| БрМЭЦМі: |
БОЮФжївЊУшЪіСЫSpring
BootГЃгУХфжУЯюЃЌПЊЗЂГЃгУзЂНтЁЊЁЊБэ/ЪЕЬхРрЁЂзжЖЮ/гђЪЙгУЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкВЉПЭдА ЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1. Spring BootГЃгУХфжУЯю
ЛљгкSpring Boot 2.0.6.RELEASE
1.1 ХфжУЪєадРр
spring.jpaЧАзКЕФЯрЙиХфжУЯюЖЈвхдкJpaPropertiesРржаЃЌ
1.2 здЖЏзАХфРр
ЩцМАЕНЕФздЖЏХфжУРрАќРЈЃКJpaBaseConfigurationЃЌHibernateJpaAutoConfiguration
1.3 ГЃгУХфжУЯю
# ЪЧЗёПЊЦєJPA RepositoriesЃЌШБЪЁ:
true
spring.data.jpa.repositories.enabled=true
# JPAЪ§ОнПтРраЭЃЌФЌШЯПЩвдздЖЏМьВтЃЌвВФмЭЈЙ§ЩшжУ
spring.jpa.database-platformДяЕНЭЌбљаЇЙћ
spring.jpa.database=ORACLE
# Ъ§ОнПтЦНЬЈЃЌГЃМћЕФжЕШчЃК
# org.hibernate.dialect.Oracle10gDialect
# org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.database-platform=org.hibernate.dialect.Oracle12cDialect
# ЪЧЗёЪЙгУJPAГѕЪМЛЏЪ§ОнПтЃЌПЩвддкЦєЖЏЪБ
ЩњГЩDDLДДНЈЪ§ОнПтБэЃЌШБЪЁЮЊfalse
spring.jpa.generate-ddl = false
# ИќЯИСЃЖШЕФПижЦJPAГѕЪМЛЏЪ§ОнПтЬиадЃЌ
гУРДЩшЖЈЦєЖЏЪБDDLВйзїЕФРраЭЃЌЯТЮФгаЯъЯИНщЩм
# ФкЧЖЪ§ОнПт hsqldb, h2, derbyЕФШБЪЁжЕЮЊcreate-drop
# ЗЧФкЧЖЪ§ОнПтЕФШБЪЁжЕЮЊnone
spring.jpa.hibernate.ddl-auto = update
# HibernateВйзїЪБЯдЪОецЪЕЕФSQL, ШБЪЁЃКfalse
spring.jpa.show-sql = true
# Hibernate 5 вўКЌУќУћВпТдРрЕФШЋЯоЖЈУћ
spring.jpa.hibernate.naming.implicit-strategy=
# Hibernate 5 ЮяРэУќУћВпТдРрЕФШЋЯоЖЈУћ
spring.jpa.hibernate.naming.physical-strategy=org.
hibernate.boot.model.naming.
PhysicalNamingStrategyStandardImpl
# Use Hibernate's newer IdentifierGenerator
for AUTO, TABLE and SEQUENCE.
spring.jpa.hibernate.use-new-id-generator-mappings=
# ЖюЭтЩшжУJPAХфжУЪєадЃЌЭЈГЃХфжУЯюЪЧЬиЖЈЪЕЯж
жЇГжЕФЃЌШчHibernateГЃгаЯТУцЕФМИЬѕХфжУЯю
spring.jpa.properties.* =
# НЋSQLжаЕФБъЪЖЗћЃЈБэУћЃЌСаУћЕШЃЉШЋВПЪЙгУв§КХРЈЦ№РД
spring.jpa.properties.hibernate.globally_quoted_identifiers=true
# ШежОМЧТМжДааЕФSQL
spring.jpa.properties.hibernate.show_sql = true
# ЪЧЗёНЋИёЪНЛЏSQLШежО
spring.jpa.properties.hibernate.format_sql =
true
# ЪЧЗёзЂВсOpenEntityManagerInViewInterceptor.
АѓЖЈJPA
EntityManager ЕНЧыЧѓЯпГЬжа. ФЌШЯЮЊ: true.
