| LinkedList是Java中的数据结构之一,即链表。本篇文章将从源码角度简单介绍LinkedList的基本实现原理。
在阅读下面内容之前,请确保你已经了解链表的基本属性与特点,在此不会再做详细解释。
本文只介绍链表的核心操作方法,如add remove get set,其他一些不太常用的方法暂时跳过。
ArrayList之前已经介绍过:http://blog.csdn.net/daydreary/article/details/50111321
简介:
在Java中使用的LinkedList,是一个双向循环带头节点的链表。至于为什么是这样的链表,在后面可以从源码中看到。
双向:一个节点可以访问其前一个节点和后一个节点
循环:可以从头节点访问最后一个节点,也可以从最后一个节点访问头节点
带头节点:头节点不存储数据,仅表示链表的起始节点。
LinkedList类中基本属性:
Hprivate transient int size = 0; |
表示存储了多少个元素,即节点个数
private transient Entry<E> header = new Entry<E>(null, null, null); |
header,即头节点,是一个Entry类型的对象。
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
} |
Entry类中包含几个基本变量,previous,next,element
Previous:是一个Entry对象,表示当前节点的前一个节点
Next:是一个Entry对象,表示当前节点的后一个节点
Element:指定的数据对象,即此节点存储的数据
构造方法:
public LinkedList() {
header.next = header.previous = header;
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
} |
默认构造方法中将header的next,previous均指向header,header自身成环,至此已经可以看出LinkedList是一个双向循环链表
构造方法还可以将已有元素追加到链表上,add方法将在后面介绍。
LinkedList中最常用的方法包括:add、set、get、remove,这些方法可能有不同的参数而形成了多个重载函数。
add方法:
public boolean add(E e) {
addBefore(e, header);
return true;
} |
添加一个节点到指定位置:
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
} |
两个方法均是调用了addBefore这个方法,其中在指定index的add方法中,传入的第二个参数是由entry方法返回的结果,其实就是进行循环查找,找到第index个节点。
entry方法:作用是找到第index位置,然后返回这个节点对象
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
} |
