| ȫ�ļ�������Solrϵ�С�������ƪ
Solr����Lucene������Ϊ���ģ��ṩȫ��������������Դ��ҵƽ̨���ṩREST��HTTP/XML��JSON��API���������Solr���֣���ô�ͺ���һ�������Űɣ����̳���solr4.8��Ϊ���Ի�����jdk�汾��Ҫ1.7�����ϰ汾��
��
���ļ������Java�г��м�����ˮƽ����˲��ٽ���Java��ػ��������á����ؽ�ѹ��solr����exampleĿ¼��start.jar�ļ���������
��������
����������Ŀǰ�㿴���Ľ���û���κ����ݣ������ͨ��POSTing������Solr�����ӣ����£��ĵ���ɾ���ĵ�����exampledocsĿ¼����һЩʾ���ļ����������
java -jar post.jar solr.xml monitor.xml |
�������������solr�����������ĵ������������ļ�����������ʲô���ݣ�solr.xml����������ǣ�
<add>
<doc>
<field name="id">SOLR1000</field>
<field name="name">Solr, the Enterprise Search Server</field>
<field name="manu">Apache Software Foundation</field>
<field name="cat">software</field>
<field name="cat">search</field>
<field name="features">Advanced Full-Text Search Capabilities using Lucene</field>
<field name="features">Optimized for High Volume Web Traffic</field>
<field name="features">Standards Based Open Interfaces - XML and HTTP</field>
<field name="features">Comprehensive HTML Administration Interfaces</field>
<field name="features">Scalability - Efficient Replication to other Solr Search Servers</field>
<field name="features">Flexible and Adaptable with XML configuration and Schema</field>
<field name="features">Good unicode support: héllo (hello with an accent over the e)</field>
<field name="price">0</field>
<field name="popularity">10</field>
<field name="inStock">true</field>
<field name="incubationdate_dt">2006-01-17T00:00:00.000Z</field>
</doc>
</add> |
��ʾ������������һ���ĵ����ĵ�������������������Դ�����ھͿ���ͨ���������������ؼ��֡�solr�������岽���ǣ�
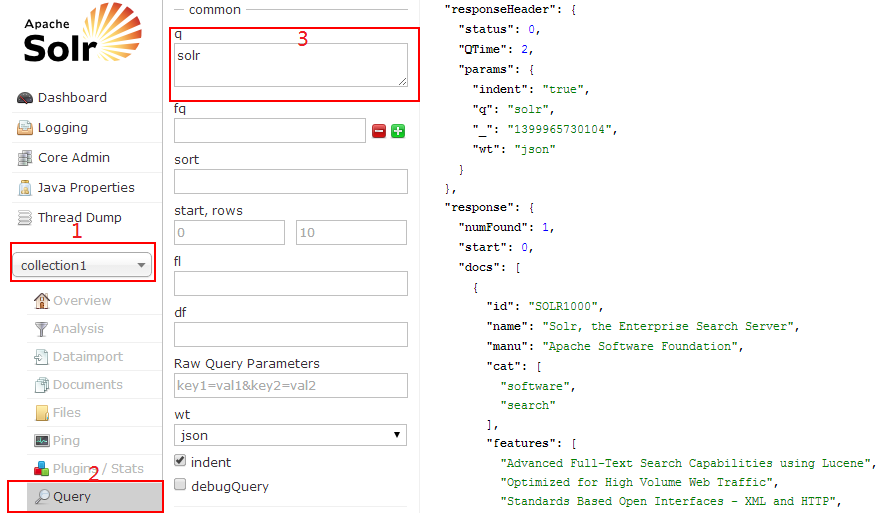
���ҳ���µ�Execute Query��ť���Ҳ�ͻ���ʾ��ѯ��������������Ǹղŵ����ȥ��solr.xml��json��ʽ��չʾ�����solr֧�ַḻ�IJ�ѯ������磺�����������ֶ�name����Ĺؼ��֡�Search���Ϳ������name:search����Ȼ���������name:xxx��û�з��ؽ���ˣ���Ϊ�ĵ���û�����������ݡ�
���ݵ���
�������ݵ�Solr�ķ�ʽҲ�Ƕ��ֶ����ģ�
����ʹ��DIH(DataImportHandler)�����ݿ������
֧��CSV�ļ����룬���Excel����Ҳ�����ɵ���
֧��JSON��ʽ�ĵ�
�������ĵ����磺Word��PDF
�����Ա�̵ķ�ʽ���Զ��嵼��
��������
���ͬһ���ĵ�solr.xml�ظ���������ʲô����أ�ʵ����solr������ĵ����ֶ�id��Ψһ��ʶ�ĵ������������ĵ���id�Ѿ�����solr�У���ô����ĵ��ͱ����µ����ͬid���ĵ��Զ��滻��������Լ���������һ�£��۲��滻ǰ���������ļ���������Num
