| 编辑推荐: |
本文主要从概念到落地介绍了数据架构到底是什么等相关内容。希望对你的学习有帮助。
本文来自于大鱼的数据人生 ,由火龙果软件Alice编辑、推荐。 |
|
第1章 三个问题,测测你真的懂数据架构吗
如果明天领导问你:"我们公司的数据架构是什么?"——你能用一句话回答吗?
大多数人的典型反应是:"就是……数据库怎么设计的吧?"——这个回答,只对了不到20%。
再来第二个问题:数据架构和数据平台,区别是什么?
典型的错误回答:"差不多是一回事,平台建好了,数据导进去,架构自然就有了。"——这是IT管理者最常踩的认知陷阱。平台是物理设施,架构是业务蓝图。花几百万买了最牛的大数据平台,结果老板看报表数字还是对不上——问题往往不在平台,而在架构缺失。
第三个问题:一个好的数据架构,到底应该包含哪些东西?
如果你的脑子里浮现的只有ER图和几张表——那说明你对数据架构的理解,还停留在"施工图纸"层面,远没有到"城市规划"层面。
如果这三个问题你都能对答如流,可以直接跳到第五章。如果不能,这篇文章会帮你彻底搞清楚。
读完这篇,你至少能做到:①一句话向老板讲清数据架构是什么
②精准区分"买工具搭平台"和"做架构定规矩" ③判断你的企业数据架构处于什么阶段,该避开哪些架构陷阱。
|
阅读路线图: 接下来的内容依次回答——它是什么(第2章)→ 它怎么演进的(第3章)→ 它怎么工作的(第4章)→
它有哪些类型(第5章)→ 建模范式怎么选(第6章)→ 动手体验现代数据工程(第7章)→ 怎么用、怎么避坑(第8章)→
未来往哪走(第9章)。有基础的读者可以直接跳到第5章。
第2章 定义与辨析:拨开迷雾看本质
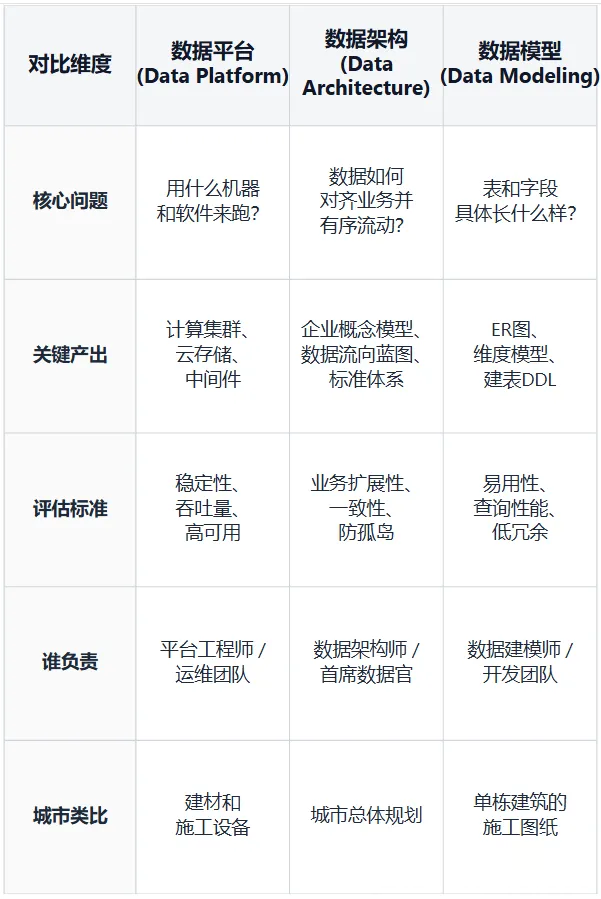
数据架构(Data Architecture)是企业对"数据有什么、放在哪、怎么流、按什么规则用、谁来负责"的整体设计蓝图。它不是某一张图、某一个模型,也不是某一个平台产品,而是一套系统性的规划和标准体系。
把它拆开看,有五个核心要素:
要素一:数据对象(What)。 企业到底有哪些关键数据?客户、订单、产品、合同、设备……这些核心数据实体是架构的起点。相当于城市规划里,先确认住宅区、商业区、学校、医院分别是什么。
要素二:数据分布(Where)。 这些数据分别存在哪些系统里?交易在ERP,客户在CRM,行为日志在数据湖。相当于城市里的住宅区、商业区、仓储区分别坐落在哪。
要素三:数据流动(How)。 数据从哪里产生、经过哪些环节加工、最终流向哪里?一条订单数据从App下单到BI看板的完整链路,就是数据流动设计要画清楚的。相当于城市的道路、桥梁和地下管网。