这段代码中进行了判断,当index < (size >> 1) 时候(size>>1等价于size/2),通过next对象向后遍历链表,因为此时index节点在链表的前半部分。否则的话,通过previous对象向前遍历链表,因为此时index节点在链表的后半部分。这样可以提高遍历的效率。
下面继续查看addBefore方法的源码:
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
} |
这个方法很简单,创建一个新的节点对象,这个新节点的next指向传入的entry,它的previous指向entry的前一节点。随后代码中修改新节点的previous.next(即entry),指向新节点,修改其next.previous(即entry的previous)指向新节点,形成双向循环。
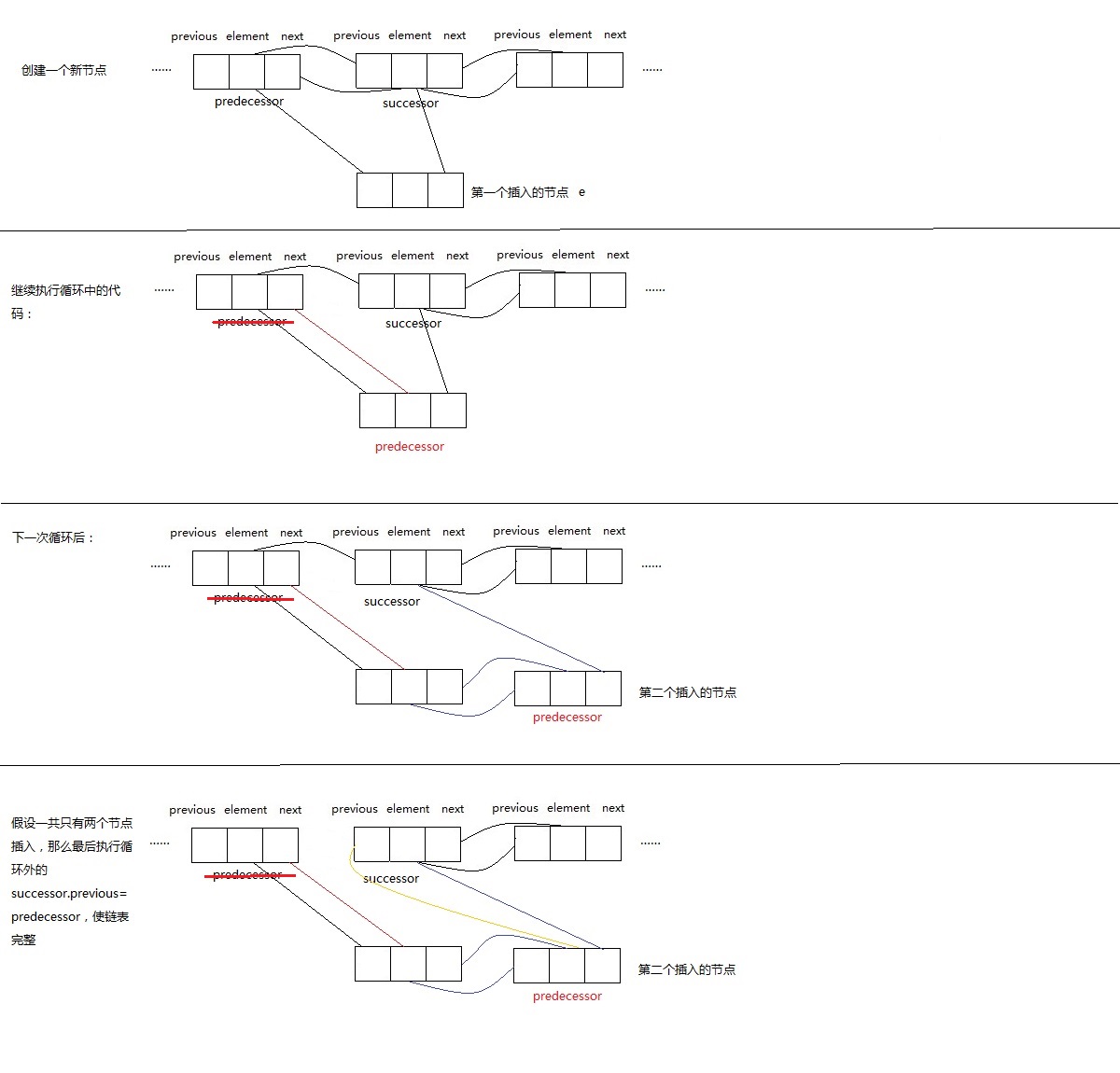
这样依据代码的表述可能比较抽象,下面画图解释一下这个过程:

如此新的节点被插入到entry前,形成了新的链表。
除了add方法外,链表也有addAll方法
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
} |
引用了addAll的另一个重载函数,插入位置是链表尾端,主要实现在这个方法中:
public boolean addAll(int index, Collection<? extends E> c) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew==0)
return false;
modCount++;
Entry<E> successor = (index==size ? header : entry(index));
Entry<E> predecessor = successor.previous;
for (int i=0; i<numNew; i++) {
Entry<E> e = new Entry<E>((E)a[i], successor, predecessor);
predecessor.next = e;
predecessor = e;
}
successor.previous = predecessor;
size += numNew;
return true;
} |
将要插入的数据转为Object数组,然后循环将元素逐个插入到指定的位置。
插入的方法,基本思路和addBefore方法一样,略有不同的地方是每次先修改了predecessor的值为新插入的节点,循环完毕后,再执行successor.previous
= predecessor,使链表形成完整回路。
这样做是因为现在要插入的是很多个节点,而不是一个,每当插入一个新节点,index的位置就发生了变化,predecessor被替换为新插入的那个节点。只有最后一个新节点被插入以后,才能修改successor的previous指向位置,这样链表才能完整。
插入过程示意图:
添加的相关方法到此介绍完毕。主要核心思路就是修改节点的previous与next存放的对象,以此来形成新的完整链表。
get和set两个方法分别是对链表中的某个节点进行取值和赋值,其本质是通过entry方法实现的,entry如何实现的在之前已经介绍过。
get方法:
看下get方法源码
