|
в§бд
ЧАУцВЉПЭЗжЯэЃЌЮвУЧвбОНВНтСЫВЛЩйЗжРрЫуЗЈЃЌгаknnЁЂОіВпЪїЁЂЦгЫиБДвЖЫЙЁЂТпМЛиЙщЁЂsvmЁЃЮвУЧжЊЕРЃЌЕБзјживЊОіЖЈЪБЃЌДѓМвПЩФмЖМЛсПМТЧЮќШЁЖрИізЈМвЖјВЛЪЧвЛИіШЫЕФвтМћЁЃЛњЦїбЇЯАДІРэЮЪЬтЪБЭЌбљШчДЫЁЃМЏГЩбЇЯАЃЈensemble
learning)ЭЈЙ§ЙЙНЈВЂНсКЯЖрИібЇЯАЦїРДЭъГЩбЇЯАШЮЮёЃЌгаЪББЛГЦЮЊЖрЗжРрЦїбЇЯАЯЕЭГЁЂЛљгкЮЏдБЛсЕФбЇЯАЕШЁЃ
ИіЬхгыМЏГЩ
ЯТЭМЯдЪОГіМЏГЩбЇЯАЕФвЛАуНсЙЙЃКЯШВњЩњвЛзщЁАИіЬхбЇЯАЦїЁБЃЌдйгУФГжжВпТдНЋЫќУЧНсКЯЦ№РДЁЃ
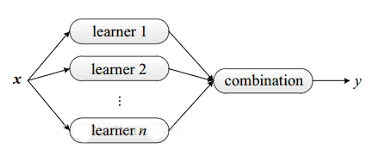
ЮвУЧЧАУцвбОЗжЯэСЫЮхжжВЛЭЌЕФЗжРрЫуЗЈЃЌЮвУЧПЩвдНЋЦфгУВЛЭЌЕФЗжРрЦїзщКЯЦ№РДЃЌетжжзщКЯНсЙћдђБЛГЦЮЊМЏГЩЗНЗЈЛђепдЊЫуЗЈЁЃЪЙгУМЏГЩЗНЗЈЪБЛсгаЖржжаЮЪНЃК1.МЏГЩжажЛАќКЌЭЌжжРраЭЕФИіЬхбЇЯАЦїЃЌетжжИіЬхбЇЯАЦївВБЛГЦЮЊЛљбЇЯАЦїЁЃ2.МЏГЩжавВПЩАќКЌВЛЭЌРраЭЕФИіЬхбЇЯАЦїЃЌетжжвьжЪМЏГЩЕФИіЬхбЇЯАЦїЪЧгЩВЛЭЌЕФбЇЯАЫуЗЈЩњГЩЁЃ
вЛАуРДЫЕЃЌМЏГЩбЇЯАЭЈЙ§НЋЖрИібЇЯАЦїНјааНсКЯЃЌГЃПЩЛёЕУБШЕЅвЛбЇЯАЦїЯджјгХдНЕФЗКЛЏадФмЁЃЕЋЪЧДгЪЕМЪОбщжаЗЂЯжЃЌвЊЛёЕУКУЕФМЏГЩЃЌИіЬхбЇЯАЦїгІЁАКУЖјВЛЭЌЁБЃЌМДИіЬхбЇЯАЦївЊгавЛЖЈЕФЁАзМШЗадЁБЃЌМДбЇЯАЦїВЛФмЬЋЛЕЃЌВЂЧввЊгаЁАЖрбљадЁБЃЌМДбЇЯАЦїжЎМфОпгаВювьЁЃ
bagging
здОйЛуОлЗЈЃЌвВГЦbaggingЗНЗЈЃЌЪЧвЛжжЛљгкЪ§ОнЫцЛњжиГщбљЕФЗжРрЦїЙЙНЈЗНЗЈЁЃbaggingдРэШчЯТЃК
ИјЖЈАќКЌmИібљБОЕФЪ§ОнМЏЃЌЮвУЧЯШЫцЛњШЁГівЛИібљБОЗХШыВЩбљМЏжаЃЌдйАбИУбљБОЗХЛиГѕЪМЪ§ОнМЏЃЌЪЙЕУЯТДЮВЩбљЪБПЬИУбљБОШдгаПЯФмБЛбЁжаЃЌетбљОЙ§mДЮЫцЛњВЩбљВйзїЃЌЮвУЧЕУЕНКЌmИібљБОЕФВЩбљМЏЃЌГѕЪМбЕСЗМЏжагаЕФбљБОдкВЩбљМЏжаЖрДЮГіЯеЃЌгаЕФдђДгЮДГіЯжЁЃееетбљЃЌЮвУЧПЩВЩбљГіTИіКЌmИібЕСЗбљБОЕФВЩбљМЏЁЃ
