| 第
1 部分: 基本特性和 Solr 模式
使用 Solr 进行索引、搜索和层面浏览
Solr 是一种可供企业使用的、基于 Lucene 的搜索服务器,它支持层面搜索、命中醒目显示和多种输出格式。在这篇分两部分的文章中,Lucene
Java? 的提交人 Grant Ingersoll 将介绍 Solr 并向您展示如何轻松地将其表现优异的全文本搜索功能加入到
Web 应用程序中。
一旦用户需要某种信息,就可以立即搜索到这些信息,这种要求再也不是可有可无的了。随着
Google 和类似的复杂搜索引擎的出现,用户希望得到高质量的搜索结果,帮助他们快速、轻易地找到所需的信息。经理对您的在线购物站点同样抱有很高的期望,要求它能够提供一个可伸缩、高度可用且易于维护的搜索解决方案,并且安装这个解决方案不应太昂贵。对于您而言,只是希望事业进步,让老板和客户满意,以及保持头脑清醒。
使用 Apache Solr 可以满足所有的这些要求,它是一种开放源码的、基于 Lucene Java
的搜索服务器,易于加入到 Web 应用程序中。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括
XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于 HTTP 的管理界面。您可以坚持使用
Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。Solr 还拥有一个活跃的开发者群体,如有需要,您可以随时向他们寻求帮助。
这篇分为两部分的文章将介绍 Solr,展示其特性并举例说明如何将其完全加入到
Web 应用程序中。 我们将首先提供一些 Solr 的基本介绍,包括安装和配置的说明。然后引入一个示例应用程序(博客界面),您可以通过该程序让自己熟悉一下
Solr 的各种特性。您将学习如何使用 Solr 来索引和搜索内容并探索 Solr 对层面浏览的支持。第
1 部分的最后将简要介绍一下 Solr 的模式并解释如何针对示例应用程序的索引结构配置模式。
Solr 的历史
Solr 最初由 CNET Networks 开发,2006 年初,Apache
Software Foundation 在 Lucene 顶级项目的支持下得到了 Solr。Solr 于
2007 年 1 月酝酿成熟,在整个项目孵化期间,Solr 稳步地积累各种特性并吸引了一个稳定的用户群体、贡献者和提交人。Solr
现在是 Lucene(Apache 的基于 Java 的全文本搜索引擎库)的一个子项目。
安装和配置
要开始使用 Solr,需安装以下软件:
Java 1.5 或更高版本。
Ant 1.6.x 或更高版本。
Web 浏览器,用来查看管理页面。建议使用 Firefox;相比之下使用
Internet Explorer 可能要复杂些。
servlet 容器,如 Tomcat 5.5。本文中的示例假定您的 Tomcat
在 8080 端口上运行,这是 Tomcat 的默认设置。如果运行的是其他 servlet 容器或在其他的端口上运行,则可能要修改给出的
URL 才能访问示例应用程序和 Solr。我已经假定示例应用程序的各个部分都运行在 Tomcat 的本地主机上。另外还要注意
Solr 以打包的方式与 Jetty 一起提供。
要下载和安装所有这些应用程序,请参阅 参考资料。
设置 Solr
一旦搭建好运行环境,就可以从 Apache Mirrors Web 站点
下载 Solr 1.1 版。接下来,执行以下操作:
停止 servlet 容器。
在命令行选择希望在其中执行操作的目录,从中输入 mkdir dw-solr。
输入 cd dw-solr。
将 Solr 下载版本复制到当前目录中并解压缩。 即可得到 apache-solr-1.1.0-incubating
目录。不用注意 incubating 标记;Solr 早已孵化成熟。
将 Solr WAR 文件复制到 servlet 容器的 webapps
目录中。
下载示例应用程序,将其复制到当前目录,然后解压缩,即可在当前工作目录中得到一个
solr 目录。本文将一直把它用作 Solr 的主目录。
可以通过以下三种方式之一设置 Solr 的主位置:
设置 java 系统属性 solr.solr.home (没错,就是 solr.solr.home)。
配置 java:comp/env/solr/home 的一个 JNDI
查找指向 solr 目录。
在包含 solr 目录的目录中启动 servlet 容器。(默认的 Solr
主目录是当前工作目录下的 solr。)
将示例 WAR 文件(位于 dw-solr/solr/dist/dw.war
中)复制到 servlet 容器的 webapps 目录中,方法与复制 Solr WAR 文件相同。WAR
文件的 Java 的代码位于 dw-solr/solr/src/java 中,而 JSP 和其他 Web
文件位于 dw-solr/solr/src/webapp 中。
要验证所有程序都正常运行,请启动 servlet 容器并将浏览器指向 http://localhost:8080/solr/admin/。如果一切顺利,您应该看到类似图
1 所示的页面。如果没有出现管理页面,查看容器日志中的错误消息。另外,确保从 dw-solr 目录启动
servlet 容器,以便可以正确地设置 Solr 的主位置。
关于 Lucene
要了解 Solr 就必须熟悉 Lucene。 Lucene 是一个基于
Java 的高性能文本搜索引擎库,最初由 Doug Cutting 编写,后来被捐赠给 Apache Software
Foundation。很多应用程序都利用 Lucene 来增强自身的搜索功能,因为 Lucene 高速、易用和具有活跃社区的特点。Solr
构建在这些功能之上,使 Lucene 可供企业使用,并具有最小的编程需求。有关 Lucene 的更多信息,请参见
参考资料。
图 1. 一个 Solr 管理屏幕示例
Solr 基础
因为 Solr 包装并扩展了 Lucene,所以它们使用很多相同的术语。更重要的是,Solr
