| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫМЧТМЪЙгУspring
batchзіЪ§ОнЧЈвЦЪБЪБгіЕНЕФвЛИіЙиМќЮЪЬтЃКЪ§ОнЧЈвЦСПДѓЪБШчКЮБЃжЄФкДцЕШЯрЙиФкШнЁЃ
БОЮФРДздгк CSDN ЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ИХЪі
БОЦЊВЉПЭЪЧМЧТМЪЙгУspring batchзіЪ§ОнЧЈвЦЪБЪБгіЕНЕФвЛИіЙиМќЮЪЬтЃКЪ§ОнЧЈвЦСПДѓЪБШчКЮБЃжЄФкДцЁЃЕБЮвУЧдкЪЙгУspring
batchЪБЃЌЮвУЧБиаыХфжУШ§ИіЖЋЮї: readerЃЌprocessorЃЌКЭwriterЁЃЦфжаЃЌreaderгУгкДгЪ§ОнПтжаЖСЪ§ОнЃЌЕБЪ§ОнСПНЯаЁЪБЃЌreaderЕФТпМВЛЛсЖдФкДцДјРДЬЋЖрбЙСІЃЌЕЋЪЧЕБЮвУЧвЊШЅЖСЕФЪ§ОнСПЗЧГЃДѓЕФЪБКђЃЌЮвУЧОЭВЛЕУВЛПМТЧФкДцЕШЗНУцЕФЮЪЬтЃЌвђЮЊШєЪ§ОнСПЗЧГЃДѓЃЌФкДцЃЌжДааЪБМфЕШЕШЖМЛсЪмЕНгАЯьЁЃЙигкspring
batchЕФЛљДЁжЊЪЖКЭНщЩмЧыВЮПМетЦЊВЉПЭЃК ХњДІРэПђМмspring batchНщЩмМАЪЙгУЁЃ
ЮЪЬтЪЧЪВУД
дкЩЯУцЕФФкШнЕБжаЮвУЧвбОЬсЕНСЫ,ЮвУЧУцСйЕФЮЪЬтЪЧЪ§ОнЧЈвЦСПДѓЪБЕФФкДцЮЪЬтЁЃЕЋЪЧетбљЕФУшЪіЗЧГЃС§ЭГЃЌвђДЫВЉжїОіЖЈНЋетвЛВПЗжЕЅЖРСрГіРДЫЕЁЃ
дкбЇЯАСЫspring batchЕФжЊЪЖжЎКѓЮвУЧгІИУКмЧхГўЕФвЛЕуЪЧЃЌУПвЛИіspring batchЕФstepЖМАќКЌШчЯТЕФВПЗж:

МДЖСЪ§ОнЃЌДІРэЪ§ОнЃЌаДЪ§ОнЁЃетШ§ИіВНжшРяУцзюПЩФмЛсЕМжТФкДцБфДѓЮЪЬтЕФЮовЩЪЧЖСЪ§ОнЛЗНкЁЃЖСЪ§ОнзїЮЊspring
batchЕФЪ§ОнЪфШыЃЌЪЧећИіspring batch jobЕФПЊЭЗТпМЁЃ
ШєЮвУЧЕФЪ§ОнСПВЛДѓЃЌШчжЛгаМИЪЎЭђЬѕЃЌФЧЮвУЧЮовЩВЛЛсУцСйФкДцЮЪЬтЃЌМДБувЛДЮНЋЫљгаЪ§ОнМгдиЕНФкДцЕБжаЃЌеМЕФФкДцвВВЛЛсЗЧГЃЖрЃЌЧвspring
batchЪ§ОнЧЈвЦЕФЫйЖШЗЧГЃжЎПьЃЌМИЪЎЭђЬѕЕФЪ§ОнЭљЭљЪЧМИЪЎУыЕФЪБМфОЭПЩвдЧЈвЦЭъГЩЁЃЕЋЪЧЕБЪ§ОнСПБфДѓжЎКѓЃЌЮЪЬтОЭВЛвЛбљСЫЁЃЕБЮвУЧЕФЪ§ОнСПДяЕНЪ§АйЭђЛђЩЯЧЇЭђЪБЃЌШєвЛДЮадНЋЫљгаЪ§ОнШЋВПЖСЕНФкДцЕБжаЃЌдђЛсеМОндЖдЖГЌГіе§ГЃЗЖЮЇЕФЗЧГЃДѓЕФФкДцЁЃИУЮЪЬтЪОвтЭМШчЯТЫљЪО:
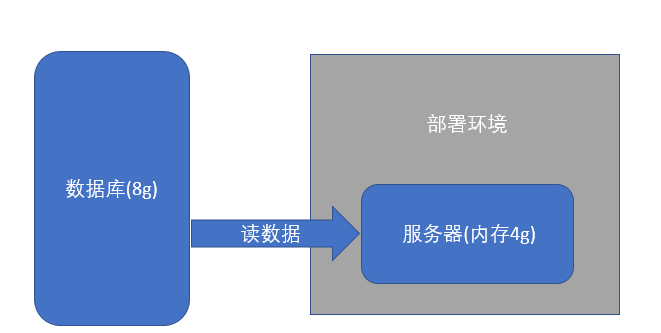
ЮвУЧаДЕФШЮКЮГЬађЖМЛсгавЛИідЫааФкДц,МйЩшетИіФкДцЕФзмШнСПЯждкжЛга4gЃЌЖјЮвУЧЪ§ОнПтРяашвЊВйзїЕФЪ§Онга8gЃЌФЧУДЮовЩЃЌвЛДЮадЕФНЋЪ§ОнЖСГіРДОЭЛсГіДэЁЃетБуЪЧашвЊПМТЧЕУЮЪЬтЁЃ
SpringЬсЙЉЕФreaderЪЕЯж
springЬсЙЉСЫЗЧГЃЗсИЛЕФReaderЪЕЯжЃЌЦфжаБШНЯГЃгУЕФДгЪ§ОнПтЖСЪ§ОнЕФгаJdbcCursorItemReader,JdbcPagingItemReaderЕШЁЃ
JdbcCursorItemReader
ЪЙгУJdbcCursorItemReaderЕФЪОР§ДњТыШчЯТЃК
@Bean
public JdbcCursorItemReader<CustomerCredit>
itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}
|
JdbcCursorItemReaderЕФКУДІдкгкЪЙгУМђЕЅЃЌЕЋЪЧЮвУЧДгЫќЕФsqlОЭФмЗЂЯжЃЌJdbcCursorItemReaderЛсвЛДЮАбЫљгаЕФЪ§ОнШЋВПФУЛиРДЃЌЕБЪ§ОнСПЙ§ДѓЖјЗўЮёЦїФкДцВЛЙЛЪБЃЌОЭЛсгіЕНЯТУцЮоЗЈЗжХфФкДцЕФЮЪЬтЃК

БЈДэаХЯЂЮЊ:Resource exhaustion event:The
JVM was unable to allocate memory from the heap. втЫМОЭЪЧашвЊЗжХфФкДцЕФЪ§ОнЬЋЖрЃЌЕЋЪЧЮоЗЈевЕНзуЙЛЕФФкДцСЫЁЃ
ЗДгГдкФкДцРяЃЌЖбФкДцЛсГЪЯжГіШчЯТЕФЧщПі:
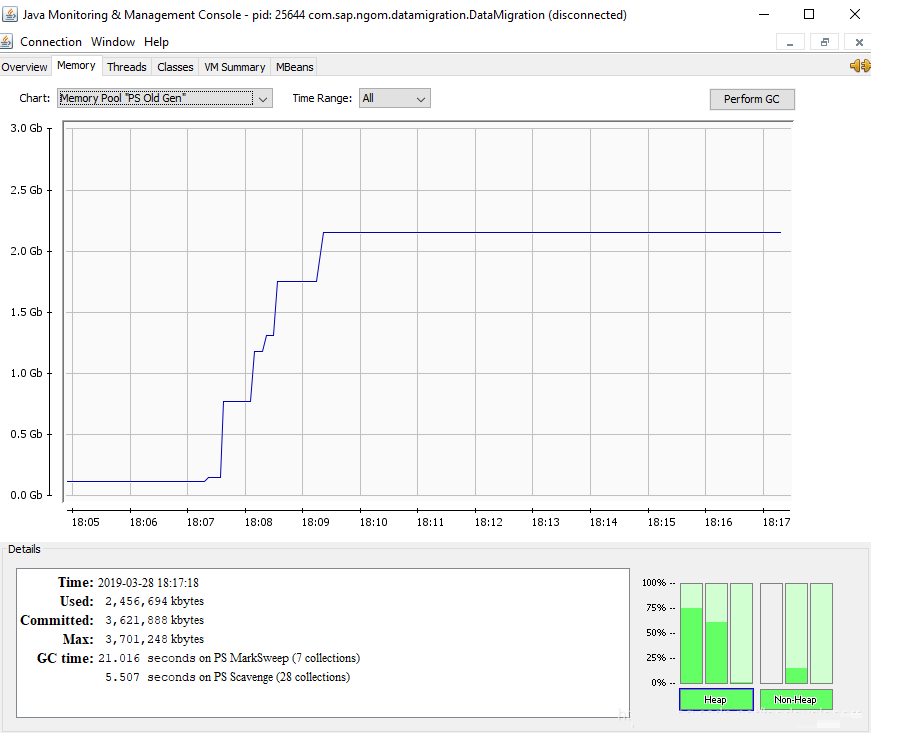
ЫцзХУПвЛДЮЪ§ОнЖСШыЃЌЖбФкДцЖМЛсдіДѓЃЌдвђОЭдкгкJdbcCursorItemReaderвЛДЮадЖСЛиСЫЫљгаЕФЪ§ОнЃЌЗЕЛижЎКѓОЭЛсДцдквЛИіЖдЯѓРяУцЃЌЖјетИіЖдЯѓЕФГпДчЙ§ДѓЃЌвђДЫжБНгНјШыСЫРЯФъДњЁЃдкЪ§ОнЧЈвЦЭъГЩжЎЧАЃЌетаЉЪ§ОнЖМВЛЛсБЛЛиЪеЁЃШчЯТЭМЫљЪО:

КСЮовЩЮЪЃЌЕБЮвУЧЕФЪ§ОнСПДѓЪБВЛгІИУЪЙгУетжжРраЭЕФreaderРДЖСШЁЪ§ОнЁЃ
JdbcPagingItemReader
