| 编辑推荐: |
本文就Java真的老了吗展开讲述,诠释了作者作为一名Java开发者的所思所感。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者,由火龙果软件Linda编辑、推荐。 |
|
阿里妹导读
本文就Java真的老了吗展开讲述,诠释了作者作为一名Java开发者的所思所感。
最近抽空看了Go、Rust等一些语言的新版本特性,还有云原生的一些基础设施(Docker,Kubernetes,ServiceMesh,Dapr,Serverless),有点感慨Go真的是云原生的“一等公民”,像是启动速度快、依赖少、内存占用少、Goroutine
并发等无一不是击中Java的软肋。然后突发奇想在Google上搜了下“Java老矣”,能搜出520,000条结果。不禁想问:Java真的老了吗?
“落寞”的Java
自1995年出生以来,Java已经有27年历史了,曾经的风流雨打风吹去,一些优秀的设计在今天看来似乎并不那么重要甚至过时了。比方说:
"Write Once, Run Everywhere"的平台无关特性在当年确实是真香,但现在这种部署的便利性已经完全可以交由Docker为代表的的容器提供了(从某种意义上说,JVM也是字节码的容器),而且做得更好,可以将整个运行环境进行打包。想想Docker的口号也是:"Build
Once, Run Anywhere"。
Java 总体上是面向大规模、长时间运行的服务端应用而设计的。在语法层面,Java+Spring框架写出的代码一致性很高;在运行期,有JIT编译、GC等组件保障应用稳定可靠。这些特性对于企业级应用十分关键,曾经是Java最大的优势之一。但在微服务化甚至Serverless化的部署形态下,有了高可用的服务集群,也无须追求单个服务要
7×24 小时不可间断地运行,它们随时可以中断和更新,Java的这一优势无形中被削弱了。
另一个广为诟病的是Java的资源占用问题,这主要包含两方面:静态的程序大小和动态的内存占用。
不管多大的应用,都要随身带一个臃肿的JRE环境(这里先不讨论模块化改造),加上各种复杂的Jar包依赖,看了下我们团队的每个Java应用的容器镜像大小都轻松上G。
应用的运行期内存占用居高不下,这个是Java天生的缺陷,很难克服。

Java的启动时间也是一大心病,主要原因在于启动时虚拟机初始化和大量类加载的时间开销(当然还有一个罪魁祸首是Spring的bean初始化,我之前写了个异步初始化Spring
Bean的starter rhino-boot-turbo,把串行改并行启动速度会快很多)。本身镜像体积大,拉取时间就长,再加上分钟级的启动时间,部署应用就更显得慢了。传统的企业应用更看重长时间运行的稳定性,重启和发布频率相对较低,对启动时间相对没那么敏感,然而对于需要快速迭代、水平扩展的微服务应用而言,更快的的启动速度就意味着更高的交付效率和更加快速的回滚。尤其是对于Serverless应用或函数,冷启动速度至关重要,之前看AWS
Lambda函数允许最多运行5分钟,很难想象还要花一分钟时间先启动。
云原生的潮流滚滚而来,Java的这些缺陷在要求快速交付的大环境下显得格格不入,难怪Java与Go、Rust等原生语言相比,会显得“落寞”了。
作为一个Java程序员,肯定想问,Java还有机会吗?想起有位长者说过:一个人的命运啊,当然要靠自我的奋斗,另一方面,也要考虑历史的进程。我想把它改成:Java的命运啊,当然要靠自身的努力,另一方面,也要考虑队友们给不给力。
JDK的演进
我们的大部分系统都还跑在Java 8之上,因此作为开发同学对Java 8也是最熟悉的。从Java
9开始,JDK的版本号堪比版本狂魔Chrome涨得飞快,除去开发者能够肉眼感知的语法和API的变动(Productivity)之外,Java也在性能(Performance)上一直努力。
我捋了一下OpenJDK官网[1]从Java 9开始的JEP列表,按照个人理解列出了关键的一些特性。
Java 9:难产的模块化
在数次delay之后,Java 9终于正式引入了Java平台模块系统(JPMS),项目代号Jigsaw。在这之前,Java以package对代码进行组织,再将package和资源打成Jar包,模块则在package的概念上将多个逻辑上、功能上相关的包以及相关的资源文件封装成模块。关于模块的详细介绍,可以参考下官方的介绍文档:Understanding
Java 9 Modules[2]。
此前,Java Runtime的庞大臃肿一直为人诟病(一个rt.jar就有60多M,整个JRE环境可以达到上百M),瘦身正是Project
Jigsaw的目标[3]之一。此外,还有Jar Hell、安全性等等问题。

不过模块化看着很好,也隐藏着陷阱:
不可忽视的改造成本
虽然提供了未命名模块和自动模块,Oracle也提供了迁移指南和工具[4]供参考,但改造的成本依旧很大,特别是梳理模块之间的依赖关系,较为繁琐。
小心使用内部API
模块化的最大卖点之一是强大的封装性,它确保非public类以及非导出包中的类无法从模块外部访问。但在这之前,jar包中类的访问是没有限制的(即使是private也可以通过反射访问)。比如JDK中的大部分com.sun.*
和 sun.*包是内部无法访问的,但这之前被用得很多(出于性能/向前兼容等等原因),虽然Oracle的建议是不要使用这些类:Why
Developers Should Not Write Programs That Call 'sun'
Packages[5]。
小心使用内部JAR
像lib/rt.jar和lib/tools.jar等内部 JAR不能再访问了。不过正常来说,应该只有IDE或类似工具会直接依赖?
小心使用JAR中的资源
一些API会在运行期获取JAR中的资源文件(例如通过ClassLoader.getSystemResource),在Java9之前会拿到
jar:file:<path-to-jar>!<path-to-file-in-jar>这类格式的URL
Schema,而Java9之后则变成了 jrt:/<module-name>/<path-to-file-in-module>
其他一些问题[6]
对于新的项目,使用模块构建似乎是值得的,但现状是,大多数开发者会忽略模块系统,尤其是对于已经运行了多年的大型项目,改造的成本令人望而却步。我猜测肯定会有人吐槽类似的问题:
我已经分成不同jar包了,我感觉这样就可以了,有必要更进一步吗?
