一、开篇
距离上篇《Step by Step-构建自己的ORM系列-开篇》的时间间隔的太久了,很对不住大家啊,主要是因为有几个系列必须提前先写完,才能继续这个系列,当然我也在
写这几个系列的过程中,对ORM这个系列中的原来的实现的想法有了新的认识和改进,当然这些都不是说是很先进的思想或者认识,也可能是大家见过的思路吧,希望后面我能在
写设计模式系列的过程中,穿插讲解ORM系列,当然我的这个构建的系列,也只能说是很简易的,自己平时开发个小应用工具或者什么的,可能用他,因为是自己开发的嘛,毕竟使用起来还是比较顺手的!符合自己的操作习惯嘛。
当然我写这个系列的过程中,也会有自己认识偏激的地方,或者思路不正确的地方,还请大伙多多指出和批评。我也是在我目前的项目中学习到了很多的宝贵的经验,其实我们应该能看到ORM给我们提供的方便和不便之处,我们取其精华,剔除糟粕,不过这真的很难。我其实对一些流行的ORM的底层实现,研究的不多也不深,像Nhibernate,我只是了解Hibernate,是当时从JAVA中了解过来的,不深入,Castle框架倒是用过一段时间,EntityFreamWork,我也没有用过,只是象征性的下载最新版本,体验了下AOP的方式,我感觉其实有很多的时候,我们使用AOP的方式,能够改进我们程序的灵活性。这块可能还需要大牛们多多指点。
我理想的ORM是实现持久化的透明,这个怎么理解呢?就是说我在程序的开发中,我不想在业务代码中书写相应的持久化操作,也不关心业务层中的去如何调用你的
ORM,去完成CRUD的操作。我只关心我的业务逻辑,这个有点像DDD(领域驱动开发)里面的领域层了,只关心领域内部的业务逻辑,而不关心其他的东西,这样方便我们快速的抓住关注的东西,而尽量让与领域无关的东西不要影响业务领域逻辑的实现。
二、摘要
本篇主要开始讲述《Step by Step-构建自己的ORM系列-数据访问层》关于数据访问层的部分,其实前面也对这块的内容有了一定的介绍了,其实本篇就是教你如何完成
ORM中的数据访问层的操作,这里是提供统一的数据访问方法的实现。当然这里的操作还是主要集中在数据库的操作,包括如何根据实体对象返回实体的列表,包括生成SQL语
句的几类实现,还包括一些实现后续的ORM的配置管理的维护,这里就是提供可视化的XML文件的配置,这个具体怎么来做呢?因为我们平时针对ORM的使用,都是直接修改XML文件,我们可以提供一个可视化的界面,让那个用户配置这些相应的设置。通过这些配置,我们可以实现数据库的平滑的迁移,缓存应用的配置,包括其他的一些相关设置信息。总体来说这些操作都可以依托于,我们这里的数据访问层来完成。
我们来看看ORM中数据访问层的重要作用和地位吧:
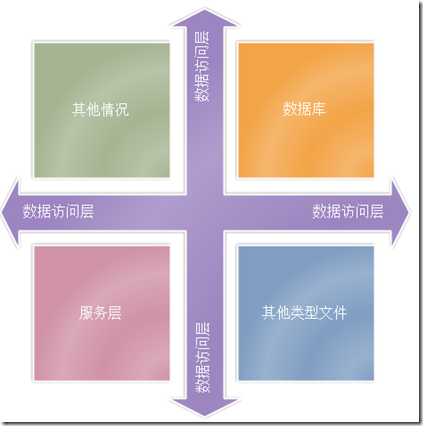
上图我们知道,我们所有的相关功能的基础,都是基于数据访问层来做的,所以我们处理好这个层的相关逻辑后,后续的问题就会比较容易开展。下面我们就会针对这些疑问开始一个个的解决我们的数据访问层应该提供的相关功能!大体的功能应该有如下功能:
