|
4.4 网络IO消耗分析
分布式系统,网络IO的消耗时非常值得关注的,尤其要注意网卡中断是不是均衡地分配到各CPU的(可通过
cat /proc/interrupts 查看的),见图-25

图-25
对于网络中断只分配到一个CPU的现象,google采用修改kernel的方法对网络中断分配不均的问题进行修复,据其测试性能大概能提升3x左右,或是采用支持MSI-X的网络来修复。
由于默认的Linux内核参数考虑的是最通用的场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux参数,使得Nginx等Web服务可以拥有更高的性能:
首先,需要修改/etc/sysctl.conf来更改内核参数。如下最常用的配置
fs.file-max = 999999
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_keepalive_time = 60
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.ip_local_port_range = 1024 61000
net.ipv4.tcp_rmem = 4096 32768 262142
net.ipv4.tcp_wmem = 4096 32768 262142
net.core.netdev_max_backlog = 8096
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn.backlog = 1024 |
然后执行 sysctl -p 命令,使上述修改生效。
上面的参数意义解释如下:
(1) file-max:这个参数表示进程(比如一个work进程)可以同时打开的最大句柄数,这个参数直接限制最大并发连接数,需根据实际情况配置。
(2) tcp_tw_reuse: 这个参数设置为1,表示允许将TIME-WAIT状态的socket重新用于新的TCP连接,这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态。
(3) tcp_keepalive_time: 这个参数表示当keepalive启用时,TCP发送keepalive消息的频率。默认是2小时,若将其设置的小一些,可以更快第清理无效的连接。
(4) tcp_fin_timeout: 这个参数表示当服务器主动关闭连接时,socket保持在FIN-WAIT-2状态的最大时间。
(5) tcp_max_tw_buckets: 这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除病打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。
(6) tcp_max_syn_backlog:这个参数表示TCP三次握手建立阶段接收SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
(7) ip_local_port_range:这个参数定义了在UDP和TCP连接中本地(不包括连接的远端)端口的取值范围。
(8) net.ipv4.tcp_rmem:这个参数定义了TCP接收缓存(用于TCP接收滑动窗口)的最小值、默认值、最大值。
(9) net.ipv4.tcp_wmem:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
(10)netdev_max_backlog:当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。这个参数表示该队列的最大值。
(11)rmem_default:这个参数表示内核套接字接收缓存区默认的大小。
(12)wmem_default:这个参数表示内核套接字发送缓存区默认的大小。
(13)rmem_max: 这个参数表示内核套接字接收缓存区的最大大小。
(14)wmem_max: 这个参数表示内核套接字发送缓存区的最大大小。
(15)tcp_syncookies:该参数与性能无关,用于解决TCP的SYN攻击。
4.4.1 网络IO分析的常用命令
在Linux中可采用sar分析网络IO的消耗状况,
sar 命令
例子:
sar -n ALL sar -n DEV
sar -n { <keyword> [,...] | ALL }
Network statistics
Keywords are:
DEV Network interfaces
EDEV Network interfaces (errors)
NFS NFS client
NFSD NFS server
SOCK Sockets (v4)
IP IP traffic (v4)
EIP IP traffic (v4) (errors)
ICMP ICMP traffic (v4)
EICMP ICMP traffic (v4) (errors)
TCP TCP traffic (v4)
ETCP TCP traffic (v4) (errors)
UDP UDP traffic (v4)
SOCK6 Sockets (v6)
IP6 IP traffic (v6)
EIP6 IP traffic (v6) (errors)
ICMP6 ICMP traffic (v6)
EICMP6 ICMP traffic (v6) (errors)
UDP6 UDP traffic (v6)
|
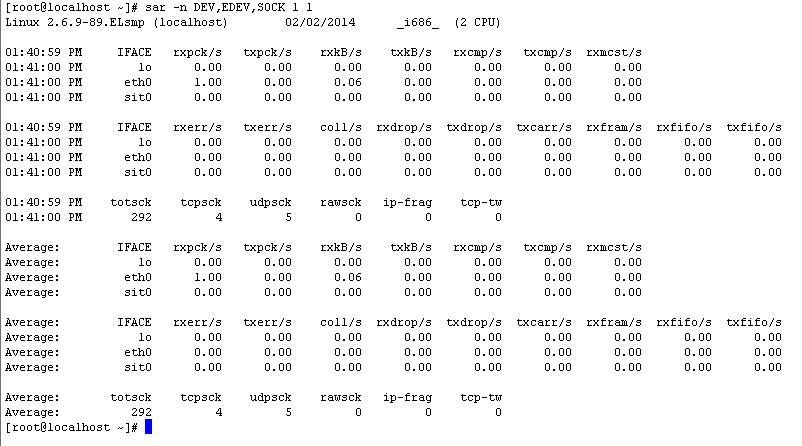
图-26
上面的输出的信息主要分三部分:
第一部分为网卡上成功接包和发包的信息,其报告中的信息主要有: rxpck/s
txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
第二部分为网卡上失败的接包和发包的信息,其报告中的信息主要有: rxerr/s
txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s
txfifo/s
第三部分为网卡上sockets的统计信息,其报告中的信息主要有: rtotsck
tcpsck udpsck rawsck ip-frag tcp-tw
对于Java应用而言,使用的主要为tcpsck 和 udpsck
tcpsck: Number of TCP sockets currently
in use.
udpsck: Number of UDP sockets currently
in use.
tcp-tw: Number of TCP sockets in TIME_WAIT
state.