baggingЕФЬиЕу
1.бЕСЗвЛИіbaggingМЏГЩгыжБНгЪЙгУЛљбЇЯАЫуЗЈбЕСЗвЛИібЇЯАЦїЕФИДдгЖШЭЌНз
2.гыБъзМЕФadboostжЛЪЪгУгкЖўЗжРрШЮЮёВЛЭЌЕФЪЧЃЌbaggingФмВЛОаоИФЕигУгкЖрЗжРрЁЂЛиЙщЕШШЮЮё
3.гЩгкзджњВЩбљЙ§ГЬЕФаджЪЃЌАќЭтбљБОПЩвдгУзїАќЭтЙРМЦЃЌПЩгУРДИЈжњМєжІЃЌМѕаЁЙ§ФтКЯЗчЯе
4.ДгЦЋВю-ЗНВюНЧЖШПДЃЌbaggingжївЊЙизЂНЕЕЭЗНВюЃЌвђДЫЫќдкВЛМєжІОіВпЪїЁЂЩёОЭјТчЕШвзЪмбљБОШХЖЏЕФбЇЯАЦїЩЯаЇгУИќУїЯдЁЃ
ЫцЛњЩСж
ЫцЛњЩСжЪЧИќЯШНјЕФbaggingЗНЗЈЁЃRFЪЧдквдОіВпЪїЮЊЛљбЇЯАЦїЙЙНЈbaggingМЏГЩЕФЛљДЁЩЯЃЌНјвЛВНдкОіВпЪїЕФбЕСЗЙ§ГЬжав§ШыСЫЫцЛњЪєадбЁдёЁЃДЫДІЯъЧщЧыДСЃКRF
boosting
boostingЪЧвЛжжгыbaggingКмРрЫЦЕФММЪѕЁЃВЛТлЪЧboostingЛЙЪЧbaggingЃЌЫљЪЙгУЕФЗжРрЦїЕФРраЭЖМЪЧвЛжТЕФЁЃЕЋЪЧbaggingЪЧИіЬхбЇЯАЦїМфВЛДцдкЧПвРРЕЙиЯЕЁЂПЩЭЌЪБЩњГЩЕФВЂааЛЏЗНЗЈЃЛboostingЪЧИіЬхбЇЯАЦїМфДцдкЧПвРРЕЙиЯЕЁЂБиаыДЎааЩњГЩЕФађСаЛЏЗНЗЈЁЃ
boostingВЛЭЌЕФЗжРрЦїЪЧЭЈЙ§ДЎаабЕСЗЖјЛёЕУЕФЃЌУПИіаТЗжРрЦїЖМИљОнвббЕСЗГіЕФЗжРрЦїадФмРДНјаабЕСЗЁЃboostingЪЧЭЈЙ§МЏжаЙизЂБЛвбгаЗжРрЦїДэЗжЕФФЧаЉЪ§ОнРДЛёЕУаТЕФЗжРрЦїЁЃ
гЩгкboostingЗжРрЕФНсЙћЪЧЛљгкЫљгаЗжРрЦїЕФМгШЈЧѓКЭНсЙћЕФЃЌвђДЫboostingгыbaggingВЛЬЋвЛбљЁЃbaggingжаЕФЗжРрЦїШЈжиЪЧЯрЕШЕФЃЌЖјboostingжаЕФЗжРрЦїШЈжиВЂВЛЯрЕШЃЌУПИіШЈжиДњБэЦфЖдгІЗжРрЦїдкЩЯвЛТжЕќДњжаЕФГЩЙІЖШЁЃ
