| 编辑推荐: |
本文主要介绍OO + N-Tier的几个基本观点,希望对您的学习有所帮助。
本文来自于cnblogs,由火龙果软件Linda编辑、推荐。 |
|
(一)Hello world的时代
中学的时候,学校里开设了电脑课。当时的电脑还是一种比较希罕的东西,学校里的电脑一共就十几台,还专门找了一个大厅摆放这些机器。厅里面铺着厚厚的地毯,整天都拉着重重的窗帘。每次上课前一天,我们需要沐浴更衣,剪好指甲。上课时大家都穿上鞋套,排好队伍,列队进入机房。然后各位同学坐在座位上,在老师的指挥下,拿出一张五英寸的软磁盘,磁盘里安装着DOS操作系统,插入电脑的A驱动器。然后依次打开显示器、主机电源,在一阵吱吱声中,等待着电脑的启动,进入一个充满了幻想的神奇世界。
我就是在那个时候写出了第一行程序。当时我们学的是一种叫做GWBASIC的语言,这是BASIC语言的一个分支。
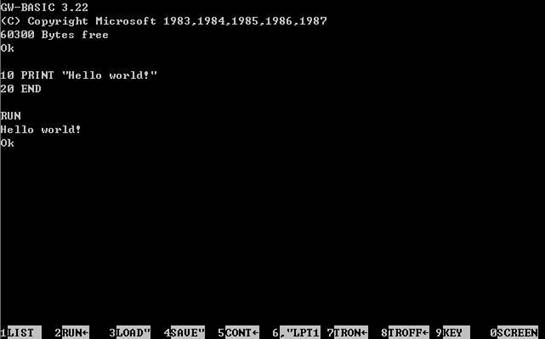
BASIC是一种非常简单的交互式程序设计语言。编码人员需要为每一行代码编制一个行号。行号是一个自然数,为了日后调试的需要,一般都是在最初编制行号的时候故意留下富余,不是按照1、2、3……的方式编制行号,而是按照10、20、30……的形式。程序输入完毕以后,运行“RUN”命令,编译器按照行号的顺序,解释执行程序。
这样的编程方式太简单了,只要记住几个流程控制、输入输出的关键字,就可以写出一个简单的程序。那段时间我每天都在想着把平时遇到的东西用程序写出来,多元多次的方程式、猜数字的游戏、三角函数曲线……先把编程的思路记在纸上,每个星期上课的时候再在电脑上写出来,调试运行。调试方式也非常简单,就是把数值往屏幕上PRINT,然后运行查看结果。写完了之后运行“SAVE”命令,把代码保存到软盘里。
中学时期应该是一个人的思维最灵活的时期,以后的时期经验逐渐的丰富,但是学习新知识的能力实际上是在走下坡路。除非特地去培养,很多方面的知识也就停留在中学的水平。比如对于一个搞计算机的专业人员来说,他的历史、语文、物理、化学知识很可能就永远的停留在中学时期的水平。那段时间我疯狂的写着程序,最大的愿望就是家里能有一台电脑,安装着GWBASIC的编译器,我可以每天把自己关在屋子里,用GWBASIC写出超级玛丽,或者坦克大战一样的游戏。
GWBASIC使用一种非常原始的方式进行流程控制——GOTO。他也有函数的概念,但是实际上也是GOTO到某段代码上去(使用GOSUB指令),执行完了再GOTO回来(使用RETURN指令)。按照当时流行的观念,程序中使用GOTO并无不妥,这是实现条件循环的一种很正常的方式。例如下面这段代码:
50 LET I = 0
60 I = I + 2
70 PRINT I
80 IF I < 100 THEN GOTO 60
下面是我当时写出的一段代码,这是一个猜数字的游戏,他就是在GOTO来GOTO去的兜圈子,像是进入了一个迷宫。还好这个迷宫的规模不大,很容易就能找出他在干什么。这段代码之所以能够保存到现在,是因为他没有象其他代码一样保存在软盘里,而是随手记录在了书的空白处。
10 PRINT "Guess a number"
20 INPUT A
30 IF A > 5 THEN GOTO 60
40 IF A < 5 THEN GOTO 80
50 IF A = 5 THEN GOTO 100
60 PRINT "Too big"
70 GOTO 20
80 PRINT "Too small"
90 GOTO 20
100 PRINT "Right"
110 END
这样的编程方式就是:面条式代码。这是一种最简单的编码方式,不需要长时间的学习或太多的经验就可以立即掌握。但是他能解决的问题也是有限的,也就只能写一个猜数字的小游戏,或者画出一个Y=A*SIN(X)+B的函数曲线图。如果要真的用他来写一个超级玛丽,那将是很很很很很困难的。
后来进入了结构化编程的时代,GOTO成了破坏程序结构化的罪人,渐渐的被大家抛弃,现在只在的很少的地方仍然发挥着作用(比如在VB或者C语言中进行异常处理)。但是这种GOTO式的编程方法影响了我很久。直到我大学时期,学习FORTRAN77的时候,仍然在采用这种编程方式。这样的方式很简单,不用想的太多就能解决问题,也使我小富即安,懒得去研究别的编程方式。
结构化编程方式是面条式代码的一种改良。他首先把需要处理的问题划分成若干个模块,然后再把每个模块划分成更小的模块,这样一步步细化下去,直到每个模块的功能可以用一个程序语句实现,这就完成了程序的设计。在划分模块的时候,结构化编程的原则是:一个模块只能有一个入口和一个出口,并在要按照基本结构完成模块之间的连接。这就意味着GOTO只能与IF配合使用,以构成分支和循环的结构。分支和循环结构在任何一种编程语言中都有更简单明确的关键字来实现,GOTO自然就失去了存在的意义。
结构化编程是一种面向过程的编程方式。所谓“面向过程编程”是译自“Procedure-oriented programming”,实际上应该理解成“以过程为导向的编程方式”。按照这样的编程方式,人们首先要确定用什么样的流程来实现业务需求,接着就一步步的分解这个流程,分解,再分解……直到可以用一个语句实现,最后就用程序实现这样的流程。下面的流程就实现了这样一个小测验:测试计算11到20的平方,每算对一个数可以得到10分,最后输出总分。
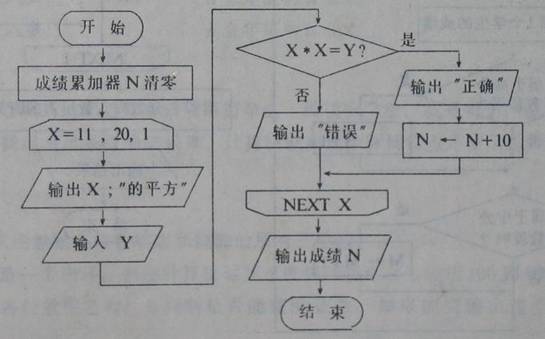
面向过程的编程方式必须在编程之前将解决问题的流程确定下来,这是一种很不灵活的方式。我们解决一个问题的时候,是很难在一开始就把流程定的很合理的。比如说,我们开发一个Email服务器,用户最初要求有这样的功能:收到邮件的时候判断一下是不是垃圾邮件,如果是垃圾邮件,就直接移到垃圾邮件夹里。后来我们在开发的过程中发现,垃圾邮件的识别率并不是很高,难免会把一些正常邮件当作垃圾邮件移走了,造成用户的邮件不能及时收到。于是这个流程必须调整成这样:发现垃圾邮件不能移走,而是在标题上加上一个警告标记。并且这个流程的改变会影响其他的流程:使用POP客户端下载邮件的时候,对垃圾邮件只能下载标题和纯文本的内容,确保客户端的安全。可以看出,业务流程的制定需要在随后的开发过程中不断得到反馈,不断进行调整,最后才能达到一个比较好的效果。但是按照面向过程的编程方式,我们必须先确定一个流程,再开始设计,否则需求就不确定。如果在编程的过程中发现流程不合适,在效率或者准确性上不满足需要,程序就要重新设计了。这样边写边改,又要顾忌对其他流程的影响,程序写起来是很困难的。
后来又发展出来另外一种编程方式:面向对象的编程。面向对象的编程是译自“Object-oriented programming”,简称OOP,其实上也应该理解成“以对象为导向的编程方式”。用这样的编程方式,先不要急于确定用什么样的流程来实现业务需求,而是先看看需求里面包含有哪些“东西”,这些东西是怎样出现的,具有什么样的属性,可以做哪些事情,会发生什么样的事件,这些东西之间是什么样的关系。用程序把这些东西造出来,然后就让这些东西运行起来,实现预想的功能。
比如刚才那个Email服务器的问题,在流程不确定的情况下,我们可以先看看这个Email服务器里面有哪些东西,最明显的,应该有Email类。Email类有三个行为:接收(Receive)、显示(Show)和下载(Download)。垃圾邮件是邮件的一个特例,可以看作Email的一个子类,如下:
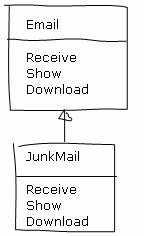
JunkMail覆盖了Email的接收、显示和下载方法。如果垃圾邮件应该有一些特别的处理方式,就可以只修改JunkMail类——在接收时移至垃圾邮件夹、或者在显示的时候加上一个警示标志、下载时过滤掉其中的非文本内容——没有其他类的代码需要改动。这样不会对普通邮件的处理流程产生任何影响。
面向过程和面向对象这两种编程思想的区别在于:他们对于需求的理解是不一样的。面向过程的编程人员,他们把需求理解成一条一条的业务流程,他们喜欢问用户“你的业务流程是什么样的?”,然后他们分析这些流程,把这些流程交织组合在一起,最后实现了需求;面向对象的编程人员,他们把需求理解成一个一个的对象,他们喜欢问用户“这个东西叫做什么,他从哪里来,他能做什么事情?”,然后他们制造这些对象,让这些对象互相调用,符合了业务需要。关于这两种编程方式的对比,在后面的章节中会有具体的说明。这里简单的说两点:
1、对象比流程更加稳定。业务流程的制定需要受到很多条件的限制,甚至程序的效率、运行方式都会反过来影响业务流程。有时候用户也会为了更好的实现商业目的,主动的改变业务流程,并且一个流程的变化经常会带来一系列的变化。这就使得按照业务流程设计的程序经常面临变化。
2、对象比流程更加封闭。业务流程从表面上看只有一个入口、一个出口,但是实际上,流程的每一步都可能改变某个数据的内容、改变某个设备的状态,对外界产生影响。而对象则是完全通过接口与外界联系,接口内部的事情与外界无关。
按照面向对象的编程方式,我们要用对象来体现现实世界中出现的事物。如果需求比较复杂,这样会造成程序里出现大量的对象、复杂的关系,修改程序的时候越来越麻烦。其实一些对象之间总是有着比较固定的关系,有的对象之间是包含的关系,有的是依赖的关系,有的对象是别的对象的创建者……有经验的程序员会从这些关系中发现一些规律,寻找出处理这些关系的一些方法,这就形成了设计模式。比如一个通信公司为他的用户设置各种套餐,用户选择不同的套餐,通话就采用不同的计费策略,这种情况可以采用Strategy模式;一家销售自行车的公司同时销售自行车的零件,有的零件是多个零件的组合,又可以和别的零件组合成一个更大的零件,这就可以采用Composite模式。有时候程序员可以从模式中获得设计的灵感,对软件的整体构架产生影响。在以后的章节中我会对设计模式进行介绍。
