| 编辑推荐: |
本文主要讲解Spring
Data 的核心接口 ,Query 方法 ,调整Repository接口,Repository
的NULL处理等希望对您能有所帮助。
本文来自于简书,由火龙果软件Delores编辑推荐 |
|
核心概念
Repository
Repository 是Spring Data 的核心接口 。 它将domain 类 和 domain 类的ID作为管理参数 。 其他的Repository都继承实现该接口。 如CrudRepository :
public interface
CrudRepository<T,
ID extends Serializable>
extends Repository<T, ID> {
<S extends T> S save(S entity);
Optional<T> findById(ID primaryKey);
Iterable<T> findAll();
long count();
void delete(T entity);
boolean existsById(ID primaryKey);
// … more functionality omitted.
} |
其他特定技术的抽象如 JpaRepository or MongoRepository 都是CrudRepository的子类。
在CrudRepository上层还有一个抽象接口 PagingAndSortingRepository , 提供分页排序功能:
public interface
PagingAndSortingRepository<T,
ID extends Serializable>
extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
} |
Query 方法
使用spring data 进行数据查询有如下四个步骤:
声明一个接口, 该接口需要继承Repository 或其子接口 ,并提供domain 类和id参数, 如下:
interface PersonRepository
extends
Repository<Person, Long> { … } |
在该接口中声明查询方法:
interface PersonRepository
extends
Repository<Person, Long> {
List<Person> findByLastname
(String lastname);
} |
使用spring建立该接口的代理接口, 可以通过JavaConfig 或 Xml 配置。
3.1 使用Javaconfig
import org.springframework.data.jpa.
repository.config.EnableJpaRepositories;
@EnableJpaRepositories
class Config {} |
3.2 使用xml配置
<?xml version="1.0"
encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.repositories"/>
</beans> |
上例使用了JPA名称空间。若使用其他的数据源,需要修改为其他的名称空间 。
注意:javaConfig 并咩有显示声明包名称, 因为默认会使用注解所在的包。 要修改默认需要使用 basePackage属性。
注入repository实例并使用之 :
class SomeClient
{
private final PersonRepository repository;
SomeClient(PersonRepository repository) {
this.repository = repository;
}
void doSomething() {
List<Person> persons = repository.
findByLastname("Matthews");
}
} |
后续章节将详细介绍这4个步骤。
定义Repository 接口
首先,定义repository接口,需要指定domain class 和id 类型 , 可以直接继承Repository接口,或者其子接口如CrudRepository 。
调整Repository接口
一般的,定义repository接口需要继承 Repository, CrudRepository, or PagingAndSortingRepository. 但如果不想使用Spring data提供的接口,也可以自定义 。自定义接口上加 @RepositoryDefinition 注解。
当继承CrudRepository时, 会暴露所有的CRUD接口, 若不想暴露那么多 , 则可以直接从Repository继承, 如下所示:
@NoRepositoryBean
interface MyBaseRepository<T,
ID extends Serializable>
extends
Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
interface UserRepository extends
MyBaseRepository<User,
Long> {
User findByEmailAddress
(EmailAddress emailAddress);
} |
例中, UserRepository 只会暴露 findById 、save findByEmailAddress接口, 不会暴露其他的 。
注意: @NoRepositoryBean 使spring data 不会生成相应repository的实例, 用在中间repository定义上。
Repository 的NULL处理
从spring data 2.0 开始 , repository的方法使用java 8 的Optional来表示可能缺少的值。 除此之外,spring data还为查询提供如下的封装类:
com.google.common.base.Optional
scala.Option
io.vavr.control.Option
javaslang.control.Option (deprecated as Javaslang is deprecated)
另外, 查询方法可以选择不使用这些封装类。 通过返回null表示没有查询结果 。 Repository 方法返回集合、变种集合、封装、流 时会保证不会出现null , 而是返回相应的空。
repository 方法的可空注解如下:
@NonNullApi : 在包级别上使用,以声明参数和返回值的默认行为是不接受或生成空值。
@NonNull : 使用在参数或返回值上,他们不能为null (在使用了@NonNullApi时不需要。)
@Nullable : 使用在参数或返回值上, 表示可以为null。
