|
一、高性能WEB开发之如何加载JavaScript
所有浏览器在下载JS的时候,会阻止一切其他活动,比如其他资源的下载,内容的呈现等等。至到JS下载、解析、执行完毕后才开始继续并行下载其他资源并呈现内容。为什么JS不能像CSS、image一样并行下载了?
外部JS的阻塞下载
所有浏览器在下载JS的时候,会阻止一切其他活动,比如其他资源的下载,内容的呈现等等。至到JS下载、解析、执行完毕后才开始继续并行下载其他资源并呈现内容。
有人会问:为什么JS不能像CSS、image一样并行下载了?这里需要简单介绍一下浏览器构造页面的原理,
当浏览器从服务器接收到了HTML文档,并把HTML在内存中转换成DOM树,在转换的过程中如果发现某个节点(node)上引用了CSS或者IMAGE,就会再发1个request去请求CSS或image,然后继续执行下面的转换,而不需要等待request的返回,当request返回后,只需要把返回的内容放入到DOM树中对应的位置就OK。但当引用了JS的时候,浏览器发送1个js
request就会一直等待该request的返回。因为浏览器需要1个稳定的DOM树结构,而JS中很有可能有代码直接改变了DOM树结构,比如使用document.write
或 appendChild,甚至是直接使用的location.href进行跳转,浏览器为了防止出现JS修改DOM树,需要重新构建DOM树的情况,所以就会阻塞其他的下载和呈现.
阻塞下载图:下图是访问blogjava首页的时间瀑布图,可以看出来开始的2个image都是并行下载的,而后面的2个JS都是阻塞下载的(1个1个下载)。

嵌入JS的阻塞下载
嵌入JS是指直接写在HTML文档中的JS代码。上面说了引用外部的JS会阻塞其后的资源下载和其后的内容呈现,哪嵌入的JS又会是怎样阻塞的了,看下面的列2个代码:
代码1:
<</span>div>
ul>
li>blogjavaspan style="color: #800000;">li>
li>CSDNspan style="color: #800000;">li>
li>博客园span style="color: #800000;">li>
li>ABCspan style="color: #800000;">li>
li>AAAspan style="color: #800000;">li>
ul>
span style="color: #800000;">div>
script type="text/javascript">
// 循环5秒钟
var n = Number(new Date());
var n2 = Number(new Date());
while((n2 - n) (6*1000)){
n2 = Number(new Date());
}
span style="color: #800000;">script>
div>
ul>
li>MSNspan style="color: #800000;">li>
li>GOOGLEspan style="color: #800000;">li>
li>YAHOOspan style="color: #800000;">li>
ul>
span style="color: #800000;">div> |
代码2(test.zip里面的代码与代码1的JS代码一模一样):
div>
ul>
li>blogjavaspan style="color: #800000;">li>
li>CSDNspan style="color: #800000;">li>
li>博客园span style="color: #800000;">li>
li>ABCspan style="color: #800000;">li>
li>AAAspan style="color: #800000;">li>
ul>
span style="color: #800000;">div>
script type="text/javascript" src="http://www.blogjava.net/Files/BearRui/test.zip">span
style="color: #800000;">script>
div>
ul>
li>MSNspan style="color: #800000;">li>
li>GOOGLEspan style="color: #800000;">li>
li>YAHOOspan style="color: #800000;">li>
ul>
span style="color: #800000;">div> |
运行后,会发现代码1中,在前5秒中页面上是一篇空白,5秒中后页面全部显示。
代码2中,前5秒中blogjava,csdn等先显示出来,5秒后MSN才显示出来。
可以看出嵌入JS会阻塞所有内容的呈现,而外部JS只会阻塞其后内容的显示,2种方式都会阻塞其后资源的下载。
嵌入JS导致CSS阻塞加载的问题
CSS怎么会阻塞加载了?CSS本来是可以并行下载的,在什么情况下会出现阻塞加载了(在测试观察中,IE6下CSS都是阻塞加载,下面的测试在非IE6下进行):