软件开发思想经过了几十年的发展。最早的面条式的代码,一个中学生很快就能学会,可以立即用它来解决一个多元多次方程;后来发展到结构化编程,把代码分割成了多个模块,增强了代码的复用性,方便了调试和修改,但是结构也复杂了很多。最早的编程方式是面向过程的,非常直观,一个初学者很快就可以理解;后来有了面向对象的方式,问题的解决看上去不再这么直截了当,需要首先开发业务对象,然后才能实现业务流程。随着面向对象编程方式的发展,又出现了设计模式、MVC、ORM、以及不计其数的工具、框架。软件为什么会越来越复杂呢?其实这不是软件本身的原因,而是因为软件需要解决的需求越来越复杂了。
最早的计算机只需要帮助人们做纯粹的计算任务,他用插头和开关作为输入设备,用信号灯做输出设备,没有存储器,也没有程序。当时人们需要计算机,只是想让他帮助人们在人口普查、天气预报这样的事情中担任计算任务。早期的计算机曾经参与了曼哈顿计划,最初军方雇用了大约100名计算员,参与计算原子核裂变的各项数据,但是无法达到满意的进度。后来由于计算机的研制成功,大大加速了原子弹的研制速度,这也加速了第二次世界大战的尽快结束。
稍后一点的计算机采用卡片穿孔的方式作为控制方式。程序员把需要运行的运算用二进制的方式记录在卡片上,穿孔的地方代表1,不穿孔的地方代表0。把卡片塞进计算机的输入设备,计算机就按预定的方式运行,这就是最早的机器语言。随着计算机的运算速度越来越快,人们发现很多时候都是计算机在等待着输入设备,很多时间被浪费掉了。于是人们设计出了一次可以处理多个卡片的计算机。多张卡片可以同时放入计算机,计算机按照一定的规则进行调度,按照某种优先顺序执行他们,这就是中断和任务的调度的概念,最早的操作系统就这样出现了。银行、会计事务所这样的公司每星期把写好的卡片放到计算机中运行,很快就可以完成大量数据的处理工作。这时的计算机仍然是一种非常复杂的设备,维护、使用都十分困难,当时的计算机生产公司必须提供全套的安装、维护、运行解决方案。
此时的计算机编程就是在卡片上穿孔,所使用的语言完全是机器代码。机器代码难以记忆,不容易理解。于是人们发明了汇编语言,汇编语言实际上是机器语言的助记符号,可以用编译器翻译成机器代码卡片。从词法和语法上说,他更接近与自然语言,但是从流程上说,仍然是机器语言的那一套。
这个时候,计算机软件已经成为了一种耗资巨大的工程。当时的计算机硬件是一种十分高档的昂贵设备,以至于一些大公司都没有勇气独立购买,而是采取租用的方式,租借机器的投资可以达到上百万。而软件开发所花的钱比起租机器的钱是只多不少。最为典型的工程是IBM360的操作系统。当时IBM公司研发新的电脑——IBM360,他们的计划是为这种机器单独开发一个操作系统。软件开发耗资巨大,工期一再拖延,直到整机上市一年以后,操作系统才得以发布。后来一位参与操作系统开发的工程师写了一本书,描述了他在项目中得到的一个重要经验:向一个进度缓慢的软件项目中盲目的追加人力,只能让进度更加缓慢。软件开发需要很大的人际交流成本,这使得项目的规模不能简单的用人月数来衡量。
汇编语言这解决了机器代码难写难记的问题,但是不同公司生产的机器、不同型号的机器汇编指令集是不同的,在一种机器上写出来的程序无法移植到另一种机器上执行。于是有人希望解决这个问题,他设计了一种新的程序语言——FORTRAN。FORTRAN的语法更加接近自然语言,并且他设计了适用于多种机型的编译器,可以把FORTRAN的源码编译成可以在多种机器上执行的机器代码。计算机的创始人之一,冯·诺伊曼当时认为搞这种高级语言没有多大的意义,计算机发展的重点不应该在这个地方。冯·诺伊曼肯定是一个汇编高手,写起机器代码来也是相当的娴熟,自然认为搞什么高级语言没有多大的必要,汇编挺好的嘛。这种感觉就应该类似于当今的一些C语言高手面对JAVA和C#时的感想。
FORTRAN的意义在于,他使计算机不再是计算机专业人员才能操纵的工具。数学家、工程师、会计师、学生都有机会亲自使用计算机来解决自己的工作中遇到的问题。高级语言的诞生使得软件业得到突飞猛进的发展。当时的FORTRAN仍然不是一种结构化的编程语言,FORTRAN中的变量都是全局变量,他使用与汇编相似的方式进行流程控制。
随后的几年中,LISP、ALGOL、COBOL等一批高级语言陆续不断的涌现出来。这些语言都有一个共同点:他们都出现了局部变量的概念,都是结构化的编程语言。局部变量有着更加清晰的作用域和生命周期,程序划分为若干个子过程,某个子过程中定义的变量在其他子过程中是不能访问的。有了这样的机制,程序员不用再担心自己定义的变量被意外的修改,这样就有利于更多的程序员合作编写大规模的程序。
接下来的几年出现了越来越多的高级语言,在文字处理、科学计算、数据制表等各种领域发挥着重要的作用。BASIC语言也就是在这一时期出现(BASIC语言并不是结构化语言),他的全称是:初学者通用符号指令代码。BASIC语法简单,易学易用,普通人稍加训练就可以用BASIC进行编程了。
从这一段历史看出,计算机软件技术不断发展,他的目的是使人们使用计算机解决问题的过程越来越简单。人们需要用计算机来解决越来越复杂的需求,从最初的科学计算,逐渐发展到表格处理,会计计算,管理一个大型企业的商业活动,这就迫使软件开发技术和思想不断进步。要创建新的技术平台,让设计人员在这个平台上不用考虑过多的基本技术问题;要创建新的分析方法,让设计人员可以忽略细节上的复杂度,更容易从整体上把握软件的构架。
现在的软件技术发展仍然是在延续这样的方向。软件的构架越来越庞大,从单层的、简单的面向过程的代码,发展到多层的、面向对象的代码,表面上看是变得复杂了,实际上是使得软件的逻辑结构更加清晰,从而不断的满足日益复杂的业务需求。程序员可以从技术细节中腾出力量,去解决更加复杂的业务问题。
学习和运用各种先进的技术也应该注意这一点:技术的发展是为了更容易的解决业务问题,降低开发成本——这也是我们运用他们的目的。本文在后面的章节介绍一些编程的思想和技术,也会遵循着这样一种思路,要看看这些东西是如何使程序员更加迅速准确的解决业务需求。为了能够说明这些思想和技术是如何使得问题的解决逐渐变得简单,本文在举例说明的时候,会尽量的使用接近于实际情况的例子。简单的玩具形式的例子,比如用Cat、Dog和Animal来说明多态的规则,看上去很形象,也是很有趣味,但是事情本身过于简单。使用这样的方式很容易把技术的原理说清楚,但是却让人不易明白他们的使用场景,甚至误以为他们把原本简单的事情搞得复杂了。本文中的事例有的牵涉到一些特定业务领域的知识,看起来难免晦涩枯燥,希望大家能够容忍一下。
(二)OO设计初次见面
我使用OO技术第一次设计软件的时候,犯了一个设计者所能犯的所有错误。那是一个来自国外的外包项目,外方负责功能设计,我们公司负责程序设计、编码和测试。
第一个重要的错误是,我没有认真的把设计说明书看明白。功能点设计确实有一些问题,按照他们的设计,一个重要的流程是无法实现的。于是我在没有与投资方沟通的情况下,擅自改动了设计,把一个原本在Linux系统上开发的模块改到了Windows系统上。结果流程确实是实现了,但是很不幸,根本不符合他们的需要,比起原先的设计差的更多。在询问了这个流程的设计意图之后,我也清楚了这一点。对方的工程师承认了错误,但是问题是:“为什么不早说啊,我们都跟领导讲过了产品的构架,也保证了交货时间了,现在怎么去说啊?”。他们设计的是一个苹果,而我造了一个桔子出来。最后和工程师商议的结果是:先把桔子改成设计书上的苹果,按时交货,然后再悄悄的改成他们真正需要的香蕉。的这时候距离交货的时间已经不足三天了,于是我每天加班工作到天明,把代码逐行抽出来,用gcc编译调试。好在大部分都是体力活,没有什么技术含量,即使在深夜大脑半休眠的情况下仍然可以接着干。
项目中出现的另外一个错误是:我对工作量的估计非常的不准确。在第一个阶段的时候,按照功能设计说明书中的一个流程,我做了一个示例,用上了投资方规定的所有的技术。当我打开浏览器,看到页面上出现了数据库里的“Tom,Jerry,王小帅”,就愉快的跑到走廊上去呼吸了一口新鲜空气,然后乐观的认为:设计书都已经写好了,示例也做出来了,剩下的事情肯定就象砍瓜切菜一样了。不就是把大家召集起来讲讲设计书,看看示例,然后扑上去开工,然后大功告成。我为每个画面分配的编码工作量是三个工作日。结果却是,他们的设计并不完美,我的理解也并不正确,大家的思想也并不一致。于是我天天召集开会,朝令夕改,不断返工。最后算了一下,实际上写完一个画面用的时间在十个工作日以上。编码占用了太多的时间,测试在匆忙中草草了事,质量……能掩盖的问题也就只好掩盖一下了,性能更是无暇顾及了。
还有一个方面的问题是出在技术上的,这方面是我本文要说的重点。按照投资方的方案,系统的主体部分需要使用J2EE框架,选择的中间件是免费的JBoss。再加上Tomcat作为Web服务器,Struts作为表示层的框架。他们对于这些东西的使用都是有明确目的,但是我并不了解这些技术。新手第一次进行OO设计,加上过多的新式技术,于是出现了一大堆的问题。公司原本安排了一个牛人对我进行指导,他熟悉OO设计,并且熟悉这些开源框架,曾熟读Tomcat和Struts源代码。可是他确实太忙,能指导我的时间非常有限。
投资方发来设计书以后,很快就派来了两个工程师对这个说明书进行讲解。这是一个功能设计说明书,包括一个数据库设计说明书,和一个功能点设计说明。功能点说明里面叙述了每一个工作流程,画面设计和数据流程。两位工程师向我们简单的说明了产品的构想,然后花了一个多星期的时间十分详细的说明了他们的设计,包括数据表里每一个字段的含义,画面上每一个控件的业务意义。除了这些功能性的需求以外,他们还有一些技术上的要求。