Docs��Max Doc��Deleted Docs�ı仯��
numDocs����ǰϵͳ�е��ĵ����������п��ܴ���xml�ļ���������Ϊһ��xml�ļ������ж��<doc>��ǩ��
maxDoc��maxDoc�п��ܱ�numDocs��ֵҪ�����ظ�postͬһ���ļ���maxDocֵ�������ˡ�
deletedDocs���ظ�post���ļ����滻���ϵ��ĵ���ͬʱdeltedDocs��ֵҲ���1��������ֻ�����ϵ�ɾ������û���������������Ƴ���
ɾ������
ͨ��idɾ��ָ�����ĵ�������ͨ��һ����ѯ��ɾ��ƥ����ĵ�
java -Ddata=args -jar post.jar "<delete><id>SOLR1000</id></delete>"
java -Ddata=args -jar post.jar "<delete><query>name:DDR</query></delete>" |
��ʱsolr.xml�ĵ���������ɾ���ˣ��ٴ��ѡ�solr��ʱ���ٷ��ؽ������ȻsolrҲ�����ݿ��е�����ִ��ɾ�������ʱ�������Զ��ύ�ˣ��ĵ��ͻ�������������ɾ������Ҳ����commit����Ϊfalse���ֶ��ύ����
java -Ddata=args -Dcommit=false -jar post.jar "<delete><id>3007WFP</id></delete>" |
ִ�������������ʱ�ĵ���û������ɾ�������ǿ��Լ���������ؽ����������ͨ�����
�ύ�����ĵ��ͳ���ɾ���ˡ����ڰѸո�ɾ�����ļ����µ���Solr�������������ǵ�ѧϰ��
ɾ���������ݣ�
http://localhost:8983/solr/collection1/update?stream.body=<delete><query>*:*</query></delete>&commit=true |
ɾ��ָ������
http://localhost:8983/solr/collection1/update?stream.body=<delete><query>title:abc</query></delete>&commit=true |
������ɾ��
http://localhost:8983/solr/collection1/update?stream.body=<delete>
<query>title:abc AND name:zhang</query></delete>&commit=true |
��ѯ����
��ѯ���ݶ���ͨ��HTTP��GET�����ȡ�ģ������ؼ����ò���qָ�����������ָ���ܶ��ѡ�IJ�����������Ϣ�ķ��أ����磺��flָ�����ص��ֶΣ�����f1=name����ô���ص����ݾ�ֻ����name�ֶε�����
http://localhost:8983/solr/collection1/select?q=solr&fl=name&wt=json&indent=true |
����
Solr�ṩ����Ĺ��ܣ�ͨ������sort��ָ������֧���������߶���ֶ�����
q=video&sort=price desc
q=video&sort=price asc
q=video&sort=inStock asc, price desc |
Ĭ�������£�Solr����socre �������У�socre��һ��������¼������ضȼ��������һ��������
����
��ҳ�����У�Ϊ��ͻ��������������ܻ��ƥ��Ĺؼ��ָ���������Solr�ṩ�˺ܺõ�֧�֣�ֻҪָ��������
hl=true #������������
hl.fl=name #ָ����Ҫ�������ֶ�
http://localhost:8983/solr/collection1/select?q=Search&wt=json&indent=true&hl=true&hl.fl=features |
���ص������а�����
"highlighting":{
"SOLR1000":{
"features":["Advanced Full-Text <em>Search</em> Capabilities using Lucene"]
}
} |
�ı�����
�ı��ֶ�ͨ�����ı��ָ�ɵ����Լ����ø���ת���������磺Сдת���������Ƴ����ʸ���ȡ����������schema.xml�ļ��ж������ֶ��������У���Щ�ֶν�����������.