boostingзхЫуЗЈзюОпДњБэадЕФЪЧAdaBoostЁЃЙигкAdaBoostЮвЧАУцгаЦЊВЉПЭгаЗжЯэЃКРћгУAdaBoostдЊЫуЗЈЬсИпЗжРрадФмЁЃетРяЮвНЋНсКЯФЧЦЊВЉПЭЕФФкШнЩюШыЗжЮіAdaBoostЕФдРэгыЪЕЯжЁЃ
зюаЁЛЏжИЪ§Ы№ЪЇКЏЪ§
AdaBoostЫуЗЈгаКмЖрЕФЭЦЕМЗНЪНЃЌБШНЯШнвзРэНтЕФЪЧЛљгкЁАМгадФЃаЭЁБЃЌМДЛљбЇЯАЦїЕФЯпадзщКЯЃК
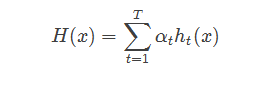
РДзюаЁЛЏжИЪ§Ы№ЪЇКЏЪ§ЃЌжаМфЭЦЕМВЛзїЯъЯИНщЩмЁЃ
AdaBoostЪЧadaptive boostingЕФЫѕаДЃЌЦфдЫааЙ§ГЬШчЯТЃК
бЕСЗЪ§ОнжаЕФУПИібљБОЃЌВЂИГгшЦфвЛИіШЈжиЃЌетаЉШЈжиЙЙГЩСЫЯђСПDЁЃвЛПЊЪМетаЉШЈжиШЋВПБЛГѕЪМЛЏГЩЯрЕШЕФжЕЁЃЪзЯШдкбЕСЗЪ§ОнЩЯбЕСЗГівЛИіШѕЗжРрЦїВЂМЦЫуИУЗжРрЦїЕФДэЮѓТЪЃЌШЛКѓдкЭЌвЛЪ§ОнМЏЩЯдйДЮбЕСЗШѕЗжРрЦїЁЃдкЗжРрЦїЕФЕкЖўДЮбЕСЗжаЃЌНЋЛсжиаТЕїећУПИібљБОЕФШЈжиЃЌЦфжаЕквЛДЮЗжЖдЕФбљБОШЈжиНЋЛсНЕЕЭЃЌЖјЕкЖўДЮЗжДэЕФбљБОШЈжиНЋЛсЬсИпЁЃЮЊСЫДгЫљгаШѕЗжРрЦїжаЕУЕНзюжеЕФЗжРрНсЙћЃЌAdaBoostЮЊУПИіЗжРрЦїЖМЗжХфСЫвЛИіШЈжижЕalphaЃЌетаЉalphaжЕЪЧЛљгкУПИіШѕЗжРрЦїЕФДэЮѓТЪНјааМЦЫуЕФЁЃ
ЮвУЧЖЈвхШѕЗжРрЦїЕФДэЮѓТЪЮЊЃК

ЭЈЙ§зюаЁЛЏЫ№ЪЇКЏЪ§ЃЌЧѓЕУAdaBoostИјУПИіЗжРрЦїЗжХфЕФШЈжижЕalphaЃЌЙЋЪНШчЯТЃК
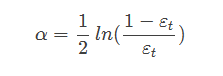
AdaBoostЫуЗЈЕФСїГЬШчЯТЭМЫљЪОЃК
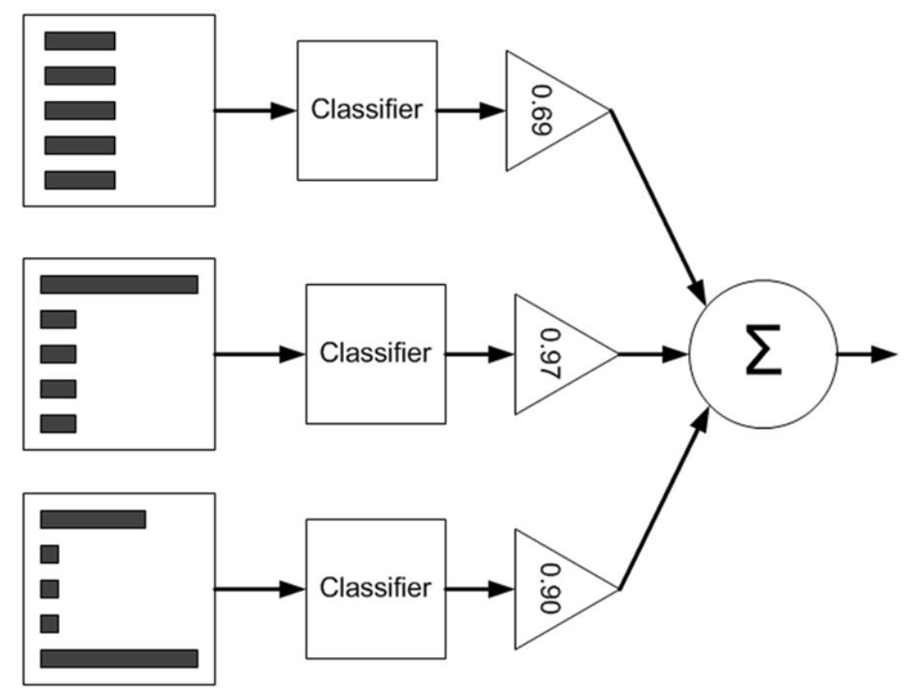
ШчЩЯЭМЫљЪОЃКзѓБпЪЧЪ§ОнМЏЃЌЦфжажБЗНЭМЕФВЛЭЈПэЖШБэЪОУПИібљР§ЩЯЕФВЛЭЌШЈжиЁЃОЙ§вЛИіЗжРрЦїжЎКѓЃЌМгШЈЕФдЄВтНсЙћЛсЭЈЙ§Ш§НЧаЮжаЕФalphaжЕНјааМгШЈЁЃУПИіШ§НЧаЮжаЪфГіЕФМгШЈНсЙћдкдВаЮжаЧѓКЭЃЌДгЖјЕУЕНзюжеЕФЪфГіНсЙћЁЃ