为了减少客户的拥有成本,他们不想将产品绑定在特定的数据库和操作系统上,并且希望使用免费的平台。于是他们选择了Java作为开发语言,并且使用了一系列免费的平台。选用的中间件是JBoss,使用Entity Bean作为数据库访问的方式。我们对Entity Bean的效率不放心,因为猜测他运用了大量的反射技术。在经过一段时间的技术调查之后,我决定不采用Entity Bean,而是自己写出一大堆的Value Object,每个Value Object对应一个数据库表,Value Object里面只有一些setter和getter方法,只保存数据,不做任何事情。Value Object的属性与数据库里面的字段一一对应。与每个Value Object对应,做一个数据表的Gateway,负责把数据从数据库里面查出来塞到这些Value Object里面,也负责把Value Object里面的数据塞回数据库。

按照这样的设计,需要为每一个数据表写一个Gateway和一个Value Object,这个数量是比较庞大的。因此我们做了一个自动生成代码的工具,到数据库里面遍历每一个数据表,然后遍历表里面的每一个字段,把这些代码自动生成出来。
这等于自己实现了一个ORM的机制。当时我们做这些事情的时候,ORM还是一个很陌生的名词,Hibernate这样的ORM框架还没听说过。接着我们还是需要解决系统在多种数据库上运行的问题。Gateway是使用JDBC连接数据库的,用SQL查询和修改数据的。于是问题就是:要解决不同数据库之间SQL的微小差别。我是这样干的:我做了一个SqlParser接口,这个接口的作用是把ANSI SQL格式的查询语句转化成各种数据库的查询语句。当然我没必要做的很全面,只要支持我在项目中用到的查询方式和数据类型就够了。然后再开发几个具体的Parser来转换不同的数据库SQL格式。
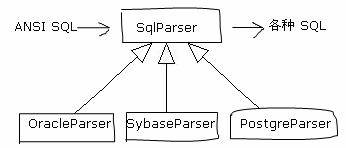
到这个时候,数据库里面的数据成功转化成了程序里面的对象。非常好!按道理说,剩下的OO之路就该顺理成章了。但是,很不幸,我不知道该怎样用这些Value Object,接下来我就怀着困惑的心情把过程式的代码嫁接在这个OO的基础上了。
我为每一个画面设计出了一个Session Bean,在这个Session Bean里面封装了画面所关联的一切业务流程,让这个Session Bean调用一大堆Value Object开始干活。在Session Bean和页面之间,我没有让他们直接调用,因为据公司的牛人说:“页面直接调用业务代码不好,耦合性太强。”这句话没错,但是我对“业务代码”的理解实在有问题,于是就硬生生的造出一个Helper来,阻挡在页面和Session Bean中间,充当了一个传声筒的角色。
于是在开发中就出现了下面这副景象:每当设计发生变更,我就要修改数据库的设计,用代码生成工具重新生成Value Object,然后重新修改Session Bean里面的业务流程,按照新的参数和返回值修改Helper的代码,最后修改页面的调用代码,修改页面样式。
实际情况比我现在说起来复杂的多。比如Value Object的修改,程序规模越来越大以后,我为了避免出现内存的大量占用和效率的下降,不得不把一些数据库查询的逻辑写到了Gateway和Value Object里面,于是在发生变更的时候,我还要手工修改代码生成工具生成的Gateway和Value Object。这样的维护十分麻烦,这使我困惑OO到底有什么好处。我在这个项目中用OO方式解决了很多问题,而这些问题都是由OO本身造成的。
另一个比较大的问题出在Struts上。投资方为系统设计了很灵活的界面,界面上的所有元素都是可以配置出来,包括位置、数据来源、读写属性。并且操作员的权限可以精确到每一个查看、修改的动作,可以控制每一个控件的读写操作。于是他们希望使用Struts。Struts框架的每一个Action恰好对应一个操作,只需要自己定义Action和权限角色的关系,就可以实现行为的权限控制。但是我错误的理解了Struts的用法,我为每一个页面设计了一个Action,而不是为每一个行为设计一个Action,这样根本就无法做到他们想要的权限控制方式。他们很快发现了我的问题,于是发来了一个说明书,向我介绍Struts的正确使用方式。说明书打印出来厚厚的一本,我翻了一天,终于知道了错在什么地方。但是一大半画面已经生米煮成熟饭,再加上我的Session Bean里面的流程又是按画面来封装的,于是只能改造小部分能改造的画面,权限问题另找办法解决了。
下面就是这个系统的全貌,场面看上去还是蔚为壮观的:
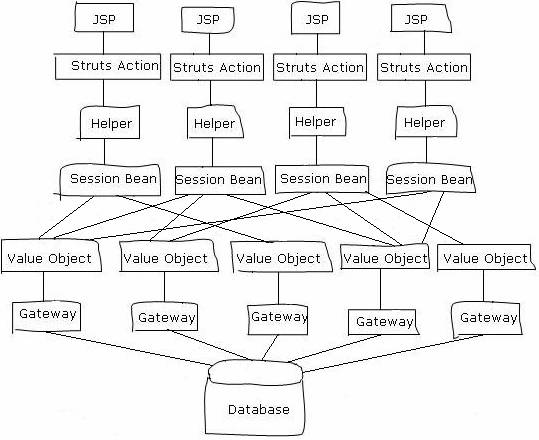
系统经历过数次较大的修改,这个框架不但没有减轻变更的压力,反而使得变更困难加大了。到后来,因为业务流程的变更的越来越复杂,现有流程无法修改,只得用一些十分曲折的方式来实现,运行效率越来越低。由于结构过于复杂,根本没有办法进行性能上的优化。为了平衡效率的延缓,不得不把越来越多的Value Object放在了内存中缓存起来,这又造成了内存占用的急剧增加。到后期调试程序的时候,服务器经常出现“Out of memory”异常,各类对象庞大繁多,系统编译部署一次需要10多分钟。投资方原先是希望我们使用JUnit来进行单元测试,但是这样的流程代码测试起来困难重重,要花费太多的时间和人手,也只得作罢。此外他们设计的很多功能其实都没有实现,并且似乎以后也很难再实现了。设计中预想的很多优秀特点在这样框架中一一消失,大家无奈的接受一个失望的局面。
在我离开公司两年以后,这个系统仍然在持续开发中。新的模块不断的添加,框架上不断添加新的功能点。有一次遇到仍然在公司工作的同事,他们说:“还是原来那个框架,前台加上一个个的JSP,然后后台加上一个个的Value Object,中间的Session Bean封装越来越多的业务流程。”
我的第一个OO系统的设计,表面上使用了OO技术,实际上分析设计还是过程主导的方式。设计的时候过多、过早、过深入的考虑了需要做哪些画面,画面上应该有哪些功能点,功能点的数据流程。再加上一个复杂的OO框架,名目繁多的对象,不仅无法做到快速的开发,灵活的适应需求的变化,反而使系统变得更加复杂,功能修改更加的麻烦了。
在面条式代码的时代,很多人用汇编代码写出了一个个优秀的程序。他们利用一些工具,或者共同遵守一些特别的规约,采用一致的变量命名方式,规范的代码注释,可以使一个庞大的开发团队运行的井井有条。人如果有了先进的思想,工具在这些人的手中就可以发挥出超越时代的能量。而我设计的第一个OO系统,恰好是一个相反的例子。
实际上,面向对象的最独特之处,在于他分析需求的方式。按照这样的方式,不要过分的纠缠于程序的画面、操作的过程,数据的流程,而是要更加深入的探索需求中的一些重要概念。下面,我们就通过一个实例看一看,怎样去抓住需求中的这些重要概念,并且运用OO方法把他融合到程序设计中。也看看OO技术是如何帮助开发人员控制程序的复杂度,让大家工作的更加简单、高效。
我们来看看一个通信公司的账务系统的开发情况。最开始,开发人员找到电信公司的职员询问需求的情况。电信公司的职员是这样说的:
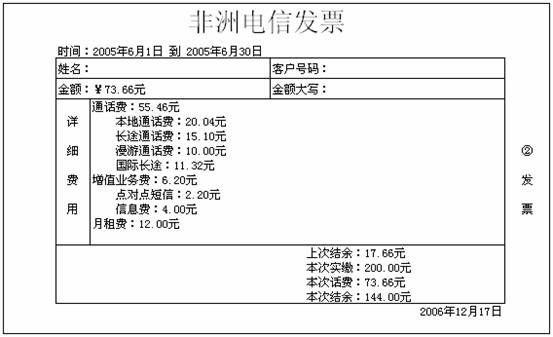
“账务系统主要做这样几件事情:每个月1日凌晨按照用户使用情况生成账单,然后用预存冲销这个账单。还要受理用户的缴费,缴费后可以自动冲销欠费的账单,欠费用户缴清费用之后要发指令到交换上,开启他的服务。费用缴清以后可以打印发票,发票就是下面这个样子。”
经过一番调查,开发人员设计了下面几个主要的流程:
1、 出账:根据一个月内用户的消费情况生成账单;
2、 销账:冲销用户账户上的余额和账单;
3、 缴费:用户向自己的账户上缴费,缴清欠费后打印发票。
弄清了流程,接着就设计用户界面来实现这样的流程。下面是其中一个数据查询界面,分为两个部分:上半部分是缴费信息,记录了用户的缴费历史;下半部分是账单信息,显示账单的费用和销账情况。
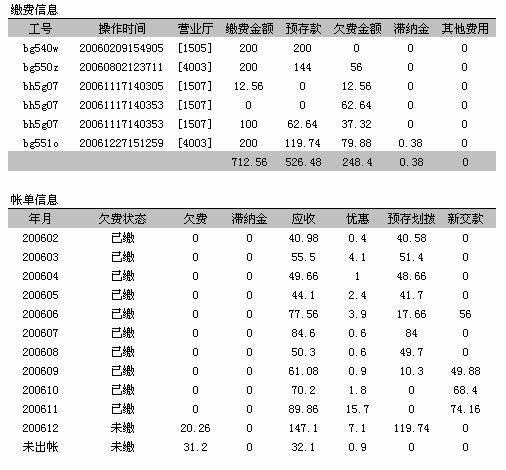
界面上的数据一眼看起来很复杂,其实结合出账、缴费、销账的流程讲解一下,是比较容易理解的。下面简单说明一下。
缴费的时候,在缴费信息上添加一条记录,记录下缴费金额。然后查找有没有欠费的账单,如果有就做销账。冲抵欠费的金额记录在“欠费金额”的位置。如果欠费时间较长,就计算滞纳金,记录在“滞纳金”的位置上。冲销欠费以后,剩余的金额记录在“预存款”的位置上。“其他费用”这个位置是预留的,目前没有作用。
每个月出账的时候,在账单信息里面加上一条记录,记录下账单的应收和优惠,这两部分相减就是账单的总金额。然后检查一下账户上有没有余额,如果有就做销账。销账的时候,预存款冲销的部分记录在“预存划拨”的位置,如果不足以冲抵欠费,账单就暂时处于“未缴”状态。等到下次缴费的时候,冲销的金额再记录到“新交款”的位置。等到所有费用缴清了,账单状态变成“已缴”。
销账的流程就这样融合在缴费和出账的过程中。
看起来一切成功搞定了,最重要的几个流程很明确了,剩下的事情无疑就像砍瓜切菜一样。无非是绕着这几个流程,设计出其他更多的流程。现在有个小问题:打印发票的时候,发票的右侧需要有上次结余、本次实缴、本次话费、本次结余这几个金额。
上次结余:上个月账单销账后剩下来的金额,这个容易理解;
本次结余:当前的账单销账后剩下的金额,这个也不难;
本次话费:这是账单的费用,还是最后一次完全销账时的缴费,应该用哪一个呢?