我又不是开发中间件和框架的,我开发业务应用,为什么要关心这些?
就算我有二方包要开放出去,为二方包维护模块定义似乎也带不来多少收益?
该如何分离每个模块,基于什么原则?就跟DDD一样,我知道这东西很美好,有最佳实践可以参考吗?
搜了一下,似乎国外网友也有一样的疑惑[7]。不过,我认为让程序员可以定义应用程序的模块是什么,它们将如何被其他模块使用,以及它们依赖于哪些其他模块,这些事情还是有必要做的。
当然Java9除了模块化之外,还有一些其他特性也值得关注:
compact strings[8],通过对底层存储的优化来减少String的内存占用。String对象往往是堆内存的大头(通常来说可以达到25%),compact
string可以减少最多一倍的内存占用;
AOT编译[9],一个实验性的AOT编译工具jaotc[10]。它借助了Graal编译器,将所输入的Java类文件转换为机器码,并存放至生成的动态共享库之中。jaotc的一大应用便是编译java.base
module(也就是模块化后Java核心类库中最为基础的类)。这些类很有可能会被应用程序所调用,但调用频率未必高到能够触发即时编译。
JVMCI[11]( JVM 编译器接口),另一个experimental的编译特性。用Java写Java编译器,Java也可以说我能自举了!
关于 JVMCI 多介绍一些。相比用 C 或 C++ 编写的现有编译器(说的就是你,C2),用Java写编译器更容易维护和改进。JVMCI的API
提供了访问 JVM 结构、安装编译代码和插入 JVM 编译系统的机制,后面讲到的Graal正是基于JVMCI。
JVMCIJIT编译器与JVM的交互可以分为如下三个方面。
响应编译请求;
获取编译所需的元数据(如类、方法、字段)和反映程序执行状态的profile;
将生成的二进制码部署至代码缓存(code cache)里。
即时编译器通过这三个功能组成了一个响应编译请求、获取编译所需的数据,完成编译并部署的完整编译周期。
传统情况下,即时编译器是与Java虚拟机紧耦合的。也就是说,对即时编译器的更改需要重新编译整个Java虚拟机。这对于开发相对活跃的Graal来说显然是不可接受的。
为了让Java虚拟机与Graal解耦合,引入 JVMCI 将上述三个功能抽象成一个Java层面的接口。这样一来,在Graal所依赖的JVMCI版本不变的情况下,我们仅需要替换Graal编译器相关的jar包(Java
9以后的jmod文件),便可完成对Graal的升级。
其实JVMCI接口就长这样:
public interface JVMCICompiler {
/**
* Services a compilation request. This object should compile the method to machine code and
* install it in the code cache if the compilation is successful.
*/
CompilationRequestResult compileMethod(CompilationRequest request);
}
|
Java 10:小升级
Java10的性能提升点并不多(6个月一次的版本节奏难免要挤挤牙膏):
G1的多线程并发mark-sweep-compact:这个feature的背景是G1垃圾回收器在Java9中引入,但那会还使用单线程做mark-sweep-compact。
Application Class-Data Sharing[12]:通过在不同Java进程间共享应用类的元数据来降低启动时间和内存占用,算是对Java
5引入的CDS的扩展,在这之前只支持Bootstrap Classloader加载的系统类。
其实这个特性还挺有用的,因为Java启动慢很大一部分时间耗在类加载上,CDS生成的存档类似于一个快照,在运行时可以直接做内存映射,还可以在多个JVM之间共享存档文件来减少内存占用。这个JEP中也提了一嘴:对Serverless云服务的分析表明,其中许多在启动时加载了数千个应用程序类,AppCDS
可以让这些服务快速启动并提高整体系统响应时间。
Docker的支持[13]更好了,能认出Docker环境了。
Java 11:ZGC闪亮登场
Java 11是LTS版本,也可能是企业选择从万年Java 8升级到的第一个版本。Java11最大的改动是引入了新一代的垃圾回收器-ZGC[14]。ZGC的首要目标是实现低停顿(暂停时间不超过10ms)、高并发的垃圾回收,ZGC回收器与G1一样基于Region内存布局,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-整理。
但ZGC并不是完美的,逃不过内存占用(Footprint)、吞吐量(Throughput)和延迟(Latency)的三元悖论。与G1相比,它的强项是低延迟,缺点是内存占用更高,吞吐量比G1稍低(不过这强依赖于测试用例,我也看到一些benchmark显示ZGC的吞吐量高于G1),另外还有一些其他问题[15]也值得注意。总的来说,如果考虑使用ZGC替代CMS,建议是使用Java
15之后的版本。

数据来源:Understanding the JDK’s New Superfast Garbage
Collectors[16]
另一个容易被人忽略的特性是Java 11中引入了一个号称无操作的垃圾回收器Epsilon[17],即不会做GC的垃圾回收器。这个很有意思,但确实对于一些不需要长时间运行、小规模的程序来说,会更关注启动时间、内存占用等指标,很典型的就比如Serverless函数。只要JVM能正确分配内存,然后在堆耗尽之前退出,那显然运行负载极小、没有任何回收行为的Epsilon便是很恰当的选择。