МЦЫуГіalphaжЕКѓПЩвдЖдШЈжиЯђСПDНјааИќаТЃЌвдЪЙЕУФЧаЉе§ШЗЗжРрЕФбљБОЕФШЈжиНЕЕЭЃЌЖјДэЗжбљБОЕФШЈжиЩ§ИпЁЃDЕФМЦЫуЗНЗЈШчЯТЁЃ
ШчЙћФГИібљБОБЛе§ШЗЗжРрЃЌФЧУДИУбљБОЕФШЈжиИќИФЮЊЃК
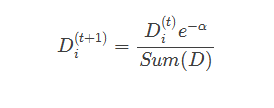
ШчЙћФГИібљБОБЛДэЗжЃЌФЧУДИУбљБОЕФШЈжиИќИФЮЊЃК
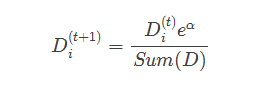
дкМЦЫуГіDжЎКѓЃЌAdaBoostгжПЊЪМНјШыЯТвЛТжЕќДњЁЃAdaBoostЛсВЛЖЯЕижиИДбЕСЗКЭЕїећШЈжиЕФЙ§ГЬЃЌжЊЕРбЕСЗДэЮѓТЪЮЊ0ЛђепШѕЗжРрЦїЕФЪ§ФПДяЕНгУЛЇЕФжИЖЈжЕЮЊжЙЁЃ
AdaBoostЕФЪЕЯж
ЛљгкЕЅВуОіВпЪїЙЙНЈШѕЗжРрЦї
ЕЅВуОіВпЪїЪЧвЛжжМђЕЅЕФОіВпЪїЁЃЧАУцЮвУЧвбОНщЩмСЫОіВпЪїЕФЙЄзїдРэЃЌНгЯТРДЙЙНЈвЛИіЕЅВуОіВпЪїЃЌЖјЫќНіНіЛљгкЕЅИіОіВпЬиеїРДзіОіВпЁЃгЩгкетПУЪїжЛгавЛДЮЗжСбЙ§ГЬЃЌвђДЫЫќЪЕМЪЩЯОЭЪЧвЛИіЪїзЎЁЃвђДЫвВБЛГЦЮЊОіВпЪїзЎЁЃ
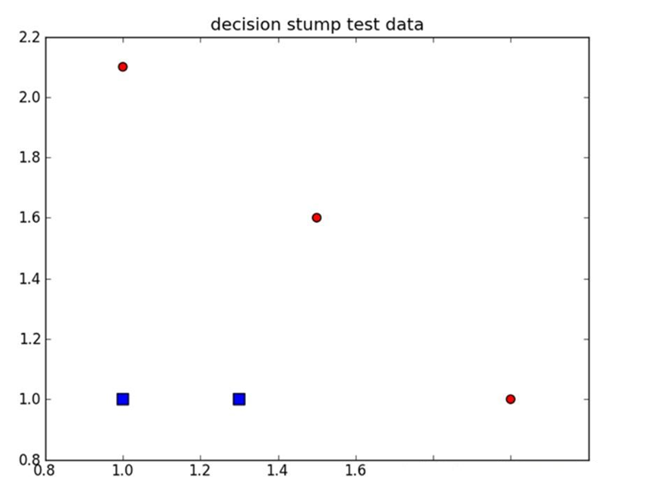
ШчЩЯЭМЫљЪОЃЌЮвУЧЯЃЭћДгФГИізјБъжсЩЯбЁдёвЛИіжЕРДНЋЩЯЭМжаЕФЫљгадВаЮЕуКЭЗНаЮЕуЗжПЊЃЌетЯдШЛЪЧВЛПЩФмЕФЁЃетОЭЪЧЕЅВуОіВпЪїФбвдДІРэЕФвЛИіжјУћЕФЮЪЬтЁЃЭЈЙ§ЪЙгУЖрПУЕЅВуОіВпЪїЃЌЮвУЧОЭФмЙЙНЈГіЖдИУЪ§ОнМЏЭъШЋе§ШЗЗжРрЕФЗжРрЦїЁЃ
ЕЅВуОіВпЪїЕФЮБДњТыШчЯТЫљЪОЃК

ЩЯЪіЮБДњТыЕФКЫаФЫМЯыОЭЪЧбАевОпгазюЕЭДэЮѓТЪЕФЕЅВуОіВпЪїЁЃ
ДњТыШчЯТЃК
| def
stumpClassify(dataMatrix,dimen,threshVal,
threshIneq):#just
classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal]