创建的索引与 Lucene 搜索引擎库完全兼容。通过对 Solr 进行适当的配置,某些情况下可能需要进行编码,Solr
可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如 Luke)也可以使用
Solr 创建的索引。
在 Solr 和 Lucene 中,使用一个或多个 Document 来构建索引。Document
包括一个或多个 Field。Field 包括名称、内容以及告诉 Solr 如何处理内容的元数据。例如,Field
可以包含字符串、数字、布尔值或者日期,也可以包含您想添加的任何类型。Field 可以使用大量的选项来描述,这些选项告诉
Solr 在索引和搜索期间如何处理内容。我将在本文中稍后详细讨论这些选项。现在,查看一下表 1 中列出的重要属性的子集:
表 1. 字段属性

Solr 的分析过程
您可以在对应用程序内容索引之前运行 Solr 的分析过程来修改这些内容。在
Solr 和 Lucene 中,Analyzer 包括一个 Tokenizer 和一个或多个 TokenFilter。Tokenizer
负责 生成 Token,后者在多数情况下对应要索引的词。TokenFilter 从 Tokenizer
接受 Token 并且可以在索引之前修改或删除 Token。 例如,Solr 的 WhitespaceTokenizer
根据空白断词,而它的 StopFilter 从搜索结果中删除公共词。其他类型的分析包括词干提取、同义词扩展和大小写折叠。如果应用程序要求以某种特殊方式进行分析,则
Solr 所拥有的一个或多个断词工具和筛选器可以满足您的要求。
您还可以在搜索操作期间对查询应用分析。一个总体规则是:应该对查询和要索引的文档运行相同的分析。不熟悉这些概念的用户常犯的一个错误就是:对文档标记进行词干提取,但不对查询标记进行词干提取,通常导致零搜索匹配。Solr
的 XML 配置使它可以轻易地使用简单声明创建 Analyzer,本文稍后会对此作出展示。
有关 Solr 和 Lucene 的分析工具,以及索引结构和其他功能的更多信息,请参阅
参考资料。
示例应用程序
以下各节将使用实际的示例应用程序向您介绍 Solr 的功能。该示例应用程序是一个基于
Web 的博客界面,您可以使用它来记录条目、给条目指派元数据,然后索引和搜索条目。在索引和搜索过程的每一步,您都可以选择显示发送到
Solr 的命令。
要查看示例应用程序,请将浏览器指向 http://localhost:8080/dw/index.jsp。如果一切设置正确(如
“设置 Solr” 描述的那样),则您可以看到一个题为 “Sample Solr Blog Search”
的简单用户界面,在标题的正下方有一些菜单项。当您浏览本文的两个部分时,将会了解到菜单中的所有主题。
索引操作
在 Solr 中,通过向部署在 servlet 容器中的 Solr Web
应用程序发送 HTTP 请求来启动索引和搜索。Solr 接受请求,确定要使用的适当 SolrRequestHandler,然后处理请求。通过
HTTP 以同样的方式返回响应。默认配置返回 Solr 的标准 XML 响应。您也可以配置 Solr 的备用响应格式。我将在本文的第
2 部分向您展示如何定制请求和响应处理。
索引就是接受输入(本例中是博客条目、关键字和其他元数据)并将它们传递给
Solr,从而在 HTTP Post XML 消息中进行索引的过程。您可以向 Solr 索引 servlet
传递四个不同的索引请求:
add/update 允许您向 Solr 添加文档或更新文档。直到提交后才能搜索到这些添加和更新。
commit 告诉 Solr,应该使上次提交以来所做的所有更改都可以搜索到。
optimize 重构 Lucene 的文件以改进搜索性能。索引完成后执行一下优化通常比较好。如果更新比较频繁,则应该在使用率较低的时候安排优化。一个索引无需优化也可以正常地运行。优化是一个耗时较多的过程。
delete 可以通过 id 或查询来指定。按 id 删除将删除具有指定
id 的文档;按查询删除将删除查询返回的所有文档。
一个索引示例
浏览到 http://localhost:8080/dw/index.jsp
可以查看索引过程的更多细节。首先为表单中的每个字段填入适当的条目并按 Submit 按钮。示例应用程序接受条目、创建
Solr 请求并显示请求以便在下一个屏幕上查看。清单 1 包含了一个 add 命令的例子,当您按下 Submit
按钮时向 Solr 发送这个命令。
清单 1. Solr add 命令样例
<add>
<doc>
<field name="url">http://localhost/myBlog/solr-rocks.html</field>
<field name="title">Solr Search is Simply Great</field>
<field name="keywords">solr,lucene,enterprise,search</field>
<field name="creationDate">2007-01-06T05:04:00.000Z</field>
<field name="rating">10</field>
<field name="content">Solr is a really great open source search server. It scales,
it's easy to configure and the Solr community is really supportive.</field>
<field name="published">on</field>
</doc>
</add> |
清单 1 的 <doc> 中的每个 field 条目告诉 Solr
应该将哪些 Field 添加到所创建文档的 Lucene 索引中。可以向 add 命令添加多个 <doc>。稍后我将解释
Solr 如何处理这些 field。现在,知道包含清单 1 中指定的七个 field 的文档将会被索引就足够了。
当您在 “Solr XML Command” 页面提交命令时,结果将发往
