| 编辑推荐: |
| 本文来自于csdn,本文详细介绍了Aggregator模式的原理,以及通过一个示例,完整的实现了利用Aggregator聚合多条消息,希望对您的学习有所帮助。 |
|
1、前言:
用了Aggregator这个模式几个月了,自己对于其中的原理一向不怎么上心,直到前些天项目中的一个突发问题引发了我的兴趣,于是开始探究Aggregator模式的原理,下面来和大家分享一下。
2、概述
Apache Camel总共提供了60种左右的企业级集成模式,有5种模式比较常见,分别是Aggregator、Splitter、Routing
Slip、Dynamic Router、Load Balancer,这几种模式也是JCF提供给我们使用的,其中Aggregator是最复杂的一种。下面,我们先了解一下这个模式的作用:主要用于将分割后的若干条输入消息重新组装成一条完整的输出消息,Aggregator的作用和Splitter的作用刚好对立。
3、详解
下面先通过一张图对整体有个大概的了解,如下:
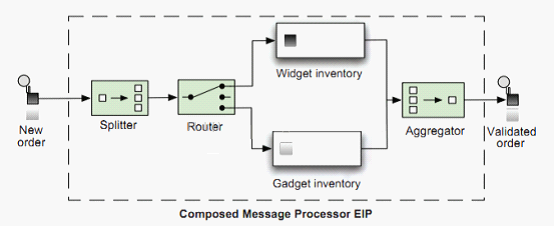
这张图中涉及到了3种模式,这也说明模式之间是可以组合使用的,从而形成一种新的模式,其中Aggregator模式将接收到的消息流和相关联的标识消息聚合成一条输出消息。下面来看一个简单的使用示例,如下:

在上图中,3条消息被依次送入Aggregator,最后被聚合成了一个消息,要实现上图的功能,我们需要关注3个配置,并且这3个配置缺一不可,如果没有配置其中任意一个,在Camel启动的时候就会报配置缺失的错误,这3个配置如下:
Correlation identifier--一条表达式,决定哪个输入消息是属于一个组的。
Completion condition--一个断言或者是基于时间的条件,决定了什么时候输出聚合的结果消息。
Aggregation strategy--一种聚合策略,指定了通过何种方式来聚合成一条消息。
下面我们来看一个简单的例子,来实现字母的聚合,例如输入消息依次为:‘A’、‘B’、‘C’,输出消息为‘ABC’,通过这个简单的例子来让后面的流程好继续下去。如下图所示:
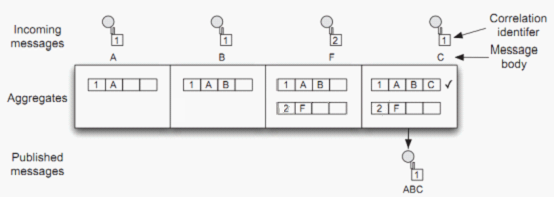
当第一条消息带着关联标志1进来的时候,就初始化了一个聚合器来存储这条消息,在这个例子中,完成条件是当有3条消息被聚合的时候完成。所以当第一条消息进来的时候,整个聚合还没有完成,当第二条带着关联标志1进来的时候,发现该标志下已经存在一个现成的聚合器,就不会再生成新的聚合器,当第三条消息带着关联标志2进来的时候,发现该标志没有对应的聚合器,就会新生成一个关联的聚合器,将该消息存到这个聚合器中,当第四条消息带着关联标志1进来的时候,已经满足了聚合的完成条件,此时会通过聚合策略进行聚合,聚合完成之后,就会输出结果消息。下面通过Camel
route的Java DSL来说明一下(注意文中加粗体的地方):
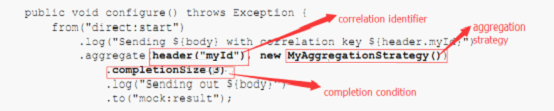
其中,关联性标志就是header(“myId”),是一个Camel的表达式,会存放在header中被带回,第二个配置元素是AggregationStrategy是一个实现了AggregationStrategy接口的实现类,后面我们会深入的学习这个类,最后要说的就是这个完成条件,此处的完成条件是基于大小的,只要接收到3条输入消息,就任务符合条件,关于完成条件,后面会做深入的讲解。上面示例中的java代码实现如下:

运行结果如下:

通过上面控制台的输出可以看到,虽然中间过程中输入了一个F,但是这个消息的关联性标志为2,并不是1,当3个关联性标志都为1的输入消息到达后,Camel就认为满足完成条件,可以进行聚合了。也许有人看到这会问,那么这个输入的F消息后面会发生什么事了?由于这个消息的完成条件并不满足,所以会在聚合器中一直等待,直到满足完成条件,关于这点,后面会进行详解,下面继续来看下聚合的原理。当满足完成条件之后,聚合器就会根据聚合策略来进行聚合,其中聚合策略是一个接口,在org.apache.camel.processor.aggregation包下,该接口的定义如下:
| public
interface AggregationStrategy {
Exchange aggregate(Exchange oldExchange, Exchange
newExchange);
} |
该接口只有一个方法,当运行的时候,一有新的输入消息达到,aggregate这个方法就会执行一次,在上面的这个例子中,这个方法一共执行了4次,下面列一下每执行一次,都发生了什么:
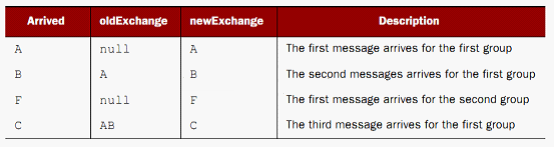
在随后的聚合中,只要不为null,消息就会被更新到Exchange中,在此做下说明:Aggregator使用了synchronization来确保AggregationStrategy是线程安全的,同一时刻,只允许一个线程来执行aggregate这个方法,Aggregator同时也是有序的,消息进入的时候是什么顺序,聚合的时候就是什么顺序。
下面,我们来说一下完成条件(Completion conditions),完成条件在聚合中扮演的角色远远超出了我们的想象,假设当一个完成条件从不出现,就会导致聚合的消息永远都不会被发布出去,为了补救这种糟糕的情况,我们需要添加一个超时条件,这样就可以避免因为某些消息收不到而导致的死等,为此,Camel提供了5个供选择的完成条件,我们可以根据具体的需求来使用。如下所示:
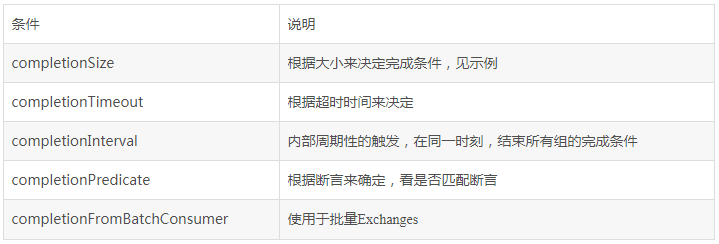
在上面的5个完成条件中,最多可以同时使用4个,其中completionTimeout和completionInterval不能够同时使用。在Exchange中,我们可以在property中获取和设置相应的属性,属性列表如下:
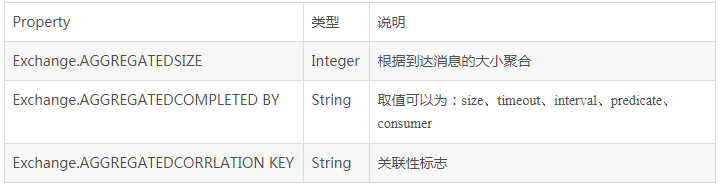
4、持久化
Aggregator是有状态的,因为需要存储进程中的聚合物,直到满足完成条件并将聚合的消息发布出去,默认情况下,Aggregator只会保存状态到内存中,当应用关闭或者主机宕机的时候,这些状态会丢失,为了补救这个问题,我们需要存储状态到持久化仓库中,Camel提供了一个可插拔的特征供我们选择性的使用,下面介绍下这2中方式。
AggregationRepository--这是一个接口,该接口定义了常规的方法来操作仓库,例如添加数据到仓库,从仓库删除数据等,默认情况下,Camel使用MemoryAggregationRepository,这是一个内存仓库。接口定义如下:
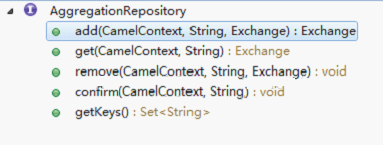
RecoverableAggregationRepository--也是一个接口,该接口继承了AggregationRepository接口,定义了额外的操作来支持恢复丢失的状态。接口定义如下:
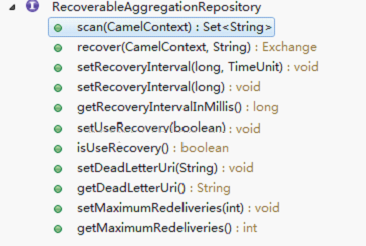
Camel提供了一个camel-hawtdb组件,HawtDB是一个轻量级和可嵌入的基于key-value的文件数据库,他允许Camel为各种模式提供持久化,例如Aggregator,在未来,会有更多的Camel模式利用HawtDB.下面我们来看看HawtDB怎么使用。
首先,我们需要设置HawtDB,设置方式如下:
| AggregationRepository
myRepo = new HawtDBAggregationRepository(“myrepo”,
“data/myrepo.dat”);
|
如上所示,我们创建了一个HawtDBAggregationRepository的示例,同时提供了两个参数,仓库名称必须指定,并且多个仓库是可以同名的。
5、示例
下面,我们来看一个完整的示例。
◎画流程图,如下:
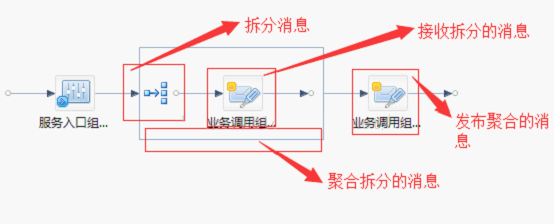