本次缴费:这个和本次话费有什么区别,他在哪里算出来?
带着问题,开发者去问电信公司的职员。开发者把他们设计的界面指点给用户看,向他说明了自己的设计的这几个流程,同时也说出了自己的疑问。用户没有直接回答这个疑问,却提出了另一个问题:
“缴费打发票这个流程并不总是这样的,缴费以后不一定立刻要打印发票的。我们的用户可以在银行、超市这样的地方缴话费,几个月以后才来到我们这里打印发票。并且缴费的时间和销账的时间可以相距很长的,可以先缴纳一笔话费,后面几个月的账单都用这笔钱销账;也可以几个月都不缴费,然后缴纳一笔费用冲销这几个账单。你们设计的这个界面不能很好的体现用户的缴费和消费情况,很难看出来某一次缴费是在什么时候用完的。必须从第一次、或者最后一次缴费余额推算这个历史,太麻烦了。还有,‘预存划拨'、‘新交款'这两个概念我们以前从来没有见过,对用户解释起来肯定是很麻烦的。”
开发人员平静了一下自己沮丧(或愤怒)的心情,仔细想一想,这样的设计确实很不合理。如果一个会计记出这样的账本来,他肯定会被老板开除的。
看起来流程要改,比先前设计的更加灵活,界面也要改。就好像原先盖好的一栋房子忽然被捅了几个窟窿,变得四处透风了。还有,那四个数值到底应该怎样计算出来呢?我们先到走廊上去呼吸两口新鲜空气,然后再回来想想吧。
现在,让我们先忘记这几个变化多端的流程,花一点时间想一想最基本的几个概念吧。系统里面最显而易见的一个概念是什么呢?没错,是账户(Account)。账户可以缴费和消费。每个月消费的情况是记录在一个账单(Bill)里面的。账户和账单之间是一对多的关系。此外,账户还有另一个重要的相关的概念:缴费(Deposit)。账户和缴费之间也是一对多的关系。在我们刚才的设计中,这些对象是这样的:
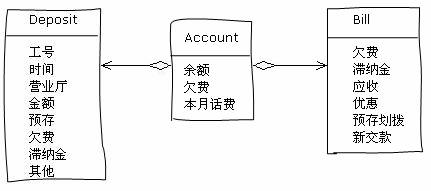
这个设计看来有些问题,使用了一些用户闻所未闻的概念(预存划拨,新交款)。并且他分离了缴费和消费,表面上很清楚,实际上使账单的查询变得困难了。在实现一些功能的时候确实比较简单(比如缴费和销账),但是另一些功能变得很困难(比如打印发票)。问题到底在什么地方呢?
涉及到账务的行业有很多,最容易想到的也许就是银行了。从银行身上,我们是不是可以学到什么呢?下面是一个银行的存折,这是一个委托收款的账号。用户在账户上定期存钱,然后他的消费会自动从这里扣除。这个情景和我们需要实现的需求很相似。可以观察一下这个存折,存入和支取都是记录在同一列上的,在支出或者存入的右侧记录当时的结余。

有两次账户上的金额被扣除到0,这时候金额已经被全部扣除了,但是消费还没有完全冲销。等到再次存入以后,会继续支取。这种记账的方式就是最基本的流水账,每一条存入和支出都要记录为一条账目(Entry)。程序的设计应该是这样:

这个结构看上去和刚才那个似乎没有什么不同,其实差别是很大的。上面的那个Deposit只是缴费记录,这里的Entry是账目,包括缴费、扣费、滞纳金……所有的费用。销账扣费的过程不应该记录在账单中,而是应该以账目的形式记录下来。Account的代码片段如下:
public class Account
{
public Bill[] GetBills()
{
//按时间顺序返回所有的账单
}
public Bill GetBill(DateTime month)
{
//按照月份返回某个账单
}
public Entry[] GetEntrees()
{
//按时间顺序返回所有账目
}
public void Pay(float money)
{
//缴费
//先添加一个账目,然后冲销欠费的账单
}
public Bill GenerateBill(DateTime month)
{
//出账
//先添加一个账单,然后用余额冲销这个账单
}
public float GetBalance()
{
//返回账户的结余
//每一条账目的金额总和,就是账户的结余
}
public float GetDebt()
{
//返回账户的欠费
//每一个账单的欠费金额综合,就是账户的欠费
}
} |
Entry有很多种类型(存入、支取、滞纳金、赠送费),可以考虑可以为每一种类型创建一个子类,就像这样:
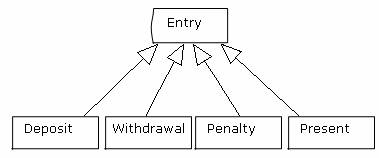
搞成父子关系看起来很复杂、麻烦,并且目前也看不出将这些类型作为Entry的子类有哪些好处。所以我们决定不这样做,只是简单的把这几种类型作为Entry的一个属性。Entry的代码片段如下:
public class Entry
{
public DateTime GetTime()
{
//返回账目发生的时间
}
public float GetValue()
{
//返回账目的金额
}
public EntryType GetType()
{
//返回账目的类型(存入、扣除、赠送、滞纳金)
}
public string GetLocation()
{
//返回账目发生的营业厅
}
public Bill GetBill()
{
//如果这是一次扣除,这里要返回相关的账单
}
} |
Entry是一个枚举类型,代码如下:
public enum EntryType
{
Deposit = 1,
Withdrawal = 2,
Penalty = 3,
Present = 4
} |
下面的界面显示的就是刚才那个账户的账目。要显示这个界面只需要调用Account的GetEntrees方法,得到所有的账目,然后按时间顺序显示出来。这个界面上的消费情况就明确多了,用户很容易弄明白某个缴费是在哪几个月份被消费掉的。
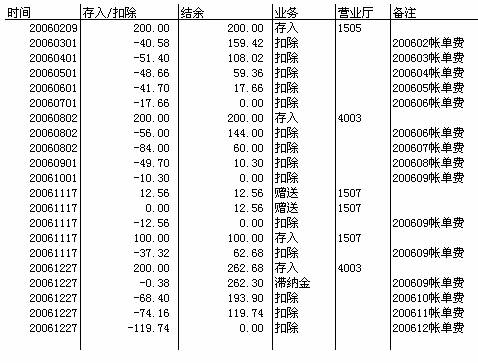
并且,发票上的那几个一直搞不明白的数值也有了答案。比如2005年6月份的发票,我们先看看2005年6月份销账的所有账目(第六行、第八行),这两次一共扣除73.66元,这个金额就是本次消费;两次扣除之间存入200元,这个就是本次实缴;第五行的结余是17.66元,这就是上次结余;第八行上的结余是144元,这个就是本次结余。
用户检查了这个设计,觉得这样的费用显示明确多了。尽管一些措辞不符合习惯的业务词汇,但是他们的概念都是符合的。并且上次还有一个需求没有说:有时候需要把多个月份的发票合在一起打印。按照这样的账目表达方式,合并的发票数值也比较容易搞清楚了。明确了这样的对象关系,实现这个需求其实很容易。
面向对象的设计就是要这样,不要急于确定系统需要做哪些功能点和哪些界面,而是首先要深入的探索需求中出现的概念。在具体的流程不甚清楚的情况下,先把这些概念搞清楚,一个一个的开发出来。然后只要把这些做好的零件拿过来,千变万化的流程其实就变得很简单了,一番搭积木式的装配就可以比较轻松的实现。
另一个重要的类型也渐渐清晰的浮现在我们的眼前:账单(Bill)。他的代码片段如下:
public class Bill
{
public DateTime GetBeginTime()
{
//返回账单周期的起始时间
}
public DateTime GetEndTime()
{
//返回账单周期的终止时间
}
public Fee GetFee()
{
//返回账单的费用
}
public float GetPenalty()
{
//返回账单的滞纳金
}
public void CaculatePenalty()
{
//计算账单的滞纳金
}
public float GetPaid()
{
//返回已支付金额
}
public float GetDebt()
{
//返回欠费
//账单费用加上滞纳金,再减去支付金额,就是欠费
return GetFee().GetValue() + GetPanalty() - GetPaid();
}
public Entry GetEntrees()
{
//返回相关的存入和支取的账目
}
public Bill Merge(Bill bill)
{
//合并两个账单,返回合并后的账单
//合并后的账单可以打印在一张发票上
}
} |
Bill类有两个与滞纳金有关的方法,这使开发者想到了原先忽略的一个流程:计算滞纳金。经过与电信公司的确认,决定每个月进行一次计算滞纳金的工作。开发人员写了一个脚本,先得到系统中所有的欠费账单,然后一一调用他们的CaculatePenalty方法。每个月将这个脚本执行一次,就可以完成滞纳金的计算工作。
Bill对象中有账户的基本属性和各级账目的金额和销账的情况,要打印发票,只有这些数值是不够的。还要涉及到上次结余、本次结余和本次实缴,这三个数值是需要从账目中查到的。并且发票有严格的格式要求,也不需要显示费用的细节,只要显示一级和二级的费用类就可以了。应该把这些东西另外封装成一个类:发票(Invoice):
通信公司后来又提出了新的需求:有些账号和银行签订了托收协议,每个月通信公司打印出这些账户的托收单交给银行,银行从个人结算账户上扣除这笔钱,再把一个扣费单交给通信公司。通信公司根据这个扣费单冲销用户的欠费。于是开发人员可以再做一个托收单(DeputyBill):
账单中的GetFee方法的返回值类型是Fee,Fee类型包含了费用的名称、金额和他包含的其他费用。例如下面的情况:
我们可以用这样的一个类来表示费用(Fee),一个费用可以包含其他的费用,他的金额是子费用的金额和。代码片段如下:
public class Fee
{
private float valuee = 0;
public string GetName()
{
//返回费用的名称
}
public bool HasChildren()
{
//该费用类型是否有子类型
}
public Fee[] GetChildren()
