| БрМЭЦМі: |
| БОЮФДгЖЖвє
Java OOM ФкДцгХЛЏЕФжЮРэЪЕМљГіЗЂЃЌГЂЪдИјДѓМвЗжЯэвЛЯТЖЖвєЭХЖгЙигк Java
ФкДцгХЛЏжаЕФвЛаЉЫМПМЃЌАќРЈЙЄОпНЈЩшЁЂгХЛЏЗНЗЈТлЁЃ БОЮФРДздгкзжНкЬјЖЏММЪѕЭХЖгЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
ФкДцзїЮЊМЦЫуЛњГЬађдЫаазюживЊЕФзЪдДжЎвЛЃЌашвЊдЫааЙ§ГЬжазіЕНКЯРэЕФзЪдДЗжХфгыЛиЪеЃЌВЛКЯРэЕФФкДцеМгУЧсдђЪЙЕУгУЛЇгІгУГЬађдЫааПЈЖйЁЂANRЁЂКкЦСЃЌжидђЕМжТгУЛЇгІгУГЬађЗЂЩњ
OOMЃЈout of memoryЃЉБРРЃЁЃЖЖвєзїЮЊвЛПюгУЛЇЪЙгУЙуЗКЕФВњЦЗЃЌашвЊдкИїжжЛњЦїзЪдДЩЯБЃГжгХауЕФСїГЉадКЭЮШЖЈадЃЌФкДцгХЛЏЪЧБиаывЊжиЪгЕФЛЗНкЁЃ
ЖЖвє Java OOM БГОА
дкЮДЖдЖЖвєФкДцНјаазЈЯюжЮРэжЎЧАЮвУЧЪсРэСЫвЛЯТећЬхФкДцжИБъЕФОјЖджЕКЭЯрЖдБРРЃЃЌЗЂЯжеМБШЖМКмИпЁЃСэЭтЃЌФкДцЯрЙижИБъдкШЅФъДКНкЛюЖЏЪБгждйДЮМЄдіДяЕНРњЪЗаТИпЃЌЫљвдећЬхРДПДФкДцЮЪЬтЯрЕБбЯОўЃЌБиаывЊЖдЦфНјаазЈЯюжЮРэЁЃЖЖвєетБпЭЈЙ§ЧАЦкЙщвђЁЂЙЄОпНЈЩшвдМАЭЖШывЛИіЫЋдТЕФФкДцзЈЯюжЮРэНЋећЬх
Java OOM гХЛЏСЫАйЗжжЎ 80ЁЃ
Java OOM Top ЖбеЛЙщвђ
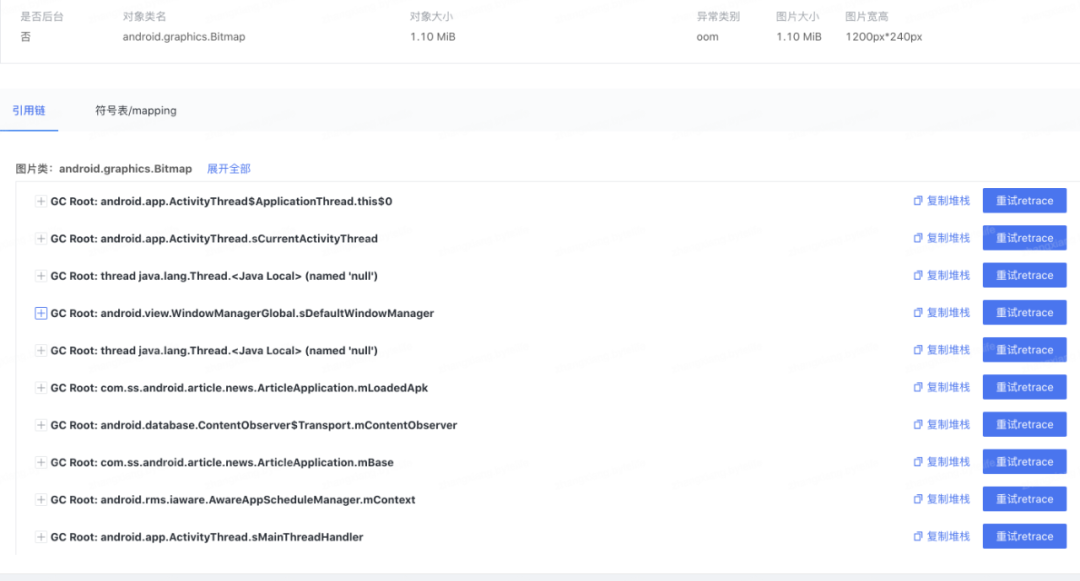
дкЖдЖЖвєЕФ Java ФкДцгХЛЏжЮРэжЎЧАЮвУЧЯШИљОнЦНЬЈЩЯБЈЕФЖбеЛвьГЃЖдЕБЧАЕФ OOM НјааЙщвђЃЌжївЊЗжЮЊЯТУцМИРрЃК
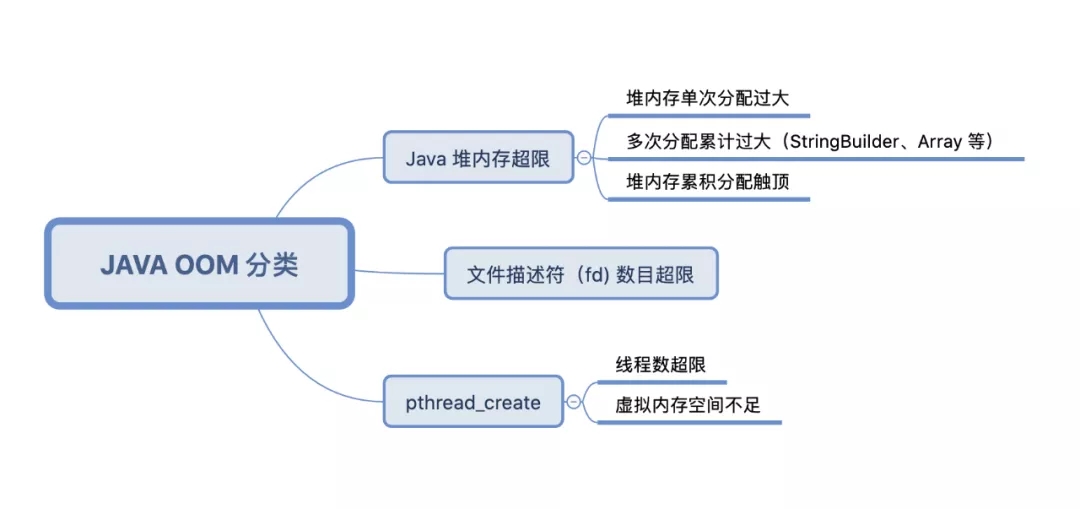
ЭМ 1. OOM ЗжРр
Цфжа pthread_create ЮЪЬтеМЕНСЫзмБШР§ДѓдМдкАйЗжжЎ 50ЃЌJava ЖбФкДцГЌЯоЮЊАйЗжжЎ
40 ЖрЃЌЪЃЯТЪЧЩйСПЕФ fd Ъ§СПГЌЯоЁЃЦфжа pthread_create КЭ fd Ъ§СПВЛзуОљЮЊ
native ФкДцЯожЦЕМжТЕФ Java ВуБРРЃЃЌЮвУЧЖдетВПЗжЕФФкДцЮЪЬтвВзіСЫеыЖдадгХЛЏЃЌжївЊАќРЈЃК
ЯпГЬЪеСВЁЂМрПи
ЯпГЬеЛаЙТЉздЖЏаоИД
FD аЙТЉМрПи
ащФтФкДцМрПиЁЂгХЛЏ
ЖЖвє 64 ЮЛзЈЯю
жЮРэжЎКѓ pthread_create ЮЪЬтНЕЕЭЕНСЫ 0.02ЁывдЯТЃЌетЗНУцЕФжЮРэЪЕМљЛсдкЯТвЛЦЊЖЖвє
Native ФкДцжЮРэЪЕМљжаЯъЯИНщЩмЃЌДѓМвОДЧыЦкД§ЁЃБОЮФжиЕуНщЩм Java ЖбФкДцжЮРэЁЃ
ЖбФкДцжЮРэЫМТЗ
Дг Java ЖбФкДцГЌЯоЕФЗжРрРДПДЃЌжївЊгаСНРрЮЪЬтЃК
1. ЖбФкДцЕЅДЮЗжХфЙ§Дѓ/ЖрДЮЗжХфРлМЦЙ§ДѓЁЃ
ДЅЗЂетРрЮЪЬтЕФдвђгаЪ§ОнвьГЃЕМжТЕЅДЮФкДцЗжХфЙ§ДѓГЌЯоЃЌвВгавЛаЉЪЧ StringBuilder ЦДНгРлМЦДѓаЁЙ§ДѓЕМжТЕШЕШЁЃетРрЮЪЬтЕФНтОіЫМТЗБШНЯМђЕЅЃЌЮЪЬтОЭдкЕБЧАЕФЖбеЛЁЃ
2. ЖбФкДцРлЛ§ЗжХфДЅЖЅЁЃ
етРрЮЪЬтЕФЮЪЬтЖбеЛЛсБШНЯЗжЩЂЃЌдкШЮКЮФкДцЗжХфЕФГЁОАЩЯЖМгаПЩФмЛсБЛДЅЗЂЃЌФЧаЉИпЦЕЕФФкДцЗжХфНкЕуЗЂЩњЕФИХТЪЛсИќИпЃЌБШШч
