| 编辑推荐: |
本文主要要通过剖析Palantir的核心技术平台及其“本体”概念,阐述了数据应用架构,希望对你的学习有帮助。
本文来自于笑看江湖叶雨稠 ,由火龙果软件Alice编辑、推荐。 |
|
一个词的意义就是它在语言中的使用。 ——维特根斯坦
Palantir 无疑是资本市场最耀眼的明星之一,其股价在 2025 年累计上涨超过 150% ,过去三年内更是实现了近 3000% 的惊人涨幅,成为了散户投资者追捧的 “AI 信仰 ” 标的。 Palantir 的核心神话色彩更多源于其与美国军方和情报机构深度绑定的高壁垒合作案例,比如在 “ 海神之矛行动 ” 中定位并击毙了本 · 拉登,这使其成为数据驱动决策、将 AI 技术与复杂业务场景深度融合的“新质生产力”代表。
Foundry 是 Palantir 的核心数据操作平台。而本体( Ontology )则是其架构中的一个核心概念。这个哲学概念一出,让大家对 Palantir 更加佩服,同时也把一个数据集成和挖掘过程搞得非常神秘。让我们从技术的逻辑来简单梳理一下。
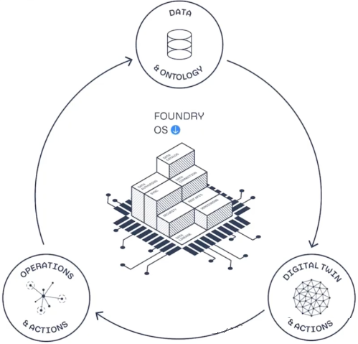
上图是 Foundry 的核心模块,通过数据集成、数字孪生和决策执行,形成一个企业数字驱动的运营和决策闭环。这其中本体是其核心概念, Palantir 自己对本体的定义是它是组织的操作层,位于数据资产之上,在 Palantir 的平台中对应着真实世界的对象,是组织的数字孪生 [1] 。作为企业决策中心的本体系统的概念,其实现逻辑如下图 [2] 所示。
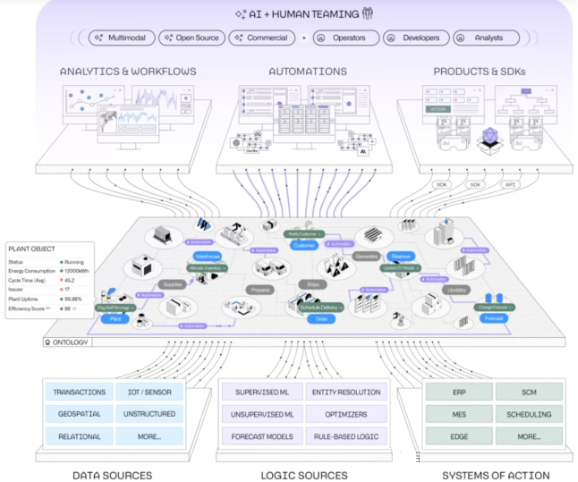
