ
ЗДФЃЪНвЛЃКЙпадЫМЮЌ/бигУЙиЯЕФЃаЭ
ЙиЯЕФЃаЭЪЧЪ§ОнДцДЂЕФОЕфФЃаЭЃЌЪЙгУЪ§ОнФЃаЭЗЖЪНЕФКУДІЗЧГЃЕФУїЯдЁЃЕЋЪЧгЩгкЮФЕЕЪ§ОнПтВЛжЇГжJoin(АќРЈКЭЭтМќЯЂЯЂЯрЙиЕФЭтМќдМЪј)ЕШЬиадЃЌЯАЙпадЕФбигУЙиЯЕФЃаЭгаЕФЪБКђЛсГіЯжЮЪЬтЁЃашвЊРћгУЦ№ЮФЕЕЪ§ОнПтЬсЙЉЕФЗсИЛЕФЪ§ОнФЃаЭРДгІЖдЁЃ
жЕЕУвЛЬсЕФЪЧЮФЕЕЪ§ОнПтЕФЩшМЦКЭЙиЯЕФЃаЭВЛЭЌЃЌЪЧСщЛюЖрбљЕФЁЃЖдгкЭЌвЛИіЧщаЮЃЌПЩвдЩшМЦГігаЖржжФмЙЛЙЄзїЕФФЃаЭЃЌУЛгаОјЖдвтвхЩЯзюКУЕФФЃаЭЁЃ
ЯТЭМЪЧЙиЯЕФЃаЭКЭЮФЕЕФЃаЭЕФЖдБШЁЃ
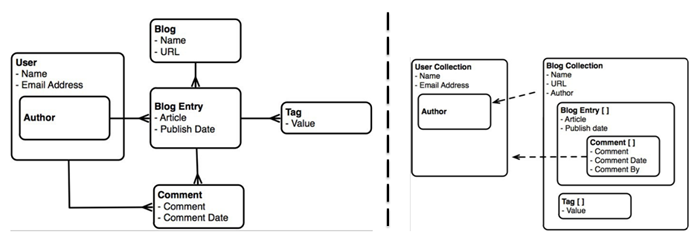
ЙиЯЕФЃаЭ VS ЮФЕЕФЃаЭ
етИівЛИіВЉПЭЕФЪ§ОнФЃаЭЃЌгаBlog,UserЕШБэЁЃзѓВрЪЧЙиЯЕФЃаЭЃЌгвВрЪЧЮФЕЕФЃаЭЁЃетИіЮФЕЕФЃаЭВЂВЛЪЧЭъШЋКЯРэЃЌПЩвдзїЮЊЁАе§ЗДСНУцНЬВФЁБдкЯТЮФВЛЖЯВћЪіЁЃ
ЮЪЬтвЛЃКДцдкУшЪіЖрЖдЖрЕФЙиЯЕБэ
жЂзДЃКЮФЕЕЪ§ОнПтжаДцДЂдкгаДПДтЕФЙиЯЕБэЃЌР§ШчЃК
| id |
user_id |
blog_id |
0 |
0 |
0 |
1 |
0 |
1 |
етбљЕФБэОЭЫудкЙиЯЕФЃаЭжавВЪЧВЛЭзЕФЃЌвђЮЊетИіIDЗЧГЃЕФЖргрЃЌПЩвдгУСЊКЯжїМќРДНтОіЁЃЕЋЪЧдкЮФЕЕЪ§ОнПтжаЃЌгЩгкБиаыЧПжЦЕЅжїМќЃЌВЛЕУВЛВЩШЁетбљЕФЩшМЦЁЃ
ЛЕДІЃК
1.ЦЦЛЕЪ§ОнЭъБИадЁЃгЩгкIDЪЧжїМќЃЌдкЪ§ОнФЃаЭЩЯУЛгадМЪјРДБЃжЄВЛГіЯжжиИДЕФuser_id,blog_idЖдЁЃвЛЕЉЪ§ОнГіЯжжиИДЃЌИќаТЩОГ§ЖМЪЧЮЪЬтЁЃ
2.Ыїв§Й§ЖрЁЃгЩгкЪЧЙиЯЕБэЃЌБиаыдкuser_idКЭblog_idЩЯУцЗжБ№НЈвЛИіЫїв§ЁЃгАЯьадФмЁЃ
НтОіЗНАИЃК
ЪЙгУЮФЕЕЪ§ОнПтЕфаЭЕФДІРэЖрЖдЖрЕФАьЗЈЁЃВЛЪЧНЈСЂвЛеХЙиЯЕБэЃЌЖјЪЧдкЦфжавЛИіЮФЕЕ(ШчUser)жаЃЌМгШывЛИіListзжЖЮЁЃ
| user_id |
user_name |
blog_id[] |
ЁЁ |
0 |
Jake |
0,1 |
ЁЁ |
| 1 |
Rose |
1,2 |
ЁЁ |
ЮЪЬтЖў:УЛгаЧјЗжЁБвЛЖдЖрЙиЯЕЁБКЭЁАЖрЖдвЛЙиЯЕЁБ
жЂзДЃКЙиЯЕФЃаЭВЛЧјЗжЁАвЛЖдЖрЁБКЭЁАЖрЖдвЛЁБЃЌЖдгкЮФЕЕЪ§ОнПтРДНВЃЌЙиЯЕФЃаЭжЛгаЁАЖрЖдвЛЁБЁЃОЭЯёетеХCommentБэЃК
| comment_id |
user_id |
content |
ЁЁ |
0 |
0 |
ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ |
ЁЁ |
| 1 |
0 |
ЁАЪЧАЁЁБ |
ЁЁ |
ШчЙћећИіФЃаЭЖМЪЧетбљЕФЁАЖрЖдвЛЁБЙиЯЕОЭашвЊЗДЫМСЫЁЃ
ЛЕДІЃК
1.ЖюЭтЫїв§ЁЃШчЙћПЭЛЇЖЫвбжЊuser_id,ашвЊЛёЕУUserаХЯЂКЭCommentаХЯЂЃЌашвЊжДааСНДЮВщбЏЁЃЦфжавЛДЮВщбЏашвЊЪЙгУЫїв§ЁЃВЂЧввЊдкПЭЛЇЖЫздМКJoinЁЃетбљПЩФмгаЧБдкадФмЮЪЬтЁЃ
НтОіЗНАИЃК
ЮЪЬтЕФКЫаФдкгкЪЧвбжЊuser_idВщбЏСНеХБэЃЌЛЙЪЧвбжЊcomment_idВщбЏСНеХБэЁЃШчЙћЪЧвбжЊcomment_idетбљЕФЩшМЦОЭЪЧКЯРэЕФЃЌЕЋЪЧШчЙћЪЧвбжЊuser_idРДВщбЏЃЌАбЙиЯЕЗХдкuserБэРяЕФЩшМЦИќКЯРэвЛаЉЁЃ
| user_id |
user_name |
comment_id[] |
ЁЁ |
0 |
Jake |
0,1 |
ЁЁ |
| 1 |
Rose |
1,2 |
ЁЁ |
етбљЕФЩшМЦЃЌОЭПЩвдБмУтвЛИіЫїв§ЁЃЭЌРэЃЌЖдгкЖрЖдЖрвВЪЧвЛбљЕФЃЌЭЈЙ§КЯРэЕФАВХХзжЖЮЕФЮЛжУПЩвдБмУтЫїв§ЁЃ
е§ШЗЪЙгУЕФГЁКЯЃК
ЙиЯЕаЭФЃаЭЪЧЗЧГЃГЩЙІЕФЪ§ОнФЃаЭЃЌКЯРэЕФбигУЪЧЗЧГЃКУЕФЁЃЕЋЪЧгЩгкЮФЕЕЪ§ОнПтЕФЬиЕуЃЌашвЊЪЪЕБЕФЕїећЃЌетбљЕУГіЕФЪ§ОнФЃаЭЃЌОЁЙмадФмВЛЪЧзюгХЃЌЕЋЪЧгазюКУЕФСщЛюадЁЃВЂЧввВгаРћгкКЭЙиЯЕЪ§ОнПтзЊЛЛЁЃ
ЗДФЃЪНЖўЃКДІДІв§гУПЭЛЇЖЫJoin
жЂзДЃКЪ§ОнПтЩшМЦжаГфТњСЫxx_idЕФзжЖЫЃЌдкВщбЏЕФЪБКђашвЊДѓСПЕФЪжЖЏJoinВйзїЁЃОЭЩцМАЕНСЫетИіЗДФЃЪНЁЃе§ШчЩЯУцЬсЕНЕФВЉПЭЕФЙиЯЕФЃаЭЃЌШчЙћвбжЊblog_idВщбЏcommentsЃЌашвЊжСЩйжДаа3ДЮВщбЏЃЌВЂЧвЪжЖЏJoinЁЃ
ЛЕДІЃК
1.ЪжЖЏJoinЃЌТщЗГЧввзГіДэЁЃЮФЕЕЪ§ОнПтВЛжЇГжJoinЧвУЛгаЭтМќБЃжЄЁЃвђДЫашвЊдкПЭЛЇЖЫJoinЃЌетбљЕФВйзїЖдгкШэМўПЊЗЂРДНВЪЧБШНЯЗБЫіЕФЁЃгЩгкУЛгаЭтМќБЃжЄЃЌвђДЫВЛФмБЃжЄШЁЕУЕФIDдкЪ§ОнПтРяУцЪЧгаЪ§ОнЕФЁЃдкДІРэЕФЪБКђашвЊВЛЖЯХаЖЯЃЌШнвзГіДэЁЃ
2.ЖрДЮВщбЏЁЃШчЙћв§гУЙ§ЖрЃЌВщбЏЕФЪБКђашвЊЖрДЮВщбЏВХФмВщЕНзуЙЛЕФЪ§ОнЁЃБОРДЮФЕЕЪ§ОнПтЪЧКмПьЕФЃЌЕЋЪЧгЩгкЖрДЮВщбЏЃЌИјЪ§ОнПтдіМгСЫбЙСІЃЌЛёШЁШЋВПЪ§ОнЕФЪБМфвВЛсдіМгЁЃ