Bitmap ЗжХфФкДцЁЃетРр OOM ЕФИљБОдвђЪЧФкДцРлЛ§еМгУЙ§ЖрЃЌЖјЕБЧАЕФЖбеЛжЛЪЧбЙЫРТцЭеЕФзюКѓвЛИљЕОВнЃЌВЂВЛЪЧЮЪЬтЕФИљБОЫљдкЁЃЫљвдетРрЮЪЬтЮвУЧашвЊЗжЮіећЬхЕФФкДцЗжХфЧщПіЃЌДгжаевЕНВЛКЯРэЕФФкДцЪЙгУЃЈБШШчФкДцаЙТЖЁЂДѓЖдЯѓЁЂЙ§ЖраЁЖдЯѓЁЂДѓЭМЕШЃЉЁЃ
ЙЄОпНЈЩш
ЙЄОпЫМТЗ
ЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦїЁЃДгЩЯУцЕФФкДцжЮРэЫМТЗПДЃЌЙЄОпашвЊжївЊНтОіЕФЮЪЬтЪЧЗжЮіећЬхЕФФкДцЗжХфЧщПіЃЌЗЂЯжВЛКЯРэЕФФкДцЪЙгУЃЈБШШчФкДцаЙТЖЁЂДѓЖдЯѓЁЂЙ§ЖраЁЖдЯѓЕШЃЉЁЃ
ЮвУЧДгЯпЯТКЭЯпЩЯСНИіЮЌЖШРДНЈЩшЙЄОпЃК
ЯпЯТ
ЯпЯТЙЄОпЪЧзюЯШПМТЧЕФЃЌдкбаЗЂКЭВтЪдЕФЪБКђФмЙЛЬсЧАЗЂЯжФкДцаЙТЉЮЪЬтЁЃвЕНчЕФжїСїЙЄОпвВЪЧетИіЫМТЗЃЌБШШч
Android Studio Memory ProfilerЁЂLeakCanaryЁЂMemory Analyzer
(MAT)ЁЃ
ЮвУЧЛљгк LeakCanary КЫаФПтдкЯпЯТЩшМЦСЫвЛЬзздЖЏЗжЮіЩЯБЈФкДцаЙТЖЕФЙЄОпЃЌжївЊСїГЬШчЯТЃК
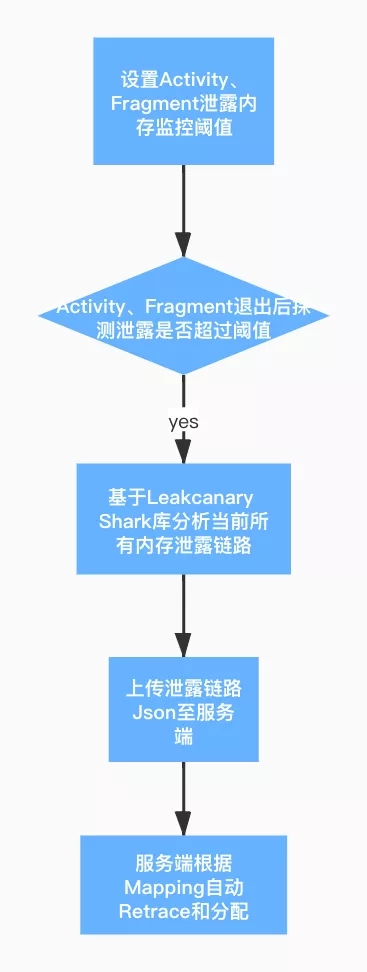
ЭМ 2.ЯпЯТздЖЏЗжЮіСїГЬ
ЖЖвєдкдЫааСЫвЛЖЮЯпЯТЕФФкДцаЙТЉЙЄОпжЎКѓЃЌЗЂЯжСЫЯпЯТЙЄОпЕФИїжжБзЖЫЃК
МьВтГіРДЕФФкДцаЙТЉЙ§ЖрЃЌВЂЧввВУЛгаБШНЯКУЕФгХЯШМЖХХађЃЌбаЗЂЯћЗбВЛЙ§РДЃЌРњЪЗЮЪЬтОЭвЛжБЖбЛ§ЁЃСэЭтвВКмФбКЭвЕЮёбаЗЂЙЕЭЈЮЪЬтНтОіЕФЪевцЃЌДѓМвеыЖдНтОіЯпЯТЕФФкДцаЙТЉЮЪЬтЕФ
ROIЃЈЭЖШыВњГіБШЃЉБШНЯФбЖдЦыЁЃ
ЯпЯТГЁОАФмХмЕНЕФГЁОАгаЯоЃЌКмФбАбЫљгагУЛЇГЁОАЧюОЁЁЃЖЖвєгУЛЇЛљЪ§КмДѓЃЌЮвУЧОГЃгіЕНвЛаЉЯпЩЯЕФ OOM
МЄдіЮЪЬтЃЌвђЮЊШБЩйЯпЩЯЪ§ОнЖјЮоДгВщЦ№ЁЃ
Android ЖЫЕФ HPORF ЕФЛёШЁвРРЕдЩњЕФ Debug.dumpHporfЃЌdump Й§ГЬЛсЙвЦ№жїЯпГЬЕМжТУїЯдПЈЖйЃЌЯпЯТЪЙгУЬхбщНЯВюЃЌОГЃЛсгабаЗЂЗДРЁгАЯьВтЪдЁЃ
LeakCanary Лљгк Shark ЗжЮів§ЧцЗжЮіЃЌЗжЮіЫйЖШНЯТ§ЃЌЭЈГЃдк 5 ЗжжгвдЩЯВХФмЗжЮіЭъГЩЃЌЗжЮіЙ§ГЬЛсгАЯьНјГЬФкДцеМгУЁЃ
ЗжЮіНсЙћНЯЮЊЕЅвЛЃЌНіНіжЛФмЗжЮіГі FragmentЁЂActivity ФкДцаЙТЖЃЌЯёДѓЖдЯѓЁЂЙ§ЖраЁЖдЯѓЮЪЬтЕМжТЕФФкДц
OOM ЮоЗЈЗжЮіЁЃ
ЯпЩЯ
е§ЪЧгЩгкЩЯЪівЛаЉБзЖЫЃЌЖЖвєзюдчЕФЯпЯТЙЄОпКЭжЮРэСїГЬВЂУЛгаЦ№ЕНЪВУДЬЋДѓзїгУЃЌЮвУЧВЛЕУВЛжиаТЩѓЪгвЛЯТЃЌЙЄОпНЈЩшЕФжиаФДгЯпЯТзЊГЩСЫЯпЩЯЁЃЯпЩЯЙЄОпЕФКЫаФЫМТЗЪЧЃКдкЗЂЩњ
OOM ЛђепФкДцДЅЖЅЕШДЅЗЂЬѕМўЯТЃЌdump ФкДцЕФ HPROF ЮФМўЃЌЖд HPROF ЮФМўНјааЗжЮіЃЌЗжЮіГіФкДцаЙТЉЁЂДѓЖдЯѓЁЂаЁЖдЯѓЁЂЭМЦЌЮЪЬтВЂАДееаЙТЖСДТЗздЖЏЙщвђЃЌНЋДѓЪ§ОнЮЪЬтАДеегУЛЇЗЂЩњДЮЪ§ЁЂаЙТЖДѓаЁЁЂзмДѓаЁЕШЮГЖШХХађЃЌЭЦНјвЕЮёбаЗЂАДеегХЯШМЖЫГађРДНЈСЂЯћЗбСїГЬЁЃЮЊДЫЮвУЧбаЗЂСЫвЛЬзЛљгк
