| БрМЭЦМі: |
БОЮФжївЊЭЈЙ§СаОй
Data Mesh ЕФЛљБОддђКЭетаЉддђЧ§ЖЏЕФИпМЖТпММмЙЙЃЌзмНсГіСЫ Data
Mesh ЗНЗЈЁЃЯЃЭћЖдФњгаАяжњЁЃ
БОЮФРДздгкInfoQЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ
|
|
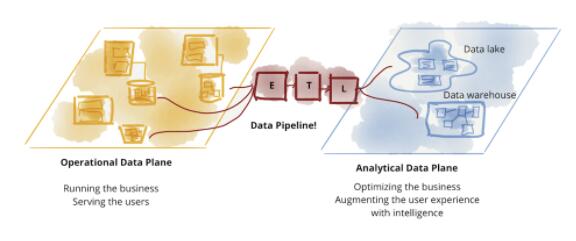
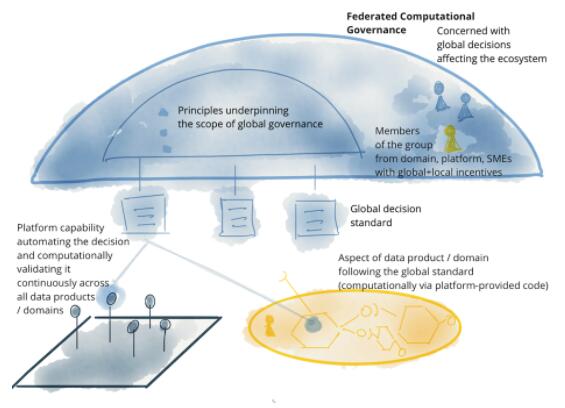
ЮвУЧПЪЭћЭЈЙ§Ъ§ОнРДдіЧПКЭИФЩЦЩЬвЕКЭЩњЛюЕФИїИіЗНУцЃЌетЧ§ЪЙЮвУЧдкДѓЙцФЃЙмРэЪ§ОнЗНУцНјааЗЖЪНзЊБфЁЃОЁЙмЙ§ШЅЪЎФъЕФММЪѕНјВНвбНтОіСЫЪ§ОнСПКЭЪ§ОнДІРэМЦЫуЕФЙцФЃЮЪЬтЃЌЕЋЫќУЧЮоЗЈНтОіЦфЫћЗНУцЕФЙцФЃЮЪЬтЃКЪ§ОнИёОжЕФБфЛЏЃЌЪ§ОнРДдДЕФЗКРФЃЌЪ§ОнгУР§КЭгУЛЇЕФЖрбљад
ЃЌвдМАЖдБфЛЏЕФЯьгІЫйЖШЁЃData Mesh НтОіСЫетаЉЮЪЬтЃЌЫќгЩвдЯТЫФИіддђзщГЩЃКУцЯђСьгђЕФШЅжааФЛЏЪ§ОнЫљгаШЈКЭМмЙЙЃЌЪ§ОнМДВњЦЗЃЌзджњЗўЮёЪ§ОнЛљДЁЩшЪЉМДЦНЬЈЃЌСЊКЯжЮРэЁЃУПИіддђЖМЧ§ЖЏзХММЪѕМмЙЙКЭШЫдБзщжЏНсЙЙЕФаТЕФТпМЪгЭМЁЃ
ЕБЧАЃЌаэЖрЦѓвЕУцСйЕФЬєеНдкгкШчКЮдкММЪѕМмЙЙКЭШЫдБзщжЏВуУцаЮГЩЪ§ОнЧ§ЖЏЁЂдЫгУЪ§ОнНЈСЂОКељгХЪЦвдМАЙцФЃЛЏЕиРћгУЪ§ОнЧ§ЖЏМлжЕЃЌЁАДгЕЅЬхЪ§ОнКўЕНЗжВМЪНЪ§ОнЭјИёЁБЖдЩЯЪіЭДЕугаЩюШыЕФРэНтЃЈЮвЙФРјФњЯШдФЖСИУЮФеТЃЉЁЃЫќЬсЙЉСЫвЛжжЬцДњЕФЙлЕуЃЌИУЙлЕуЮќв§СЫаэЖрзщжЏЕФзЂвтСІЃЌВЂИјЮвУЧДјРДСЫвЛИіВЛЭЌЧАОАЕФЯЃЭћЁЃЫфШЛетЦЊЮФеТУшЪіСЫетжжЙлЕуЃЌЕЋЫќдкКмЖрЩшМЦКЭЪЕЯжЕФЯИНкЩЯСєЯТСЫШУШЫЯыЯѓЕФПеМфЁЃЮвВЂВЛЯыдкБОЮФжаЙ§ЗжЙцЗЖетаЉЃЌвджСгкЖѓЩБСЫДѓМвЪЕЯж
Data Mesh ЕФЯыЯѓСІКЭДДдьСІЁЃЕЋЪЧЃЌЮвШЯЮЊзїЮЊЭЦЖЏЗЖЪНЯђЧАЗЂеЙЕФЕцНХЪЏЃЌБОЮФжЛИКд№дкМмЙЙВуУцЙцЗЖЫќЕФЖЈвхЁЃ
БОЮФЪЧЩЯЪіЮФеТЕФКѓајЃЌ ЫќЭЈЙ§СаОй Data Mesh ЕФЛљБОддђКЭетаЉддђЧ§ЖЏЕФИпМЖТпММмЙЙЃЌзмНсГіСЫ
Data Mesh ЗНЗЈЁЃдкЮвжЎКѓаДЮФеТЩюШыбаОП Data Mesh КЫаФзщМўЕФЯъЯИМмЙЙжЎЧАЃЌНЈСЂИпМЖТпМФЃаЭЪЧЗЧГЃБивЊЕФЁЃвђДЫЃЌШчЙћФње§дкЮЊ
Data Mesh бАЧѓШЗЧаЕФЙЄОпКЭЗНЗЈЃЌФЧУДБОЮФПЩФмЛсШУФњИаЕНЪЇЭћЁЃШчЙћФње§дкбАЧѓМђЕЅЧвЮоЙиММЪѕЯИНкЕФФЃаЭРДНЈСЂУшЪіИУЗНЗЈЕФЭЈгУгябдЃЌЧыПьРДЁЃ
КЯРэЛЎЗжЪ§Он
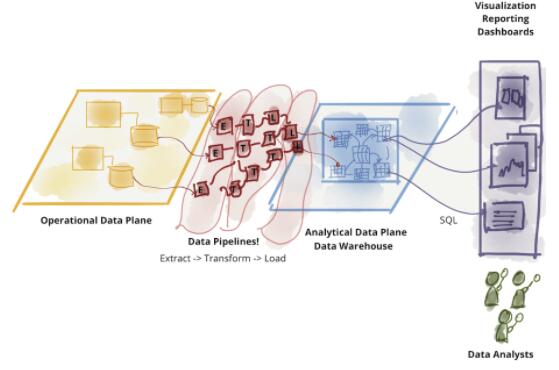
Ъ§ОнЕНЕзЪЧЪВУДЃПетИіЮЪЬтЕФД№АИШЁОігкФњЮЪЫЁЃДгЯжНзЖЮЕФЪгНЧРДПДЃЌ ЮвУЧНЋЪ§ОнЗжЮЊвЕЮёЪ§ОнКЭЗжЮіаЭЪ§ОнЁЃвЕЮёЪ§ОнЮЛгквЕЮёЮЂЗўЮёБГКѓЕФЪ§ОнПтжаЃЌЫќОпгаЪТЮёадЃЌФмЙЛМЧТМЕБЧАзДЬЌВЂЧвТњзувЕЮёгІгУЕФашЧѓЁЃЗжЮіаЭЪ§ОнЪЧвЛЖЮЪБМфФквЕЮёЪТЪЕаЮГЩЕФОлКЯЪгЭМЃЌЫќЕФЪ§ОнФЃаЭЭЈГЃБЛгУРДжЇГжРњЪЗЪ§ОнЗжЮіЛђЮДРДЧїЪЦдЄВтЃЌ
вВгУгкЛњЦїбЇЯАЕФФЃаЭбЕСЗЛђЩњГЩЗжЮіБЈИцЁЃФПЧАЃЌММЪѕЁЂМмЙЙКЭзщжЏНсЙЙЕФЯжзДЖМЗДгГСЫвЕЮёгыЗжЮіЪ§ОнЦНУцЕФВювьЃЌЫќУЧМЏГЩдквЛЦ№ЕЋЪЧгжЯрЛЅЖРСЂДцдкЁЃетжжВювьЪЙМмЙЙБфЕУДрШѕЁЃЖдгкФЧаЉЪдЭМСЌНгетСНИіЦНУцЃЌЯывЊНЋЪ§ОнДгвЕЮёЪ§ОнЦНУцСїзЊЕНЗжЮіЦНУцШЛКѓдйЗЕЛиЕНвЕЮёЪ§ОнЦНУцЕФШЫРДЫЕЃЌВЛЖЯЪЇАмЕФ