3.ЪТЮёДІРэЗБЫіЁЃЮФЕЕЪ§ОнПтвЛАуВЛжЇГжвЛАувтвхЩЯЪТЮёЃЌжЛжЇГжааЫјЁЃШчЙћЮФЕЕЪ§ОнПтгаИјЖрИіСЌНгЁЃдкВхШыЕФЪБКђЃЌЪТЮёЕФДІРэОЭЪЧиЌУЮЁЃдкЮФЕЕЪ§ОнПтжаЪЙгУЪТЮёЃЌашвЊЪЙгУааЫјЃЌдкНјааДѓСПЕФДІРэЁЃЬЋЙ§ЗБЫіЃЌИааЫШЄЕФЖСепПЩвдЫбвЛЯТЁЃ
НтОіЗНАИЃК
ЪЪЕБЪЙгУФкСЊЪ§ОнНсЙЙЁЃгЩгкЮФЕЕЪ§ОнПтжЇГжИќИДдгЕФЪ§ОнНсЙЙПЩвдНЋв§гУзЊЛЛЮЊФкСЊЕФЪ§ОнЃЌЖјВЛгУаТНЈвЛеХБэЁЃетбљзіПЩвдНтОіЩЯУцЕФвЛаЉЮЪЬтЃЌЪЧвЛИіЭЦМіЕФЗНАИЁЃОЭЯёЩЯУцВЉПЭЕФР§згвЛбљЁЃНЋЮхеХБэМђЛЏГЩСЫСНеХБэЁЃФЧЪВУДЪБКђЪЙгУФкСЊФиЃПвЛАуШЯЮЊ
- ЪЙгУФкСЊПЩвдНтОіЖСадФмЮЪЬтЃЌУїЯдМѕЩйQueryЕФДЮЪ§ЕФЪБКђЁЃ
- ПЩвдМђЛЏЪ§ОнФЃаЭЃЌЛЏМђБэжЎМфЕФЙиЯЕЃЌЖјЭЌЪБВЛЛсгАЯьСщЛюадЕФЪБКђЁЃ
- ЪТЮёПЩвдЕУЕНМђЛЏЮЊЕЅааЪТЮёЕФЪБКђ
е§ШЗЪЙгУЕФГЁКЯЃК
ЗЖЪНЛЏЕФЪЙгУГЁОАЃЌЮФЕЕЪ§ОнПтЛсБЛЖрИігІгУЪЙгУЁЃгЩгкЪ§ОнПтЩшМЦЮоЗЈЙРМЦЖрИігІгУЯждкМАНЋРДЕФВщбЏЧщПіЃЌашвЊМЋДѓЕФСщЛюадЁЃдкетИіЪБКђЃЌЪЙгУв§гУБШФкСЊППЦзЁЃ
ЗДФЃЪНШ§ РФгУФкСЊКѓЛМЮоЧю
ЮЪЬтвЛ ЗСАЕНВщбЏЕФФкСЊ
жЂзДЃКЦЕЗБВщбЏвЛаЉФкСЊзжЖЮЃЌЖЊЦњЦфЫћзжЖЮЁЃ
ЛЕДІЃК
1.ЮоIDдМЪјЃКЪЙгУФкСЊзжЖЮКЭв§гУВЛЭЌЃЌЪЧУЛгаIDдМЪјЕФЁЃвђДЫВЛФмЭЈЙ§ID(жїМќ)РДЙмРэЃЌШчЙћОГЃашвЊЕЅЖРВйзїФкСЊЖдЯѓЛсЗЧГЃВЛБуЁЃ
2.Ыїв§ЗКРФЃКШчЙћвдФкСЊзжЖЮЮЊЬѕМўНјааВщбЏЃЌашвЊНЈСЂЫїв§ЁЃгаПЩФмдьГЩЫїв§ЗКРФЁЃ
3.адФмРЫЗбЃКДѓВПЗжЮФЕЕЪ§ОнПтЕФЪЕЯжЪЧАДааДцДЂЕФЃЌвВОЭвтЮЖзХЃЌОЁЙмжЛВщбЏвЛИізжЖЮЃЌЕЋЪЧDBашвЊНЋећааДгДХХЬжаШЁГіЁЃШчЙћзжЖЮЙЛаЁЃЌЮФЕЕЙЛДѓЃЌЪЧКмВЛКЯЫуЕФЁЃ
НтОіЗНАИЃК
ШчЙћГіЯжвдЩЯЕФжЂНсЃЌОЭПЩвдПМТЧЪЙгУв§гУДњЬцФкСЊСЫЁЃФкСЊЬиаджївЊЕФгУЭОдкгкЬсИпадФмЃЌШчЙћГіЯжадФмВЛЩ§ЗДНЕЃЌФЧОЭУЛгавтвхСЫЁЃШчЙћЖдадФмгаКмЧПСвЕФвЊЧѓЃЌПЩвдПМТЧЪЙгУжиИДЪ§ОнЃЌЭЌбљЕФЪ§ОнМДдкФкСЊзжЖЮжавВдкв§гУЕФБэРяУцЁЃетбљПЩвдНсКЯФкСЊКЭв§гУЕФадФмгХЪЦЁЃШБЕуЪЧЪ§ОнГіЯжжиИДЃЌЮЌЛЄЛсБШНЯТщЗГЁЃ
ЮЪЬтЖў ЮоЯоХђеЭЕФФкСЊ