Solr 进行处理。HTTP POST 将命令发往在 http://localhost:8080/solr/update
运行的 Solr Update Servlet。如果一切进展顺利,则会随 <result status="0"/>
返回一个 XML 文档。Solr 使用相同的 URL 自动更新文档(示例应用程序中的 URL 是 Solr
识别文档以前是否被添加过所使用的惟一 id)。
实践索引
现在再添加几个文档并提交这些文档,以便在下一节中有文档可供搜索。一旦您熟悉
add 命令的语法后,就可以取消选择 Index 按钮旁边的 “Display XML...” 复选框,跳过
“Solr XML Command” 页面。本文附带的 样例文件 包含了一个很多这些示例中使用的索引版本。
您可以通过在 http://localhost:8080/dw/delete.jsp
页面输入文档的 URL、提交并查看命令,然后将命令提交到 Solr 来删除文档。有关索引和删除命令的更多信息,请参阅
参考资料 中的 “Solr Wiki” 参考。
关于查询语法的一点注意
用于 StandardRequestHandler 的 Solr 查询语法与
Lucene QueryParser 支持的查询语法相同,只是前者加入了一些排序支持。示例应用程序对输入的值几乎没有进行验证,而且没有演示如查询增强、短语、范围筛选等功能,所有这些功能在
Solr 和 Lucene 中都有效。有关 Lucene QueryParser 的更多信息,请参阅 参考资料。在本文的第
2 部分,我将介绍管理界面中的一些有助于调试查询语法和结果的工具。
搜索命令
添加文档后,就可以搜索这些文档了。Solr 接受 HTTP GET 和
HTTP POST 查询消息。收到的查询由相应的 SolrRequestHandler 进行处理。出于本文的讨论目的,我们将使用默认的
StandardRequestHandler。在本文的第 2 部分,我将向您展示如何为其他的 SolrRequestHandler
配置 Solr。
要查看搜索运行,返回到示例应用程序并浏览到 http://localhost:8080/dw/searching.jsp。此屏幕应该与索引屏幕非常类似,只是增加了几个搜索相关的选项。与索引类似,可以向各种输入字段中输入值,选择搜索参数并将查询提交给示例应用程序。示例应用程序醒目显示了一些
Solr 中更常见的查询参数。这些参数如下所示:
布尔运算符:默认情况下,用于合并搜索条目的布尔运算符是 OR。将它设为
AND 要求匹配的文档中出现所有的条目。
结果数目:指定返回的最大结果数目。
开始:结果集中开始的偏移量。此参数可用于分页。
醒目显示:醒目显示匹配文档字段的条目。参考 清单 2 底部的 <lst>
节点。醒目显示的条目标记为 <em>。
一旦输入和提交值后,博客应用程序就返回一个可以立即提交给 Solr 的查询字符串。提交字符串后,如果一切正常并且存在匹配文档,则
Solr 返回一个 XML 响应,其中包含了结果、醒目显示的信息和一些有关查询的元数据。清单 2 给出了一个示例搜索结果:
清单 2. 搜索结果示例
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">6</int>
<lst name="params">
<str name="rows">10</str>
<str name="start">0</str>
<str name="fl">*,score</str>
<str name="hl">true</str>
<str name="q">content:"faceted browsing"</str>
</lst>
</lst>
<result name="response" numFound="1" start="0" maxScore="1.058217">
<doc>
<float name="score">1.058217</float>
<arr name="all">
<str>http://localhost/myBlog/solr-rocks-again.html</str>
<str>Solr is Great</str>
<str>solr,lucene,enterprise,search,greatness</str>
<str>Solr has some really great features, like faceted browsing
and replication</str>
</arr>
<arr name="content">
<str>Solr has some really great features, like faceted browsing
and replication</str>
</arr>
<date name="creationDate">2007-01-07T05:04:00.000Z</date>
<arr name="keywords">
<str>solr,lucene,enterprise,search,greatness</str>
</arr>
<int name="rating">8</int>
<str name="title">Solr is Great</str>
<str name="url">http://localhost/myBlog/solr-rocks-again.html</str>
</doc>
</result>
<lst name="highlighting">
<lst name="http://localhost/myBlog/solr-rocks-again.html">
<arr name="content">
<str>Solr has some really great features, like <em>faceted</em>
<em>browsing</em> and replication</str>
</arr>
</lst>
</lst>
</response> |
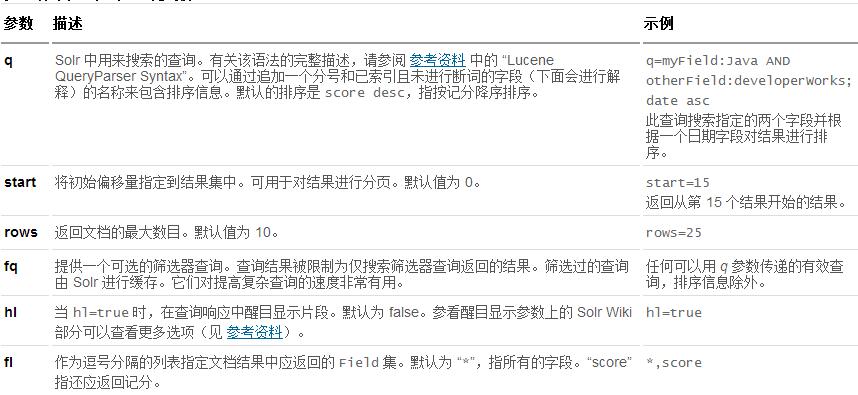
一条查询消息可以包含大量的参数,表 2 中对醒目显示的那些参数进行了描述。参阅 参考资料 中的 “Solr