要素四:数据标准(Rule)。 字段命名规范、数据质量规则、安全分级、生命周期管理……如果财务和销售各有一套"有效订单"的统计标准,系统必然会瘫痪。相当于城市的门牌号、道路命名和交通规则。
要素五:数据责权(Owner)。 谁负责定义这个数据?谁负责保证它的质量?谁有权限使用?这个维度经常被忽略,但它决定了架构能不能真正落地——没有人负责的数据标准,就是贴在墙上的废纸。相当于城市的物业管理和市政执法。
用一句话记住:数据架构
= What + Where + How + Rule + Owner。这五个问题没答清,架构就不完整。
|
2.1 最大的误区:"买平台 = 有架构"
这是IT管理者最常踩的坑,必须单独拎出来说。
很多企业花了几百万上大数据平台,把Kafka、Spark、Hadoop一通部署,以为这就是"数据架构升级"。错了。
你展示的只是一套"施工装备",而不是企业的"数据架构"。
打个比方:你买了最贵的钢筋、水泥和挖掘机,堆在施工现场——这叫采购建材。但"这片区域建住宅还是建商场、主干道怎么走、门牌号怎么编、交通规则怎么定"——这才叫城市规划。
简单说:数据平台是"建材和施工队",数据架构是"城市总体规划",数据模型是"单栋建筑的施工图纸"。
三者层级不同,不可混淆。
2.2 核心类比:数据架构就是企业的"数据城市规划"
这个类比会贯穿全文,先建立完整的映射关系:
城市规划 → 数据架构
功能分区(住宅区、商业区、工业区)→ 数据域划分(交易域、客户域、供应链域)
道路网络(主干道、支路、高速公路)→ 数据集成层(ETL管道、API接口、实时消息流)
建筑规范(楼高限制、消防标准)→ 数据标准(命名规范、质量规则、安全分级)
市政基础设施(水电煤、排水系统)→ 数据平台(数据库、数据仓库、数据湖)
物业管理与市政执法 → 数据责权体系(数据Owner、治理委员会)
单栋建筑图纸 → 数据模型(ER图、维度模型)
一个没有城市规划的城市会怎样?道路不通、功能混乱、重复建设、扩展困难。一个没有数据架构的企业,数据问题完全一样。
数据架构师不是画ER图的人,也不是搭平台的人——他是企业数据世界的"城市总规划师"。
|
那这座"数据城市"是怎么从一间小平房,一步步长成今天这个样子的?
第3章 从平房到智慧城市:数据架构的认知阶梯
数据架构的演进,本质上是企业"榨取数据价值的渴望"与"计算存储瓶颈"之间的持续博弈。
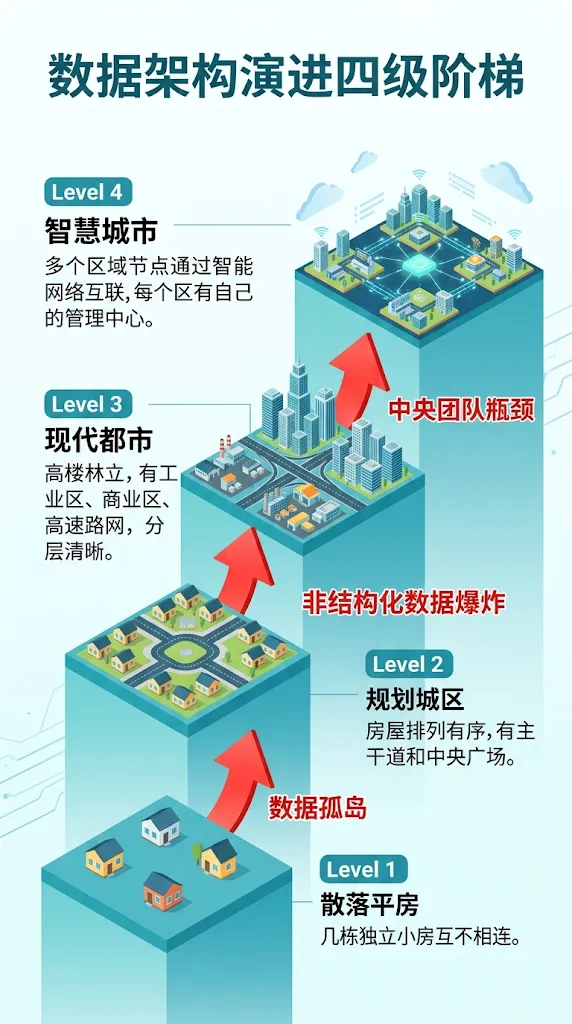
Level 1:散落的平房(独立筒仓阶段)
企业最早期的数据"架构",就是没有架构。
CRM配一个库,ERP配一个库,财务系统配一个库。各自为战,互不相通。业务要看跨部门报表,只能写脚本临时去对方库里捞数据。
