| Cross-Site
Request Forgery��CSRF��������һ��������վ����α�졣������ѡowasp©���б�Top10���ڵ�ǰweb©�������У���XSS��SQLע�벢��ǰ������ǰ������ȣ�CSRF�����˵�ܵ��Ĺ�עҪС�ܶ࣬����Σ��ȴ�dz���
ͨ������£������ַ������㷺��������CSRF��������֤token����֤HTTP�����Referer��������֤XMLHttpRequests����Զ���header����������ԭ�������ַ�����������ô�������������ס�
CSRF�ķ���
�ڿ�վ����α�죨CSRF���������棬������ͨ���û����������ע�����������������ƻ�һ����վ�Ự�������ԡ���������İ�ȫ������������ǰҳ�淢�͵��κε�ַ���������Ҳ����ζ�ŵ��û��������/�������Ƶ���Դʱ�������߿��Կ���ҳ���������������������������Ĺ��������
1���������ӡ����磬�����������ֱ�ӷ��ʷ���ǽ�ڵ���Դ�����������÷���ǽ���û����������ӵĶ���������ʵ���Դ������������������������һ�������������Ϊ���ƹ�����IP��ַ����֤���ԣ������ܺ��ߵ�IP��ַ���������뷢�������
2����֪�������״̬�����������������ʱ��ͨ������£�����Э����������������״̬�������а����ܶ࣬����cookie���ͻ���֤������������֤��header����ˣ��������߽������������Ҫ������Щcookie��֤���header������֤��վ�㷢�������ʱ��վ������������ʵ�û������ߡ�
3���ı��������״̬���������߽������������һ�������ʱ�������Ҳ���������Ӧ����˵�response���ٸ����ӣ��������˵�response�������һ��Set-Cookie��header�����������Ӧ���Set-Cookie�����Ĵ洢�ڱ��ص�cookie����Щ�Ķ����ᵼ�º���Ĺ��������ǽ��ڵ�������������
���÷�Χ�ڵ���в�����ǰ��ղ���Σ���Ĵ�С���˲��ֳַ����ֲ�ͬ��Σ��ģ�͡�
1����̳�ɽ����ĵط����ܶ���վ��������̳�����û��Զ���������������ݡ�������˵��ͨ������£���վ�����û��ύһЩ��������ͼ������ӵ����ݡ������������ͼ���urlָ��һ������ĵ�ַ����ô��������������п��ܵ���CSRF��������Щ�ط������Է���������Щ�������Զ���HTTP
header�����ұ���ʹ��GET����������HTTPЭ��淶Ҫ�������ܴ���Σ�������Ǻܶ���վ����������һҪ��
2��Web�����ߡ�������web�����ߵĶ�����ָ���Լ��Ķ��������Ķ������������attacker.com������ӵ��attacker.com��HTTPS֤���web�����������е���Щ����ֻ��Ҫ��10��Ԫ������������һ���û�����attacker.com�������߾Ϳ���ͬʱ��GET��POST���������վ����ΪCSRF������
3�����繥���ߡ���������繥����ָ�����ܿ����û��������ӵĶ�����������磬�����߿���ͨ����������·��������DNS�������������û����������ӡ����ֹ�����web������Ҫ�������Դ��������������Ϊ���HTTPSվ��Ҳ����в����ΪHTTPSվ��ֻ�ܷ�����Դ���硣
���÷�Χ�����в���������ǻ��г���һЩ���ڱ��������۷�Χ�����Σ��ģ�͡�����ЩΣ���ķ�����ʩ������CSRF�ķ�����ʩ�γɺܺõĻ�����
1����վ�ű���XSS��������������ܹ�����վע��ű�����ô�����߾ͻ��ƻ�����վ�û��Ự�������Ժͱ����ԡ���ЩXSS������Ҫ�������������罫�û������˻����Ǯת�Ƶ������ߵ��˻������ͨ������£���CSRF�ķ�����û�п��ǵ���Щ��������ǵ�����ȫ����������վ����ʵ�ֶ�XSS��CSRF��ͬʱ������
2����������������������ܹ����û��ĵ��������ж�����������ô�����߾Ϳ��Կ����û������������Щ���ŵ���վע��ű�����ʱ�����������ķ������Խ���ʧЧ����Ϊ�����߿����ú��ж���������������滻�û����������
3��DNS�����°���CSRFһ����DNS���°���ʹ���û���IP��ַ�����ӹ�����ָ���ķ����������ڷ���ǽ�����ڵķ�����������Щ����IP��ַ��֤�ķ�������Ҫһ���Կ�DNS���°ķ�������������DNS���°Ĺ�����CSRF��������ͼ�dz����ƣ��������ǻ�����Ҫ���Բ�ͬ�Ľ��������һ���Ľ��DNS���°����ķ�������Ҫ��֤������HTTP����header��ȷ��������Ԥ��ֵ������һ������������ǹ���DNS��������ֹ���ⲿ��DNS���ƽ������ڲ�˽�е�ַ��
4��֤���������û��ڳ���HTTPS֤������ʱ��Ը�����������ʣ���ôHTTPS�ܹ��ṩ�ĺܶలȫ������û�����塣��һЩ��ȫ�о���ָ���������һ������������������ڱ����У����Ǽ����û������ڳ�����HTTPS֤�����֮�����������ʡ�
5�����㡣���û��ڷ��ʵ�����վ��ʱ����������֤��ʱ�����������Ϣ�����㹥���ͷ����ˡ����㹥���ֽ�dz��ձ�Ҳ����Ч����Ϊ�û��е�ʱ����ĺ������ֵ�����վ����������վ��
6���û����١�һЩ������վ�����ÿ�վ���������û������ϰ�߽���һ��������Ϊ�⡣������������ͨ����֯������cookie��������ֹ���Ƶĸ��٣��������ù�վ�������������һ���Կ��Ա��ƹ���
��¼CSRF
������������������������ӻ��������������״̬���������CSRF�����۶��������ܸı�����״̬���������档����CSRF������ͨ���ı��������״̬�����û��ڷ��ʿ�����վʱ�����Σ�������Ƕ��������ӳ̶Ȼ��Dz������ٵ�½CSRF�������棬�����������û��ڿ�����վ���û���������������վ����һ��α������һ������ɹ����������˾ͻ���Ӧһ��Set-Cookie��header����������յ��Ժ�ͻὨ��һ��session
cookie������¼�û��ĵ�½״̬�����session cookie�������������������Ҳ�ɱ�������������Ϊ������֤�����ݲ�ͬ����վ����½CSRF������������ɺ����صĺ����
������¼�������ȸ���Ż��Ⱥܶ����������������ǵ��û�ѡ���Ƿ�ͬ�Ᵽ�����ǵ�������¼������Ϊ�û��ṩһ���ӿ����鿴�����Լ���˽��������¼��������������������û�����Ϊϰ�ߺ���Ȥ��һЩ����ϸ�ڣ������߿���������Щϸ������ƭ�û��������û������ݻ��߿�̽�û��������������û����ݵ�½������������Ϳ��Կ����û���������¼����ͼ1.