Wiki” 参考可以查看参数的完整清单。
表 2. 醒目显示的查询参数
层面浏览
最近,似乎所有流行的购物站点都添加了便利的条件列表,帮助用户根据制造商、价格和作者缩小搜索结果的范围。这些列表是层面浏览的结果,层面浏览是一种分类方式,用于对已经返回到有意义的、已证实存在的种类的结果进行分类。层面用于帮助用户缩小搜索结果的范围。
通过浏览到 http://localhost:8080/dw/facets.jsp 可以查看层面的运行。在这个页面上,您需要关注两种输入形式:
一个文本区域,您可以在其中输入查询,根据索引中的 all 字段发布此查询。将 all 字段看作一连串已索引的所有其他字段。(稍后将对此作详细介绍。)
一个可以用于分层面的字段下拉列表。此处并未列出所有的已索引字段,其原因马上就会得到解释。
输入一个查询并从下拉列表中选择一个层面字段,然后单击 Submit 与生成的查询一起传递给 Solr。博客应用程序解析结果并返回类似图
2 中的结果:
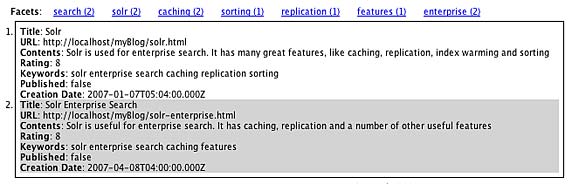
图 2. 层面浏览结果示例
层面浏览结果示例的屏幕截图。
在图 2 中,您可以在顶部看见所有非零值的层面计数,底部则是匹配所提交查询的两个搜索结果。单击示例中的层面链接提交原始查询,另外将
Facet 关键字作为一个新关键字。如果原始查询是 q=Solr 而层面字段是 keywords,并且单击图
2 中的 replication 链接,则新查询将会是 q=Solr AND keywords:replication。
运行层面不需要打开它或在 Solr 中进行配置,但是可能需要按照新的方式对应用程序内容进行索引。在已索引的字段中完成分层,层面对未进行断词的非小写词最为有效。(因此我并未包含
content 字段或 Facet Field 下拉列表中添加到文档的其他字段。)Facet 字段通常不需要存储,因为分层面的总体思想就是显示人类可读的值。
另外还要注意 Solr 没有在层面中创建类别;必须由应用程序自身在索引期间进行添加,正如在索引应用程序时给文档指派关键字一样。如果存在层面字段,Solr
就提供了查明这些层面及其计数的逻辑。
Solr 模式
迄今为止,我已向您介绍了 Solr 的特性,但没有实际解释如何配置这些特性。本文的剩余部分主要介绍配置,首先介绍
Solr 模式(schema.xml)然后向您展示它如何与 Solr 的特性相关联。
在编辑器中,最好是支持 XML 标记醒目显示的编辑器,打开位于 <INSTALL_DIR>/dw-solr/solr/conf
中的 schema.xml 文件。首先要注意的是大量的注释。如果您以前使用过开放源码的软件,您将会为模式文件中的文档及整个
Solr 中的文档欣喜不已。因为 schema.xml 的注释非常全面,所以我主要介绍文件的一些关键属性,具体细节可查阅文档。首先,注意
<schema> 标记中模式(dw-solr)的名称。Solr 为每个部署支持一个模式。将来它可能支持多个模式,但是目前只允许使用一个模式。(参阅
参考资料 中的 “Solr Wiki” 参考,了解如何简单地配置 Tomcat 和其他容器,以便为每个容器使用多个部署。)
模式可以组织为三部分:
类型
字段
其他声明
<types> 部分是一些常见的可重用定义,定义了 Solr(和 Lucene)如何处理
Field。在示例模式中,有 13 个字段类型,按名称从 string 到 text。<types>
部分顶部声明的字段类型(如 sint 和 boolean)用于存储 Solr 中的原始类型。在很大程度上,Lucene
只处理字符串,因此需要对整型、浮点型、日期型和双精度型进行特殊处理才能用于搜索。使用这些字段类型会警告
Solr 使用适当的特殊处理索引内容,不需要人为干涉。
类型
本文前面的内容中,我简要介绍了 Solr 的分析过程的基础。仔细观察一下 text 字段类型声明,您可以看见
Solr 管理分析的细节。清单 3 给出了 text 字段类型声明:
清单 3. 文本字段类型声
<fieldtype name="text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
generateNumberParts="1" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory"
protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
generateNumberParts="1" catenateWords="0"
catenateNumbers="0" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldtype> |
类属性
在 Solr 模式中的很多实例中,类属性简化为类似 solr.TextField
的样子。 这是 org.apache.solr.schema.TextField 的简略表达形式。在本文的第
2 部分中您将看到,类路径中扩展 org.apache.solr.schema.FieldType 类的任何有效类都可能使用到。
首先,注意我在清单 3 中声明了两个不同的 Analyzer。虽然 Analyzer
对于索引和搜索并非完全相同,但是它们只是在查询分析期间的同义词添加方面有所差别。词干提取、停止词删除以及相似的操作都被应用于标记,然后才进行索引和搜索,导致使用相同类型的标记。接下来,注意我首先声明断词工具,然后声明使用的筛选器。示例应用程序的
Solr 配置按以下步骤进行设置:
根据空白进行断词,然后删除所有的公共词(StopFilterFactory)
使
破折号处理特殊的大小写、大小写转换等等。(WordDelimiterFilterFactory);将所有条目处理为小写(LowerCaseFilterFactory)
使用 Porter Stemming 算法进行词干提取 (EnglishPorterFilterFactory)
删除所有的副本(RemoveDuplicatesTokenFilterFactory)