用城市规划的类比:这是散落在荒地上的独立平房——没有规划、没有道路,邻居之间喊一嗓子传递信息。
但是,企业一旦长大,问题就来了—— 老板想看跨部门综合报表时,三个部门给出三个不同的数字。因为"各家管各家的账"。
这就是经典的"数据孤岛"问题——每个系统自成一体,数据无法流通。
|
Level 2:规划城区(企业数据仓库阶段)
为了解决孤岛,企业引入了ETL(抽取-转换-加载)机制,建立中央数据仓库。所有数据先经过严格清洗,才能进入数仓。
这是数据架构史上的第一次系统性规划。有了统一的维度定义、标准化的数据模型、集中的数据管理。企业终于有了一本统一的账本。
用城市规划的类比:政府出手了——画了第一版城市规划图,修了主干道,统一了门牌号,建了中央广场。
但是,互联网时代来了—— 日志、图片、视频等非结构化数据涌入,只能存表格的传统数仓存不下、也算不动了。而且集中式架构扩建成本极高。
Level 3:现代化都市(数据湖与湖仓一体阶段)
Hadoop技术带来了数据湖:先把所有原始数据"倒进来",不管格式,之后再按需分析。
但很多企业的数据湖很快变成了"数据沼泽"——数据倒进去了,但没有标准、没有治理,业务人员根本找不到可用的数据。
于是湖仓一体(Lakehouse)诞生:在数据湖的低成本存储之上,构建数仓级的事务管理和质量控制。
用城市规划的类比:城市扩展成了现代化都市——有工业区(原始数据存储)、有商业中心(数据仓库)、有高速公路网(实时数据管道)把它们连起来。分层清晰:原始层→清洗层→聚合层→应用层。
但是,当企业规模极大时—— 一个中央规划局管不过来了。所有需求排队等中央团队处理,响应速度跟不上业务。
Level 4:智慧城市(数据网格阶段)
这是当前最前沿的演进方向。数据网格(Data Mesh)不再追求把所有数据放到一个中心,而是要求各业务域自己管理自己的数据,把它当作"产品"来运营,对外提供标准接口。
架构师的职责从"画中央规划图"变成了"制定联邦互操作标准"。
用城市规划的类比:这是智慧城市阶段——每个区拥有高度自治权,但遵循全市统一的建筑规范和道路标准。
3.1 演进背后的两大底层范式
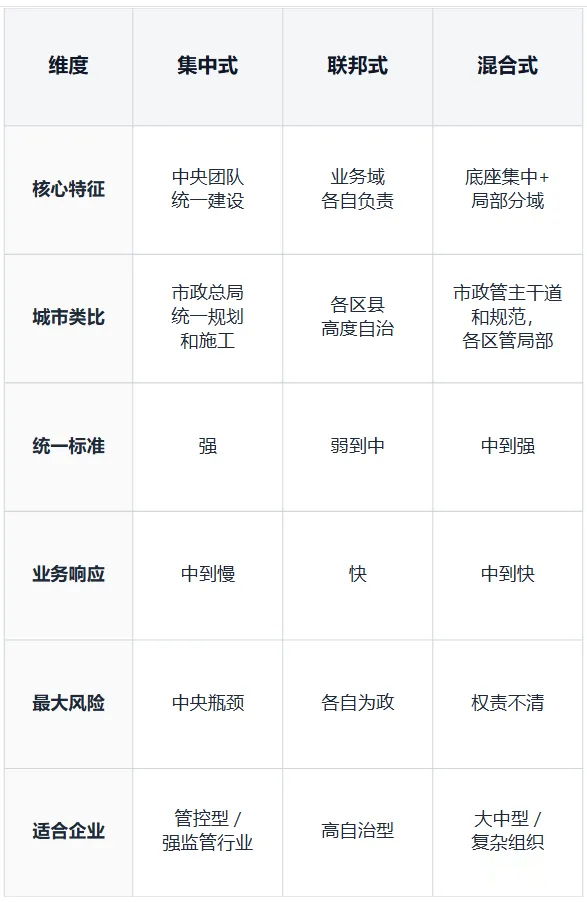
理解这段演进,必须看透背后的范式碰撞:集中式 vs 分布式。
集中式范式(数仓/湖仓一体)——像计划经济。 坚信中央统筹效率最高。核心优势是标准统一、全局好管理。核心局限是中央团队极易成为全公司的业务响应瓶颈。就像一座城市只有一个规划局、所有审批都得排队。
分布式范式(Data Mesh)——像市场经济。 坚信一线业务最懂自己的数据。核心优势是极其敏捷,贴近业务。核心局限(阿喀琉斯之踵)是要求极高的组织成熟度——如果联邦标准没建好,就是从"旧孤岛"走向"新孤岛"。就像给每个区放权自建,如果没有统一建筑规范,城市就会变成违章搭建的重灾区。