HPORF ЗжЮіЕФЯпЯТЁЂЯпЩЯБеЛЗЕФздЖЏЛЏЗжЮіЙЄОп LikoЃЈдЂвт ko ФкДц Leak ЮЪЬтЃЉЁЃ
Liko НщЩм
Liko ећЬхМмЙЙ
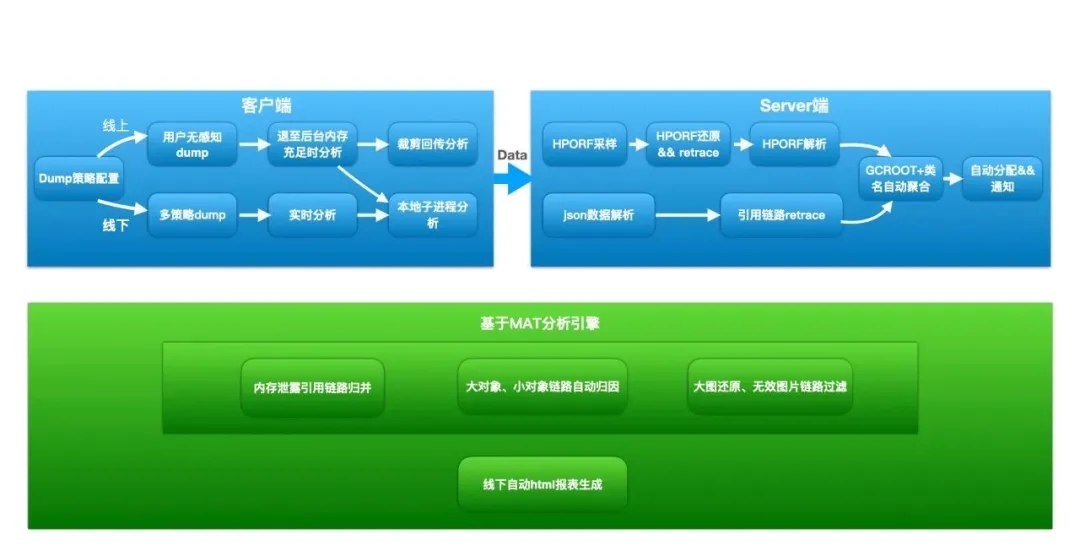
ЭМ 3. Liko МмЙЙЭМ
ећЬхМмЙЙгЩПЭЛЇЖЫЁЂServer ЖЫКЭКЫаФЗжЮів§ЧцШ§ВПЗжЙЙГЩЁЃ
ПЭЛЇЖЫ
дкПЭЛЇЖЫЭъГЩ HPROF Ъ§ОнВЩМЏКЭЗжЮіЃЈеыЖдЖЫЩЯЗжЮіФЃЪНЃЉЃЌетРяЯпЩЯКЭЯпЯТВпТдВЛЭЌЁЃ
ЯпЩЯЃКжївЊдк OOM КЭФкДцДЅЖЅЪБЭЈЙ§гУЛЇЮоИажЊ dump РДЛёШЁ HPROF ЮФМўЃЌЕБ App
ЭЫГіЕНКѓЬЈЧвФкДцГфзуЕФЧщПіНјааЗжЮіЃЌЮЊСЫОЁСПМѕЩйЖд App дЫааЪБгАЯьЃЌжївЊЭЈЙ§ВУМє HPROF ЛиДЋНјааЗжЮіЃЌЮЊМѕЧсЗўЮёЦїбЙСІЃЌЖдВПЗжБШР§гУЛЇВЩгУЖЫЩЯЗжЮізїЮЊ
BackupЁЃ
ЯпЯТЃКdump ВпТдХфжУНЯЮЊМЄНјЃЌдк OOMЁЂФкДцДЅЖЅЁЂФкДцМЄдіЁЂМрВт ActivityЁЂFragment
аЙТЉЪ§СПДяЕНвЛЖЈуажЕЖржжГЁОАЯТДЅЗЂ dumpЃЌВЂЪЕЪБдкЖЫЩЯЗжЮіЩЯДЋжСКѓЬЈВЂдкБОЕиздЖЏЩњГЩ html
БЈБэЃЌАяжњбаЗЂЬсЧАЗЂЯжПЩФмДцдкЕФФкДцЮЪЬтЁЃ
Server ЖЫ
Server ЖЫИљОнЯпЩЯЛиДЋЕФДѓЪ§ОнЭъГЩСДТЗОлКЯЁЂЛЙдЁЂЗжХфЃЌВЂИљОнгУЛЇЗЂЩњДЮЪ§ЁЂаЙТЖДѓаЁЁЂзмДѓаЁЕШЮГЖШДйНјбаЗЂВтЯћЗбЃЌЖдгкЛиДЋЗжЮіФЃЪНдђЛсСэЭтНјаа
HPORF ЗжЮіЁЃ
ЗжЮів§Чц
Лљгк MAT ЗжЮів§ЧцЭъГЩФкДцаЙТЖЁЂДѓЖдЯѓЁЂаЁЖдЯѓЁЂЭМЦЌЕШздЖЏЙщвђЃЌЭЌЪБжЇГждкЯпЯТздЖЏЩњГЩ Html
БЈБэЁЃ
Liko СїГЬЭМ
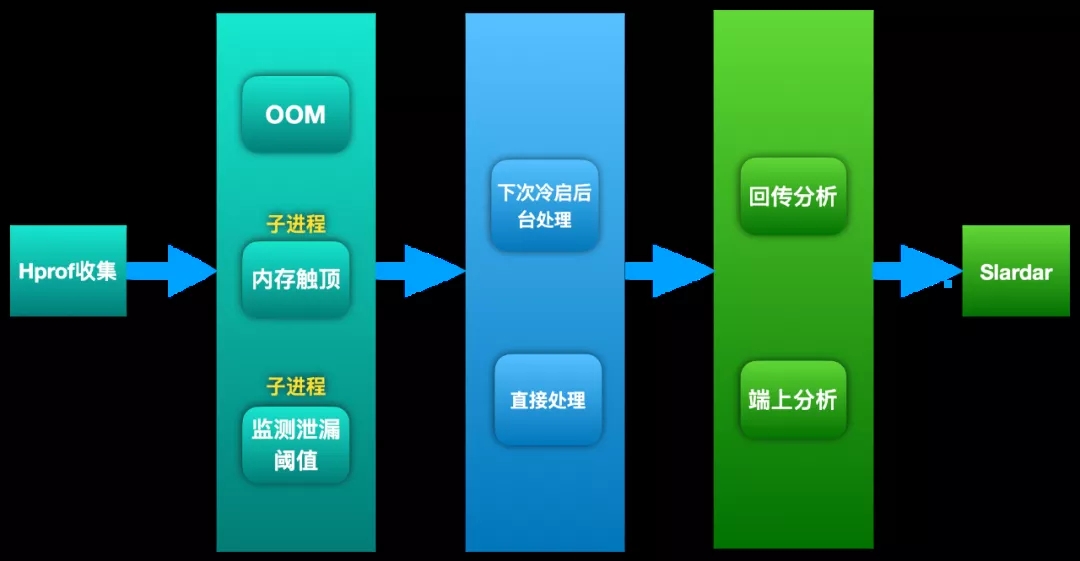
ЭМ 4. Liko СїГЬЭМ
ећЬхСїГЬЗжЮЊЃК
Hprof ЪеМЏ
ЗжЮіЪБЛњ
ЗжЮіВпТд
Hprof ЪеМЏ
ЪеМЏЙ§ГЬЮвУЧЩшжУСЫЖржжВпТдПЩвдздгЩзщКЯЃЌжївЊга OOMЁЂФкДцДЅЖЅЁЂФкДцМЄдіЁЂМрВт ActivityЁЂFragment
аЙТЉЪ§СПДяЕНвЛЖЈуажЕЪБДЅЗЂЃЌЯпЯТЯпЩЯВпТдХфжУВЛЭЌЁЃ
ЮЊСЫНтОі dump ЙвЦ№НјГЬЮЪЬтЃЌЮвУЧВЩгУСЫзгНјГЬ dump+fileObsever ЕФЗНЪНЭъГЩ
dump ВЩМЏКЭМрЬ§ЁЃ
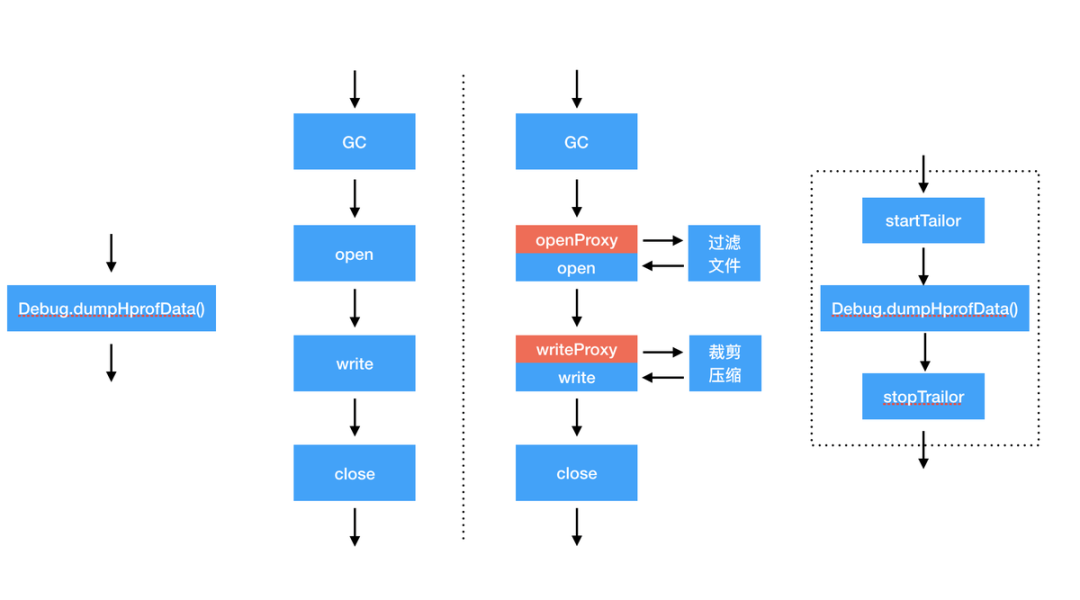
дк fork згНјГЬжЎЧАЯШ Suspend ЛёШЁжїНјГЬжаЕФЯпГЬПНБДЃЌЭЈЙ§ fork ЯЕЭГЕїгУДДНЈзгНјГЬШУзгНјГЬгЕгаИИНјГЬЕФПНБДЃЌШЛКѓ
fork ГіЕФзгНјГЬжаЕїгУ Hprof ЕФ DumpHeap КЏЪ§МДПЩЭъГЩАбКФЪБЕФ dump ВйзїдкЗХдкзгНјГЬЁЃгЩгк
suspend КЭ resume ЪЧЯЕЭГКЏЪ§ЃЌЮвУЧетРяЭЈЙ§здбаЕФ native hook ЙЄОпЖд libart.so
hook ЛёШЁЯЕЭГЕїгУЁЃгЩгкаДШыЪЧдкзгНјГЬЭъГЩЕФЃЌЮвУЧЭЈЙ§ Android ЬсЙЉЕФ fileObsever
ЮФМўаДШыНјааМрПиЛёШЁ dump ЭъГЩЪБЛњЁЃ