�������û���������ѯ��¼�ͱ��洢���˹����ߵ�������¼������߾Ϳ��Ե�½�Լ����˻�����ѯ�û���������¼��
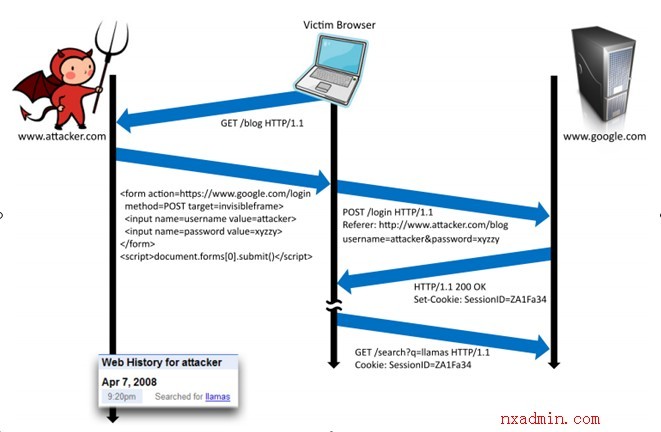
ͼ1. ��½CSRF�����¼��ĸ���ͼ���ܺ��˷��ʹ����ߵ���վ����������ȸ�α��һ����վ������ĵ�½������ܺ��߱������ߵ�½���ȸ衣����ܺ���ʹ��������ʱ��������¼�ͱ�������¼������
PayPal��PayPal���������û��֮������ת���ʽ�ת���ʽ��ʱ���û�Ҫע�����ÿ����������˻��������߿������õ�½CSRF���������¹�����
1���ܺ��߷����˶����̼ҵ���վ����ѡ��ʹ��PayPal֧����
2���ܺ��߱��ض���PayPal����Ҫ���½��/�����˻���
3����վ�ȴ��û���½��/����PayPal�˻���
4�������ʱ���ܺ������ǵǼ��Լ������ÿ����������ÿ�ʵ�����Ѿ������ӵ������̼ҵ�PayPal�˻���
iGoogle���û�����ͨ��ʹ��iGoogle�������Լ��Ĺȸ���ҳ��Ҳ����һЩ�����Ϊ�������ԣ���Щ����ǡ�Ƕ�뵽iGoogle�ġ�����Ҳ����ζ�����ǽ�Ӱ�쵽iGoogle�İ�ȫ��ͨ������£�iGoogle�������²����ʱ����ѯ���û��������ξ��������ǹ����߿���ͨ����¼CSRF�����������û������������Ӷ���װ����IJ����
1��������ͨ���û����������Ȩ��װһ��iGoogle��������ж���ű���������������ӵ��û��Ķ��ƻ�iGoogle��ҳ��
2��������ʹ�û���½�ȸ裬����һ����iGoogle�Ŀ�ܡ�
3���ȸ���Ϊ�ܺ��߾��ǹ����ߣ����������ߵIJ�������ܺ��ߣ�����������������https://www.google.com�������нű���
4�����������ڿ��ԣ���a������ȷ��URLҳ�湹��һ����½��b����ȡ�û��Զ��������루c������һ�����ڵȴ��û���½����ȡdocument.cookie��
�����Ѿ�������©����֪�˹ȸ裬�����Ѿ���������������©��������Σ�������ȣ��ȸ��Ѿ�������Ƕ�IJ������ֹ�����߿������ƵIJ����ֻ�����ٲ��ֱȽ��ܻ�ӭ����Ƕ�������Σ��ȸ��Ѿ�������˽��token������������½CSRF(���潫������)�������������ֻ�Ե�½�˵��û�����Ч������Ԥ�ƣ��ȸ�һ����ֲ��������ǵķ���������������Ч֮��������ǵĵ�½CSRF©����
���е�CSRF��������
һ����վ�����ַ���CSRF�����ķ�������1����֤tokenֵ����2����֤HTTPͷ��Referer����3����XMLHttpRequest������header��������ַ������ڹ㷺ʹ�ã��������ǵ�Ч����������ô���������⡣
Token��֤
��ÿ��HTTP�����︽��һ������Ϣ��һ������CSRF�����ĺܺõķ�������Ϊ���������ж������Ƿ��Ѿ���Ȩ���������֤token��Ӧ�ò������ı�δ��¼���û��²�����������������û�������֤token����token����ƥ��Ļ���������Ӧ�þܾ��������
Token��֤�ķ�����������������½CSRF�����ǿ�����������������֤����Ϊ���û�е�½���Ͳ���ͨ��session����CSRF
token����վҪ������֤token�ķ�ʽ��������½CSRF�����Ļ����ͱ����ȴ���һ����ǰsession�����������ܲ���CSRF�ķ�������������֤ͨ����֮���ٴ���һ��������session��
Token����ơ��кܶ༼������������֤token��
session��ʶ�����������cookie�洢��ʽ����Ϊ�˷�ֹ��ͬ��֮�以�����cookie��һ���ձ��������ֱ�������û���session��ʶ������Ϊ��֤token���������ڴ���ÿһ������ʱ�������û���token��session��ʶ����ƥ�䡣����������ܹ��²���û���token����ô�����ܵ�¼�û����˻��������������и����õĵط����ڣ�ż���û�������������ݻᷢ��������������ͨ�������ʼ�ֱ������ҳ�����ϴ�����������̵�bug�������ݿ⡣����������ҳ��������û���session��ʶ�����κ��ܿ������ҳ����˶���ģ���û���½����վ��ֱ���Ự���ڡ�
����session���������ֱ��ʹ���û���session��ʶ����һ�����ǣ����û���һ�ε�½��վ��ʱ���������Բ���һ��������������洢���û���cookie���档����ÿһ�������������Ὣtoken��洢��cookie���ֵƥ�䡣���磬�㷺ʹ�õ�Trac�������ϵͳ�����õĴ˼�������������������ܷ������������繥������ʹ������webӦ�ö�ʹ�õ���HTTPSЭ�顣��Ϊ�����߿���ʹ�����Լ���CSRF
token�������������������session���������������ʹ��һ��ƥ���token��α��һ����վ����
����session���������һ���Ľ�����������ķ����ǽ��û���session��ʶ����CSRF token������Ӧ��ϵ��洢�ڷ���ˡ��������ڴ��������ʱ����֤�����е�token�Ƿ���session��ʶ��ƥ�䡣��������и����õĵط����Ƿ���˱���Ҫά��һ���ܴ�Ķ�Ӧ��ϵ������ϣ������
session��ʶ����HMAC����һ�ַ�������Ҫ�������ά����ϣ�������ǿ��Զ��û���session token��һ�����ܺ�����CSRF
��token�����磬 Ruby on Rails��web����һ�㶼��ʹ�õ����ַ���������������ʹ��session��ʶ����HMAC����ΪCSRF
token�ġ�ֻҪ���е���վ��������������HMAC��Կ����ôÿ����������������֤�������CSRF token
�Ƿ���session��ʶ��ƥ�䡣HMAC��������ȷ����ʹ������֪���û���CSRF token��Ҳ�����ƶϳ��û���session��ʶ����
�����г������Դ����վ������ʹ��HMAC����������CSRF���������ǣ��ܶ���վ��һЩCSRF�ķ�����ܣ�����NoForge,
CSRFx ��CSRFGuard����������ȷ��ʵ�ֱȽ����ص�token������һ�������Ĵ�������ڴ�����վ�����ʱ��¶��CSRF
token���ٸ����ӣ�һ�����ŵ���վ�ڶ���һ����վ���������ʱ������CSRF token����ô�Ǹ���վ�Ϳ��Զ�������ŵ���վα��һ����վ����
�����о���NoForge.NoForge����ʹ�÷���˱����ϣ���ķ�ʽ����֤�û���CSRF
token�������������Ӻͱ����ύ��ʱ��ḽ��һ��CSRF token��������ּ�����̫���Ƶ�ԭ��������������
1��HTML����������ﶯ̬�����ģ������ᱻ���¼���CSRF token����Щ��վ���ڿͻ��˴���HTML�ġ�����Gmail,
Flickr, �� Digg������JavaScript ����������������Щ����������ҪCSRF������ʩ�ġ�
2��NoForge��û�ж�ָ��վ����վ�ij����������֡������һ��ָ����վ�ij����ӣ���ô��վ���������������ȡ���û���CSRF
token�����磬���phpBB������NoForge����ôһ���û������һ�����ӣ����ӵ�վ��Ϳ��Ի�ȡ���û���CSRF
token����ʹNoForge�������DZ�վ�����ӻ�����վ�����ӣ���ΪReferer ���ǻᱩ¶�û���CSRF
token��
3��NoForge�Ե�½CSRF��û��ʲôЧ������Ϊ����û��Ѿ�����session��ʶ������½�ˣ�����ôNoForgeֻ����֤CSRF
token����������ȱ���ǿ�������������Ҳ˵����Ҫ����ȷ��ʵʩtoken��֤���Բ�����һ�����������顣
��Ȼ��������ԭ���ǿ������ģ�������Щȱ�ݶ�˵����Ҫ����ȷ��ʵʩtoken��֤���ԣ��Ǻܸ��ӵ�һ�����顣CSRFx
�� CSRFGuard�����кܶ���վ��˵������һ���⡣
Referer
���������£������������һ��HTTP�������е�Referer��ʶ�������Ǵ������ġ����HTTPͷ�������Referer��ʱ�����ǿ�������������ͬ���»��ǿ�վ����ģ���ΪReferer������˷��������URL����վҲ����ͨ���ж�������������Ƿ���ͬ���·����������CSRF������
���ҵ��ǣ�ͨ��Referer�������һЩ������Ϣ�����ܻ��ַ��û�����˽�����磬Referer������ʾ�û���ij��˽����վ�������Ͳ�ѯ��������Щ���ݶ�˽����վվ����˵�Ǻ��£���Ϊ���ǿ���ͨ����Щ�������Ż�������������������һЩ�û�������Ϊ�ַ������ǵ���˽�����⣬������֯Ҳ�ܵ���Referer���ܻὫ������һЩ������Ϣй¶��ȥ��
©��������ʷ���������������һЩ©��ʹ��һЩ������վ����ƭReferer�ļ�ֵ����������ʹ�ô�����������ʱ�ܶ��Referer��ƭ�����۶��������������Referer����α�졣Mozilla��Fire-fox
1.0.7�����Ѿ�����Referer��ƭ��©����Ŀǰ��IE�����ⷽ���©����������Щ©��ֻ��Ӱ��XMLHttpRequest������ֻ������α��Referer��ת���������Լ�����վ��
�߶ȡ������վѡ��ʹ��Referer������CSRF�����Ļ�����ô��վ�Ŀ�����Ա����Ҫ����������ʹ�ñȽϿ��ɻ��DZȽ��ϸ��Referer��֤���ԡ�������ÿ��ɵ�Referer��֤���ԣ���վ��Ӧ����ֹRefererֵ���Ե����������������û��Referer���ͽ�����������������õĺ��ձ飬�����������ױ��ƹ�����Ϊ�����߿�����header����ȥ��Referer�����磬FTP������URL�������������Ͳ�����Referer�����ʹ���ϸ��Referer��֤���ԣ���վ��Ҫ��ֹû��Referer��������������Ҫ��Ϊ�˷�ֹ������վ��������Referer����Ҳ��������������⣬�������ɱһ���ֺϷ���������Ϊ��Щ����������������Ĭ�Ͼ��Dz�����Referer�ġ�����˵�����һ��Ҫ���պã��ܶ�ʱ��ȡ���ھ��顣���ǻ�����4.2.1������������⡣