1、持久化的操作方法CUD。可以扩展提供创建表+其他的修改表等相关的自动脚本工具。提供持久化透明的方式。
2、提供缓存服务,将对象的相应映射信息缓存起来,这样后续执行生成语句等操作,效率上会是很大的提升。
3、我们在处理对象对于Update语句,应该能处理好只能更变化的信息,如果没有发生变化,那么我们是不是不用执行更新操作了呢?减少数据库的操作次数。
4、提供基础的查询方法,以后所有的基于ORM上的查询基于这个查询进行扩展。提供持久化透明的查询方式。
5、并发和事务的控制。我们这里可能提供一个内部的版本号的方式来做,一旦修改过这个对象或者发生改变,任何时候的操作,我们都是针对这个版本号的记录来做的,版本号
通过内部提供的方法来进行。
三、本文大纲
1、开篇。
2、摘要。
3、本文大纲。
4、ORM之数据访问层分析。
5、ORM相关代码实现。
6、本章总结。
7、系列进度。
8、下篇预告。
四、ORM之数据访问层分析
我们先来针对上面的几个问题,我们给出实现思路,来分析下给出的思路的可行性和如何实现的解析。具体的代码下节给出核心实现方案。
4.1、提供通用的持久化的操作
这个具体的解析在上篇中已经给出了相应的思路了,我们通过在底层提供相应的方法来做。一般来说,对应数据库的四种操作,我们在数据访问层,也提供了相应的语句的
自动构造的过程,具体的构造,我们前面给出的实现方案是通过特性来实现,特性中定义具体的数据库字段,类型,长度等一些列的参数。我这里就不复述了,我这里分析下我们
这样实现的好处。我们知道继承的方式是挺好的,我为什么这么说,通过提供一个基类,基类中定义通用的CUD的操作方法,这样只要是继承这个类的子类,都会有CUD的操作方法了,但是我们为了提供持久化透明的方案,那么无疑,对于持久化的操作,我们就不希望由业务逻辑层中的业务逻辑对象来完成,那么如何来做呢?我们通过数据访问层,提供统一的操作方法,让服务层来完成业务对象的持久化操作。这样就能实现,持久化透明的方案。
所以我们可以这样来做,在数据访问层中,我们提供一个接口,接口中定义持久化操作的几类方案,通过不同的实现配置,我们可以在XML配置文件中进行指定,我们采用
重量级的ORM还是轻量级的ORM,这样我们也理想的实现了低耦合的特性。同时,对于不同的文件的操作,我们可以支持多文件类型的写入,当然对于不同的数据库存储,如果我们利用关系型数据库我们需要ORM,对于对象数据库的操作,或者
XML文件的操作,我们这时候的ORM就变了。
4.2、提供缓存服务