如:在package-info.java 上声明:
@org.springframework.lang.NonNullApi
package com.acme; |
如例:
package com.acme;
// 该包定义在我们声明的non-null包中;
import org.springframework.lang.Nullable;
interface UserRepository extends
Repository<User,
Long> {
// 当返回为空时抛出 EmptyResultDataAccessException
异常,当输入参数emailAddress空时抛出
IllegalArgumentException
User getByEmailAddress(EmailAddress emailAddress);
@Nullable
// 允许输入参数为空; 允许返回空值
User findByEmailAddress
(@Nullable EmailAddress
emailAdress);
// 当没有查询结果时返回Optional.empty() ;
当输入emailAddress为空时抛出
IllegalArgumentException
Optional<User> findOptionalByEmailAddress
(EmailAddress
emailAddress);
} |
多数据源repository
当使用单一spring data module时,会很简单, 因为所有的repository都会绑定到该模块上。 但是当应用要求多个数据module时, 需要明确repository使用的模块 。
当spring 检查到引入多个数据module时, 他会按照如下规则进行判断:
repository 是否继承自特定数据源, 将根据特定数据源进行判断。
domain 类上是否有特定数据源的注解, spring data支持第三方的注解(如JPA的@Entity ) , 也有自己的注解 (如Mongo和Elasticsearch的@Document )
如下例子显示了使用JPA的例子:
interface MyRepository
extends
JpaRepository<User, Long> { }
@NoRepositoryBean
interface MyBaseRepository<T,
ID extends
Serializable> extends
JpaRepository<T,
ID> {
…
}
interface UserRepository extends
MyBaseRepository<User,
Long> {
…
} |
MyRepository and UserRepository 继承自JpaRepository , 会使用spring data JPA。
如下例子 repository 继承通用的repository:
interface AmbiguousRepository
extends
Repository<User, Long> {
…
}
@NoRepositoryBean
interface MyBaseRepository<T, ID
extends
Serializable> extends
CrudRepository<T,
ID> {
…
}
interface AmbiguousUserRepository
extends MyBaseRepository<User,
Long> {
…
} |
通过上述继承关系是无法判断的 。
在定义user类时, 若使用@Entity ,则使用的是 JPA ; 若使用的是@Document , 则使用的是mongo。
如下例子在person上同时使用了两个注解, 会引发异常:
interface JpaPersonRepository
extends
Repository<Person, Long> {
…
}
interface MongoDBPersonRepository
extends Repository<Person,
Long> {
…
}
@Entity
@Document
class Person {
…
} |
在同一domain类型上使用多个持久性技术特定的注释是可能的,并允许跨多种持久性技术重用域类型。 但是,Spring Data不再能够确定用于绑定存储库的唯一模块。
区分repository的最后一种方法是定义使用repository的范围。 基础包定义了扫描repository接口定义的起点,这意味着将repository定义放在相应的包中。 默认情况下,注释驱动的配置使用配置类的包。 基于XML的配置中的基本包是必需的。
@EnableJpaRepositories(basePackages
= "com.acme.repositories.jpa")
@EnableMongoRepositories(basePackages
= "com.acme.repositories.mongo")
interface Configuration { } |
定义查询方法
有两种方式来确定查询方法:
根据方法名推断
手工定义查询
查询策略
使用XML配置,您可以通过query-lookup-strategy属性在命名空间配置策略。 对于Java配置,您可以使用Enable $ {store}存储库注释的queryLookupStrategy属性。 特定数据存储可能不支持某些策略。
CREATE: 从方法名构造特定数据源的查询语句 。 一般方法是去掉方法前缀,解析其余部分。后面有详细介绍。
USE_DECLARED_QUERY : 查找声明的查询,未找到则会抛出异常 。 可以是注解或其他方式。 repository在启动时尝试查找相应数据源的声明, 未找到则fail。
CREATE_IF_NOT_FOUND : 默认选项。 结合 CREATE and USE_DECLARED_QUERY 。 它首先查找声明,未声明则创建一个基于方法名的查询 。 这是默认方式。 它允许根据方法名快速定义,也允许自定义查询 。
Query Creation
其机制是剥离前缀find ... By,read ... By,query ... By,count ... By,and get ...By ,然后解析其余部分。同时也可以使用And Or distinct等等。
例:
interface PersonRepository
extends
Repository<User, Long> {
List<Person> findByEmailAddressAndLastname
(EmailAddress
emailAddress, String lastname);
// Enables the distinct flag for the query
List<Person> findDistinctPeopleByLastnameOr