жЂзДЃКList,MapРраЭЕФФкСЊзжЖЮВЛЖЯХђеЭЃЌЖјЧвУЛгаЯожЦЁЃОЭЯёЧАУцЬсЕНЕФBlogЕФФкСЊзжЖЮCommentЁЃШчЙћЖдУПвЛЦЊBlogЕФCommentЪ§СПУЛгаЯожЦЕФЛАЃЌCommentЛсЮоЯоХђеЭЁЃЧсдђгАЯьадФмЃЌжидђВхШыЪЇАмЁЃ
| Blog_id |
content |
Comment[] |
ЁЁ |
0 |
ЁАЁЁБ |
ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ,
ЁАЪЧАЁЁБ,ЁБЮоЯодіГЄжаЁБЁ |
ЁЁ |
ЛЕДІЃК
1.ВхШыЪЇАмЁЃЮФЕЕЪ§ОнПтЕФУПЬѕМЧТМЖМгазюДѓДѓаЁЃЌВЂЧввВгаЭЦМізюМбЕФДѓаЁЁЃвЛАуВЛЛсГЌЙ§4MЁЃОЭЯёИеИеЬсЕНЕФР§згЃЌШчЙћЪЧЦЊШШУХЕФВЉЮФЕФЛАЃЌЦРТлЕФДѓаЁКмШнвзОЭГЌЙ§4MЁЃНьЪБЮФЕЕНЋЮоЗЈИќаТЃЌаТЕФЦРТлЮоЗЈВхШыЁЃ
2.адФмЭЯгЭЦПЁЃгЩгкФкСЊзжЖЮХђеЭЃЌЦфДѓаЁНЋдЖдЖГЌЙ§ЦфЫћВПЗжЃЌгАЯьЦфЫћВПЗжЕФадФмБэЯжЁЃВЂЧввђДЫЕМжТИУМЧТМДѓаЁЦЕЗББфЛЏЃЌЖдЕЕЪ§ОнПтЕФЪ§ОнЮФМўФкВППЩФмвђДЫВњЩњКмЖрЫщЦЌЁЃ
НтОіЗНАИЃК
ЩшЖЈзюДѓЪ§ФПЛђепЪЙгУв§гУЁЃЛЙЪЧBlogКЭCommentЕФР§згЃЌПЩвдНЋCommentДгBlogжаАўРыГіГЩвЛеХБэЁЃШчЙћПМТЧЕНадФмЃЌПЩвддкBlogБэжааТНЈвЛИізжЖЮШчзюНќЕФЦРТлЁЃетбљМШБЃжЄСЫадФмЃЌгжФмЙЛдЄЗРХђеЭЁЃ
| Blog_id |
content |
last_five_comment[] |
ЁЁ |
0 |
ЁАЁЁБ |
ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ,
ЁАЪЧАЁЁБ,ЁБзюЖр5ЬѕЁБЁ |
ЁЁ |
ЮЪЬтШ§ ЮоЗЈЮЌЛЄЕФФкСЊ
жЂзДЃКDBAЯыЕЅЖРЮЌЛЄФкСЊзжЖЮЃЌЕЋЮоЗЈзіЕНЁЃЛЕДІЃК
1.ШЈЯоЙмРэФбЁЃЪ§ОнПтЕФШЈЯоЙмРэЕФзюаЁСЃЖШЪЧБэЁЃШчЙћЪЙгУФкСЊММЪѕЃЌОЭвтЮЖзХФкСЊВПЗжБиаыКЭЦфЫћзжЖЮгУЭЌвЛИіШЈЯоРДЙмРэЁЃУЛгаАьЗЈдкDBМЖБ№вўВиЁЃ2.ЧаБэФбЁЃШчЙћЗЂЯжвЛеХБэЕФХгДѓашвЊЧаБэЁЃетИіЪБКђОЭБШНЯОРНсСЫЁЃШчЙћвЛЕЖЧаЃЌpartion
KeyЕФбЁдёЃЛЫїв§ЕФЪЇаЇЖМЛсГЩЮЊЮЪЬтЁЃШчЙћОѕЕУВ№ЮЊСНеХБэЃЌОЭЛсКмКУВйзїЕФЛАЃЌОЭЪЧФкСЊЕФЙ§ЖШЪЙгУСЫ ЁЃ
3.БИЗнФбЁЃЙиЯЕЪ§ОнПтжаУПеХБэПЩвдгаВЛЭЌЕФБИЗнВпТдЁЃЕЋЪЧШчЙћФкСЊЦ№РДЃЌетбљЕФБИЗнОЭзіВЛЕНСЫЁЃ
НтОіАьЗЈЃК