Ĭ�������������power-shot���Dz���ƥ�䡱powershot���ģ�ͨ����schema.xml�ļ�(solr/example/solr/collection1/confĿ¼)����features��text�ֶ��滻�ɡ�text_en_splitting�����ͣ������������ˡ�
<field name="features" type="text_en_splitting" indexed="true" stored="true" multiValued="true"/>
...
<field name="text" type="text_en_splitting" indexed="true" stored="false" multiValued="true"/> |
���������solr��Ȼ�����µ����ĵ�
���ھͿ���ƥ����
power-shot��>Powershot
features:recharing��>Rechargeable
1 gigabyte �C> 1G |
�ܽ�
��Ϊ�������£�����û������̫������װ�������ĵ����£���solr���˳������Ե���ʶ����һƪ������ȫ�ļ����Ļ���ԭ����
ȫ�ļ�������Solrϵ�С��Cȫ�ļ�������ԭ��
������Сʱ�����Ƕ�ʹ�ù��»��ֵ䣬������㷭����38ҳ���ҵ����ӵ������ڵ�λ�ã���ʱ�����ô���أ��������ʣ�����۾����38ҳ�ĵ�һ���ֿ�ʼ��ͷ��β��ɨ�裬ֱ���ҵ����ӵ�������Ϊֹ������������������˳��ɨ�跨���������������ݣ�ʹ��˳��ɨ���ǹ��õġ���������������ӵ��ġ��ӡ�������һҳʱ����Ҫ�Ǵӵ�һҳ�ĵ�һ���������ɨ����ȥ����������DZ����ˡ���ʱ�����Ҫ�õ�������������¼�ˡ��ӡ�������һҳ����ֻ�����������ҵ����ӡ��֣�Ȼ���ҵ���Ӧ��ҳ�룬�𰸾ͳ����ˡ���Ϊ�������в��ҡ��ӡ����Ƿdz���ģ���Ϊ��֪������ƫ�ԣ����Ҳ�Ϳ�Ѹ�ٶ�λ������֡�
��ô�»��ֵ��Ŀ¼��������������ô��д���ɵ��أ����ȶ����»��ֵ��Ȿ����˵����ȥĿ¼���Ȿ�����һ��û�нṹ�����ݼ������Ǵ�������������˼���ܽᣬ����ÿ���ֶ����Ӧ��һ��ҳ�룬���硰�ӡ��־��ڵ�38ҳ�����������ڵ�90ҳ���������Ǿʹ�����ȡ��Щ��Ϣ�������һ���нṹ�����ݡ��������ݿ��еı��ṹ��
word page_no
---------------
�� 38
�� 90
... ... |
�������γ���һ��������Ŀ¼�������⣩�����ҵ�ʱ��ͷdz������ˡ�����ȫ�ļ���Ҳ�����Ƶ�ԭ���������Թ��Ϊ�������̣�1.����������Indexing��2.