Firstname(String
lastname, String firstname);
List<Person> findPeopleDistinctByLastnameOr
Firstname(String
lastname, String firstname);
// Enabling ignoring case for an
individual
property
List<Person> findByLastnameIgnoreCase
(String
lastname);
// Enabling ignoring case for all
suitable properties
List<Person> findByLastnameAnd
FirstnameAllIgnoreCase
(String
lastname, String firstname);
// Enabling static ORDER BY for a query
List<Person> findByLastnameOrderByFirstnameAsc
(String
lastname);
List<Person> findByLastnameOrderByFirstnameDesc
(String
lastname);
} |
最终的语句依赖不同的数据源有所不同, 但是有些共同的部分:
表达式是属性和运算符的结合, 支持AND 、 OR 、Between 、LessThen 、GreaterThen 、like 等, 另外因数据源不同有些操作符也不同。
方法解析器支持为各个属性设置IgnoreCase标志(例如,findByLastnameIgnoreCase(...))或支持所有属性忽略大小写(通常是String实例 - 例如,findByLastnameAndFirstnameAllIgnoreCase(...))。 是否支持忽略大小写可能因数据源不同而异,因此请参阅参考文档中有关查询方法的相关章节。
排序, 使用OrderBy后接字段来实现, 并可以指定方向(Asc或Desc)
属性表达式
如 : person中定义了Address , address 有zipCode字段:
List< Person > findByAddressZipCode(ZipCode zipCode);
spring data 会尝试去判断在哪儿进行分割 ,有可能会出现错误。
建议使用进行显示分割,以防其分割错误:
List< Person > findByAddress_ZipCode(ZipCode zipCode);
但是,在java中是保留字符, 不建议使用, 建议使用驼峰结构来表示。
特殊参数处理
特定参数指分页 排序, Pageable and Sort 。 这俩参数将被特殊对待。
如下:
Page<User>
findByLastname
(String lastname, Pageable pageable);
Slice<User> findByLastname
(String lastname,
Pageable pageable);
List<User> findByLastname
(String lastname,
Sort sort);
List<User> findByLastname
(String lastname,
Pageable pageable); |
第一个方法传入参数 org.springframework.data.domain.Pageable 以生成动态分页查询。 返回的Page对象有全部页数信息和当前页信息。 全部页数信息是通过一个计数语句完成的。这在某些数据源上可能会比较昂贵。 另一种方式是返回Slice结构, 该结构会包含一个是否还有下一页数据字段,这对大数据集非常有用。
Pageable 实例同时会处理sort 。 若只需要sort ,可以直接使用 org.springframework.data.domain.Sort 。 分页也可以只返回List, 这样不会触发count查询, 但是这只适用于查询给定范围的信息。
限制查询结果
查询结果可以通过附加first 和top 关键字来返回一部分数据。 first 和top后跟一个数字, 若没有数字, 则默认为1 。
例子:
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname
(String
lastname, Pageable pageable);
Slice<User> findTop3ByLastname
(String
lastname, Pageable pageable);
List<User> findFirst10ByLastname
(String
lastname, Sort sort);
List<User> findTop10ByLastname
(String
lastname, Pageable pageable); |
限制查询支持Distinct 关键字。 查询结果也可以包装为Optional。
若限制查询中使用了 page 或slice , 则是对限制查询后的结果进行page 或slice 。
流化查询结果
可以将查询结果返回为Java8 Stream< T > 结构, 或者使用特定数据源的stream查询。
例子:
@Query("select
u from User u")
Stream<User> findAllByCustomQueryAndStream();
Stream<User> readAllByFirstnameNotNull();
@Query("select u from User u")
Stream<User> streamAllPaged(Pageable pageable); |
使用stream 需要在使用完后进行close , 可以手工close , 或使用try-with-resources结构:
try (Stream<User>
stream = repository.
findAllByCustomQueryAndStream())
{
stream.forEach(…);
} |
注意: 不是所有的spring data模块都支持stream
异步查询
某些数据源支持异步查询, 查询方法会立即返回 , 但是不会立即出结果 。
@Async
Future<User> findByFirstname
(String firstname);
@Async
CompletableFuture<User> findOneByFirstname
(String
firstname);
@Async
ListenableFuture<User> findOneByLastname
(String
lastname);
Use java.util.concurrent.Future as the return
type.