我们知道,我们第一篇中主要是通过自定义特性+反射的形式来处理:我们并没有提供完整的特性操作,其实还有很多的情况,比如说,我们还可以提供对视图的映射,提供一个视图的特性等。还有其他的特性有很多,后续会给出完整的代码结构,我们知道自定义特性+反射,如果每次在将对象映射成数据库表的时候,那么效率上是多么的低下啊,那么这个时候,我们可以考虑使用缓存的方式,将数据库表中的数据库列与对象中的属性列进行映射,我们可以把这些对应关系放在缓存中,那么如果我们在后续的处理中遇到与数据库相关操作,需要进行对象映射的时候,我们都先会去缓存中查找有没有指定键值的映射数据库表列存在,存在取出生成SQL语句,否则通过反射取出对应的数据库表列,放在缓存中。下面给出示意图。将这个过程进行描述:
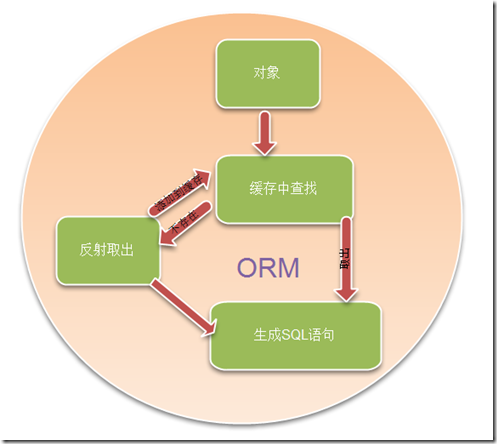
当然我这里给出的肯定是反向的根据对象生成操作数据的SQL语句的方式。这里没有考虑,当数据库表发生变化的时候,我应该自动同步缓存中的映射集合信息,当然我们可以通过一定的策略,来实现这样的双向同步问题。例如如下的方式可能就是可行的方案。
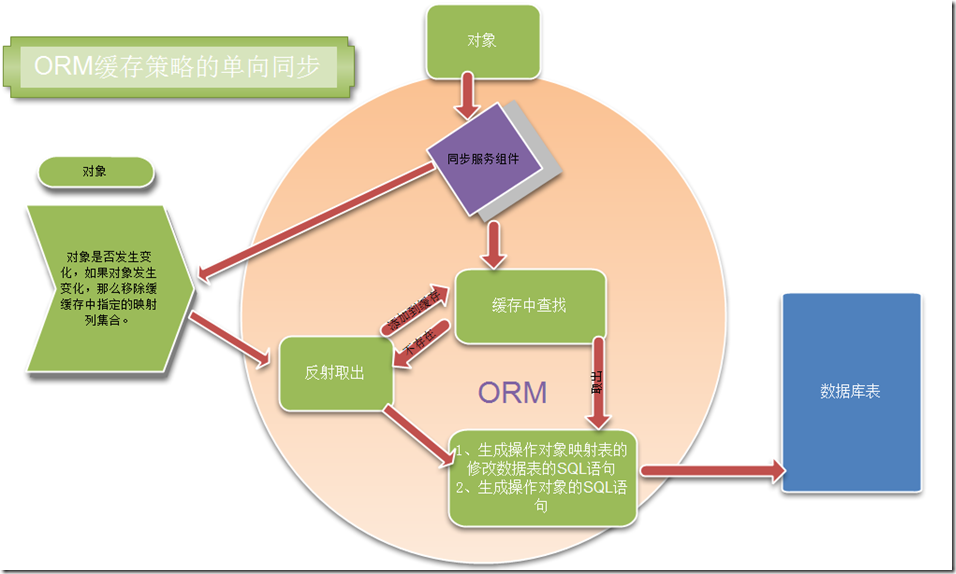
通过上述的方式,我们通过同步组件,在每次进行数据操作之前,我们可以应用更好的策略,比如记录或者遍历文件的修改状态,对比文件的最后修改日期,是不是发生修改,或者当某个文件发生修改之后,我们记录在某个配置文件中,这样我们可以提高同步的效率,因为通过这样的方式,我们不需要每次检查对象是不是发生变化了,这样我们如果发现对象没有发生变化,那么我们就不要让同步组件去检测对象是否发生变化,这样就能提高效率,同时支持当映射对象发生变化的时候,我们不用修改我们的关系数据库。大家都知道,面向对象设计建模与关系数据库的最大难题就是双方的变化的同步性的方案是很难定的,我这里只是给出一个简单的思路和方式,可能还有更好的方案,也请大家多多告诉我。
4.3、Update语句的操作
我不知道,你们在面试的时候,如果你经常开发底层的面向对象的ORM的时候,应该会遇到这样的问题,我们在查询一个映射对象的时候,我们可能只需要取出这个对象的部分列,而不是全部的数据列,这个时候,我们如何指定呢?就是填充对象的时候,我们只需要填充指定的列?或者我们需要在在保存编辑的时候,我们不更新未发生变化的数据库,其实主要是要求,我们在生成SQL语句的时候,我们希望我们的更新语句中不要出现,没有发生变化的数据列的设置,这个如何做到呢?我想我们可以通过如下的2种方式来做。
1、通过对象的序列化,来复制一个对象,并且系统中缓存这个对象,在编辑之前,缓存,等到提交后,释放这个对象。这个由系统默认的提供方法。前提是标记对象是编
辑状态,这样在修改对象之前进行复制,不然如果修改完了,再复制就没有什么意义了
2、通过字典来保存更新数值的数据列,通过数据字典来存放。我们在字典中存放映射的数据列,将发生变化的数据列和数据列的值进行标记发生改变,我们在生成更新语句的时候。直接遍历这个集合,将列状态发生改变的列生成相应的操作语句即可。这些都是可行的方式,我们在前面的架构设计中也提到过的。都是给过思路的,这里我也不多复述了。
3、…。可能还有其他的更好的方式,还请大家多提出好的思路,我备注在这个位置!