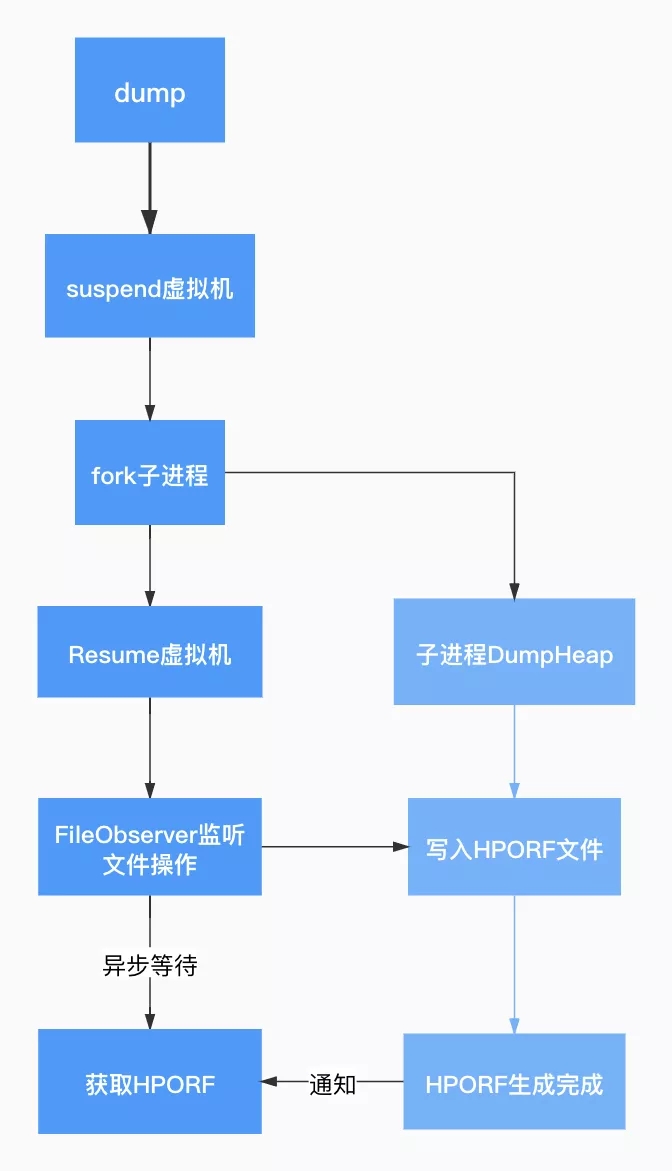
ЭМ 5.згНјГЬ dump СїГЬЭМ
Hprof ЗжЮіЪБЛњ
ЮЊСЫДяЕНЗжЮіЙ§ГЬЖдгкгУЛЇЮоИаЃЌЮвУЧдкЯпЩЯЁЂЯпЯТХфжУСЫВЛЭЌЕФЗжЮіЪБЛњВпТдЃЌЯпЯТдк dump ЗжЮіЭъГЩКѓИљОнФкДцзДЬЌжїЖЏДЅЗЂЗжЮіЃЌЯпЩЯЕБгУЛЇЯТДЮРфЦєЭЫГігІгУКѓЬЈЧвФкДцГфзуЕФЧщПіЯТДЅЗЂЗжЮіЁЃ
ЗжЮіВпТд
ЗжЮіВпТдЮвУЧЬсЙЉСЫСНжжЃЌвЛжждк Android ПЭЛЇЖЫЗжЮіЃЌвЛжжЛиДЋжС Server ЖЫЗжЮіЃЌОљЭЈЙ§
MAT ЗжЮів§ЧцНјааЗжЮіЁЃ
ЖЫЩЯЗжЮі
ЗжЮів§Чц
ЖЫЩЯЗжЮів§ЧцЕФадФмКмживЊЃЌетРяЮвУЧжївЊЖдБШСЫ LeakCanary ЕФЗжЮів§Чц Shark КЭ Haha
ПтЕФ MATЁЃ
.jpg)
ЭМ 6. Shark VS MAT
ЮвУЧдкЯрЭЌПЭЛЇЖЫЛЗОГЖд 160M ЕФ HPROF ЖрДЮЗжЮіЖдБШЗЂЯж MAT ЗжЮіЫйЖШУїЯдгХгк SharkЃЌСэЭтеыЖд
MAT ЗжЮіКѓШдГжгаЭГжЮепЪїеМгУФкДцЮвУЧвВзіСЫжїЖЏЪЭЗХЃЌЖдБШадФмЪевцКѓВЩгУЛљгк MAT ПтЕФЗжЮів§ЧцНјааЗжЮіЃЌЖдФкДцаЙТЉв§гУСДТЗздЖЏЙщВЂЁЂДѓЖдЯѓаЁЖдЯѓв§гУСДздЖЏЗжЮіЁЂДѓЭМЯпЯТздЖЏЛЙдЯпЩЯЙ§ТЫЮогУСДТЗЃЌЗжЮіНсЙћШчЯТЃК
ФкДцаЙТЉ
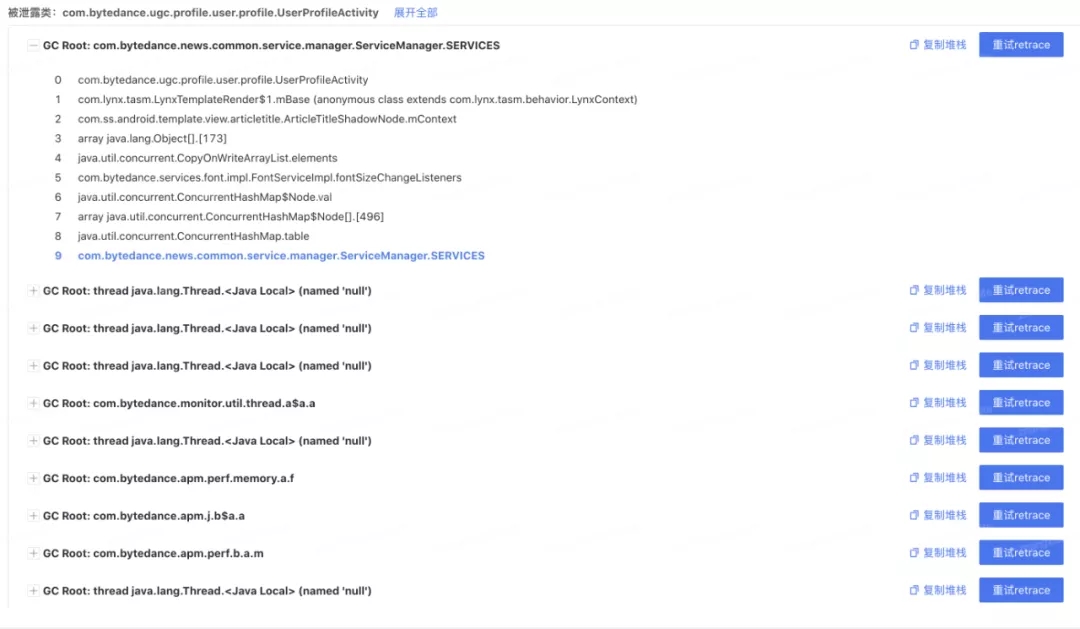
ЭМ 7. ФкДцаЙТЉСДТЗ
ЖдаЙТЉЕФ Activity ЕФв§гУСДНјааСЫОлКЯЗжЮіЃЌЗНБувЛДЮадНтОіИУ Activity ЕФаЙТЉСДЪЭЗХФкДцЁЃ
ДѓЖдЯѓ
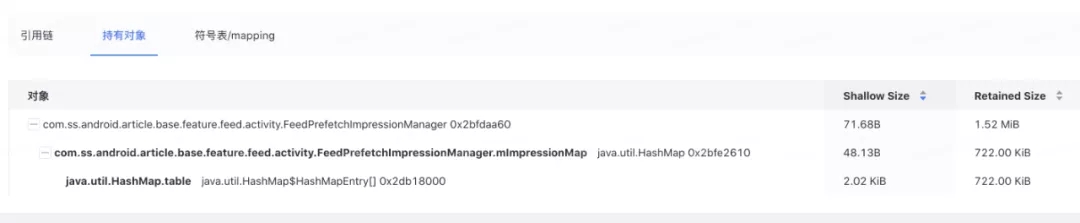
ЭМ 8. ДѓЖдЯѓСДТЗ
ДѓЖдЯѓВЛжЙЗжЮіСЫв§гУСДТЗЃЌЛЙЕнЙщЗжЮіСЫФкВП top ГжгаЖдЯѓЃЈInRefrenreceЃЉЕФ RetainedSizeЁЃ
аЁЖдЯѓ
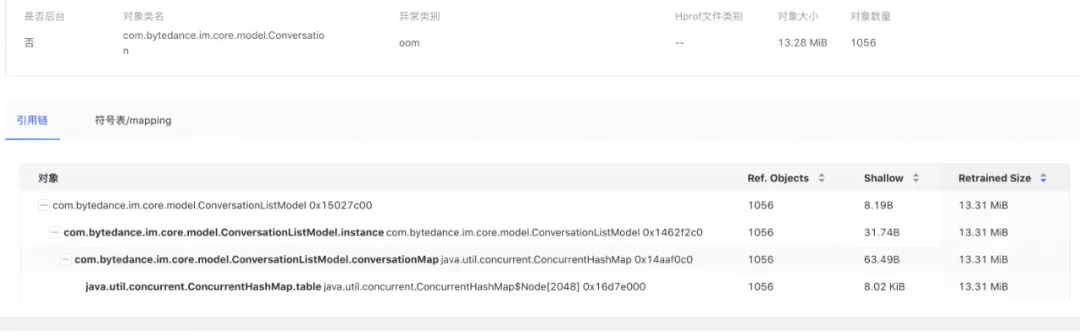
ЭМ 9. аЁЖдЯѓСДТЗ
аЁЖдЯѓЮвУЧЖд top ЕФЭтВПГжгаЖдЯѓЃЈOutRefrenreceЃЉНјааОлКЯЕУЕНеМгааЁЖдЯѓзюЖрЕФСДТЗЁЃ
ЭМЦЌ
ЭМ 10. ЭМЦЌСДТЗ
ЭМЦЌЮвУЧЙ§ТЫСЫЭМЦЌПтЕШЮоаЇв§гУЧвЖд Android 8.0 вдЯТЕФДѓЭМдкЯпЯТНјааСЫЛЙдЁЃ
ЛиДЋЗжЮі
ЮЊСЫзюДѓЯоЖШЕФНкЪЁгУЛЇСїСПЧвЙцБмвўЫНЗчЯеЃЌЮвУЧЭЈЙ§здба HPROF ВУМєЙЄОп Tailor дк dump
Й§ГЬЖд HPROF НјааСЫВУМєЁЃ
ВУМєЙ§ГЬ
ЭМ 11. Tailor ВУМєСїГЬ
ШЅГ§СЫЮогУаХЯЂ
ЬјЙ§ header
Зж tag ВУМє
ВУМєЮогУаХЯЂЃКchar[]; byte[]; timestamp; stack trace serial
number; class serial number;
бЙЫѕЪ§ОнаХЯЂ
ЭЌЪБЖдЪ§ОнНјаа zlib бЙЫѕЃЌдк server ЖЫЪ§ОнЛЙдЃЌећЬхВУМєаЇЙћЃК180M--->50M---->13M
гХЛЏЪЕМљ
ФкДцаЙТЉ
Г§СЫЭЈЙ§КѓЬЈИљОн GCROOT+ в§гУСДздЖЏЗжХфбаЗЂИњНјНтОіЮвУЧГЃМћЕФФкДцаЙТЉЭтЃЌЮвУЧЛЙЖдЯЕЭГЕМжТвЛаЉФкДцаЙТЉНјааСЫЗжЮіКЭаоИДЁЃ
ЯЕЭГвьВН UI аЙТЉ
