| 编辑推荐: |
本文主要介绍写出高性能代码的三个方面:善用算法和数据结构、巧用数据特性
,优化内存回收(GC),
希望对您的学习有所帮助。
本文来自于CSDN,由火龙果软件Alice编辑、推荐。 |
|
(一)善用算法和数据结构
同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
“如何写出高性能代码”系列源自我在组内做的一次分享,本系列将以我个人之前的经验为基础,尝试帮助大家写出更高性能的代码 。原ppt分享的面有宽也比较浅薄,所以这里将原ppt拆分成5个独立的部分,分别成文,也作为对原ppt的扩展和补充,本文是第一篇——善用算法和数据结构。
荀子-劝学中说道:君子生非异也,善假于物也。其大意是君子的资质跟一般人没什么不同,只是善于借助外物罢了。 对于程序猿而已,我们在日常编码过程中,可能最常用的就是数据结构。现代各语言的开发库里基本上都封装好了各类的数据结构,我们基本不需要自己去实现。但错误地使用数据结构可能导致代码性能出现大幅的下降。
这里我举三个Java中因未考虑到底层实现导致性能损耗的示例。

上面这段代码本身功能上没有任何问题,但Java中ArrayList在添加过程中在容量不足时会触发扩容,扩容的过程会额外消耗CPU资源。但我在上述代码中指定了ArrayList的初始化容量为100后,用JMH压测发现有了33%的性能提升。
在Java中,很多容器都有动态扩容的特性,而扩容的过程涉及到内存的拷贝,很消耗性能。 所以建议如果能预知到数据量大小,在容器初始化的时候给定一个初始容量。这点在现在很多公司的编码规范中也明确提出了,如下图来自阿里巴巴Java开发手册。

再来看一个错误使用LinkedList导致的性能问题。

// jdk LinkedList中的get(int index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
// 这里会从前到后遍历链表
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
|
LinkedList并不受动态扩容的影响,但是它的底层实现是用的链表,而链表最大的问题在于不支持随机遍历,所以LinkedList中get(int index)的底层实现是用了遍历,时间复杂度是O(n),而ArrayList的底层实现是数组,它的get时间复杂度是O(1)。在上述代码中我将LinkedList改成ArrayList后压测确实也得到了十倍以上的性能提升。

在Java中,Set和List都提供了contains()方法,其作用就是校验某个在是否存在于这个集合中,但其contains实现方法完全不一样。在HashSet中,contains直接是从hash表中查找,其时间复杂度只有O(1)。而在ArrayList和LinkedList中,都是需要遍历一次全量数据才能得出结果,时间复杂度是O(n),代码这里就不再赘述,具体可以自行查阅。
在我实际测试是,Set和List的contains性能差异确实也非常明显。我用JMH测试发现,当有100个元素时,HashSet.contains的性能是ArrayList的10倍,是LinkedList的20倍,当数据量更大时,这个差异会更明显。
以上3个错误的示例其实在我们日常代码中经常会遇到,或许你现在去翻阅下项目代码,很容易就能找到List和Set使用不当之处。 也许你会反驳,JDK中这些Api的性能都极高,而且这部分也只是业务逻辑中非常非常小的一部分,错误得使用可能只会导致整体百分之一甚至千分之一的差异,但是不积跬步无以至千里,不积小流无以成江河。