{
//返回该费用类型的子类型
}
public float GetValue()
{
//返回费用的金额
if (HasChildren())
{
float f = 0;
Fee[] children = GetChildren();
for (int i = 0; i < children.Length; i ++)
{
f += children[i].GetValue();
}
return f;
}
else
{
return valuee;
}
}
} |
现在开发者设计出了这么一堆类,构成软件系统的主要零件就这么制造出来了。下面要做的就是把这些零件串在一起,去实现需要的功能。OO设计的重点就是要找到这些零件。就像是设计一辆汽车,仅仅知道油路、电路、传动的各项流程是不够的,重要的是知道造一辆汽车需要先制造哪些零件。要想正确的把这些零件设计出来不是一件容易的事情,很少有开发者一开始就了解系统的需求,设计出合理的对象关系。根本的原因在于领域知识的贫乏,开发者和用户之间也缺乏必要的交流。很多人在软件开发的过程中才渐渐意识到原来的设计中存在一些难受的地方,然后探索下去,才知道了正确的方式,这就是业务知识的一个突破。不幸的是,当这个突破到来的时候,程序员经常是已经忙得热火朝天,快把代码写完了。要把一切恢复到正常的轨道上,需要勇气,时间,有远见的领导者,也需要有运气。
(三)设计模式
在上一篇里面,我们初步了解了OO设计,OO设计的最独特之处在于他看待需求的方式。用这样的方式,我们不需要急于确定软件需要实现哪些流程、设计哪些功能点、制作哪些画面,而是要关注需求中一些更加基本的概念。首先根据这些概念开发出一些零件,然后把这些零件组装起来实现需要的功能。用这样的方式,我们不需要一开始就去知道所有的业务需求,只需要知道一些比较重要的需求,就可以开始开发了。这样开发出来的程序不仅可以实现当前的需要,同时也是一个业务开发的平台,在这个平台上可以不断的开发新的功能。
这种设计思想有很多实际的例子,比如Microsoft Office。下面的图就展示了Excel里面最基本的几个对象:
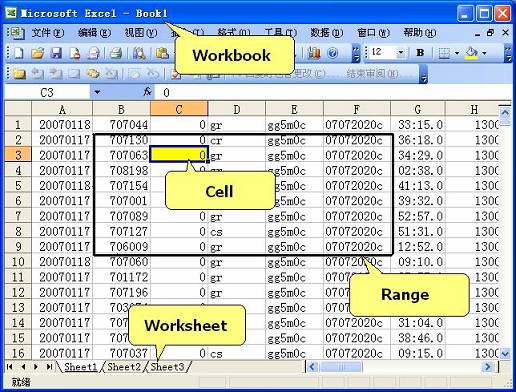
Excel的各项功能都是建立在这个对象模型基础上的。比如要实现设置字体的功能,就可以这样编写:先打开一个字体对话框,使用者选择字型、字号,然后把这个字体设置到区域上:
Font font = CommonFontDialog.ChooseFont();
Application.ActiveWorkbook.ActiveSheet.Range("A1").Font = font; |
Excel还把这些对象的引用暴露给了脚本引擎,于是我们就可以使用VBA调用他们,实现我们自己想要的各种功能,这就是Office宏。我们可以编写一段VB脚本,把鼠标选中区域的单元格复制到另一个工作表中,然后把某一个的单元格的值赋值为一个公式,计算出我们需要的数值。Excel不仅本身是一个好用的制表工具,他更是一个强大、易用的开发平台。使用者可以随时根据自己的想法,开发出需要的功能。一些大型的软件系统都是具有这样的特点,一开始就明确所有的功能需求是不可能的,重要的是形成一个业务开发的平台,提供一些业务编程接口,在这个平台上就可以不断的开发出新的功能。这样的开发方式不使用OO设计是很难实现的。
软件的第一个维护者和第一个使用者就是开发者本人,因此,开发迅速、功能灵活、维护简单——这些特点在精心设计的软件中经常是同时具有的。
运用OO方法设计程序的时候会遇到的这样困难:我们从需求中发现了一些模糊的概念,但是怎样才能根据这些概念建立合理的对象模型呢,到底哪些概念应该是一个类,哪些概念只应该是一个方法和属性,这些类之间应该是什么样的关系?要解决这个问题,最根本的途径当然是尽量深入的了解需求(比如说翻翻会计原理,看看应收款未收和已收的时候应该如何记账,其中一个记账原则也许就是一个重要的对象;协助用户做一个供电方案,随手画出的草图,或者某个计算公式就是一个重要的对象)。在解决了一个个困难之后,有人总结了经验,形成了一些解决特定问题的固定套路,这样的套路就是设计模式。
有些设计模式和OO没有什么必然的关系,比如层次模式,消息模式。但是大部分设计模式都是在OO设计中形成的,这些模式可以帮助我们发现系统中的对象、设计对象之间的关系。了解这些模式可以帮助我们把软件设计的更加合理。并且,在探索需求的过程中,我们也可以从模式中得到一些启发,获得设计的灵感,发现需求的真实面貌。
在上一篇我们看见了“费用”这个类型:Fee,其实这就是一个简单的设计模式:组合模式(Composite)。这个类的结构如下:
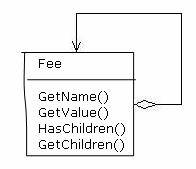
Fee类型是他本身的一个聚合,可以使用GetChildren方法得到某个费用包含的其他费用。如果一个费用没有包含其他费用,他的金额就是由他自己确定的,否则就是由他包含的费用相加确定的,这两种情况对外界提供的都是相同的方法:GetValue。这样,我们想显示一个账单费用的时候,不用再去判断他是否包含了其他的费用,调用起来就简单了很多。组合模式很好的体现了账单费用的层次包含关系。
刚才的情况里面,聚合类和元素类都是同样的类型。也有些情况他们分别属于不同的类型。比如一个企业,他的营销网络是由下面一些元素组成的:公司,市场部,直销店,代理商,自由代理人,营业员。如同下面的情况:
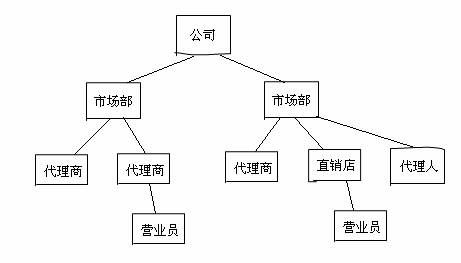
公司按照行政区域建立了多个市场部,市场部建立了自己的直销店,同时也与很多代理商和独立代理人进行合作,直销店和代理商雇用了营业员。每天公司需要对每个销售网点的情况进行查询和分析,需要知道他们定下了多少订单、收了多少货款、发展了多少新的客户。
这是一个比较复杂的结构关系,网点类型比较多,他们的销售方式差异很大,各类数据统计的方式也不同。并且在统计一些数值的时候,需要把下属网点的数量加起来,再加上自身的数量。如果采用组合模式,就可以解决这种问题。
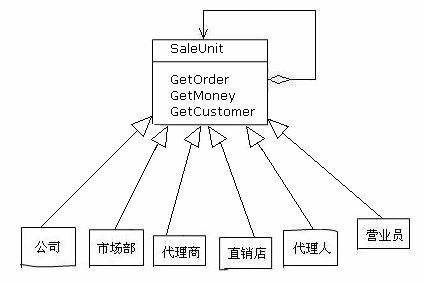
我们可以设计一个类,叫做销售单位(SaleUnit)。这个类是他本身的一个聚合,可以通过一个集合成员访问到他下属的单位。并且他的每一种下属单元也是SaleUnit的子类。各种销售网点统计数据的方式是不同的:有的数据保存在数据库表里面,经过一些统计运算可以得到;有的直接放在数据表的某个字段里面,直接查出来就可以了;还有的是每天发过来的一个Excel电子表格。对于每一种不同的销售网点,都可以使用一致的接口对他们进行访问,得到需要的数据。
组合模式可以很精确的反映销售网点间的聚合关系,并且对查询和统计提供了非常一致的接口,调用者不必区分具体的网点类型。类似这样的情况,当我们发现需求中一些对象具有聚合关系,并且我们希望对他们做一些共同的事情,就可以采用组合模式。
现在产生了一个严重的问题:是的,调用一个对象的确实没有必要去区分具体的网点类型了,但是他们是在哪里被创建的呢,创建的时候还是要区分网点的类型,复杂的代码只是从一个地方转移到另一个地方罢了,这样做有什么好处呢?为了解释这个疑问,下面会介绍另一个常见的模式:工厂模式(Factory)。
工厂模式用来彻底的断绝调用者和被调用的具体类型之间的关系,他使用一个工厂创建具体的类型,调用者从工厂中取得对象的实例。调用者既不需要知道对象是怎样被创建的,也不需要知道创建的是什么类型。下面通过一个例子说明一下工厂模式的用处。
这是一个电气设备监控系统,他的一个任务是从安装在各处的传感器上采集各种设备的运行数据,集中显示在监视器上。还可以在设备上定义告警条件,当采集到的数据满足告警条件的时候,向监控人员发出告警,监视器上显示告警标志。基本的情况是这样的:
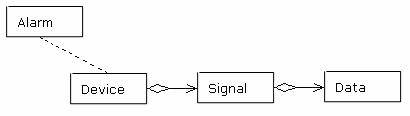
一个设备上可以有多个信号,比如一个变压器,上面可以有电压、电流、冷却剂温度等各种信号,分别由不同的传感器采集。每个信号隔一段时间会采集到一个数据,有的数据是直接采集到的,另一些是根据多个信号的情况计算出来的(比如一个电网环路上有n个节点,我们已经知道了其中n-1个节点的电压,就可以计算出最后一个节点的电压),还有的数据是一个推测值(需要根据一些经验数据进行推测)。传感器采集到信号数据以后,程序要判断这个数据的值,有时还要结合其他的信号,判断是否满足告警的条件,发出告警。
数据采集是一项十分复杂的工作,需要监控的设备种类繁多,数据意义复杂,传感器的通信方式也不相同。好在用户已经建设了了一个综合采集系统,解决了设备的实时数据采集工作。综合采集系统与各种传感器进行通信,将采集到的实时数据不断的输入到一个数据表里面。下面就是这个表里面的一些数据:
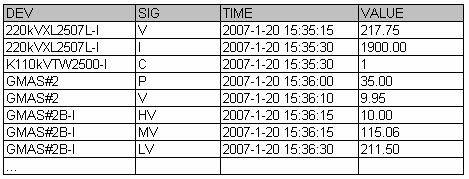
有了这么一个系统,直接采集数据的问题算是解决了。但是不同的信号类型对这个数据的解释仍然是不同的,我们仍然要应付这个问题。粗略的划分一下,有下面三种信号:
1、模拟信号:从综合采集系统里面查到实时数据,然后加上一个单位(比如伏特、安培),就可以显示了;
2、状态信号:需要定义一个状态描述。比如一个开关,采集数据高于0的时候就是闭合,等于0的时候就是断开;
3、推测信号:一些信号的数据从综合采集系统里面是无法得到的,必须通过公式计算出来。计算出来数值之后,加上一个单位显示出来。
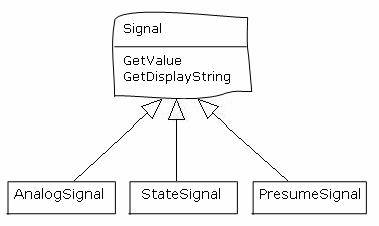
我们可以把信号的定义存储在数据库里面,数据如下:
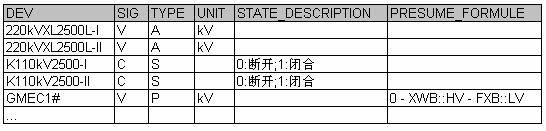