◎拆分消息,将输入的hello,world拆分成hello和world两个字符串,示例代码如下:
| public
class AggreSplitter {
public Collection<Message> splitter(Exchange
exchange) throws UnsupportedEncodingException
{
MessageContext msg = ((MessageContext) exchange.getIn().getBody());
String inputData = JCFUtils.buffer2String(msg.getBody());
List<Message> list = new ArrayList<Message>();
// 分割
String[] strArray = inputData.split(",");
for (String str : strArray) {
Message message = new DefaultMessage();
message.setBody(str);
list.add(message);
}
return list;
}
} |
◎接收拆分的消息,示例代码如下:
| public
class GetMessage implements Processor {
@Override
public void process(Exchange exchange) throws
Exception {
String message = exchange.getIn().getBody(String.class);
exchange.getIn().setBody(message);
}
} |
◎聚合接收到的消息,示例代码如下:
| public
class AggreData implements AggregationStrategy
{
@SuppressWarnings("unchecked")
@Override
public Exchange aggregate(Exchange oldEx, Exchange
newEx) {
String message = newEx.getIn().getBody(String.class);
ArrayList<String> list = null;
if(oldEx == null){
list = new ArrayList<String>();
list.add(message);
newEx.getIn().setBody(list);
return newEx;
}else{
list = oldEx.getIn().getBody(ArrayList.class);
list.add(message);
return oldEx;
}
}
} |
◎发布消息,示例代码如下:
| public
class ReturnOutMessage implements Processor
{
@SuppressWarnings("unchecked")
@Override
public void process(Exchange exchange) throws
Exception {
List<String> list = exchange.getIn().getBody(ArrayList.class);
System.out.println("接收到的报文为:"+list);
for(String str:list){
System.out.println("接收到的报文为:"+str);
}
exchange.getIn().setBody(list);
}
} |
测试结果如下:
接收到的报文为:[hello, world]
接收到的报文为:hello
接收到的报文为:world
上面的示例,完整的实现了利用Aggregator聚合多条消息,关于Camel的Aggregator模式,就先讲到这里。
|









