| 编辑推荐: |
本文讲解对开源学习框架进行攻击,对数据进行污染攻击, 对算法模型进行逆向攻击,
对算法进行对抗样本攻击, 希望对您有所帮助
本文来自于csdn,由火龙果软件Delores编辑、推荐。 |
|
人工智能作为引领新一轮科技革命和产业变革的战略性技术,已成为世界主要国家谋求新一轮国家科技竞争主导权的关键领域。随着政府人工智能战略布局的落地实施,全球人工智能发展正进入技术创新迭代持续加速和融合应用拓展深化的新阶段,深刻改变着国家政治、经济、社会、国防等领域的运行模式,对人类生产生活带来翻天覆地的变化。人工智能在未来世界无疑将扮演重要的角色,在工业制造、医疗健康、教育、生活、安防、电商零售、金融等越来越多的领域都可以看到人工智能技术应用的身影。
机器学习算法支撑着人工智能系统。而机器学习算法在一些攻击面前脆弱不堪。机器学习通过“学习”一些相对敏感的模式而获得能力,这些模式很有用但也容易被干扰。与公众的认识相反,机器学习模型并不是“聪明的”,也无法真正模仿人类的能力。事实上,它们的工作能力来自学习一些统计学上的关联性,这些统计特性很容易被玩弄。由于完全依赖数据,数据恰恰成为扰乱机器学习模型的主要途径。机器学习完全通过从数据集中提取模式而实现“学习”。与人类不同,机器学习模型并没有可用的基础知识, 它们的全部知识都来自提供给它们的数据。污染数据,就可以污染人工智能系统。算法的黑盒特性,导致很难对其进行检查。机器学习算法(如深度神经网络)的学习和工作过程至今仍然是一个神秘的黑盒子。因此,很难判断某个机器学习模型是否被敌人渗透,甚至无法确定某个输出错误是源于遭受攻击还是系统本身性能不佳。以上特征说明,目前还没有完美的技术方案足以应对人工智能攻击。这些漏洞并非传统的网络安全补丁方式可以解决,问题源于人工智能本身的固有特性。本文概述研讨对人工智能攻击的四种方式。
攻击人工智能的四种方式:
1.对开源学习框架进行攻击
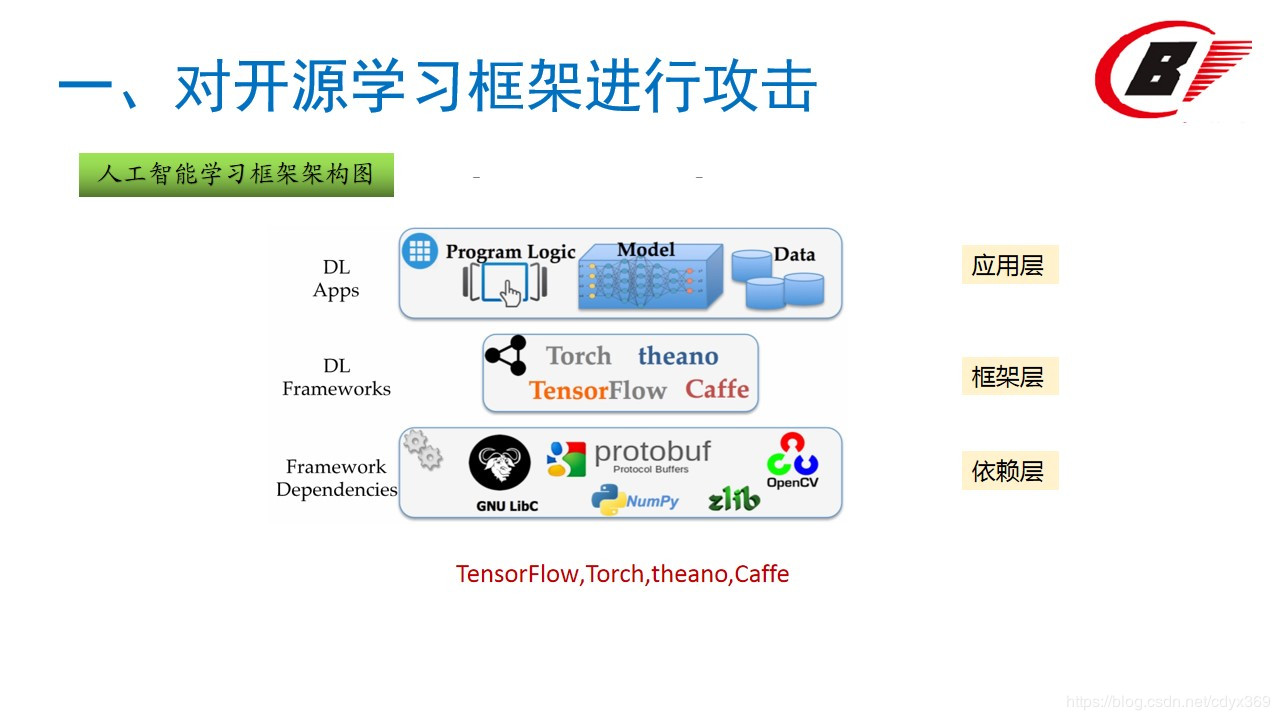