ИљОнЩЯДЋОлКЯЕФв§гУСДЮвУЧЗЂЯждк Android 6.0 вдЯТгавЛИі HandlerThread зїЮЊ
GCROOT ГжгаДѓСП Activity ЕМжТФкДцаЙТЉЃЌИљОнв§гУЗЂЯжетаЉаЙТЉЕФ Activity ЖМБЛвЛИі
RunnableЃЈетРяЪЧ Runnable ЪЧвЛИіЯЕЭГЪТМў SendViewStateChangedAccessibilityEventЃЉГжгаЃЌетаЉ
Runnable БЛЬэМгЕНвЛИі RunQueuel жаЃЌетИіЖгСаБОЩэБЛ TheadLocal ГжгаЁЃ

ЭМ 12. HandlerThread аЙТЖСДТЗ
ЮвУЧДг SendViewStateChangedAccessibilityEvent ШыЪжЖддДТыНјааСЫЗжЮіЗЂЯжЫќдк
notifyViewAccessibilityStateChangedIfNeeded жаБЛХзГіЃЌЯЕЭГЕФДѓСП
view ЖМЛсдкздЩэЕФвЛаЉ UI ЗНЗЈЃЈeg: setCheckedЃЉжаДЅЗЂИУКЏЪ§ЁЃ

SendViewStateChangedAccessibilityEvent ЕФ runOrPost
ЗНЗЈЛсзпЕНЮвУЧГЃгУЕФ View ЕФ postDelay ЗНЗЈжаЃЌетИіЗНЗЈдкЕБ view ЛЙЮДБЛ attched
ЕНИљ view ЕФЪБКђЛсМгШыЕНвЛИі runQueue жаЁЃ

етИі runQueue ЛсдкжїЯпГЬЯТвЛДЮЕФ performTraversals() жаЯћЗбЕєЁЃ

ШчЙћетИі runQueue ВЛдкжїЯпГЬФЧОЭУЛгаЯћЗбЕФЛњЛсЁЃ
ИљОнЩЯУцЕФЗжЮіЗЂЯждьГЩетжжФкДцаЙТЉашвЊТњзувЛаЉЬѕМўЃК
view ЕїгУСЫ postDelay ЗНЗЈ ЃЈетРяЪЧ notifyViewAccessisbilityStateChangeIfNeeded
ДЅЗЂЃЉ
view ДІгк detached зДЬЌ
ЩЯЪіЙ§ГЬЪЧдкЗЧжїЯпГЬРяУцВйзїЕФЃЌThreadLocal ЗЧ UIThreadЃЌГжгаЕФ runQueue
ВЛЛсзп performTraversals ЯћЗбЕєЁЃ
ЖЖвєетБпДѓСПЪЙгУСЫвьВН UI ПђМмРДгХЛЏфжШОадФмЃЌПђМмФкВПгЩвЛИі HandlerThread Ч§ЖЏЃЌЭъШЋЗћКЯЩЯЪіЬѕМўЁЃеыЖдИУЮЪЬтЃЌЮвУЧЭЈЙ§ЗДЩфЛёШЁЗЧжїЯпГЬЕФ
ThreadLocalЃЌдкУПДЮвьВНфжШОЭъжїЖЏЧхРэФкВПЕФ RunQueueЁЃ
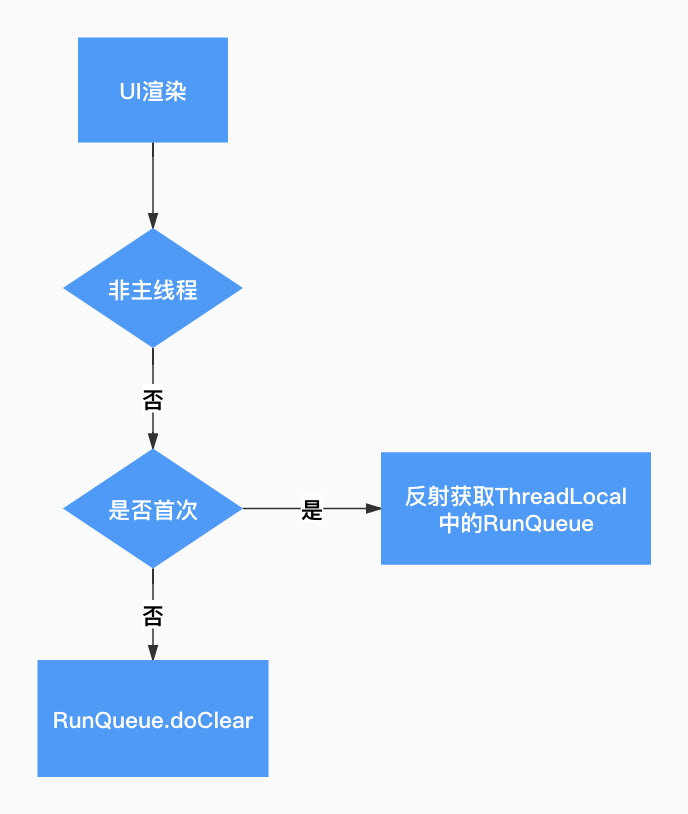
ЭМ 13. ЗДЩфЧхРэСїГЬ
СэЭтЃЌGoogle дк 6.0 ЩЯвВаоИДСЫ notifyViewAccessisbilityStateChangeIfNeeded
ЕФХаЖЯВЛбЯНїЮЪЬтЁЃ

ФкДцаЙТЉЖЕЕз
ДѓСПЕФФкДцаЙТЉЃЌШчЙћЮвУЧЖМППЭЦНјбаЗЂНтОіЃЌОГЃЛсГіЯжЩњВњДѓгкЯћЗбЕФЧщПіЃЌеыЖдетаЉЮДБЛЯћЗбЕФФкДцаЙТЉЮвУЧдкПЭЛЇЖЫзіСЫМрПиКЭжЙЫ№ЃЌНЋ
onDestory ЕФ Activity ЬэМгЕН WeakRerefrence жаЃЌбгГй 60s МрПиЪЧЗёЛиЪеЃЌЮДЛиЪедђжїЖЏЪЭЗХаЙТЉЕФ
Activity ГжгаЕФ ViewTree ЕФБГОАЭМКЭ ImageView ЭМЦЌЁЃ
ДѓЖдЯѓ
жївЊЖдШ§жжРраЭЕФДѓЖдЯѓНјаагХЛЏ
ШЋОжЛКДцЃКеыЖдШЋОжЛКДцЮвУЧАДашЪЭЗХКЭНЕМЖСЫВЛашвЊЕФЛКДцЃЌОЁСПЪЙгУШѕв§гУДњЬцЧПв§гУЙиЯЕЃЌБШШчеыЖдЦЕЗБаЙТЉЕФ
EventBus ЮвУЧНЋФкВПЕФЖЉдФепЙиЯЕИФЮЊШѕв§гУНтОіСЫДѓСПЕФ EventBus аЙТЉЁЃ