下图是各种常用数据结构各种操作的时间、空间复杂度供大家查阅:
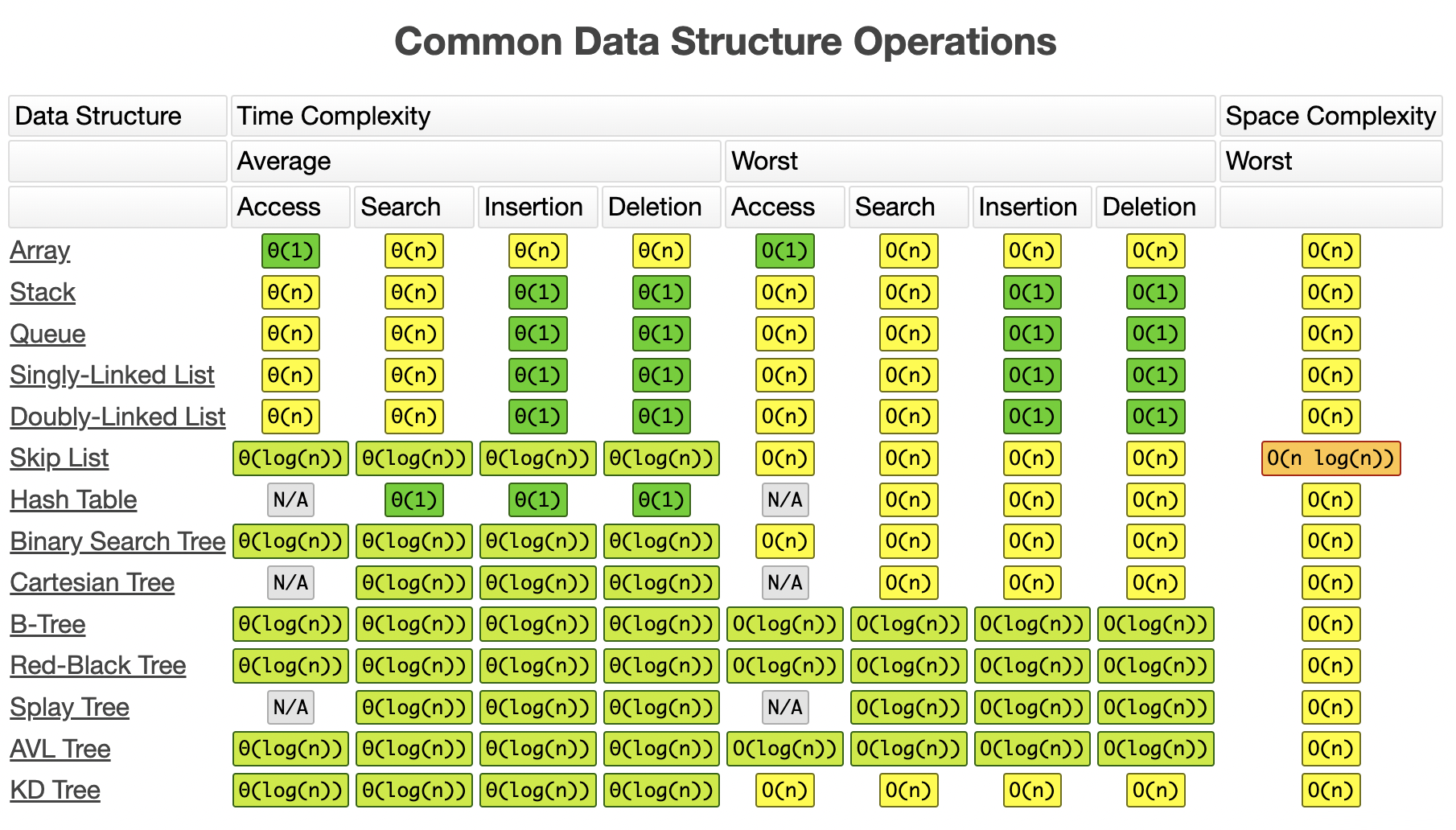
算法和数据结构是一个程序员的根基,虽然日常我们很少自己去实现某种具体的算法或数据结构,但我们却无时无刻不在使用各种已被封装好的算法或数据结构,我们应当做到对各种算法和数据结构烂熟于心,包括其时间复杂度、空间复杂度、适用范围。
(二)巧用数据特性 导语
同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员 不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
本文是《如何写出高性能代码》系列的第二篇,本文将告诉你如何利用数据的几个特性以达到提升代码性能的目的。
可复用性
我们在代码中所用到的大部分数据,都是可以被重复使用的,这种能被重复使用的数据就不要去反复去获取或者初始化了,举个例子:

上图中在for循环中调用了getSomeThing()函数,而这个函数实际和循环无关,它是可以放在循环外,其结果也是可以复用的,上面代码放在循环内白白多调用了99次,这里如果getSomeThing()是个非常耗时或者耗CPU的函数,性能将会查近百倍。

在Java代码中,我们很常用的枚举类,大部分的枚举类可能经常有获取所有枚举信息的接口,大部分人可能写出来的代码像上面的getList()这样。然而这种写法虽然功能上没啥问题,但每调用一次就会生成一个新的List,如果调用频次很高就会对性能产生显著的影响。正确的做法应该静态初始化生成一个不可变的list,之后直接复用就行。
温馨提示:这里我特意标注了一个不可变,在对象复用的情况下需要额外关注下是否有地方会改变对象内容,如果对象需要被改变就不能复用了,可以deepcopy之后再更改。当然如果这个对象生来就是会被改变的,就没必要复用了。
非必要性
非必要性的意思是有些数据可能没必要去做初始化。举个简单的例子:

在上面代码中sth对象被获取后,才校验了参数的合法性,事实上如果参数是不合法的,sth就没必要初始化了,这里sth就具备了非必要性。类似上面这种代码其实很常见,我在我们公司代码库中就遇到了很多次,基本的模式都是先获取了某些数据,但在之后有些过滤或者检查的逻辑导致代码跳出,然后这些数据就完全没有用上。
应对非必要性的一个解决方案就是延迟初始化,有些地方也叫 懒加载 或者 惰性加载,像上面代码中只需要把getSomeThing()移动到参数校验的后面,就可以避免这个性能问题了。像Java中我们在用的checkstyle插件,就提供了一个VariableDeclarationUsageDistance 的规则,这个规则的作用强制让代码的声明和使用不会间隔太多行,从而避免出现上述这种声明但未使用导致的性能问题。
事实上,延迟初始化是一个非常常用的机制,比如著名的copy on write其实就是延迟初始化的典范。另外像Jdk中很多集合基本也都是延迟初始化的,就拿HashMap为例,你在执行new HashMap()时,只是创建了一个空壳对象,只有第一次调用put()方法时整个map才会初始化。
// new HashMap()只是初始化出来一个空壳hashmap
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 第一次put触发内部真正的初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 省略其它代码