最上面一层,是开发者看得见的深度学习应用,包含应用逻辑、深度学习模型和相应的数据;中间一层是TensorFlow、Caffe等深度学习框架;最下面一层,则是底层框架依赖,也就是深度学习框架所用到的那些组件,比如说OpenCV、GNU LibC、NymPy、以及Google的protobuf等等。在一篇论文中,作者就详细分析了各个框架的依赖包及数量关系。比如说使用最广泛的TensorFlow,就有97个Python依赖库;Caffe背后,有137个依赖库,老牌框架Torch7,也有48个Lua模块。相比较而言,TensorFlow算是表现出色的,但其中也有两个Python软件包(NumPy和)存在DoS攻击风险。其实这些公开的依赖包是有安全风险的,开源计算机视觉代码库OpenCV中的漏洞最多,总共发现了11处。Caffe和Torch框架中都使用了OpenCV。另外,Caffe中还有图像处理库libjasper和图像浏览器OpenEXR的易受攻击版本。
有意思的是,研究人员还发现如何利用越界写入(out-of-bounds write)欺骗AI:在OpenCV中,数据指针可以设置为readData函数中的任何值,然后可以将指定的数据写入数据指向的地址。即可以用来改写分类结果。
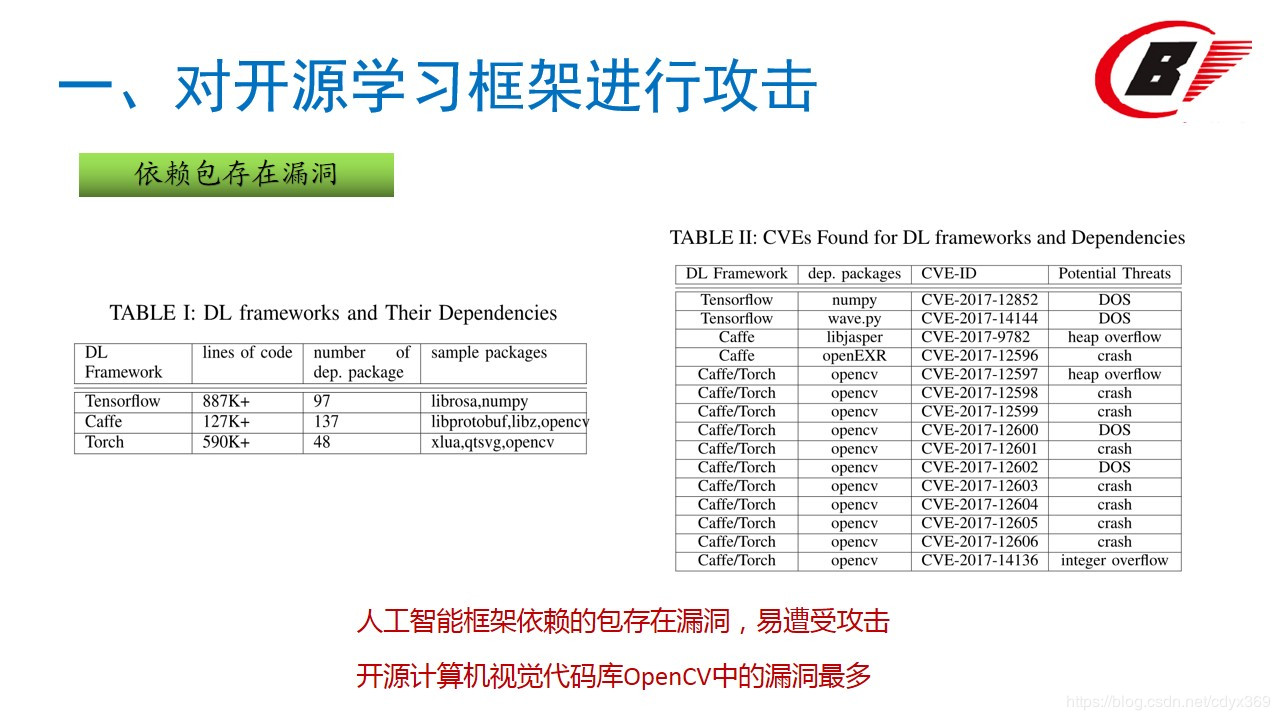

OpenCV的例子如下:
我们来详细看一下这几类攻击:
威胁一、DoS拒绝服务攻击
我们在深度学习框架中发现,最常见的漏洞是软件错误,导致程序崩溃,或者进入死循环,或者耗尽所有的内存。
威胁二、躲避攻击
面对脆弱的深度学习框架,攻击者可以利用软件漏洞实施躲避攻击,例如:1、通过漏洞覆盖分类结果,修改特定内存内容 2、劫持控制流程以跳过或重新排序模型执行。
威胁三、系统妥协
攻击者可以利用漏洞劫持控制流,或者远程控制托管深度学习应用的系统。这个情况发生在深度学习应用作为云服务运行,并从网络输入馈送时。这项研究,已经在敦促框架开发者对安全性进行改进了。作者们在论文中说:“我们的研究结果已经得到相关开发商的证实,其中很多已经根据我们的建议进行了修补。
2.对数据进行污染攻击
