| 编辑推荐: |
本文主要介绍了什么是solr,如何使用Lucene的案列对solr搜索引擎进行详细的搭建,希望本文对您的学习有所帮助。
本文来自博客园,由火龙果软件Alice编辑、推荐。 |
|
1、什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
* 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述
Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
* 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对Solr服务器返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建页面UI的功能,但是
提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
简单来说:Solr类似我们开发的web项目,是一个war包,把它放在tomcat下直接运行就好
2、Solr和Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
简单来说:如果不知道Lucene,那么配置Solr方面将寸步难行
有一个问题:我们可以使用数据库查询,为什么要用Solr呢?
答案:最大的一个原因是效率会高 很 多 ,还有其他原因,比如SQL无法做到相关度排序等等
另一个问题:我们为什么不用Lucene呢?
答案:Lucene的工作量过大,Solr是基于Lucene的框架,便捷完善,可配置可扩展,可以高效完成站内搜索功能
接下来就开始:
搭建solr服务器(Tomcat):
注意:solr本身可以运行,不过它是运行在jetty上的,相比Tomcat显得不稳定,所以我们要在tomcat中搭建Solr
准备一个Tomcat7和Solr4.10.3:网上下载即可

按这个路径找到solr.war复制到Tomcat的webapp下

然后把这个war包解压了:注意解压后把war包删了,因为solr文件夹里要添加其他东西,但是Tomcat每次启动都会解压war包覆盖,所以需要删了war包
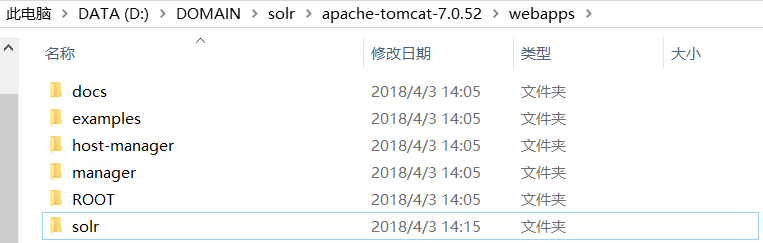
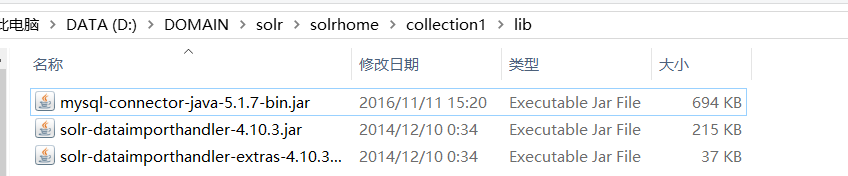
按目录找到这5个包:
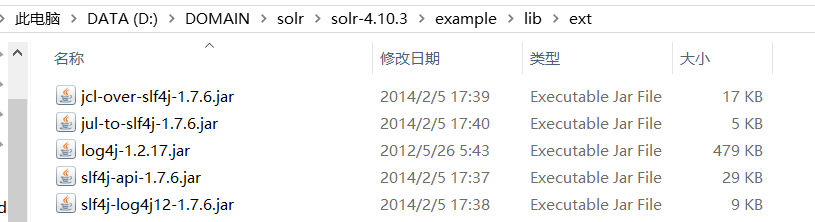
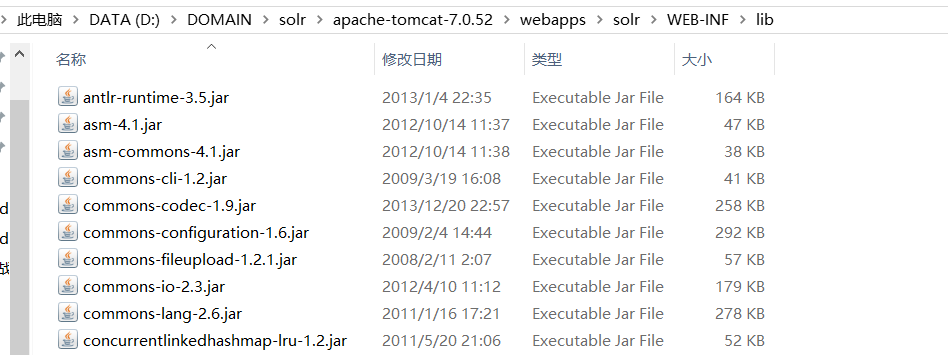
把它们复制到这个文件夹中:
接下来:在刚才的文件夹下新建一个文件夹:solrhome(充当索引库)
把这个路径的这些东西复制过去:
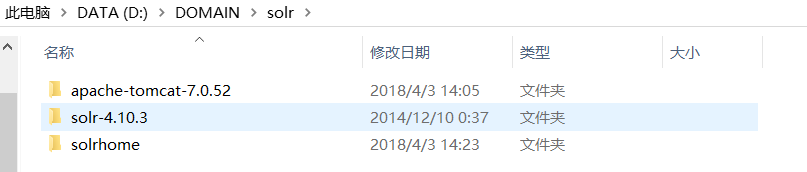
然后修改下这个配置文件:
在40行处修改如下:

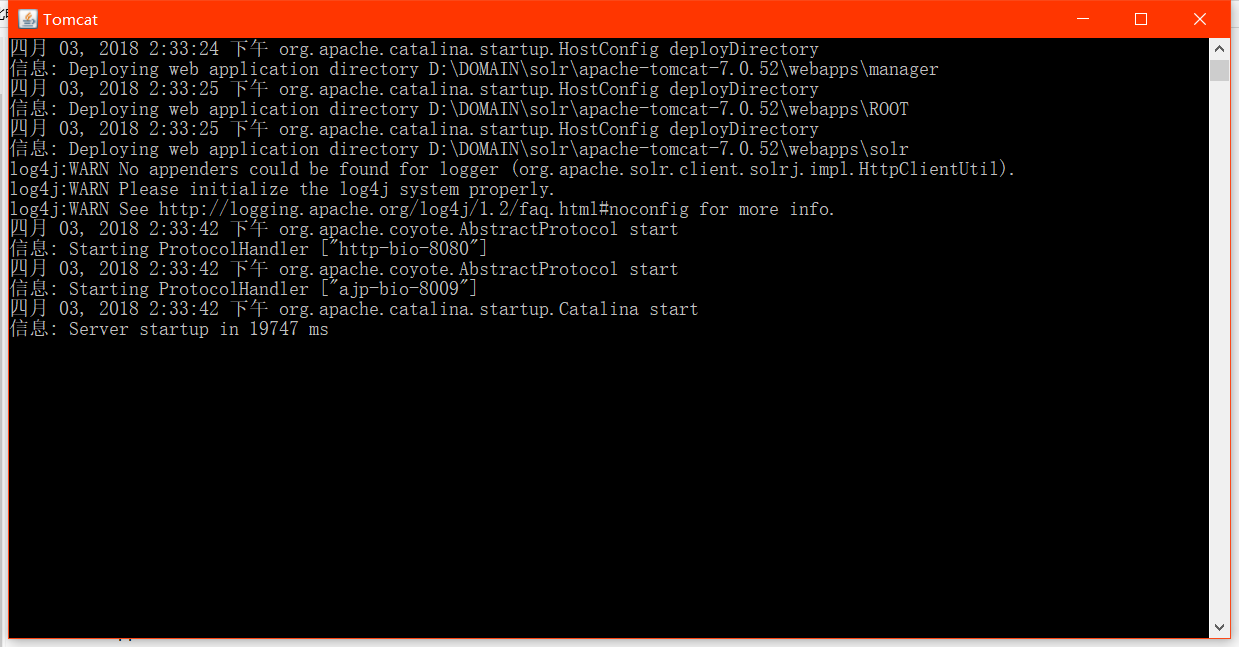
好的,启动Tomcat:

我访问8080:
到这里,搭建就成功了!
