| 前言
本文简单描述SolrCloud的特性,基本结构和入门,基于Solr4.5版本。
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库。Solr是以Lucene为基础实现的文本检索应用服务。
SolrCloud是Solr4.0版本开发出的具有开创意义的基于Solr和Zookeeper的分布式搜索方案,或者可以说,SolrCloud是Solr的一种部署方式。Solr可以以多种方式部署,例如单机方式,多机Master-Slaver方式,这些方式部署的Solr不具有SolrCloud的特色功能。
特色
SolrCloud有几个特色功能:
1、集中式的配置信息
使用ZK进行集中配置。启动时可以指定把Solr的相关配置文件上传Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。
另外,Solr的一些任务也是通过ZK作为媒介发布的。目的是为了容错。接收到任务,但在执行任务时崩溃的机器,在重启后,或者集群选出候选者时,可以再次执行这个未完成的任务。
2、自动容错
SolrCloud对索引分片,并对每个分片创建多个Replication。每个Replication都可以对外提供服务。一个Replication挂掉不会影响索引服务。
更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
3、近实时搜索
立即推送式的replication(也支持慢推送)。可以在秒内检索到新加入索引。
4、查询时自动负载均衡
SolrCloud索引的多个Replication可以分布在多台机器上,均衡查询压力。如果查询压力大,可以通过扩展机器,增加Replication来减缓。
5、自动分发的索引和索引分片
发送文档到任何节点,它都会转发到正确节点。
6、事务日志
事务日志确保更新无丢失,即使文档没有索引到磁盘。
其它值得一提的功能有:
1、索引存储在HDFS上
索引的大小通常在G和几十G,上百G的很少,这样的功能或许很难实用。但是,如果你有上亿数据来建索引的话,也是可以考虑一下的。我觉得这个功能最大的好处或许就是和下面这个“通过MR批量创建索引”联合实用。
2、通过MR批量创建索引
有了这个功能,你还担心创建索引慢吗?
3、强大的RESTful API
通常你能想到的管理功能,都可以通过此API方式调用。这样写一些维护和管理脚本就方便多了。
4、优秀的管理界面
主要信息一目了然;可以清晰的以图形化方式看到SolrCloud的部署分布;当然还有不可或缺的Debug功能。
概念
Collection:在SolrCloud集群中逻辑意义上的完整的索引。它常常被划分为一个或多个Shard,它们使用相同的Config
Set。如果Shard数超过一个,它就是分布式索引,SolrCloud让你通过Collection名称引用它,而不需要关心分布式检索时需要使用的和Shard相关参数。
Config Set: Solr Core提供服务必须的一组配置文件。每个config set有一个名字。最小需要包括solrconfig.xml
(SolrConfigXml)和schema.xml (SchemaXml),除此之外,依据这两个文件的配置内容,可能还需要包含其它文件。它存储在Zookeeper中。Config
sets可以重新上传或者使用upconfig命令更新,使用Solr的启动参数bootstrap_confdir指定可以初始化或更新它。
Core: 也就是Solr Core,一个Solr中包含一个或者多个Solr Core,每个Solr
Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或者Collection的Shard,Solr
Core的提出是为了增加管理灵活性和共用资源。在SolrCloud中有个不同点是它使用的配置是在Zookeeper中的,传统的Solr
core的配置文件是在磁盘上的配置目录中。