ЩшМЦЪ§ОнПтФЃаЭЕФЪБКђашвЊПМСПжЎКѓЕФЮЌЛЄВйзїЃЌгШЦфЪЧФкСЊЕФзжЖЮашВЛашвЊЕЅЖРЕФЮЌЛЄЁЃашвЊКЭдЫЮЌЩЬСПЁЃШчЙћЖдФкСЊЕФзжЖЮгаЕЅЖРЮЌЛЄЕФвЊЧѓЃЌПЩвдВ№ЗжГіРДзїЮЊв§гУЁЃ
ЮЪЬтЫФ ЖЂЫРгІгУЕФФкСЊ
жЂзДЃКгІгУПЩвдЗЧГЃКУЕФдЫаадкЪ§ОнПтЩЯЁЃЕЋЪЧЕБаТЕФгІгУНгШыЕФЪБКђЛсКмТщЗГЁЃвђЮЊЩшМЦЪ§ОнФЃаЭЕФЪБКђПМТЧЕНСЫВщбЏЁЃЫљвдЕБгааТгІгУЃЌаТВщбЏНгШыЕФЪБКђЃЌОЭЛсФбгкЪЙгУдгаЕФФЃаЭЁЃ
ЛЕДІЃК1.аТгІгУНгШыФбЁЃЕБаТЕФгІгУЪдЭМЪЙгУЭЌвЛИіЪ§ОнПтЕФЪБКђЃЌНгШыБШНЯРЇФбЁЃвђЮЊВщбЏЪБВЛЭЌЕФЃЌашвЊЕїећЪ§ОнФЃаЭВХФмЪЪгІЁЃЕЋЪЧЕїећФЃаЭгжЛсгАЯьдгагІгУЁЃ
2.МЏГЩФбЁЃВЛЭЌЕФЙиЯЕаЭЪ§ОнПтПЩвдМЏГЩдквЛЦ№ЃЌЙВЭЌЪЙгУЁЃЕЋЪЧЖдгкЮФЕЕЪ§ОнПтЃЌЫфШЛЙІФмЩЯПЩвдЛЅВЙЃЌЕЋЪЧгЩгкФкСЊЪ§ОнНсЙЙЕФВювьЃЌвВБШНЯФбгкМЏГЩЁЃ
3.ETLФбЁЃЯждкДѓВПЗжЕФЪ§ОнЗжЮіЯЕЭГЪЙгУЕФЪЧЙиЯЕФЃаЭЃЌОЭСЌHadoopЫфШЛВЛгУЙиЯЕФЃаЭЃЌЕЋЪЧЦфЩЯЕФHiveЕФГЃгУЙЄОпвВЪЧАДЙиЯЕФЃаЭЩшМЦЕФЁЃ
НтОіЗНАИЃК
ЪЙгУЗЖЪНЩшМЦЪ§ОнПтЃЌМДгУв§гУДњЬцФкСЊЁЃЛђепдкЪЙгУФкСЊЕФЪБКђЃЌИјУПИіФкСЊЖдЯѓвЛИіШЋОжЮЈвЛЕФKeyЃЌБЃжЄЦфКЭЙиЯЕФЃаЭжБНгПЩвдДцдкгГЩфЙиЯЕЃЌетбљПЩвдЬсИпЪ§ОнФЃаЭЕФСщЛюадЁЃШчBlogБэЃК
| Blog_id |
content |
Comment[] |
ЁЁ |
0 |
ЁАЁЁБ |
[{"id"=1,"content"=ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ},
{"id"=2,"content"=ЁАЪЧАЁЁБ}Ё] |
ЁЁ |
етбљЕФЩшМЦМШПЩвдРћгУЕНФкСЊЕФКУДІЃЌгжФмНЋЦфКЭЙиЯЕФЃаЭгГЩфЦ№РДЁЃШЗЖЈЪЧашвЊЪжЖЏЮЌЛЄcomment_idЃЌБЃжЄЦфШЋОжЮЈвЛадЁЃ
ЗДФЃЪНЫФЃКдкЯпМЦЫу
жЂзДЃКгавЛаЉдЫааЪБМфКмГЄЕФQuery,гЩгкгаОлКЯМЦЫуЃЌЫїв§вВВЛФмНтОіЁЃЫцзХЪ§ОнСПЕФдіГЄЃЌж№НЅГЩЮЊадФмЦПОБЁЃЛЕДІЃК
1.гАЯьгУЛЇЬхбщЁЃдкЯпвЕЮёжаЃЌШчЙћвЛИіВщбЏДѓгк4sЃЌгУЛЇЬхбщЛсМБОчЯТНЕЁЃАДжїМќКЭАДЫїв§ЕФВщбЏЖМФмТњзувЊЧѓЁЃЕЋЪЧОлКЯВйзїЭљЭљаш
ЩЈУшШЋБэЛђепДѓСПЕФЪ§ОнЃЌЫцзХЪ§ОнСПЕФдіМгЃЌВщбЏЪБМфЛсБфГЄЃЌгУЛЇВЛПЩШнШЬЁЃ