TYPE字段表示这个信号的类型:A是模拟信号,S是状态信号,P是推测信号。根据这个字段建立对应的信号实例,不同类型信号的数据处理就由对应的子类去负责。模拟信号会把采集到的数据加上单位(UNIT)显示出来;状态信号会把采集到的数据根据状态描述(STATE_DESCRIPTION)的定义显示出来;推测信号会按照推测公式(PRESUME_FORMULE)的定义去计算信号的值,然后加上单位(UNIT)显示出来。
我们可以在设备中处理Signal子类的创建,这样也不是不可以。但是,如果我们采用一个工厂,由他来负责Signal对象的建立,这样就完全隔离了设备和信号的每个子类的关系。设备在调用信号对象的时候,完全不需要知道这个实例是属于哪个类型。工厂的代码如下:
class SignalFactory
{
public static Signal CreateSignal(string dev, string sig)
{
//获取信号的定义
string sql =
"SELECT * FROM SIG WHERE DEV='" + dev + "' AND SIG='" + sig + "'";
// 查数据库表 查数据库表
//判断需要创建的类型
Signal signal = null;
if (type == 'A')
{
signal = new AnalogSignal();
}
else if (type == 'S')
{
signal = new StateSignal();
}
else if (type == 'P')
{
signal = new PresumeSignal();
}
else
{
return null;
}
//设置Signal的配置参数
signal.SetUnit(unit);
signal.SetStateDescription(state_description);
signal.SetPresumeFormule(presume_formule)
return signal;
}
} |
如果我们需要显示设备上的某个信号,这样就可以了:
Signal sig = SignalFactory.CreateSignal(dev, sig);
string s = sig.GetDisplayString(); |
其实,我们还可以采用一些小手段,比如利用反射的方式,彻底的把Signal的各个子类与其他的代码隔离开,甚至连SignalFactory都不需要和子类产生联系。我们可以把信号配置的数据修改一下:

TYPE字段原先设计的是一个标志(A、S和P),现在直接记录类型的命名空间和名称。SignalFactory在创建实例的时候,直接查出TYPE字段的内容,然后按照这个类的名称,就可以用反射的方式创建需要的实例。这样,无论是Signal的创建者,还是调用者,都不需要知道他们创建和调用的实际类型是哪一个,各种信号的数据和显示处理完全是由Signal的每个子类负责,程序就很好的符合了开放闭合原则。假如以后出现了一些很独特的信号采集和计算方式,甚至不得不采用硬编码的方式去实现,也不会对其他代码造成不良影响影响,维护起来非常的方便。
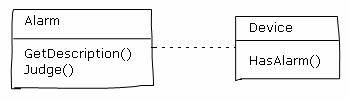
我们利用一个工厂解决了信号数据采集的问题,并且为下一步可能发生的变化留下了扩展的可能。下面看看告警应该怎样处理。我们先简单的考虑一下告警的形成:首先是在设备上采集到最新的实时数据,然后按照某个规则去判断这些数据是不是符合了告警的条件。在符合条件的情况下,在设备上面产生告警。在大部分情况下,一个告警只和一个设备有关,但是也有这样的情况:某个告警条件需要同时判断多个设备上的多个信号。于是我们设计出下面这样的结构:
告警的定义保存在告警定义数据表里面,如下:

表里面的CONDITIONA字段表示告警条件,这是一个公式,判断的时候把信号的数值代入,然后判断公式条件是否得到满足。如果满足条件,就产生一个告警。
程序的运行时序是这样:设备对象得到自己所包含的信号上的实时数据,然后找到与自己相关的每一个告警对象,依次调用他们的Judge方法。Judge方法根据告警条件公式判断是否有告警存在,如果存在的话,就把相关设备的HasAlarm属性设置为True。就这样,程序的主要功能实现了。
下面是这个程序的一个客户端界面:
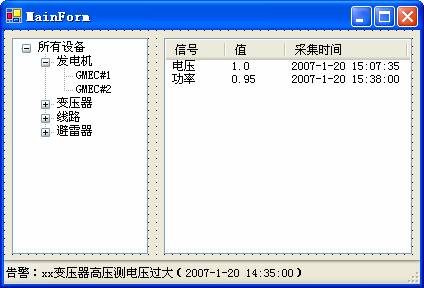
界面的左侧是一个树,表示设备的分类关系,每个叶子表示一个设备;当鼠标在树上点击一个设备,右侧的列表视图上显示这个设备上的信号和采集数据;如果设备上有告警,对应的树节点要标示一个显著的颜色,并且状态栏上要显示最近的告警。
要实现界面的刷新,最简单的方式莫过于在窗体上设置一个定时器,每隔一段时间检查一下所有设备的HasAlarm属性,发现有告警的设备,就把这个设备在树上的图标换掉,然后再把告警的内容显示在状态栏上。但是这样做有一个缺点,定时器的时间间隔无论怎样设置都是不合适的,时间太长了,可能会有一些告警要很久才能显示出来;时间太短的话,可能很多次刷新都没有告警,白白的消耗资源。这种刷新的机制是不合理的。要解决这个问题,可以采用观察模式(Observer)。一个对象需要等待另一个对象发出一个消息,然后再采取响应措施,等待消息的对象不需要知道消息如何发生、何时发生,发出消息的对象也不需要知道谁会关注这个消息、如何响应。这种情况就可以采用观察模式。
使用C#实现观察模式有一种非常简单的方法,那就是事件。我们可以在设备上定义一个事件:告警。当设备的HasAlarm属性被设置的时候,他会检查参数,如果发现参数为True,就发出告警事件。设备的代码片段如下:
class Device
{
public event System.EventHandler Alarm;//定义告警事件
public Device()
{
this.Alarm += new System.EventHandler(this.Device_Alarm);
}
public void SetHasAlarm(bool has)
{
if (has == true)
{
Alarm(this, null);//发出告警事件
}
}
private void Device_Alarm(object sender, EventArgs e)
{
}
} |
当设备上产生告警的时候,设备对象会发出Alarm事件。界面上的树视图可以捕获这个事件,将对应的树节点图标设为红色;状态栏也可以捕获这个事件,把设备上的告警显示出来。比起定时轮循,这是一种更加合理高效的方式。
对象设计是不是合理,所参照的标准是这个设计是不是反映了业务需求的实际概念。要做到真实的反映业务需求,最根本的方法是要深刻的去理解需求,深入的探索业务人员的工作和思想,甚至去留意他们自己都无法用语言表达的思维环节。在一个涉及者众多的企业支撑系统中,这种情况很常见的。有经验的业务人员肯定会积累很多这样的思想,体现了这些思想的对象模型才是最优秀的。要让软件系统来帮助业务人员进行工作,也就必然无法回避这样的问题。合理的使用设计模式可以最大限度的降低系统的复杂程度,但是归根到底,复杂程度是由业务需求所决定的。当对象设计基本清晰之后,设计模式可以帮助设计人员更好的处理对象之间的复杂关系,建立一个更加简单、稳定的对象模型。同时,设计人员也可以从设计模式中得到启发,去发现一些原本没有留意的细节。
(四)Model-View-Controller
Model-View-Controller简称为MVC,这是图形界面(GUI)应用程序的一种架构形式。Model是业务领域层,比如我们在前面两篇里面提到的Account、Entry、Bill、Invoice之类的对象,这些类构成了一个电信账务系统的业务领域层;View就是用户界面;Controller是指用户界面和业务对象之间的控制器,控制器的作用是从业务对象中获取数据显示到用户界面上,并且从界面上收集用户的输入和动作,然后调用业务对象完成业务功能。
大部分软件系统的工作可以总结成下面这样的流程:从存储数据的地方取得数据,把他们显示在用户界面上,然后用户在界面上修改这些数据,再把数据写回存储。数据在存储和界面之间来回流动。这种看似简单的分析方式经常让开发者有这样一种冲动:把界面和数据写在一起,这样可以少很多层次,少写很多代码,也可以减少运行过程的环节,似乎可以加快程序的运行效率。但是实际上,这种直来直去的烟囱式系统不能很好的隔离界面和业务代码,在开发和维护的过程中会带来很多麻烦。
把程序的界面和业务代码分离开会带来很多好处。一般的说来,界面比起业务逻辑来变化来的更加频繁一些,修改界面的时候,不应该对业务代码造成影响;开发这两个部分所使用的技巧也有很大的差别;在有些系统里面,需要为同一个功能开发多种界面,比如一个Windows窗体界面给后台管理人员使用,一个Web页界面提供给广大人民群众,还需要做一个适用于PDA浏览器的界面,如果界面和业务代码是混杂在一起的,多种界面的开发就需要做很多重复性的工作;把界面和业务代码分离开也使可以为自动化的单元测试提供很多方便,要对用户界面创建单元测试代码是十分繁杂的,而对业务代码做单元测试则是简单的,也是必要的。
于是有经验的开发者会在设计程序的时候创建一个业务领域层,在这个层次中有很多业务对象,他们直接体现了业务需求的核心。用户界面层不是自己实现业务功能,而是调用后台的业务对象。用户界面向用户展示业务对象的属性,并且捕获用户的输入,调用业务对象的方法实现各种功能需求。当业务逻辑层和用户界面层都具备了以后,剩下的一个问题就是:如何把这两个层次粘和起来——这就是控制器需要做的工作。