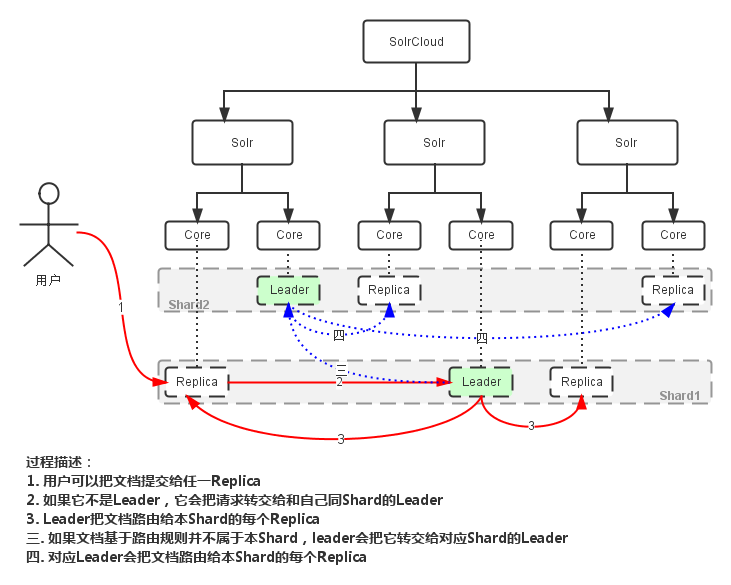
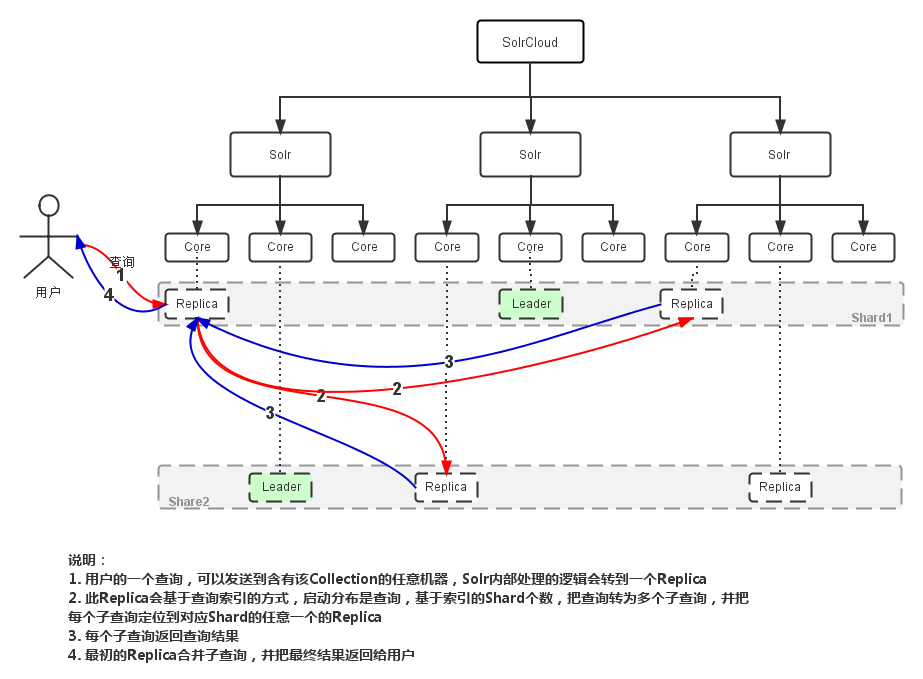
Leader: 赢得选举的Shard replicas。每个Shard有多个Replicas,这几个Replicas需要选举来确定一个Leader。选举可以发生在任何时间,但是通常他们仅在某个Solr实例发生故障时才会触发。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到全部Shard的replicas。
Replica: Shard的一个拷贝。每个Replica存在于Solr的一个Core中。一个命名为“test”的collection以numShards=1创建,并且指定replicationFactor设置为2,这会产生2个replicas,也就是对应会有2个Core,每个在不同的机器或者Solr实例。一个会被命名为test_shard1_replica1,另一个命名为test_shard1_replica2。它们中的一个会被选举为Leader。
Shard: Collection的逻辑分片。每个Shard被化成一个或者多个replicas,通过选举确定哪个是Leader。
Zookeeper: Zookeeper提供分布式锁功能,对SolrCloud是必须的。它处理Leader选举。Solr可以以内嵌的Zookeeper运行,但是建议用独立的,并且最好有3个以上的主机。
架构
索引(collection)的逻辑图

索引和Solr实体对照图

创建索引过程
检索过程
Shard Splitting

入门
安装配置
前提,你需要先安装好Java,6.0+。 假设我们有5台机器要安装Solr。
1.安装外部zookeeper
Solr默认是用内置的Zookeeper,为了方便管理和维护,建议使用外部Zookeeper。
wget http://apache.dataguru.cn/zookeeper/zookeeper-3.4.3/zookeeper-3.4.3.tar.gz
tar -zxvf zookeeper-3.4.3.tar.gz
Java的程序解压后就可以运行,不需要安装。
修改或者创建配置文件$ZOOKEEPER_HOME/conf/zoo.cfg,内容如下:
# 注意修改为你的真实路径
dataDir=/home/hadoop/zookeeper-3.4.3/data
clientPort=2181
# 编号从1开始,solr1-3每个是一台主机,共3个
server.1=solr1:2888:3888
server.2=solr2:2888:3888
server.3=solr3:2888:3888 |
在3台机器上都同样安装。
另外,还需要在$dataDir中配置myid,zookeeper是以此文件确定本机身份。
# 注意每台机器上的不一样
echo "1" > myid #在solr1上
echo "2" > myid #在solr2上
echo "3" > myid #在solr3上 |
启动, 需要在3台机器上分别启动
$ZOOKEEPER_HOME/bin/zkServer.sh start
# 查看状态,确认启动成功
$ZOOKEEPER_HOME/bin/zkServer.sh status |
2.Solr安装下载
在5台机上做同样操作
wget
http://apache.mirrors.pair.com/lucene/solr/4.5.0/solr-4.5.0.tgz
tar -xzf solr-4.5.0.tgz
cd solr-4.5.0
cp -r example node1
cdo node1 # 第一条solr机器
java -Dbootstrap_confdir=./solr/collection1/conf
-Dcollection.configName =myconf -DnumShards=2 -DzkHost=solr1:2181,solr2:2181,solr3:2181