Use a Java 8 java.util.concurrent.
CompletableFuture
as the return type.
Use a org.springframework.util.concurrent.
ListenableFuture
as the return type. |
创建Repository 实例
定义完repository接口后, 需要定义该接口实例 。 一种方法是使用spring data module提供的名称空间配置, 但我们建议使用java configuration 。
xml 配置
每个spring data module 都包含一个 repositories 元素 , 它定义一个将扫描的base package
<?xml version="1.0"
encoding="UTF-8"?>
<beans:beans xmlns:beans=
"http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<repositories base-package="com.acme.repositories"
/>
</beans:beans> |
上例中, spring 将会扫描com.acme.repositories 及其子package ,寻找repository及其子接口。 对于每个找到的接口 , spring 都会使用特定数据源的FactoryBean 来创建合适的代理。 每个bean都会注册一个同接口名的bean 。 例如 UserRepository 接口的bean名即为UserRepository 。 另外 base-package属性支持通配符。
使用过滤的例子:
<repositories
base-package
="com.acme.repositories">
<context:exclude-filter type="regex"
expression=".*SomeRepository" />
</repositories> |
支持 < include-filter /> and < exclude-filter /> 过滤 。
javaConfig
在类上使用注解 @Enable${store}Repositories 可以同样实例化repository 。
如下例子 配置一个JPA:
@Configuration
@EnableJpaRepositories
("com.acme.repositories")
class ApplicationConfiguration {
@Bean
EntityManagerFactory entityManagerFactory(){
// …
}
} |
@Configuration @Bean
@Bean注解的角色与 xml中配置< bean >标签的角色一样。 其作用的方法上, 指示方法实例化、配置、初始化由Spring IoC容器管理的新对象。
@Bean可与Spring @Component一起使用,但是,它们最常用于@Configuration bean。
@Configuration 注解使用在类上 , 作为bean的定义源。在类中通过简单调用@Bean方法来表示bean间依赖关系。
如:
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyServiceImpl();
}
}
等同于xml配置如下:
<beans>
<bean id="myService" class="com.acme.
services.MyServiceImpl"/>
</beans> |
当@Bean 与 @Configuration一起使用时, @Bean可以定义bean间的依赖。
但当@Bean不与@Configuration一起使用时, 只是使用了Bean 工厂,不定义依赖。
独立使用
可以在Spring 容器之外使用repository 。 例如, 在CDI环境 。 但仍然需要spring librries。 spring data模块提供特定数据源的RepositoryFactory 以支持repository。 例:
RepositoryFactorySupport
factory
= … // Instantiate factory here
UserRepository repository
= factory.getRepository(UserRepository.class); |
自定义实现repository
首选自定义一个接口 , 如
interface CustomizedUserRepository
{
void someCustomMethod(User user);
} |
实现该接口 , 接口实现类必须以Impl结尾
class CustomizedUserRepositoryImpl
implements CustomizedUserRepository {
public void someCustomMethod(User user) {
// Your custom implementation
}
} |
定义repository时继承标准的repository和该自定义的
interface UserRepository
extends
CrudRepository<User, Long>,
CustomizedUserRepository
{
// Declare query methods here
} |
这样客户端即可使用自定义实现的方法了 。
(当然也 同时支持多个自定义repository)
优先级
自定义方法的优先级高于通用repository 和 特定存储库提供的。
可以在自定义中覆盖通用或特定存储库的方法。
xml配置
当使用xml配置时, 同样遵循impl后缀原则 。 spring会扫描base-package下的自定义实现。
<repositories
base-package=
"com.acme.repository" />
<repositories base-package=
"com.acme.repository"
repository-impl-postfix="MyPostfix"
/> |
可以通过配置修改默认后缀, 如上。
歧义处理
若多个相同类名的 实现在不同的package中发现 , spring data 通过bean名称来确定使用哪一个。
例:
package com.acme.impl.one;
class CustomizedUserRepositoryImpl implements
CustomizedUserRepository {
// Your custom implementation
}
package com.acme.impl.two;
@Component("specialCustomImpl")
class CustomizedUserRepositoryImpl implements
CustomizedUserRepository {
// Your custom implementation
} |
如上有CustomizedUserRepository 的两个实现, 则第一个实现的bean名符合约定, 使用之。
自定义base repository
如果需要为所有的repository添加base实现, 可以通过实现特定数据源的repository来实现。
class MyRepositoryImpl<T,
ID extends Serializable>
extends SimpleJpaRepository<T, ID> {
private final EntityManager entityManager;
MyRepositoryImpl(JpaEntityInformation
entityInformation,
EntityManager entityManager) {
super(entityInformation, entityManager);
// Keep the EntityManager around to used
from
the newly introduced methods.