示例分析加入了很多用于改进搜索结果的常见方法,但不应被看作分析文本的惟一方式。每个应用程序都可能有一些自己的分析需求,这个示例或者甚至是
Solr 或 Lucene 中的任何现有 Analyzer 都可能没有涉及相应需求。请参阅 参考资料 中的
“More Info On Solr Analysis”,了解关于分析的更多选项以及如何使用其他 Analyzer
的信息。
字段
继续介绍模式的 <fields> 部分,查看 Solr 如何处理索引和搜索期间使用的
8 个(实际上是 7 个,外加一个 all)字段。清单 4 中重复了这些字段:
清单 4. 博客应用程序的声明字段
<field name="url" type="string" indexed="true" stored="true"/>
<field name="title" type="text" indexed="true" stored="true"/>
<field name="keywords" type="text_ws" indexed="true" stored="true"
multiValued="true" omitNorms="true"/>
<field name="creationDate" type="date" indexed="true" stored="true"/>
<field name="rating" type="sint" indexed="true" stored="true"/>
<field name="published" type="boolean"
indexed="true" stored="true"/>
<field name="content" type="text"
indexed="true" stored="true"
/>
<!-- catchall field,
containing many of the other searchable text fields
(implemented via copyField further on in this
schema) -->
<field name="all" type="text"
indexed="true" stored="true"
multiValued="true"/> |
理解字段类型后,您可以清晰地看见如何处理每个字段。例如,url 字段是一个经过索引、存储和未经分析的
string 字段。 同时,使用 清单 3 中声明的 Analyzer 来分析 text 字段。all
字段如何处理?all 字段是一个 text 字段,如 title 或 content 一样,但是它包含了连接在一起的几个字段的内容,便于使用备用搜索机制(记住层面搜索使用的是
all 字段)。
对于字段的属性,在 表 1 中您已经了解了 indexed 和 stored 的意义。multiValued
属性是一个特殊的例子,指 Document 可以拥有一个相同名称添加了多次的 Field。比如在我们的示例中,可以多次添加
keywords。omitNorms 属性告诉 Solr(和 Lucene)不要存储规范。省略规范对于节省不影响记分的
Field 的内存非常有用,比如那些用于计算层面的字段。
在结束 <fields> 部分之前,简要介绍一下字段声明下方的 <dynamicField>
声明。动态字段是一些特殊类型的字段,可以在任何时候将这些字段添加到任何文档中,由字段声明定义它们的属性。动态字段和普通字段之间的关键区别在于前者不需要在
schema.xml 中提前声明名称。Solr 将名称声明中的 glob-like 模式应用到所有尚未声明的引入的字段名称,并根据其
<dynamicField> 声明定义的语义来处理字段。例如,<dynamicField
name="*_i" type="sint" indexed="true"
stored="true"/> 指一个 myRating_i 字段被 Solr
处理为 sint,尽管并未将其声明为字段。这种处理比较方便,例如,当需要用户定义待搜索内容的时候。
其他声明
最后,schema.xml 文件的最后部分包含了字段和查询相关的各种声明。最重要的声明是 <uniqueKey>url</uniqueKey>。该声明用于告诉
Solr 先前声明的 url 字段是用于确定何时添加或更新文档的惟一标识符。defaultSearchField
是查询条目没有前缀任何字段时 Solr 在查询中使用的 Field。示例所使用的查询与 q=title:Solr
类似。如果您输入 q=Solr,则应用默认搜索字段。 最终结果与 q=all:Solr 相同,因为 all
是博客应用程序中的默认搜索字段。
<copyField> 机制让您能够创建 all 字段而无需将文档的所有内容手工添加到单独的字段。复制字段是以多种方式索引相同内容的简便方法。例如,如果您希望提供区分大小写的精确匹配和忽略大小写的匹配,则可以使用一个复制字段自动分析收到的内容。然后严格按照收到的内容进行索引(所有的字母使用小写)。
下一步:用于企业的 Solr
目前为止,您已经安装了 Solr 并学习了如何使用它在示例应用程序中索引和搜索文档。您也了解了 Solr
中层面浏览如何工作,并学习了如何使用 Solr 的 schema.xml 文件声明索引结构。本文附带的
示例应用程序 演示了这些功能和介绍了如何为 Solr 格式化命令。
在文章的第 2 部分,我将会介绍一些特性,它们将 Solr 从一个简单的搜索界面扩展成一个可供企业使用的搜索解决方案。您将学习
Solr 的管理界面和高级配置选项,以及性能相关的特性(如缓存、复制和日志记录)。我还将简要讨论扩展 Solr
以满足企业需求的一些方法。同时,充分利用示例应用程序,帮助自己熟悉 Solr 的基本功能。
第 2 部分: 用于企业的 Solr
管理、配置和性能
在本部分中,Lucene Java? 的提交人 Grant Ingersoll
通过对用于企业的特性(包括管理界面、高级配置选项)以及与性能相关的特性(比如缓存、复制和日志记录)的探究,完成了对
Solr 的介绍。
配置和管理
本部分介绍了可用于监视和控制 Solr 功能性的诸多选项,首先来看看 Solr