代码1(为了效果,这里选择了1个国外服务器的CSS):
html xmlns="http://www.w3.org/1999/xhtml">
head>
title>js testspan style="color: #800000;">title>
meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
link type="text/css" rel="stylesheet" href="http://69.64.92.205/Css/Home3.css" />
span style="color: #800000;">head>
body>
img src="http://www.blogjava.net/images/logo.gif" /><</span>br />
img src="http://csdnimg.cn/www/images/csdnindex_piclogo.gif" />
span style="color: #800000;">body>
span style="color: #800000;">html> |
时间瀑布图:

代码2(只加了1个空的嵌入JS):
head>
title>js testspan style="color: #800000;">title>
meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
link type="text/css" rel="stylesheet" href="http://69.64.92.205/Css/Home3.css" />
script type="text/javascript">
function a(){}
span style="color: #800000;">script>
span style="color: #800000;">head>
body>
img src="http://www.blogjava.net/images/logo.gif" /><</span>br />
img src="http://csdnimg.cn/www/images/csdnindex_piclogo.gif" />
span style="color: #800000;">body> |
时间瀑布图:

从时间瀑布图中可以看出,代码2中,CSS和图片并没有并行下载,而是等待CSS下载完毕后才去并行下载后面的2个图片,当CSS后面跟着嵌入的JS的时候,该CSS就会出现阻塞后面资源下载的情况。
有人可能会问,这里为什么不说说嵌入的JS阻塞了后面的资源,而是说CSS阻塞了? 想想我们现在用的是1个空函数,解析这个空函数1ms就够,而后面2个图片是等CSS下载完1.3s后才开始下载。大家还可以试试把嵌入JS放到CSS前面,就不会出现阻塞的情况了。
根本原因:因为浏览器会维持html中css和js的顺序,样式表必须在嵌入的JS执行前先加载、解析完。而嵌入的JS会阻塞后面的资源加载,所以就会出现上面CSS阻塞下载的情况。
嵌入JS应该放在什么位置
1、放在底部,虽然放在底部照样会阻塞所有呈现,但不会阻塞资源下载。
2、如果嵌入JS放在head中,请把嵌入JS放在CSS头部。
3、使用defer
4、不要在嵌入的JS中调用运行时间较长的函数,如果一定要用,可以用setTimeout来调用
PS:很多网站喜欢在head中嵌入JS,并且习惯放在CSS后面,比如看到的www.qq.com,当然也有很多网站是把JS放到CSS前面的,比如yahoo,google
二、高性能WEB开发之如何减少请求数
每次请求都会带上一些额外的信息进行传输(这次请求中还没有带cookie),当请求的资源很小,比如1个不到1k的图标,可能request带的数据比实际图标的数据量还大。所以当请求越多的时候,在网络上传输的数据自然就多,传输速度自然就慢了。所以要要减少请求数,那如何减少请求数呢?
我们先分析下请求头,看看每次请求都带了那些额外的数据.下面是监控的google的请求头
Host www.google.com.hk
User-Agent Mozilla/5.0 (Windows; U; Windows NT
5.2; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3
GTBDFff GTB7.0
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language zh-cn,en-us;q=0.7,en;q=0.3
Accept-Encoding gzip,deflate
Accept-Charset ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive 115
Proxy-Connection keep-alive
返回的response head
Date Sat, 17 Apr 2010 08:18:18 GMT
Expires -1
Cache-Control private, max-age=0
Content-Type text/html; charset=UTF-8