人工智能与数据相辅相成、互促发展。一方面,海量优质数据助力人工智能发展。现阶段,以深度学习为代表的人工智能算法设计与优化需要以海量优质数据为驱动。谷歌研究提出,随着训练数据数量级的增加,相同机器视觉算法模型的性能呈线性上升。牛津大学国际发展研究中心将大数据质量和可用性作为评价政府人工智能准备指数的重要考察项。美国欧亚集团咨询公司将数据数量和质量视为衡量人工智能发展潜力的重要评价指标另一方面,人工智能显著提升数据收集管理能力和数据挖掘利用水平。人工智能对数据有特殊的喜爱胃口,也正是因为这种数据驱动特征,导致人工智能易遭受数据污染等新型攻击。
污染型攻击(Poisoning Attacks):在人工智能系统的创建过程中偷偷做手脚,从而使该系统按照攻击者预设的方式发生故障。其中一种最直接的方法是对机器学习阶段所用的数据做手脚。这是因为人工智能通过机器学习“学会”如何处理一项任务,由于它们学习的唯一源泉就是数据,因此污染这些数据,就可以污染人工智能系统。人工智能训练数据污染可导致人工智能决策错误。“数据投毒”通过在训练数据里加入伪装数据、恶意样本等行为可破坏数据的完整性,进而导致训练的算法模型决策出现偏差。
“数据投毒”主要有两种攻击方式:
一种是采用模型偏斜方式:主要攻击目标是训练数据样本,通过污染训练数据达到改变分类器分类边界的目的;
另一种则是采用反馈误导方式:主要攻击目标是人工智能的学习模型本身,利用模型的用户反馈机制发起攻击,直接向模型“注入”伪装的数据或信息,误导人工智能做出错误判断。


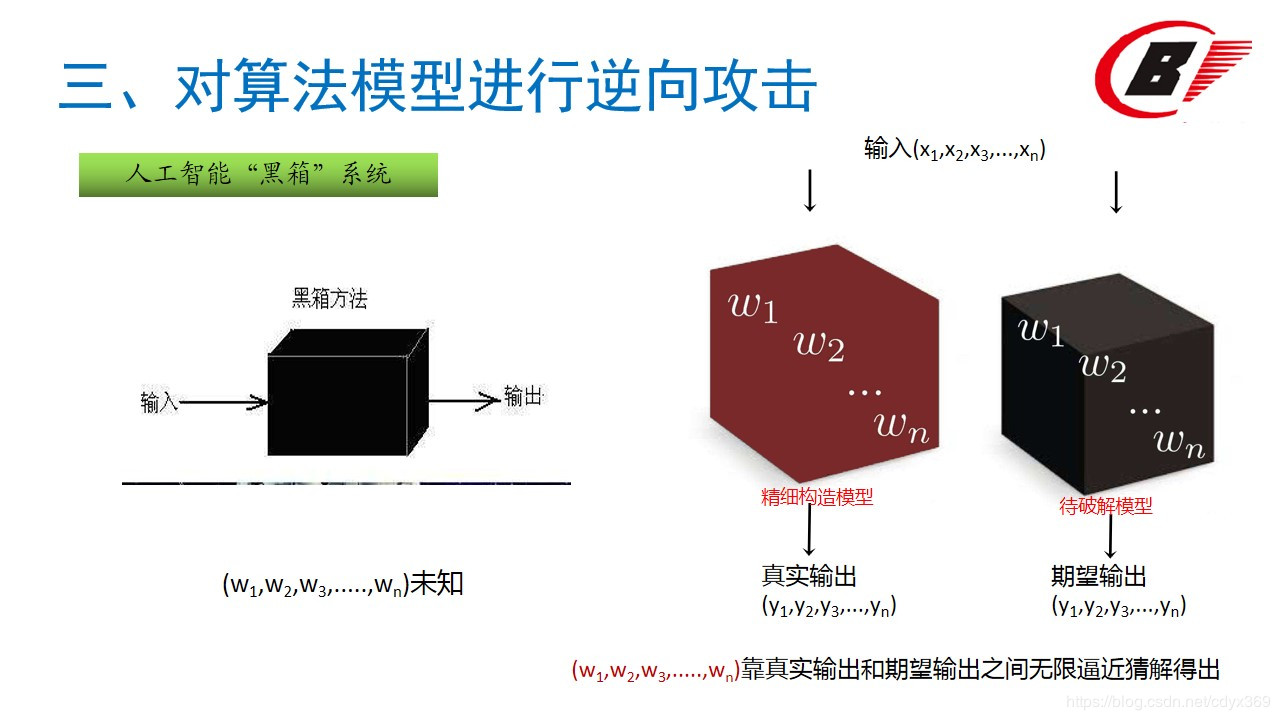
3.对算法模型进行逆向攻击
计算机科学中正迅速发展的机器学习领域,工程师们常将人工智能(AI)称作“黑箱”系统:一旦机器学习引擎经由样本数据集训练,用以执行从面部识别到恶意软件检测等各种任务,它们便能接受询问——这是谁的脸?这个App安全吗?并能自行给出答案——无需任何人,甚至是其创造者的指导,自身内部就完全理解了决策机制。
但研究人员逐渐证明,虽然这些机器学习引擎的内部机制神秘莫测,它们也并非是完全隐秘的。事实上,研究人员已经发现这些黑箱的内容物可以被逆向,甚至完全复制——用某队研究员的话说就是“窃取”,逆向和复制方法还是用以创建这些系统的同一套。9月初发表的一篇论文《通过 Prediction API 盗取机器学习模型》中,来自康乃尔科技学院、瑞士洛桑理工学院(EPFL)、北卡罗莱纳大学的一队计算机科学家,详细描述了他们是怎样仅靠发问和分析响应,来逆向机器学习训练过的AI的。