中间层是本体,下层的三个模块表达了三个含义:本体来自于各种系统或数据源的数据集成,可统一表达为多源异构的数据源;在本体的建立过程中,可以采用各种机器学习算法、模型和规则,统称为逻辑来源;本体的操作可以作用于 ERP 、 MES 等企业管理信息系统。上层是基于本体构建的各种应用,系统支持低代码构建各种数据分析、自动化处理流程等,也可以作为其它第三方应用的平台。最终基于本体构建了一个人机协同可演进的智能时代数字化应用图景,这无疑是众多企业级用户的理想, Palantir 还号称从零开始实现企业的数字连接,不超过一个月,先不论它的 AIP 等 AI 故事 ,就这一点,也足以吸引众多投资者了。
大数据的故事,数字化转型的故事大家都在讲,但真正做过的都知道,故事和现实是两回事,从数据集成、数据治理到数据孪生,在实践中都有很多困难。从数据集成开始,虽然现在的数据中台提供各种 ETL 工具和低代码开发平台,但是面对各种业务系统和数据源,数据治理工作量仍然巨大。特别是随着数据挖掘应用目标的变换,还要对数据集成过程反复修改,陷入无休止的定制交付之中。
一种方案是将治理规则和管控措施前置并深度嵌入到数据生成的应用中,基于统一的数据模型构建应用程序。从而使系统原生具有统一的数据底座,统一的数据逻辑,实现“不治而治”,一些大厂还推出了相关的产品。实际上,这是一种非常理想的概念,在一定的组织和场景中可能可行。因为在“信息化、数据化、智能化”这个过程中,肯定是信息化先行,因此所有的组织在做数据化时,都已经面临各个阶段建设的大量信息化系统,全新重建肯定不现实。退一步说,有多少系统设计时都具有统一规划的数据模型,在实践演进过程中面对各种业务需求忘了初心,数据越来越乱。“乱”和“治”一直纠缠在信息系统研发交付维护的整个生命周期。