ЯЕЭГДѓЖдЯѓЃКЯЕЭГДѓЖдЯѓШч PreloadDrawableЁЂJarFile ЮвУЧЭЈЙ§дДТыЗжЮіШЗЖЈжїЖЏЪЭЗХВЂВЛИЩШХдгаТпМЃЌдкЦєЖЏЭъГЩЛђдкФкДцДЅЖЅЪБжїЖЏЗДЩфЪЭЗХЁЃ
ЖЏЛЃКгУдЩњЖЏЛДњЬцСЫФкДцеМгУНЯДѓЕФжЁЖЏЛЃЌВЂЖд Lottie ЖЏЛаЙТЉзіСЫЪжЖЏЪЭЗХЁЃ
ЭМ 14. ДѓЖдЯѓгХЛЏЕу
аЁЖдЯѓ
аЁЖдЯѓгХЛЏЮвУЧМЏжадкзжЖЮгХЛЏЁЂвЕЮёгХЛЏЁЂЛКДцгХЛЏШ§ИіЮГЖШЃЌВЛЭЌЕФЮГЖШгаВЛЭЌЕФгХЛЏВпТдЁЃ
ЭМ 15. аЁЖдЯѓгХЛЏЫМТЗ
ЭЈгУРргХЛЏ
дкЖЖвєЕФвЕЮёжаЃЌЪгЦЕЪЧзюКЫаФЧвЭЈгУЕФ ModelЃЌЖЖвєвЕЮёВуЕФЪ§ОнДцДЂЗжЩЂдкИїИівЕЮёЮЌЛЄСЫИїздЪгЦЕЕФ
ModelЃЌModel БОЩэгЩгкОлКЯСЫИїИівЕЮёашвЊЕФЪєадКмЖрЕМжТЕЅИіЪЕР§ФкДцеМгУОЭВЛЕЭЃЌЫцзХгУЛЇЪЙгУЙ§ГЬЪЕР§діГЄФкДцеМгУдНРДдНДѓЁЃЖд
Model БОЩэЮвУЧПЩвдДгЪєадгХЛЏКЭВ№ЗжетСНжжЫМТЗРДгХЛЏЁЃ
зжЖЮгХЛЏЃКеыЖдвЛДЮадЕФЪєадзжЖЮЃЌдкЪЙгУЭъжЎКѓМАЪБЧхРэЕєЛКДцЃЌБШШчдкЪгЦЕ Model ФкВПДцдквЛИі
Json ЖдЯѓЃЌдкЗДађСаЭъГЩжЎКѓ Json ЖдЯѓОЭУЛгаЪЙгУМлжЕСЫЃЌПЩвдМАЪБЧхРэЁЃ
РрВ№ЗжЃКеыЖдЭЈгУ Model ШпдгЙ§ЖрЕФвЕЮёЪєадЃЌГЂЪдЖд Model БОЩэНјаажЮРэЃЌНЋИїИівЕЮёЯпашвЊгУЕНЕФЪєадНјааЪсРэЃЌНЋ
Model В№ЗжГЩЖрИівЕЮё Model КЭвЛИіЭЈгУ ModelЃЌВЩгУзщКЯЕФЗНЪНШУИїИівЕЮёЯпзюаЁЛЏвРРЕздМКЕФвЕЮё
ModelЃЌМѕЩйДѓдгЛт Model ВЛБивЊЕФФкДцРЫЗбЁЃ
вЕЮёгХЛЏ
АДашМгдиЃКЖЖвєетБп IM ЛсШЋОжБЃДцЛсЛАЃЌApp ЦєЖЏЪБЛсвЛДЮад Load ЫљгаЛсЛАЃЌЕБгУЛЇЕФЛсЛАЙ§ЖрЪБЯргІШЋОжеМгУЕФФкДцОЭЛсНЯДѓЃЌЮЊСЫНтОіИУЮЪЬтЃЌЛсЛАСаБэЗжСНДЮМгдиЃЌЪзДЮжЛМгдивЛЖЈЪ§СПЕНФкДцЃЌашвЊЪБдйМгдиШЋВПЁЃ
ФкДцЛКДцЯожЦЛђЧхРэЃКЪзвГЭЦМіСаБэЕФУПвЛДЮ Loadmore ВйзїЃЌЖМВЛЛсЧхРэжЎЧАЛКДцЦ№РДЕФЪгЦЕЖдЯѓЃЌЕМжТгУЛЇГЄЪБМфЭЃСєдкЭЦМі
Feed ЪБЃЌЛКДцЦ№РДЕФЪгЦЕЖдЯѓЙ§ЖрЛсЕМжТФкДцЗНУцЕФбЙСІЁЃдкЭЈЙ§ЪЕбщбщжЄВЛЛсЖдвЕЮёВњЩњИКУцгАЯьЧщПіЯТЖдЪзвГЕФЛКДцНјааСЫвЛЖЈЪ§СПЕФЯожЦРДМѕаЁФкДцбЙСІЁЃ
ЛКДцгХЛЏ
ЩЯУцЬсЕНЕФЪгЦЕ ModelЃЌЖЖвєзюдчЪЙгУ Manager РДЙмРэЭЈгУЕФЪгЦЕЪЕР§ЁЃManager ЪЙгУ
HashMap ДцДЂСЫЫљгаЕФЪгЦЕЖдЯѓЃЌзюГѕЕФЗНАИРяУцУЛгаЖдФкДцДѓаЁНјааЯожЦЧвУЛгаЧхГ§ТпМЃЌЫцзХЪЙгУЪБМфЕФдіМгЖјВЛЖЯХђеЭЃЌзюжеГіЯж
OOM вьГЃЁЃЮЊСЫНтОіЪгЦЕ Model ЮоЯоХђеЭЕФЮЪЬтЩшМЦСЫвЛЬзЛКДцПђМмжївЊСїГЬШчЯТЃК
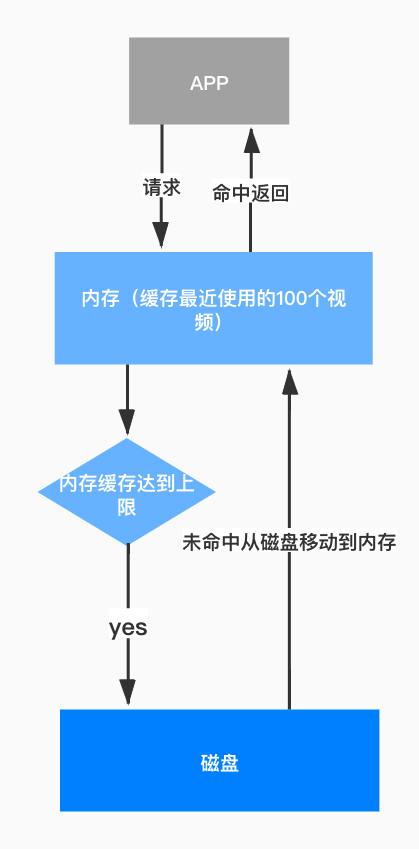
ЭМ 16. ЪгЦЕЛКДцПђМм