通过用目标AI的输出来训练他们自己的AI,这队科学家可以产出能近100%预测被克隆AI响应的软件,有时候仅用几千甚至几百个查询来训练就行了。康乃尔科技学院教授阿里·祖尔说:“拿到黑箱,通过这个窄小的接口,你就可以重建其内部,逆向工程这个箱子。某些情况下,真能达到完美重现。”拿下黑箱内部研究人员表示,该手法可被用于允许用户上传数据给机器学习引擎,并在线发布或共享结果模型的服务。亚马逊、谷歌、微软、BigML之类的公司都有提供此类服务,有时候是以按查询付款的商业模式提供。研究人员将自己的方法称之为“萃取攻击”,该方法能复制本应专有的AI引擎,某些情况下甚至能重现当初用以训练AI的敏感私有数据。进入斯坦福大学之前忙于此AI盗取项目的EPFL研究员弗洛里安·特拉马尔说:“一旦你发现了其中模型,就不需要再为专利AI付费了,还能获取大量隐私泄露。”其他情况下,该技术可能会让黑客逆向并击溃基于机器学习的安全系统,比如用来过滤垃圾邮件和恶意软件的那些。“几个小时的努力后,你就能萃取出一个AI模型,如果此模型被用于某个产品系统,那这个系统从此对你再无阻碍。”研究人员的技术,基本上是通过机器学习自身来逆向机器学习软件。简单举例,机器学习训练的垃圾邮件过滤器,可以判定所给邮件是否垃圾邮件,它会给出一个“置信度值”,揭示其判断的正确程度。回答可被描述为AI决策阈值界限任一边的点,置信度值显示的就是这个点距离界限的远近。不断用测试邮件尝试过滤器,可以揭示出定义那条界限的精确线。该技术可被扩展成更加复杂的多维模型,给出更为精准的答案而非简单的“是/不是”回答。这种攻击方法可以用来窃取股市预测模型和垃圾邮件过滤模型。
4.对算法进行对抗样本攻击
目前已有的机器学习模型和神经网络模型都是通过提取数据特征,构建数学判别公式然后根据数学模型进行学习。提取数据特征的过程中容易提取到错误特征、而且判别公式也可能出现与真实决策面分布不同的问题,因此攻击者可以利用AI模型的弱点,生成欺骗模型的对抗样本。例如在图像识别领域,可以通过在正常图片上加入一个微小的噪声从而使图像识别分类器无法正常识别图像,导致错误分类的效果。如从一张熊猫的图像开始,攻击者添加一个小干扰,且该小干扰被计算出来,使图像被认为是一个具有高置信度的长臂猿。