的 Administration Start Page,该页可在 http://localhost:8080/solr/admin/
找到。一旦找到了起始页,在继续之前,请务必花些时间熟悉一下上面的各种菜单选项。在起始页中,根据这些选项所提供的信息的不同对它们进行了分组:
Solr 给出了有关这种活动模式(请参见 第 1 部分)、配置以及当前部署的统计数据的详细信息。
App server 给出了容器的当前状态,包括 threading 信息以及所有
Java 系统属性的列表。
Make a Query 提供了调试查询所需的快捷界面以及到功能更加全面的查询界面的链接。
Assistance 提供了到外部资源的有用链接以便理解和解决使用 Solv
可能遇到的一些问题。
如下的章节详细介绍了这些菜单选项并重点突出了其中的管理特性。
要使用 Solr 的配置选项,可以单击初始页上的 CONFIG 链接,这会显示当前的
solrconfig.xml 文件。您可以在 示例应用程序 的 dw-solr/solr/conf 目录找到该文件。现在,让我们先来看看与索引和查询处理有关的一些常见的配置选项,而与
缓存、复制 和 扩展 Solr 有关的配置选项则留到后面的章节再介绍。
索引配置
mainIndex 标记段定义了控制 Solr 索引处理的低水平的 Lucene
因素。Lucene 基准发布(位于 Lucene 源代码的 contrib/benchmark 之下)包含了很多可用来对这些因素的更改效果进行基准测试的工具。此外,请参阅
参考资料 一节中的 “Solr 性能因素” 来了解与各种更改相关的性能权衡。表 1 概括了可控制 Solr
索引处理的各种因素:
表 1. 对性能因素进行索引
查询处理配置
在 <query> 部分,有一些与 缓存 无关的特性,这一点您需要知道。首先,<maxBooleanClauses>
标记定义了可组合在一起形成一个查询的子句数量的上限。对于大多数应用程序而言,默认的 1024 就应该已经足够;然而,如果应用程序大量使用了通配符或范围查询,增加这个限值将能避免当值超出时,抛出
TooManyClausesException。
通配符和范围查询
通配符和范围查询是可自动扩展以包括所有可能匹配查询条件的条目的 Lucene
查询。通配符查询允许使用 * 和 ? 通配符运算符,而范围查询则要求匹配文档必须要在指定的范围之内。例如,若查找
b*,可能导致潜在的数千个不同项都组合进这个查询,进而会导致 TooManyClausesException。
接下来,若应用程序预期只会检索 Document 上少数几个 Field,那么可以将
<enableLazyFieldLoading> 属性设置为 true。懒散加载的一个常见场景大都发生在应用程序返回和显示一系列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的显示常常只需要显示很短的一段信息。若考虑到检索大型
Document 的代价,除非必需,否则就应该避免加载整个文档。
最后,<query> 部分负责定义与在 Solr 中发生的事件相关的几个选项。首先,作为一种介绍的方式,Solr(实际上是
Lucene)使用称为 Searcher 的 Java 类来处理 Query 实例。Searcher 将索引内容相关的数据加载到内存中。根据索引、CPU
以及可用内存的大小,这个过程可能需要较长的一段时间。要改进这一设计和显著提高性能,Solr 引入了一种
“温暖” 策略,即把这些新的 Searcher 联机以便为现场用户提供查询服务之前,先对它们进行 “热身”。<query>
部分中的 <listener> 选项定义 newSearcher 和 firstSearcher
事件,您可以使用这些事件来指定实例化新搜索程序或第一个搜索程序时应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新搜索程序或第一个搜索程序时就应该反注释这些部分并执行适当的查询。
solrconfig.xml 文件的剩余部分,除 <admin>
之外,涵盖了与 缓存、复制 和 扩展或定制 Solr 有关的项目。admin 部分让您可以定制管理界面。有关配置
admin 节的更多信息,请参看 Solr Wiki 和 solrconfig.xml 文件中的注释。
监视、记录和统计数据
在 http://localhost:8080/solr/admin 的管理页,有几个菜单条目可以让
Solr 管理员监视 Solr 过程。表 2 给出了这些条目:
表 2. 用于监视、记录和统计数据的 Solr 管理选项
调试此分析过程
经常地,当创建搜索实现时,您都会输入一个应该匹配特定文档的搜索,但它不会出现在结果中。在大多数情况下,故障都是由如下两个因素之一引起的:
查询分析和文档分析不匹配(虽然不推荐,但对文档的分析可能会与对查询的分析不同)。
Analyzer 正在修改不同于预期的一个或多个条目。
可以使用位于 http://localhost:8080/solr/admin/analysis.jsp
的 Solr 分析管理功能来深入调查这两个问题。Analysis 页可接受用于查询和文档的文本片段以及能确定文本该如何分析并返回正被修改的文本的逐步结果的
Field 名称。图 1 显示了分析句子 “The Carolina Hurricanes are the
reigning Stanley Cup champions, at least for a few more
weeks” 以及相关的查询 “Stanley Cup champions” 的部分结果,正如为示例应用程序
schema.xml 中指定的 content Field 分析的那样:
图 1. 对分析进行调试
调试 Solr 的分析过程
分析屏幕显示了每个条件在被上述表结果 Tokenizer 或 TokenFilter
处理后的结果。比如,StopFilterFactory 会删除字 The、are 和 the。EnglishPorterFilterFactory