最简单的控制方式就是直接在界面中调用业务对象,这种方式称为Model-View模式。
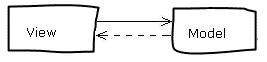
Model-View模式在界面和业务模型之间建立了一种最简单的依赖关系,界面直接调用业务模型,模型通过消息这样的松耦合方式修改界面上的表示内容(比如上一篇里面使用C#语言中的事件实现告警在界面上的显示)。这样可以实现层次的分离,对改善软件系统的构架是有一定的帮助的。
使用过Microsoft Visual Studio各个版本的开发者一定对Model-View的控制方式非常熟悉,无是在VB、VC,还是后来的C#、ASP.NET中,我们把一个按钮控件拖放到窗体上,然后鼠标点击这个控件,就会自动生成一段事件响应代码。下面是用这种方式编写的一段程序,这是“非洲电信公司账务系统”的一个界面,营业员使用这个界面为用户缴费:
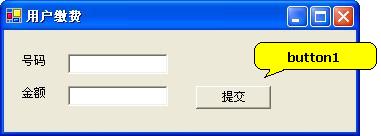
营业员在“号码”输入框里面填写用户的电话号码,在“金额”输入框里填写需要交的金额,然后点击“提交”按钮,就可以把钱交进账户。如果发生了异常情况,程序会出现提示。
按下“提交”按钮的时候,按钮发出Click事件,窗体可以捕获这个事件,采取响应行动。控制器就是用这样的机制实现的。
private void button1_Click(object sender, System.EventArgs e)
{
//按下缴费按钮,调用业务对象,实现缴费功能
try
{
string phone_no = textBox1.Text;
string money = textBox2.Text;
//根据电话号码得到用户对象
User user = GetUserByPhoneNumber(phone_no);
//得到这个用户的账号
Account account = user.Account;
//调用账号的Pay,接口给账号交钱
//Pay接口处理完费用之后要判断欠费,
//如果不再欠费向交换网络发指令,给用户开机
account.Pay(float.Parse(money));
MessageBox.Show("缴费成功了");
}
catch (Exception e)
{
MessageBox.Show(e.Message);
}
} |
这种控制器叫做“页面控制器”(Page Controller),控制器的功能是融合在界面中实现的。页面控制器简单实用,代码编写量很少,所涉及的技巧也并不高深,一个初学编程的人也很快就可以掌握。在解决一个简单的界面的时候,这样的控制器是非常适用的。但是,如果需要设计的程序具有更加复杂的功能,需要设计大量的界面和功能,这样的简单方式就会带来难以控制的复杂度。
下面的界面复杂一些,这是一种常见的图形界面模式:
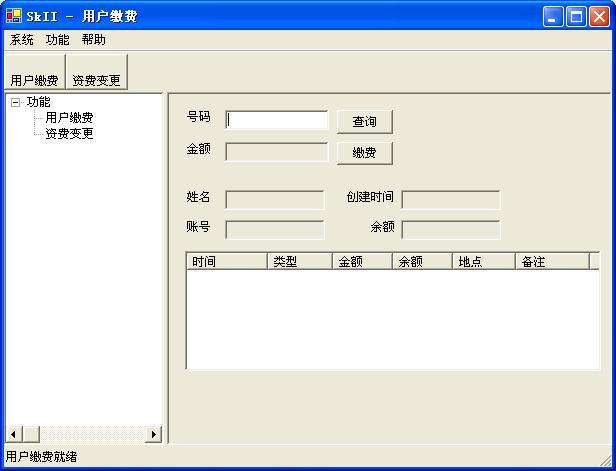
窗体上方是一个菜单,排列着所有的功能点(比如用户缴费、资费变更),还有一些系统性的功能(比如重新登录、修改密码);菜单下面是一个工具条,工具条上列出了常用的功能;左侧是一个树视图,列出了所有的功能点;点击菜单、工具条和树视图上的功能图标的时候,窗体右侧会打开功能界面,用户在这个界面上进行操作;窗体最下面是一个状态栏,显示一些帮助信息和程序运行过程中出现的消息。
如果我们使用页面控制器的方式来实现这样的界面,就会在界面的代码里面出现大量的事件响应代码。这些代码相似,而又不同。他们调用着各种业务对象,实现复杂的功能,这使得界面的代码日益庞大。再加上一些权限、安全性方面的功能(这样的功能通常会涉及到所有的业务功能,我们把这种功能称作“横切面功能”),代码会复杂到难以控制。到最后一点简单的需求变更会在多处修改代码,造成大量的重复工作。
下面我们就来看看怎样使用MVC的构架方式实现这样的界面方式。我们将使用一种叫做“前端控制器”(Front Controller)的控制方式。这样的控制器采用一种集中控制的方法,做到了视图、业务模型和控制器的分离,软件形成了真正的MVC架构:
前端控制器由两个部分组成:第一个部分是一个任务分派机制,用户在界面上的每一个请求都是通过这个分派机制传递给后台的对象进行执行的;第二个部分是一个“Command模式”(命令模式)构成的请求处理方式,对分派来的任务进行处理。下面先补上一节设计模式课,简单的介绍一下命令模式。
下面的类图表示了一个最简单的命令模式:
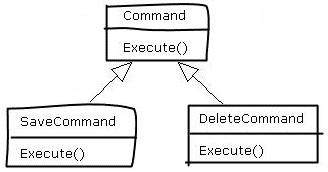
Command类有一个Execute方法,SaveCommand和DeleteCommand都是Command的子类,他们都覆盖了Command类的Execute方法。
当我们想执行保存动作的时候,就这样做:
Command cmd = new SaveCommand();
cmd.Execute(); |
当我们想删除的时候,就调用DeleteCommand对象:
Command cmd = new DeleteCommand();
cmd.Execute(); |
执行不同的任务的时候,只有创建的命令对象类型是不一样的,执行过程都一样。如果用一个工厂封装创建Command对象的业务逻辑,就可以用完全相同的调用方式执行不同的任务。这个模式可以使我们在程序中扩充新的功能,而不对已经完成的功能造成影响。命令模式在很多系统里面广泛的使用,比如在Tomcat Web服务器中,当我们访问一个JSP页面的时候,Tomcat会把这个JSP编译成HttpJspBase类的一个子类,然后调用他的_jspService方法,执行我们自己编写的页面代码。这就是一个命令模式。
下面我们来看看刚才提到的图形界面是如何实现的,并且通过什么样的方式调用后台的业务逻辑层进行实际的工作。示例代码可以在这里下载:http://files.cnblogs.com/lane_cn/skii.zip。这是用Visual Studio 2003编写的一个项目。项目代码分为三个包。打开项目文件可以看见三个对应的文件夹:
1、AfricaTelecom:这个文件夹里是“非洲通信公司账务管理系统”的业务代码,业务逻辑层的对象都在这里面;
2、View:这里是视图。其中的BaseView是所有视图的基类。还有两个实际的视图PayMoney和ChangePrice,分别是用户缴费视图和资费变更视图。ViewFactory是建立视图实例的工厂;
3、Action:这里是程序中所有的行为,是控制器的重要部分。其中的BaseAction是所有行为的基类,ActionFactory是建立行为对象的工厂,其余的行为是分别用于用户缴费和资费变更等各项业务活动。
我们先来看看View(视图)。BaseView是一个用户控件,从他的定义可以看出来:
public class BaseView : System.Windows.Forms.UserControl
{
} |
我们为BaseView定义了Id和ViewName两个属性,用来标记系统中的所有视图。BaseView向外界提供了一个“视图属性”接口,调用者可以使用这个接口把一些“名-值”对保存到视图中:
private Hashtable attributes = new Hashtable();
/// <summary>
/// 视图属性
/// </summary>
public object GetAttribute(string key)
{
try
{
return this.attributes[key];
}
catch
{
return null;
}
}
/// <summary>
/// 视图属性
/// </summary>
/// <param name="key"></param>
/// <param name="valuee"></param>
public void SetAttribute(string key, object valuee)
{
try
{
this.attributes.Remove(key);
}
catch {}
this.attributes.Add(key, valuee);
} |
视图提供了UpdateView和UpdateAttributes两个方法,用于把attributes容器里的“名-值”对显示到界面上,或者把界面上的文字保存到attributes容器中。这两个方法需要在子类中覆盖。
视图还向外界提供了两个事件:Change和MessageOut。Change向外界发出“视图已经被改变”的事件,这个事件可以用来实现这样的功能:在工具栏上有一个“保存”按钮,当视图打开时,这个“保存”按钮是不可用的,一旦视图发生变化,就会发出Change事件,于是工具栏可以捕捉到这个事件,将“保存”按钮设置为可用状态。MessageOut用于向外界发出消息,可以随时向外界通知某个任务的执行状态。
程序的主画面(MainWin)提供了一个LoadView方法,这个方法可以在窗体右侧区域加载一个视图,所加载的视图一定是BaseView的某个子类:
/// <summary>
/// 打开视图
/// </summary>
/// <param name="view">视图</param>
public void LoadView(Skii.View.BaseView view)
{
this.panel1.Controls.Clear();
view.Dock = System.Windows.Forms.DockStyle.Fill;
this.panel1.Controls.Add(view);