Set-Cookie PREF=ID=b94a24e8e90a0f50:NW=1:TM=1271492298:LM=1271492298:S=JH7CxsIx48Zoo8Nn;
expires=Mon, 16-Apr-2012 08:18:18 GMT; path=/;
domain=.google.com.hk NID=33=EJVyLQBv2CSgpXQTq8DLIT2JQ4aCAE9YKkU2x-h4hVw_ATrGx7njA69UUBMbzVHVnkAOe_jlGGzOoXhQACSFDP1i53C8hWjRTJd0vYtRNWhGYGv491mwbngkT6LCYbvg;
expires=Sun, 17-Oct-2010 08:18:18 GMT; path=/;
domain=.google.com.hk; HttpOnly
Content-Encoding gzip
Server gws
Content-Length 4344 |
这里发送的请求头的大小大概420 bytes,返回的请求头大概 600
bytes。
可见每次请求都会带上一些额外的信息进行传输(这次请求中还没有带cookie),当请求的资源很小,比如1个不到1k的图标,可能request带的数据比实际图标的数据量还大。
所以当请求越多的时候,在网络上传输的数据自然就多,传输速度自然就慢了。
其实request自带的数据量还是小问题,毕竟request能带的数据量还是有限的。
http连接的开销
相比request头部多余的数据,http连接的开销则更加严重。先看看从用户输入1个URL到下载内容到客户端需要经过哪些阶段:
1. 域名解析
2. 开启TCP连接
3. 发送请求
4. 等待(主要包括网络延迟和服务器处理时间)
5. 下载资源
可能很多人认为每次请求大部分时间都花在下载资源上,让我们看看blogjava资源下载瀑布图(每种颜色代表的阶段与上面5个阶段对应):
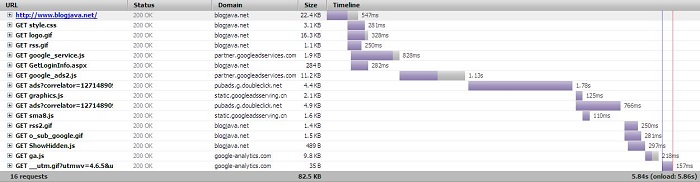
看了上图你可能惊讶,花费在等待阶段的时间比实际下载的时间要多的多,上图告诉我们:
1. 每次请求花费的大部分时间在其他阶段,而不是在下载资源阶段
2. 再小的资源照样会花费很多时间在其他阶段,只是下载阶段会比较短(见上图的第6个资源,才284Byte)。
正对上面提到的2种情况,我们应该要怎么进行优化了?减少请求数来减少其他阶段的花销和网络中传输的数据。
如何减少请求数
1、合并文件
合并文件就是把很多JS文件合并成1个文件,很多CSS文件合并成1个文件,这种方法应该很多人用到过,这里不做详细介绍,
只推荐1个合并的工具:yuiCompressor 这个工具yahoo提供的。 http://developer.yahoo.com/yui/compressor/
2、合并图片
这是利用css sprite,通过控制背景图片的位置来显示不同的图片。这种技术也是大家都用过的,不做详细介绍,推荐1个在线合并图片的网站:http://csssprites.com/
3、把JS、CSS合并到1个文件
上面第1种方法说的只是把几个JS文件合并成1个JS文件,几个CSS文件合并成1个CSS文件,哪如何把CSS和JS都合并到1个文件中,见我的另1篇文章:
http://www.blogjava.net/BearRui/archive/2010/04/18/combin_css_js.html
4、使用Image maps
Image maps 是把多个图片合并成1个图片,然后使用html中的标签连接图片,并实现点击图片不同的区域执行不同的动作,image
map在导航条中比较容易使用到。
image map的使用方法见: http://www.w3.org/TR/html401/struct/objects.html#h-13.6
5、data嵌入图片
这种方法把图片进行编码直接嵌入到html中进行使用,以减少HTTP请求,但这个会增加HTML页面的大小,而且这样嵌入的图片不能缓存。见下面这个图片:
上面的图片就是把图片进行base64编码后使用data:嵌入到html中,代码如下(后面的省略了,大家可以查看源代码看):
<IMG SRC="data:image/gif;base64,/9j/4AAQSkZJRgABAQEAYABgAAD/4QAWRXhpZgAASUkqAAgAA......"> |
其中google的视频搜索中,搜索出来的视频缩略图就都是使用嵌入的图片的,见下图:
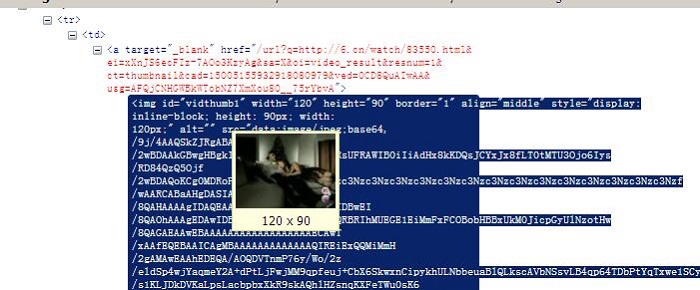
以上几种方法在都有利有弊,在不同情况下可以选择不同的使用方式,比如使用data嵌入图片虽然减少了请求数,但会增加页面大小。
所以微软的bing搜索在用户第一次访问的时候使用data嵌入图片,然后后台懒加载真真的图片,以后访问就直接使用缓存的图片,而不使用data。
三、高性能WEB开发之减少请求、响应的数据量
这次说说如何减少请求、响应的数据量(即在网络中传输的数据量),减少传输的数据量不仅仅可以加快页面加载速度,更可以节约服务器带宽,为你剩不少钱(好像很多机房托管都是按流量算钱的).