“数字孪生”前几年在“元宇宙”概念火的时候也非常热,但要做到真正意义的“数字孪生”比“数据治理”难度更大。所谓数字孪生,首先要建立真实物理对象的数字化镜像,然后实现真实对象和数字对象之间的双向数据流动 [3] 。首先一个难题是如何建立数字镜像,由于真实物理世界的复杂性,其数字镜像必然存在于一个超高维的数字空间,现有技术无法处理,因此数字孪生只能是一定业务场景的孪生。 Palantir 的数字孪生是对众多企业数字系统的数据、行为、对象建立模型,以重新构建统一的数字管理应用、数据洞察和业务决策,并可对各系统产生反作用行为。面对复杂的企业级多源异构数据,这仍然是一个不小的挑战, Palantir 的答案是动态本体。
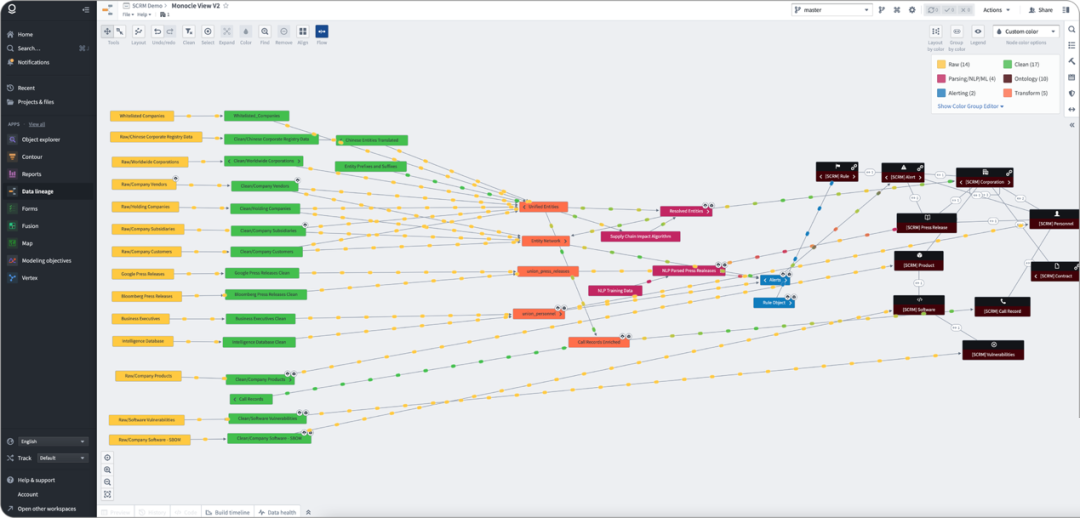
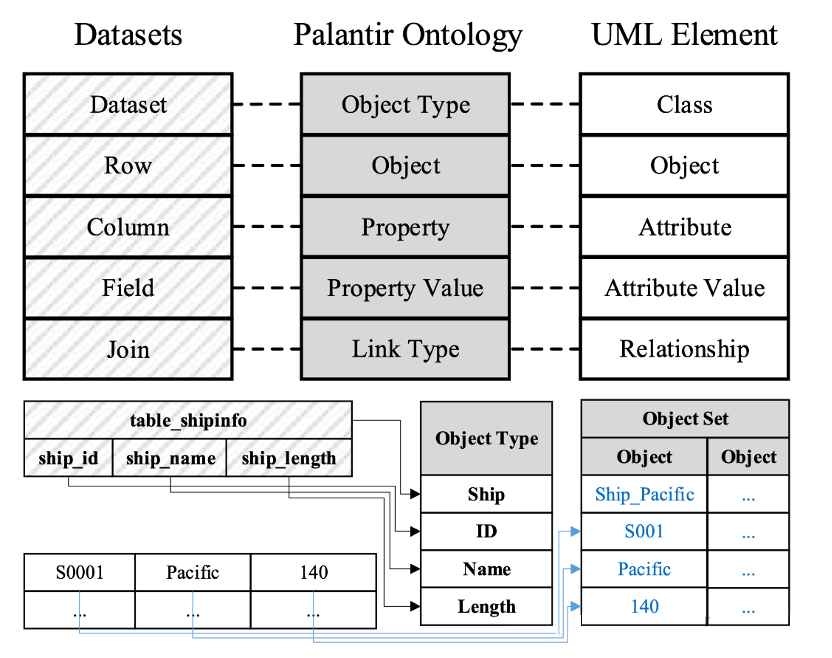
我们来看 Palantir 是如何处理的。下图是一个本体建立的例子,黄色、绿色、橙色和粉红色分别代表原始数据、清洗数据、转换数据和算法处理的数据。这是一个典型的数据集成和治理过程,和一般的数据中台给出的解决方案没有本质差别。
在构建本体(灰色数据)前,有个蓝色数据块,实现了治理数据到本体的桥接。如下图,治理后的数据选择部分内容映射为本体的对象,而选择的依据是业务逻辑。本体不可能实现一个通用的数字孪生,而是一个高度客制化,特定领域的内容映射,因此在这个例子中本体数据及其组织方式实际上是和客户的具体业务和洞察目标高度对齐的 [4] 。我们认为这是本体概念能够落地的关键。