如需要详细跟踪TCP/IP通信的过程信息,则可通过tcpdump命令进行。
查看网络的常用命令:
netstat -ps
nfsstat
ethtool
snmp
ifport
ifconfig
route
arp
ping
traceroute
host
nslookup
ifconfig eth0 |
Linux下查看那些UDP类型端口开发,那些TCP端口开放
netstat -nupl (UDP类型的端口)
netstat -ntpl (TCP类型的端口)
netstat -n | awk '/^tcp/ {++S[$NF]}
END {for(a in S) print a, S[a]}';
4.4.2 网络IO消耗分析案例
由于没方法分析具体每个线程锁消耗的网络IO, 因此当网络IO消耗高时,对于Java应用而言只能对进程进行dump,查找产生了大量网络IO操作的线程。这些线程的特征是读取或写入网络流,在用Java实现网络通信时,通常要将对象序列化为字节流,进行发送,或读取字节流,并反序列化为对象。这个过程要消耗JVM堆内存,JVM堆内存大小通常有限。
网络容易出现问题地方如:数据库连接没有关闭(在抛出异常的情况下、网络经常出现抖动情况下)。 一端关闭另一端没有关闭等。运行程序见参考附件:NetUsedHighTCPServer.java
和 NetUsedHighTCPClient.java

图-27 显示 rxpck/s(Total number of packets
received per second.) txpck/s(Total number of packets
transmitted per second.) rxkB/s(Total number of kilobytes
received per second.) txkB/s(Total number of kilobytes
transmitted per second.) 都比较高
图-28
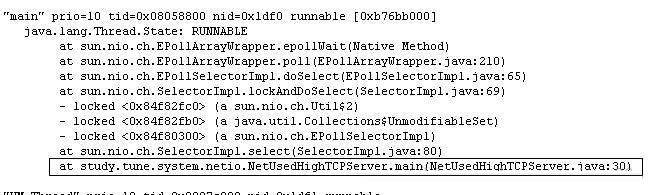
图-29
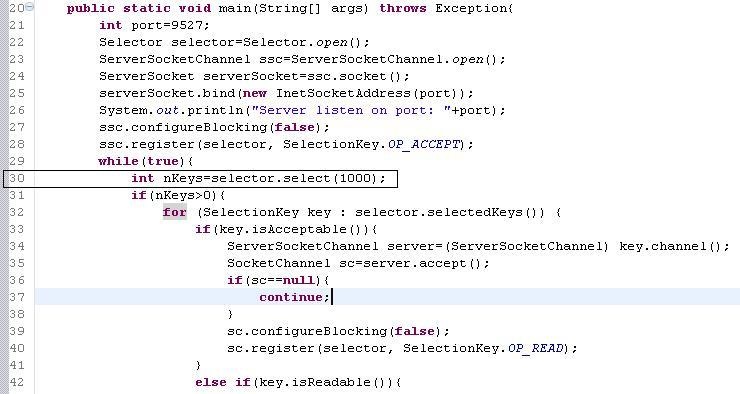
图-30
4.5程序执行慢原因分析
有些情况时资源消耗不多,但程序执行仍然慢,这种现象多出现于访问量不是非常大的情况下,造成这种现象的原因主要有以下三种:
4.5.1. 未充分使用硬件资源
当前主流机器CPU基本都是4或8核,如果程序中都是单线程串行的操作,并没有充分发挥硬件资源的作用,那么就可进行一定的优化(如:将串行修改为并发或并行的)来充分使用硬件资源,提升程序的执行速度。
如果在一定的负载情况下,多核CPU使用率不高,程序执行慢(通过记录执行的整个过程时间消耗或使用JProfiler等工具),找到执行耗时比例最大的代码。
4.5.2. 锁竞争激烈
锁竞争激烈直接就会造成程序执行慢, 例如一个典型的例子是数据库连接池(底层也是一个网络连接池),通常数据库连接池提供的连接数都是有限的。假设提供的是10个,那么就意味着同时能够进行数据库操作的就只有10个线程,而如果此时有50个线程要进行数据库操作,那就会造成另外的40个线程处于等待状态,这种情况下对于8核类型的机器而言,CPU的消耗并不会高,但程序的执行仍然会较慢。
4.5.3. 数据量增长
数据量增长通常也是造成程序执行慢的典型原因,例如当数据库中单表的数据从100万条记录上涨到1个亿后,数据库的读写速度将大幅度下降,相应的操作此表的程序的执行速度也就下降了。
如果在一定的负载情况下,多核CPU使用率不高,程序执行慢(通过记录执行的整个过程的时间消耗或使用JProfiler等工具),找到执行耗时比例最大的代码。
5 性能调整(优)
在寻找到系统的性能瓶颈后,接下来的步骤就是调优,以提高系统性能,狭义的调优通常可以从硬件、操作系统、JVM以及应用程序四个方面入手,硬件和操作系统方面的知识不是本文章的重点,下面结合性能瓶颈的分析从JVM及程序方面来介绍一些常用的调优方法。
5.1 JVM调优
JVM调优主要是内存管理方面的调优包括 各个代的大小,GC策略 等。由于GC动作会挂起应用线程,严重影响应用程序的性能,这些调优对于应用程序而言至关重要,根据应用程序的情况选择不同的内存管理策略有些时候能够大幅度地提升应用程序的性能,尤其是对于内存消耗较多的应用。下面就来看一些常用的内存管理调优的方法,这些方法都是为了尽量降低GC所导致的应用程序暂停时间。
5.1.1 代大小的调优
在不采用G1(G1不区分minor GC和Full GC)的情况下,通常minor
GC会远快于Full GC, 各个代的大小设置直接决定了minor GC和Full GC触发的时机,在代大小的调优上,最关键的参数为:-Xms
-Xmx -Xmn -XX:SurvivorRatio -XX:MaxTenuringThreshold
-Xms和-Xmx通常设置为相同的值,避免运行时要不断地扩展JVM内存空间,这个值决定了JVM
Heap所能使用的最大空间。
-Xmn决定了新生代(New Generation)空间的大小,新生代中Eden、S0
和 S1 三个区域的比率可通过-XX:SurvivorRatio 来控制。
-XX:MaxTenuringThreshold 控制对象在经历多少次Minor
GC后才转入旧生代,通常又将此值称为新生代存活周期,此参数只有在串行GC时有效,其他GC方式时则由Sun
JDK自行决定。
介绍Minor GC 和 Full GC触发的时机??,在此处就直接举例来看看不同的代大小设置情况下,应用耗费在GC上的时间,从中也可看出在不同的场景下代大小调优的方法。
5.1.1.1. 避免新生代大小 设置过小
当新生代大小设置过小时会产生两种比较明显的现象: 一是minor GC的次数更加频繁;二是有可能导致minor
GC对象直接进入旧时代,此时如进入旧生代的对象占据了旧生代剩余空间,则触发Full GC.