现实中,多数大型企业走的是混合路线——底座和标准集中,数据供给和局部建模分域。像市政负责主干道和建筑规范,各区负责局部建设和运营。
从一间平房到智慧城市——数据架构的演进史,就是一部"让企业数据从无序走向有序、从集中走向协同"的历史。
|
演进脉络看清楚了。但一个关键问题还没回答——在这座城市里,一条数据到底是怎么从"生数据"变成"可用数据"的?
第4章 工作原理:数据如何在城市里有序流转
数据架构不是挂在墙上的静态蓝图,而是一套必须落地执行的动态机制。业界最权威的参考标准,是DAMA(国际数据管理协会)发布的DMBOK框架。
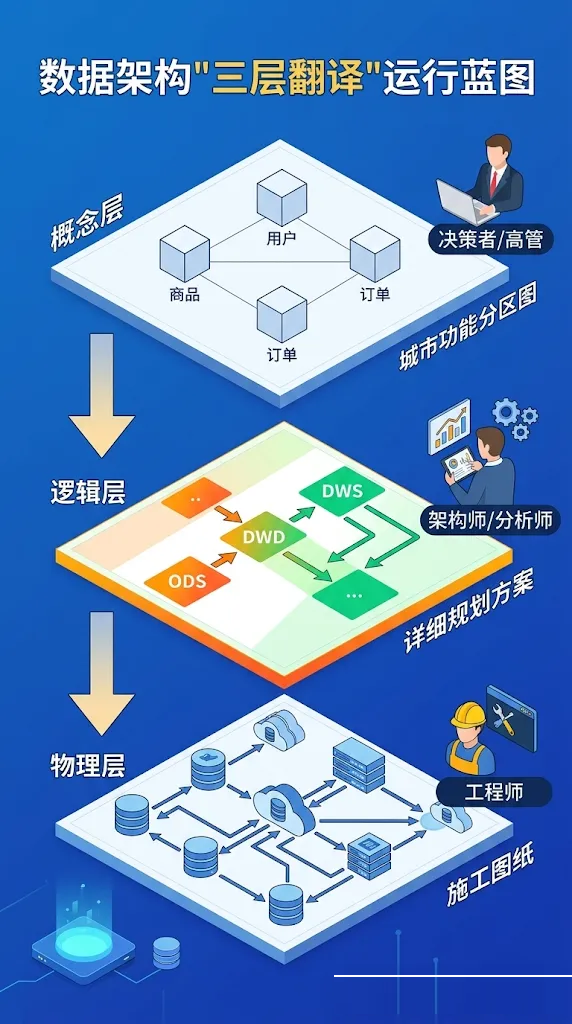
按照DAMA的核心逻辑,架构的运转是一个"三层翻译"过程——确保每一条数据准确流向该去的地方。
4.1 第一层:概念模型(城市功能分区图——给决策者看)
架构师首先要梳理出企业的核心业务实体。
比如一家电商公司,概念层要定义清楚什么是"用户"、什么是"订单"、什么是"商品"。如果连什么是"有效订单"各部门都无法达成共识,底层系统再牛也白搭。
这一步不涉及任何技术。就像城市功能分区图——"这一片是住宅区,那一片是商业区"——决策者一看就懂。
4.2 第二层:逻辑模型与数据流向(详细规划方案——给分析师和架构师看)
有了业务概念,接下来设计数据如何分层清洗和流转。这就是业界通用的数据分层架构:
贴源层(ODS): 原封不动把业务库的数据抽过来。相当于城市把原材料运进来,先堆在仓储区,不做任何加工。
明细层(DWD): 统一格式、去除脏数据、标准化字段。相当于原材料进入加工厂——去杂质、统一规格。
汇总层(DWS): 按业务维度(按天、按省份、按品类)聚合成可快速调用的主题数据。相当于加工好的成品进入商业区的货架——分门别类,随取随用。
架构师还要在这一层明确指定:哪个系统才是某个字段的唯一合法来源(黄金源),并画出完整的数据血缘(Data
Lineage)——就像城市里每一件商品都能追溯到它的产地和加工链路。
4.3 第三层:物理模型(施工图纸——给工程师看)
最后才是真正的技术选型。前面的业务规则全确定了,我们再来决定"订单表"用什么数据库来存。
比如:贴源层数据量大,用对象存储(如S3/OSS);明细层和汇总层需要快速查询,选用列式数据库进行加速。
就像城市规划确定了"这里建商场"之后,施工队才来决定用钢结构还是混凝土框架。
很多失败的数据项目,根源在于跳过前两层,直接让程序员在物理层建表。这就像没有城市规划就开始盖楼——盖完发现商业区在城市边缘,学校离住宅区十公里。
|
4.4 环境的动态性:好架构必须假设"上游永远在变"