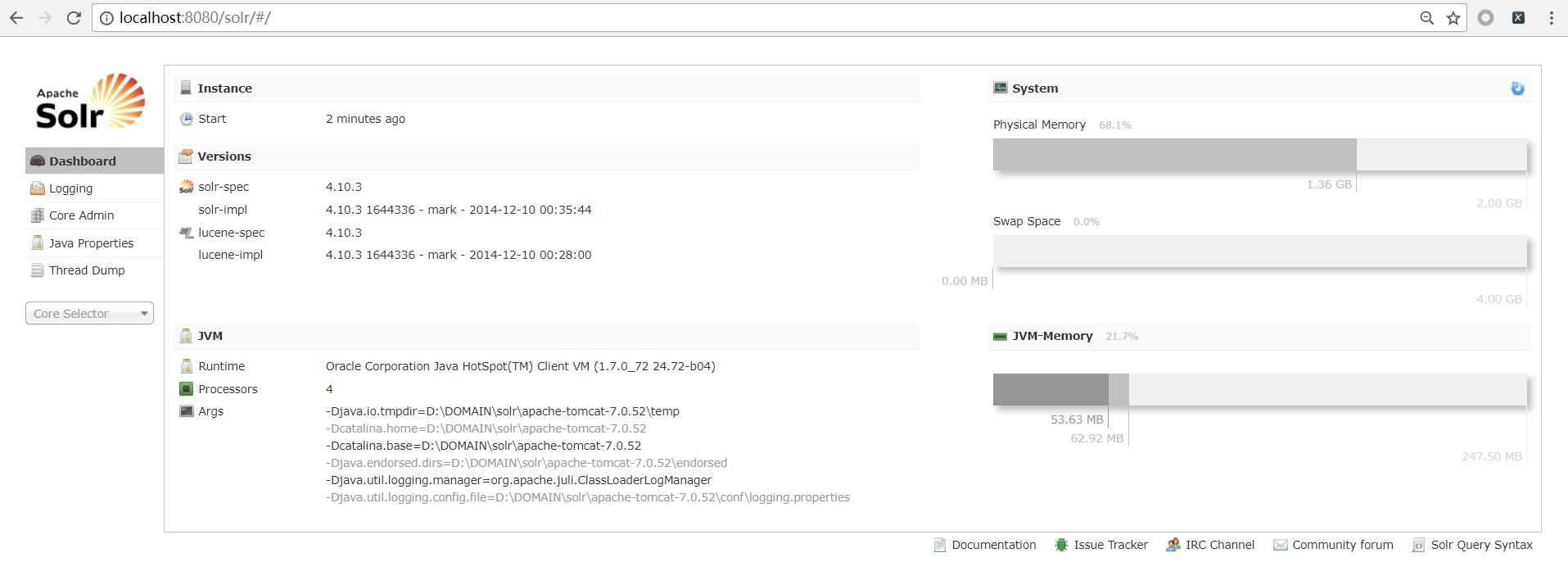
在这个页面就可以增删改查索引了!
比如增(注意必须有id):
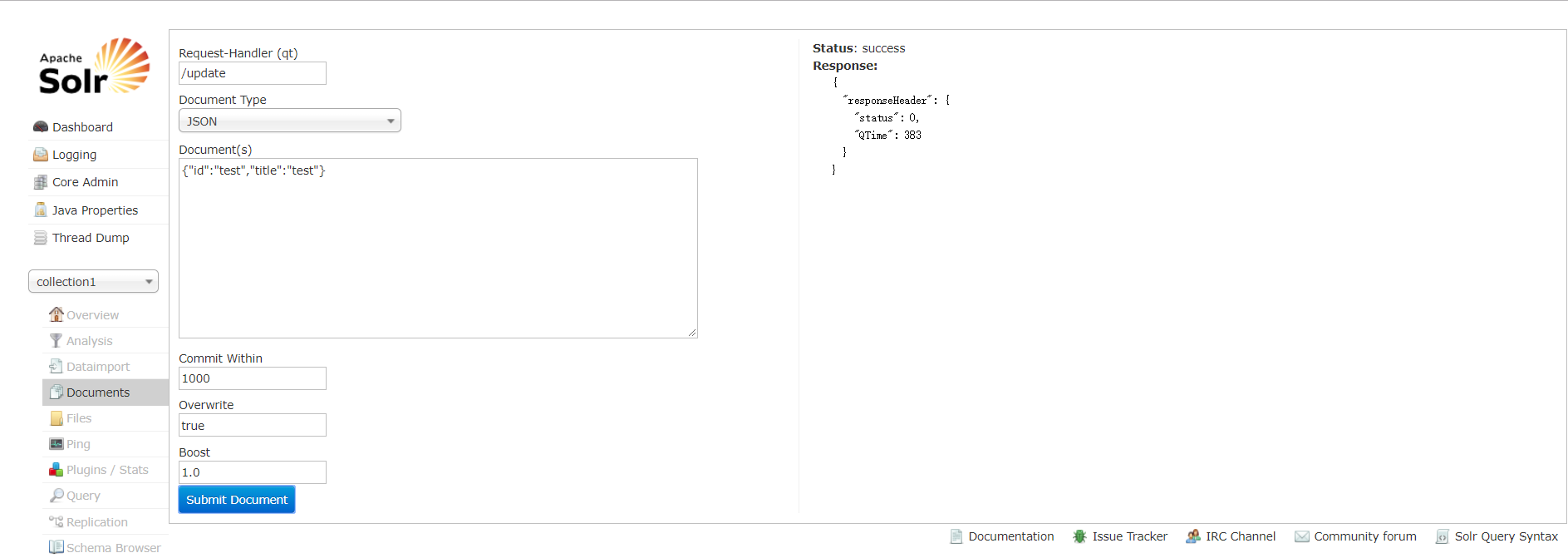
查:
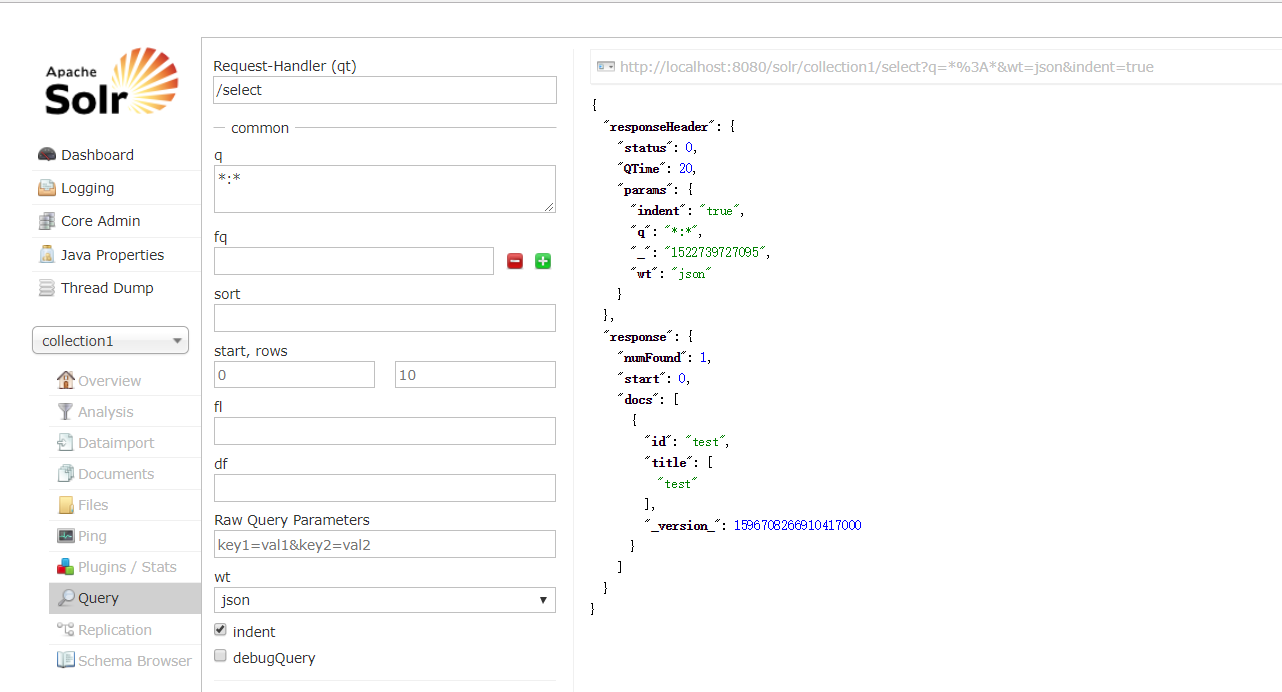
但是还没有结束:
接下来修改配置文件:
打开这里:我们需要关注的是这两个配置文件

好的,接下来就配置它们:
schema.xml:配置域相关的信息
可以打开看看,里面是域的相关信息,只有里面存在的域才可以使用!