运行示例程序(示例程序GCDemo.java在参考部分下载)
首先以JVM启动参数:-Xms135M -Xmx135M -Xmn10M
-XX:+UseSerialGC执行上面的代码,通过jstat跟踪到的GC状况为:

图-31
其次,按照这样的思路调大新生代到30MB,则JVM启动参数为:-Xms135M
-Xmx135M -Xmn50M -XX:+UseSerialGC执行上面的代码,通过jstat跟踪到的GC状况为:
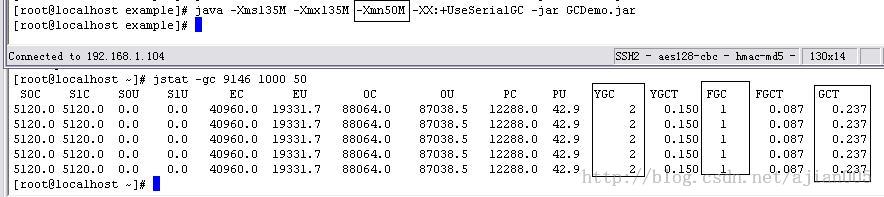
图-32
通过对比发现,当配置-Xmn10M与-Xmn50M,GCT耗费的时间从0.403秒降到0.237秒。
除了调大新生代大小外,如果能够调大JVM Heap的大小,通常意味着单次GC时间的增加。
当minor GC过于频繁,或发现经常出现minor GC时,Survivor的一个区域空间满,且Old
Gen增长超过了Survivor区域大小时,就需要考虑新生代大小的调整了。调整时的原则是在不能调大JVM
Heap的情况下,尽可能放大新生代空间,尽量让对象在minorGC阶段被回收,但新生代空间也不可过大;在能够调大JVM
Heap的情况下,则可以按照增加的新生代空间大小增加JVM Heap大小,以保证旧生代空间够用。
5.1.1.2. 避免新生代大小 设置过大
新生代设置过大会带来两个典型的现象,一是旧生代变小了,有可能导致Full
GC频繁执行; 二是minor GC的耗时大幅度增加。
仍然用上面的例子 首先以JVM启动参数:-Xms135M -Xmx135M
-Xmn105M -XX:+UseSerialGC执行上面的代码,通过jstat跟踪到的GC状况为:
首先以JVM启动参数:-Xms135M -Xmx135M -Xmn105M
-XX:+UseSerialGC 执行上面的代码,通过jstat跟踪到的GC状况为:
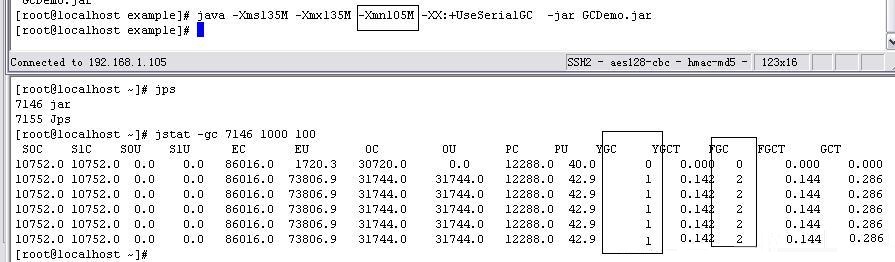
图-33
其次以JVM启动参数:-Xms135M -Xmx135M -Xmn25M
-XX:+UseSerialGC 执行上面的代码,通过jstat跟踪到的GC状况为:

图-34
从这个调整和之前把新生代调为25MB时对比,此时minor GC下降了,但Full
GC仍然多了一次。原因在于,当第二次到达minor GC的触发条件时,JVM基于悲观原则,判断目前old区的剩余空间小于可能会从新生代晋升到old区的对象的大小,于是执行了Full
GC,从而minor GC消耗的时间来看,单词minor GC的时间也比以前慢了不少。
从上面的分析来看,可见新生代通常不能设置得过大,大多数场景下都应设置的比旧生代小,通常推荐的比例是新生代占JVM
Heap区大小的33%左右。
5.1.1.3. 避免Survivor区设置过小或过大
在采用串行GC时,默认情况下Eden、S0、s1的大小比例为 8:1,调整为以下参数执行上面的示例代码:
java -Xms135M -Xmx135M -Xmn20M -XX:SurvivorRatio=10
-XX:+UseSerialGC -jar GCDemo.jar ,通过jstat -gc [pid]
1000 50 观察到其GC状况为:

图-35
从上面的分析来看,在无法调整JVM Heap以及新生代的大小时,合理调整Survivor区的大小也能带来一些效果。
当调大SurvivorRatio值意味着Eden区域变大,minor GC的触发次数会降低,但此时Survivor区域的空间变小了,如有超过Survivor空间大小的对象在minor
GC后仍没有被回收,则会直接进入旧生代;
当调小SurvivorRatio则意味着Eden区域变小,minor GC的触发次数会增加,Survivor区域变大,意味着可以存储更多在minor
GC后仍存活的对象,避免其进入旧生代。
5.1.1. 4. 合理设置新生代存活周期
新生代存活周期的值决定了新生代的对象经过多少次Minor GC后进入旧生代,因此这个值也需要根据应用的状况来做针对性的调优,JVM参数上这个值对应的为-XX:MaxTenuringThreshold,默认值为15次,
下面通过设置参数的例子(参考部分附件)看一下:
首先 -Xms150M -Xmx150M -Xmn20M -XX:+UseSerialGC执行代码,执行结果如下
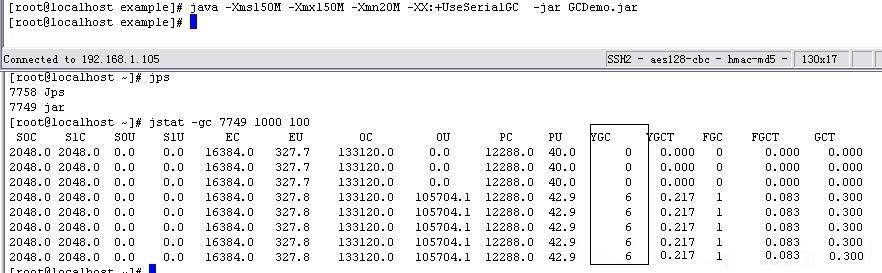
图-36
其次 -Xms150M -Xmx150M -Xmn20M -XX:+UseSerialGC
-XX:MaxTenuringThreshold=20 执行代码,执行结果如下:
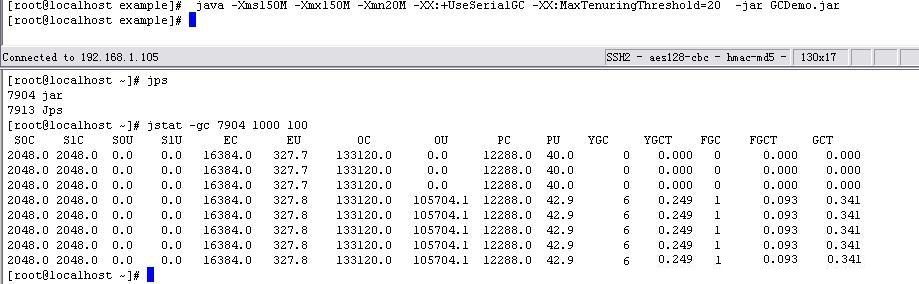
图-37
从上面的调整结果可见,在增大了存活周期后,对象在Minor GC阶段被回收的机会就增加了,但同时带来的是survivor区被占用,但此值仅在串行GC和ParNew
GC时可调整。
总结上面的几个例子来看,对于代大小的调优,主要是合理调整 -Xms、-Xmx、-Xmn
以及 -XX:SurvivorRatio的值,尽可能减少GC所占用的时间。
-Xms、-Xmx适用于调整整个JVM Heap区大小,在内存不够用的情况下可适当加大此值,这个值能调整到多大
取决于操作系统位数 以及 CPU的能力。
-Xmn 适用于调整新生代的大小、新生代的大小决定了多少比例的对象有机会再minor
GC阶段被回收,但此值相应的也决定了旧生代的大小。新生代越大,通常意味着多数对象能够在minor GC阶段被回收掉,但同时意味着旧生代的空间会变小,可能会造成更频繁的Full
GC,甚至是OutOfMemoryError.
