Scale
Out:横向扩展,增加处理节点提高整体处理能力
Scale Up:纵向扩展,通过提升单个节点的处理能力达到提升整体处理能力的目的
Replication
MySQL的replication是异步的,适用于对数据实时性要求不是特别关键的场景。slave端的IO线程负责从master读取日志,SQL线程专门负责在slave端应用从master读过来的日志(早期MySQL用一个线程实现,性能问题比较明显)。使用replication必须启用binary
log,MySQL用binary log向slave分发更新
复制级别
1. Row Level:5.1.5开始支持。mater记录每行数据的更改日志,slave根据日志逐行应用。优点:数据一致性更有保障。缺点:可能造成日志文件比较大
2. Statement Level:master记录每个执行的query语句以及一些上下文信息,slave节点根据这些信息重新在slave上执行。优点:binary
log比较小。缺点:某些情况下数据一致性难以保障
3. Mixed Level:MySQL根据情况选择哪种复制方式。5.1.8开始支持
常用架构
1. Master-Slaves:通常都采用这种方式
2. Dual Master(Master-Master):2个master节点互相同步更新。因为MySQL的异步复制方式,为了防止数据冲突造成的不一致性,一般仅将其中一台用于写操作,另一台不用或仅用于读操作。目的是其中一台master停机维护或者故障中断时可以使用另一台master
3. 级联复制(Master-Slaves-Slaves):在Master Slaves中,如果slaves过多replication将增加master的负载,这时可以让master只向其中几台slave分发更新日志,这几台slave作为一级节点再向下级节点分发更新日志
Cluster
主要通过NDB Cluster存储引擎实现,是一个Share Nothing的架构,各个MySQL Server之间并不需要共享任何数据。可以实现冗余(可靠性)以及负载均衡。刚开始MySQL需要所有数据和索引都能够加载到内存中才能使用Cluster,对内存要求高,目前通过改进只要求索引能全部加载到内存

MySQL Clusrer架构示意图,图片来自MySQL官方文档
1. SQL Nodes:负责存储层之外的事情,例如连接管理、query处理和优化、cache管理等,即剥离了存储层的MySQL服务器
2. Data Nodes:存储层的NDB节点,即Cluster环境下的存储引擎。每个cluster节点保存完整数据的一个分片,视节点数目和配置而定,一般data
nodes被组织成为一个个group,每个group存有一份完全相同的物理数据(冗余)。NDB存储引擎首先按照冗余参数配置来使用存储节点,然后根据节点数目对数据进行分段
3. Management Server:负责整个clsuter集群中各个节点的管理工作,它保存了整个cluster环境的配置,启动关闭各个节点,实现对各节点的常规维护、备份恢复等,它获取各个节点的状态和错误信息,并反映给整个集群中所有节点
Cache
1. 应用层cache:最普通的cache方式,应用层自己管理cache,与数据库无关
应用层cache的选择方案很多
a). Memcached:分布式的缓存,本身性能优秀,扩展性比较好;虽然比本地缓存方案慢,但具备共享缓存效果
b). Berkeley DB:与Memcached相比,BDB实现本地缓存;Memcached是内存式的缓存,而BDB使用磁盘,成本不一样;Memcached仅支持hash索引,而BDB支持hash索引和B-Tree索引;MySQL数据库方案下使用BDB,主要出于扩展性方面考虑,以及BDB的hash索引可以比MySQL更有效
2. MySQL-Memcached整合:有2种方式
a). 直接用Memcached作为MySQL的二级缓存。这可以增加MySQL的缓存容量,而Memcached对于应用端是不可见的。这种方案适用于一些特定场景,例如数据实在难以切分、很难对应用程序进行改造等
这种方案目前有Waffle Grid开源项目,仅支持InnoDB存储引擎。其原理是当MySQL在Local
Buffer Pool中找不到数据时则从磁盘读取,而Waffle Grid在这里加入一段处理,先尝试从Memcached
Server读取,如果Memcached Server中不存在,才通过磁盘IO读取,将读取的数据会存入Memcached,并记录在InnoDB
Buffer Pool的LRU List中,如果数据变成dirty或者缓存管理将其清出时,InnoDB将对应的LRU
List移入FLUSH List,此时Waffle Grid从Mamcached Server删除数据。从上面可以看出,缓存机制仍然由MySQL管理,Memcached中存放的仅为有效的(不是脏数据)、仅作为缓存目的的数据,Memcached
Server崩溃停机等不影响MySQL数据
架构示意图(《MySQL性能调优与架构设计》):
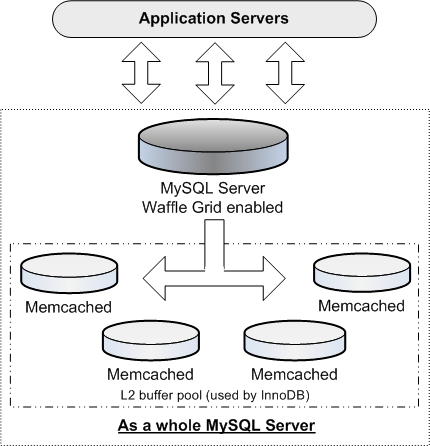
Waffle Grid是否会因为网络访问开销导致查询性能下降呢?可以参考Waffle Grid DBT2的测试结果,以及实际测试进行评估
b). 使用MySQL的UDF功能与Memcached进行整合。Memcached的数据由MySQL和应用端程序共同维护,应用端先从Memcached读取数据,读取不到时则从MySQL
Server读取,并把数据写入Memcached中,而数据有更新、删除导致Memcached数据失效时,MySQL负责将Memcached中相应数据清除
架构示意图(《MySQL性能调优与架构设计》):