Java 12:Shenandoah和内存返还
Java 12中引入了一个新的实验性的垃圾回收器-Shenandoah[18],与ZGC一样是以低停顿为目标(注意这里说的是OpenJDK,因为非亲生的缘故,OracleJDK中并没有包含)。
另一个是G1上的改动,能够自动将未使用的堆内存返还给操作系统[19]。我们经常看到,Java程序占用的内存比实际应用本身运行产生的对象占用要多,即使在应用本身没有流量时也是如此,原因是多方面的(这里不谈JVM、类的元数据、编译后的本地代码等等对内存的额外占用):
一方面,Java是一门有GC的语言,垃圾对象会持续占用内存,直到下一次GC为止
另一方面,GC算法也决定了更多的内存占用,例如:
标记-复制的算法需要有两块内存区域,一个典型的例子是新生代的Survivor区;标记-清除的算法很多时候同样需要更大的内存区域,因为在GC结束时会有大量的空间碎片,在分配大对象时会很麻烦。
像CMS/G1这样的并发回收器,因为在垃圾收集阶段用户线程还需要持续运行,那就需要预留足够内存空间提供给用户线程使用。
CMS的做法是在老年代达到指定的占用率后(Java 6后默认为92%)开始GC,可以通过-XX:CMSInitiatingOccupancyFraction参数调高这个值,但调得太高又容易碰到Concurrent
Mode Failure;
G1的解法则是为每一个Region设计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上,并且默认不回收在这个地址以上的对象。
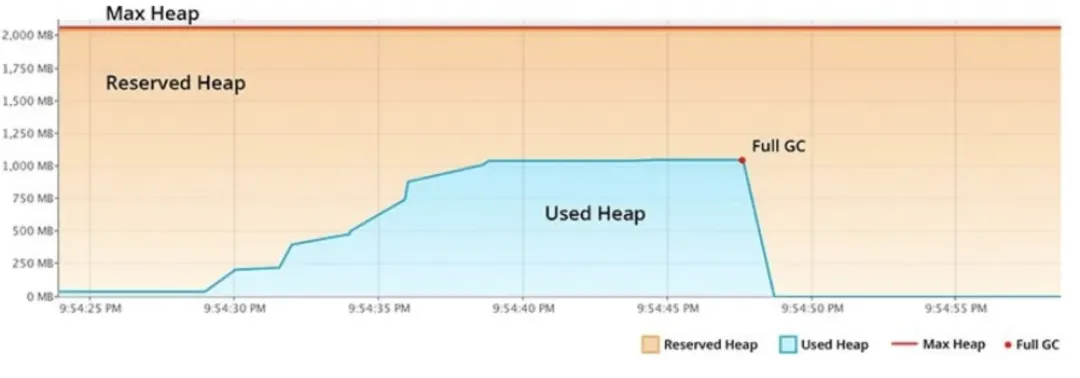
一般来说,JVM在启动时就会一次性申请大块内存(上图的Reserved Heap),然后倾向于在运行期保留这些内存。虽然一次GC结束后可能会空出很多内存,但JVM在内存返还策略上有时会左右为难,因为这些内存有可能很快就需要被拿来分配对象,如果频繁进行归还,再而触发
page fault 反而带来性能下降。折中的策略是动态地根据负载来决定是否返还。
在这之前,G1只有在Full-GC或并发周期期间才能返还内存,而G1的目标之一是避免Full-GC,并且仅根据
Java 堆占用和分配活动触发并发循环,因此多数场景下,除非强制触发,并不会有内存返回行为。在Java
12后,G1会在应用不活动的空闲期间定期尝试继续或触发并发循环以确定整体 Java 堆使用情况,并自动将
Java 堆中未使用的部分返回给操作系统。
JEP中举了一个Tomcat服务器的示例,服务器在白天提供HTTP请求,而在夜间大部分时间处于空闲状态,新的内存返还特性可以使得JVM提交的内存减少85%。
Java 13:小升级+1
同Java 10一样,Java 13也是一个小升级版本:
ZGC的增强[20]:同G1和Shenandoah一样,可以将未使用的内存返还给操作系统了
AppCDS的增强[21]:在Java10的AppCDS基础上支持动态归档,可以在程序退出时自动创建
Java 14:小升级+2
ZGC支持Mac和Windows了(不过大部分生产环境应该不会用这俩?)
G1支持Numa-Aware的内存分配[22]:NUMA(Non-Uniform Memory Access,非统一内存访问架构)的介绍可以参考下这篇文章:【计算机体系结构】NUMA架构详解[23]。在NUMA架构下,G1收集器会优先尝试在请求线程当前所处的处理器的本地内存上分配对象,以保证高效内存访问。在G1之前的收集器就只有针对吞吐量设计的Parallel
Scavenge支持NUMA内存分配,如今G1也成为另外一个选择。
Java 15:ZGC和Shenandoah转正
从Java 11和Java 12分别引入ZGC和Shenandoah以来,一直是Experimental的两大垃圾回收器终于Production了。
Java 16:Alipine Linux的支持
Java 16中跟性能提升相关的特性主要包括:
ZGC支持并发线程堆栈处理[24]
弹性元空间[25]:一般Java程序里元空间(metaspace)的内存占用相比起堆来说不算高,但也很容易出现出现内存浪费。Java
16优化了元空间的内存分配机制来减少内存占用。
另外值得一提的是Java 16将JDK移植到了Alpine Linux[26]。Alipine Linux[27]是一个非常轻量的Linux发行版,其Docker镜像只有5MB左右(对比Ubuntu系列镜像接近200
MB)。更小的镜像意味着容器环境中更小的磁盘占用和更快的镜像拉取速度,正因如此,Docker 官方已开始推荐使用
Alpine 替代之前的 Ubuntu 作为基础镜像。为了瘦身,Alpine Linux默认是用musl[28]而非传统的glibc作为C标准库,因此之前的JDK并不直接支持Alpine,而是需要在Alpine基础上安装glibc。
基于Alpine Linux基础镜像,再结合Java 9引入的模块化能力,如果程序只依赖 java.base模块,Docker镜像的大小可以小至38
MB。
Java 17:最新的LTS版本
激进的团队可能会跳过Java 11,直接从Java 8升级到Java 17,因为这是最新的LTS版本。Java
17(包括最新的Java 18)本身并没有包含太多的性能提升特性,更多的是语法和API的变动,也没啥好列的了。
Project X
标题的Projext X只是代称,代表了Java官方或社区所推进的一系列项目。这些项目出于不同的动机,但最终的目的都是为了让Java更适应新的时代。完整的项目列表可以看这里[29],其中比较有代表性的有:
Project Amber[30]:旨在探索和孵化更小的、以生产力为导向的 Java 语言功能,每个提案的特性都不大,很多已经落地到不同JDK版本中了,像是Records[31]、Sealed
Class[32]、Pattern Matching、Text Blocks[33]等等。
Project Leyden[34]:旨在解决Java的启动时间、TTP(Time to Peak)性能、内存占用等顽疾。一个特性即是AOT编译,但难度太大,短期内指望不上,先寄希望于GraalVM。
Project Loom[35]:Java的协程和结构化并发[36]。
Project Valhalla[37]:旨在探索和孵化高级Java VM和语言特性,例如值类型(Value
types)[38]和基于值类型的泛型[39]。
Project Portola[40]:将 OpenJDK 向 Alpine Linux 移植,在Java
16中已经得到了落地。
Project Panama[41]: 更好地跟本地代码(主要是C代码)交互。
Project Lilliput[42]:将对象头缩减到64bit来降低内存占用。

截至今天,最新的Java 18中仅包含了Project Amber和Project Portola的一些特性,像Project
Loom、Project Valhalla等并没有包含,更别提难度最大的Project Leyden了,确实是有点落后了。不管如何,了解下这些项目做的事情可以让我们更好地理解Java未来的发展方向。
提前编译-AOT
我们一直说Java速度慢,我觉得这是一个不严谨的误会,因为实际上经过JIT编译后Java运行并不慢。为什么Java给人“更慢”的印象?可能这两方面因素是罪魁祸首:
启动慢,Java启动需要初始化虚拟机,加载大量的类
预热慢,在JIT编译器介入前,需要在解释模式下运行
Java是一门跨平台语言,但JVM并不是跨平台的,Java将源码编译成字节码,交给JVM执行,这中间装载的开销很高。
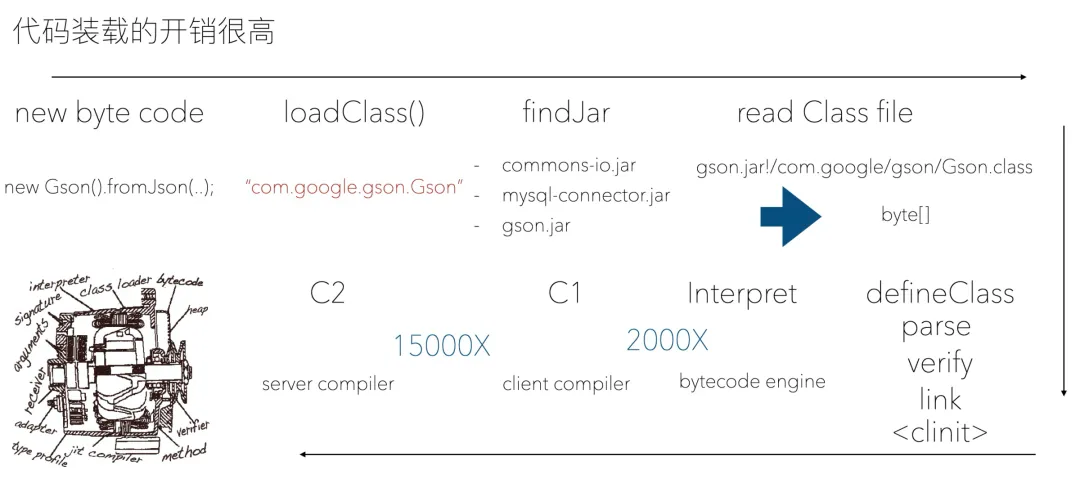
一段程序想要被加载需要经过的流程:
new 字节码或者 static 相关字节码触发类加载
从一系列 jar 包中找到感兴趣的 class 文件
将 class 文件的读取到内存里的 byte 数组
defineClass,包括了 class 文件的解析、校验、链接
类初始化(static 块,或者静态变量初始化)
开始解释执行
2000 次解释后被 client compiler JIT 编译,随后 15000 次执行后被 server
compiler JIT 编译
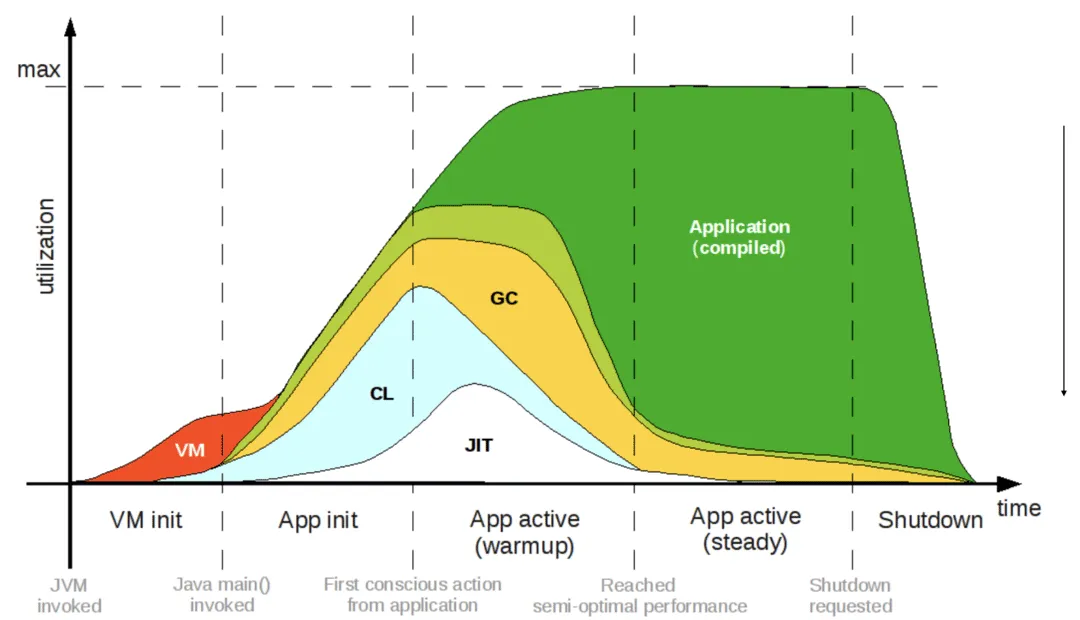
上面这张图能够清晰地看出Java从启动到达到最佳性能的不同阶段。
如果跳过字节码,直接将Java代码编译成本地代码,那么所有代码都是在编译期编译和优化好的,是不是就不存在JVM初始化和类加载的开销问题,也不用等预热到JIT编译(编译时还要耗费额外的运行期CPU资源),马上就能达到最大性能?这就是AOT(Ahead-Of-Time
Compilation)提前编译的思想。
当然AOT编译也有劣势:
峰值性能:AOT编译不像JIT编译一样能收集程序运行时的信息,因此也无法进行一些更激进的优化,例如基于类层次分析的完全虚方法内联,或者基于程序profile的投机性优化(不过这并非硬性限制,我们可以通过限制运行范围,或者利用上一次运行的程序profile来绕开这些限制)。
构建时长:从目前的实测数据看,像Graal编译器花的构建时间都比正常编译时间要长。不过这个也在情理之中,毕竟一个只需要把代码编译成字节码,一个则需要扫描然后分析程序所有的依赖做静态编译。
在生产的本地镜像(Native Image)中使用Java agents,JMX,JVMTI,JFR等组件会有一些限制。
(最关键的)动态特性的支持:AOT编译很美好,但是在Java中实现起来却很困难,主要的原因在于Java虽然是一门静态语言,但是也包含了很多动态特性,比如反射、动态代理、动态类加载、字节码Instrument
(BCI) 等等,而提前编译要求满足封闭世界假设( closed world assumption),在编译期就确定程序用到的类。
这是一个很简单的取舍问题,因为动态特性在Java中用得实在是太普遍了,不管是Spring、Hibernate这些应用框架还是CGLib这类字节码生成库,大部分生产力工具都依赖这些动态特性,所以Java的提前编译至今还是Experimental状态。
目前来看使用AOT难免需要有一些折中,例如后面要讲到的Substrate VM就要求以配置的方式明确告知编译器程序代码中有哪些方法是只通过反射来访问的,哪些类会被动态加载等等。然而另一些功能可能只能妥协或者放弃了,就像动态生成字节码这类十分常用的功能,我们熟知的Spring默认就会使用CGLib生成动态代理。从
Spring Framework 5.2 开始增加了@proxyBeanMethods注解来排除对
CGLib 的依赖,仅使用标准的动态代理去增强类,但这也就限制了动态代理的能力。
要获得有实用价值的提前编译能力,只有依靠提前编译器、组件类库和开发者三方一起协同才有可能办到。这就要靠后面说的队友的助攻了。
协程(虚拟线程)
协程[44](Coroutine,有的地方也称为纤程/Fiber)并不算一个新鲜的概念,但与线程相比一直让开发者感觉陌生,我觉得最主要的原因是大多数编程语言对于协程的支持并不像线程一样“原生”。直到Go和Kotlin这些热门的语言直接内置了协程,协程才成为“一等公民”被开发者重新审视。