-XX:SurvivorRatio 适用于调整Eden区和Survivor区的大小,Eden区越大通常也就意味着minor
GC发生的频率越低。但有可能会造成Survivor区太小,导致对象在经过minor后直接就进入旧生代了,从而更频繁的触发Full
GC, 这取决于当Eden区满的时候其中存活对象的比例。
在清楚掌握minor GC、Full GC的触发时机以及代大小的调整后,结合应用的状况(例如创建出的对象都可很快被回收掉、缓存对象多等)通常就可较好设置代的大小,减少GC锁占用的时间。在调整后可结合jstat、VisualVM等查看GC的变化是否达到了调优的目的。
5.1.2 GC策略的调优
Sun JDK所提供的几种GC策略,串行GC性能太差,因此在实际场景中使用的主要为并行和并发GC,
通过下面这个例子触发多次GC,查看并行GC以及并发GC时对于应用造成的不同的暂停时间。
首先以VM Args: -Xms680M -Xmx680M -Xmn80M
-XX:+UseConcMarkSweepGC -XX:+PrintGCApplicationStoppedTime
-XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5
参数执行,通过jstat观察到的GC状况:
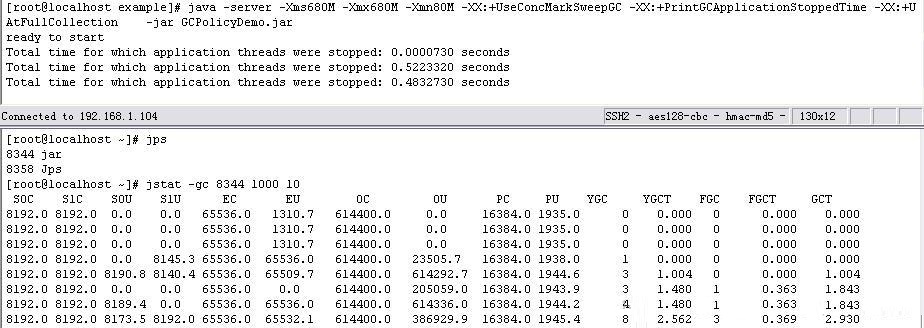
图-38
其次以VM Args: -Xms680M -Xmx680M -Xmn80M
-XX:+PrintGCApplicationStoppedTime -XX:+UseParallelGC
参数执行,通过jstat观察到的GC状况:
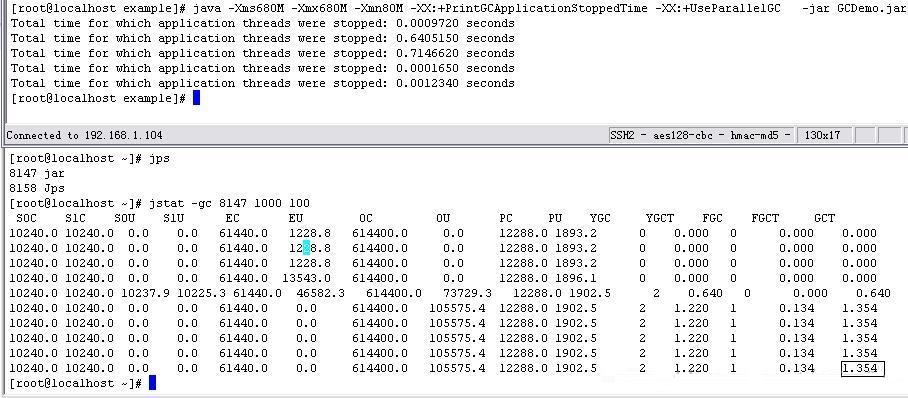
图-39
大部分大部分 Web应用在处理请求时设置了一个最大可同时处理的请求数,当超过次请求数时,会将之后的请求放入等待队列中,而这个等待队列也限制了大小。当等待队列慢了以后仍然有请求进入,那么这些请求将会直接被丢弃,所有的请求又都是有超时限制的。在这种情况下如触发了造成应用暂停时间较长的Full
GC,那么有可能在这次Full GC后,造成了3秒的暂停,那么之前在此应用上等待处理的请求就会全部超时了。从上可看出,Web应用非常需要一个对应用造成暂停时间短的GC,再加上大部分Web应用的瓶颈都不在CPU上。因此对于Web应用而言,在G1还不够成熟的情况下,CMS
GC是不错的选择。
5.1.3 JVM调优案例
以下为一个系统一段时间内的GC状况,此系统运行的机器操作系统为32为,CPU为4核,物理内存为4G,启动参数为:
VM args: -server -Xms1536m -Xmx1536m
-Xmn700m -XX:PermSize=96m -XX:MaxPermSize=96m
根据启动的参数以及机器配置来看,目前系统新生代GC的类型为Parallel
Scavenge,启动时Eden Space,S0,S1将会由HotSpot自动调整,大致空间大小:Eden561、59和72这样的分配情况,假设多数情况下均为这样的占比,目前的运行状况为每次Minor
GC后大概有16MB对象进入旧生代,假设这些对象都是因为超过Survivor Space才进入旧生代的,那么可以认为每次Minor
GC时有16+72=88MB的对象时存活的,从目前Full GC的状况来看,其实这88MB的对象在一段时间后都是可以回收的,那么理论上来说只用将Survivor
Space扩大到88MB以上即可,按着这个想法,可以将启动参数调整为:
VM args: -server -Xms1536m -Xmx1536m
-Xmn700m -XX:PermSize=96m -XX:MaxPermSize=96m -XX:InitialSurvivorRatio=7
-XX:-UseAdaptiveSizePolicy
除了以上方法外,还可采用的另一方式为将GC测量调整为CMS GC,参数如下:
VM args: -server -Xms1536m -Xmx1536m
-Xmn700m -XX:PermSize=96m -XX:MaxPermSize=96m
-XX:+UseConcMarkSweepGC -XX:+UseCompactAtFullCollection
-XX:CMSMaxAbortablePrecleanTime=500
-XX:+CMSPermGenSweepingEnabled
-XX:+CMSClassUnloadingEnabled
在做完以上的调优后,都需要继续结合jstat工具来查看是否达到了调优的目标,如果没有则需要继续按着以上步骤进行参数的调整。具体参数列表可以参考Oracle官方
在进行参数调整时,可根据目前收集到的顶峰时系统请求次数、响应时间以及GC的信息,来估计系统每次请求需要消耗的内存,以及每次Minor