ETLЃЈЬсШЁЃЌзЊЛЛЃЌМгдиЃЉСїГЬвдМАШевцИДдгЕФЪ§ОнЙмЕРУдЙЌЪЧвЛИіКмГЃМћЕФЯжЯѓЁЃ
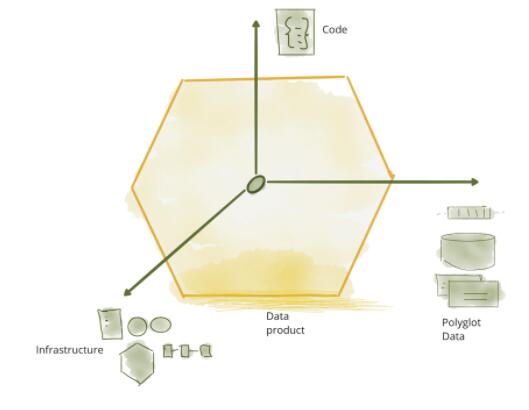
ЭМ 1ЃККЯРэЛЎЗжЪ§Он
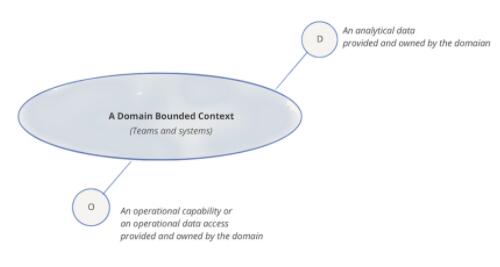
ЗжЮіаЭЪ§ОнЦНУцБОЩэвбОЗжВцЮЊСНЬзжївЊЕФМмЙЙКЭММЪѕеЛЃКЪ§ОнКўКЭЪ§ОнВжПтЁЃЪ§ОнКўжЇГжЪ§ОнПЦбЇЗУЮЪФЃЪНЃЌЪ§ОнВжПтжЇГжЗжЮіКЭЩЬвЕжЧФмБЈИцЗУЮЪФЃЪНЁЃдкБОЮФжаЃЌ
ЮвднВЛПМТЧетСНжжММЪѕеЛжЎМфЕФНЛВцЃКЪ§ОнВжПтЪдЭМШЅв§ШыЪ§ОнПЦбЇЙЄзїСїЃЌЖјЪ§ОнКўдђЪдЭМЗўЮёгкЪ§ОнЗжЮіЪІвдМАЩЬвЕжЧФмЁЃЧАЮФжаЬсЕНЕФЁАДгЕЅЬхЪ§ОнКўЕНЗжВМЪНЪ§ОнЭјИёЁБЬНЬжСЫЯжгаЗжЮіЪ§ОнЦНУцМмЙЙЕФЬєеНЁЃ
ЭМ 2: ЗжЮіаЭЪ§ОнЕФНјвЛВНЛЎЗж - Ъ§ОнВжПт

ЭМ 3ЃКЗжЮіаЭЪ§ОнЕФНјвЛВНЛЎЗж - Ъ§ОнКў
Data Mesh ШЯПЩВЂз№жиетСНИіЪ§ОнЦНУцжЎМфЕФВювьЃКЪ§ОнВЛЭЌЕФЪ§ОнаджЪКЭЭиЦЫНсЙЙЃЌВЛЭЌЕФгУР§ЃЌВЛЭЌЕФЪ§ОнЯћЗбепЃЌвдМАВЛЭЌЕФЗУЮЪФЃЪНЁЃЕЋЪЧЃЌЫќЪдЭМвдВЛЭЌЕФНсЙЙЃЈвЛИіЛљгкСьгђЖјВЛЪЧММЪѕеЛЕФЕЙжУФЃаЭКЭЭиЦЫНсЙЙЃЉСЌНгетСНИіЦНУцЃЌВЂЧвНЋЙизЂЕуЗХдкЗжЮіаЭЪ§ОнЦНУцЩЯЁЃЕБНёЙмРэетСНжжЪ§ОндаЭЕФПЩгУММЪѕЕФВювьВЛгІЕМжТзщжЏЃЌЭХЖгКЭЙЄзїШЫдБЕФЗжРыЁЃЮвШЯЮЊЃЌвЕЮёаЭЕФКЭЪТЮёадЪ§ОнЕФММЪѕКЭЭиЦЫНсЙЙЯрЖдГЩЪьЃЌВЂЧвдкКмДѓГЬЖШЩЯгЩЮЂЗўЮёМмЙЙЧ§ЖЏЁЃЪ§ОнвўВидкУПИіЮЂЗўЮёЕФФкВПЃЌВЂЭЈЙ§ЮЂЗўЮёЕФ
API НјааПижЦКЭЗУЮЪЁЃЪЧЕФЃЌЛЙашвЊМЬајДДаТВХФмеце§ЪЕЯжЖрдЦдЩњвЕЮёаЭЪ§ОнПтНтОіЗНАИЃЌЕЋДгМмЙЙЕФНЧЖШРДПДЃЌвЕЮёаЭЪ§ОнЦНУцвбОТњзуСЫвЕЮёЕФашЧѓЁЃШЛЖјЃЌЙмРэКЭЗУЮЪЗжЮіаЭЪ§ОнШдШЛЪЧЙцФЃЛЏЮЪЬтЁЃЖјетБуЪЧ
Data Mesh ЕФЙизЂЕуЁЃ
ЮвЯраХЃЌдкНЋРДЕФФГИіЪБПЬЃЌВЛЖЯЗЂеЙЕФММЪѕЃЌНЋЪЙетСНИіЦНУцИќМгНєУмЕиСЊЯЕдквЛЦ№ЃЌЕЋОЭФПЧАЖјбдЃЌЮвНЈвщНЋЫќУЧЕФЙизЂЕуЗжПЊЁЃ
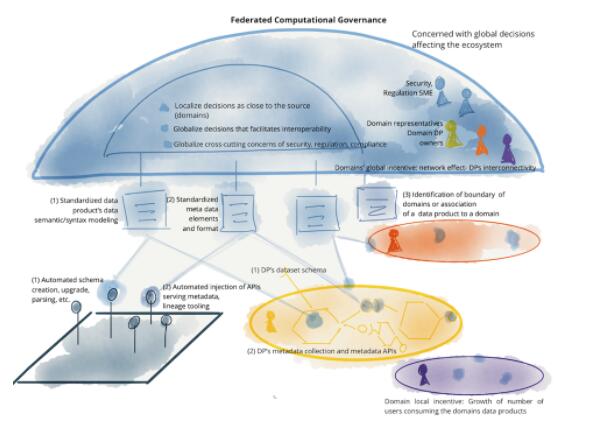
Data Mesh ЕФКЫаФдРэКЭТпММмЙЙ
Data Mesh ЕФФПБъЪЧЮЊДѓЙцФЃЕиДгЗжЮіаЭЪ§ОнКЭРњЪЗЪТЪЕжаЛёЕУМлжЕЬсЙЉЛљДЁЃЌвдЪЪгІЪ§ОнИёОжЕФВЛЖЯБфЛЏЁЂЪ§ОндДКЭЯћЗбепЕФДѓСПгПЯжЃЌгУР§ЫљашЕФзЊЛЛКЭДІРэЕФЖрбљадЃЌЖдБфЛЏЕФЯьгІЫйЖШЁЃЮЊСЫЪЕЯжДЫФПБъЃЌЮвШЯЮЊЃЌШЮКЮ
Data Mesh ЕФЪЕЯжЖМгІЬхЯжЫФИіЛљБОддђЃЌвдЪЕЯжЙцФЃЛЏЕФГаХЕЃЌЭЌЪББЃжЄЪ§ОнПЩгУЫљашЕФжЪСПКЭЭъећадЃК
1ЃЉУцЯђСьгђЕФШЅжааФЛЏЕФЪ§ОнЫљгаШЈКЭМмЙЙЃЌ2 ЃЉЪ§ОнМДВњЦЗЃЛ3ЃЉзджњЪНЪ§ОнЛљДЁЩшЪЉМДЦНЬЈЃЛ4ЃЉСЊКЯжЮРэЁЃ