对于协程的定义,不仅在不同语言中有差异,随着时代的变化定义也在变化,我试着将主流印象中的协程和线程做一个不严谨的对比:
协程是协作式的,线程是抢占式;
协程在用户模式下,由应用程序调度管理,而线程则由操作系统内核管理;
(有栈)协程拥有自己的寄存器上下文和栈,但比线程要小得多(MB和KB级别的差距),切换也快得多;
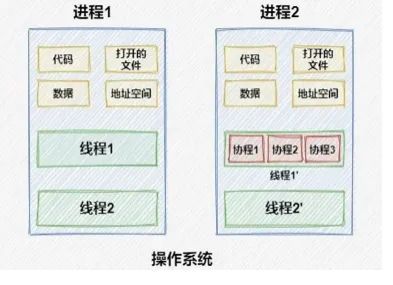
一个线程可以包含一个或多个协程,即不同的协程可以在一个线程上被调度。协程也被称为轻量级线程,有意思的是线程有时候也被成为轻量级进程;
回到Java,基本上线程模型分成1:1、N:1,N:M三种,虽然说JVM并没有限定 Java 线程需要使用哪种线程模型来实现,但一般来说Java目前主流的线程模型是直接映射到操作系统内核上的1:1
模型[45],即一个用户线程就唯一地对应一个内核线程(这里不谈在遥远的JDK1.2之前,那会也使用过称为“绿色线程”的N:1模型)。
1:1的模型对于计算密集型任务这很合适,既不用自己去做调度,也利于一条线程跑满整个处理器核心;但对于
I/O 密集型任务,譬如访问磁盘、访问数据库占主要时间的任务,这种模型就显得成本高昂,主要在于内存消耗和上下文切换上:64
位 Linux 上 HotSpot 的线程栈容量默认是 1MB,线程的内核元数据(Kernel Metadata)还要额外消耗
2-16KB 内存,所以单个虚拟机的最大线程数量一般只会设置到 200 至 400 条,当程序员把数以百万计的请求往线程池里面灌时,系统即便能处理得过来,其中的切换损耗也是相当可观的。
Project Loom 项目的目标是让 Java 支持额外的N:M 线程模型[46],实际上是将
JVM 线程与 OS 线程解耦。Loom项目新增加一种用户态的“虚拟线程”(Virtual Thread)[47],本质上它是一种有栈协程(Stackful
Coroutine)[48],多条虚拟线程可以映射到同一条物理线程之中。
在此之前,Java中已经有一些三方的实现支持协程,比如Quasar[49]和Coroutines[50],貌似都是需要挂载agent利用字节码注入的方式实现,我没有细看,有兴趣的可以了解下。
虚拟线程并不是万能的,虽然可以显著提高应用程序吞吐量,但也有前提:
并发任务的数量很高(超过几千个)
工作负载不受 CPU 限制,换句话说是I/O密集型的任务。如果是计算密集型任务,拥有比处理器内核多得多的线程并不能提高吞吐量
举个例子,假设有这样一个场景,需要同时启动10000个任务做一些事情:
// 创建一个虚拟线程的Executor,该Executor每执行一个任务就会创建一个新的虚拟线程
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
doSomething();
return i;
});
});
} // executor.close() is called implicitly, and waits
|
如果doSomething()里执行的是某类I/O操作,那么使用虚拟线程是非常合适的,因为虚拟线程创建和切换的代价很低,底层对应的可能只需要几个OS线程。如果没有虚拟线程,使用线程的话可能要这样写了:
把Executors.newVirtualThreadPerTaskExecutor()换成Executors.newCachedThreadPool()。结果是程序会崩溃,因为大多数操作系统和硬件不支持这种规模的线程数。
换成Executors.newFixedThreadPool(200)或者其他自定义的线程池,那这10000个任务将会共享200个线程,许多任务将按顺序运行而不是同时运行,并且程序需要很长时间才能完成。
如果doSomething()里执行的是某类计算任务,例如给一个大数组排序,那么虚拟线程还是平台线程都无济于事。JEP中提到了很关键的一点就是:虚拟线程不是更快的线程—它们运行代码的速度并不比平台线程快。它们的存在是为了提供scale(更高的吞吐量),而不是speed(更低的延迟)。
虚拟线程的提案[51]目前还是Preview状态,因此我们还无从知晓其最终形态,也许可以确定的几点:
虚拟线程会保持原有统一线程模型的交互方式,通俗地说就是原有的 Thread、Executor、Future、ForkJoinPool
等多线程工具都应该能以同样的方式支持新的虚拟线程。使用虚拟线程的代码可能长这样:
// 直接创建一个虚拟线程
Thread thread = Thread.ofVirtual().start(()
-> System.out.println("Hello"));
// 通过builder创建一个虚拟线程
Thread virtualThread = Thread.builder().virtual().task(()
-> {
System.out.println("Fiber Thread: "
+ Thread.currentThread().getName());
}).start();
// 创建一个基于虚拟线程的ExecutorService
ExecutorService executor = Executors.newVirtualThreadExecutor()
|
虚拟线程既便宜又量大管饱,因此永远不应该被池化。大多数虚拟线程将是短暂的并且具有浅层调用栈,执行的任务像是单个
HTTP 客户端调用或单个 JDBC 查询这样的I/O操作。相比之下,线程是重量级且昂贵的,因此通常必须被池化。
JDK的虚拟线程调度会借助ForkJoinPool[52],以 FIFO 模式运行。
值类型
在Java架构师Brian Goetz的演讲[53]中讲到,Project Valhalla的目标是"reboot