当然,里面还有一种动态域,比如*_s,*_i等等,前缀可以任意写

看看另一个配置文件:
这里要配置中文分词器
先导入这个包:

新建一个文件夹放入IK分析器配置文件:
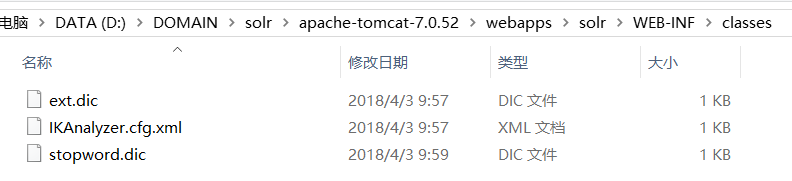
注意三个文件的格式:UTF-8无BOM格式编辑
接下来:在刚才提到的schema.xml中配置:加上这一段
| <fieldType
name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<field name="title_ik" type="text_ik"
indexed="true"
stored="true"/>
<field name="content_ik" type="text_ik"
indexed="true"
stored="false" multiValued="true"/> |
新建的这两个域支持IK分析器
测试下:重启Tomcat
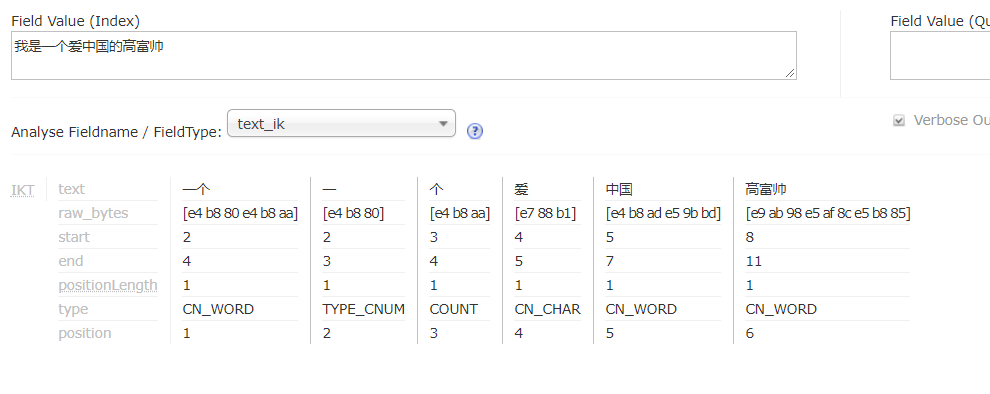
分析成功!
接下来,介绍下如何从数据库导入数据:
首先,导入包(注意位置):
打开上面提到过的solrconfig.xml配置文件:
加入下面这些代码:
<requestHandler
name="/dataimport" class="org.apache.solr.handler.dataimport.Data
ImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler> |
在当前目录下新建一个data-config.xml:
这里导入以前我做的BBS项目中用户的表
<?xml version="1.0"
encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/Blog"
user="root" password="xuyiqing"/>
<document>
<entity name="user"