4.4、提供基础的查询方法。
这里说的提供基础的查询方法,指的是基于数据库操作之上,我们提供几个常用的查询方法,包括自动生成版本号的方法等,我们的版本号可以通过日期+流水号的形式来生成,或者是其他的情况。GUID也是可行的办法。不过维护起来可能不是很方便。所以底层提供相应的操作方法更容易来做。
我们这里考虑提供如下的基础查询方法,复杂的查询方法,我们可以提供一个入口来做。例如我们提供如下几类方法:
1、底层生成版本号的方法,自增ID流水号,根据不同的生成规则自定义设置ID生成规则,来组织生成ID的通用方法。
2、提供实体与数据库行集之间的转换,我们需要将数据库记录转换为实体集合。通过查询方法返回对象集合。这里提供返回指定主键的对象集合。
3、返回一个数据表或者视图中的所有记录。
4、返回传入分页个数,和分页排序字段,分页条件的分页集合。
5、返回指定列的查询方法。(这里没有想到好的办法,怎么样的形式比较灵活能够动态的指定返回的列,比如说1列,10列,5列等),希望大家提出好的意见和建议!
6、提供统一的入口,编写SQL语句传入到数据访问层中进行查询和检索,根据指定的返回类型来返回泛型对象。
4.5、并发和事务控制
我想一个系统中必须考虑的就是事务处理了,我们进行批量操作的时候,如果数据不同步,那就太痛苦了,也是不能使用的系统的,我们希望我们的ORM能够自动的集成事务和并发,当然这里说的并发是当用户数上升到一定量的时候,就会产生这样的问题,理论上来说只要有2个以上的用户,就必须考虑并发操作!并发我们有几个控制的思路,总体来说应该说说我们前面的设计的内部的一个自动生成的版本号,是最好的选择。具体怎么个意思呢?我们来解释下:对于并发控制,我们知道,并发控制的问题:写丢失,读出来的数据是脏数据,无疑就是这么2个比较常见的问题,那么我们如何来对写丢失进行限制呢?目前通用的方案都是通过乐观锁来处理,二个人可以同时对某个信息进行读取,但是只能有一个人在进行编辑,但是最后修改的内容会把前面修改的信息覆盖掉,这是乐观锁的处理方式。悲观锁,则是只要有人在修改,那么可能你不能进行修改,也不能读取,这种方式,当然可以保证信息的修改的同步性和一致性,但是用户的易用性和友好性方面不够人性化,相比来说,有人修改,就不能被其他人修改,但是可以读取的方式体验方面要差一些,不过各有使用的场景,一般来说,悲观锁是乐观锁的一个补充。我们这里既不是乐观锁,也不是悲观锁的形式,通过版本来对某个记录的版本进行记录,一旦发生改变,那么记录的版本就要发生变化,我们这里对这个行集的版本的更新可以通过ORM提供的版本的生成规则来生成一个版本号,或者是通过触发器来实现,当然性能也是我们需要考虑的部分。对于事务,我想一般的不是分布式操作的应用,我们通过数据库提供的本身的事务服务来完成,基本上就可以满足日常的需求,也没有什么特别难的地方,我想这里我也就不详细的说了,我们来简单的说下,分布式事务的一致性,对于这种分布式的事务操作,我们可以采用离线并发模式来处理。这个怎么理解呢?就是通过工作单元来实现。我们把每一个操作看着一个工作单元,如果我们在执行某个事务操作的过程中,如果返回是0或者是其他的不是我们期望的结果时,我们不会进行任何的提交操作,如果全部执行通过,我们循环所有的工作单元进行提交,否则我们回滚所有的系统事务。我们把这样的分布式事务,看作一个业务事务,由一些列的工作单元组成,这些工作单元看作是系统事务。
五、ORM相关代码实现
5.1、CUD的基本实现代码:
1,Create语句的实现:
private Dictionary<string, Column> _autoIncrementColumns
= new Dictionary<string, Column>();
private Dictionary<string, Column> _updateColumns
= new Dictionary<string, Column>();
public string TableName
{
get
{
return string.Empty;
}
}
public Dictionary<string, Column> UpdateColumns
{
get
{
return this._updateColumns;
}
set
{
this._updateColumns = value;
}
}
public Dictionary<string, Column> AutoIncrementColumns
{
get
{
return this._autoIncrementColumns;
}
set
{
this._autoIncrementColumns = value;
}
}
public virtual IDbCommand GetDbCommand()
{
// 如果column的值没有被更新过,则返回null
if (this.UpdateColumns.Count == 0)
{
return null;
}
ArrayList fieldList = new ArrayList();
ArrayList valueList = new ArrayList();
SqlCommand cmd = new SqlCommand();
foreach (Column column in this.UpdateColumns.Values)
{
fieldList.Add("[" + column.Key + "]");
valueList.Add("@" + column.Value);
}