the layout of data in memory"。他提到Java的一些设计在刚开始是完全OK的,但过去25年中硬件发生了很大变化:
内存延迟与处理器执行性能之间的冯诺依曼瓶颈[54](Von Neumann Bottleneck)增加了100-2000倍(也就是说,如果以CPU算术计算的速度为基准看,读内存的速度没有变快反而更慢了);
指针的间接获取对性能的影响变得更大,因为对指针的解引用是昂贵的操作,尤其是当指针或它指向的对象不在处理器的缓存中时(没办法,只能读内存了);
Java是一门重指针("pointery")的语言,除了基本类型,可以说“一切皆为对象”,每个对象都有其对象标识符[55](Object
Identity)。面向对象的内存布局中,对象标识符存在的目的是为了允许在不暴露对象结构的前提下,依然可以引用其属性与行为,是Java实现多态性、可变性、锁等一系列功能的基础。尴尬的是,不管你需不需要什么多态、可变性、锁,对象标识符就在那里,也就是演讲中说的:Not
all objects need that! But all objects pay for it。
Java通过对象标识符进行链式访问,与之相对的是集中访问模式,例如C/C++中的struct会将对象在内存中拍平。两者的关键区别在于,链式访问需要读多次内存才能命中,而集中访问一次就可以将相关数据全部取出。打个比方,类A中包含类B,类B中包含类C,从A->B->C,链式访问在最坏情况下要读3次内存;而集中访问只需要读一次。
以一个常见的Point类为例:
final class Point {
final int x;
final int y;
}
|
一个Point对象数组在内存中的布局是长这样的:
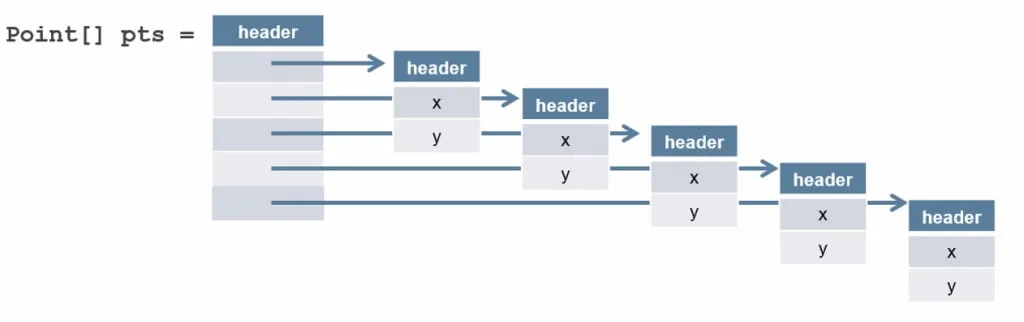
为了提升性能,有的小伙伴可能会用“曲线救国”的方法,把Point[] pts变成两个int数组int[]
xs和int[] ys,这就成"Good Code"和"Performace
Code"的两难选择了。
Valhalla引入的值类型有点向C#中的struct偷师的味道。值类型的想法是,像Point一类的对象,本质上是纯数据的聚合,只有数据,没有标识。没有标识意味着不再有多态性、可变性,不能在对象上加锁,不能为Null,只能基于状态做对象比较,但优势是:
值类型的内存布局可以像基础类型一样平坦紧凑,其他对象或数组在引用值类型时更简单;
同样也不需要object header了,可以省去内存占用和分配的开销;
甚至JVM可以在栈上直接分配值类型,而不必在堆上分配它们;
可以使用inline关键词定义一个值类型:
inline public class Point {
public int x;
public int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
|
值类型的内存布局长这样:

看上去值类型跟基础类型很像(某些小伙伴要说了,这跟我之前干的用两个int[]来代替Point[]的方式有什么区别?),不同之处在于可以将其看做一种可以快速访问的带限制的特殊对象,因此有对象的特征(Codes
like a class, works like an int),比如:
可以有变量+方法
可以继承接口,例如Point可以从某个Shape接口继承而来
可以通过封装来隐藏内部实现
可以作为泛型使用,可以有泛型参数
有了值类型的支持后,Valhalla的另一个JEP: Generics over Primitive
Types [56]就很自然了,Java 泛型中令人诟病的不支持原数据类型(Primitive Type)、频繁装箱等问题也能迎刃而解了。想象一下你只是需要一个数字列表,然后只能被定义成一个ArrayList<Integer>。对于API设计者,也不用再搞什么IntSteam<T>和ToIntFunction<T>了。
最后说一点,一个值类型看似简单,实际上创建一种新的数据类型需要对编译器、类文件结构和 JVM 都进行更改,还要支持现有的库,譬如Collections、Streams等。从14年到现在,Java
团队已经对六种同的解决方案进行了原型设计,值类型(value types)这一术语也被重命名为内联类(inline
classes),然后又变成原始类(primitive classes)。总之,耐心等待吧…
队友的助攻
Java最牛逼的是什么,是它的生态圈和圈里的队友们啊。我列了几个我觉得比较有代表性的。
GraalVM

Oracle在18年官宣了GraalVM[57]的1.0版本。虽然名字里带着VM,但实际上它既是
HotSpot 的新型 JIT 编译器[58],又可以用作AOT编译器,也是一个新的多语言虚拟机。GraalVM有3个关键的组件:
Graal - 用Java写的编译器,既可以作为 JIT 编译器取代C2在传统的OpenJDK JVM上运行,又可以当做AOT编译器使用。
Substrate VM - 是一个构建在Graal编译器之上的,支持AOT编译的运行框架。它的设计初衷是提供一个快速启动,低内存占用,以及能无缝衔接C代码(与JNI相比)的runtime,并能完美适配Truffle[59]语言实现。
Truffle - 即下图中的语言实现框架(Language Implementation Framework),用来支持多种语言跑在GraalVM上。

GraalVM算是近年来的明星Java项目,发展很快。这里我只做个简单的介绍,感兴趣的同学建议直接上官网[60]看官方文档。
Graal