上一篇中我们说到了 如何减少请求数,这次说说如何减少请求、响应的数据量(即在网络中传输的数据量),减少传输的数据量不仅仅可以加快页面加载速度,更可以节约服务器带宽,为你剩不少钱(好像很多机房托管都是按流量算钱的)。
GZIP压缩
gzip是目前所有浏览器都支持的一种压缩格式,IE6需要SP1及以上才支持(别说你还在用IE5,~_~)。gzip可以说是最方便而且也是最大减少响应数据量的1种方法。
说它方便,是因为你不需要为它写任何额外的代码,只需要在http服务器上加上配置都行了,现在主流的http服务器都支持gzip,各种服务器的配置这里就不一一介绍(其实是我不知道怎么配),
nginx的配置可以参考我这篇文章:www.blogjava.net/BearRui/archive/2010/01/29/web_performance_server.html
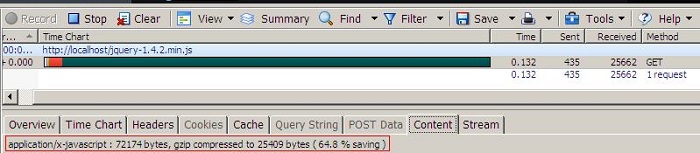
我们先看看gzip的压缩比率能达到多少,这里用jquery 1.4.2的min和src2个版本进行测试,使用nginx服务器,gzip压缩级别使用的是4:
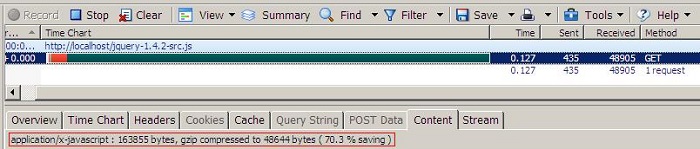
注意看上图的红色部分,jquery src文件在启用gzip后大小减少了70%
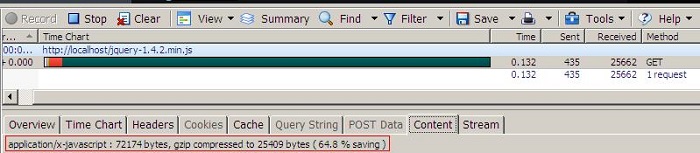
这张图片可以看出就算是已经压缩过min.js在启用gzip后大小也减少了65%。
别对图片启用gzip
在知道了gzip强大的压缩能力后,你是否想对服务器上的所有文件启用gzip了,先让我们看看图片中启用gzip后会是什么情况。
hoho,1个gif图片经过gzip压缩后反而变大了???这是因为图片本来就是一种压缩格式,gzip不能再进行压缩,反而会添加1些额外的头部信息,所以图片会变大。
在测试过程中,发现jpg的图片经过gzip压缩后会变小,不知道为何,可能跟图片压缩方式有关。不过压缩比率也比较小,所以就算是jpg,建议也不要开启gzip压缩。
比较适合启用gzip压缩的文件有如下这些:
1. javascript
2. CSS
3. HTML,xml
4、plain text
别乱用cookie
现在几乎没有哪个网站不使用cookie了,可是该怎么使用cookie比较合适了,cookie有几个重要的属性:path(路径),domain(域),expires(过期时间)。浏览器就是根据这3个属性来判断在发送请求的时候是否需要带上这个cookie。
cookie使用最好的方式,就是当请求的资源需要cookie的时候才带上该cookie。其他任何请求都不带上cookie。但事实上很多人在使用cookie的时候已经习惯性的设置成:path=/
domain=.domain.com。这样的结果就是不管任何请求都会带上cookie,就算你是请求的图片(img.domain.com)、静态资源服务器(res.domain.com)这些根本不需要cookie的资源,浏览器照样会带上这些没用的cookie。咱们一起来看现实中的1个列子,博客园(www.cnblogs.com):
先看看博客园的cookie是怎么设置的,下面是firefox查看博客园cookie的截图:
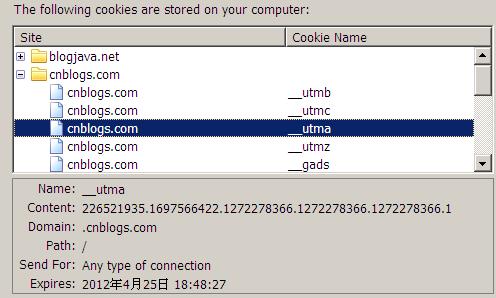
cnblogs总共有5个cookie值,而且全部设置都是 path=/ domain=.cnblogs.com。知道了cookie的设置后,我们再来监控下博客园首页的请求,监控的统计信息如下:
总请求数:39(其中图片22个,JS7个,css2个)。
其中js、css、image 主要来自3个静态资源服务器: common.cnblogs.com ,
pic.cnblogs.com ,static.cnblogs.com
再看其中1个请求图片(http://static.cnblogs.com/images/a4/banner_job.gif)的请求头:
Host static.cnblogs.com
User-Agent Mozilla/5.0 (Windows; U; Windows NT
5.2; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3
GTBDFff GTB7.0
Accept image/png,image/*;q=0.8,*/*;q=0.5
Accept-Language zh-cn,en-us;q=0.7,en;q=0.3
Accept-Encoding gzip,deflate