2.гАЯьЪ§ОнПтадФмЁЃГЄВщбЏЕФЛЕДІЪ§ВЛЧхЁЃдкЯпЩЯгІгУжаЃЌШчЙћГіЯжГЄВщбЏЃЌПЩФмЛсАдеМЪ§ОнЕФДѓВПЗжзЪдДЃЌАќРЈIOЃЌСЌНгЃЌCPUЕШЕШЁЃЕМжТЦфЫћКмКУЕФВщбЏЃЌЧсдђадФмвВЯТНЕЃЌжиепЮоЗЈЪЙгУЪ§ОнПтЁЃГЄВщбЏПЩвдГЦжЎЮЊDBЩБЪжЁЃ
НтОіЗНАИЃК
ЪзЯШвЊШЈКтЃЌетИіОлКЯВйзїЪЧВЛЪЧБивЊЕФЃЌБиаыЪЕЪБЭъГЩЁЃШчЙћУЛгаБивЊЪЕЪБЭъГЩЕФЛАЃЌПЩвдВЩШЁРыЯпВйзїЕФЗНАИЁЃдквЙЩюШЫОВЕФЪБКђЃЌХмвЛИіГЄВщбЏЃЌНЋНсЙћЛКДцЦ№РДЃЌИјЕкЖўЬьЪЙгУЁЃШчЙћБиаыЪЕЪБЭъГЩЃЌдђПЩвдаТНЈвЛИізжЖЮЃЌгУЁАincrЁБетбљЕФВйзїЃЌдкдЫааЕФЪБКђЃЌЪЕЪБОлКЯНсЙћЁЃ
ЖјВЛЪЧВщбЏЕФЪБКђжДаавЛДЮГЄВщбЏЁЃШчЙћТпМБШНЯИДдгЃЌЛђепОѕЕУДѓСПЁАincrЁБВйзїИјЪ§ОнПтЯЕЭГДјРДСЫбЙСІЃЌПЩвдЪЙгУStormжЎРр
ЪЕЪБЪ§ОнДІРэПђМмЁЃзмжЎЃЌвЊЩїгУГЄВщбЏЁЃ
ЗДФЃЪНЮхЃКАбФкСЊMapЖдЯѓЕФKeyЕБзїIDгУ
жЂзДЃКЮФЕЕЪ§ОнПтжЇГжФкСЊMapРраЭЁЃНЋЦфжаMapЕФKeyЕБзїЪ§ОнПтЕФжїМќРДгУЁЃ
| Blog_id |
content |
Comment[] |
ЁЁ |
0 |
ЁАЁЁБ |
{ЁА1Ёх=ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ,
ЁА2Ёх=ЁАЪЧАЁЁБ} |
ЁЁ |
етИіЗДФЃЪНКмШнвзЗИЃЌвђЮЊдкБрГЬгябджаMapЪ§ОнНсЙЙОЭЪЧетУДгУЕФЁЃЕЋЪЧЖдгкЪ§ОнПтФЃаЭРДЫЕЃЌетЪЧВЛелВЛПлЕФЗДФЃЪНЁЃ
ЛЕДІЃК
1.ЮоЗЈЭЈЙ§Ъ§ОнПтзіИїжж(><=)ВщбЏЁЃЖдгкЙиЯЕаЭЪ§ОнПтРДЫЕЃЌЫфШЛЪ§ОнНсЙЙПЩвдКмСщЛюЃЌЕЋВщбЏЕФЪБКђЖМЪЧАДВуДЮЕФЁЃБШШчcomment.idЃЌcomment.contentЁЃвВОЭЪЧЫЕЦфMapРраЭжаЕФKeyПЩвдРэНтЮЊЪєадУћЕФЃЌЖјВЛЪЧгУзїIDЁЃвђДЫвЛЕЉетбљЪЙгУЃЌОЭЭбРыЕФЪ§ОнПтЙмжЦЃЌЮоЗЈЪЙгУИїжжВщбЏЙІФмЁЃ2.ЮоЗЈЭЈЙ§Ыїв§ВщбЏЁЃЮФЕЕЪ§ОнПЩНЈСЂЫїв§ЪЧашвЊСаУћЕФЁЃБШШчcomment.idЁЃЖјетбљЕФЪ§ОнНсЙЙУЛгаЙЬЖЈЕФСаУћЃЌвђДЫЮоЗЈНЈСЂЫїв§ЁЃ
НтОіЗНАИЃК
ЪЙгУЪ§зщ+MapРДНтОіЁЃШчЃК
| Blog_id |
content |
Comment[] |
ЁЁ |
0 |
ЁАЁЁБ |
{ЁА1Ёх=ЁАNoSQLЗДФЃЪНЪЧКУЮФеТЁБ,
ЁА2Ёх=ЁАЪЧАЁЁБ}, {"id"=2,"content"=ЁАЪЧАЁЁБ}Ё] |
ЁЁ |