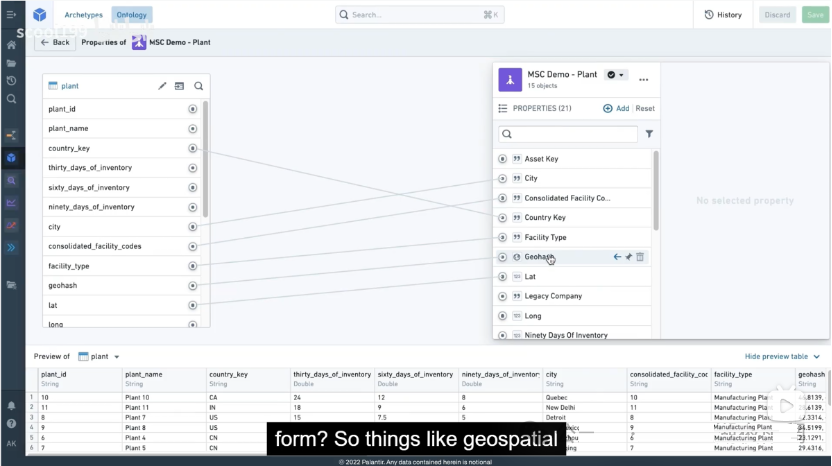
本体包括语义概念,即对象、属性和连接,以及基于这些概念的动态元素,包括行动、函数等,可以理解为数字孪生世界的各种应用,工作流程以及作用回物理系统。下图是一个本体语义概念的例子。有了前面的分析,除了对象和属性外,我们挖掘建立的关系(连接),显然也是高度场景客制化的。无关的信息和关系就不用关心了,这大大降低了系统的处理数据量和难度。
我们再分析一下本体的实现技术架构。本体对应着数据集,如下图。
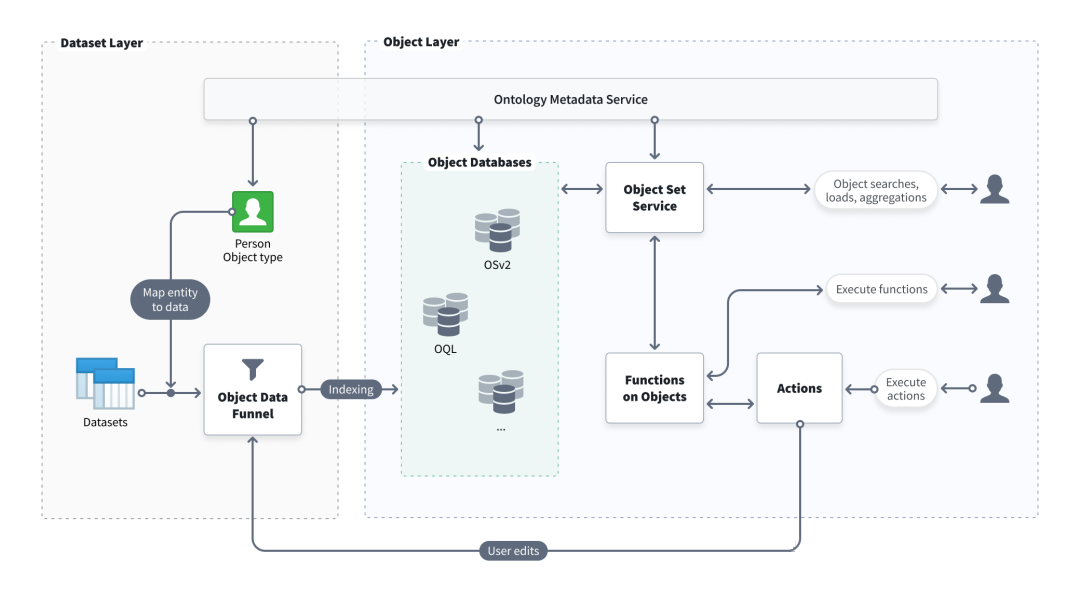
为了支撑高并发、低延迟的访问,本体采用了如下图的对象存储架构 [5] 。有两个点值得关注,通过多对象数据库,满足不同的数据结构特征(如时序、关系等),以及不同的数据持久化需求(如静态、动态、临时等),实现高性能存储访问。通过对象数据管道( Object Data Funnel )实现高效、可客制化、行为反馈的数据映射。进一步确保了本体对象敏捷满足特定场景的目标。
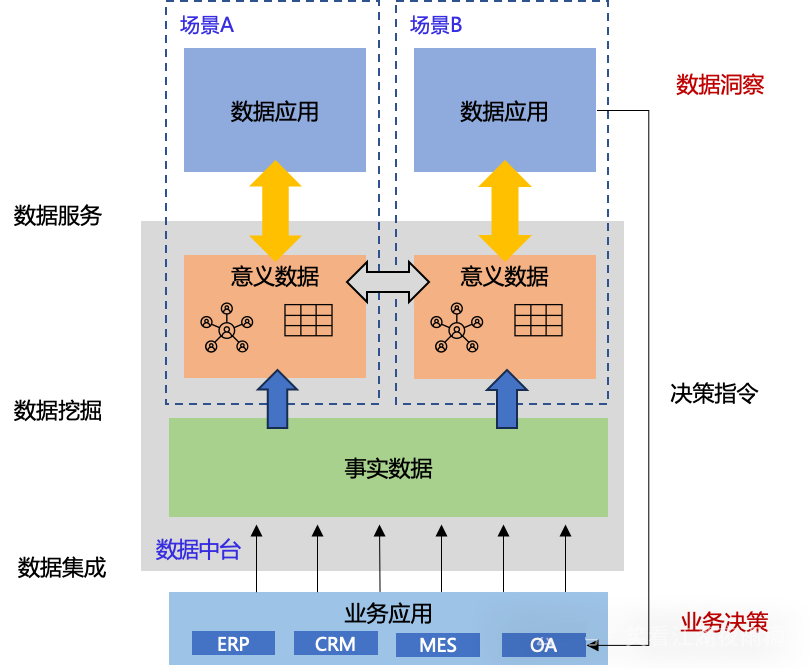
梳理 Palantir 的本体建立路径,我们发现相对于数据中台,其并不是技术上的革新,而是给出了一个切实可行的面向企业场景应用的数据集成范式。这个范式的关键点从哲学上来看,体现了维特根斯坦的名言,“一个词的意义就是它在语言中的使用”,简单地说,意义即使用。本体中的概念、属性、关系一定是在特定场景中使用才有意义,因此,我们也只需要建立需要使用的,有意义的概念数据。从这个逻辑上讲, Palantir 代表了如下图所示的数据应用范式。