= -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal]
= -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat
(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst
=
mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax =
dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over
all range in current dimension
for inequal in ['lt', 'gt']: #go over less than
and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,
threshVal,inequal)#call stump classify with
i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error
multiplied by D
#print "split: dim %d, thresh %.2f, thresh
ineqal:
%s, the weighted error is %.3f" % (i,
threshVal,
inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst |
ЩЯЪіДњТыШЈжиДэЮѓweightedErrorЪЧAdaBoostКЭЗжРрЦїНЛЛЅЕФЕиЗНЁЃЙЙНЈОіВпЪїзЎЕФЫуЗЈКЫаФОЭЪЧдквЛИіМгШЈЕФЪ§ОнМЏжабЛЗЃЌШЛКѓевЕНОпгазюЕЭДэЮѓТЪЕФЕЅВуОіВпЪїЁЃ
ЕНФПЧАЮЊжЙЮвУЧвбОЙЙНЈСЫвЛИіОіВпЪїзЎЃЌНгЯТРДЮвУЧОЭЭЈЙ§ЪЙгУЖрИіШѕЗжРрЦїРДЙЙНЈAdaBoostДњТыЁЃ
ЛљгкОіВпЪїзЎЕФAdaBoostЕФЙЙНЈ
AdaBoostбЕСЗ
AdaBoostбЕСЗЕФЮБДњТыЙЙдьШчЯТЃК

ДњТыШчЯТЃК
| def
adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build
Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc
alpha, throw in max(error,eps) to account for