string fieldString = string.Join(" , ",
(string[])fieldList.ToArray(typeof(string)));
string valueString = string.Join(" , ", (string[])valueList.ToArray(typeof(string)));
string cmdText = string.Format("INSERT INTO [{0}]({1})
VALUES({2})",
this.TableName,
fieldString,
valueString);
string sqlGetIndentityID = null;
if (this.AutoIncrementColumns.Count == 1)
{
sqlGetIndentityID = string.Format("SELECT [{0}]
= SCOPE_IDENTITY()");
}
if (sqlGetIndentityID != null)
{
cmdText = cmdText + " ; " + sqlGetIndentityID;
}
cmd.CommandText = cmdText;
return cmd;
}
}
下面给出Update语句,是从上面的更新集合中编辑,将列的状态发生改变的列添加生成到语句中-示例代码如下:
public virtual IDbCommand GetDbCommand()
{
// 如果column的值没有被更新过,则返回null
if (this.UpdateColumns.Count == 0)
{
return null;
}
ArrayList fieldList = new ArrayList();
ArrayList valueList = new ArrayList();
SqlCommand cmd = new SqlCommand();
string updateSQL=string.Empty;
foreach (Column column in this.UpdateColumns.Values)
{
if (column.State)
updateSQL += "[" + column.Key + "]="
+ "@" + column.Value;
}
string cmdText= string.Format("UPDATE {0} SET
{1}={2}", updateSQL);
cmd.CommandText = cmdText;
return cmd;
}
至于删除的代码比较简单,我这里就不给出删除的代码了,总体来说形式是相同的。
5.2、缓存服务代码
我有2篇关于缓存的介绍,缓存中最难搞的问题就是缓存的过期的问题,对应反射的性能问题也是存在过期的问题,比如说我们的数据库表发生变化,或者对象中的属性发生变化后,那么我们的缓存中的内容也需要进行更新,不然我们生成的数据库操作语句将会不正确。我们这里的策略就是将映射出来的对象,放在服务器中的缓存中,当然对于B/S和C/S系统中可能采取的缓存方式和策略还是有区别的。B/S我们的缓存可以采用缓存到服务器中,或者是通过缓存服务器来完成,一般是通过Remoting来将服务器与缓存服务器完成通信。我们看看简单的示例代码吧:
public class Cache
{
private static System.Web.Caching.Cache cache = HttpRuntime.Cache;//这里是默认取当前应用程序的服务缓存。
public static object Get(string key)
{
return cache[key];
}
public static bool Remove(string key)
{
return !(null == cache.Remove(key));
}
public static void Set(string key, object value)
{
cache.Insert(key, value, null, System.Web.Caching.Cache.NoAbsoluteExpiration,
TimeSpan.FromMinutes(3));
}
}
上面给出的缓存类的示例代码,具体的操作,使用反射后,将反射后对象元数据信息缓存起来,通过对象名来缓存:
具体代码如下:
PropertyInfo[] property = null;
if (Cache.Get("") != null)
{
property = (PropertyInfo[])Cache.Get("");
}
else
{
Type t = Type.GetType("");
property = t.GetProperties();
}
通过上面的几行简单的代码就能表达出我们上面讲述的思路,具体如何过期,这个上面也给出了一些思路,可能大伙有更好的思路,我这里就不班门弄斧了。
5.3,提供基础的查询服务
我想大伙对于查询语句的操作,应该说是司空见惯了吧,我们如何能更好的完成统一的查询服务可能是我们关心的问题,我这里不会给出多数据库的实现,但是可以给大伙一个思路,我们这里定义返回的查询命令的时候,如果说支持多数据的话,可以定义一个统一的接口,不同的数据库提供不同的实现接口,然后根据统一的ORM配置来调用不同的组件来生成SQL语句,完成调用操作。
相关的查询服务代码如下:
/// <summary>
/// 系统自动生成的版本号