在设计流转链路时,环境的动态变化是最大的致命变量。
现代业务系统高度不确定——开发可能随时修改一个字段名(Schema Drift),产品可能随时新增一种订单类型。如果你的架构没有设计边界隔离与容错机制,上游的一个小变更,就会让老板看的报表全线崩溃。
就像城市里,如果某条主干道临时封路,没有备用路线和交通调度机制,整个城区都会瘫痪。
4.5 用电商案例走查一遍完整流程
一家电商企业要做会员运营分析:
概念层: 定义核心实体——用户、订单、商品、门店、营销活动。这是城市的"功能分区图"。
逻辑层 · 数据流向: 用户在App下单 → 订单写入业务数据库(ODS层原封不动抽取)→ DWD层清洗(统一用户ID、过滤测试订单、标准化金额格式)→
DWS层汇总(按天、按城市聚合销售额)→ 最终推送到BI看板和会员标签系统。
逻辑层 · 标准规定: 用户ID统一用UUID;"有效订单"定义为"已支付且未退款",全公司只有一个口径;会员等级计算公式写在数据字典里。这是城市的"门牌号和交通规则"。
物理层: 原始数据存对象存储,明细层用列式数据库,实时推荐用内存数据库,BI报表从数据仓库出。这是"施工队选材和动工"。
好的数据架构,不是"把数据放到一起",而是让数据在正确的规则下、以正确的路径、被正确的人反复使用。
|
了解了城市怎么运转,接下来一个自然的问题——这座城市有哪些不同的建设模式?
第5章 数据架构有哪些类型:三个维度建立完整认知
谈数据架构类型,不能只用一个维度。我们从三个角度来分类,帮你建立立体化的认知框架。
5.1 按使用目标分
运营型数据架构: 支持业务系统运转,核心诉求是稳定、准确、低延迟。典型场景:交易、库存、结算、审批。像城市的主干道和供水供电系统——不能断、不能慢。
分析型数据架构: 支持报表、洞察和决策,核心诉求是整合、口径统一、可追溯。典型载体:数据仓库、指标层。像城市的地图中心和调度中心。
服务型数据架构: 支持接口输出、标签复用、数据产品供给,核心诉求是可复用、可治理、可订阅。回答的不是"能不能查",而是"能不能被别人持续拿来用"。像城市的商业服务和物流配送网络。
5.2 按组织方式分
5.3 按处理时效分
批处理架构: 按小时或按天跑,适合经营分析、管理报表。
准实时架构: 分钟级更新,适合监控、运营看板、预警。
实时架构: 秒级甚至毫秒级响应,适合风控、推荐、在线决策。
这里最容易踩的坑:不是所有问题都值得用实时。 很多企业是"业务没那么急,架构倒先复杂起来了"。T+1的报表需求上了流式架构,就像在一个小镇里修了八车道高速公路——建设成本远超实际需要。
搞清楚了架构类型,接下来进入一个更底层的问题——构建数据仓库时,该选择哪种建模哲学?
