| 全文检索引擎Solr系列――整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如:
张三说的确实在理
智能分词的结果是:
张三 | 说的 | 确实 | 在理
最细粒度分词结果:
张三 | 三 | 说的 | 的确 | 的 | 确实 | 实在 | 在理
整合IK Analyzer比mmseg4j要简单很多,下载解压缩IKAnalyzer2012FF_u1.jar放到目录:E:\solr-4.8.0\example\solr-webapp\webapp\WEB-INF\lib,修改配置文件schema.xml,添加代码:
<field name="content" type="text_ik" indexed="true" stored="true"/>
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> |
查询采用IK自己的最大分词法,索引则采用它的细粒度分词法
此时就算配置完成了,重启服务:java -jar start.jar,来看看IKAnalyzer的分词效果怎么样,打开Solr管理界面,点击左侧的Analysis页面
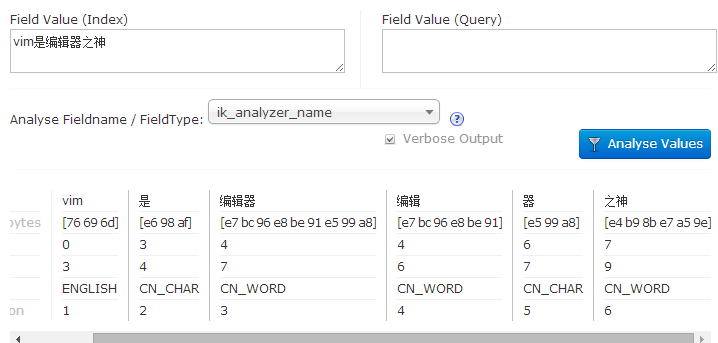
默认分词器进行最细粒度切分。IKAnalyzer支持通过配置IKAnalyzer.cfg.xml
文件来扩充您的与有词典以及停止词典(过滤词典),只需把IKAnalyzer.cfg.xml文件放入class目录下面,指定自己的词典mydic.dics
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">/mydict.dic;
/com/mycompany/dic/mydict2.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">/ext_stopword.dic</entry>
</properties> |
事实上前面的FieldType配置其实存在问题,根据目前最新的IK版本IK Analyzer 2012FF_hf1.zip,索引时使用最细粒度分词,查询时最大分词(智能分词)实际上是不生效的。
据作者linliangyi说,在2012FF_hf1这个版本中已经修复,经测试还是没用,详情请看此贴。
解决办法:重新实现IKAnalyzerSolrFactory
package org.wltea.analyzer.lucene;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
//lucene:4.8之前的版本
//import org.apache.lucene.util.AttributeSource.AttributeFactory;
//lucene:4.9
import org.apache.lucene.util.AttributeFactory;
public class IKAnalyzerSolrFactory extends TokenizerFactory{
private boolean useSmart;
public boolean useSmart() {
return useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
public IKAnalyzerSolrFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
} |
重新编译后更新jar文件,更新schema.xml文件:
<fieldType name="text_ik" class="solr.TextField" >
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analy |
全文检索引擎Solr系列――整合MySQL、MongoDB
MySQL
拷贝mysql-connector-java-5.1.25-bin.jar到E:\solr-4.8.0\example\solr-webapp\webapp\WEB-INF\lib目录下面
配置E:\solr-4.8.0\example\solr\collection1\conf\solrconfig.xml
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler> |
导入依赖库文件:
<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar"/> |
加在
<lib dir="../../../dist/" regex="solr-cell-\d.*\.jar" /> |
前面。
创建E:\solr-4.8.0\example\solr\collection1\conf\data-config.xml,指定MySQL数据库地址,用户名、密码以及建立索引的数据表
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/django_blog"
user="root"
password=""/>
<document name="blog">
<entity name="blog_blog" pk="id"
query="select id,title,content from blog_blog"
deltaImportQuery="select id,title,content from blog_blog where ID='${dataimporter.delta.id}'"
deltaQuery="select id from blog_blog where add_time > '${dataimporter.last_index_time}'"
deletedPkQuery="select id from blog_blog where id=0">
<field column="id" name="id" />
<field column="title" name="title" />
<field column="content" name="content"/>
</entity>
</document>
</dataConfig> |
query 用于初次导入到索引的sql语句。
考虑到数据表中的数据量非常大,比如千万级,不可能一次索引完,因此需要分批次完成,那么查询语句query要设置两个参数:${dataimporter.request.length}
${dataimporter.request.offset}
query=”select id,title,content from blog_blog limit ${dataimporter.request.length} offset
${dataimporter.request.offset}” |
请求:http://localhost:8983/solr/collection2/dataimport?command=full-import&commit=true&clean=false&offset=0&length=10000
deltaImportQuery 根据ID取得需要进入的索引的单条数据。
deltaQuery 用于增量索引的sql语句,用于取得需要增量索引的ID。
deletedPkQuery 用于取出需要从索引中删除文档的的ID
为数据库表字段建立域(field),编辑E:\solr-4.8.0\example\solr\collection1\conf\schema.xml:
<!-- mysql -->
<field name="id" type="string" indexed="true" stored="true" required="true" />
<field name="title" type="text_cn" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true"/>
<field name="content" type="text_cn" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true"/>
<!-- mysql --> |
Mongodb
安装mongo-connector,最好使用手动安装方式:
<code>git clone https://github.com/10gen-labs/mongo-connector.git
cd mongo-connector #安装前修改mongo_connector/constants.py的变量:设置DEFAULT_COMMIT_INTERVAL
= 0 python setup.py install </code>
默认是不会自动提交了,这里设置成自动提交,否则mongodb数据库更新,索引这边没法同时更新,或者在命令行中可以指定是否自动提交,不过我现在还没发现。
配置schema.xml,把mongodb中需要加上索引的字段配置到schema.xml文件中:
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="body" type="string" indexed="true" stored="true"/>
<field name="title" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<uniqueKey>_id</uniqueKey>
<defaultSearchField>title</defaultSearchField>
<solrQueryParser defaultOperator="OR"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema> |
启动Mongod:
<code>mongod --replSet myDevReplSet --smallfiles </code> |
初始化:rs.initiate()
启动mongo-connector:
<code>E:\Users\liuzhijun\workspace\mongo-connector\mongo_connector
\doc_managers>mongo-connector -m localhost:27017 -t
http://localhost:8983/solr/collection2 -n s_soccer.person -u id -d ./solr_doc_manager.py </code> |
-m:mongod服务
-t:solr服务
-n:mongodb命名空间,监听database.collection,多个命名空间逗号分隔
-u:uniquekey
-d:处理文档的manager文件
注意:mongodb通常使用_id作为uniquekey,而Solrmore使用id作为uniquekey,如果不做处理,索引文件时将会失败,有两种方式来处理这个问题:
指定参数--unique-key=id到mongo-connector,Mongo
Connector 就可以翻译把_id转换到id。
把schema.xml文件中的:
<code><uniqueKey>id<uniqueKey> </code> |
替换成
<code><uniqueKey>_id</uniqueKey> </code> |
同时还要定义一个_id的字段:
<code><field name="_id" type="string" indexed="true" stored="true" /> </code> |
启动时如果报错:
<code>2014-06-18 12:30:36,648 - ERROR - OplogThread: Last entry no longer in
oplog cannot recover! Collection(Database(MongoClient('localhost', 27017), u'local'), u'oplog.rs') </code> |
清空E:\Users\liuzhijun\workspace\mongo-connector\mongo_connector\doc_managers\config.txt中的内容,需要删除索引目录下的文件重新启动
测试
mongodb中的数据变化都会同步到solr中去。
|






