问题和现象
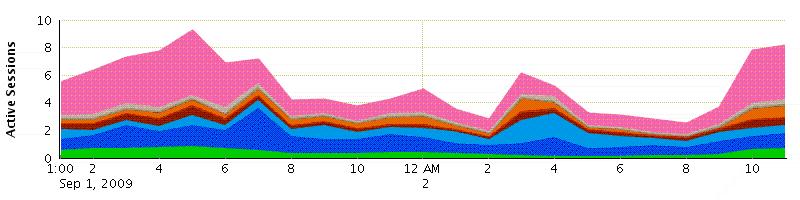
接到生产支持的同事报告:数据库反应非常慢,很多数据库操作无法完成,DB出在被hung住的状态。同时,他们通过OEM发现其中一个节点(我们的数据库是10G
RAC环境,3个节点)上发现存在很高的“Active Sessions Waiting: Other”的waits,见下图:
分析
"Active Sessions Waiting: Other"这一类的Waits是统计了RAC数据库中除IO和Idle
waits之外的所有waits事件,要分析造成这些waits的原因,我们需要知道具体是那些event导致的waits。由上图中问题出现的时间段,我取了9月1号13:00到9月2号12:00之间awr
report进行进一步分析。从awr report的top events中,得到了有价值的东西:
| Event |
Waits |
Time(s) |
Avg Wait(ms) |
% Total Call Time |
Wait Class |
|
DFS lock handle |
28,784,232 |
60,662 |
2 |
24.9 |
Other |
| db file sequential read |
4,877,624 |
54,104 |
11 |
22.2 |
User I/O |
|
enq: US - contention |
6,488,258 |
49,231 |
8 |
20.2 |
Other |
| CPU time |
|
37,748 |
|
15.5 |
|
| log file sync |
1,982,632 |
16,373 |
8 |
6.7 |
Commit |
我们可以看到,Top 5 events中,有2个events是属于Other的,也就是说,这2个event是导致系统"Active
Sessions Waiting: Other"异常的根本原因。我们再具体分析这2个events。
"DFS lock handle"这一event是在RAC环境中,会话等待获取一个全局锁的句柄时产生的。在RAC中,全局锁的句柄是由DLM(Distributed
Lock Manager 分布式锁管理器)所管理和分配的。大量发生这一event说明全局锁句柄资源不够分配了。决定DLM锁数量的参数是_lm_locks,9i以后,它是一个隐含参数,默认值是12000。没有特殊情况,这一值对于一个OLTP系统来说是足够的。我们不能盲目地直接增加资源,而是需要找到导致资源紧张的根本原因。锁资源紧张,说明存在大量事务获取了锁,但是事务没有提交、回滚。那么,又是什么导致了这些事务不结束呢?应用程序代码不完善,没有提交事务?或者那些事务还在等待别的资源?分析到此,我们暂时先放下这一event,看下top
event中的另外一个异常event。
"enq: US - contention",这个event说明事务在队列中等待UNDO
Segment,通常是由于UNDO空间不足导致的。结合对前一event的分析,初步判断正是因为大量事务在等待队列中等待UNDO资源,导致全局锁没有释放。为了验证这一判断,我分别查询发生这2个events的对象是那些。先看"DFS
lock handle"的wait对象:
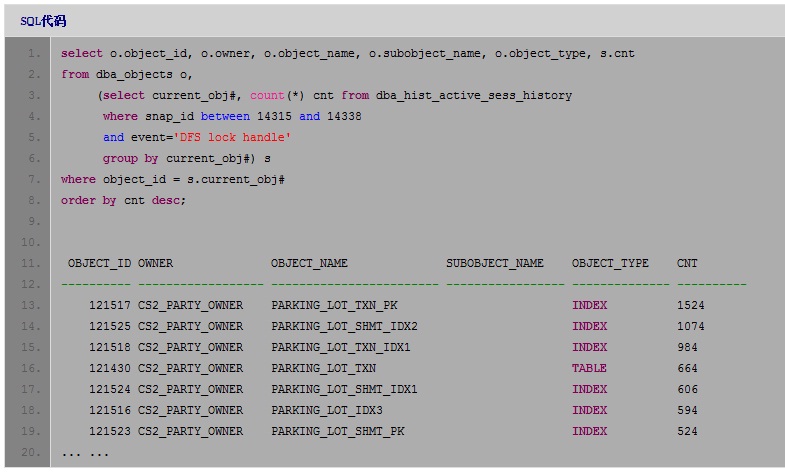
看到发生这一event的对象都是PARKING_LOT模块中的几个相关对象。再看"enq:
US - contention"的对象:
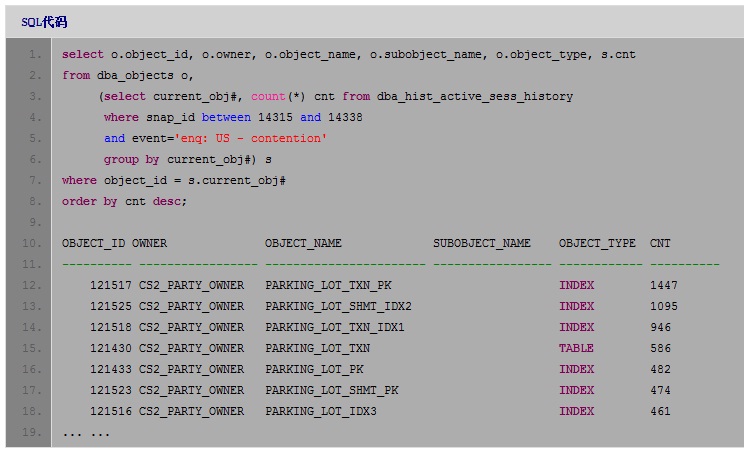
可以看到,发生这2个event的对象基本都是相同的对象。这一结果对之前的判断是一个很大的支持:"enq:
US - contention"是导致"DFS lock handle"的原因,我们需要重点着手解决"enq:
US - contention"问题。还是那句话:不要盲目增加资源,找到导致资源紧张的原因先。在我们的环境中,创建了3个UNDO
Tablespace分别指定给了3个节点,管理方式是Auto的。每个UNDO表空间的大小是20G。在这之前,从来没有出现过UNDO资源不足的问题。
首先,我想到一个可能是UNDO_RETENTION时间太长、且UNDO表空间被设置为GUARANTEE了。这样的话,会导致许多已经结束的事务的UNDO数据被保护起来不被使用,UNDO_RETENTION的时间越长,这些数据占用的UNDO空间就越多,这样就很容易导致"enq:
US - contention"问题。从awr report中看到,UNDO_RETENTION的时间设置得确实比较长:7200秒。再看一下表空间是否被GUARANTEE了:
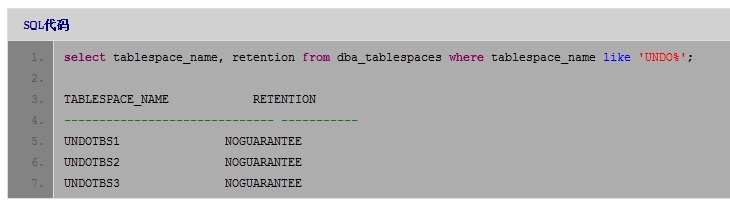
结果发现表空间并没有做retension guarantee,这一可能性被排除。
那我们再看一下到底是那些事务占用了UNDO空间,结果出乎意料:
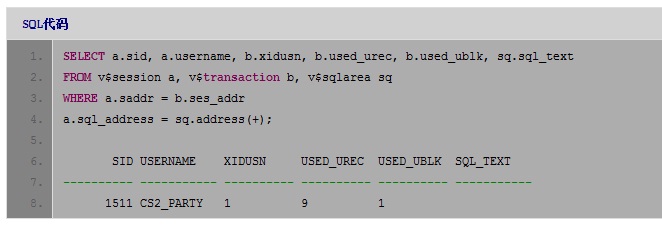
我们在该节点上并没有找到大量占用UNDO空间的事务的。那UNDO空间的实际使用情况到底是怎样的呢?

找到症结了。_SYSSMU69$这个回滚段占据了19.3G的空间!再看看这个回滚段中的扩展段(extent)的状态:
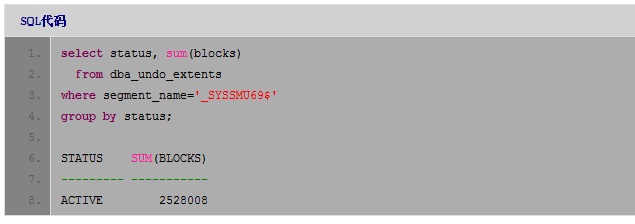
全部扩展段都是active的,正常的话,说明有事务正在使用该回滚段的所有扩展段。但实际上却找不到这样的事务:

这一点不正常。最大的可能性就是当初使用该回滚段的事务被异常终止了,导致资源没释放。这一点,通过与生产支持的同事确认,得到一个这样的事实:
1号上午,他们发现报表系统的一个housekeeping在删除一个日志表的数据消耗大量资源,影响到其它模块的运行,于是先用Kill
Session的方式杀掉会话,但是会话仍在运行(对于大事务来说,这很正常,kill session会回滚还未提交的事务,事务越大,回滚时间越久),于是就在操作系统上将该进程杀掉了。这个作业是凌晨1:00开始运行的,在删除这张表之前,会先删除其它几张表,这大概需要2、3个小时的时间,也就是说大概在4:00左右开始删除该表。那我们再查一下该回滚段是在什么时间开始激增的:
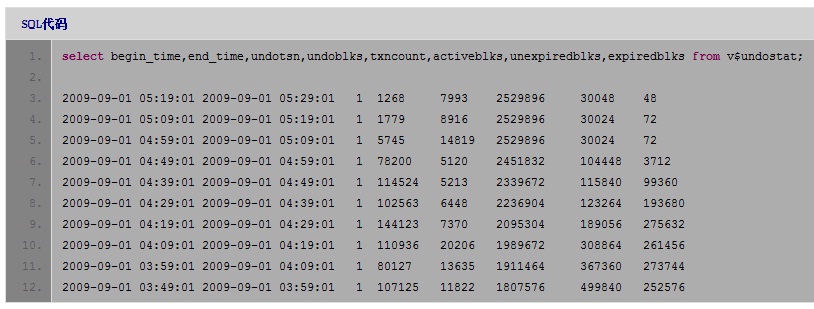
可以看到,正是在4:00左右开始急剧增长的。基本上我们可以确认正是这一异常操作导致大量的回滚段被占用也没被释放!
由于该回滚段的状态处于ONLINE状态,且其所有扩展段都是ACTIVE的,所以我们不能DROP或SHRINK它。现在,我们有两个方案来解决该问题:
- 由于对于的事务已经不存在了,我们无法通过提交或回滚事务来是否回滚段资源。那么,最直接的方法就是重启实例,重置回滚段;
- 临时解决方案就是增加或者新建一个UNDO表空间,使其它事务能正常运行。
第一个方案会影响到其它模块,只能到周末downtime的时候实施。于是采用第二个方案:临时增加了为UNDOTBS1增加了10g空间。在杀掉一些由于这些等待被彻底hung住的会话后,整个数据库恢复了正常。 | 