етбљЃЌОЭПЩвдЪЙгУcomment.idзїЮЊЫїв§ЃЌвВПЩвдЪЙгУЪ§ОнПтЕФВщбЏЙІФмЁЃМђЕЅгааЇЁЃMapРраЭжаЕФKeyЪЧЪєадУћЃЌValueЪЧЪєаджЕЁЃетбљЕФгУЗЈЪЧЮФЕЕЪ§ОнПтЪ§ОнФЃаЭЕФБОвтЃЌвђДЫЦфЬсЙЉЕФИїжжЙІФмВХФмРћгУЩЯЁЃЗёдђОЭЮоЗЈЪЙгУЁЃ
ЗДФЃЪНСљЃКВЛКЯРэЕФID
жЂзДЃКЪЙгУStringЩѕжСИќИДдгЪ§ОнНсЙЙзїЮЊЕФIDЃЌЛђепШЋВПЪЙгУЪ§ОнПтЬсЙЉЕФздЩњГЩIDЁЃШчЃК
| |
Blog_id |
content |
ЁЁ |
0 |
0 |
ЁЁ |
ЁЁ |
ЛЕДІ:
1.IDЛьТвЁЃШчЙћЪЙгУЪ§ОнПтЬсЙЉЕФздЩњГЩIDЃЌЭЌЪББэжаЛЙгавЛИіРрЫЦгажїМќКЌвхЕФBlog_idЃЌетбљКмВЛКУЃЌШнвздьГЩТпМЛьТвЁЃгЩгкЮФЕЕЪ§ОнПтВЛжЇГжIDЕФжиУќУћЃЌЯАЙпЙиЯЕЪ§ОнПтзіЗЈЕФШЫПЩФмЛсдйНЈСЂвЛИіздМКЕФТпМIDзжЖЮЁЃетЪЧУЛгаБивЊЕФЁЃ
2.Ыїв§ХгДѓЃЌадФмЕЭЯТЁЃIDЪЧЪ§ОнПтЕФЗЧГЃживЊЕФВПЗжЁЃIDЕФГЄЖШНЋОіЖЈЫїв§(АќРЈжїМќЕФЫїв§)ЕФДѓаЁЃЌжБНггАЯьЕНЪ§ОнПтадФмЁЃШчЙћЫїв§БШФкДцаЁЃЌадФмЛсКмКУЁЃЕЋвЛЕЉЫїв§ДѓаЁГЌЙ§ФкДцЃЌГіЯжЪ§ОнНЛЛЛЃЌадФмЛсМБОчЯТНЕЁЃвЛИіLongеМ8зжНкЃЌвЛИі20ИізжЗћЕФUTF8
StringеМгУдМ60ИізжНкЁЃЯрВю10БЖжЎОоЃЌВЛФмВЛПМТЧЁЃ
НтОіЗНАИЃК
ОЁСПЪЙгУгавЛЖЈвтвхЕФзжЖЮзіIDЃЌВЂЧвВЛдкЦфЫћзжЖЮжажиИДГіЯжЁЃВЛЪЙгУИДдгЕФЪ§ОнРраЭзіIDЃЌжЛЪЙгУint,longЛђепЯЕЭГЬсЙЉЕФжїМќРраЭзіIDЁЃ
ЮФЕЕЪ§ОнПтЕФЗДФЃЪНзмНс
ВћЪіСЫетУДЖрЕФЗДФЃЪНЃЌЯТУцгаИівЛРРБэЃЌКИЧСЫЩЯУцЫљгаЕФЗДФЃЪНЁЃетИівЛРРБэЃЌЪЧАДееЮФЕЕЪ§ОнПтФЃаЭНЈСЂЕФЁЃЪЧИіЮФЕЕЪ§ОнПтФЃаЭЕФР§згЁЃ
| |
ЗДФЃЪНУћ |
ЮЪЬт |
0 |
ДцдкУшЪіЖрЖдЖрЕФЙиЯЕБэ |
[{IDЃК00
жЂзДЃКЮФЕЕЪ§ОнПтжаДцДЂдкгаДПДтЕФЙиЯЕБэ
ЛЕДІЃК[ЦЦЛЕЪ§ОнЭъБИадЃЌЫїв§Й§Жр]
НтОіЗНАИЃКМгШывЛИіListзжЖЮ
},{
IDЃК01
жЂзДЃКЙиЯЕФЃаЭВЛЧјЗжЁАвЛЖдЖрЁБКЭЁАЖрЖдвЛЁБ
ЛЕДІЃКЖюЭтЫїв§
НтОіЗНАИЃККЯРэЕФАВХХзжЖЮЕФЮЛжУ
}] |
1 |
ДІДІв§гУПЭЛЇЖЫJoin |
[{
IDЃК10
жЂзДЃКВщбЏЕФЪБКђашвЊДѓСПЕФЪжЖЏJoinВйзї
ЛЕДІЃК[ЪжЖЏJoinЃЌЖрДЮВщбЏ, ЪТЮёДІРэЗБЫі]