�����о���Facebook���ݹ�Facebook�Ĵ���վ����ʹ��token��֤�ķ�ʽ������CSRF�����ġ����ǣ���Facebook�ĵ�½����ʹ�õ��ǿ��ɵ�Referer��֤���ԡ����ַ�������Ե�½CSRF�Ĺ���ʱû��ʲô���á�������˵�������߿��Խ��û���http://attacker.com/�ض���ftp://attacker.com/index.html
��Ȼ���ٶ�Facebook����һ����վ�ĵ�½������Ϊ��������FTP URL�����Դ��������������������������Referer��
ʵ��
Ϊ�������ϸ��Referer��֤���Եļ����ԣ����ǽ�����һ��ʵ�������������ж������Լ���ʲô����£��Ϸ����������治����Referer��
��ơ������һ���ܷ�����������������������������������ǿ������ù����Ϊʵ��ƽ̨����2008��4��5�յ�4��8���ڼ䣬���Ǵ�163,767������IP������283,945
����棬�ֱ���������ͬ�Ĺ��������������A��������ÿǧ��չʾ0.50��Ԫ�ļ۸������������Ĺ�棬�ؼ���Ϊ�������������Ϸ������IE��������Ƶ������YouTube����������B��������ÿǧ��չʾ5��Ԫ�ļ۸�ļ�϶��棬�ؼ���Ϊ�����١��������ڡ�������������ʳƷ���͡��ա���������ÿ����������ϻ���100��Ԫ������A��241,483�������146,310������IP��������B��42,406�������18,314������IP����
��������������ʵ���������̨�����ṩ�����������������ǴӲ�ͬ��ע���̴�����ÿ����ʾ���ʱ�������ڽ�������ÿ��������������һ���ض��ı�ʶ���������ѡ��һ̨������Ϊ������������������ͨ��HTTP����HTTPSЭ�齫�ͻ���HTML���͵����ǵķ���������ЩHTML�ܷ���һ��GET����POST�������У���������ύ������ͼ�������XMLHttpRequests�������˳��������IJ��Ҹ��û��IJ����ء������ͨ����������İ�ȫ����֮����������������һ��ͬ�������ͬʱ��η���������һ����������ÿ���������ijɱ���400��Ԫ��������7��Ԫ����һ���Ϸ���֤��䷢������õ�90������֤��HTTPS֤������ѵġ����������ݽ��յ���������������¼�������������Referer��User-Agentͷ�����ڣ��ͻ��˵�C�����磬�Ự��ʶ������������ͨ��DOM
API��¼��document.referrer��ֵ�����Dz���¼�ͻ��˵�IP��ַ��Ϊ��ͳ�ƶ�����IP��ַ������������һ�����������KEY�����Ǽ�¼HMAC�ķ�ʽ�����KEY�ᱻ��������������¼����Ϣ�����Ե���ȷ����������ߵ����ж��١�
������ʵ����������������������Ĺ���ʵ���е���Ϊ�����϶���web���ÿ�����Ϊ�����Զ��������Ĵӹ������������������Դ������ͼƬ����Ƶ����Ƶ���������ǵĹ�������HTTP������ĿԶ������ͨ�Ĺ�棬����������Ҫ�Ĵ������Ա�һ����Ƶ�����Ҫ�Ĵ���ҪС�����ǵķ�����Ҳ������һ����ֻ��¼��������¼����Ϣ��ʵ�������ǵķ�������¼����Ϣ����Ҫ����ҵ�Ĺ����Ҫ�٣���Ϊ���Dz�����¼�ͻ��˵�IP��ַ��
����������Ѿ��������ͼ2��ͼ3���ܽ�����ˣ����ǻ��������½��ֻ��95%�Ŀ��Ŷȡ�
HTTP����� ���������ͬ��������Refererͷ��������ձ飬����POST����(����ϵ��=
2130, pֵ<0.001) ��GET����(����ϵ��= 2175, pֵ<0.001) ��Ƚϣ�ǰ�߲�����Refererͷ�������Ϊ�ձ顣
�ڲ�����Refererͷ��ͳ���У�HTTP��HTTPS��Ϊ�ձ飬��������POST(����ϵ��=
6754, pֵ<0.001)������GET(����ϵ��= 6940, pֵ<0.001)����ͬ��POST(����ϵ��=
2286, pֵ<0.001)�����ͬ��GET����(����ϵ��= 2377, pֵ<0.001)��
�ڲ�����Refererͷ��ͳ���У��������B������ʽ������AҪ���ձ顣��Щ������ʽ������HTTP����POST(����ϵ��=
3060, pֵ<0.001)��HTTPͬ��POST(����ϵ��= 6537, pֵ<0.001)��HTTPS����POST(����ϵ��=
49.13, pֵ<0.001)��HTTPSͬ��POST(����ϵ��= 44.52, pֵ<0.001)����
���ǻ�ͳ�����Զ����header X-Requested-By���μ�4.3�ڣ���Origin������5�£���X-Requested-By�����0.029%��0.047%��HTTP
POST����0.084%��0.112%��HTTP GET����0.008%��0.018%��HTTPS
POST����� 0.009%��0.020%��HTTPS GET�����ﲻ������Refererͷ��Origin������������ͬ�������ﶼ������Refererͷ��
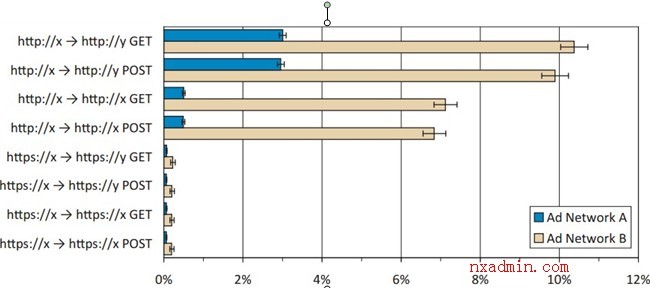
ͼ2. ������Referer��Referer����ȷ������(283,945
�����)��x��y�ֱ�������������ʹη�����������
���ۡ�����������������֤�ݿ��Ա����ڲ�����Referer�������ͨ�����������磨�������������������
1��HTTP�����HTTPS������Referer��Ϊ�ձ�����Ϊ�������������ɾ��HTTP�������header�����Dz���ɾ��HTTPS�������header����Ȼ����һЩ��ҵ�������һЩHTTPS���ն˾���һ�������������������´���������HTTPS��������������DZȽϺ����ġ�
2���������ȥ��Referer��ʱ��Ҳ��ȥ��document.referrer��ֵ���������Referer����������ȥ���Ļ���document.referrerȴ���ڡ��������Ƿ��֣�Refererȥ���������document.referrerȥ�������Ҫ��Ϊ�ձ顣
ʵ���ϣ���ʵ���У�document.referrerֵ��ȥ����Ҫ����Ϊ����������������PlayStation
3 �������֧��document.referrer��Operaȥ��document.referrer�����Dz���ȥ��Referer����Ϊ�˿�վHTTPS����XMLHttpRequest�е�Referer��ȥ���ı����ϸ�������Firefox
1.0��1.5�е�bug����ġ����е���Щ���������ֻ�м�����������������óɲ�����Referer��
Ҳ��֤�ݱ�����Referer��ȥ���������漰����˽���⣬���������Referer����վA���͵���վBʱ���û�����˽Ҳ�ڱ���¶����Ϊ��վB����ͨ��Referer���ռ��û�����վA�������Ϊ�����֮�£���ͬ���·���Referer��������˽���⣬��Ϊ��վ��ȫ����ͨ��cookie���ռ��û�����˽��Ҳ������ȫû�б�Ҫͨ��Referer���ռ��������ǻ����֣���վ�����ͬվ����Ҫ�������ֹReferer��˵�����ڿ��ǵ���˽�����⣬���ԲŻ���Ϊ����ֹReferer���͡�
�ɴˣ����ǵó�������Ҫ�Ľ��ۣ�
1��ͨ��HTTPS������CSRF����HTTPS�����Referer���Ա���������CSRF��Ϊ��ʵʩ��Referer������CSRF�IJ��ԣ���վ����ܾ���Щû��Referer��������Ϊ�����߿��Կ����������ȥ��Referer������HTTP���վ����һζ�ľܾ�û��Referer��������Ϊ���ǵ������ԣ��������൱��һ����
(��Լ 3�C11%)�û����ܾͷ��ʲ�����վ�ˡ���ͬ������HTTPS������ִ���ϸ��Referer��֤���ԣ���Ϊֻ�к�С��һ����(0.05�C0.22%)�������ȥ��Referer���ر���Ҫָ�����ǣ��ϸ��Referer��֤���Էdz��ʺ�����������½CSRF����Ϊͨ������£���½������ͨ��HTTPSЭ�鷢��ġ�
2����˽���⡣�ϸ��Referer�����Ǻܺõ�CSRF�ķ�����������Ϊ��ʵʩ�����ܼ����ҵ��ǣ���˽���Կ��ܻ���ֹ�˷��������С���ˣ�������µİ�ȫ���ܺ��µ�CSRF�������ƶ�����Ҫ�Ƚ������˽���⣬���ܴ��ģ�IJ���
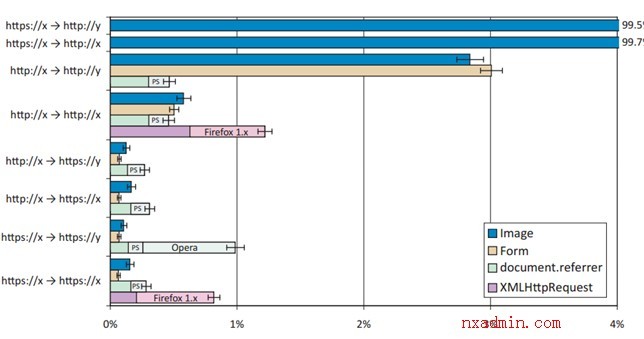
ͼ3. �������A�в�����Referer��Referer����ȷ������(241,483 �����)��Opera��ֹ�˿�վ��HTTPS
document.referrer��Firefox 1.0��1.5����bug��XMLHttpRequest��ʱ����Referer��PlayStation
3��ͼ�м�ΪPS����֧��document.referrer��
�Զ���HTTP header
����Ҳ�������Զ���HTTPͷ�ķ���������CSRF��������Ϊ��Ȼ���������ֹ����վ�����Զ����HTTPͷ������������վͨ��XMLHttpRequest�ķ�ʽ�����Զ���HTTPͷ�����磬prototype.js���JavaScript�����ʹ�����ַ���������������
X-Requested-Byͷ��XMLHttpRequest���� ��Google Web Toolkit
Ҳ���鿪��������XMLHttpRequest������һ��X-XSRF-Cookieͷ�ķ���������CSRF����������XMLHttpRequets������cookie��ֵ����ȻXMLHttpRequets�����cookie������Ҫ��������CSRF����Ϊֻ��Ҫ��ͷ���־��㹻�ˡ�
��ʹ�����ַ���������CSRF������ʱ����վ���������е�������ʹ��XMLHttpRequest������һ���Զ���ͷ������X-Requested-By�������Ҿܾ�����û���Զ���ͷ�ĵ��������磬Ϊ�˷�����½CSRF�Ĺ�������վ����ͨ��XMLHttpRequest�ķ�ʽ�����û���������֤��Ϣ���������������ǵ�ʵ����ڷ��������յ����������棬��Լ��99.90�C99.99%�������Ǻ���X-Requested-Byͷ�ģ��������һ���������ھ���������û���
���飺Origin�ֶ�
Ϊ�˷�ֹCSRF�Ĺ��������ǽ�����������ڷ���POST�����ʱ�����һ��Origin�ֶΣ����Origin�ֶ���Ҫ��������ʶ����������Ǵ������ġ�������������ȷ��Դ�������ô�ڷ��͵���������Origin�ֶε�ֵ��Ϊ�ա�
��˽���棺����Origin�ֶεķ�ʽ��Referer�����Ի�����Ϊ���������û�����˽��
1��Origin�ֶ���ֻ������˭���������û��������Ϣ (ͨ��������Ƿ����������ͻ�ĵ�URL�Ķ˿�)����Referer��һ�����ǣ�Origin�ֶβ�û�а����漰���û���˽��URL·�����������ݣ����������Ҫ��
2��Origin�ֶ�ֻ������POST����Referer��������������͵�����
�����һ�������ӣ�����������б��������ҵintranet���������ᷢ��Origin�ֶΣ��������Է�ֹ������Ϣ������й¶��
��Ӧ����˽���ⷽ�棬Origin�ֶεķ������ܸ���ӭ���û��Ŀ�ζ��
�����Ҫ���ģ���Origin�ֶεķ���������CSRF������ʱ����վ��Ҫ�������¼��㣺
1���������ܸı�״̬�������������½��������ʹ��POST����������һЩ�ض����ܸı�״̬��GET�������Ҫ�ܾ�������Ϊ�˶Կ��������ᵽ������̳����������Σ�����͡�
2��������Щ��Origin�ֶε���ֵ����������ϣ���ģ�����ֵΪ�գ���������Ҫһ�ɾܾ������磬���������Ծܾ�һ��Origin�ֶ�Ϊ��վ������
��ȫ�Է�������ȻOrigin�ֶε���Ʒdz�����������������CSRF���������ܺõ����á�
1��ȥ��Origin�ֶΡ�����֧�����ַ������������ÿ��POST�����ʱ�����Դheader����ô��վ�Ϳ���ͨ���鿴�Ƿ��������Origin�ֶ���ȷ�������Ƿ�����֧�����ַ��������������ġ������������Ч��ֹ�����߽�һ��֧�����ַ�����������ı�ɲ�֧�����ַ��������������Ϊ��ʹ��ı������ȥ����Origin�ֶΣ�Origin�ֶλ��Ǵ��ڣ�ֻ����ֵ��Ϊ���ˡ����Referer�ܲ�һ������ΪReferer
ֻҪ����������ȥ���ˣ��Ƿ�������̽�ⲻ���ˡ�
2��DNS���°������е���������棬����ͬվ��XMLHttpRequests��Origin�ֶο��Ա�α�졣ֻ�����������ӽ���������֤����վӦ��ʹ���ڵ�2�����ᵽ��DNS���°ķ�����������֤header���Host�ֶΡ���ʹ��Origin�ֶ�������CSRF������ʱ��Ҳ��Ҫ�õ�DNS���°ķ������������ศ��ɵġ���Ȼ�����ڵ��������ᵽ��CSRF����������Ҳ��Ҫ�õ�DNS���°ķ�����
3������������վ����crossdomain.xml������һ����վHTTP�����ʱ�����߿�������������Flash
Player������Origin�ֶΡ��ڴ�����վ�����ʱ��token��֤�ķ��������IJ��ã���Ϊtoken�ᱩ¶��Ϊ��Ӧ����Щ��������վ��Ӧ�����ܲ�������Դ�Ŀ�վ����
4��Ӧ�á�Origin�ֶθ������ĸ�����ȷ��������Դ�Ľ���dz����ơ�Origin�ֶ������ĸ�����Ļ�����ͳһ���Ľ��ˣ�Ŀǰ�Ѿ��м�����֯������Origin�ֶεķ������顣
Cross-Site XMLHttp Request��Cross-Site
XMLHttp Request�ķ����涨��һ��Access-Control-Origin �ֶΣ�����ȷ��������Դ������ֶδ��������е�HTTP������������ֻ��XMLHttpRequests�����ʱ��Ż���ϡ����Ƕ�Origin�ֶε����������Դ��������飬����Cross-Site
XMLHttp Request�������Ѿ��������ǵĽ���Ը�⽫�ֶ�ͳһ����ΪOrigin��
XDomainRequest����Internet Explorer 8
Beta 1����XDomainRequest��API�����ڷ���HTTP�����ʱ��Referer���·������������ɾ���ˡ����������Referer�ֶο��Ա�ʶ�������Դ�����ǵ�ʵ������������ɾ����Referer�ֶξ����ᱻ�ܾ��������ǵ�Origin�ֶ�ȴ���ᡣ���Ѿ�������������������ǵĽ��齫XDomainRequest���ɾ��Referer����ΪOrigin�ֶΡ�
JSONRequest����JSONRequest��������������һ��Domain�ֶ�������ʶ��������������������֮�£����ǵ�Origin�ֶη�����������������������������ķ����Ͷ˿ڡ�JSONRequest�淶��������Ѿ��������ǵĽ���Ը�⽫Domain�ֶθ���ΪOrigin�ֶΣ���������ֹ���繥����
Cross-Document Messaging����HTML5�淶�������һ�����飬���ǽ���һ���µ������API��������֤�ͻ�����HTML�ļ�֮�����ӡ���������������һ�����ܱ����ǵ�origin���ԣ���������ڿͻ��˵Ļ����ڷ������֤����origin���ԵĹ�����������֤origin�ֶεĹ�����ʵ��һ���ġ�
����ʵʩ�������ڷ�������������˶�ʵ��������origin�ֶεķ�������ֹCSRF������������������ǵ�ʵ��origin�ֶη�ʽ�ǣ���WebKit����һ��8�д���IJ�����Safari�������ǵĿ�Դ�����Firefox����һ��466�д���IJ�����ڷ�����������ʵ��origin�ֶεķ�ʽ�ǣ���ModSecurityӦ�÷���ǽ������ֻ��3�д��룬��Apache������һ��Ӧ�÷���ǽ���ԣ���ͼ4������Щ������POST����������֤Host�ֶκ;��кϷ�ֵ��origin�ֶΡ���ʵ����Щ����������CSRF������ʱ����վ������Ҫ����ʲô�ı䣬������Щ������ȷ��GET����û���κι�����(ǰ������������Ѿ�ʵ����origin�ֶη���)��
session��ʼ��
��session��ʼ����ʱ��½CSRFֻ������һ�����ձ��©������session��ʼ����֮��web������ͨ���Ὣ�û���������session��ʶ����������������������͵�session��ʼ��©����һ���Ƿ������������û����������³�ʼ����session����һ����һ���Ƿ������������ߵ�������session����һ��
��Ϊ�����û�����֤����ijЩ�ض�������£������߿���ʹ��һ����Ԥ����session��ʶ��ǿ����վ����һ���µ�session����һ���͵�©��һ�㶼����Ϊsession��λ©�������û��ṩ���ǵ�������Ϣ��һ��������վ����֤����վ�Ὣ�û���������һ����Ԥ����session��ʶ����һ�𡣹����ߴ�ʱ�Ϳ���ͨ�����session��ʶ���������û������ݵ�¼��վ��
��Ϊ�����ߵ���֤��������Ҳ����ͨ���û��������ǿ����վ��ʼһ���µ�session������ǿ��session�빥���ߵ����ݰ�һ�𣨵�3���Ѿ�˵���˹�������ô��ɵģ�����¼CSRF����ֻ����һ�����е����©�������ǹ����������������ķ���ǿ��ͨ���û����������session���Լ���һ��
HTTP����
OpenID����LiveJournal��Movable Type��WordPress�Ⱥܶ���վ����ʹ��OpenID
Э�飬������Щ����ʹ����ǩ��������ķ�ʽ���Կ��ظ�����������Ҫ��OpenID session���û����������һ����Ϊ�����߿���ǿ���û����������ʼ��һ��sessionȻ��session���Լ���һ�𡣹淶�������ˣ�
return_to ���URL���ܱ�ί�з��������û�����֤��������֤��֮�佨����ϵ������LiveJournal,
Movable Type��WordPress����Ϊ�ⲻ�DZ���ģ�Ҳû��ʵʩ����Ϊ�˶Կ����ֹ�������Э���ʼ����ʱ��ί�з�Ӧ������һ���µ�����������������������cookie�洢��һ�𣬽���������return_to�����ί�з��Ὣ��cookie����������return_to������������ƥ�䡣���ַ�����ʵ��token��֤�ķ��������ƣ�����ȷ���˴�һ��ʼOpenID
Э���session������ͬһ�����������ɡ�
PHP cookieless������cookie�ģ���֤�����ַ�����Hushmail ����վ������ֹ�û��ĵ����ϻ�������cookie��Cookieless
��֤�����ǽ��û���session��ʶ���洢������IJ������档��������������ܽ�session���û����������һ����˹����߿���ǿ���û����������ʼ��һ��session�빥���߰�һ��Ϊ�˷�ֹ���ֹ�������վ����ʹ������ķ�����session��ʶ�����û����������һ�����磬��վ���Թ���һ����ʱ���frame�����а�����session��ʶ�������ַ�ʽ��ͨ����session��ʶ���������ڴ��������û����������session��ʹ��PHP
cookieless��֤��������վͨ��Ҳ�����session��ʼ��©�������ù����߿���ģ��һ�����ŵ��û�����Ȼ�����Ƶ�session��λ©���кܶ���ķ������������磬���û���½����վ�����ٴ�����һ��session��ʶ����
Cookie��д
©����������������Set-Cookie�ֶ�����һ��Secure flag��ʽ�����������cookieֻ��ͨ��HTTPSЭ�鷢�͡��ֽ���������֧��������ԣ�������һЩ��ȫ��Ҫ��Ƚϸߵ���վ���������ͨ������������session�����ǣ����Secure
flag�����ܱ�֤�����ԡ������߿���ģ����վͨ��HTTP��ͬһ����������Set-Cookie�ֶΣ�����������������cookie���������ͨ��HTTPS����վ����cookie��ʱ����վ��û��һ��������ȷ��cookie�Ƿ�������д��������cookie����������û���session��ʶ���������߾Ϳ��Ժ�����ͨ����д�û���cookie������һ��session��ʼ��������������û����վ�ܹ��������ֹ�������Ϊ������Ҫ�ͻ����ṩһ��cookie������������֤�����ǣ����˽���ʹ������������ԣ�����localStorage���������ֲ���һ���㡣���仰˵�������վ��������Ӧ�ò�session����֤��ȫ������cookie��HTTP���session�صĻ��������߿�������֤֮ǰ����д�û���cookie��Ȼ������û���½��վ�����ܰ�ȫ��Ա�ܶ���ǰ��֪�������߿�����дcookie��������������̲�û��ʲô�õĶԿ��취�����̿��ǵ���ͨ���ܾ�HTTP����ķ�ʽ���Կ�cookie��д�Ĺ�����������һ������Ȼ��̫�������������ǣ���һ�����������ṩcookie�������ԣ���ΪCookie
�ֶα�������������cookie ���Ƿ���Secure flag��
����������Ϊ�˲��ı����е�cookie�ֶζ����ܱ���cookie�������ԣ��Ƿ������Secure flag�������ǽ��������������HTTPS���������¼�һ��Cookie-Integrity�ֶΣ�ר���������cookie��������״̬������Ҳ�ǿ����˼�����ǰ���Ե�����������
Cookie: SID=DQAAAHQA��; pref=ac81a9��; TM=1203��
Cookie-Integrity: 0, 2
��cookie�����ó�ʹ��HTTPSЭ�鷢�͵�ʱ��Cookie-Integrity�ֶο���������������������cookie�ֶε�������������������cookie��û�б����ó�HTTPS����ôCookie-Integrity�ֶε�ֵ��Ϊ�ա���Cookie-Integrity�ֶε������Եı�����Secure
flag���ṩ�Ļ������ศ��ɵģ�����������Ҳ�߱��ܺõļ����ԣ���Ϊ����������Ծ�����ʶ���header�����������Ǽ�����ƵĽ��飺
��������ÿһ��HTTP�������������ݱ�Ȼ����������������ӳ٣�Ϊ�˽�ʡ����������ֻ��cookie�ֶ�������cookie������ֵ������һ������������������һ������cookie�ֶεĸ���������Ϊcookie2��
�����ԡ�������������һ��������cookieͬ����cookie����ôcookie��ȫ����������ͬ����cookie����Ϊ�ڴ�������£�Ҳ��Cookie-Integrity�ֶβ��ܸ���cookie�����ֱ����ǣ��������ǿ�����cookie�ֶ�����ͨ������ֵ���������ǡ�
Rollback����HTTPS�����������Cookie-Integrity�ֶο�����Ч�ķ�ֹrollback������
���û��Cookie-Integrity�ֶΣ������ڲ��ܱ�֤cookie�����Ե�ʱ����ô��������ʱҲ����ȷ�����������cookie�Ƿ�߱������ԣ����������Ǵ�һ���Ͱ汾�����������ģ�����֧��Cookie-Integrity�ֶΣ���
ͬ������������һ�������example.com�ֱ������һ�����ŵĺ�һ�������ŵ�����www.example.com
�� users.example.com���ڶ�example.com����cookie��ʱ�����ŵ�����Ϳ���ע����������cookie�ֶΡ�Cookie-Integrity�ֶβ����ܷ�ֹ���ֹ������������ǿ���ͨ������һ���ֶ�����ʶÿ��cookie����Դ����Ȼ��Ҫȡ���ڶԴ��������ԵĿ��ǣ���
������Firefox����202��JavaScript��������ʵ����Cookie-Integrity�ֶΣ���������һ��Integrity
flag�洢��cookie���棬��Ҫ������¼���cookie�Ƿ����ó�ʹ��HTTPS���䡣
�ܽ�ͽ���
CSRF�ǵ���һ�������õķdz��㷺��©�����ܶ���վ�������ǵİ�����½CSRF©�����ڵ�CSRF©����������ƪ�������ᵽ��ʵ��ͷ��������ǽ�����վ�ڲ�ͬ�������ʹ�ò�ͬ��CSRF�������ԡ�
��½CSRF�����ǽ���ʹ���ϸ��Referer��֤������������½CSRF����Ϊ��½�ı���һ�㶼��ͨ��HTTPS���ͣ��ںϷ����������Referer������ʵ�ɿ��ġ��������û��Referer�ֶεĵ�½������ô��վӦ��ֱ�Ӿܾ��Է������ֶ�����ġ�
HTTPS��������Щר��ʹ��HTTPSЭ�����վ�����������࣬����Ҳ����ʹ���ϸ��Referer��֤����������CSRF������������Щ���ض���վ�����������վӦ�ý���һ�ݰ�������������ҳ�ȡ�
���������ݡ������վ�����˵����������ݣ�����ͼ�������ͳ����ӣ���վӦ��ʹ��һ����ȷ����֤token
�Ŀ�ܣ����� Ruby-on-Rails�����������һ�����Ч�����õĻ�����վ��Ӧ�û�ʱ������Ƹ��õ�token
��֤���ԣ�������HMAC�������û���session��token ��һ��
���ڸ���Զ�Ľ��飬����ϣ������Origin�ֶ������Referer����Ϊ�����ȱ����˼���Ч�������������û�����˽������Ҫ�ϳ�����token������CSRF�ķ�ʽ����Ϊ������վ�Ϳ��Ը��õı���������HTTP����HTTPS�������õ���token�Ƿ��й¶��
δ���Ĺ��������ʹ��Origin�ֶεķ���������CSRF��������վҪע���ڴ���GET�����ʱ��Ҫ��ʲô�����á�����HTTP�淶���Ѿ�����Ҫ���Ǻܶ���վ��û�кܺõ�������һҪ������վ��ִ����һҪ����������δ���Ĺ����ص㡣
CSRF������������һ�����֣�����������һ�����ŵ���վǶ��һ��frame�������û����������ٳ֣������ܴ����ǵĶ����Ͻ����������������CSRF����������������һ�������Ƶĵط������ڣ������߶��������û�����������������ε���վ����һ�����������ֹ����Ĵ�ͳ�취����frame
busting���������ַ����и��������������JavaScript����JavaScript���п��ܻᱻ�û����߹����߽��á������������и������ǣ�������Origin�ֶ�������һЩ������������frame����Դ��Ҳ����frame����ij����ӣ����������ε���վ�Ϳ��Ը���frame����Դ�������Ǿܾ����ǽ����������
|