spring.jpa.open-in-view=true
# Hibernate 4 УќУћВпТдЕФШЋРрУћЃЌHibernate 5ВЛдйЪЪгУ
spring.jpa.hibernate.naming-strategy= |
1.4 ХфжУЯю spring.jpa.database
ХфжУЯюspring.jpa.databaseЕФжЕЭЈГЃПЩвдздЖЏМьВтЃЌПЩШЁжЕАќРЈСЫЃК
public enum Database
{
DEFAULT,
DB2,
DERBY,
H2,
HSQL,
INFORMIX,
MYSQL,
ORACLE,
POSTGRESQL,
SQL_SERVER,
SYBASE
} |
1.5 ХфжУЯюspring.jpa.generate-ddl КЭ spring.jpa.hibernate.ddl-auto
ХфжУЯюspring.jpa.generate-ddlЙмРэЪЧЗёПЊЦєздЖЏГѕЪМЛЏSchemaЬиадЃЌ
ХфжУЯюspring.jpa.hibernate.ddl-auto НјвЛВНПижЦЦєЖЏЪБГѕЪМЛЏSchemaЕФЬиадЃЌгавдЯТПЩбЁжЕЃК
create, ЦєЖЏЪБЩОГ§ЩЯвЛДЮЩњГЩЕФБэЃЌВЂИљОнЪЕЬхРрЩњГЩБэЃЌБэжаЕФЪ§ОнНЋБЛЧхПеЃЛ
create-dropЃЌЦєЖЏЪБИљОнЪЕЬхРрЩњГЩБэЃЌsessionFactoryЙиБеЪБЩОГ§БэЃЛ
updateЃЌЦєЖЏЪБИљОнЪЕЬхРрЩњГЩБэЃЌЕБЪЕЬхЕФЪєадБфЖЏЪБЃЌБэНсЙЙвВЛсИќаТЃЌПЊЗЂНзЖЮПЩвдЪЙгУИУЪєадЃЛ
validateЃЌЦєЖЏЪБбщжЄЪЕЬхРрКЭЪ§ОнБэЪЧЗёвЛжТЃЌдкЪ§ОнНсЙЙЮШЖЈЪБПЩвдВЩШЁИУбЁЯюЃЛ
noneЃЌВЛВЩШЁШЮКЮВйзїЃЛ
1.6 ХфжУЯюhibernate.globally_quoted_identifiers
ХфжУЯюhibernate.globally_quoted_identifiersгУРДдкSQLжаМгШыв§КХЃЌвдНтОіФГаЉГЁОАжаSQLБъЪЖЗћЃЈБэУћЃЌСаУћЕШЃЉГіЯжСЫЪ§ОнПтЙиМќзжЕФЧщаЮЁЃ
OracleжаЃЌИУЪєадИјБъЪЖЗћМгЫЋв§КХЃЌзЂвтOracleЫЋв§КХжаЕФФкШнЧјЗжДѓаЁаДЃЛ
MySQLжаЃЌИУЪєадИјБъЪЖЗћМгЗДв§КХЃЈУЛДэЃЌОЭЪЧМќХЬЪ§зж1зѓУцЕФФЧИі`ЃЉЃЌзЂвтФЌШЯЧщПіЯТЃЌMySQLЕФБэУћЧјЗжДѓаЁаДЃЌЕЋСаУћВЛЧјЗжДѓаЁаДЃЌдкЗДв§КХжавВЪЧШчДЫЁЃ
2. ПЊЗЂГЃгУзЂНтЁЊЁЊБэ/ЪЕЬхРрЪЙгУ
2.1 @Entity
@EntityгУдкЪЕЬхРрЩЯЃЌБэЪОетЪЧвЛИіКЭЪ§ОнПтБэгГЩфЕФЪЕЬхРрЁЃ
2.2 @Table
@TableгУРДЩљУїЪЕЬхРрЖдгІЕФБэаХЯЂЁЃАќРЈБэУћГЦЁЂЫїв§ЕШЁЃ
2.3 @SQLDeleteЃЌ
@SQLDeleteгУРДздЖЈвхЩОГ§гяОфЃЌ
ШчЙћВЛЯыЪЙгУJPA RepositoryздДјЕФЩОГ§гяОфЃЌОЭПЩвдЪЙгУИУзЂНтжиаДЃЌШчГЃМћЕФШэЩОГ§ЃК
@Entity
@Table(name = "App")
@SQLDelete(sql = "Update App set isDeleted
= 1 where id = ?") |
@WhereгУРДжИЖЈФЌШЯВщбЏЬѕМўЃЌПЩвдгУРДХфКЯШэЩОГ§ЁЃ
@Entity
@Table(name = "App")
@SQLDelete(sql = "Update App set isDeleted
= 1 where id = ?")