НтОіЗНАИЃКЪЪЕБЪЙгУФкСЊЪ§ОнНсЙЙЁЃ
}] |
2 |
РФгУФкСЊКѓЛМЮоЧю |
[{
IDЃК20
жЂзДЃКЦЕЗБВщбЏвЛаЉФкСЊзжЖЮЃЌЖЊЦњЦфЫћзжЖЮ
ЛЕДІЃК[ЮоIDдМЪјЃЌЫїв§ЗКРФ, адФмРЫЗб]
НтОіЗНАИЃКЪЙгУв§гУДњЬцФкСЊСЫ,дЪаэжиИДЪ§Он
},{
IDЃК21
жЂзДЃКList,MapРраЭЕФФкСЊзжЖЮВЛЖЯХђеЭЃЌЖјЧвУЛгаЯожЦ
ЛЕДІЃК[ВхШыЪЇАм, адФмЭЯгЭЦП]
НтОіЗНАИЃКЩшЖЈзюДѓЪ§ФПЛђепЪЙгУв§гУЁЃ
},{
IDЃК22
жЂзДЃКDBAЯыЕЅЖРЮЌЛЄФкСЊзжЖЮЃЌЕЋЮоЗЈзіЕН
ЛЕДІЃК[ШЈЯоЙмРэФб, ЧаБэФб, БИЗнФб]
НтОіЗНАИЃКЩшМЦЪ§ОнПтФЃаЭЕФЪБКђашвЊПМСПжЎКѓЕФЮЌЛЄВйзї
},{
IDЃК23
жЂзДЃКгІгУПЩвдЗЧГЃКУЕФдЫаадкЪ§ОнПтЩЯЁЃЕЋЪЧЕБаТЕФгІгУНгШыЕФЪБКђЛсКмТщЗГЁЃФкСЊЖЂЫРСЫгІгУ
ЛЕДІЃК[аТгІгУНгШыФб, МЏГЩФб, ETLФб]
НтОіЗНАИЃКЪЙгУЗЖЪНЩшМЦЪ§ОнПтЃЌМДгУв§гУДњЬцФкСЊЁЃБЃжЄЦфКЭЙиЯЕФЃаЭжБНгПЩвдДцдкгГЩфЙиЯЕ
}] |
3 |
дкЯпМЦЫу |
[{
IDЃК30
жЂзДЃКгавЛаЉдЫааЪБМфКмГЄЕФQuery, ж№НЅГЩЮЊадФмЦПОБЁЃ
ЛЕДІЃК[гАЯьгУЛЇЬхбщЃЌгАЯьЪ§ОнПтадФм]
НтОіЗНАИЃКШЁЯћВЛБивЊЕФОлКЯВйзї. дЫааЕФЪБКђЃЌЪЕЪБОлКЯНсЙћ.ЪЙгУЕкШ§ЗНЪЕЪБЛђЗЧЪЕЪБЙЄОпЁЃШчHadoopЃЌStorm.
}] |
4 |
АбФкСЊMapЖдЯѓЕФKeyЕБзїIDгУ |
[{
IDЃК40
жЂзДЃКЮФЕЕЪ§ОнПтжЇГжФкСЊMapРраЭЁЃНЋЦфжаMapЕФKeyЕБзїЪ§ОнПтЕФжїМќРДгУЁЃ
ЛЕДІЃК[ЮоЗЈЭЈЙ§Ъ§ОнПтзіИїжж(><=)ВщбЏЃЌЮоЗЈЭЈЙ§Ыїв§ВщбЏ]
НтОіЗНАИЃКЪЙгУЪ§зщ+MapРДНтОіЁЃ
}] |
5 |
ВЛКЯРэЕФID |
[{
IDЃК50
жЂзДЃКгУStringЩѕжСИќИДдгЪ§ОнНсЙЙзїЮЊЕФIDЃЌЛђепШЋВПЪЙгУЪ§ОнПтЬсЙЉЕФздЩњГЩIDЁЃ
ЛЕДІЃК[IDЛьТвЃЌЫїв§ХгДѓ]
НтОіЗНАИЃКОЁСПЪЙгУгавЛЖЈвтвхЕФзжЖЮзіIDЁЃВЛЪЙгУИДдгЕФЪ§ОнРраЭзіIDЁЃ
}] |
БОЮФЪдЭМзмНсСЫБЪепжЊЕРЕФживЊЕФЮФЕЕЪ§ОнПтЕФЗДФЃЪНЁЃЯждкЙигкNoSQLЪ§ОнФЃаЭЩшМЦФЃЪНЕФЬжТлВХИеИеЦ№ВНЃЌНЋРДвВаэЛсж№НЅздГЩЬхЯЕЁЃЖдгкСаЪ§ОнПтКЭKey-ValueЕФЗДФЃЪНЃЌБЪепЕШЕНгаСЫзуЙЛЛ§РлЕФЪБКђЃЌдйКЭДѓМвЗжЯэЁЃ
| 