GC时存活的对象所占的内存,从而估计需要设置多大的Survivor才能够尽可能地避免对象进入旧生代。
例如:每秒的请求为60次,GC信息显示每10秒执行一次minor GC,每次Minor
GC会有10MB对象转入旧生代,每次Minor GC在Eden分配的内存为600MB,Survivor为100MB.根据这些信息,可以简单认为系统中每次请求消耗的内存大致为1MB,
并粗略估计为在开始Minor GC时,还有110个请求未处理完。 对于这样的状况,简单的调优方式可以在保持Eden
Space 600 MB的情况下, 将Survivor Space增长到120MB,那就基本可以做到在当前的响应速度下,如10秒内接受的请求最多为600个时,Minor
GC时大部分情况不会有对象转入旧生代,但毕竟系统中的请求响应时间、内存消耗分布不会这么平均,并且还回出现直接在旧生代分配的现象,因此通常按这样粗略的估计设置的参数仍然会达不到目标,要继续进行一些细微的调节来逐步达到目标。
由于参数的估计是以请求次数和响应时间为基准的,因此一旦系统的响应速度下降或请求的次数上升,就可能仍然会导致大量对象进入旧生代,从而触发频繁的Full
GC,频繁的Full GC又导致系统的响应速度下降,从这个层面来看,根本上需要做的调优仍然是提升请求的处理速度以及降低每次请求需要分配的内存,只有这样才能使的应用能够支撑更高的并发量,否则就会随着并发量的上涨而迅速出现瓶颈。
旧生代大小的调整一方面要依据新生代的大小,另一方面要依据系统中持久存活的对象会消耗多大的内存来决定。
如系统不是CPU密集型,且从新生代进入旧生代的大部分对象时可回收的,那么采用CMS
GC可以更好地在旧生代满之前完成对象的回收,更大程度降低了Full GC发生的可能。
目前内存管理方面,JVM自身已经做得非常不错了,因此如果不是有确切的GC造成性能低的理由,就没有必要做过多的细节方面的调优(例如:survivor区大小的设置等)。多数情况下只须选择GC策略并设置JVM
Heap的大小即可。在调整了内存管理方面的参数后应通过-XX:+PrintGCDetails、-XX:+PrintGCTimeStamps、-XX:+PrintGCApplicationStoppedTime
及jstat 或 visualvm等方式来观察调整后GC的状况,除内存管理方面的调优外,Sun JDK还提供了一些其他方面的调优参数:
如:-XX:CompileThreshold、 -XX:+UseFastAccessorMethods
及 -XX:+UseBiasedLocking等。
基本上JVM调优,多数请下只需要选择GC策略(串行、并行、并发、G1)并设置JVM
Heap的大小即可。在调整了内存管理方面的参数应通过-XX:+PrintGCDetails、-XX:+PrintGCTimeStamps、-XX:+PrintGCApplicationStoppedTime及jstat
或 visualvm等方式来观察调整后GC的情况,除了内存管理方面的调优外, Sun JDK还提供了一些其他方面的调优参数:如-XX:CompileThreshold、-XX:+UseFastAccessorMethods
及-XX:+UseBiasedLocking等。
除了以上基于对JDK实现及JDK调优参数的掌握进行的调优外,关注JDK的新版本也是不错的选择。每次JDK新版本的发布几乎都会在性能上做出一些优化,也许这些优化正是应用所需要的额。
5.2 程序调优
5.2.1 CPU消耗严重的解决方法
5.2.1.1. CPU us高的解决方法
根据之前的分析,CPU us高的原因主要是执行线程无任何挂起动作,且一直执行,导致CPU没有机会去调度执行其他的线程,造成线程饿死的现象。对于这种情况,常见的一种优化方法是对这种线程的动作增加Thread.sleep(),以释放CPU的执行权,降低CPU的消耗。解决示例:UsHighOfCpuSolveDemo.java
按照这样的思路,对"CPU消耗分析"中的例子进行修改,在往集合中增加元素的部分增加sleep,修改如下代码:
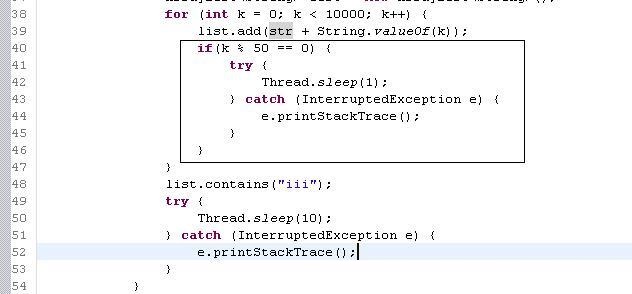
图-40
重新执行以上代码,通过top查看效果如图执行效果:
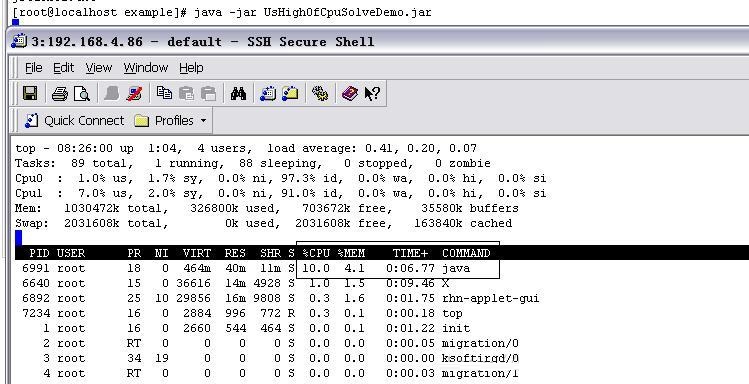
图-41
从上结果可见,CPU的消耗大幅度下降,当然,这种修改方式是以损失单次执行性能为代价的,但由于降低了CPU的消耗,对于多线程的应用而言,反而提高了总体的平均性能。
在实际的Java应用中会有很多类似的场景,例如多线程的任务执行管理器,它通常要通过扫描任务集合列表来执行任务。对于这些类似场景,都可通过增加一定的sleep时间来避免消耗过多的CPU.