@Where(clause = "isDeleted = 0") |
2.4 @MappedSuperclass
@MappedSuperclassгУРДЖЈвхШєИЩБэжаЙЋЙВЕФзжЖЮЃЌНЋЫќУЧЗтзАдквЛИіЛљРржаЃЌЛљРрЩЯЪЙгУИУзЂНтЃЌдђЦфзгЪЕЬхРрНЋздЖЏЛёЕУИИРржаЕФзжЖЮгГЩфЙиЯЕЃЌЭЌЪБВЛашвЊЖюЭтЮЊИИРрНЈСЂецЪЕЕФБэЃЌвВОЭЪЧеце§ЕФБэжЛЖдгІ@MappedSuperclassЕФзгРрЁЃ
2.5 @Inheritance
@MappedSuperclassжИЖЈСЫЪЕЬхРржЎМфЪЧПЩвдДцдкВуДЮЙиЯЕЕФЃЌЭЈЙ§@InheritanceПЩвдНјвЛВНЙмРэВуДЮЙиЯЕЃЌЦфШЁжЕInheritanceTypeгавдЯТУЖОйБфСПЃК
public enum InheritanceType
{
/** A single table per class hierarchy. */
SINGLE_TABLE,
/** A table per concrete entity class. */
TABLE_PER_CLASS,
/**
* A strategy in which fields that are specific
to a
* subclass are mapped to a separate table than
the fields
* that are common to the parent class, and a
join is
* performed to instantiate the subclass.
*/
JOINED
} |
Р§Шч
ИИРрЩљУїШчЯТЃЌвтЮЖзХУПИізгЪЕЬхРрЖдгІСЫвЛеХБэ
@MappedSuperclass
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class BaseEntity |
згЪЕЬхРрИДгУИИРрЩљУїЕФгђ/зжЖЮЃК
@Entity
@Table(name="App")
public class AppEntity entends BaseEntity |
3. ПЊЗЂГЃгУзЂНтЁЊЁЊзжЖЮ/гђЪЙгУ
3.1 @Column
@ColumnЩљУївЛИіБэзжЖЮгыгђ/ЗНЗЈЕФгГЩфЃЌЦфЪєадПЩвдНјвЛВНжИЖЈЪЧЗёПЩЮЊNULLЃЌЪЧЗёЮЈвЛЕШЯИНкЁЃ
3.2 @Id
@IdБъзЂвЛИіЪєадЃЌБэЪОИУЪєадгГЩфЮЊЪ§ОнПтЕФжїМќЁЃ
ЕЅЖРЪЙгУ@IdРДБъЪЖЪЕЬхРрЕФЕЅИігђгГЩфЮЊЪ§ОнПтБэЕФжїМќЃЌЖдгкСЊКЯжїМќЖјбдЃЌОЭвЊХфКЯ@IdClassЪЙгУЁЃ
ЖЈвхвЛИіЃЈЭтВПЃЉжїМќРрЃЌжїМќРржаЩљУїСЫЪЕЬхРрЃЈФПБъБэЃЉСЊКЯжїМќжаЕФЫљгажїЪєадЃЌжїМќРрашЪЕЯжSerializableНгПкЃЛ
дкеце§ЕФЪЕЬхРрЩЯЪЙгУ@IdClassЃЌвдЩЯвЛВНЖЈвхЕФжїМќРрзїЮЊВЮЪ§ЃЛ
ЪЕЬхРрЕФжїЪєадБиаыКЭжїМќРржаЕФжїЪєадЭъШЋЖдгІЃЈИіЪ§ЃЌРраЭЃЌУћГЦЃЉ;
дкЪЕЬхРрЕФЫљгажїЪєадЩЯУцЬэМг@IdзЂНтЃЛ
ЪОР§
ЭтВПжїМќРрЃК
public class
RoleUserId implements Serializable {
private Long roleId;
private Long userId;
} |
ЪЕЬхРрЃК
@Entity
@Table(name = "TB_ROLE_USER")
@IdClass(RoleUserId.class)
public class RoleUserDO {
@Id
private Long roleId;
@Id
private Long userId;
// ...