this.SetActiveView(view);
this.statusBar1.Text = this.GetActiveView().GetName() + "就绪";
this.Text = "SkII - " + this.GetActiveView().GetName();
this.GetActiveView().MessageOut +=
new ViewMessageHandler(ActiveView_MessageOut);
this.GetActiveView().Change +=
new ViewChangeHandler(ActiveView_Change);
} |
窗体右侧有一个面板控件:panel1,LoadView方法首先把面板上的控件全部去掉,然后把视图对象放到面板上。视图添加上去之后,更新主窗体的ActiveView属性,修改状态栏和窗体标题上的文字。最后再为MessageOut和Change事件设定响应函数。
MainWin向外界提供了一个静态的Instance属性,调用者可以通过这个属性得到主窗体的实例引用,然后调用LoadView方法。
下面我们再来介绍控制器。打开Action目录,BaseAction是所有Action的基类,他有Id和ActionName两个属性,用于标示系统中的行为。BaseAction有Enabled和IsVisible两个属性,分别表示行为是否可用、是否可见。
BaseAction中有几个Init方法,这几个方法分别对不同的窗体控件进行绑定,目前支持的控件有按钮、菜单、工具条、树节点。如果需要的话,还可以添加支持别的控件。控件和行为进行绑定时,需要参照行为的可用和可见情况,对控件的外观和行为进行设置。当控件被用户操作时,会触发响应函数,这些响应函数最后都会调用Execute方法。
/// <summary>
/// 执行行为
/// </summary>
public virtual void Execute()
{
} |
这样就为所有的窗体控件做到了统一的控制方式。比如我们可以把主窗体上的某个菜单项、工具栏按钮、树视图节点都绑定在同一个行为上,当这些控件发生动作的时候,都会触发这个行为的Execute方法。如果我们把这个行为设置为不可用,所有的相关控件同时都会成为灰色,不可点击。
在示例程序里,当主画面打开时,会建立三个Action,并且绑定相应的界面控件。请看MainWin的Form1_Load方法:
private void Form1_Load(object sender, System.EventArgs e)
{
//退出应用程序
BaseAction exitAction = ActionFactory.CreateAction(1000);
exitAction.Init(menuItem7);
//打开用户缴费的界面
BaseAction openPayMoneyAct = ActionFactory.CreateAction(1001);
openPayMoneyAct.Init(toolBarButton1);
openPayMoneyAct.Init(menuItem5);
openPayMoneyAct.Init(this.treeView1.Nodes[0].Nodes[0]);
//打开资费变更的界面
BaseAction openChangePriceAct = ActionFactory.CreateAction(1002);
openChangePriceAct.Init(toolBarButton2);
openChangePriceAct.Init(menuItem6);
openChangePriceAct.Init(treeView1.Nodes[0].Nodes[1]);
//openChangePriceAct.IsVisible = false;
//openChangePriceAct.Enabled = false;
} |
在用户缴费和资费变更的界面上,也是用相似的方式实现了行为的控制。请看PayMoney和ChangePrice的构造函数,他们分别建立了自己需要的行为,并且和按钮进行绑定。
在Action的Execute方法中,收集视图上的输入,调用业务对象进行工作。然后再把工作的结果展现在视图上。下面是PayMoneyAction的Execute方法,他实现了缴费功能:
public override void Execute()
{
//更新视图属性,把视图元素的值更新到属性里面
BaseView view = MainWin.GetInstance().GetActiveView();
view.UpdateAttributes();
//得到界面上的电话号码和缴费金额
string phone_no = view.GetAttribute("phone_no").ToString();
string money_amount = view.GetAttribute("money_amount").ToString();
//调用业务对象进行缴费
try
{
User user = User.GetUserByPhoneNo(phone_no);
Account account = user.GetAccount();
account.Pay(float.Parse(money_amount));
}
catch (Exception e)
{
MessageBox.Show(e.Message);
return;
}
//向界面发出成功消息
MessageBox.Show("缴费成功 :)");
//把界面清空
view.SetAttribute("phone_no", "");
//根据视图的属性,更新视图界面
view.UpdateView();
} |
现在我们实现了一个前端控制器的最简单的示例。令人不满意的是,其中有很多硬编码:在主窗体上的控件都是手工拖放上去的,行为也要手工定义,然后与控件进行绑定;并且在ActionFactory和ViewFactory中,行为和视图的建立也是用硬编码实现的。下面我们就来做一些事情,消除程序里的硬编码。
我们需要定义一个表,名叫ACTION_LIST,用来表示系统中所有的行为:
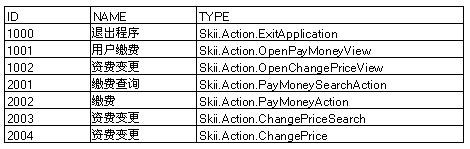
ActionFactory可以根据传入的ID编号查找到对应的类型,然后使用反射的方式建立需要的实例。如果我们需要对行为进行权限控制,可以再建立一个“访问控制表”(Access Control List,简称ACL),在这个访问控制表中记录用户和行为的访问限制关系。ActionFactory在建立Action实例之后,需要参照这个ACL对Action的Enabeld属性和IsVisible属性进行设置。只要维护一个ACL,就能实现最灵活的行为权限控制。
再建立一个类似的表:VIEW_LIST,用来定义所有的视图。ViewFactory可以根据这个表创建需要的视图实例:

ActionFactory和ViewFactory采用了反射的方式建立实例。尽管反射是一种比较消耗资源的方式,但是由于工厂把建立的实例缓存了起来,下次再调用的时候直接返回以前建立的实例,这样最大限度的避免了效率的下降。
下面,我们只要在主窗体中定义一个“控件行为表”,就可以消除所有的硬编码了:
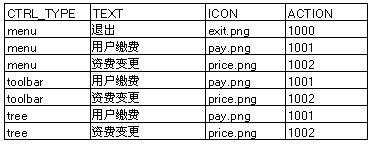
当应用程序启动的时候,主窗体按照这个控件行为表的内容创建控件,并且绑定指定的行为。这样就消除了所有的硬编码,也大大加强了软件的灵活性。主窗体现在只是一个空空的框架,视图和业务模型也被很好的隔离。同时,在前端控制器中,应用软件的所有控制行为是集中的,这样,当我们希望在所有的控制器上统一加上某个功能的时候,会非常的简单。比如刚才看到的权限控制。再比如我们需要在所有的行为开始的时候建立一个数据库连接,在行为结束的时候再把连接销毁。使用这样框架,这种统一的行为将十分容易实现,不需要重复的复制粘贴代码。
采用这样的构架,视图和行为可以不断的实现增量开发,各个部件互相不会产生影响。加上.NET程序集的部署方式,可以将这些代码编译成多个动态链接库,实现增量部署,对程序的自动下载更新也是一个有利的条件。
MVC是一种十分重要的构架形式,他可以增强软件的灵活性,使得变更更加的容易。他的优势主要体现在图形界面软件上,主要也是用于增强这一类软件的灵活性,使得和界面相关的修改更加容易一些。比如刚才的主窗体,如果我们要把他改一个样子,如下:
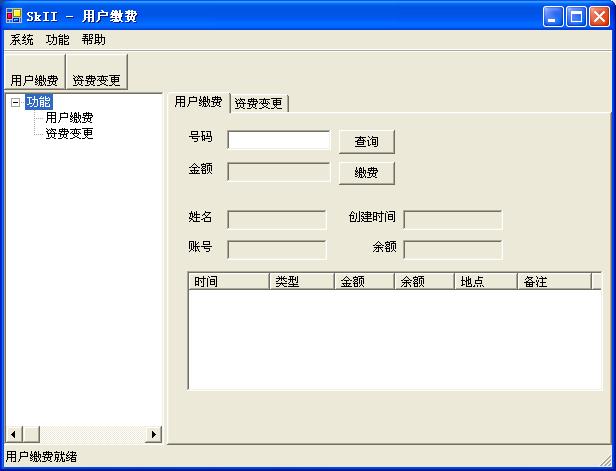
右侧的面板换成了一个Tab标签页。用户切换视图之后,以前的视图不会直接关掉,而是保留在Tab页里,在一个新建的Tab页上显示新的视图。这样操作人员就可以暂时中断手中正在进行的工作,切换到别的视图上做事,做完了再切换回来。现在实现这个变更是十分简单的,只需要修改主窗体的LoadView代码,并且改变ActiveView属性的代码就可以了,对任何一个视图和业务行为都不会造成影响。再举一个例子:如果用户提出这样的需要:操作员可以把自己常用的功能拖放到工具栏上,根据自己的需要自由的定制工具栏的按钮。这种需要也可以很容易的实现。
但是MVC无法用来应对来自业务本身的变化。一旦这样的变化发生了,比如我们需要对变更产品资费的业务进行控制,某些号码段的用户将不允许选择某些资费,这样的控制以前是不存在的。这样的变更就只有通过业务领域层的修改才能解决了。要减轻业务变更带来的痛苦,最根本的方法还是要设计一个清晰合理的业务领域层。
|







 订阅
订阅