我们熟知的HotSpot有两个JIT编译器,C1和C2。Java 程序首先在解释模式下启动,执行一段时间后,经常被调用的方法会被识别出来,并使用
JIT 编译器进行编译——先是使用 C1,如果 HotSpot 检测到这些方法有更多的调用,就使用
C2 重新编译这些方法。这种策略被称为“分层编译”,是 HotSpot 默认采用的方式。经过这么多年优化下来,C2编译后的代码效率非常出色,可以与
C++ 相媲美(甚至更快)。不过,近年来 C2 并没有带来多少重大的改进。不仅如此,C2 中的代码变得越来越难以维护和扩展,新加入的工程师很难修改使用
C++ 特定方言编写的代码。
Graal编译器的目标之一就是替代C2,因此这两者难免会拿来做比较。可以说最明显的区别就是Graal是用Java写的,C2则是C++。一种普遍的看法(来自Twitter
等公司和 Cliff Click 等专家)认为,C2在当前设计中不可能再进行重大改进,而Graal使用Java开发的一大优势在于可以很方便地将C2的新优化移植到Graal中,反之则不然,比如,在Graal中被证实有效的部分逃逸分析(partial
escape analysis)至今未被移植到C2中。
从我目前搜到的一些测试结果来看,总的来说Graal编译结果的性能与C2相比略优但相差不大。Graal在基于假设的优化手段上相对更激进,因此在某些场景下优势会更明显(比如这篇文章[61],再比如Twitter的报告[62]讲的Scala代码性能上Graal有10%的优势)。最关键的是,Graal还在不断演进中,未来可期。
Substrate VM
Substrate VM简单来说就是native image builder + SubstrateVM
Runtime,分别对应原生镜像(Native Image)[63]的build time和run
time。
native image builder:使用Graal编译器做静态编译的工具,它处理应用程序的所有类和依赖项(包括来自JDK的部分),通过指针分析(Points-To
Analysis)来确定在应用程序执行期间可以访问哪些类和方法,然后提前将可访问的代码和数据编译为特定操作系统和架构的可执行文件或者动态链接库。
SubstrateVM Runtime:一个特殊的精简过的VM Runtime,包括了deoptimizer、GC、线程调度等组件。因为已经做了AOT编译,比传统的Runtime少了类加载、解释器、JIT等组件。

官网放了一张图来展示Graal Native Image的两大优势:快速启动和低内存占用。不过我看到的其他一些资料上说在低时延和高吞吐(Latency/Throughput)场景下并不占优。

Substrate VM的限制其实就是前面说的AOT编译的限制,要求目标程序满足"closed-world"假设,即所有代码在编译器已知。如果不满足,那只能同时构建一个fallback
image了(使用传统JVM执行,需要JDK依赖)。一些限制条件可以通过在镜像构建时进行配置[64]来绕过,其中最关键的就是类的元数据(Metadata)相关的一些限制:
动态类加载:对于像Class.forName("myClass”)一类动态按照类名加载的操作,必须在配置文件里配上myClass,否则运行期就是一个ClassNotFoundException;
反射:构建时会通过检测对反射 API 的调用做静态分析,对于无法通过静态分析获知的,那也只能配置了;
动态代理:这里指的是使用了java.lang.reflect.Proxy API的动态代理。要求动态代理的接口列表在构建期就是已知的,构建时会简单地拦截对java.lang.reflect.Proxy.newProxyInstance(ClassLoader,
Class<?>[], InvocationHandler)和java.lang.reflect.Proxy.getProxyClass(ClassLoader,
Class<?>[])的调用来确定接口列表。同样,如果分析失败,那也只能配置了;
JNI:本机代码可以按名称访问 Java 对象、类、方法和字段,其方式类似于在 Java 代码中使用反射
API。一种替代的方式是可以考虑使用GraalVM提供的原生接口org.graalvm.nativeimage.c[65],更简单开销更低,缺点是不允许从
C 代码访问 Java 数据结构;
序列化:Java 序列化需要类的元数据信息才能起作用,因此也需要提前配置(不过,你的代码里还在用
Java 序列化吗?);
还有一些限制条件,像是invokedynamic字节码和Security Manager,是直接无法兼容的。还有一些功能跟HotSpot有区别,具体可以参考这篇文档[66]。
Truffle
Truffle是一个用Java写的语言实现框架,也可以说是一套通用语言设计的框架和API。除了像
Java、Scala、Groovy、Kotlin 等基于JVM的语言外,官方在此之上还支持了JavaScript[67]、Ruby[68]、R[69]、Python[70]、Sulong[71](LLVM-based
C/C++等),也就是说这些语言都可以“跑在”GraalVM上,号称"Run Programs
Faster Anywhere"。
完整的列表参考这里[72]。
这是我找到的一份17年的性能数据,可以看到除了C/C++和JS之外,GraalVM的性能优势还是挺大的,尤其是对于Ruby、R这类解释型语言。

Truffle提供了一套API,基于Truffle的语言实现仅需用Java实现词法分析、语法分析以及针对语法分析所生成的抽象语法树(AST)的解释器,理论上实现一个解释器要比开发一个优化的编译器要容易得多。Truffle将这些语言的源代码或源代码编译后的中间格式(例如,LLVM