我们提出事实数据和意义数据的概念。事实数据对应的是数据治理的结果,实现数据的清洗、转换和规范化,可以理解为规范数据( Canonical Data ),由于这个数据是个单向的数据集成过程,现有的大数据技术足以支撑。而意义数据一定是面向场景挖掘、理解、推理出的数据,包括场景中需要的对象、属性和关系,也可以理解为 Palantir 所谓的本体。意义数据一定是面向上下文环境的,也可以称为上下文数据( Contextualized Data ),当然不同场景的一些共同的数据可以共享,以加快数据挖掘的过程。同时,意义数据和数据应用的关系是双向的,数据应用过程可能修改意识数据。意义数据要充分利用关系数据库、图数据库、 KV、文档 等机制,以确保数据应用的性能。
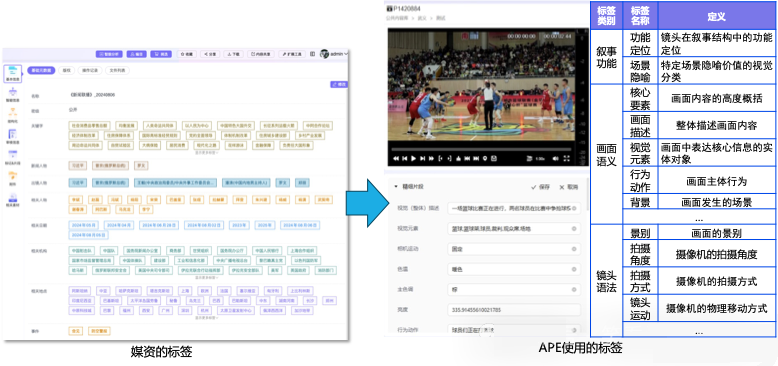
我们还可以从多媒体数据的管理维度来看这个问题,电视台媒资中有个重要的概念是编目,即为媒体素材打上结构化的描述标签。在电视生产中,我们采用的是统一的编目标准;而面对融合媒体,引入了素材标签的概念;在智能生产中,为了面向机器理解,又调整了标签的结构,并引入了 Embedding 向量索引,如下图所示。可见,面向不同的场景,我们需要不同的意义数据,内容在场景中才有意义,因此应该从场景出发来构建媒资的元数据体系,而媒资中的事实数据就是素材本身和基础的元数据信息,通过这个架构,可以实现媒资,或者说多模态内容库在 AI+ 融合媒体时代的敏捷演进。
在这个数据应用架构中,数据治理、数据挖掘、数字孪生应用过程显然可以引入智能体等 AI 手段。从实践来看,真正的数据化和智能化应该同步推进,共同实现企业的数字化洞察和业务决策。
|






 订阅
订阅