对于其他类似循环次数太多、正则、计算等造成的CPU us过高的情况,则要结合业务需求来进行调优。
对于GC频繁造成的CPU us高的现象,则要通过JVM调优或程序调优,降低GC的执行次数。
5.2.1 2. CPU sy高的解决方法
5.2.1.2.1 减少线程数
CPU sy高的原因主要是线程的运行状态要经常切换,对于这种情况,最简单的优化方法是减少线程数。

可见减少线程数时能让sy值下降的,所以不是线程数越多吞吐量就越高,线程数需要设置为合理的值,这需要根据应用情况来具体决定,同时使用线程池避免要不断地创建线程。如应用要支撑大量的并发,在减少线程数的情况下最好是增加一个缓冲队列,避免因为线程数的减少造成系统出错率上升。
造成CPU sy高的原因除了启动的线程过多以外,还有一个重要的原因是程序之间锁竞争激烈,造成了线程状态经常要切换,因此尽可能降低线程间的锁竞争也是常见的优化方法。锁竞争降低后,线程的状态切换的次数也就会下降,sy值回相应下降。但值的注意的是人线程数过多,调优后有可能会造成us值过高,所以合理地设置线程数非常关键。锁竞争更有可能造成系统资源消耗不多,但系统性能不足的现象。
5.1.2.2.2 Coroutine(协程)
除了以上两种情况外,对于分布式Java应用而言,还有一种典型现象是应用中有较多的网络IO操作或确实需要一些锁竞争机制(例如数据库连接池),但为了能够支持高的并发量,在Java应用中有只能借助启动更多的线程来支撑。在这样的情况下当并发量增长到一定程度后,可能会造成CPU
sy高的线程,对于这种现象,可采用协程(Coroutine)来支撑更高的并发量,避免并发量上涨后造成CPU
sy消耗严重、系统load迅速上涨和系统性能下降。
采用协程后,能做到当线程等待数据库执行结果时,就立刻释放此线程资源给其他请求,等到数据库执行结果返回后才继续执行,在Java中目前主要可用于实现协程的框架为Kilim.
在使用Kilim执行ixiang任务时,并不创建Thread,而是改为创建Task,Task相对于Thread而言就轻量级多了。当次Task要做阻塞动作时,可通过Mailbox.get
或 Task.pause来阻塞当前的Task,Kilim会保存Task之后执行需要的对象信息,并释放Task执行所占用的线程资源;当Task的阻塞动作完成或被唤醒时,此时Kilim会重新载入Task所需的对象信息,恢复Task的执行,相当于Kilim来承担了线程的调度以及上下文切换动作。
这种方式相对原生Thread方式更为轻量,且能够更好第利用CPU,因此可做到仅启动CPU核数的线程数,以及大量的Task来吃撑高并发量,Kilim带来的是线程使用率的提升,但同时由于要在JVM堆中保存Task上下文信息,因此在采用Kilim的情况下要消耗更多的内存。
下面是一个传统方式的例子:SimpleBenchMark.java 和基于Kilim采用Coroutine方式支撑高并发请求例子:SimpleBenchMarkV2.java
通过运行比较传统方式耗时大概为3077ms,而基于Kilim采用协程方式的耗时大概为277ms,可见在这种高并发的情况下,协程方式对性能提升以及支撑更高并发量可以起到很大的作用。
目前Kilim还比较新,没有商用成功的案例,如打算在实际的系统中使用,还需要谨慎。一方面是0.7版本中基于object.wait/notify机制实现的Scheduler在高压下会出现bug,可自行基于ThreadPoolExecutor进行改造;另一个方面Mailbox.get(timeout)是基于Timer实现的,由于Timer在增加task到队列时和运行task队列是互斥的(即使是ScheduledTheadPoolExecutor也同样需要锁整个队列),对于大并发的应用而言这里是个潜在的瓶颈。对于Java应用而言,Timer是一个经常用来实现定时任务的类,但Timer的性能在高并发下一般,感兴趣的读者可以尝试基于TimerWheel算法来提升Timer的性能。
现在要在Java应用中使用Kilim来实现协程方式并不简单,因为协程方式要求所有的操作都不阻塞原生线程,这就要求应用中不能使用目前Java里的同步、锁等机制。除了这些外,还需要解决同步访问数据库、操作文件等问题,这些都必须改为是异步方式或Kilim中的Task暂停的机制。
目前Sun JDK7中也有一个支持协程方式的实现http://code.google.com/p/coroutines/。
另外基于JVM的Scala的Actor也可用于在Java中使用协程。
除了软件方面对提升CPU使用率做出的努力外,硬件方面的CPU专业化(例如
GPU进行图形计算)也很值的关注。
5.2.2 内存消耗严重的解决方法
在内存消耗方面,最明显的在于消耗了过多的JVM Heap内存,造成GC频繁执行的现象,而物理内存方面的消耗通常来说不会成为Java应用中的主要问题。除了JVM的调优外,在寻找到内存消耗严重的代码后,可从代码本身进行优化,避免内存资源消耗过多。此处就介绍一些JVM
Heap内存消耗严重时常用的程序调试方法。
5.2.2.1. 释放不必要的引用
内存消耗最严重的情况中最典型的一种现象是代码中持有了不需要的对象引用,造成这些对象无法被GC,从而占据了JVM堆内存。这种情况最典型的一个例子是在复用线程的情况下使用ThreadLocal,由于线程复用,ThreadLocal中存放的对象如未做主动释放的话则不会被GC释放。示例如下:
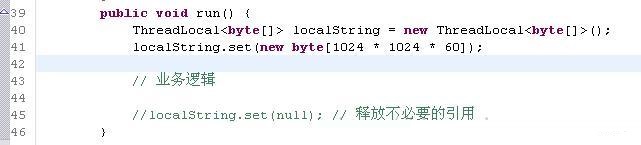
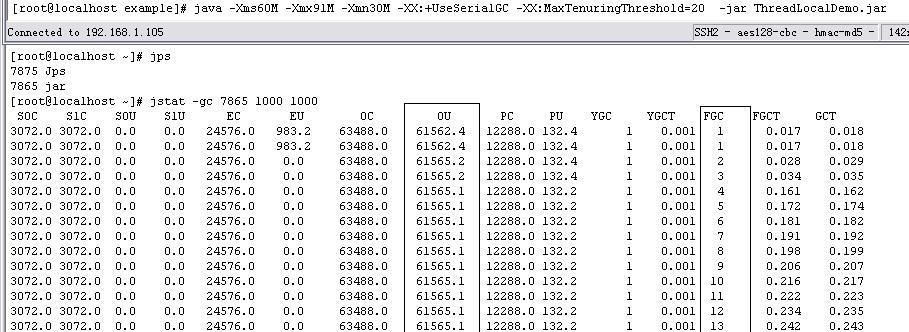
执行代码,通过jstat观察,会发现在Old Generation JVM内存一直被使用了60MB左右。

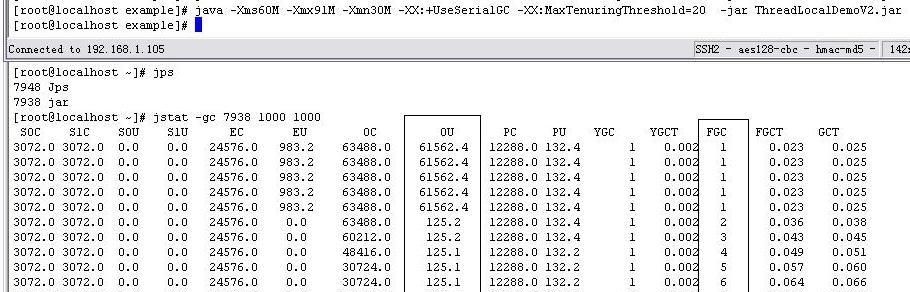
执行代码,通过jstat观察,会发现在Old Generation JVM内存一直被使用了60MB左右。对于这种情况,要注意在线程内的动作执行完毕时执行ThreadLocal.set把对象清除,避免持有不必要的对象引用。会发现在Old
Generation JVM内存从60MB左右降到了1M左右。
5.2.2.2. 使用对象缓存池
创建对象的实例要耗费一定的CPU以及内存,使用对象缓存池一定程度上可降低JVM
Heap内存的使用。
通过运行程序:ObjectPoolDemo.java(下载地址见 参考部分)
1 没有采用对象缓存池情况
参数:VM Args : -Xms128M -Xmx128M -Xmn64M
( runMode is NOTUSE_OBJECTPOOL:)
Main Args:
执行结果:Execute summary: Round( 10 ) Thread
Per Round( 100 ) Object Factor ( 10 ) Execute Time (
111594 ) ms
2 采用对象缓存池情况
参数:VM Args : -Xms128M -Xmx128M -Xmn64M
( runMode is USE_OBJECTPOOL:)
Main Args: 2
执行结果:Execute summary: Round( 10 ) Thread
Per Round( 100 ) Object Factor ( 10 ) Execute Time (
1094 ) ms
从上面的结果对比可看出,在内存消耗严重的情况下,采用对象缓存池可大幅度提升性能,避免创建对象所耗费的时间及频繁GC造成的消耗。
5.2.2.3. 采用合理的缓存失效算法
上面说到了采用对象缓冲池来降低内存的消耗,但如果放入太多的对象在缓存池中,反而会造成内存的严重消耗。同时由于缓存池一直对这些对象持有引用,从而会造成Full
GC增多,对于这种情况要合理控制缓存池的大小。
控制缓存池大小的问题在于当到达缓存池的最大容量后,如果要加入新的对象该如何处理?有一些经典的缓存失效算法来清除缓冲池中的对象,例如FIFO,LRU,LFU等。采用这些算法可控制缓存池中的对象数目,避免缓存池中的对象数量无限上涨。
ObjectCachePoolDemo.java(下载地址见 参考部分)
输入参数:向容器总插入15个元素,保存容器10个元素
输出结果:
size(10), policy(1) FIFO
6, 6
7, 7
8, 8
9, 9
10, 10
11, 11
12, 12
13, 13
14, 14
15, 15 |
分析:按着FIFO缓存失效算法,失效了元素1,2,3,4,5,保持容器中有10个元素
5.2.2.4. 合理使用SoftReference 和 WeakReference
对于占据内存但又不是必须存在的对象,例如缓存对象,也可以基于SoftReference或WeakReference的方式来进行缓存。SoftReference的对象会在内存不够用的时候进行回收,WeakReference的对象则会在Full
GC的时候回收,采用这两种方式也能一定程序上减少JVM Heap区内存的消耗。
对于以上硬件资源消耗过多造成的性能不足的现象,除了软件方面调优外,在大多数情况下还可通过升级或增加硬件来提升程序的性能。
5.2.2 文件IO消耗严重的解决方法
从程序角度而言,造成文件IO消耗严重的原因主要是多个线程在写大量的数据到同一个文件,导致文件很快变的很大,从而写入速度越来越慢,并造成各线程激烈抢文件锁,对于这类情况,通常调优的有以下方法:可以参考log4j
5.2.2.1 异步写文件
将写文件的同步动作改为异步动作,避免应用由于写文件慢而性能下降太多,例如写日志,可以使用log4j提供的AsyncAppender.
5.2.2.2 批量读写
频繁的读写操作对IO消耗会很严重,批量操作将大幅度提升IO操作的性能。
5.2.2.3 限流
频繁读写的另外一个调优方式是限流,从而将文件IO消耗控制到一个能接受的范围。log.error
log.warn. log.info. log.debug.
5.2.2.4 限制文件大小
操作太大的文件也是造成文件IO效率低的一个原因,因此对于每个输出的文件,都应该做大小的限制,在超过最大值后可生成一个新的文件,类似log4j中RollingFileAppender的maxFileSize属性的作用。
除了以上这些外,还有就是尽可能采用缓冲区等方式来读取文件内容,避免不断与操作系统交行,参考
Sun官方的关于Java文件IO优化的文章:见参考部分的[4.5]Articles: Tuning Java
I/O Performance
5.2.3 网络IO消耗严重的解决方法
从程序角度而言,造成网络IO消耗严重的原因主要是同时需要发送或接收的包太多。对于这类情况,常用的调优方法为进行限流,限流通常是限制发送packet的频率,从而在网络IO消耗可接受的情况下来发送packet.