会将字 champions 提取为 champion,将 Hurricanes 提取为 hurrican。紫色的醒目显示表明在特定文档中查询条件在何处有匹配。
回页首
查询测试
admin 页的 Make a Query 部分提供了可输入查询并查看结果的搜索框。这个输入框接受
第 1 部分 中讨论到的 Lucene 查询解析器语法,而 Full Interface 链接则提供了对更多搜索特性的控制,比如返回的结果的数量、在结果集中应该包括哪些字段以及如何格式化输出。此外,该界面还可用来解释文档的计分以更好地理解哪些条件得到了匹配以及这些条件是如何得分的。要实现这一目的,可以查看
Debug: enable 选项并滚动到搜索结果的底端来查看相关解释。
回页首
智能缓存
智能缓存是让 Solr 得以成为引人瞩目的搜索服务器的一个关键性能特征。例如,Solr
在提供缓存服务之前可通过使用旧缓存中的信息来自热缓存,以便在服务于现有用户的同时改进性能。Solr 提供了四种不同的缓存类型,所有四种类型都可在
solrconfig.xml 的 <query> 部分中配置。表 3 根据在 solrconfig.xml
文件中所用的标记名列出了这些缓存类型:
表 3. Solr 缓存类型
每个缓存声明都接受最多四个属性:
class 是缓存实现的 Java 名。
size 是最大的条目数。
initialSize 是缓存的初始大小。
autoWarmCount 是取自旧缓存以预热新缓存的条目数。如果条目很多,就意味着缓存的
hit 会更多,只不过需要花更长的预热时间。
而对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、CPU 和磁盘访问之间进行均衡。统计信息管理页
对于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在缓存中这一额外步骤而受到影响。
发布和复制
对于收到大量查询的应用程序,单一一个 Solr 服务器恐怕不足以满足性能上的需求。因而,Solr
提供了跨多个服务器复制 Lucene 索引的机制,这些服务器必须是负载均衡的查询服务器的一部分。复制过程由
solrconfig.xml 文件启动的事件侦听程序和几个 shell 脚本(位于示例应用程序的 dw-solr/solr/bin)处理。
在复制架构中,一个 Solr 服务器充当主服务器,负责向一个或多个处理查询请求的从服务器提供索引的副本(称为
snapshot)。索引命令发送到主服务器,查询则发送到从服务器。主服务器可以手动创建快照,也可以通过配置
olrconfig.xml 的 <updateHandler> 部分(请参见清单 1)来触发接收到
commit 和/或 optimize 事件时的快照创建。无论是手动创建还是事件驱动的创建,都会在主服务器上调用
snapshooter 脚本,这会在名为 snapshot.yyyymmddHHMMSS(其中的 yyyymmddHHMMSS
代表实际创建快照的时间)的服务器上创建一个目录。之后,从服务器使用 rsync 来只复制 Lucene
索引中的那些已被更改的文件。
清单 1. 更新句柄侦听程序
<listener event="postCommit" class="solr.RunExecutableListener">
<str name="exe">snapshooter</str>
<str name="dir">solr/bin</str>
<bool name="wait">true</bool>
<arr name="args"> <str>arg1</str> <str>arg2</str> </arr>
<arr name="env"> <str>MYVAR=val1</str> </arr>
</listener>
|
清单 1 显示了在收到 commit 事件后,在主服务器上创建快照所需的配置。同样的配置也同样适用处理
optimize 事件。在这个示例配置中,在 commit 完成后,Solr 调用位于 solr/bin
目录的 snapshooter 脚本,传入指定的参数和环境变量。wait 实参告知 Solr 在继续之前先等待线程返回。有关执行
snapshooter 和其他配置脚本的详细信息,请参见 Solr 网站上的 “Solr Collection
and Distribution Scripts” 文档(请参见 参考资料)。
在从服务器上,使用 snappuller shell 脚本从主服务器上检索快照。snappuller
从主服务器上检索了所需文件后,snapinstaller shell 脚本就可用来安装此快照并告知 Solr
有一个新的快照可用。根据快照创建的频率,最好是安排系统定期执行这些步骤。在主服务器上,rsync 守护程序在从服务器获得快照之前必须先行启动。rsyn
守护程序可用 rsyncd-enable shell 脚本启用,然后再用 rsyncd-start 命令实际启动。在从服务器上,snappuller-enable
shell 脚本必须在调用 snappuller shell 脚本之前运行。
排除发布故障
虽然,我们已经竭尽全力地对索引更新的发布进行了优化,但还是有几个常见的场景会为
Solr 带来问题:
优化大型索引可能会非常耗时,而且应该在索引更新不是很频繁的情况下才进行。
优化会导致多个 Lucene 索引文件合并成一个单一文件。这就意味者从服务器必须要复制整个索引。然而,这种方式的优化还是比在每个从服务器上进行优化要好很多。这些服务器可能与主服务器不同步,导致新副本再次被检索。
如果从主服务器中获取新快照的频率过高,则从服务器的性能可能会降低,这种降低源于使用
snappuller 复制更改的开销以及在安装新索引时的缓存预热。有关频繁的索引更新方面的性能均衡的详细信息,请参见
参考资料 中的 “Solr Performance Factors”。
最终,向从服务器添加、提交和获取更改的频繁程度完全取决于您自己的业务需求和硬件能力。仔细测试不同的场景将会帮助您定义何时需要创建快照以及何时需要从主服务器中获取这些快照。有关设置和执行
Solr 发布和复制的更多信息,请参看 参考资料 中的 “Solr Collection and Distribution”