ОЁЙмЮвдЄМћетаЉддђЕФЪЕМљЁЂММЪѕКЭЪЕЯжЛсЫцзХЪБМфЕФЭЦвЦЖјБфЛЏКЭГЩЪьЃЌЕЋЪЧетаЉддђЛсБЃГжВЛБфЁЃЮвгавтШУетЫФИіддђдкзмЬхЩЯЪЧБивЊКЭГфЗжЕФЃЛвдЪЕЯжОпгаШЭадЕФРЉеЙЃЌЭЌЪБНтОіВЛМцШнЪ§ОнЕФЙТЕККЭдіМгЕФдЫгЊГЩБОЕФЕЃгЧЁЃШУЮвУЧЩюШыбаОПУПИідРэЃЌШЛКѓЩшМЦжЇГжИУдРэЕФИХФюМмЙЙЁЃ
СьгђЫљгаШЈ
Data Mesh ЕФКЫаФЪЧНЋд№ШЮЗжЩЂЃЌВЂЗжХфИјзюНгНќЪ§ОнЕФШЫЃЌДгЖјФмЙЛжЇГжГжајЕФБфИќКЭРЉеЙЁЃЮЪЬтЪЧЃЌШчКЮЗжНтКЭЗжЩЂЪ§ОнЩњЬЌКЭЫќУЧЕФЫљгаШЈЃПетРяЕФзщМўЪЧгЩЗжЮіЪ§ОнЃЌдЊЪ§ОнКЭЗўЮёЪ§ОнЫљашЕФЫуСІзщГЩЁЃData
Mesh бизХзщжЏЕЅдЊЕФНЛНчЯпзїЮЊЗжНтжсЁЃЯждкЮвУЧЕФзщжЏЪЧЛљгкЫћУЧЕФвЕЮёСьгђРДЛЎЗжЕФЁЃетбљЕФЛЎЗжЃЌдкКмДѓГЬЖШЩЯОжВПЛЏСЫГжајБфИќКЭбнНјЫљДјРДЕФгАЯьЁЃвђДЫЃЌЭЈЙ§вЕЮёСьгђЕФЩЯЯТЮФРДЛЎЗжЪ§ОнЕФЫљгаШЈЪЧвЛИіКмКУЕФбЁдёЁЃ
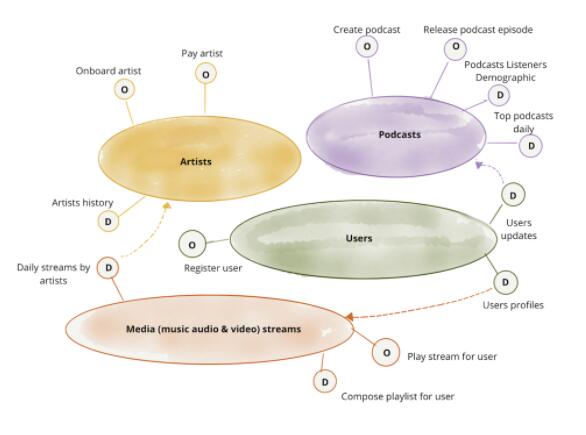
дкБОЮФжаЃЌЮвНЋМЬајЪЙгУКЭжЎЧАЮФеТЯрЭЌЕФгУР§ЃЌвЛМвЪ§зжУНЬхЙЋЫОЁЃФуПЩвдЯыЯѓетМвЙЋЫОЪЧЛљгкСьгђРДЛЎЗжвЕЮёЃЌИїИівЕЮёВПУХЖМгажЇГждЫгЊЕФЯЕЭГКЭЭХЖгЁЃР§ШчЃЌpodcastsЃЈВЅПЭЃЉвЕЮёЃЌЦфЭХЖгКЭЯЕЭГЙмРэ
podcast ЗЂааЮяКЭЦфжїГжШЫЃЛЛЙга artists ЃЈвеЪѕМвЃЉвЕЮёЃЌЦфЭХЖгКЭЯЕЭГИКд№ artists
ЕФШыжАВЂжЇИЖЦфЗбгУЃЌЕШЕШЁЃData Mesh ЕФЙлЕуЪЧЗжЮіЪ§ОнЕФЫљгаШЈКЭЦфЬсЙЉЕФЗўЮёгІИУзёДггкетаЉСьгђЕФЛЎЗжЁЃР§ШчЃЌЖдгкЙмРэ
podcastsЃЌвдМАЬсЙЉ API РДЗЂВМ podcasts ЕФЭХЖгЃЌЫћУЧгІИУЭЌЪБЬсЙЉЙ§ШЅвЛЖЮЪБМфФквбОЗЂВМЕФЁАВЅПЭЁБ
КЭЪеЬ§ТЪЪ§ОнЁЃЯывЊИќЩюШыЕФСЫНтетИіЛЎЗжддђЃЌПЩвдВЮПМЁЖУцЯђСьгђЕФЪ§ОнЗжНтКЭЫљгаШЈЁЗетЦЊЮФеТЁЃ
ТпММмЙЙЃКУцЯђСьгђЕФЪ§ОнКЭМЦЫу
ЮЊСЫЭЦЖЏетбљЕФЛЎЗжЃЌЮвУЧашвЊНЈСЂвЛИіАбЗжЮіЪ§ОнАВЗХЕНИїИіСьгђШЅЕФМмЙЙФЃаЭЁЃдкетИіМмЙЙжаЃЌФГСьгђБЉТЖИјзщжЏжаЦфЫћСьгђЕФНгПкЃЌВЛНіНіБЉТЖвЕЮёФмСІЃЌЛЙБЉТЖЖдгкетИіСьгђЕФЗжЮіЪ§ОнЕФЗУЮЪФмСІЁЃР§ШчЃЌPodcast
етИіСьгђЃЌВЛНіЬсЙЉСЫЁАДДНЈаТвЛМЏЕФ podcastЁБЕФ APIЃЌвВЬсЙЉСЫЛёШЁЁАЙ§ШЅ n ИідТЕФЫљга
podcasts Ъ§ОнЁБЕФНгПкЁЃетвтЮЖзХИУМмЙЙБиаывЦГ§ЫљгазшСІЛђепёюКЯЃЌвдБуШУСьгђЖдЭтБЉТЖЗжЮіЪ§ОнЃЌЗЂВММЦЫуЪ§ОнЕФДњТыЃЌетБиаыЪЧЖРСЂгкЦфЫћСьгђЕФЁЃЮЊСЫРЉеЙЃЌИУМмЙЙБиаыжЇГжИїСьгђЭХЖгЕФзджЮЃЌЪЙЕУИїСьгђЭХЖгФмЙЛзджїЗЂВМКЭВПЪ№ЦфвЕЮёЯЕЭГКЭЗжЮіЪ§ОнЯЕЭГЁЃЯТУцетИіР§згеЙЪОСЫУцЯђСьгђЕФЪ§ОнЫљгаШЈддђЁЃЭМР§жЛЪЧТпМЩЯКЭЪОР§адЕФБэЪОЃЌВЂВЛЪдЭМеЙЪОЭъећЕФР§згЁЃУПИіСьгђПЩвдБЉТЖвЛИіЛђЖрИівЕЮёаЭ
APIЃЌвдМАвЛИіЛђЖрИіЗжЮіаЭЪ§ОнЖЫЕуЁЃ
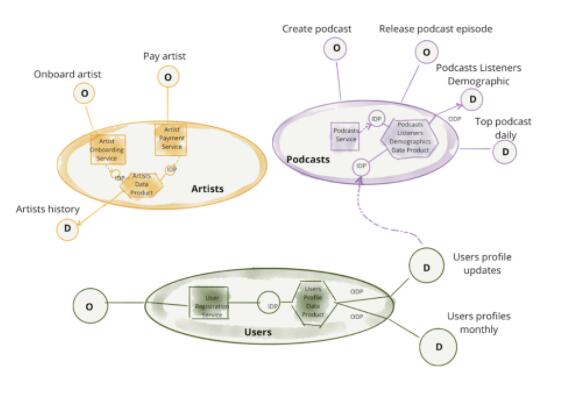
ЭМ 4: зЂвтЃКСьгђЃЌМАЦфАќКЌЕФЗжЮіЪ§ОнФмСІКЭвЕЮёФмСІ
здШЛЕиЃЌИїИіСьгђПЩвдвРРЕЦфЫћСьгђЕФвЕЮёКЭЗжЮіЪ§Он APIЁЃдкЯТУцетИіР§згжаЃЌpodcasts СьгђЯћЗб
users СьгђЬсЙЉЕФгУЛЇИќаТЕФЗжЮіЪ§ОнЃЌДгЖјЭЈЙ§ podcasts Ь§жкЪ§ОнМЏЃЌРДЬсЙЉ podcasts