this.entityManager = entityManager;
}
@Transactional
public <S extends T> S save(S entity)
{
// implementation goes here
}
} |
配置时需要使用
@Configuration
@EnableJpaRepositories(repositoryBaseClass
= MyRepositoryImpl.class)
class ApplicationConfiguration { … } |
或
<repositories
base-package="com.acme.repository"
base-class="….MyRepositoryImpl" /> |
Aggregate roots 事件发布
在Domain-Driven Design 应用中, 聚合根发布domain 事件。
在domain类的方法中使用。
使用@DomainEvents 发布事件
使用@AfterDomainEventPublication 清理事件
这些方法会在调用save时被调用。
Spring data 扩展
目前,大多数扩展都是扩展spring mvc。
Querydsl扩展
Querydsl是一个框架,可以通过其流畅的API构建静态类型的SQL类查询。
有几款spring data module 通过 QuerydslPredicateExecutor 提供 Querydsl的整合。 如下:
public interface
QuerydslPredicateExecutor<T> {
Optional<T> findById(Predicate predicate);
Iterable<T> findAll(Predicate predicate);
long count(Predicate predicate);
boolean exists(Predicate predicate);
// … more functionality omitted.
} |
Finds and returns a single entity matching the Predicate.
Finds and returns all entities matching the Predicate.
Returns the number of entities matching the Predicate.
Returns whether an entity that matches the Predicate exists.
然后通过继承QuerydslPredicateExecutor 来使用之:
interface UserRepository
extends
CrudRepository<User, Long>,
QuerydslPredicateExecutor<User>
{
} |
使用如下:
Predicate predicate
= user.firstname.
equalsIgnoreCase("dave")
.and(user.lastname.startsWithIgnoreCase
("mathews"));
userRepository.findAll(predicate); |
Web 支持
通过在configurationclass 上添加注解 @EnableSpringDataWebSupport 来支持:
@Configuration
@EnableWebMvc
@EnableSpringDataWebSupport
class WebConfiguration {} |
@EnableSpringDataWebSupport 会自动添加几个组件。 另外他还会检测classpath上是否有HATEOAS , 有则自动注册之。
若使用基于xml的配置, 见下:
<bean class="org.springframework.data.web.
config.SpringDataWebConfiguration"
/>
<!-- If you use Spring HATEOAS, register
this one *instead* of the former -->
<bean class="org.springframework.data.web.config.