/// </summary>
/// <returns></returns>
public string GetVersion()
{
return DateTime.Now.Year.ToString() + DateTime.Now.Month.ToString()
+ DateTime.Now.Day.ToString() + DateTime.Now.Minute.ToString()
+ DateTime.Now.Second.ToString();
}
public int GetMax<T>()
{
//根据T的类型获取T的最大列,完成查询操作。
string sqlText = " Select MAX(ISNULL(列名,0))+1 FROM
TableName";
return 0;
}
public List<T> GetAll<T>()
{
//根据T的类型获取T的最大列,完成查询操作。
string sqlText = " Select * FROM TableName";
return new List<T>();
}
public List<T> GetList<T>(string condition,int
pagesize,string orderField)
{
//根据T的类型获取T的最大列,完成查询操作。
string sqlText = " Select * FROM TableName where
" + condition + " order by " + orderField;
return new List<T>();
}
上面给出的不是全部的代码,部分代码还是大家自己去完成吧,我这里想的是,一些客户比较复杂的自定义代码通过一个接口传入的形式,来完成基础查询服务的调用。
我们这里给出通用的接口定义:
CommandType CommandType
{
get;
set;
}
string whereCondition
{
get;
set;
}
string orderCondition
{
get;
set;
}
string TableName
{
get;
set;
}
Column[] ColumnList
{
get;
set;
}
string SQL
{
get;
set;
}
给出默认几类示例的实现:
public class BaseSQL : ISelect
{
public System.Data.CommandType CommandType
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
public string whereCondition
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
public string orderCondition
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
public string TableName
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
public Column[] ColumnList
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
public string SQL
{
get
{
throw new NotImplementedException();
}
set
{
throw new NotImplementedException();
}
}
具体调用的代码如下:
public class SpecialSQL : BaseSQL
{
public void Test()
{
this.TableName = "";
this.SQL = " SELECT * FROM TEST ";
this.whereCondition = " ID=4 ";
this.orderCondition = " ORDER BY ID DESC ";
}
}
当然这里的继承的方式不是很推荐,可以采用抽象工厂的模式,来创建这个查询对象,然后我们在调用这个查询对象的地方,我们可以自定义这个SQL查询对象,后台的ORM自动解析,完成自定义SQL语句的统一查询服务入口。当然如果您有更好的方案,可以提出来,非常感谢!
六、本章总结
本文主要是讲述ORM中的数据访问层,我这里由于一些特殊的原因,代码给出的不是特别的详细,一方面是由于之前的那部分的代码丢了,现在一时难以还原,所以造成有
些代码给出的不是特别完整的情况,请大家见谅,文章中的有些部分的内容,我在实现的过程中也是遇到了不少的问题,我现在的具体问题列出来,也请大家帮我解决一下,我的疑问,我目前在架构设计的过程中遇到如下的问题:
1、我在实现服务层持久化透明服务的时候,我也想把查询服务透明,意思就是业务对象与服务层只通过DTO来完成,业务对象的所有数据都通过服务层的访问来完成。
2、如果现在有比较复杂的业务逻辑的操作语句的时候,我的这个SQL语句放在数据访问层好呢?还是放在哪里?应该具体的职责划分要明确。
3、我只是希望业务逻辑层处理业务数据,具体的业务数据怎么来的,我想让业务逻辑只关心DTO。
4、对于这样的服务层提供的统一查询方式的话,我在表现层调用的时候,如何传参,能够很好的组织参数的传递和调用,传统的方式不再目前的考虑当中。
感谢大伙能够给出一些意见和建议!相信这个ORM系列能越来越好!
| 

