|
摘要:基于可靠性的需求,各个公司对容灾的要求也是越来越高。单在数据中心备份副本明显已经跟不上用户的需求,这里LogicMonitor首席架构师兼运营副总监Jeff
Behl给我们带来了Linux环境下优化Rsync作业的思想。其中涉及到备份作业状态的存储、简易备份操作的实现及监视等。
Jeff Behl ―― LogicMonitor首席架构师兼运营副总监,拥有20多年的监管经验,为多家基于SaaS公司提供架构和监管支持。
用于灾难性恢复的数据备份
灾难恢复计划中不可或缺的一部分就是确保用户数据储存在多个位置。LogicMonitor――用于实体、虚拟以及云环境基于SaaS的监视方案,我们希望用户数据文件的副本在数据中心内外都有储存。前者是为了预防设施中单个服务器失败,后者则是防范整个数据中心的丢失。
在Linux环境中使用Rsync
像每个人在Linux环境下开始所做的事情一样,我们使用Rsync拷贝数据。
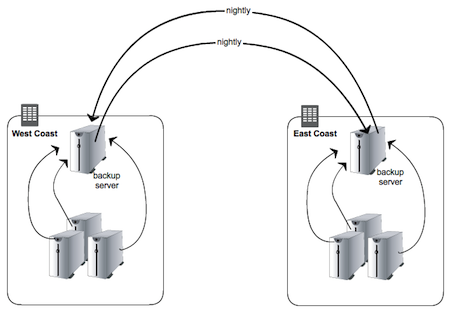
只要服务器的数量、数据的数量以及文件的数量不是非常巨大,Rsync都是可靠、准确以及经得住考验的。然而当数据体积超出预期,将不可避免的出现一些问题;一旦Rsync作业数量超出掌控,你就必须面对以下问题:
- 备份作业重叠
- 备份作业次数增加
- 同时发生的作业太多以至于服务器和网络过载
- 作业完成时,额外步骤的协调将变的异常困难
- 作业数量、作业统计的监视以及故障报警将难以实现
在LogicMonitor我们的理念和深入信仰的理由就是基础设施中的一切都需要被监视,而失去监视Rsync作业的能力无疑是非常糟糕的(而且我们也不相信通过电子邮件来监视作业的状态!)。我们需要更好的统计和警报,不仅是为了记录备份作业的状态,也为了保障作业逻辑的进行(不会因为同时执行的作业太多而失败)。
显而易见的方案就是将这些信息储存到数据库中,那么就会用到一个储存备份作业元数据的数据库
―― 作业可以在这里更新自己的状态,而其他的组件可以从这里获得信息用来协调任务(比如删除过期作业)。同时我们可以通过一些简单的查询来获得备份作业的状态,比如:正在运行的作业数量(全部或者单服务器),上次备份至今的时间,备份作业的体积等等。
使用MongoDB存储备份作业元数据
作业统计的类型不可能是始终如一的,所以MongoDB弱数据结构模型的文件存储设计将非常适合:易安装、易查询、弱数据结构模型、JSON结构(易于存储作业信息)。MongoDB的出色还在于性能以及易维护性。对比MySQL,MongoDB副本集成员的增加是自动管理的。
这样的话首要思想是继续使用Rsync,但是使用MongoDB来追踪作业的状态。然而这只是一个“蹩脚的组装”,我们只将所有类型的报告以及查询逻辑组装到了Rsync周围的脚本中。备份作业的元信息和真实的备份文件仍然是分开的
―― 元数据储存于MongoDB中而备份文件驻留在一些系统的磁盘上。如果能整合数据和数据库,岂不是非常完美。如果我想查询一个指定的备份作业,然后使用同样的查询语言查询一个待备份文件并进行备份。如果只需要一个简单的查询就可以对数据进行恢复……进入GridFS。
为什么GridFS
如果你在MongoDB网站上阅读了详细的GridFS介绍,我只想说这是一个叠加在MongoDB上的简单文件系统(文件被简单的分块并储用同样的方式进行储存)。取代使用Rsync脚本,完美的恢复脚本同时将数据和元数据存储到了同一个地方,所以可以简单的查询任何东西。
当然MongoDB通过GridFS响应工作,这就意味着需要备份的文件会立即在数据中心内外同时进行复制。通过一个Amazon
EC2中的副本,我们可以使用Snapshots根据需要得到任意数量的备份。我们现在的结构会像这样:
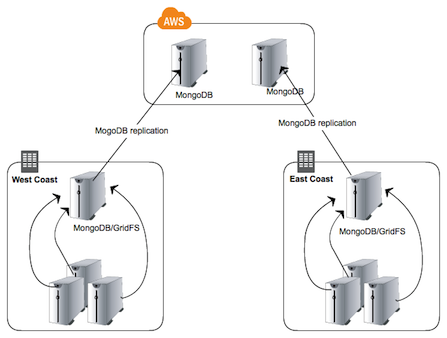
优势所在:
- 通过简单的查询就可以获得作业状态信息
- 通过备份作业本身(包括文件)可以通过查询进行恢复和删除
- 基本上可以做到站点之外位置的实时复制
- 合理的分片
- 通过EBS,MongoDB可以使用Snapshots轻松的进行无限制备份。
- 轻松的实现自动化监视
通过LogicMonitor进行监视
LogicMonitor的宗旨是让你基础设施的所有方面(从实体层到应用程序层),都会出现在同一个监视系统中:UPS、底盘温度、操作系统状态、数据库统计、负载平衡器、缓存层、JMX统计、磁盘延时等。它应该随处可见,包括备份。出于这个目的,LogicMonitor应该不只能监视MongoDB统计和状态,还可以对MongoDB执行任何需要的查询。这些查询可以是任意的,从登录统计到页面访问量再到前一个小时内执行的备份作业。
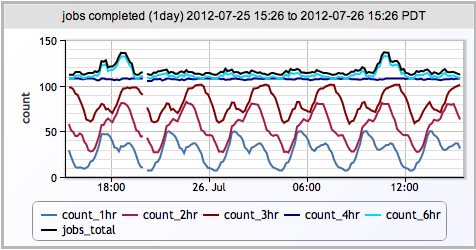
现在我们的工作基本上完全的通过MongoDB执行,我们可以针对以下的几点进行跟踪(比较重要,需要注意的几项):
- 单个服务器运行的备份作业数目
- 所有服务器同时执行的备份作业数量
- 任何用户数据的备份间隔不能高于6个小时
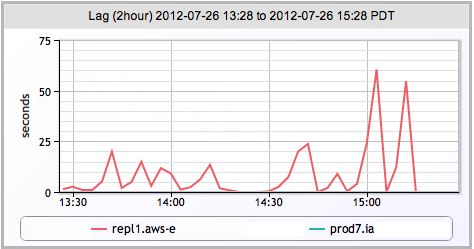
- MongoDB同步的延时
Replication Lag
Jobs Completed
| 