HateoasAwareSpringDataWebConfiguration"
/> |
基础web 支持
DomainClassConverter : 让Spring MVC从请求参数或路径变量中解析domain类的实例。
HandlerMethodArgumentResolver : 让spring mvc 从请求参数中解析Pageable 和Sort实例。
DomainClassConverter
DomainClassConverter 允许在spring mvc中直接使用domain类, 而不用手工查找:
@Controller
@RequestMapping("/users")
class UserController {
@RequestMapping("/{id}")
String showUserForm(@PathVariable("id")
User user, Model model) {
model.addAttribute("user", user);
return "userForm";
}
} |
该方法接收一个User实例,spring mvc 通过解析请求信息为id类型,然后调用findById方法。
HandlerMethodArgumentResolvers
web支持会同时注册PageableHandlerMethodArgumentResolver 和 SortHandlerMethodArgumentResolver 。 这样controller就可以使用Pageable 和sort。
例 :
@Controller
@RequestMapping("/users")
class UserController {
private final UserRepository repository;
UserController(UserRepository repository)
{
this.repository = repository;
}
@RequestMapping
String showUsers(Model model,
Pageable pageable)
{
model.addAttribute("users",
repository.findAll(pageable));
return "users";
}
} |
例中, spring mvc 将请求参数转换为Pageable ,涉及如下参数:
page : 想要获取的页码,从0开始 ,默认为0
size : 每页条数 , 默认20
sort : 排序属性 ,以property的格式 property,property(,ASC|DESC) 。默认是升序 。 支持多个参数,如: ?sort=firstname&sort=lastname,asc
要自定义该行为, 通过实现接口 PageableHandlerMethodArgumentResolverCustomizer 和 SortHandlerMethodArgumentResolverCustomizer , 实现其中的customize()方法。
若修改MethodArgumentResolver 满足不了需求, 可以通过继承SpringDataWebConfiguration 或 HATEOAS-enabled equivalent , 重写 pageableResolver() or sortResolver() 方法 ,导入自定义配置而不是使用@Enable注解。
若需要从request中解析出多组Pageable 或sort ,如多table情况, 可以使用spring 的@Qualifier标签。 同时request的参数前需要加${qualifier}_前缀 。 例:
String showUsers(Model
model,
@Qualifier("thing1") Pageable first,
@Qualifier("thing2") Pageable second)
{ … } |
默认传递到方法中的pageable 等同于 new PageRequest(0, 20) , 可以通过在Pageable参数上加注解@PageableDefault 来自定义 。
超媒体分页
Spring HATEOAS 提供PagedResources类来丰富分页信息。
将Page转换为PagedResources 由PagedResourcesAssembler 实现。
@Controller
class PersonController {
@Autowired PersonRepository repository;
@RequestMapping(value = "/persons",