Ь§жкШЫПкЭГМЦШЋУВЁЃ
ЭМ 5ЃКЪОР§ЃКУцЯђСьгђЛЎЗжЗжЮіЪ§ОнКЭвЕЮёФмСІЫљгаШЈ
дкетИіР§згжаЃЌЮвЪЙгУСЫУќСюЪНЕФгябдРДЗУЮЪвЕЮёЪ§ОнЛђепФмСІЃЌР§ШчИЖЧЎИј artistsЁЃетжЛЪЧЯывЊЧПЕїЗУЮЪвЕЮёЪ§ОнКЭЗжЮіЪ§ОнвтЭМжЎМфЕФВЛЭЌЁЃЪЕМЪЩЯвЕЮё
API ЛсЪЙгУвЛжжИќБэвтЕФЗНЪНРДЪЕЯжЃЌР§ШчЗУЮЪ RESTFul зЪдДЛђепЭЈЙ§ GraphQL ВщбЏЁЃ
Ъ§ОнМДВњЦЗ
ЯжгаЗжЮіаЭЪ§ОнМмЙЙЕФЬєеНжЎвЛЪЧЬНЫїЃЌРэНтЃЌаХШЮвдМАзюжеЪЙгУгХжЪЪ§ОнЕФИпФІВСКЭИпГЩБОЁЃШчЙћВЛНтОіЃЌЫцзХЬсЙЉЪ§ОнЃЈМДСьгђЃЉЕФГЁЫљКЭЭХЖгЪ§СПЕФдіМгЃЌИУЮЪЬтжЛЛсАщЫцзХЪ§ОнЭјИёМгОчЁЃетЪЧ
Data Mesh ЕквЛддђШЅжааФЛЏНЋЛсдьГЩЕФНсЙћЁЃ
Ъ§ОнМДВњЦЗддђжМдкНтОіЪ§ОнжЪСПКЭГТОЩЕФЪ§ОнЙТЕКЮЪЬтЃЛЛђ Gartner ЫљЫЕЕФЁААЕЪ§ОнЁБЁЊЁЊЁАдке§ГЃЕФЩЬвЕЛюЖЏжаЪеМЏЃЌДІРэКЭДцДЂЕФаХЯЂзЪВњЃЌЭЈГЃВЛФмгУгкЦфЫћФПЕФЁБЁЃСьгђЬсЙЉЕФЗжЮіЪ§ОнаыБЛЪгЮЊВњЦЗЃЌЪ§ОнЕФЯћЗбепвВгІИУБЛЪгЮЊПЭЛЇЁЃЁАДгЕЅЬхЪ§ОнКўЕНЗжВМЪНЪ§ОнЭјИёЁБвЛЮФСаОйСЫвЛЯЕСаФмСІЃЌАќРЈПЩЗЂЯжадЃЌАВШЋадЃЌПЩЬНЫїадЃЌПЩРэНтадЃЌПЩаХРЕадЕШЃЌЫљвддкЪЕЯж
Data Mesh ЪБгІИУАбСьгђЪ§ОнЪгЮЊвЛжжВњЦЗЁЃ
етЦЌЮФеТЛЙЯъЯИНщЩмСЫЭХЖгБиаыв§ШыЕФСьгђЪ§ОнВњЦЗИКд№ШЫЃЌИУНЧЩЋИКд№ЖЈвхПЭЙлЕФЖШСПжИБъРДШЗБЃЪ§ОнзїЮЊВњЦЗНЛИЖЁЃетаЉЖШСПжИБъАќРЈЪ§ОнжЪСПЃЌЫѕЖЬЪ§ОнЯћКФЕФЧАжУЪБМфЃЌвдМАвЛАуЖјбдЕФЭЈЙ§ОЛЭЦМіжЕЃЈNet
Promoter ScoreЃЉЫљЬхЯжЕФЪ§ОнгУЛЇТњвтЖШЁЃСьгђЪ§ОнВњЦЗИКд№ШЫБиаыЩюШыСЫНтЪ§ОнгУЛЇЪЧЫЃЌЫћУЧШчКЮЪЙгУЪ§ОнЃЌвдМАЫћУЧЯћЗбЪ§ОнЕФЫГЪжЗНЗЈЁЃЖдЪ§ОнгУЛЇЕФЩюШыСЫНтПЩвдЩшМЦГіТњзуЦфашЧѓЕФЪ§ОнВњЦЗНгПкЁЃЪЕМЪЩЯЃЌЭјИёЩЯЕФДѓЖрЪ§Ъ§ОнВњЦЗЃЌЖМгавЛаЉГЃЙцЕФгУЛЇНЧЩЋЃЌБШШчЪ§ОнЗжЮіЪІКЭЪ§ОнПЦбЇМвЃЌЛљгкЫћУЧЖРгаЕФЙЄОпКЭашЧѓРДЪЙгУЪ§ОнЁЃЫљгаЪ§ОнВњЦЗЖМПЩвдПЊЗЂБъзМЛЏЕФНгПкРДжЇГжЯћЗбепЁЃЪ§ОнгУЛЇгыВњЦЗИКд№ШЫжЎМфЕФЖдЛАЪЧНЈСЂЪ§ОнВњЦЗНгПкЕФБивЊЛЗНкЁЃ
УПИіСьгђЖМЛсгаЪ§ОнВњЦЗПЊЗЂШЫдБЃЌЫћУЧИКд№ЙЙНЈЃЌЮЌЛЄКЭЬсЙЉИїздСьгђЕФЪ§ОнВњЦЗЁЃЪ§ОнВњЦЗПЊЗЂШЫдБНЋгыИУСьгђЕФЦфЫћПЊЗЂШЫдБвЛЦ№ЙЄзїЁЃУПИіСьгђЭХЖгПЩвдЗўЮёвЛИіЛђЖрИіЪ§ОнВњЦЗЁЃвВПЩвдзщНЈаТЕФЭХЖгЃЌИјФЧаЉВЛЪЪКЯЯжгавЕЮёСьгђЕФЪ§ОнВњЦЗЬсЙЉЗўЮёЁЃзЂвтЃКгыЙ§ШЅЕФЗЖЪНЯрБШЃЌетЪЧвЛжжд№ШЮЕФЕЙжУФЃаЭЁЃЪ§ОнжЪСПЕФд№ШЮЯђЩЯгЮзЊвЦЃЌОЁПЩФмППНќЪ§ОндДЁЃ
ТпММмЙЙЃКНЋЪ§ОнВњЦЗЪгЮЊМмЙЙСПзг
дкЬхЯЕНсЙЙЩЯЃЌЮЊСЫжЇГжЪ§ОнзїЮЊСьгђПЩвдзджїЗўЮёЛђЪЙгУЕФВњЦЗЃЌData mesh в§ШыСЫЪ§ОнВњЦЗЕФИХФюЃЌВЂзїЮЊЦфМмЙЙСПзгЁЃгЩбнНјЪНМмЙЙЖЈвхЕФМмЙЙСПзгЪЧзюаЁЕФМмЙЙЕЅдЊЃЌЫќПЩвдЖРСЂВПЪ№ЃЌОпгаИпЖШЕФЙІФмФкОладЃЌВЂАќКЌЦфЙІФмЫљашЕФЫљгаНсЙЙдЊЫиЁЃЪ§ОнВњЦЗЪЧЭјИёЩЯЕФНкЕуЃЌЫќЗтзАСЫЦфЙІФмЫљашЕФШ§ИіНсЙЙзщМўЃЌзїЮЊВњЦЗЬсЙЉЖдСьгђЗжЮіЪ§ОнЕФЗУЮЪЁЃ