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
局部性
局部性也是老生常谈的特性了,局部性有好多种,数据局部性、空间局部性、时间局部性……可以说就是因为局部性的存在,世界才能更高效地运行。更多关于局部性的内容,可以参考下我之前写的一篇文章局部性原理——各类优化的基石。
这里先说下数据局部性,在大多数情况下,只有少量的数据是会被频繁访问的,俗称热点数据。处理热点数据最简单的方法就是给它加缓存加分片,具体方案就得看具体问题了。我来举个在互联网公司很常见的例子,很多业务数据都是存在数据库中,然而数据库在面对超大量的请求就有点力不从心了,因为局部性的存在,只有少量的数据是被频繁访问的,我们可以将这部分数据缓存在Redis中,从而减少对数据库的压力。
另外说个大家比较容易忽略的一点,代码局部性。系统中只有少量的代码是被反复执行的,而且如果系统有性能问题,也是少量的代码导致的,所以只要找出并优化好这部分代码,系统性能就能显著提升。依赖一些性能分析工具,比如用arthas火焰图就能很容易找到这部分代码(其他工具会在本系列第五篇文章中介绍)。
多读少写
除了局部性外,数据还有另外一个非常显著的特性,就是多读少写。这个也很符合大家的直觉和习惯,比如大部分人都是看文章而不是写文章,你到如何网站上也都是看的多,改的少,这是一条几乎放之四海而皆准的规律。 那这个特性对我们写代码有什么意义? 这个特性意味着大概率你的代码局部性就产生在读数据的代码上,额外关注下这部分代码。
当然也不是说写数据不重要,这里就不得不说到多读少写的另外一个特点了,那就是写的成本远高于读的成本,而且写的重要性也远高于读的重要性。 重要性不言而喻,去银行只是看不到余额可以接受,但取不了钱那肯定就是不行了。 那为什么写数据的成本会远高于读数据的成本呢? 简单可以这么理解,由于数据局部性的加持,很多读都可以通过各种手段来优化,而写就不大行,而且写可能会产生很多额外的副作用,需要添加很多校验之类的逻辑避免不必要的副作用。
(三)优化内存回收(GC)
导语
同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员 不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
本文是《如何写出高性能代码》系列的第三篇,本文将告诉你如何写出GC更优的代码,以达到提升代码性能的目的
优化内存回收
垃圾回收GC(Garbage Collection)是现在高级编程语言内存回收的主要手段,也是高级语言所必备的特性,比如大家所熟知的Java、python、go都是自带GC的,甚至是连C++ 也开始有了GC的影子。GC可以自动清理掉那些不用的垃圾对象,释放内存空间,这个特性对新手程序猿极其友好,反观没有GC机制的语言,比如C++,程序猿需要自己去管理和释放内存,很容易出现内存泄露的bug,这也是C++的上手难度远高于很多语言的原因之一。
GC的出现降低了编程语言上手的难度,但是过度依赖于GC也会影响你程序的性能。这里就不得不提到一个臭名昭著的词——STW(stop the world) ,它的含义就是应用进程暂停所有的工作,把时间都让出来让给GC线程去清理垃圾。别小看这个STW,如果时间过长,会明显影响到用户体验。像我之前从事的广告业务,有研究表明广告系统响应时间越长,广告点击量越低,也就意味着挣到的钱越少。