文档。
定制 Solr
Solr 提供了几个插件点,您可以在这里添加定制功能来扩展或修改 Solr
处理。此外,由于 Solr 是开源的,所以如果需要不同的功能,您尽可以更改源代码。有两种方式可以向 Solr
添加插件:
打开 Solr WAR,在 WEB-INF/lib 目录下添加新的库,重新打包这些文件,然后将
WAR 文件部署到 servlet 容器。
将 JAR 放入 Solr Home lib 目录,然后启动 servlet
容器。这种方法使用了定制 ClassLoader 且有可能不适用于某些 servlet 容器。
接下来的几个章节突出介绍了可能希望扩展 Solr 的几个领域。
请求处理
若现有的功能不能满足业务需求,Solr 允许应用程序实现其自身的请求处理功能。比如,您可能想要支持您自己的查询语言或想要将
Solr 与您的用户配置文件相集成来提供个性化的效果。SolrRequestHandler 接口定义了实现定制请求处理所需的方法。实际上,除了
第 1 部分 所使用的那些默认的 “标准” 请求处理程序之外,Solr 还定义了其他几个请求处理程序:
默认的 StandardRequestHandler 使用 Lucene
Query Parser 语法处理查询,添加了排序和层面浏览。
DisMaxRequestHandler 被设计用来通过更为简单的语法来跨多个
Field 进行搜索。它也支持排序(使用与标准处理程序稍有不同的语法)和层面浏览。
IndexInfoRequestHandler 可以检索有关索引的信息,比如索引中的文档数或
Field 数。
请求处理程序是由请求中的 qt 参数指定的。Solr servlet 使用参数值来查找给定的请求处理程序并将输入用于请求处理程序的处理。请求处理程序的声明和命名通过
solrconfig.xml 中的 <requestHandler> 标记指定。要添加其他的内容,只需实现定制的
SolrRequestHandler 线程安全的实例即可,将其添加到 上述 定义好的 Solr,并将其包括到
如前所述 的类路径中,之后就可以通过 HTTP GET 或 POST 方法开始向其发送请求了。
响应处理
与请求处理类似,也可以定制响应输出。必须要支持老式的搜索输出或必须要使用二进制或加密输出格式的应用程序可以通过实现
QueryResponseWriter 来输出所需的格式。 然而,在添加您自己的 QueryResponseWriter
之前,需要先深入研究一下 Solr 所自带的实现,如表 4 所示:
表 4. Solr 的查询响应书写器
QueryResponseWriter 通过 <queryResponseWriter>
标记及其附属属性被添加至 Solr 的 solrconfig.xml 文件。响应的类型通过 wt 参数在请求中指定。默认值是
“标准”,即在 solrconfig.xml 中设定为 XMLResponseWriter。最后要强调的是,QueryResponseWriter
的实例必须提供用来创建响应的 write() 和 getContentType() 方法的线程安全的实现。
Analyzer、Tokenizer、TokenFilter 和 FieldType
借助新的 Analyzer、Tokenizer、TokenFilter
可以定制 Solr 的索引输出以提供新的分析功能。自身需要 Tokenizer 或 TokenFilter
的应用程序必须实现其自身的 TokenizerFactory 和 TokenFilterFactory,这两者使用
<tokenizer> 或 <filter> 标记(作为 <analyzer>
标记的一部分)在 schema.xml 中声明。如果您从之前的应用程序中已经获得了一个 Analyzer,那么就可以在
<analyzer> 标记的 class 属性中声明它并进行使用。您无需创建新的 Analyzer,除非是想要在其他
Lucene 应用程序中使用这些分析器 ―― 在 schema.xml 中使用 <analyzer>
标记声明 Analyzer 真是容易呀!
如果应用程序有特定的数据需求,您可能需要添加一个 FieldType 来处理数据。比如,可以添加一个
FieldType 来处理来自旧的应用程序的二进制字段,在 Solr 中应该可以搜索到这个应用程序。只需使用
<fieldtype> 声明将 FieldType 添加到 schema.xml 并确保它在类路径中可用。
性能考虑
虽然 Solr 可以开箱即用,但还是有几个技巧可有助于让它更易于使用。与任何应用程序一样,仔细考虑您对数据访问的具体业务需求任重而道远。比如,添加的已索引
Field 越多,对内存的需求就越多、索引就越大、优化该索引所需的时间也越长。同样的,检索已存储的 Field
会因为太多的 I/O 处理而减慢服务器的速度。使用懒散字段加载或在他处存储大型内容可以为搜索请求释放 CPU
资源。
在搜索层面上,您应该考虑所支持的查询类型。很多应用程序都不需要 Lucene
Query Parser 语法的全部,尤其是使用通配符和其他高级查询类型的情况下就更是如此。若能分析日志和确保常用的查询被缓存,将会非常有帮助。为一般的查询使用
Filter 对于减少服务器的负载也非常有用。与任何应用程序一样,全面地测试应用程序可确保 Solr 能够满足您的性能需求。有关
Lucene(和 Solr)性能的更多信息,请参阅 参考资料 中给出的 ApacheCon Europe
的 “Advanced Lucene” 幻灯片演示。
Solr 前景光明
构建于 Lucene 的速度和强大功能之上,Solr 本身就证明了它完全可以成为企业级的搜索解决方案。它吸引了大量活跃的社区使用者,这些使用者已经将它用到了各种大型的企业环境。Solr
也获得了开发人员的衷心支持,他们还一直在寻找提高它的途径。
在这个包含两部分的文章,您了解了 Solr,包括它开箱即用的索引和搜索功能以及用来配置其功能的
XML 模式。另外,您还浏览了让 Solr 得以成为企业架构的理想选择的配置和管理特性。最后,您还获悉了采用
Solr 时的性能考虑以及可用来扩展它的架构。
|