query="select * from blog_user" >
<field column="u_id" name="id"></field>
<field column="username" name="username"></field>
<field column="u_password" name="password"></field>
<field column="qq" name="qq"></field>
<field column="avatar" name="avatar"></field>
<field column="article_count" name="count"></field>
</entity>
</document>
</dataConfig> |
只写这些不够的,还要在schema.xml中配置域:
<field
name="username" type="text_ik"
indexed="true"
stored="true"/>
<field name="password" type="text_ik"
indexed="false"
stored="false"/>
<field name="qq" type="text_ik"
indexed="true"
stored="true"/>
<field name="avatar" type="string"
indexed="false"
stored="true"/>
<field name="count" type="float"
indexed="true"
stored="true"/> |
保存!重启tomcat
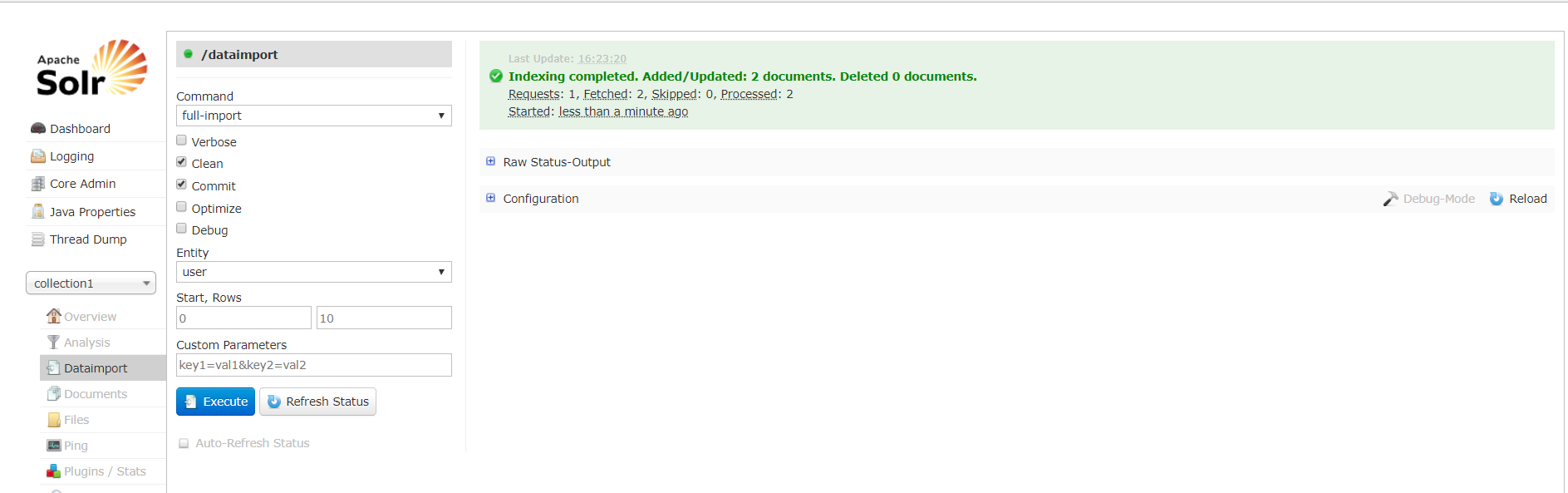
导入成功!
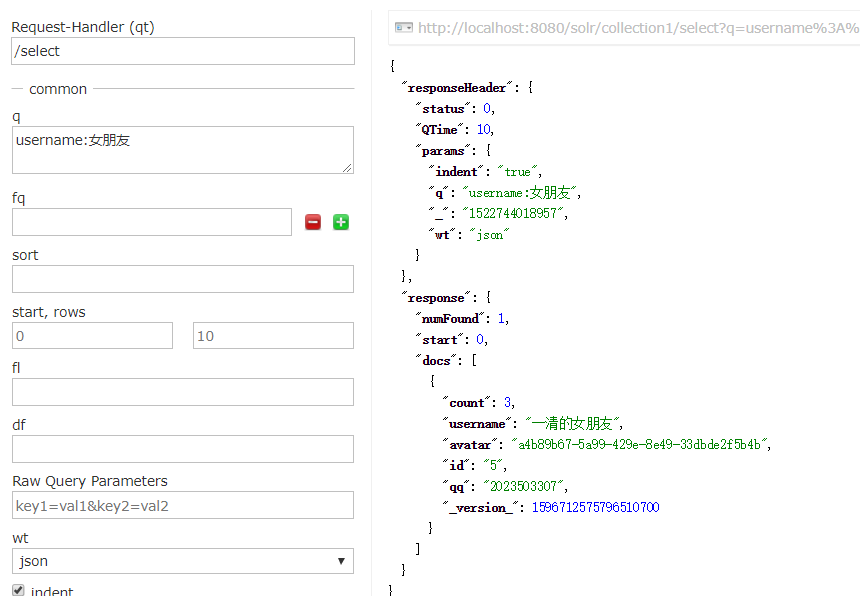
我们查询一下(成功):

可以按条件查询:
到这里搭建Solr就成功了
SolrJ:通过SorlJ的API操作Solr
|