字节码、Class 字节码)通过解释器转换为能被 GraalVM 接受的中间表示(Intermediate
Representation,IR),然后就可以使用Graal编译器对这些解释器进行优化,因此性能上有时候比传统编译器反而还有优势。
此外,Truffle的精华之处在于,运行时所有的解释器都通过同样的协议来互相操作不同编程语言中的对象,这就为所有生态系统下的库和模块都敞开了大门,你只需要选择最合适的语言去解决你要解决的问题就可以了,而不用为了项目所用的某个语言去专门实现一些缺少的模块。
这是一个官方的示例,展示了多语言如何直接进行交互:
const express = require('express')
const app = express()
const BigInteger = Java.type('java.math.BigInteger')
app.get('/', function (req, res) {
var text = 'Hello World from Graal.js!<br>
'
// Using Java standard library classes
text += BigInteger.valueOf(10).pow(100)
.add(BigInteger.valueOf(43)).toString() +
'<br>'
// Using R methods to return arrays
text += Polyglot.eval('R',
'ifelse(1 > 2, "no", paste(1:42,
c="|"))') + '<br>'
// Using R interoperability to create graphs
text += Polyglot.eval('R',
`svg();
require(lattice);
x <- 1:100
y <- sin(x/10)
z <- cos(x^1.3/(runif(1)*5+10))
print(cloud(x~y*z, main="cloud plot"))
grDevices:::svg.off()
`);
res.send(text)
})
app.listen(3001, function () {
console.log('Example app listening on port
3001!')
})
|
Spring是Java生态圈的绝对大佬,曾几何时,Spring也称得上一个轻量级框架(相比EJB?),然而现在看看,Spring的模块量级、启动速度、内存占用恐怕都谈不上多轻量了。Spring是一个动态性很强的框架,其核心的IoC和AOP功能大量使用了反射、动态字节码生成等技术,这与前面说的AOT编译的封闭世界假设是冲突的。所以尴尬的事情出现了,我想要使用AOT或者说GraalVM,但是第一个难题居然是代码中的Spring框架不支持…
基于此,社区中出现了spring-native[73]和spring-fu[74]这样的项目(目前都还是实验阶段),其中spring-native基本确定会在Spring
Framework 6和Spring Boot 3中直接集成。
关于spring-native,ATA上已经有大佬们做过比较深入的分析了,比如:让Spring启动提速95.5倍,项目解读之Spring-Graalvm-Native,也可以参考下官方的announcing-spring-native-beta[75]。
我理解Spring Native做的事情关键就是用 AOT 插件(Maven/Gradle)生成 GraalVM
的配置(反射、资源、动态代理、Native-Image选项):

从benchmark测试结果看,Spring Native的启动速度、镜像大小、内存占用与传统Spring
Boot相比有非常明显的提升,但峰值性能、构建时长等方面还处于劣势(同样的话好像说了好几次了?)
其他:Quarkus/Micronut/Helidon等等
近几年来,开源社区涌现了Quarkus[76]、Micronaut[77]、Helidon[78]等一批以提升
Java 在云原生环境下的适应性为卖点的微服务框架,从他们的slogan中可以提取到一些高频关键词:
Cloud Native
Container First
GraalVM
Reactive
Fast Boot And Low Memory Footprint
相比更常见的Spring Boot,这些新的框架天生对 GraalVM 有更好的适配,更轻量、启动更快、内存占用更低,非常适合容器化交付。虽然目前看起来尚显稚嫩,生态系统相比Spring还不算成熟,但就我个人而言,非常愿意在小的项目里使用这些框架。
其他的,像Apache、JBoss还有Eclipse等等社区,其实都很活跃,仍然充满活力。
未来?
捋完这么多,我发现对于Java的未来我还是充满迷茫。一方面,在新生语言的挑战下,Java似乎不可避免地慢慢变成一种“传统”,“老旧”,“经典”的语言;另一方面,Java和它的队友们一直在努力开创或者吸纳各种新特性、新功能,包括但不限于:
更具生产力的语法和API改进
以ZGC为代表的更先进的GC
在启动速度、内存占用等短板上的各种优化
以GraalVM为代表的新编译器+Native Image+多语言编程
更好的云原生支持
虽然很多特性短期内还不能落地,但道阻且长,行则将至。至少就目前看来,Java在传统的企业级和服务端应用领域构筑的堡垒还是牢不可破,再加上由强大生态所构建的护城河,留给Java的时间还有很多。
最后,作为一个Java开发者,很诚实地希望,在可见的未来,Java能一直流行下去。
| 






 订阅
订阅