《Linux Performance and Tuning Guidelines.pdf》《IO的阻塞与非阻塞、同步与异步以及Java网络IO交互方式》
5.3 对于资源消耗不多,但程序执行慢的情况(需补充)
对于分布式Java应用而言,造成这这种情况的主要原因通常有锁竞争激烈及未充分发挥硬件资源两种。
5.3.1 锁竞争激烈
线程多了后,锁竞争的状况会比较明显,这时线程很容器处于等待锁的状况,从而导致性能下降以及CPU
sy上升。
示例:LockHotDemo.java
执行结果:Execute summary: Round( 10 ) Thread
Per Round( 200 ) Execute Time ( 10579 ) ms
此时各方面的资源消耗并不高,但性能比没哟锁的情况下降了非常多。从这个例子可见,锁是影响性能的重要因素,但为了保证资源的一致性,多线程应用中锁的使用是不可避免的,只能尽量去降低线程间的锁竞争,常见的方法如下:使用并发包中的类、使用Treiber算法、使用Michael-Scott非阻塞队列算法、尽可能减少锁、拆分锁、去除读写操作的互斥锁等
5.3.1.1 使用并发包中的类
第三方并发库:Disruptor、JPPF、Kilim、Amino
对于java.util.concurrent包中的类的分析,可以看出,并发包中的类多数都采用了
lock-free、nonblocking算法,减少了多线程情况下资源的锁竞争,因此对于线程间要共享操作的资源而言,应尽量使用并发包中的类来实现(AtomicInteger、ConcurrentHashMap等),当系统提供的并发包中的类无法满足需求时,可参考学习一些nonblocking算法来自行实现,nonblocking算法的机制,为基于CAS来做到无需lock就可实现资源一致性的保证,主要的实现nonblocking的算法有:
5.3.1.2 使用Treiber算法
Treiber算法主要用于实现Stack,基于Treiber算法实现的无阻塞的Stack代码如下:
代码例子参考:并发栈ConcurrentStack<E>:
http://blog.csdn.net/ajian005/article/details/18324407
由于Stack是LIFO方式,因此不能采用类似LinkedBlockingQueue中两把锁的机制。这里巧妙地采用AtomicReference来实现了无阻塞的push和pop,
在push时基于AtomicReference的CAS方法来比较目前的head是否一致。如不一致,说明有其他线程改动了,如有改动则继续循环,直到一致,才修改head元素,在pop时可以采用同样的方式进行操作。
测试用例,测试结果:
Stack consume Time: 125 ms
ConcurrentStack consume Time: 63 ms
5.3.1.3 使用Michael-Scott非阻塞队列算法
和Treiber算类似,Michael-Scott算法也是基于CAS以及AtomicReference来实现队列的非阻塞操作,java.util.concurrent中的ConcurrentLinkedQueue就是典型的基于Michael-Scott实现的非阻塞队列。ConcurrentLinkedQueue在执行offer动作时,通过CAS比较拿到的tail元素是否为当前处于末尾的元素,如不是则继续循环,如是则将tail元素更新为新的元素。
在执行poll动作时,通过CAS比较拿到的head元素是否为当前处于首位的元素,如不是则继续循环,如是则将head后的元素赋值给head,同时获取之前head元素中的值并返回。
从上面两种算法来看,基于CAS 和 AtomicReference来实现无阻塞是不错的选择。但值得注意的是,由于CAS是基于不断的循环比较来保证资源一致性的,对于冲突较多的应用场景而言,CAS会带来更高的CPU消耗,因此不一定采用CAS实现无阻塞的就一定比采用Lock方式的性能好。业界中还有一些无阻塞算法的改进,例如MCAS、WSTM等。
5.3.1.4 尽可能少用锁
尽可能让锁仅在需要的地方出现,通常没必要对整个方法加锁,而只对需要控制的资源做加锁操作。
将锁最小化后,性能会有提高,在编写多线程程序时,要仔细考虑哪些地方是要加锁的,哪些地方是不要加锁的。尽可能让锁最小化,只对互斥及原子操作的地方加锁,加锁时尽可能以被包含资源的最小粒度为单位。
5.3.1.5 拆分锁
拆分锁即把独占锁拆分为多把锁,常见的有读写锁拆分及类似ConcurrentHashMap中默认拆分为16把锁的方法。拆分锁很大程度上能提高读写的速度,但需要注意的是在采用拆分锁后,全局性质的操作会变的比较复杂,例如ConcurrentHashMap中的size操作。
是否拆分锁还得根据业务场景来决定。有些场景并不适合做锁的拆分,而且锁拆分的太多也会造成其他副作用,例如CPU的消耗明显增加等,因此锁拆分要在合理的业务场景以及CPU消耗下进行。
5.1.3.6 去除读写操作的互斥锁
在修改时加锁,并在复制对象时进行修改,修改完毕后切换对象的引用,而读取时则不加锁,这种方式称为CopyOnWrite.
CopyOnWriteArrayList是CopyOnWrite方法的典型实现,CopyOnWrite的好处是可以明显提升读的性能,对于读多写少的应用非常适合,但由于写操作时每次都要复制一份对象,会造成更多的内存消耗。
5.3.2 未充分使用硬件资源
这种情况也是性能低的应用中经常出现的,主要体现在未充分使用CPU 和 内存。
5.3.2.1 未充分使用CPU
对于Java应用而言,未充分使用CPU的原因主要是在能并行处理的场景中未使用足够的线程。
例子 CpuNotUseEffectiveDemo.java 单线程
对于有多个或多核的CPU而言要充分使用CPU.
例子 CpuUseEffectiveDemo.java 单线程
对于此类可以演变为多线程也无须加锁的场景而言,启动多个线程后的性能会远高于单线程,并且只要启动的线程数合理,也不会给CPU造成过大的负担。如从单线程演变为多线程要加锁,则要引入尽量减少锁竞争的方法,并进行性能测试以保证调优后的资源消耗以及性能满足要求。
此种类型的场景还有不少,例如单线程的计算,可以拆分为多线程来分别计算,最后将结果合并,这样的方式也可很大程度提升系统的性能,JDK7中的fork-join框架可以给以上这类场景提供一个好的支撑方法。
在CPU资源消耗可接受,且不会因为线程增加带来激烈锁竞争的场景下,应适当对处理过程进行分解,增加线程数从而能并行处理以提升系统的运行性能。但在重构为并行时,要注意控制内存消耗,而且通过重构为并行能提升的性能也是有限的。著名的Amdahl定律中的简单计算公式为:
系统提升的性能 = 1/ (F+(1-F)/N), 其中F为必须串行化的执行在整个执行过程中所占的比率,
N为处理器个数,例如在整个执行过程中串行化的过程占50%,那么最多只能提升2倍的性能。
5.3.2.2 未充分使用内存
未充分使用内存的场景非常多,如数据的缓存、耗时资源的缓存(例如数据库连接的创建、网络连接的创建等)、页面片段的缓存等,这样的场景比较容易理解,毕竟内存的读取肯定远快于硬盘、网络的读取。但也要避免内存资源的过度使用,在内存资源消耗可接受,GC频率及系统结构(例如集群环境可能会带来缓存的同步等)可接受的情况下,应充分使用内存来缓存数据,提升系统的性能。
5.3.2.3 对于数据量大造成的性能不足
数据分库、分表、分区等
好的调优策略应是收益比(调优后提升的效果/调优改动所付出的代价)最高的,通常来说功能简单的系统调优比较好做,否则有可能出现调优了当前功能影响到了其他功能,因此应尽量保持单机上应用功能的纯粹性,这是大型系统的基本架构原则。
从纯粹的软件调优角度来讲,充分而不过分使用硬件资源,合理调整JVM(操作系统、虚拟机)以及合理使用JDK包(语言提供的核心库)是调优的三大有效原则,调优没有“银弹”,结合系统现状和多尝试不同的调优策略是找到合适的调优方法的唯一途径。
查看是否有进程被系统给kill掉了:
dmesg | grep -i oom
cat /var/log/messages
sudo grep oom /var/log/messages
sudo less /var/log/messages
|
|