} |
3.3 @GeneratedValue
@GeneratedValueЩшжУзжЖЮЕФздЖЏЩњГЩЗНЪНЁЃ
ЦфstrategyЪєадШЁжЕЮЊУЖОйGenerationTypeЃК
/**
* Indicates that the persistence provider must
assign
* primary keys for the entity using an underlying
* database table to ensure uniqueness.
*/
TABLE,
/**
* Indicates that the persistence provider must
assign
* primary keys for the entity using a database
sequence.
*/
SEQUENCE,
/**
* Indicates that the persistence provider must
assign
* primary keys for the entity using a database
identity column.
*/
IDENTITY,
/**
* Indicates that the persistence provider should
pick an
* appropriate strategy for the particular database.
The
* <code>AUTO</code> generation strategy
may expect a database
* resource to exist, or it may attempt to create
one. A vendor
* may provide documentation on how to create
such resources
* in the event that it does not support schema
generation
* or cannot create the schema resource at runtime.
*/
AUTO |
ЪЙгУзддіЕФЪ§ОнПтСаЩњГЩжїМќЪЧвЛжжГЃМћЕФжїМќЩњГЩЗНЪНЃЌMySQLжЇГжIdentityСаЁЃ
Oracle 12cвдКѓжЇГжIdentity ColumnЃЈЩэЗнСаЃЉЃЌПЩвдЪЙгУGenerationType.IDENTITYзїЮЊЩњГЩВпТдЃЌДЫЪБЮоашдйЪЙгУ@SequenceGeneratorжИЖЈЖдгІађСаЁЃДЫЧАЕФOracleЭЈГЃЪЙгУађСаЪЕЯжзддізжЖЮЃЌашвЊНЋЩњГЩВпТджИЖЈЮЊGenerationType.SEQUENCEВЂХфКЯ@SequenceGeneratorЃЈЯТЮФЃЉЪЙгУЁЃ
Oracle 12cаТдіIdentity ColumnЕФЪЙгУЧыдФЖСЃКhttps://www.cnblogs.com/zyon/p/11067115.html
ЪЙгУЩэЗнСаЩњГЩзддіжїМќЪБЃЌдкжїМќЪєадЩЯЪЙгУ@IdКЭ@GeneratedValue(strategy
= GenerationType.IDENTITY)
@Entity
public class Author {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", updatable = false,
nullable = false)
private Long id;
// Ё
} |
@GeneratedValue#generatorЪєаджИЖЈжїМќЩњГЩЦїЕФУћГЦЃЌашвЊгы@SequenceGeneratorЛђ@TableGeneratorЕФУћГЦЖдгІЦ№РДЁЃ
3.4 @SequenceGenerator
ШчЙћЪЙгУађСаЗНЪНЩњГЩжїМќЃЌ@SequenceGeneratorжИЖЈздЖЏЩњГЩжїМќЪБЖдгІЕФађСаЃЈSequenceЃЉЁЃ