ЪЙгУ LRU ЛКДцЛњжЦРДЛКДцЪгЦЕЖдЯѓЁЃдкФкДцжаЛКДцзюНќЪЙгУЕФ 100 ИіЪгЦЕЖдЯѓЃЌЕБЪгЦЕЖдЯѓДгФкДцЛКДцжавЦГ§ЪБЃЌНЋЦфЛКДцжСДХХЬжаЁЃдкЛёШЁЪгЦЕЖдЯѓЪБЃЌЪзЯШДгФкДцжаЛёШЁЃЌШєФкДцжаУЛгаЛКДцИУЖдЯѓЃЌдђДгДХХЬЛКДцжаЛёШЁЁЃдкЭЫГі
App ЪБЃЌЧхГ§ Manager ЕФДХХЬЛКДцЃЌБмУтДХХЬПеМфеМгУВЛЖЯдіГЄЁЃ
ЭМЦЌ
ЙигкЭМЦЌгХЛЏЃЌЮвУЧжївЊДгЭМЦЌПтЕФЙмРэКЭЭМЦЌБОЩэгХЛЏСНИіЗНУцЫМПМЁЃЭЌЪБЖдВЛКЯРэЕФЭМЦЌЪЙгУвВзіСЫЖЕЕзКЭМрПиЁЃ
ЭМЦЌПт
еыЖдгІгУФкЭМЦЌЕФЪЙгУзДПіЖдЭМЦЌПтЩшжУСЫКЯРэЕФЛКДцЃЌЭЌЪБдкгІгУ or ЯЕЭГФкДцГдНєЕФЧщПіЯТжїЖЏЪЭЗХЭМЦЌЛКДцЁЃ
ЭМЦЌздЩэгХЛЏ
ЮвУЧжЊЕРЭМЦЌФкДцДѓаЁЙЋЪН = ЭМЦЌЗжБцТЪ * УПИіЯёЫиЕуЕФДѓаЁЁЃ
ЭМЦЌЗжБцТЪЮвУЧЭЈЙ§ЩшжУКЯРэЕФВЩбљРДМѕЩйВЛБивЊЕФЯёЫиРЫЗбЁЃ
//ПЊЦєВЩбљ
ImagePipelineConfig config = ImagePipelineConfig.newBuilder(context)
.setDownsampleEnabled(true)
.build();
Fresco.initialize(context, config);
//ЧыЧѓЭМЦЌЪБЃЌДЋШыresizeЕФДѓаЁЃЌвЛАужБНгШЁViewЕФПэИп
ImageRequest request = ImageRequestBuilder.newBuilderWithSource (uri)
.setResizeOptions (new ResizeOptions(50, 50))
.build(); mSimpleDraweeView.setController(
Fresco.newDraweeControllerBuilder()
.setOldController (mSimpleDraweeView.getController())
.setImageRequest (request)
.build()); |
ЖјЕЅИіЯёЫиДѓаЁЃЌЮвУЧЭЈЙ§ЬцЛЛЯЕЭГ drawable ФЌШЯЩЋВЪЭЈЕРЃЌНЋВПЗжУЛгаЭИУїЭЈЕРЕФЭМЦЌИёЪНгЩ ARGB_8888
ЬцЛЛЮЊ RGB565ЃЌдкЭМЦЌжЪСПЩЯЕФЫ№ЪЇМИКѕШтблВЛПЩМћЃЌЖјдкФкДцЩЯПЩвджБНгНкЪЁвЛАыЁЃ
ЭМЦЌЖЕЕз
еыЖдвђ activityЁЂfragment аЙТЉЕМжТЕФЭМЦЌаЙТЉЃЌЮвУЧдк onDetachedFromWindow
ЪБЛњНјааСЫМрПиКЭЖЕЕзЃЌОпЬхСїГЬШчЯТЃК
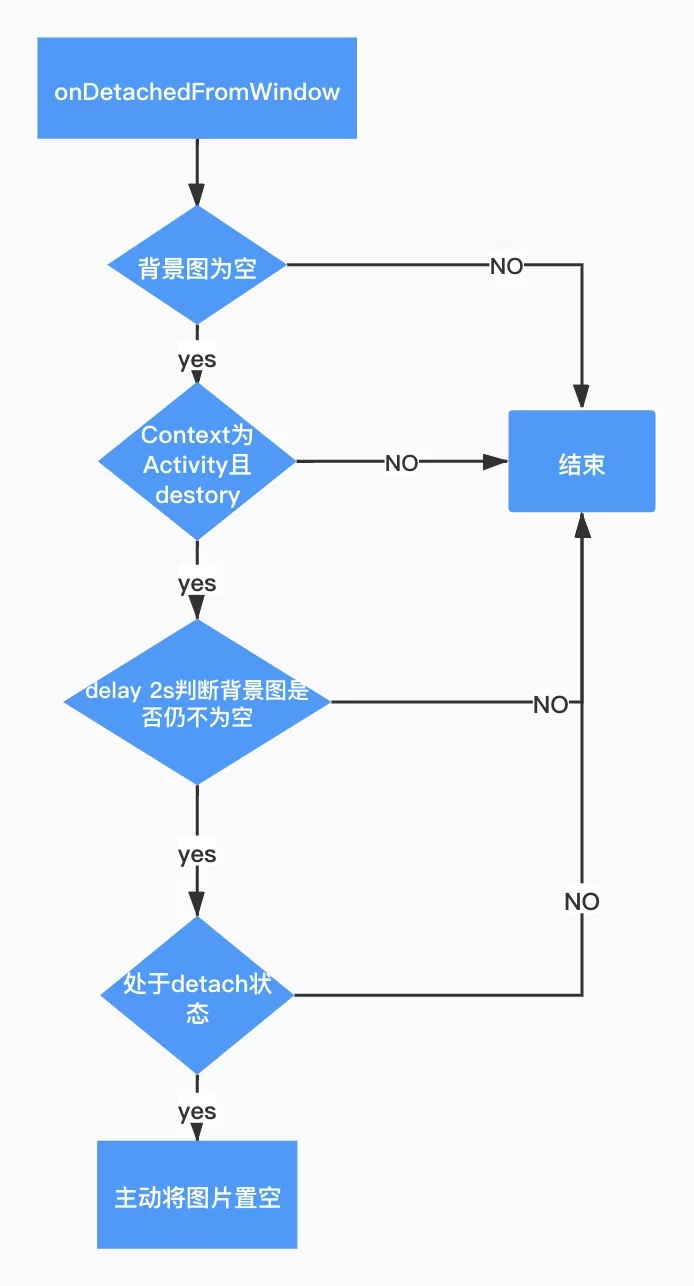
ЭМ 17. ЭМЦЌЖЕЕзСїГЬ
ЭМЦЌМрПи
ЙигкЖдВЛКЯРэЕФДѓЭМ or ЭМЦЌЪЙгУЮвУЧдкзжНкТыВуУцНјааСЫРЙНиКЭМрПиЃЌдкдЩњ Bitmap or ЭМЦЌПтДДНЈЪБЛњМЧТМЭМЦЌаХЯЂЃЌЖдВЛКЯРэЕФДѓЭМНјааЩЯБЈЃЛСэЭтдк
ImageView ЕФЩшжУЙ§ГЬжаеыЖд Bitmap дЖГЌЙ§ view БОЩэГЌЙ§ДѓаЁЕФГЁОАвВНјааСЫМЧТМКЭЩЯБЈЁЃ
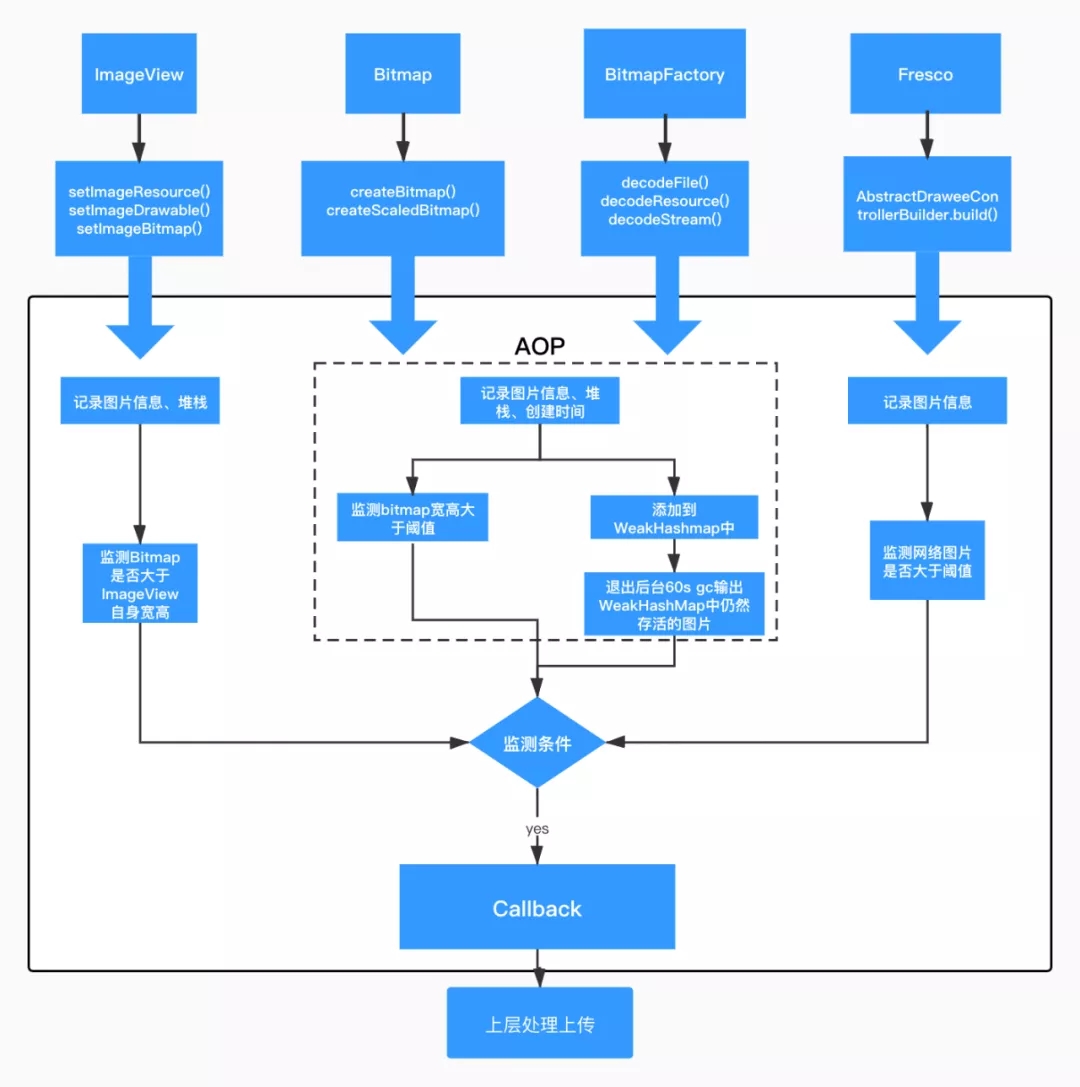
ЭМ 18. ЭМЦЌзжНкТыМрПиЗНАИ
ИќЖрЫМПМ
ЪЧВЛЪЧНтОіСЫ OOM ФкДцЮЪЬтОЭИцвЛЖЮТфСЫФиЃПзїЮЊвЛжЛзЗЧѓМЋжТЕФЭХЖгЃЌЮвУЧГ§СЫНтОіОВЬЌЕФФкДцеМгУЭтвВздбаСЫ
KenzoЃЈMemory InsightЃЉЙЄОпГЂЪдНтОіЖЏЬЌФкДцЗжХфдьГЩЕФ GC ПЈЖйЁЃ
Kenzo дРэ