����������Search������ô������������δ������أ����������ŵ�����ʲô�����أ������ĵ�ʱ���������ȥ�����������أ�������һϵ������������¿���
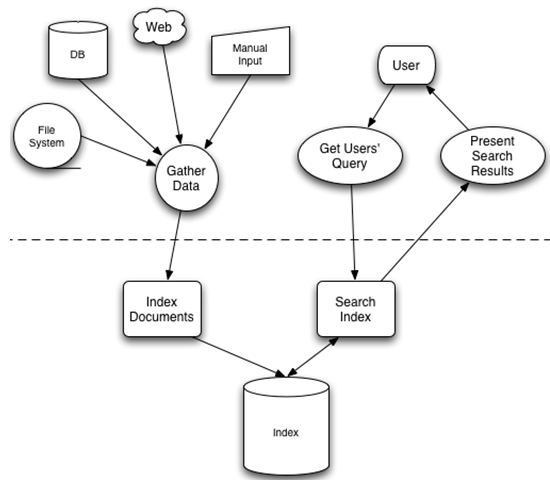
����
Solr/Lucene���õ���һ�ַ�����������ν�������������Ǵӹؼ��ֵ��ĵ���ӳ����̣���������ӳ��������Ϣ��������Ϊ��������
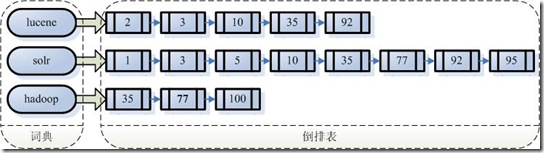
��߱�������ַ�������
�ұ����ַ������ĵ���Document�������������Ϊ���ű���Posting
List��
�ֶδ��б����ĵ�����������߹�����һ���ֵ䡣������������lucene������ô����ֱ�Ӹ������ǣ������С�lucene�����ĵ��У�2��3��10��35��92���������������ĵ�����������ҡ���������ѼȰ�����lucene���ְ�����solr�����ĵ�����ô��֮��Ӧ���������ű�ȥ�������ɻ�ã�3��10��35��92��
��������
��������������ԭʼ�ĵ���
�ĵ�һ��Students should be allowed to go
out with their friends, but not allowed to drink beer.
�ĵ�����My friend Jerry went to school to
see his students but found them drunk which is not allowed.
�������̴�ŷ�Ϊ���²��裺
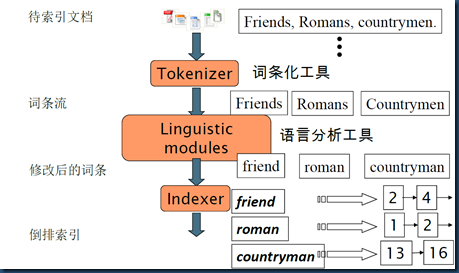
һ����ԭʼ�ĵ������ִ����(Tokenizer)
�ִ����(Tokenizer)�������¼�������(������̳�Ϊ��Tokenize)�������õ��Ľ���Ǵʻ㵥Ԫ��Token��
���ĵ��ֳ�һ��һ�������ĵ���
ȥ��������
ȥ��ͣ��(stop word)
��νͣ��(Stop word)����һ��������û�о��庬�壬������������²�����Ϊ�����Ĺؼ��ʣ�
����һ����������ʱ�ܼ��������Ĵ�С��Ӣ����ͣ��(Stop word)�磺
��the������a������this���������У����ģ��á��ȡ�
��ͬ���ֵķִ����(Tokenizer)�������Լ���ͣ��(stop word)���ϡ�
�����ִ�(Tokenizer)��õ��Ľ����Ϊ�ʻ㵥Ԫ(Token)���������У���õ����´ʻ㵥Ԫ(Token)��
"Students"��"allowed"��"go"��"their"��"friends"��"allowed"��
"drink"��"beer"��"My"��"friend"��"Jerry"��"went"��"school"��
"see"��"his"��"students"��"found"��"them"��"drunk"��"allowed"
�����ʻ㵥Ԫ(Token)�������Դ������(Linguistic Processor)
���Դ������(linguistic processor)��Ҫ�ǶԵõ��Ĵ�Ԫ(Token)��һЩ������صĴ�����
����Ӣ����Դ������(Linguistic Processor)һ�������¼��㣺
��ΪСд(Lowercase)��
����������Ϊ�ʸ���ʽ���硱cars������car���ȡ����ֲ�����Ϊ��stemming��
������ת��Ϊ�ʸ���ʽ���硱drove������drive���ȡ����ֲ�����Ϊ��lemmatization��
���Դ������(linguistic processor)�����õ��Ľ����Ϊ��(Term)�������о������Դ�����õ��Ĵ�(Term)���£�
"student"��"allow"��"go"��"their"��"friend"��"allow"��"drink"��"beer"��"my"��"friend"��
"jerry"��"go"��"school"��"see"��"his"��"student"��"find"��"them"��"drink"��"allow"��
�������Դ���������driveʱdroveҲ�ܱ�����������Stemming
�� lemmatization����ͬ��
��֮ͬ����
Stemming��lemmatization��Ҫʹ�ʻ��Ϊ�ʸ���ʽ��
���ߵķ�ʽ��ͬ��
Stemming���õ��ǡ��������ķ�ʽ����cars������car������driving������drive����
Lemmatization���õ��ǡ�ת�䡱�ķ�ʽ����drove������drove������driving������drive����
���ߵ��㷨��ͬ��
Stemming��Ҫ�Dz�ȡij�̶ֹ����㷨����������������ȥ����s����
ȥ����ing���ӡ�e��������ational����Ϊ��ate��������tional����Ϊ��tion����
Lemmatization��Ҫ�Dz�������Լ���ĸ�ʽ����ij���ֵ��С�
�����ֵ����С�driving������drive������drove������drive������am,
is, are������be����ӳ�䣬��ת��ʱ�������ֵ���Լ���ķ�ʽת���Ϳ����ˡ�
Stemming��lemmatization���ǻ����ϵ�����н����ģ��еĴ����������ַ�ʽ���ܴﵽ��ͬ��ת����
�����õ��Ĵ�(Term)���ݸ��������(Indexer)
���õõ��Ĵ�(Term)����һ���ֵ�
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2
jerry 2
go 2
school 2
see 2
his 2
student 2
find 2
them 2
drink 2
allow 2 |
���ֵ䰴��ĸ˳������
Term Document ID
allow 1
allow 1
allow 2
beer 1
drink 1
drink 2
find 2
friend 1
friend 2
go 1
go 2
his 2
jerry 2
my 2
school 2
see 2
student 1
student 2
their 1
them 2 |
�ϲ���ͬ�Ĵ�(Term)��Ϊ�ĵ�����(Posting List)����postlist
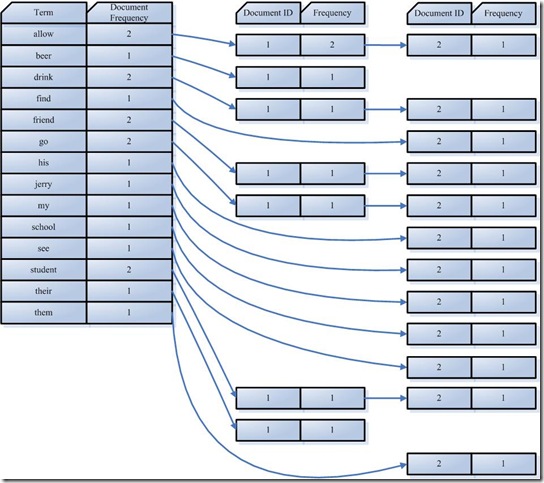
Document Frequency���ĵ�Ƶ�Σ���ʾ�����ĵ����ֹ��˴�(Term)
Frequency����Ƶ����ʾij���ĵ��иô�(Term)���ֹ�����
�Դ�(Term) ��allow���������ܹ�����ƪ�ĵ������˴�(Term)���ʣ�Term)������ĵ������ܹ�����������һ����ʾ������allow���ĵ�һƪ�ĵ�����1���ĵ������ĵ��У���allow��������2�Σ��ڶ�����ʾ������allow���ĵڶ����ĵ�����2���ĵ������ĵ��У���allow��������1��
��������������ɣ�������drive��ʱ����driving������drove������driven��Ҳ�ܹ����ѵ�����Ϊ�������У���driving������drove������driven�����ᾭ�����Դ�������ɡ�drive����������ʱ����������롱driving��������IJ�ѯ���ͬ�������ִ���������Դ�����������IJ��裬��Ϊ��ѯ��drive�����Ӷ�������������Ҫ���ĵ���
��������
������microsoft job�����û���Ŀ����ϣ��������һ�ݹ���������ѳ����Ľ����:��Microsoft
does a good job at software industry������������û�������ƫ��̫Զ�ˡ���ν��к�����Ч���������������û�����Ҫ�ý���أ�������Ҫ�����²��裺
һ���Բ�ѯ���ݽ��дʷ�����������������Դ���
�ʷ����������ֲ�ѯ�����е��ʺؼ��֣����磺english and janpan����and�����ǹؼ��֣���english���͡�janpan������ͨ���ʡ�
���ݲ�ѯ���������γ�һ����
���Դ������ʹ�������ʱ������ʽ��һ���ġ����磺leaned�C>lean��driven�C>drive
���������������õ�����������ĵ�����
�������ݲ�ѯ������ĵ�������ԣ��Խ����������
���ǰѲ�ѯ���Ҳ������һ���ĵ������ĵ����ĵ�֮�������ԣ�relevance�����д�֣�scoring���������߱Ƚ�Խ��أ�������Խ��ǰ����Ȼ�������˹�Ӱ���֣�����ٶ��������Ͳ�һ����ȫ����������������ġ�
��������ĵ�֮�������ԣ�һ���ĵ��ɶ��������һ�����ʣ�Term����ɣ����磺��solr���� ��toturial������ͬ�Ĵʿ�����Ҫ�Բ�һ��������solr�ͱ�toturial��Ҫ�����һ���ĵ�������10��toturial����ֻ������һ��solr������һ�ĵ�solr������4�Σ�toturial����һ�Σ���ô���ߺ��п��ܾ���������Ҫ���ѵĽ������������Ȩ�أ�Term
weight���ĸ��
Ȩ�ر�ʾ�ô����ĵ��е���Ҫ�̶ȣ�Խ��Ҫ�Ĵʵ�ȻȨ��Խ�ߣ�����ڼ����ĵ������ʱӰ��������ͨ����֮���Ȩ�صõ��ĵ�����ԵĹ��̽����ռ�����ģ���㷨(Vector
Space Model)
Ӱ��һ�������ĵ��е���Ҫ����Ҫ���������棺
Term Frequencey��tf����Term�ڴ��ĵ��г��ֵ�Ƶ�ʣ�ftԽ���ʾԽ��Ҫ
Document Frequency��df������ʾ�ж����ĵ��г��ֹ����Trem��dfԽ���ʾԽ����Ҫ
����ϣΪ��Ҷ��еĶ�������Ȼ�Ͳ���ô�����ˣ�ֻ����ר�еĶ�����ʾ������������Ȩ�صĹ�ʽ��

�ռ�����ģ��
�ĵ��дʵ�Ȩ�ؿ���һ������
Document = {term1, term2, ���� ,term N}
Document Vector = {weight1, weight2,
���� ,weight N}
����Ҫ��ѯ����俴��һ�����ĵ���Ҳ��������ʾ��
Query = {term1, term 2, ���� , term N}
Query Vector = {weight1, weight2, ����
, weight N}
�����������ĵ���������ѯ��������Nά�ȵĿռ��У�ÿ���ʱ�ʾһά��
�н�ԽС����ʾԽ���ƣ������Խ��
|