@SequenceGenerator#nameжИЖЈађСаЩњГЩЦїЕФУћГЦЃЌ@GeneratedValue#generatorЭЈЙ§в§гУИУжЕгыОпЬхЕФађСаЩњГЩЦїЙиСЊЃЌНјЖјЙиСЊОпЬхЕФађСаЁЃ
@SequenceGenerator#sequenceNameжИЖЈздЖЏЩњГЩжїМќЪБЕФЮяРэађСаУћГЦЃЛ
@SequenceGenerator#initialValueЪєаджИЖЈађСаГѕжЕЃЛ
@SequenceGenerator#allocationSizeжИЖЈзддіВНГЄЃЛ
ЪЕР§ЃК
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "sequence")
@SequenceGenerator(name = "sequence",
sequenceName = "ID_SEQ", allocationSize
= 1)
@Column(name = "Id")
private long id; |
3.5 JPAДѓЖдЯѓжЇГж
ГЃгУЯрЙизЂНт
@Lob
@Basic
3.5.1 дкзжЗћДЎаЭгђЩЯгУ@Lob
@Lob
private String description; |
oracleгГЩфзжЖЮЕФРраЭЪЧCLOBЃЌjava.sql.Clob, Character[], char[]
КЭ java.lang.String НЋБЛГжОУЛЏЮЊ Clob РраЭЁЃ
mysqlжагГЩфзжЖЮЕФРраЭЪЧlongtextЁЃ
3.5.2 дкЖўНјжЦЕШРраЭгђЩЯгУ@Lob
oracleжаjava.sql.Blob, Byte[], byte[] КЭ SerializableЪЕЯжРрНЋБЛГжОУЛЏЮЊ
Blob РраЭЁЃ
mysqlжаЖдгІlongblobЁЃ
@LobГжОУЛЏЮЊBlobЛђепClobРраЭ,ИљОнgetЗНЗЈЕФЗЕЛижЕВЛЭЌЃЌздЖЏНјааClobКЭBlobЕФзЊЛЛЁЃ
3.5.3 ДѓЖдЯѓзжЖЮЕФбгГйМгди
@Lob
@Basic(fetch=FetchType.LAZY)
private Byte[] file; |
вђЮЊДѓЖдЯѓЪ§ОнвЛАуеМгУЕФФкДцПеМфБШНЯДѓЃЌЫљвдЭЈГЃЪЙгУбгГйМгдиЕФЗНЪНЃК@BasicзЂНтЩшжУМгдиЗНЪНЮЊFetchType.LAZYЁЃ
ЮЪЬтЃК
бгГйМгдиЪЧбгГйЕНЪВУДЪБКђЃПетИіЮЪЬтвЛжБУЛгаевЕНШЗЧаЕФНтД№ЁЃ
4. ГЃгУRepositoryПЊЗЂ
4.1 RepositoryНгПк
| public interface
Repository<T, ID> |
зюЛљДЁЕФRepositoryНгПкЃЌВЛЬсЙЉШЮКЮВйзїЗНЗЈЁЃ
4.2 CrudRepositoryНгПк
| public interface
CrudRepository<T, ID> extends Repository<T,
ID> |
ЬсЙЉCRUDЛљБОВйзїЕФRepositoryНгПкЁЃ
4.3 PagingAndSortingRepository НгПк
| public interface
PagingAndSortingRepository<T, ID> extends
CrudRepository<T, ID> |
ЫќМЬГа CrudRepository НгПкЃЌдк CrudRepository ЛљДЁЩЯаТдіСЫСНИігыЗжвГгаЙиЕФЗНЗЈЁЃ
вВПЩвдВЛНЋздЖЈвхЕФГжОУВуНгПкжБНгМЬГаPagingAndSortingRepositoryЃЌЖјЪЧМЬГа
Repository Лђ CrudRepository ЕФЛљДЁЩЯЃЌдкздЖЈвхЗНЗЈВЮЪ§СаБэзюКѓдіМгвЛИі