-jar start.jar
# 其它solr机器
java -DzkHost=solr1:2181,solr2:2181,solr3:2181 -jar
start.jar |
启动成功后,你可以通过浏览器8983看到solr的Web页面。
3.索引
cd $SOLR_HOME/node1/exampledocs
java -Durl=http://solr1:8983/solr/collection1/update -jar post.jar ipod_video.x |
4.检索
你可以在web界面选定一个Core,然后查询。solr有查询语法文档。
5.如果要想把数据写到HDFS
在$SOLR_HOME/node1/solr/collection1/conf/solrconfig.xml
增加
<directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory">
<str name="solr.hdfs.home">hdfs://mycluster/solr</str>
<bool name="solr.hdfs.blockcache.enabled">true</bool>
<int name="solr.hdfs.blockcache.slab.count">1</int>
<bool name="solr.hdfs.blockcache.direct.memory.allocation">true</bool>
<int name="solr.hdfs.blockcache.blocksperbank">16384</int>
<bool name="solr.hdfs.blockcache.read.enabled">true</bool>
<bool name="solr.hdfs.blockcache.write.enabled">true</bool>
<bool name="solr.hdfs.nrtcachingdirectory.enable">true</bool>
<int name="solr.hdfs.nrtcachingdirectory.maxmergesizemb">16</int>
<int name="solr.hdfs.nrtcachingdirectory.maxcachedmb">192</int>
<str name="solr.hdfs.confdir">${user.home}/local/hadoop/etc/hadoop</int>
</directoryFactory> |
重新启动
| java
-Dsolr.directoryFactory=HdfsDirectoryFactory -Dsolr.lock.type
=hdfs -Dsolr.data.dir=hdfs://mycluster/solr -Dsolr.updatelog=hdfs://mycluster/solrlog
-jar start.jar |
可以增加如下参数设定直接内存大小,优化Hdfs读写速度。
XX:MaxDirectMemorySize=1g |
其它
NRT 近实时搜索
Solr的建索引数据是要在提交时写入磁盘的,这是硬提交,确保即便是停电也不会丢失数据;为了提供更实时的检索能力,Solr设定了一种软提交方式。
软提交(soft commit):仅把数据提交到内存,index可见,此时没有写入到磁盘索引文件中。
一个通常的用法是:每1-10分钟自动触发硬提交,每秒钟自动触发软提交。
RealTime Get 实时获取
允许通过唯一键查找任何文档的最新版本数据,并且不需要重新打开searcher。这个主要用于把Solr作为NoSQL数据存储服务,而不仅仅是搜索引擎。
Realtime Get当前依赖事务日志,默认是开启的。另外,即便是Soft
Commit或者commitwithin,get也能得到真实数据。 注:commitwithin是一种数据提交特性,不是立刻,而是要求在一定时间内提交数据。 |