Kenzo ВЩгУ JVMTI ЭъГЩЖдФкДцМрПиЙЄзїЃЌJVMTIЃЈJVM Tool InterfaceЃЉЪЧ
Java ащФтЛњЫљЬсЙЉЕФ native БрГЬНгПкЁЃJVMTI ПЊЗЂЪБЃЌгІгУНЈСЂвЛИі Agent ЪЙгУ
JVMTIЃЌПЩвдЪЙгУ JVMTI КЏЪ§ЃЌЩшжУЛиЕїКЏЪ§ЃЌВЂДг Java ащФтЛњжаЕУЕНЕБЧАЕФдЫааЬЌаХЯЂЃЌВЂзїГіздМКЕФвЕЮёХаЖЯЁЃ
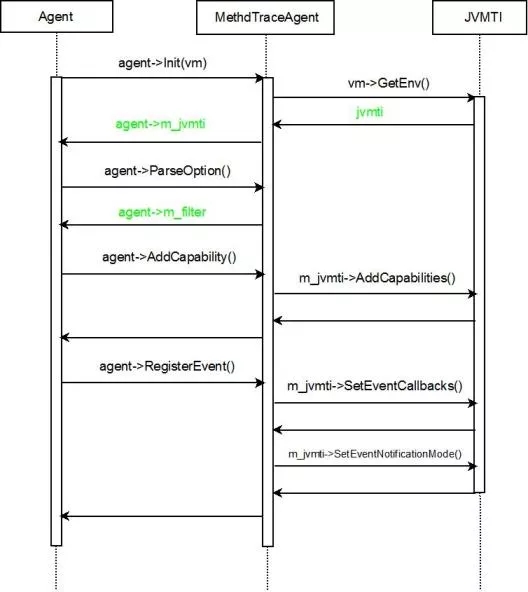
ЭМ 19. Agent ЪБађЭМ
Jvmti SetEventCallbacks ЗНЗЈПЩвдЩшжУФПБъащФтЛњФкВПЪТМўЛиЕїЃЌПЩвдИљОн jvmtiCapabilities
жЇГжЕФФмСІКЭЮвУЧЙизЂЕФЪТМўРДЖЈвхашвЊ hook ЕФЪТМўЁЃ
Kenzo ВЩгУ Jvmti ЭъГЩШчЯТЪТМўЛиЕїЃК
РрМгдизМБИЪТМў -> МрПиРрМгди
ClassPrepareЃКФГИіРрЕФзМБИНзЖЮЭъГЩЁЃ
GC -> МрПи GC ЪТМўгыЪБМф
GarbageCollectionStartЃКGC ЦєЖЏЪБЁЃ
GarbageCollectionFinishЃКGC НсЪјКѓЁЃ
ЖдЯѓЪТМў -> МрПиФкДцЗжХф
ObjectFreeЃКGC ЪЭЗХвЛИіЖдЯѓЪБЁЃ
VMObjectAllocЃКащФтЛњЗжХфвЛИіЖдЯѓЕФЪБКђЁЃ
ПђМмЩшМЦ
Kenzo ећЬхЗжЮЊСНИіВПЗжЃК
ЩњВњЖЫ
ВЩМЏФкДцЪ§Он
вд sdk аЮЪНМЏГЩЕНЫожї App
ЯћЗбЖЫ
ДІРэЩњВњЖЫЕФЪ§Он
ЪфШы Kenzo МрПиЕФФкДцЪ§Он
ЪфГіПЩЪгЛЏБЈБэ 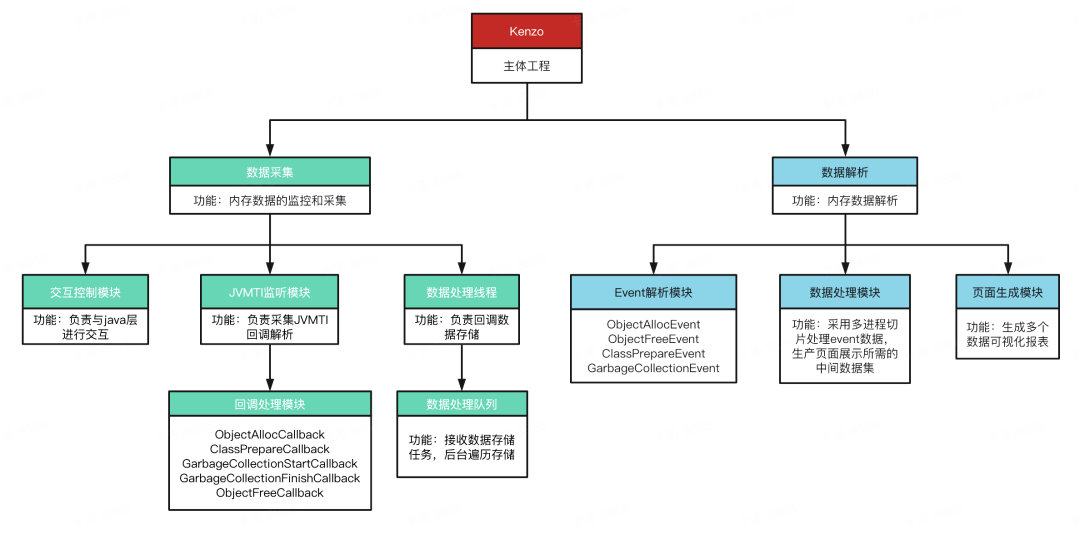
ЭМ 20. kenzo ПђМм
ЩњВњЖЫжївЊвд Java Нјаа API ЕїгУЃЌC++ЭъГЩЕзВуМьВтТпМЃЌЭЈЙ§ JNI ЭъГЩЕзВуТпМПижЦЁЃ
ЯћЗбЖЫжївЊвд Python ЭъГЩЪ§ОнЕФНтЮіЁЂЪгЭМКЯГЩЃЌвд HTML ЭъГЩвГУцФкШнеЙЪОЁЃ
ЙЄзїСї
ЭМ 21. kenzo ПђМм
ПЩЪгЛЏеЙЪО

22. kenzo ОлКЯеЙЪО
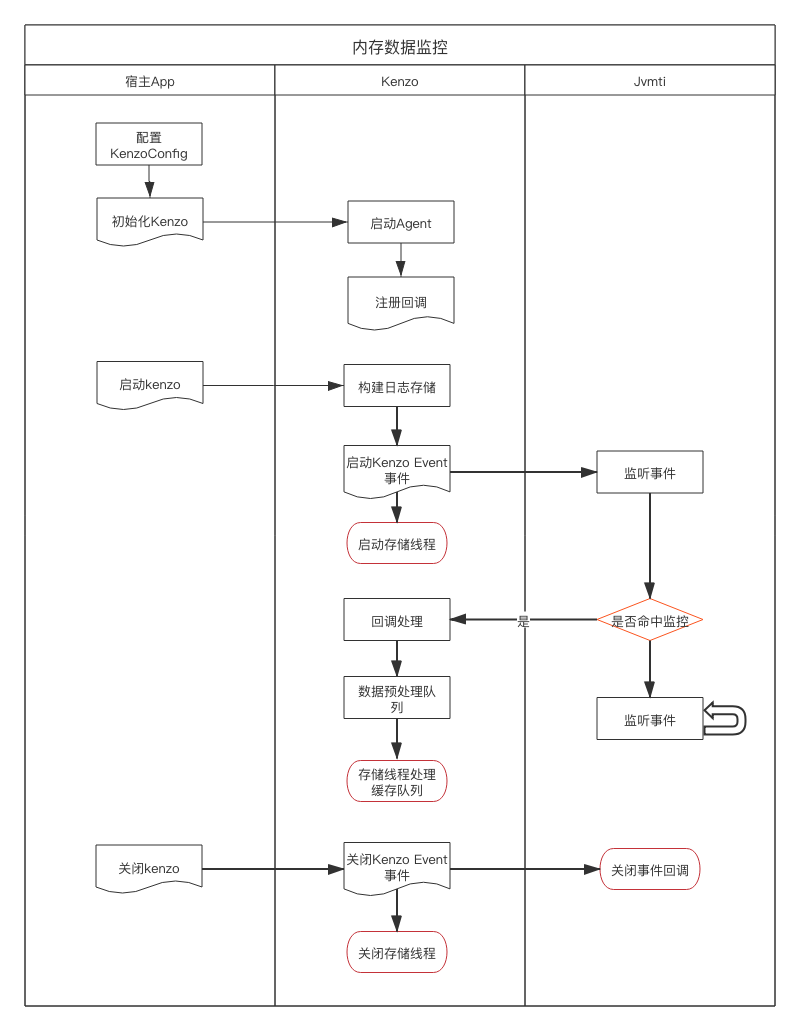
ЦєЖЏНзЖЮФкДцЙщвђ
ЛљгкЖЏЬЌФкДцМрПиЮвУЧЖдзюЮЊКЫаФЕФЦєЖЏГЁОАЕФФкДцЗжХфНјааСЫЙщвђЗжЮіЃЌгХЛЏСЫвЛаЉЭЗВПЕФФкДцНкЕуЗжХф:

ЭМ 23.ЦєЖЏНзЖЮФкДцНкЕуЙщвђ
СэЭтЮвУЧвВЗЂЯжЦєЖЏНзЖЮДцдкДѓСПЕФзжЗћДЎЦДНгВйзїЃЌЫфШЛБрвыЦївбОгХЛЏГЩСЫ StringBuider
appendЃЌЕЋЪЧЩюШы StringBuider дДТыЗжЮіШддкДцдкДѓСПЕФЖЏЬЌРЉШнЖЏзїЃЈSystem.copyЃЉЃЌЮЊСЫгХЛЏИпЦЕГЁОАДЅЗЂЖЏЬЌРЉШнЕФадФмЫ№КФЃЌдк
StringBuilder дк appendЕФЪБКђЃЌВЛжБНгЭљ char[]РяШћЖЋЮїЃЌЖјЪЧЯШФУвЛИі String[]АбЫќУЧЖМДцЦ№РДЃЌЕНСЫзюКѓВХАбЫљга
String ЕФ length МгЦ№РДЃЌЙЙдьвЛИіКЯРэГЄЖШЕФ StringBuilderЁЃЭЈЙ§ЪЙгУБрвыЪБзжНкТыЬцЛЛЕФЗНЪНЃЌЬцЛЛЫљга
StringBuilder ЕФ append ЗНЗЈЪЙгУздЖЈвхЪЕЯжЃЌгХЛЏКѓЪзДЮАВзАЪзвГ Feed ЛЌЖЏ
1min ЕФ FPS ЬсЩ§ 1 жЁ/SЃЌЗЧЪзДЮАВзАЦєЖЏЃЌЛЌЖЏ 1min ЕФ FPS ЬсЩ§ 0.6 жЁ/SЁЃ | 