|
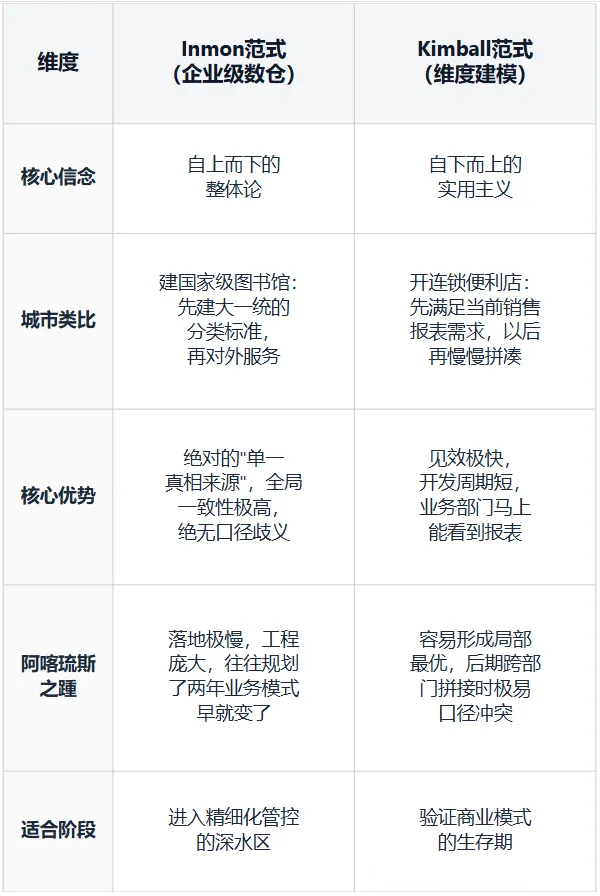
第6章 建模范式之争:Inmon vs Kimball
在构建企业级数据中心时,架构师面临着最经典的路线之争。这就好比规划城市,是先修主干道再建社区,还是先建社区再串联主干道?
6.1 两大流派对比
6.2 性价比拐点怎么选?
公司处于快速扩张期: 坚决用Kimball范式。快速产出报表、活下来最重要。先建便利店,先服务好眼前的客户。
跨部门指标"打架"成为全公司第一痛点时: 必须引入Inmon的思想做顶层架构治理。当财务和销售始终对不上账,当老板每次看报表都拍桌子——这就是需要统一规划的信号。
成熟企业的最优解: 多数大型企业最终走向融合路线——用Inmon的思想做顶层概念模型和数据标准(先画全市总规划),用Kimball的方法快速交付各部门的分析主题(各区按需建设)。
这两大范式不是"谁对谁错",而是"不同阶段的最优解"。判断标准只有一个:你的企业现在最痛的问题是"看不到数据",还是"数据对不上"。
|
理论框架都清楚了。纸上得来终觉浅——在现代技术栈里,这些规矩是怎么被"写"出来的?