JdbcPagingItemReaderЕФзїгУКЭЫќЕФУћзжвЛбљЃЌЫќПЩвдЗжвГЖСШЁЪ§ОнЃЌЕЋЪЧЪЙгУЦ№РДЯрБШгкJdbcCursorItemReaderИќМгИДдгЃЌЪОР§ДњТыШчЯТ:
@Bean
public JdbcPagingItemReader itemReader(DataSource
dataSource, PagingQueryProvider queryProvider)
{
Map<String, Object> parameterValues = new
HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider()
{
SqlPagingQueryProviderFactoryBean provider = new
SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name,
credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
}
|
ПЩвдПДЕНЮвУЧФмЙЛЩшжУpageЕФДѓаЁЃЌJdbcPagingItemReaderНЋИљОнетИівГЕФДѓаЁЃЌУПДЮЖСШЁетУДЖрЕФЪ§ОнЃЌвђДЫетаЉЪ§ОнЗЕЛиБЃДцЕФЖдЯѓЃЌОЭжЛЛсЪЧаЁЖдЯѓЃЌвђДЫЫћУЧВЛЛсжБНгдкРЯФъДњРяЗжХфЃЌЖјЪЧЯШЗжХфдкФъЧсДњЃЌЫцзХФъЧсДњВЛЖЯБфДѓЃЌminor
gcвВВЛЖЯНјааЃЌЛиЪеЕєвбОДІРэЭъЕФЪ§ОнЃЌРЯФъДњЕФФкДцЪЙгУСПВЛЛсгаШЮКЮдіДѓЃЌРрЫЦЯТЭМЃК
РЯФъДњФкДцВЛЛсгаШЮКЮБфЛЏЃЌФъЧсДјЛсЫцзХЗўЮёЦїЪ§ОнЧЈвЦНјааЖјдіДѓЭЌЪББЛЛиЪеЁЃ
дкЪЙгУJdbcPagingItemReaderЪБЃЌгавЛИіБиаызЂвтЕФЕиЗНОЭЪЧХХађЙиМќзжЪЧБиаыжИЖЈЕФЃЌдвђдкгкХХађЪЧЗжвГЪЕЯждРэЕФММЪѕЛљДЁЁЃsortKeyКЭЮвУЧжИЖЈЕФЦфЫћзжОфвЛЦ№ЙЙНЈГіSQLгяОфГіРДЁЃдкsortKeyЩЯБиаыЪЙгУunique
key constraintдМЪјЃЌвђЮЊжЛгаетбљВХФмЕУвдШЗБЃжДаажЎМфВЛЛсЖЊЪЇШЮКЮЪ§ОнЁЃетвВПЩвдЫЕЪЧJdbcCursorItemReaderЯрЖдБуРћЕФвЛЕугХЪЦЁЃ
змНс
Ъ§ОнСПаЁЪБбЁдёЕФЗНАИВюБ№ВЛЛсКмДѓЃЌЕБЪ§ОнСПДѓЪБЃЌЮЊСЫгаКУЕФФкДцБэЯждђЪЙгУЗжвГЕФreaderЪЧБивЊЕФЁЃЕЋЭЌЪБЃЌвђЮЊвЊЪЕЯжЗжвГЃЌвВЛсДјРДвЛаЉВЛПЩБмУтЕФЯожЦЁЃ
| 