Pageable Лђ Sort РраЭЕФВЮЪ§ЃЌгУгкжИЖЈЗжвГЛђХХађаХЯЂЃЌПЩвдЪЕЯжБШжБНгМЬГа PagingAndSortingRepository
ИќДѓЕФСщЛюадЁЃ
4.4 JpaRepositoryНгПк
| public interface
JpaRepository<T, ID> extends PagingAndSortingRepository<T,
ID>, QueryByExampleExecutor<T> |
JpaRepository МЬГаPagingAndSortingRepositoryЃЌЪЧеыЖд JPA
ММЪѕЬсЙЉЕФНгПкЃЌЫќдкИИНгПкЕФЛљДЁЩЯЃЌЬсЙЉСЫЦфЫћвЛаЉЗНЗЈЃЌБШШчflush()ЃЌsaveAndFlush()ЃЌdeleteInBatch()
ЕШЁЃ
4.5 здЖЈвхJPA RepositoryЗНЗЈ
здЖЈвхJPA RepositoryЗНЗЈЃЌгІВЮПМвдЯТЙцЗЖЃК
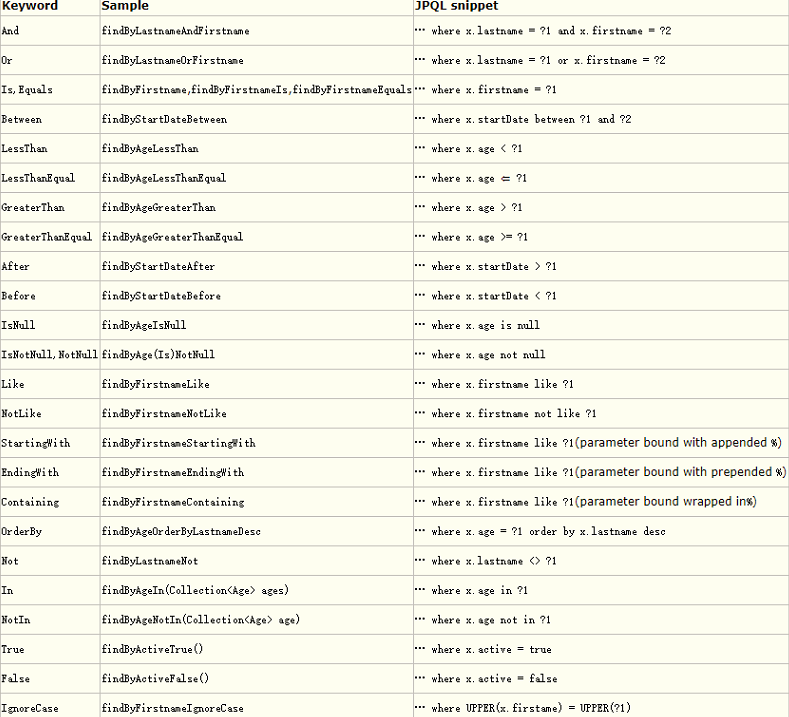
зЂвтСНЕуЃК
ГіЯждкЗНЗЈУћжагУгкзщКЯВщбЏЬѕМўЕШЕФЪЧЪЕЬхРрЕФгђУћГЦЃЌЖјВЛЪЧЪ§ОнПтЕФБэзжЖЮЃЛ
етжжЗНЪНгУРДзщКЯвЛаЉЙЬЖЈФЃЪНЕФSQLЃЌЩњГЩSQLЕФЙ§ГЬЖдГЬађдБЪЧЭИУїЕФЃЌГЬађдБВЛгУздМКаДSQLЁЃ
4.6 @QueryзЂНт
org.springframework.data.jpa.repository.QueryзЂНтгУРДжИЖЈJPA
RepositoryЗНЗЈЖдгІЕФВщбЏHSQLЁЃ
ЪОР§ЃК
import org.springframework.data.repository.query.Param;
//...
@Query("select a from App a where a.name
LIKE %:name%")
List<App> findByName(@Param("name")
String name); |
ашвЊзЂвтЕФЪЧЃЌ@QueryжаЕФВЮЪ§HQLФЌШЯВЛЪЧецЪЕЕФSQLгяОфЃЌЖјЪЧУцЯђЖдЯѓЕФЁЃ
ЭЈГЃЮвУЧПЩвдЪЙгУ@TableжИЖЈЪЕЬхРрЖдгІЕФБэУћЃЌШчЙћЪЕЬхРрЕФРрУћКЭЖдгІЕФБэУћВЛЭЌЃЌ@QueryжагІИУЪЙгУРрУћЃЌЭЌЪБВЮЪ§HQLжаЪЙгУЕФЪЧЪЕЬхРрЕФгђУћГЦЖјВЛЪЧЪЕМЪЕФзжЖЮУћЁЃ
ШчВЛетбљЃЌР§Шчдк@QueryЕФВЮЪ§HQLжаЪЙгУСЫЪЕМЪЕФБэУћЖјЗЧЪЕЬхРрУћЃЌдђЛсБЈЃКQuerySyntaxException:
XXX is not mapped.ЁЃ
ШчЙћЯЃЭћЪЙгУдЩњSQLЃЌНЋ@Query#nativeQueryЩшжУЮЊtrueМДПЩЃК
@Query(nativeQuery
= true, value = "SELECT * FROM AUTH_USER
WHERE name = :name1 OR name = :name2 ")
List<UserDO> findSQL(@Param("name1")
String name1, @Param("name2") String
name2); |
4.7 @ModifyingзЂНт
org.springframework.data.jpa.repository.ModifyingзЂНтБъЪЖвЛИіJPA
RepositoryЗНЗЈЖдгІЕФSQLЛсаоИФЪ§ОнПтЁЃ
ЪОР§ЃК
@Modifying
@Query("update appnamespace set isDeleted=1,
dataChangeLastModifiedBy = ?3 where appId = ?1
and name = ?2")
int delete(String appId, String namespaceName,
String operator); |
| 