ДњТыЃКАќРЈ
(a)Ъ§ОнСїЫЎЯпДњТыЃЌИКд№ЯћЗбЃЌзЊЛЛКЭЗўЮёРДздвЕЮёСьгђЯЕЭГЛђепЩЯгЮЪ§ОнВњЦЗЕФЪ§ОнЃЛ(b) API
ДњТыЃЌЬсЙЉЖдЪ§ОнЁЂгявхКЭгяЗЈФЃЪНЁЂПЩЙлВьаджИБъКЭЦфЫћдЊЪ§ОнЕФЗУЮЪ;(c)ЧПжЦдМЪјадДњТыЃЌАќКЌжюШчЗУЮЪПижЦВпТдЃЌКЯЙцадЃЌРДдДЕШЁЃ
Ъ§ОнКЭдЊЪ§Он:
етОЭЪЧЮвУЧЕФЬжТлФкШнЃЌвдЖржжгябдаЮЬЌЬсЙЉЕзВуЕФЗжЮіКЭРњЪЗЪ§ОнЁЃИљОнСьгђЪ§ОнЕФаджЪМАЦфЯћЗбФЃаЭЃЌЪ§ОнПЩвдЭЈЙ§ЪТМўЃЌХњДІРэЮФМўЁЂЙиЯЕаЭЪ§ОнБэЁЂЭМЕШЗНЪНЬсЙЉИјЯћЗбепЃЌЭЌЪББЃГжЯрЭЌЕФгявхЁЃЮЊСЫЪЙЪ§ОнПЩгУЃЌашвЊЖЈвхвЛзщЯрЙиЕФдЊЪ§ОнЃЌАќРЈЪ§ОнМЦЫуЮФЕЕЁЂгявхКЭгяЗЈЩљУїЁЂжЪСПжИБъЕШЁЃгааЉдЊЪ§ОнЪЧЪ§ОнЫљЙЬгаЕФЃЌР§ШчгяЗЈЖЈвхЃЌЖјгааЉдЊЪ§ОнЭЈЙ§МЦЫужЮРэДЋДяЪ§ОнЬиеїЃЌДгЖјЪЕЯждЄЦкааЮЊЃЌР§Шч
ЗУЮЪПижЦВпТдЁЃ
ЛљДЁЩшЪЉ:
ЛљДЁЩшЪЉзщМўжЇГжЙЙНЈЁЂВПЪ№КЭдЫааЪ§ОнВњЦЗДњТыЃЌвдМАДцДЂКЭЗУЮЪДѓЪ§ОнКЭдЊЪ§ОнЁЃ
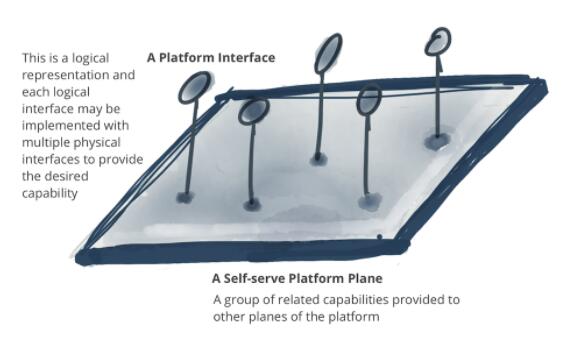
ЭМ 6ЃКЪ§ОнВњЦЗЕФзщГЩВПЗж
ЯТУцЕФЪОР§НЈСЂдкЩЯвЛНкЕФЛљДЁЩЯЃЌеЙЪОСЫЪ§ОнВњЦЗзїЮЊМмЙЙСПзгЁЃЭМР§жЛАќРЈЪОР§ФкШнЃЌВЂВЛЪдЭМАќРЈЭъећЕФЩшМЦКЭЪЕЯжЯИНкЁЃЫфШЛетвРОЩЪЧвЛжжТпМБэЪОЃЌЕЋЫќРыецЪЕЪЕЯжИќНќСЫвЛВНЁЃ

ЭМ 7ЃКзЂвтЃКСьгђЃЌМАЦфАќКЌЕФЗжЮіЪ§ОнФмСІКЭвЕЮёФмСІ
ЭМ 8ЃКЗўЮёгкУцЯђСьгђЗжЮіЪ§ОнЕФЪ§ОнВњЦЗ
зЂвт:Data mesh ФЃаЭВЛЭЌгкЙ§ШЅЕФЗЖЪНЃЌдкЙ§ШЅЕФЗЖЪНжаЃЌЪ§ОнЙмЕРзїЮЊЖРСЂзщМўЙмРэЃЌгыЫќУЧВњЩњЕФЪ§ОнЮоЙи;
ЛљДЁЩшЪЉЃЌБШШчЪ§ОнВжПтЛђЪ§ОнКўДцДЂеЪЛЇЕФЪЕР§ЃЌЭЈГЃЛсдкаэЖрЪ§ОнМЏжЎМфЙВЯэЁЃЪ§ОнВњЦЗЪЧЫљгазщМў(ДњТыЁЂЪ§ОнКЭЛљДЁЩшЪЉ)дкСьгђЯоНчЩЯЯТЮФСЃЖШЩЯЕФзщКЯЁЃ
зджњЪ§ОнЛљДЁЩшЪЉЦНЬЈ
ПЩвдЯыЯѓЃЌвЊЙЙНЈЃЌВПЪ№ЃЌжДааЃЌМрПиКЭЗУЮЪвЛИіВЛЦ№блЕФСљБпаЮЃЈМДЪ§ОнВњЦЗЃЉЃЌашвЊДюНЈКЭдЫааЯрЕБЖрЕФЛљДЁЩшЪЉЁЃгУРДЬсЙЉетаЉЛљДЁЩшЪЉЕФММЪѕЪЧЯрЖдзЈвЕЕФЃЌВЂЧвФбвддкИїИіСьгђжаИДжЦЁЃзюживЊЕФЪЧЃЌЭХЖгФмЙЛзджїЙмРэЦфЪ§ОнВњЦЗЕФЮЈвЛЗНЗЈЃЌОЭЪЧЭХЖгПЩвдЗУЮЪЛљДЁЩшЪЉЕФИпМЖГщЯѓЁЊЁЊетВуГщЯѓвЦГ§СЫДюНЈЪ§ОнВњЦЗКЭЙмРэЪ§ОнВњЦЗЩњУќжмЦкЕФИДдгадКЭФбЖШЁЃетОЭашвЊвЛжжаТЕФддђЃЌМДЪЙСьгђзджЮЕФзджњЪ§ОнЛљДЁЩшЪЉМДЦНЬЈЁЃ
Ъ§ОнЦНЬЈПЩвдБЛЪгЮЊЖдвбОДцдкЕФПЩвддЫааКЭМрПиИїжжЗўЮёЕФНЛИЖЦНЬЈЕФбгЩьЁЃЕЋЯжЪЕЪЧЃЌгУРДВйзїЪ§ОнВњЦЗЕФЕзВуММЪѕеЛгыеыЖдвЕЮёЗўЮёЕФНЛИЖЦНЬЈ
ЫљЪЙгУЕФММЪѕеЛДѓЯрОЖЭЅЁЃетЭъШЋЪЧгЩгкДѓЪ§ОнЦНЬЈгывЕЮёЦНЬЈжЎМфММЪѕеЛЕФВювьЫљЕМжТЕФЁЃР§ШчЃЌСьгђЭХЖгПЩФмЪЙгУ
Docker ШнЦїРДВПЪ№ЦфЗўЮёЃЌЖјНЛИЖЦНЬЈЪЙгУ Kubernetes НјааБрХХЃЛЕЋЪЧЃЌЯрСкЕФЪ§ОнВњЦЗПЩФме§дквд