Accept-Charset ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive 115
Proxy-Connection keep-alive
Referer http://www.cnblogs.com/
Cookie __gads=ID=a15d7cb5c3413e56:T=1272278620:S=ALNI_MZNMr6_d_PCjgkJNJeEQXkmZ3bxTQ;
__utma=226521935.1697566422.1272278366.1272278366.1272278366.1;
__utmb=226521935.2.10.1272278366; __utmc=226521935;
__utmz=226521935.1272278367.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none) |
我们发现在请求banner_job.gif这个图片的时候,浏览器把cnblogs.com的所有cookie都带上了(其他图片的请求都是一样的),我估计博客园在处理图片的时候应该不需要用到cookie吧?也许你认为这几个cookie的大小只有300个字节左右,无所谓啦。
我们做个简单的计算,假设博客园每天有50W个PV(实际情况应该不止吧),每次PV大概有15次请求静态资源,15*500000*300/1024/1024=2145M。也就说这几个cookie每天大概会耗费博客园2G的带宽。当然这种简单的计算方式肯定会有偏差,毕竟我们还没把静态资源缓存考虑进去。但是个人觉得要是博客园要是把cookie的domain设置为www.cnblogs.com会更好一些。
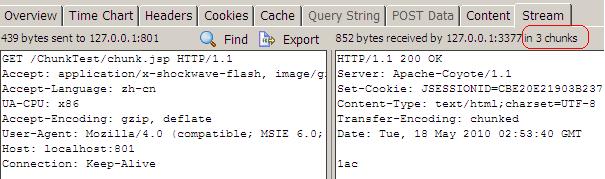
妙用204状态
http中200,404,500状态大家都很清楚,但204状态大家可能用的比较少,204状态是指服务器成功处理了客户端请求,但服务器无返回内容。204是HTTP中数据量最少的响应状态,204的响应中没有body,而且Content-Length=0。很多人在使用ajax提交一些数据给服务器,而不需要服务器返回的时候,常常在服务端使用下面的代码:response.getWriter().print(""),这是返回1个空白的页面,是1个200请求。它还是有body,而且Content-Length不会等于0。其实这个时候你完全可以直接返回1个204状态(response.setStatus(204))。204在一些网站分析的代码中最常用到,只需要把客户端的一些信息提交给服务器就完事,让我们看看google首页的1个204响应,google首页的最后1个请求返回的就是204状态,但这个请求是干嘛用的就没猜出来了:

四、高性能WEB开发之JS、CSS的合并压缩
本篇文章主要讨论下目前JS,CSS 合并、压缩、缓存管理存在的一些问题,然后分享下自己项目中用到的1个处理方案,并提供1个实例下载。
存在的问题:
合并、压缩文件主要有2方面的问题:
1. 每次发布的时候需要运行一下自己写的bat文件或者其他程序把文件按照自己的配置合并和压缩。
2. 因生产环境和开发环境需要加载的文件不一样,生产环境为了需要加载合并、压缩后的文件,而开发环境为了修改、调试方便,需要加载非合并、压缩的文件,所以我们常常需要在JSP中类似与下面的判断代码:
<c:if test="${env=='prod'}">
<script type="text/javascript" src="/js/all.js"></script>
</c:if>
<c:if test="${env=='dev'}">
<script type="text/javascript" src="/js/1.js"></script>
<script type="text/javascript" src="/js/2.js"></script>
<script type="text/javascript" src="/js/3.js"></script>
</c:if> |
缓存问题:在现在JS满天飞的时代,大家都知道缓存能带来的巨大好处,但缓存确实非常麻烦的一个问题,相信很多人曾经历过下面的情况:为了让程序更快,在服务器上为JS加上缓冲5天的代码,但产品更新后第二天就接到电话说系统出错,详细了解后就发现是缓存引起的,让用户删除缓存后就会OK。原因很简单,就是你JS已经修改了,但用户还在使用缓存中的老JS。在经历几次这种情况,被领导数落了几次后。没办法只能把JS的缓冲去掉,或者改成8个小时。可这样就完全失去了缓存的优势了,哪我们到底需要解决哪些问题才能让我们使用缓冲顺心如意了?