public E get(int index) {
return entry(index).element;
} |
其实就是通过entry方法获取到index位置的节点,然后只要返回其中的数据即可。
set方法:
public E set(int index, E element) {
Entry<E> e = entry(index);
E oldVal = e.element;
e.element = element;
return oldVal;
} |
先通过entry方法获取到index位置的节点,然后修改其中的值。
remove:
remove方法即删除链表中某个节点,具体实现方法也是修改指向位置,是add的一个逆过程而已。
remove一共有3个重载函数
public E remove(int index) {
return remove(entry(index));
} |
这是最常用的一个方法,删除index位置的节点,其实是调用了另一个重载函数。
public boolean remove(Object o) {
if (o==null) {
for (Entry<E> e = header.next; e != header; e = e.next) {
if (e.element==null) {
remove(e);
return true;
}
}
} else {
for (Entry<E> e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e);
return true;
}
}
}
return false;
} |
这个方法是按照元素的值进行删除,循环、查找、找到这个节点后调用另一个重载函数删除掉这个节点。
remove的核心实现:
private E remove(Entry<E> e) {
if (e == header)
throw new NoSuchElementException();
E result = e.element;
e.previous.next = e.next;
e.next.previous = e.previous;
e.next = e.previous = null;
e.element = null;
size--;
modCount++;
return result;
} |
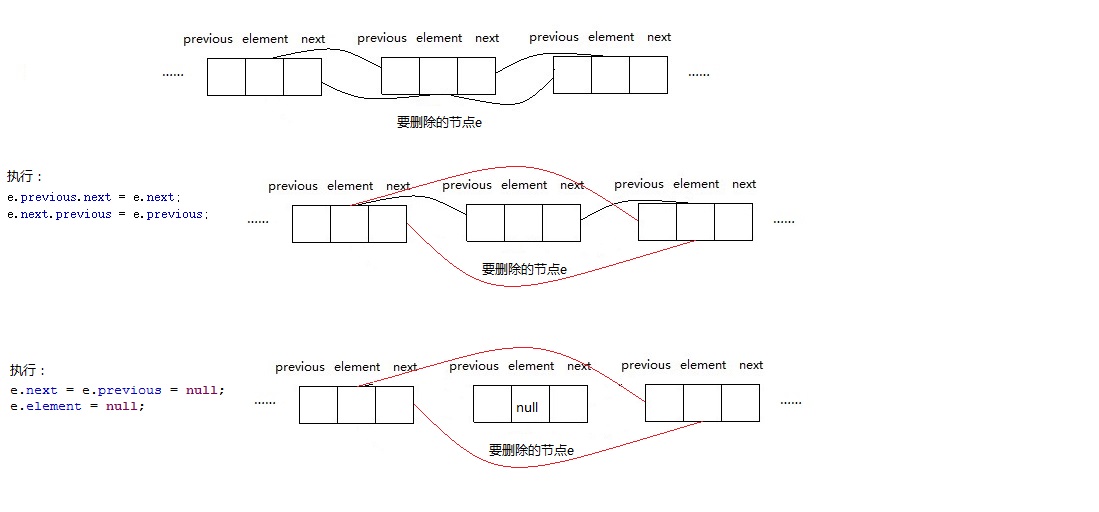
要删除的节点就是传入的参数e
将e的下一个节点的previous指向e的前一个节点
将e的前一个节点的next指向e的下一个节点
最后将e置为null,就可以完成删除操作了
删除节点操作示意图:
总结:
链表存储的数据在内存中是不连续的,通过previous和next来指向一个节点的前后节点,使得其连起来,形成完整的表结构。
由于其在内存中是连续的,所以其删除、插入操作效率很高,因为只是简单的修改previous和next的值,那么新的节点就被插入了。而ArrayList插入一个新的元素,将使得其他大量数据进行位置移动,消耗比链表高很多。
虽然删除和插入效率高,但链表的查询效率比较低,entry方法就是查询的核心,每次都要进行循环操作,虽然说根据数据位置尽量减少了循环次数,但依然不能避免本质问题。
|