Spark зївЕЕФаЮЪНдк Databricks ШКМЏЩЯдЫааЪ§ОнСїЫЎЯпДњТыЁЃеташвЊДюНЈКЭСЌНгСНзщЗЧГЃВЛЭЌЕФЛљДЁЩшЪЉЃЌЪ§ОнЭјИёжЎЧАЕФММЪѕВЂВЛашвЊетжжМЖБ№ЕФЛЅСЌадЁЃЮвИіШЫЕФЯЃЭћЪЧЃЌдкКЯРэЕФЕиЗНПЊЪМПДЕНвЕЮёКЭЪ§ОнЛљДЁЩшЪЉЕФШкКЯЁЃР§ШчЃЌЮвЯЃЭћФмЙЛдкКЭвЕЮёЯЕЭГЯрЭЌЕФБрХХЯЕЭГЩЯдЫаа
SparkЃЌБШШч KubernetesЁЃ
ЯжЪЕЪЧЃЌЮЊСЫЪЙЖрУцЪжЕФПЊЗЂШЫдБПЩвдПЊЗЂЗжЮіЪ§ОнВњЦЗЃЌзджњЦНЬЈГ§СЫМђЛЏВњЦЗДюНЈЭтЃЌЛЙашвЊеыЖдМШгаЕФСьгђПЊЗЂШЫдБЬсЙЉвЛЬзаТЕФЙЄОпКЭНгПкРрБ№ЁЃзджњЪ§ОнЦНЬЈБиаыФмДДНЈЙЄОпЃЌвджЇГжСьгђЪ§ОнВњЦЗПЊЗЂШЫдБдкДДНЈЁЂЮЌЛЄКЭдЫааЙЄзїСїЪБМѕЩйЖдзЈвЕММЪѕжЊЪЖЕФвРРЕЁЃЩЯЦЊЮФеТжаЬсЕНСЫзджњЪ§ОнЦНЬЈЬсЙЉвЛЯЕСаЙІФмСаБэЃЌАќРЈЗУЮЪЃКПЩРЉеЙЕФВЛЭЌРраЭЕФЪ§ОнДцДЂЃЌЪ§ОнВњЦЗФЃЪНЃЌЪ§ОнЙмЕРЩљУїКЭБрХХЃЌЪ§ОнВњЦЗбЊдЕЃЌМЦЫуКЭЪ§ОнБОЕиадЕШЁЃ
ТпММмЙЙЃКЖрЦНУцЪ§ОнЦНЬЈ
зджњЗўЮёЦНЬЈЙІФмПЩЗжЮЊЖрИіРрБ№ЛђЦНУцЃЌШчФЃаЭжаЫљЪіЁЃзЂвтЃКЦНУцЖдДцдкВуУцЕФГщЯѓБэДя-ЫћУЧЯрЛЅМЏГЩЕЋЖРСЂЁЃРрЫЦгкЮяРэЛђвтЪЖЦНУцЃЌЛђЭјТчжаЕФПижЦКЭЪ§ОнЦНУцЁЃЦНУцМШВЛЪЧВуЃЌвВВЛвтЮЖзХЩбЯЕФЗжВуЗУЮЪФЃаЭЁЃ
ЭМ 9 зЂвтЃКЦНЬЈжавЛИіЭЈЙ§здЗўЮёНгПкЬсЙЉСЫЖржжЯрЙиФмСІЕФЦНУцзджњЦНЬЈПЩвдОпгаЖрИіЦНУцЃЌУПИіЦНУцЗўЮёгкВЛЭЌРраЭЕФгУЛЇЁЃ дквдЯТЪОР§жаЃЌСаГіСЫШ§ИіВЛЭЌЕФЪ§ОнЦНЬЈЦНУцЃК
Ъ§ОнЛљДЁЩшЪЉХфжУЦНУцЃКжЇГжЕзВуЛљДЁЩшЪЉЕФХфжУЃЌетЪЧдЫааЪ§ОнВњЦЗКЭЭјИёЫљБиашЕФЁЃЦфжаАќРЈХфжУЗжВМЪНЮФМўДцДЂЃЌДцДЂеЪЛЇЃЌЗУЮЪПижЦЙмРэЯЕЭГЃЌдЫааЪ§ОнВњЦЗФкВПДњТыЕФБрХХв§ЧцЃЌвдМАЮЊЪ§ОнВњЦЗМЏШКЬсЙЉЗжВМЪНВщбЏв§ЧцЕШЁЃЮвЯЃЭћЦфЫћШЮКЮЪ§ОнЦНЬЈЛђИпМЖЪ§ОнВњЦЗПЊЗЂШЫдБЖМФмжБНгЪЙгУетИіЦНУцЬсЙЉЕФНгПкЁЃетЪЧвЛИіЯрЕБЕзВуЕФЪ§ОнЛљДЁЩшЪЉЩњУќжмЦкЙмРэЦНУцЁЃ
Ъ§ОнВњЦЗПЊЗЂШЫдБЬхбщЦНУцЃКетЪЧЕфаЭЕФЪ§ОнВњЦЗПЊЗЂШЫдБжївЊЪЙгУЕФНгПкЁЃетаЉНгПкГщЯѓСЫаэЖрИДдгЕФФкШнЃЌвджЇГжЪ§ОнВњЦЗПЊЗЂШЫдБЕФЙЄзїСїГЬЁЃЫќЬсЙЉСЫБШЁАХфжУЦНУцЁБИќИпЕФГщЯѓМЖБ№ЁЃЫќЪЙгУМђЕЅЕФЩљУїадНгПкРДЙмРэЪ§ОнВњЦЗЕФЩњУќжмЦкЁЃЫќЛсздЖЏКсЧавЛаЉЙизЂЕуЃЌетаЉЙизЂЕуБЛЖЈвхЮЊЮЊвЛзщБъзМКЭШЋОждМЖЈЃЌЪЪгУгкЫљгаЪ§ОнВњЦЗМАЦфНгПкЁЃ
Ъ§ОнЭјИёМрЖНЦНУцЃКгааЉФмСІзюКУФмдкЭјИёЃЈЪ§ОнВњЦЗаЮГЩЕФЭјТчЃЉВуУцШЋОжЕиЬсЙЉЁЃОЁЙмУПИіНгПкЕФЪЕЯжПЩФмЖМвРРЕгкЕЅЖРЕФЪ§ОнВњЦЗЙІФмЃЌЕЋдкЭјИёВуУцЬсЙЉетаЉЙІФмИќЮЊЗНБуЁЃР§ШчЃЌзюКУЭЈЙ§ЫбЫїЛђфЏРРЪ§ОнВњЦЗЕФЭјИёРДЬсЙЉЗЂЯжЬиЖЈгУР§ЕФЪ§ОнВњЦЗЕФФмСІЃЛЛђепзюКУЭЈЙ§дкЪ§ОнЭјИёЩЯжДааПчЪ§ОнВњЦЗЕФЪ§ОнгявхВщбЏВйзїРДДДдьИќИпНзЕФЖДМћЁЃ
вдЯТФЃаЭНіЪЧЪОР§адЕФЃЌВЂВЛЭъећЁЃОЁЙмЭМжаЦНУцМфДцдкВуМЖЃЌЕЋВЂВЛБэЪОЦНУцМфДцдкбЯИёЕФВуМЖЙиЯЕЁЃ