第7章 应用场景与避坑指南
7.1 三个典型应用场景
场景一:企业数字化转型的"第一张图"。
很多企业启动数字化转型,第一个动作是买系统、上平台。但如果没有先做数据架构规划,结果往往是——新系统和老系统的数据打不通,花了几千万搭的平台变成了"高级数据孤岛"。
正确做法: 选型之前,先完成概念层和逻辑层的数据架构设计。至少画清楚数据域地图和核心数据流向图。先画城市规划总图,再决定买什么建材。
场景二:跨部门口径统一。
同一个收入、利润、客户数,报表里经常打架。这背后通常不是报表问题,而是数据架构没有把标准层设计好。当财务和销售各有一套"有效订单"的统计标准,吵到天荒地老也对不上。
正确做法: 以数据架构的标准层为基础,建立全公司唯一的业务指标字典,明确每个指标的唯一信任源。统一全城的门牌号和地址系统。
场景三:并购整合中的"数据融合蓝图"。
两家公司合并后,最头疼的问题之一就是数据整合。两套客户编码、两套产品分类、两套财务口径——没有统一的数据架构做参照,整合就是一场噩梦。
正确做法: 并购后第一步不是合并系统,而是做两家公司的数据架构对标——就像两座城市合并,先对标功能分区和道路编号,再谈基础设施对接。
7.2 反模式:以下场景绝对不要盲目上架构
资深专家的价值不仅在于指出方向,更在于标出悬崖。
避坑1:杀鸡用牛刀。 全公司核心数据不到1TB,却跟风上Hadoop集群或复杂的微服务。一台高配单机数据库加上良好索引,足够跑赢95%的同行。这就像一个小镇搞一线城市的地铁规划——建设成本远超实际价值。
避坑2:垃圾进、垃圾出。 业务系统全是烂账,地址乱填、编码混乱,却指望买个"数据湖"把脏数据全存起来,以后靠AI洗干净。如果不从源头治理数据质量,数据湖最终只会变成极其昂贵的"数据垃圾场"。
城市规划再漂亮,如果源头都是违建,整治成本只会越拖越高。
避坑3:用买工具掩盖组织管理乱象。 部门墙极高,业务线之间互相防备、拒绝共享数据。不要以为买一套数百万的软件就能打通孤岛。架构师必须先解决组织契约,再谈技术架构。
买药代治,只会让IT部背上最大的黑锅。
避坑4:把数据架构当一次性项目。 "花三个月做完数据架构,交付文档,项目结项。"——这样做出来的文档,三个月后就和实际情况脱节了。城市规划不是画完就结束——城市在生长,规划必须持续演进。
好的数据架构不是最先进的,而是最适合的。资深架构师的最高境界不是什么新技术都会用,而是敢于在狂热的技术推销面前说:"我们的业务,现阶段用不到这个。"
|
第8章 前沿趋势与当前局限
局限一:架构设计依赖"老法师"的经验。 目前数据架构设计主要靠资深架构师的经验判断,两个架构师画出来的方案可能完全不同,很难客观评估哪个更优。
趋势方向: AI辅助的架构设计和评估工具正在萌芽。通过分析企业现有数据资产和使用模式,AI可以推荐数据域划分和存储策略。
局限二:架构蓝图与落地之间的鸿沟。 一份漂亮的蓝图画完了,但落地阶段受制于遗留系统、组织阻力、预算限制,实现出来的和设计的差距巨大。
趋势方向: "架构即代码"理念(如本文第7章dbt演示)正在缩短从设计到实现的距离——让架构蓝图直接生成技术配置和代码框架,而不是停留在Word文档里。
局限三:跨组织的数据架构协同几乎空白。 在企业内部做统一架构已经很难了,跨企业的数据架构协同(供应链上下游、行业数据共享)更是缺乏成熟方法论。
趋势方向: 行业级数据标准和数据空间(Data Space)概念正在欧洲等地区推进,探索跨组织的数据架构互操作——像不同城市之间的高速公路标准和收费互通。
进一步学习建议
经典书籍: 《DAMA-DMBOK2 数据管理知识体系》——数据架构领域的"圣经",建议至少读完第四章"数据架构"。
方法论参考: TOGAF(企业架构框架)中的数据架构部分,提供了从战略到落地的完整方法论。
动手实践: 去GitHub搜索并克隆 jaffle_shop 项目——这是dbt官方提供的本地实战教程。跑通一遍,你对"架构即代码"的理解会从"听过"升级到"做过"。
第一步行动: 尝试为你自己负责的业务画一张数据域地图——列出所有核心数据实体,标注它们分别在哪个系统里,数据怎么流转,谁负责。这是数据架构实践的第一步。
从堆砌各种炫酷的大数据组件,到精心设计数据的分层与流转——数据架构的成熟史,就是一部"让技术回归业务常识"的历史。你的企业不缺工具,缺的是一张清晰的"城市规划图"。
|
|






 订阅
订阅