GC还有个关键的性能指标——吞吐率(Throughput),它的定义是运行用户代码的时间占总CPU运行时间的比例。举个例子,假设吞吐率是60%,意味着有60%的CPU时间是运行用户代码的,而剩下的40%的CPU时间是被GC占用。从其定义来看,当然是吞吐率越高越好,那么如何提升应用的GC吞吐率呢? 这里我总结了三条。
减少对象数量
这个很好理解了,产生的垃圾对象越少,需要的GC次数也就越少。那如何能减少对象的数量?这就不得不回顾下我们在上一讲巧用数据特性 中提到的两个特性——可复用性和非必要性,忘记的同学可以再点开上面的链接回顾下。这里再大概讲下这两个特性是如何减少对象生成的。
可复用性
可复用性在这里指的是,大多数的对象都是可以被复用的,这些可以被复用的对象就没必要每次都新建出来,浪费内存空间了。 处了巧用数据特性 中的例子,我这里再个Java中已经被用到的例子,这个还得从一段奇怪的代码说起。
Integer i1 = Integer.valueOf(111);
Integer i2 = Integer.valueOf(111);
System.out.println(i1 == i2);
Integer i3 = Integer.valueOf(222);
Integer i4 = Integer.valueOf(222);
System.out.println(i3 == i4);
|
上面这段代码的输出结果会是啥呢?你以为是true+true,实际上是true+false。 What?? Java中222不等于222,难道是有Bug? 其实这是新手在比较数值大小时常犯的一个错误,包装类型间的相等判断应该用equals而不是’’,'’只会判断这两个对象是否是同一个对象,而不是对象中包的具体值是否相等。
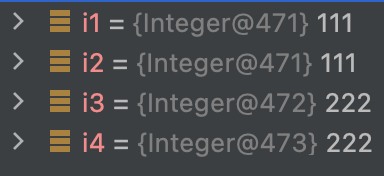
像1、2、3、4……等一批数字,在任何场景下都是非常常用的,如果每次使用都新建个对象很是浪费,Java的开发者也考虑到了这点,所以在Jdk中提取缓存了一批整数的对象(-128到127),这些数字每次都可以直接拿过来用,而不是新建一个对象出来。而在-128到127范围外的数字,每次都会是新对象,下面是Integer.valueOf()的源码及注释:
/**
* Returns an {@code Integer} instance representing the specified
* {@code int} value. If a new {@code Integer} instance is not
* required, this method should generally be used in preference to
* the constructor {@link #Integer(int)}, as this method is likely
* to yield significantly better space and time performance by
* caching frequently requested values.
*
* This method will always cache values in the range -128 to 127,
* inclusive, and may cache other values outside of this range.
*
* @param i an {@code int} value.
* @return an {@code Integer} instance representing {@code i}.