ЭМ 10ЃКЖрЦНУцЕФздЗўЮёЪ§ОнЦНЬЈ Цфжа DP жИЕФЪЧЪ§ОнВњЦЗ
СЊКЯжЮРэ
е§ШчФуЫљПДЕНЕФЃЌЪ§ОнЭјИёзёбЗжВМЪНЯЕЭГМмЙЙЃЌгЩЖРСЂЕФЪ§ОнВњЦЗзщГЩЃЌУПИіЪ§ОнВњЦЗОпгаЖРСЂЕФЩњУќжмЦкЃЌЭЈГЃгЩЖРСЂЭХЖгЙЙНЈКЭВПЪ№
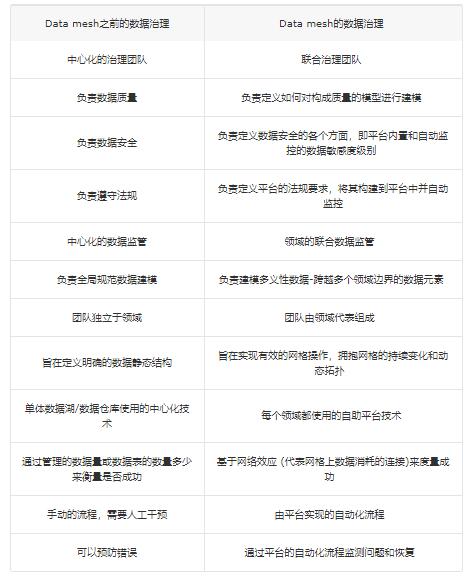
ЁЃШЛЖјЃЌдкДѓЖрЪ§ЯжЪЕГЁОАЯТЃЌЮЊСЫЭЈЙ§ИпНзЪ§ОнМЏЁЂЖДМћвдМАЛњЦїжЧФмЕФаЮЪНЛёШЁМлжЕЃЌЖРСЂЕФЪ§ОнВњЦЗашвЊЯрЛЅВйзїЃЛВЂФмЙЛШУЪ§ОнЯрЛЅЙиСЊЁЂКЯВЂЁЂевЕННЛМЏЃЌЛђепЖдЪ§ОнНјааДѓЙцФЃЕФЭМЛђМЏКЯВйзїЁЃЮЊСЫЪЕЯжетаЉВйзїЃЌЪ§ОнЭјИёЕФЪЕЯжашвЊвЛИіжЮРэФЃаЭЃЌетИіФЃаЭАќКЌШЅжааФЛЏЃЌСьгђзджЮЃЌжЇГжШЋОжБъзМЛЏЕФЛЅВйзїадЁЂЖЏЬЌЭиЦЫЃЌвдМАзюживЊЕФЪЧгЩЦНЬЈздЖЏжДааОіВпЁЃЮвГЦжЎЮЊСЊКЯМЦЫужЮРэЁЃ
ЫќЪЧгЩСьгђЪ§ОнВњЦЗОРэКЭЪ§ОнЦНЬЈВњЦЗОРэзщГЩЕФСЊКЯЫљСьЕМЕФОіВпФЃаЭЃЌОпБИзджЮШЈКЭСьгђФкЕФОіВпФмСІЃЌЭЌЪБДДНЈКЭзёЪивЛЬзШЋОжЙцдђЃЌетЬзЙцдђгІгУгкЫљгаЪ§ОнВњЦЗМАЦфНгПкЃЌвдШЗБЃвЛИіНЁПЕКЭПЩЛЅВйзїЕФЩњЬЌЯЕЭГЁЃИУаЁзщгавЛЯюМЌЪжЕФЙЄзїЃКШчКЮБЃГжжабыжааФЛЏКЭШЅжааФЛЏжЎМфЕФЦНКтЃЛФФаЉОіВпашвЊзїгУгкЕЅИіСьгђЃЌФЧаЉОіВпашвЊзїгУгкЫљгаСьгђЁЃзюжеЃЌШЋОжОіВпгавЛИіФПЕФЃЌМДЭЈЙ§ЗЂЯжКЭзщКЯЪ§ОнВњЦЗРДДДдьЛЅВйзїадКЭИДдгЕФЭјТчаЇгІЁЃData
mesh жажЮРэЕФгХЯШМЖВЛЭЌгкДЋЭГЕФЗжЮіаЭЪ§ОнЙмРэЯЕЭГЁЃЫфШЛЫќУЧзюжеЖМЯЃЭћДгЪ§ОнжаЛёШЁМлжЕЃЌЕЋЪЧДЋЭГЕФЪ§ОнжЮРэЪдЭМЭЈЙ§жааФЛЏЕФОіВпШЈРДДяГЩФПБъВЂНЈСЂШЋОжЙцЗЖЕФЪ§ОнГЪЯжЗНЪНЃЌЕЋФбвджЇГжБфИќЁЃЯрЗДЕФЪЧЃЌ
Data mesh ЕФСЊКЯМЦЫужЮРэгЕБЇБфЛЏКЭЖржжНтЪЭадЩЯЯТЮФЁЃ
НЋЯЕЭГжУгкКуЖЈзДЬЌЛсЕМжТбнНјЕФДрШѕЁЃ-- C.S. Holling, ecologist
ТпММмЙЙЃКЯђЭјИёжаЧЖШыЕФМЦЫуВпТд
жЇГжаЭЕФзщжЏНсЙЙЁЂМЄРјФЃаЭКЭМмЙЙЖдгкСЊКЯжЮРэФЃаЭЕФдЫааБиВЛПЩЩйЃКЫќУЧгажњгкдкз№жиБОЕиСьгђзджЮЕФЭЌЪБЃЌжЦЖЈШЋОжЛЅВйзїадОіВпКЭБъзМЃЌВЂгааЇЪЕЪЉШЋОжеўВпЁЃ
ЭМ 11ЃКзЂвтЃКСЊКЯМЦЫужЮРэФЃаЭ
ШчЧАЫљЪіЃЌФФаЉгІИУеыЖдЫљгаСьгђКЭЦфЪ§ОнВњЦЗНјааШЋОжБъзМЛЏЃЌЪЕЪЉЃЌЩѕжСЧПжЦжДааЃПФФаЉгІИУСєИјСьгђздМКОіВпЃПдкетСНИіЮЪЬтжЎМфзїГіЦНКтЪЧвЛУХвеЪѕЁЃР§ШчЃЌСьгђЪ§ОнФЃаЭгІИУЪЧСьгђздЩэашвЊЙизЂЕФЮЪЬтЃЌвђЮЊСьгђзюЪьЯЄЫќЁЃОЭЯёЃЌШчКЮЖЈвхЁАВЅПЭЪмжкЁБЪ§ОнФЃаЭЕФгявхКЭгяЗЈЃЌетМўЪТЧщБиаыНЛИјЁАВЅПЭСьгђЁБЭХЖгЁЃШЛЖјЃЌЯрБШжЎЯТЃЌШчКЮЪЖБ№ЁАВЅПЭЬ§жкЁБЪЧвЛИіШЋОжЙизЂЕФЮЪЬтЁЃpodcast
Ь§жкЪЧЁАгУЛЇЁБШКЬхЃЈЦфЩЯгЮЯоНчЩЯЯТЮФЃЉЕФГЩдБЃЌЫћУЧПЩвдПчдНСьгђЕФБпНчВЂЭЌЪБДцдкгкЁАгУЛЇВЅЗХСїЁБжЎРрЕФЦфЫћСьгђЁЃЭГвЛЕФБъЪЖШУЮвУЧПЩвдЙиСЊМШЪЧЁАpodcast