1. 如何在修改了某个JS后,自动把所有引用该JS页面的代码中加上1个版本号?
2. 该如何生成版本号,根据什么来产生这个版本号。
可能有人为了解决上面的缓存问题,写了个JSP标签,通过标签读取JS、css文件的修改时间来作为版本号,从而来解决上面2个问题。但这种方法有下面几个缺点:
1. 每次请求都要通过标签读取读取文件的修改时间,速度慢。当然你可以把文件的修改时间放到缓存中,这样也会加到了内存使用量。
2. 在HTML静态页面中用不了
3. 如果你们公司是如下的部署发布方式(我们公司就是这样),则会失效。每次发布,不是直接覆盖之前的WEB目录,运维的为的发布方便,要求每次发布直接给他们1个war包,他们会把之前WEB目录整个删除,然后上传现在的war包,这样就导致程序运行后,所有文件的最后修改时间都是解压war的时间。
分享自己项目中的处理方案:
为了解决上面讨论过的问题,在下写了1个如下的组件,组件中根据我们自己的实际情况使用了文件大小来做为文件的版本号,虽然在文件修改很小(比如把字符a改成b),可能文件大小并没有变,导致版本号也不会变。
但这种机率还是非常低的。当然如果你觉的使用文件修改时间作为版本号适合你,只需要修改一行代码就行,下面看下这个组件的处理流程(本来想用流程图表达,最后还是觉的文字来的直白写):
1. 程序启动(contextInitialized)
2. 搜索程序目录下的所有merge.txt文件,根据merge.txt文件的配置合并文件, merge.txt文件实例如下:
# 文件合并配置文件,多个文件以|隔开,以/开头的表示从根目录开始,
# 空格之后的文件名表示合并之后的文件名
# 把1,2,3合并到all文件中
1.js|2.js|3.js all.js
#合并CSS
/css/mian.css|/css/common.css all.css |
3. 搜索程序目录下所有JS,CSS文件(包括合并后的),每个文件都压缩后生成对应的1个新文件。
4. 搜索程序目录下所有JSP,html文件,把所有JS,css的引用代码改成压缩后并加了版本号的引用。
实例:
实例的文件结构如下图:
看JSP原始代码(程序运行前):
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<% boolean isDev = false; // 是否开发环境%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>JSP Page</title>
<% if(isDev){ %>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/jquery-1.4.2.js"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/1.js"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/2.js"></script>
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/1.css" />
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/2.css" />
<% }else{ %>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/jquery-1.4.2.js"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/all.js"></script>
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/all.css" />
<% } %>
</head>
<body>
<h1 class="c1">Hello World!</h1>
</body>
</html> |
程序运行后JSP的代码:
<%@page contentType="text/html" pageEncoding="UTF-8"%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<%
boolean isDev = false; // 是否开发环境
%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>JSP Page</title>
<% if(isDev){ %>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/jquery-1.4.2-3gmin.js?99375"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/1-3gmin.js?90"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/2-3gmin.js?91"></script>
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/1-3gmin.css?35" />
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/2-3gmin.css?18" />
<% }else{ %>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/jquery-1.4.2-3gmin.js?99375"></script>
<script type="text/javascript" src="<%=request.getContextPath() %>/js/all-3gmin.js?180"></script>
<link type="text/css" rel="stylesheet" href="<%=request.getContextPath() %>/css/all-3gmin.css?53" />
<% } %>
</head>
<body>
<h1 class="c1">Hello World!</h1>
</body>
</html> |
加3gmin后缀的文件全部是程序启动时自动生成的。
|