* @since 1.5
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
|
我在Idea中通过Debug看到了i1-i4几个对象,其实111的两个对象确实是同一个,而222的两个对象确实不同,这就解释了上面代码中的诡异现象。
非必要性
非必要性的意思是有些对象可能没必要生成。这里我举个例子,可能类似下面这种代码,在业务系统中会很常见。
private List<UserInfo> getUserInfos(List<String> ids) {
List<UserInfo> res = new ArrayList<>(ids.size());
if (ids == null || res.size() == 0) {
return new Collections.emptyList();
}
List<UserInfo> validUsers = ids.stream()
.filter(id -> isValid(id))
.map(id -> getUserInfos(id))
.filter(Objects::nonNull)
.collect(Collectors.toList());
res.addAll(validUsers);
return res;
}
|
上面代码非常简单,就是通过一批用户Id去获取出来完整的用户信息,获取前要对入参做校验,之后还会对id做合法性校验。 上面代码的问题是 res对象初始化太早了,如果一个UserInfo没查到,res对象就白初始化了。另外,最后直接返回validUsers是不是就行了,没必要再装到res中,这里res就具备了非必要性。
像上述这种情况,可能在很多业务系统里随处可见(但不一定这么直观),提前初始化一些之后没用的对象,除了浪费内存和CPU之外,也会给GC增加负担。
缩小对象体积
缩小体积对象也很好理解,如果对象在单位时间内生成的对象数量固定,但体积减小后,同样大小的内存就能装载更多的对象,更晚才触发GC,GC的频次就会降低,频次低了自然对性能的影响就会变小。
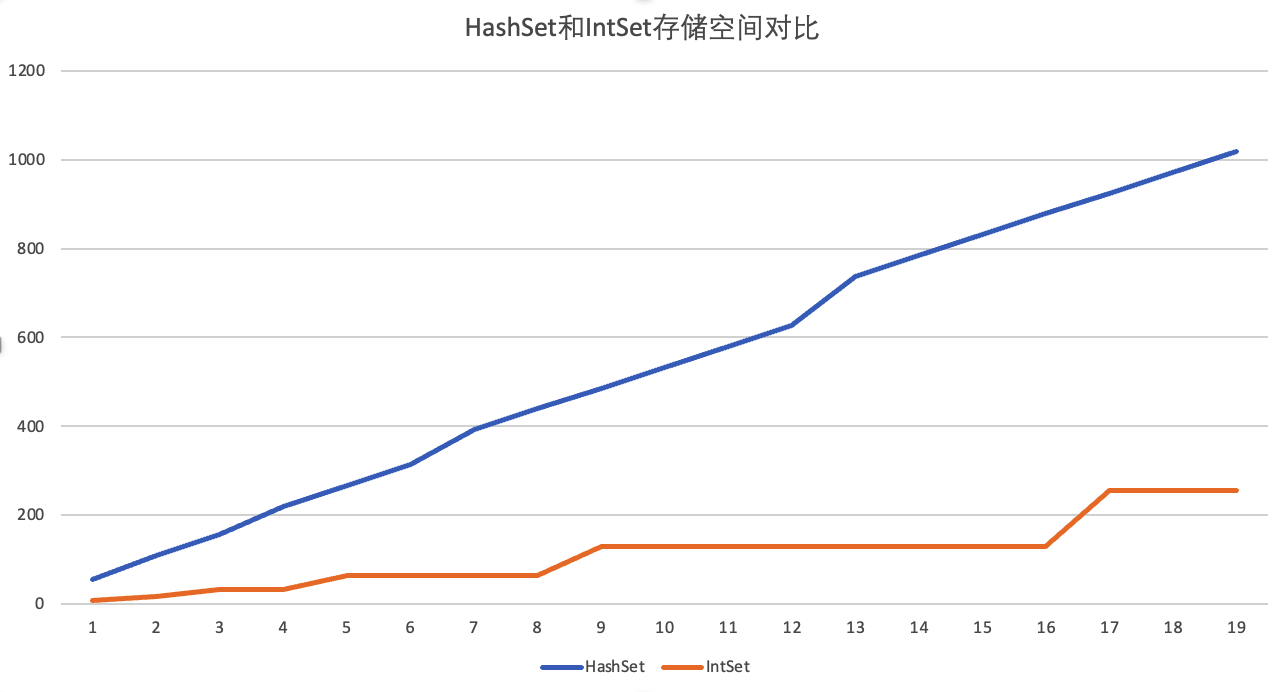
关于减少对象体积,这里我给大家推荐一个jar包——eclipse-collections,其中提供了好多原始类型的集合,比如IntMap、LongMap…… 使用原始类型(int,long,double……)而不是封装类型(Integer,Long,Double……),在一些数值偏多的业务中很有优势,如下图是我对比了HashSet和eclipse-collections中IntSet在不同数据量下的内存占用对比,IntSet的内存占用只有HashSet的四分之一。
另外,咱在写业务代码的时候,写一些DO、BO、DTO的时候没必要的字段就别加进去了。查数据库的时候,不用的字段也就别查出来了。我之前看到过很多业务代码,查数据库的时候把整行都查出来了,比如我要查一个用户的年龄,结果把他的姓名、地址、生日、电话号码…… 全查出来,这些信息放在Java里面需要一个个的对象去存储的,没有用到部分字段首先就是白取了,其实存它还浪费内存空间。