method = RequestMethod.GET)
HttpEntity<PagedResources<Person>>
persons(Pageable pageable,
PagedResourcesAssembler assembler) {
Page<Person> persons
= repository.findAll(pageable);
return new ResponseEntity<>
(assembler.toResources(persons),
HttpStatus.OK);
}
} |
web 数据绑定
spring data 的projections(预测)可以用来绑定请求数据, 例子:
@ProjectedPayload
public interface UserPayload {
@XBRead("//firstname")
@JsonPath("$..firstname")
String getFirstname();
@XBRead("/lastname")
@JsonPath({ "$.lastname", "$.user.lastname"
})
String getLastname();
} |
对于spring mvc , 只要@EnableSpringDataWebSupport注解激活并且类路径上有相关的依赖, 则必要的转换器会自动被注册 。 要使用RestTemplate ,则需要手工注册 ProjectingJackson2HttpMessageConverter (JSON) or XmlBeamHttpMessageConverter 。
repository populators
当使用spring data jdbc模块时, 我们熟悉使用sql语言来与datasource交互 。 作为repository 级别的抽象, 不使用sql作为定义语言,因为他们是依赖数据源的。
populator 是支持json 和xml的 。
如有如下data.json文件:
[ { "_class"
: "com.acme.Person",
"firstname"
: "Dave",
"lastname" :
"Matthews" },
{ "_class" : "com.acme.Person",
"firstname" : "Carter",
"lastname" : "Beauford" }
] |
你可以使用repository命名空间的populator来操作repository 。 声明如下:
<?xml version="1.0"
encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:repository=
"http://www.springframework.org/schema/data/repository"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/repository
http://www.springframework.org/schema/data/repository/spring-repository.xsd">
<repository:jackson2-populator locations="classpath:data.json"
/>
</beans> |
上述data.json文件将由Jackson的ObjectMapper来读取并序列化。
Json根据文件中的_class 来确定序列化的对象。
下例显示如何声明使用JAXB来处理xml:
<?xml version="1.0"
encoding="UTF-8"?>
<beans xmlns=
"http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:repository="http://www.springframework.org
/schema/data/repository"
xmlns:oxm="http://www.springframework.org/schema/oxm"
xsi:schemaLocation=
"http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/repository
http://www.springframework.org/schema/data/repository/spring-repository.xsd
http://www.springframework.org/schema/oxm