Ь§жкЁБгжЪЧЁАВЅЗХСїЬ§жкЁБЕФЁАгУЛЇЁБЕФаХЯЂЁЃвдЯТЪЧ data mesh ЙмРэФЃаЭжаЩцМАЕФдЊЫиЕФЪОР§ЁЃетВЛЪЧвЛИіШЋУцЕФР§згЃЌНіЫЕУїСЫдкШЋОжЗЖЮЇФкЕФЯрЙиЮЪЬтЁЃ
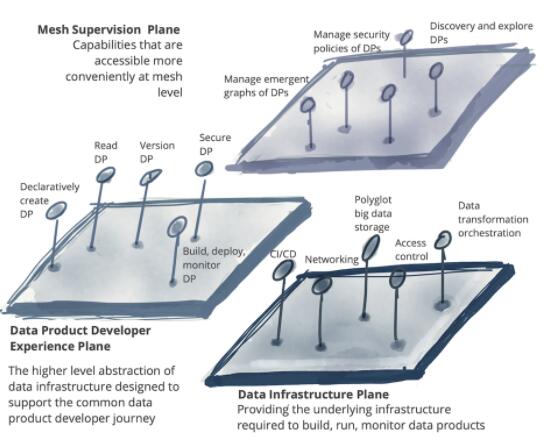
ЭМ 12ЃКСЊКЯжЮРэАќКЌЕФдЊЫиЪОР§ЃКЭХЖгЃЌЖЏЛњ//TODOЃЌздЖЏЪЕЯжКЭШЋОжБъзМЛЏ
зїЮЊжааФЛЏЕФжАФмЃЌ Ъ§ОнЭјИёжЎЧАЕФКмЖржЮРэЪЕМљЃЌВЛдйЪЪгУгкЪ§ОнЭјИёЁЃР§ШчЃЌЙ§ШЅБЛШЯЮЊЗЧГЃживЊЕФЛЦН№Ъ§ОнМЏШЯжЄЃЈМДОЙ§МЏжажЪСППижЦКЭШЯжЄЙ§ГЬВЂБъМЧЮЊПЩаХРЕЕФЪ§ОнМЏЃЉзїЮЊжааФжЮРэЙІФмНЋВЛдйЪЪгУЁЃ
етдДгквдЯТЪТЪЕЃКдквдЧАЕФЪ§ОнЙмРэЗЖР§жаЃЌЮоТлжЪСПКЭИёЪНШчКЮЃЌЪ§ОнЖМЪЧДгвЕЮёСьгђЪ§ОнПтжаЬсШЁЃЌВЂМЏжаДцДЂдкЪ§ОнВжПтЛђЪ§ОнКўжаЃЌЯждкашвЊжааФЛЏЕФЭХЖгРДЖдЪ§ОнНјааЧхЯДЃЌећРэКЭМгУмЃЛетЭЈГЃгЩжабыжЮРэаЁзщИКд№ЁЃЪ§ОнЭјИёЭъШЋЗжЩЂСЫетаЉЮЪЬтЁЃСьгђЪ§ОнМЏНідкСьгђФкЭЈЙ§СЫжЪСПБЃеЯДІРэЃЈТњзудЄЦкЕФЪ§ОнВњЦЗжЪСПжИБъКЭШЋОжБъзМЛЏЙцдђЃЉжЎКѓЃЌВХГЩЮЊЪ§ОнВњЦЗЁЃСьгђЪ§ОнВњЦЗОРэзюЯШОіЖЈШчКЮКтСПЦфСьгђЕФЪ§ОнжЪСПЃЌвђЮЊЫћУЧзюдчСЫНтВњЩњЪ§ОнЕФСьгђВйзїЕФЯъЯИаХЯЂЁЃОЁЙмгаетбљЕФБОЕиЛЏОіВпКЭзджЮШЈЃЌЕЋЫќУЧШдашвЊзёбгЩШЋОжСЊКЯжЮРэЭХЖгЖЈвхВЂгЩЦНЬЈздЖЏЛЏЕФШЋОжжЪСПБъзМКЭ
SLOЃЈЗўЮёЫЎЦНФПБъЃЉЙцИёНјааНЈФЃЁЃЯТБэеЙЪОСЫжааФЛЏЕФЪ§ОнжЮРэЃЈШчЪ§ОнКўЁЂЪ§ОнВжПтЃЉФЃаЭКЭЪ§ОнЭјИёжЎМфЕФЖдБШЁЃ
ддђзмНсгыЖЅВуТпММмЙЙ
злЩЯЫљЪіЃЌЮвУЧЬжТлСЫжЇГХ Data mesh ЕФЫФИіддђЁЃ
УцЯђСьгђЕФШЅжааФЛЏЪ§ОнЫљгаШЈКЭМмЙЙ
вђДЫЃЌЩњВњКЭЯћЗбЪ§ОнЕФЩњЬЌЯЕЭГПЩвдЫцзХЪ§ОндДЕФЪ§СПЁЂгУР§ЕФЪ§СПКЭЪ§ОнЗУЮЪФЃаЭЕФЖрбљадЕФдіМгЖјРЉеЙ;
жЛашдіМгЭјИёЩЯЕФзджЮНкЕуОЭПЩвдЪЕЯжетжжРЉеЙЁЃ
Ъ§ОнМДВњЦЗ
вђДЫЃЌеыЖдЗжВМдкЖрИіСьгђЕФЪ§ОнЃЌЦфЪЙгУепПЩвдКмЗНБуЕиШЅЗЂЯжЁЂРэНтвдМААВШЋЕиШЅЪЙгУетаЉИпжЪСПЕФЪ§ОнЃЌЭЌЪБЛёЕУСМКУЕФЯћЗбепЬхбщЁЃ
зджњЪ§ОнЛљДЁЩшЪЉМДЦНЬЈ
вђДЫЃЌСьгђЭХЖгОЭПЩвдЭЈЙ§ЦНЬЈГщЯѓзджїЕиДДНЈКЭЪЙгУЪ§ОнВњЦЗЃЌДгЖјвўВиСЫЙЙНЈЁЂжДааКЭЮЌЛЄАВШЋЧвПЩЛЅВйзїЕФЪ§ОнВњЦЗЕФИДдгадЁЃ
СЊКЯжЮРэ
вђДЫЃЌЪ§ОнгУЛЇПЩвдДгЖРСЂЪ§ОнВњЦЗЕФОлКЯКЭЙиСЊжаЛёЕУМлжЕЁЊЁЊЪ§ОнЭјИёОЭЯёзёбШЋОжЛЅВйзїадБъзМЕФЩњЬЌЯЕЭГЃЌЭЈЙ§МЦЫуНЋБъзМећКЯЕНЦНЬЈжаЁЃетаЉдРэаЮГЩСЫвЛИіТпММмЙЙФЃаЭЃЌЪЙЗжЮіЪ§ОнКЭвЕЮёЪ§ОндкЭЌвЛИіСьгђжаИќМгНєУмЕиСЊЯЕдквЛЦ№,
ЭЌЪБз№жиЫќУЧЕФЛљДЁММЪѕЕФВювьЁЃетаЉВювьАќРЈЗжЮіЪ§ОнЕФДцДЂЮЛжУЃЌДІРэвЕЮёЗўЮёКЭЗжЮіЗўЮёЕФВЛЭЌМЦЫуЛњММЪѕЃЌВщбЏКЭЗУЮЪЪ§ОнЕФВЛЭЌЗНЪНЕШЕШЁЃ

ЭМ 13ЃКЪ§ОнЭјИёЕФТпММмЙЙ
ЮвЯЃЭћЕНетРяЮвУЧвбОНЈСЂСЫвЛЬзЭЈгУЕФгябдКЭТпМЫМЮЌФЃаЭЃЌПЩвдгУРДНјвЛВНЯъЪі Data Mesh зщМўЕФРЖЭМЃЌР§ШчЪ§ОнВњЦЗЃЌЪ§ОнЦНЬЈКЭБиашЕФБъзМЁЃ
|