对抗性输入:这是专门设计的输入,旨在确保被误分类,以躲避检测。对抗性输入包含专门用来躲避防病毒程序的恶意文档和试图逃避垃圾邮件过滤器的电子邮件。
2017年发布的一篇论文《Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN》是第一篇公开引用有关人工智能帮助恶意软件逃脱例子的论文。论文提出了一个重要观点,如果AI能够通过学习识别出恶意软件,那么反过来,恶意软件的AI也可以通过学习预测出识别方式,从而达到“最小程度被检测出”的目的。而恶意软件的AI进行防甄别的方式主要是通过改变部分代码来实现的。该论文还指出,数据的微小变化都会引起监测系统的识别错误,因此,黑客只需要更改不到1%的字节,恶意软件就有可能躲过监测。而这并不会影响恶意软件的入侵功能。


防御方法
当放大图像时人眼还是能看到的观察到对抗样本的区别。
图像去噪:
廖方舟使用传统方法(中值滤波等)和深度网络模型U-Net试图使用去燥方法解决问题(PGD Pixel Guided Denoiser)。效果不佳,虽然绝大部分噪声被消除了,但是并没有增加分类准确率。他们研究将对抗样本和去噪后的图像输入到网络中,计算网络每一层的特征的距离。发现如果只是普通的噪声,比如高斯噪声,这些噪声的影响会随着网络的加深而逐渐变小;但是对于对抗样本的噪声,这些噪声的影响会随着网络的加深而逐渐变大。这一趋势在图像经过基本的去噪后仍然存在。后来提出HGD(High-Level Representation Guided Denoiser)方法。

对抗训练:生成对抗样本训练模型
此外,目前在网络安全公开赛中,算法对抗已经成为热点。例如IJCAI-19 阿里巴巴人工智能对抗算法竞赛的目的是对AI模型的安全性进行探索。这个比赛主要针对图像分类任务,包括模型攻击与模型防御。参赛选手既可以作为攻击方,对图片进行轻微扰动生成对抗样本,使模型识别错误;也可以作为防御方,通过构建一个更加鲁棒的模型,准确识别对抗样本。
|