http://www.springframework.org/schema/oxm/spring-oxm.xsd">
<repository:unmarshaller-populator
locations="classpath:data.json"
unmarshaller-ref="unmarshaller" />
<oxm:jaxb2-marshaller contextPath="com.acme"
/>
</beans> |
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:金刚_30bf
链接:https://www.jianshu.com/p/376b223d2b4a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
JVM被分为三个主要的子系统:类加载器子系统、运行时数据区、执行引擎
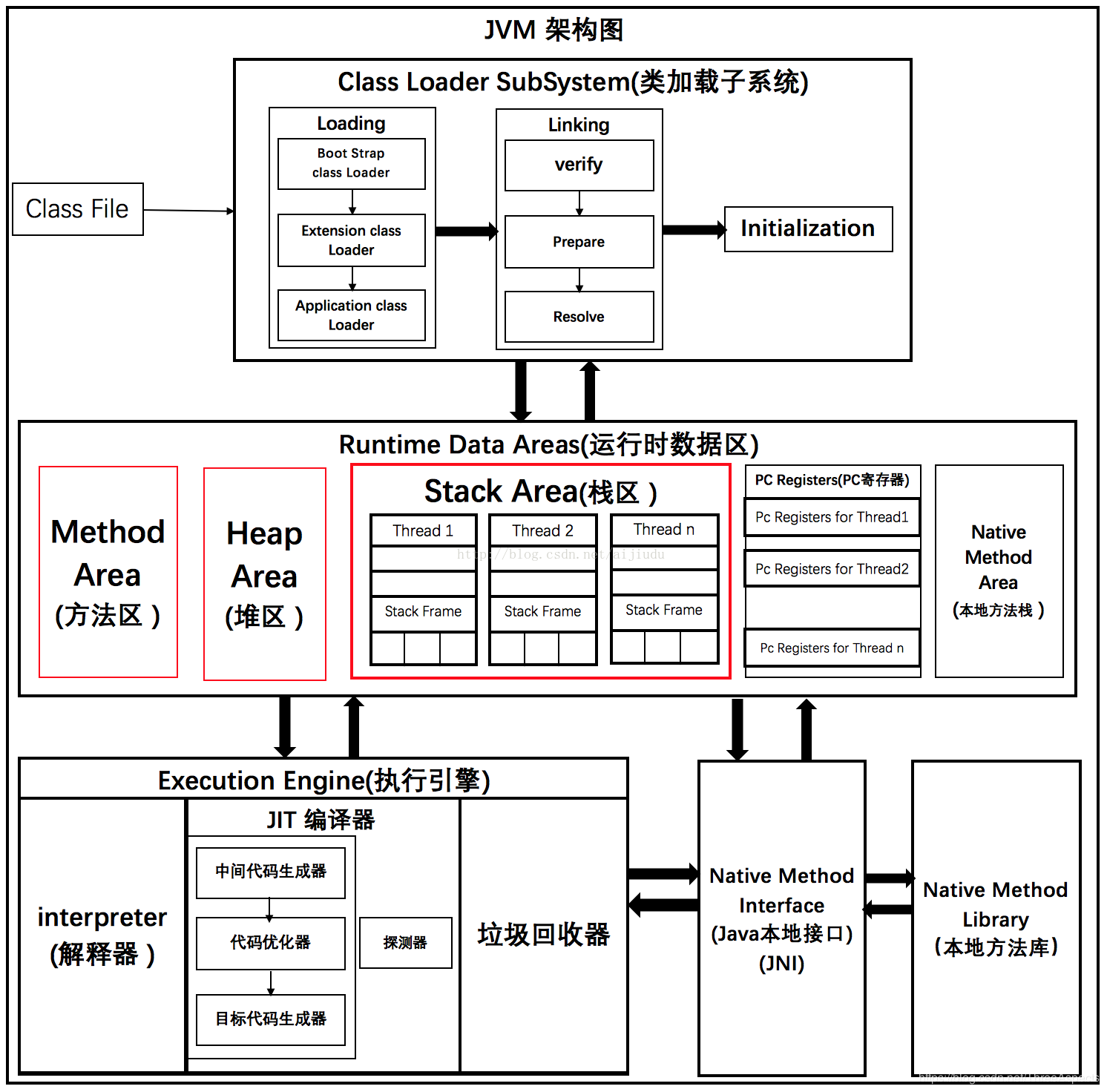
类加载器子系统
Java的动态类加载功能是由类加载器子系统处理。当它在运行时(不是编译时)首次引用一个类时,它加载、链接并初始化该类文件。
加载
类由此组件加载。启动类加载器 (BootStrap class Loader)、扩展类加载器(Extension class Loader)和应用程序类加载器(Application class Loader) 这三种类加载器帮助完成类的加载。
启动类加载器 – 负责从启动类路径中加载类,无非就是rt.jar。这个加载器会被赋予最高优先级
扩展类加载器 – 负责加载ext 目录(jre\lib)内的类
应用程序类加载器 – 负责加载应用程序级别类路径,涉及到路径的环境变量等
上述的类加载器会遵循委托层次算法(Delegation Hierarchy Algorithm)加载类文件。
链接
校验 – 字节码校验器会校验生成的字节码是否正确,如果校验失败,会得到校验错误
准备 – 分配内存并初始化默认值给所有的静态变量
解析 – 所有符号内存引用被方法区(Method Area)的原始引用所替代
初始化
这是类加载的最后阶段,这里所有的静态变量会被赋初始值, 并且静态块将被执行。
运行时数据区(Runtime Data Area)
运行时数据区域被划分为5个主要组件:
方法区(Method Area)
所有类级别数据将被存储在这里,包括静态变量。每个JVM只有一个方法区,它是一个共享的资源。
堆区(Heap Area)
所有的对象和它们相应的实例变量以及数组将被存储在这里。每个JVM同样只有一个堆区。由于方法区和堆区的内存由多个线程共享,所以存储的数据不是线程安全的。
栈区(Stack Area)
对每个线程会单独创建一个运行时栈。对每个函数呼叫会在栈内存生成一个栈帧(Stack Frame)。所有的局部变量将在栈内存中创建。栈区是线程安全的,因为它不是一个共享资源。栈帧被分为三个子实体:
局部变量数组 – 包含多少个与方法相关的局部变量并且相应的值将被存储在这里
操作数栈 – 如果需要执行任何中间操作,操作数栈作为运行时工作区去执行指令
帧数据 – 方法的所有符号都保存在这里。在任意异常的情况下,catch块的信息将会被保存在帧数据里面

PC寄存器
每个线程都有一个单独的PC寄存器来保存当前执行指令的地址,一旦该指令被执行,pc寄存器会被更新至下条指令的地址。
本地方法栈
本地方法栈保存本地方法信息。对每一个线程,将创建一个单独的本地方法栈。
执行引擎
分配给运行时数据区的字节码将由执行引擎执行。执行引擎读取字节码并逐段执行。
解释器
解释器能快速的解释字节码,但执行却很慢。 解释器的缺点就是,当一个方法被调用多次,每次都需要重新解释。
编译器
JIT编译器消除了解释器的缺点。执行引擎利用解释器转换字节码,但如果是重复的代码则使用JIT编译器将全部字节码编译成本机代码。本机代码将直接用于重复的方法调用,这提高了系统的性能。
中间代码生成器 – 生成中间代码
代码优化器 – 负责优化上面生成的中间代码
目标代码生成器 – 负责生成机器代码或本机代码
探测器(Profiler) – 一个特殊的组件,负责寻找被多次调用的方法。
垃圾回收器
收集并删除未引用的对象。可以通过调用"System.gc()"来触发垃圾回收,但并不保证会确实进行垃圾回收。JVM的垃圾回收只收集哪些由new关键字创建的对象。所以,如果不是用new创建的对象,你可以使用finalize函数来执行清理。
Java本地接口 (JNI):JNI 会与本地方法库进行交互并提供执行引擎所需的本地库。本地方法库:是一个执行引擎所需的本地库的集合。
| 