缩短对象存活时间
为什么减少对象的存活时间就能提升GC的性能?总的垃圾对象并没有减少啊! 是的 没错,单纯缩短对象的存活时间并不会减少垃圾对象的数量,而是会减少GC的次数。要理解这个就得先知道GC的触发机制,像Java中当堆空间使用率超过某个阈值后就会触发GC,如果能缩短对象的时间,那每次GC就能释放出来更多的空间,下次GC也就会来的更迟一些,总体上GC次数就会减少。
这里我举个我自己经历的真实案例,我们之前系统有个接口,仅仅是调整了两行代码的顺序,这个接口的性能就提升了40%,这个整个服务的CPU使用率降低了10%+,而这两行顺序的改动,缩短了大部分对象的生命周期,所以导致了性能提升。
private List<Object> filterTest() {
List<Object> list = getSomeList();
List<Object> res = list
.stream()
.filter(x -> filter1(x)) // filter1需要调用外部接口做过滤判断,性能低且过滤比例很少
.filter(x -> filter2(x))
.filter(x -> filter3(x)) // filter3 本地数值校验,不依赖外部,效率高且过滤比例高
.collect(Collectors.toList());
}
|
上面代码中,filter1性能很低但过滤比低,filter3恰恰相反,往往没被filter1过滤的会被filter3过滤,做了很多无用功。这里只需要将filter1和filter3互换下位置,除了减少无用功之外,List中的大部分对象生命周期也会缩短。
其实有个比较好的编程习惯,也可以减少对象的存活时间。其实在本系列的第篇中我也大概提到过,那就是缩小变量的作用域。能用局部变量就用局部变量,能放if或者for里面就放里面,因为编程语言作用域实现就是用的栈,作用域越小就越快出栈,其中使用到的对象就越快被判断为死对象。
除了上述三种优化GC的方式话,其实还有种骚操作,但是我本人不推荐使用,那就是——堆外内存
堆外内存
在Java中,只有堆内内存才会受GC收集器管理,所以你要不被GC影响性能,最直接的方式就是使用堆外内存,Java中也提供了堆外内存使用的API。但是,堆外内存也是把双刃剑,你要用就得做好完善的管理措施,否则内存泄露导致OOM就GG了,所以不推荐直接使用。但是,凡事总有但是,有一些优秀开源代码,比如缓存框架ehcache就可以让你安全的享受到堆外内存的好处,具体使用方式可以查阅官网,这里不再赘述。
好了,今天的分享就到这里了,看完你可能会发现今天的内容和上一讲 (二)巧用数据特性有一些重复的内容,没错,我理解性能优化底层都是同一套方法论,很多新方法只是以不同的视角在不同领域所衍生出来的。最后感谢下大家的支持,希望你看完文章有所收获。另外有兴趣的话也可以关注下本系列的前两篇文章。
| 






 订阅
订阅