error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump
Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
#exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next
iteration
D = D/D.sum()
#calc training error of all classifiers, if
this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst |
AdaBoostВтЪд
етРяЮвУЧжЛЪЧМђЕЅЕигІгУСЫЕЅВуОіВпЪїЁЃЪфГіЕФЙРМЦРрБ№жЕГЫЩЯИУЕЅВуОіВпЪїЕФalphaШЈжиЃЌШЛКѓНјааРлМгЃЌОЭЭъГЩСЫЗжРрЙ§ГЬЁЃДњТыШчЯТЃК
| def
adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar
to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return sign(aggClassEst) |
AdaboostгІгУ
ЮвУЧгІгУЩЯЭМЗНаЮгыдВаЮЪ§ОнЕуЪ§ОнЃЌРДНјааЗжРрЁЃ
ЪзЯШЮвУЧПДвЛЯТбЕСЗЪ§ОнЃК
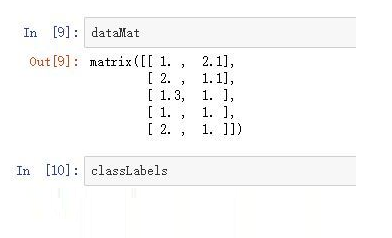
ШЛКѓПДвЛЯТбЕСЗНсЙћЃК
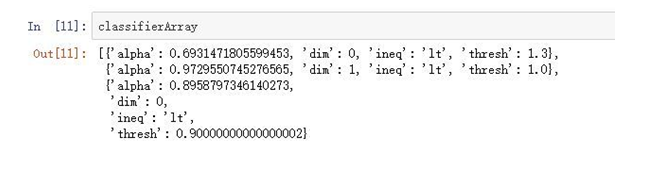
етРябЕСЗСЫШ§ИіШѕЗжРрЦїЁЃ
зюКѓПДвЛЯТВтЪдНсЙћЃЌетРяЮвУЧбЁдёСЫСНИібЕСЗЪ§ОнЃЈ0ЃЌ0ЃЉЃЛЃЈ5ЃЌ5ЃЉЃК
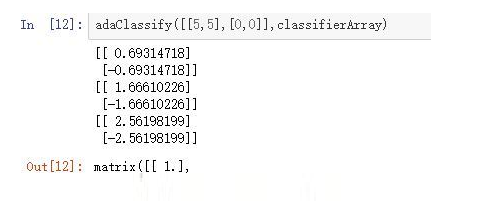
змНс
БОДЮЗжЯэНщЩмСЫСНжжМЏГЩЗНЗЈЃКbaggingЃЌboostingЁЃдкbaggingжаЃЌЪЧЭЈЙ§ЫцЛњГщбљЕФЬцЛЛЗНЪНЕУЕНгыдЪМЪ§ОнМЏЙцФЃвЛбљЕФЪ§ОнМЏЁЃboostingБШbaggingЫМЯыИќНјвЛВНЃЌдкЪ§ОнМЏЩЯЫГађгІгУСЫЖрИіВЛЭЌЕФЗжРрЦїЁЃБОЮФКѓАыВПЗжжиЕуНВЪіСЫAdaBoostЕФМђЛЏАцЪЕЯжЗНЗЈЃЌAdaBoostКЏЪ§ПЩвдгІгУгкШЮвтЗжРрЦїЃЌжЛвЊИУЗжРрЦїФмЙЛДІРэМгШЈЪ§ОнМДПЩЁЃ
|