MySQL Memcached UDFs下载和使用参考Using
the MySQL memcached UDFs
数据切分、Sharding
分为垂直切分和水平切分,垂直切包括将一个表按不同字段切分成多个表、将不同表建在不同的MySQL Server中,水平切分指将同一个表的数据切分到多个表中存储
1. 表结构设计垂直切分。常见的一些场景包括
a). 大字段的垂直切分。单独将大字段建在另外的表中,提高基础表的访问性能,原则上在性能关键的应用中应当避免数据库的大字段
b). 按照使用用途垂直切分。例如企业物料属性,可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直切分
c). 按照访问频率垂直切分。例如电子商务、Web 2.0系统中,如果用户属性设置非常多,可以将基本、使用频繁的属性和不常用的属性垂直切分开
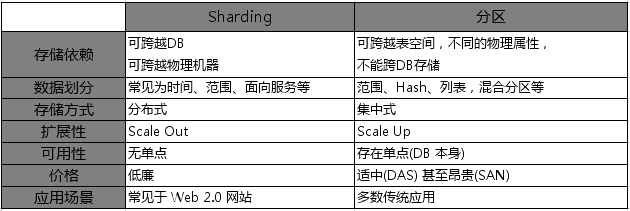
2. Sharding
Sharding指一种"shared nothing"形式的垂直切割,将切割后的部分部署在不同的服务器上。关于sharding和partition的区别可参考DBA
Notes冯大辉的开源数据库
Sharding 技术 (Share Nothing)
Sharding方案可以考虑:
a). Session-based sharding,只需在创建session时确定处理节点,随后的请求都直接定向到该节点进行处理
b). Statement-based sharding,每个语句都需要确定处理节点
c). Transaction-based sharding,根据事务中第一条语句确定处理节点
Sharding潜在问题:
a). 被分割开的部分之间无法使用数据库级别的join操作(cross-shard joins,可以考虑将一些公共的、全局的表部署到每一个节点上,使用replication机制分发)
b). 被分割开的部分之间事务处理复杂
c). 对自增长键的管理(主要出现在混合了水平切分的Sharding情况下)
3. 水平切分
示例:
a). 比如在线电子商务网站,订单表数据量过大,按照年度、月度水平切分
b). Web 2.0网站注册用户、在线活跃用户过多,按照用户ID范围等方式,将相关用户以及该用户紧密关联的表做水平切分
c). 例如论坛的置顶帖子,因为涉及到分页问题,每页都需要显示置顶贴,这种情况可以把置顶贴水平切分开来,避免取置顶帖子时从所有帖子的表中读取
难点之一,逻辑、关联关系的复杂性阻碍水平切分。这样的场景难在如何确定切分的范围和策略,例如SAP这样的大型ERP,模块、表非常多,之间的逻辑复杂,SAP按每Client(公司、集团)将整个业务数据完全切分开,如果粒度需要再细化难度就非常大。方案一般有:a).
按主键切分;b). 维护一个主切割索引表,这种方案扩展性非常好,但是需要查找主索引表
第二点是如何使得水平切分具备扩展性。以Web 2.0网站为例,如果按照会员ID范围进行切分,假如现在决定水平切分为5份,如果使用user_id
% 5的值确定该用户属于哪个部分,这样在将来随着用户量的增长,如果以后需要再切分成为20份就会相当麻烦
水平切分和Sharding的混合模式,理论上可以实现线性伸缩,但受限于应用程序的状况、设计以及切分、Sharding实现方案
切分和整合方案
主要2种实现思路:
1. 每个应用程序模块配置管理自己需要的一个或多个数据源,直接访问各个数据库
2. 通过中间代理层统一管理所有的数据源,后端数据库集群架构对前端应用透明
使用MySQL Proxy:
这是MySQL官方提供的,位于客户端程序与MySQL Server之间,能够监控、分析、转换他们之间的通讯。常用的场景有负载均衡、故障恢复、查询分析、查询过滤和修改,以及基本的HA机制,目前在实现读写分离方面仍存在一些问题,架构示意图(《MySQL性能调优与架构设计》):
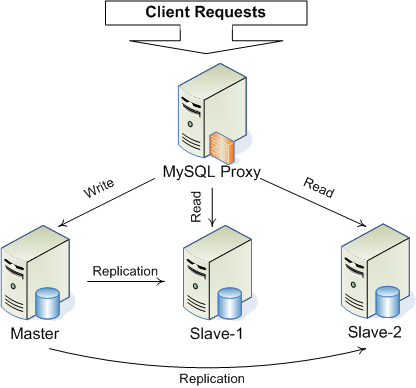
MySQL Proxy提供一个基础的框架,其他功能需要编写LUA脚本实现(牺牲一定性能,带来灵活性)
HSCALE是MySQL Proxy的一个LUA模块,他透明的分析和重写查询,切分、分区逻辑从应用程序层转移到代理层
HSCALE项目官方网站:http://www.hscale.org,作者博客网站:http://pero.blogs.aprilmayjune.org/
使用Amoeba:
Amoeba是基于Java开发的分布式数据库数据源整合Proxy程序的开源框架,Amoeba
开发者博客,项目主页
主要解决以下问题:
a). 数据切分后复杂数据源整合
b). 提供数据切分规则并降低数据切分规则给数据库带来的影响
c). 降低数据库与客户端连接
d). 读写分离路由
Amoeba For MySQL是专门针对MySQL数据库的方案,架构示意图:

图片来自《MySQL性能调优与架构设计》
Amoeba For Aiadin是个更通用的方案,他前端接收MySQL协议的请求,后端可以使用MySQL、Oracle、PostGreSql等其他数据源,这些对应用程序是透明的。架构示意图:

图片来自《MySQL性能调优与架构设计》
使用HiveDB
HiveDB也是基于Java的开源框架,有商业公司支持,目前仅支持水平切分,同时支持数据的冗余及基本的HA机制。他使用Hibernate
Shards实现数据水平切分,自行实现数据冗余机制。HiveDB中通过用户自定义的各种Partition
keys将数据分散到多个MySQL Server,访问时解析query请求,自动分析过滤条件,并行从多个MySQL
Server读取数据,合并结果集返回给客户端应用程序。架构示意图:

Hibernate Shards由Google贡献,他使用标准的Hibernate编程模型,会用Hibernate就会用Hibernate
Shards;可扩展的sharding策略;支持virtual shards,用于简化resharding时的处理
Spock Proxy
由实际项目产生的一个开源项目(Spock是Rails的应用,Speck Proxy应当可用于Rails之外的,例如PHP或.NET),基于MySQL
Proxy开发,是MySQL Proxy的一个分支,支持range-based horizontal paritioning,他对MySQL
Proxy所做的改进包括:
a). 不使用LUA脚本,提升性能。例如将多个数据源返回的结果集合并期间还要与LUA脚本交互,这样的性能开销比较大
b). 客户端登录验证。MySQL Proxy支持客户端与各个服务器直接进行登录验证,Spock Proxy则将其统一管理,分离客户端与服务器的连接
c). 动态连接池。受益于客户端登录认证机制的改善
d). 目前的MySQL Proxy无法做到读写分离,Spock Proxy实现了这一点,并且异步并行执行
架构示意图:
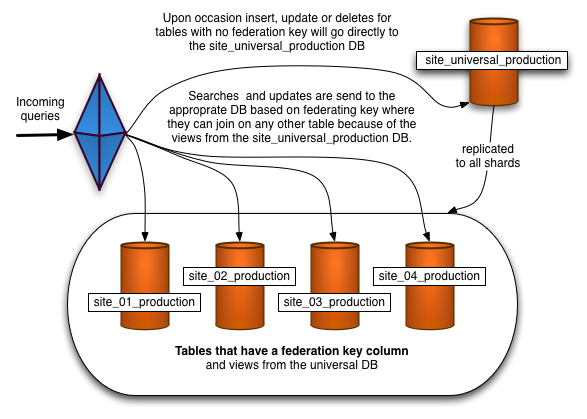
图片来自Spock Proxy官方网站:http://spockproxy.sourceforge.net/
Pyshards
基于Python的Sharding方案,是一个个人研究开源项目,他的目标想实现自动re-balancing(re-sharding),比较有挑战。目前仅支持MySQL。http://code.google.com/p/pyshards/
参考:《MySQL性能调优与架构设计》
| 

