| Solr
��һ�ֿɹ���ҵʹ�õġ����� Lucene ����������������֧�ֲ���������������Ŀ��ʾ�Ͷ��������ʽ������ƪ�����У�������
Solr ��չʾ������ɵؽ�����������ȫ�ı��������ܼ��뵽 Web Ӧ�ó����С�
����������
System��Windows
WebBrowser��IE6+��Firefox3+
JDK��1.6+
JavaEE Server��tomcat5.0.2.8��tomcat6
IDE��eclipse��MyEclipse 8
���������⣺
JavaEE 5��solr 3.4
һ�����úͰ�װsolr
1�� ����ȥapache�ٷ���վ����solr�����ص�ַ
http://labs.renren.com/apache-mirror//lucene/solr/3.4.0/
Ŀǰ���µ���3.4�İ汾
2�� ���غ��ѹĿ¼����
client��һ��rubyʵ�ֵ�ʾ�������������ʱ����
contrib��һЩ����ģ������Ҫ��jar��
dist�Ǵ�������õĹ���war��
docs�ǰ����ĵ�
example��ʾ���������д������õ�solr����ʾ����servlet����jetty�������û��tomcat����ֱ��ʹ��Jetty�������������solrʾ����
3�� ����������solrʾ��
A�� �����Դ���Jetty������
������dos�����н��뵽���غõ�solr��ѹ��Ŀ¼apache-solr-3.4.0��exampleĿ¼
cd E:\JAR\solr\apache-solr-3.4.0\example
Ȼ������java�������jetty��������Java �Cjar start.jar
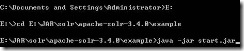
����Jetty�ɹ������û�п���������Ϣ������Կ����˿���Ϣ��

�����Ķ˿ڳ�ͻ�ˣ�����Ե���ѹ��solrʾ������example/etc��jetty.xml�У��Ķ˿�port��Ϣ��
<Set name="port">
<SystemProperty name="jetty.port" default="8983"/>
</Set> |
B�� ����tomcat����solrʾ��
�����ص�solr��ѹ����apache-solr-3.4.0\distĿ¼���������solr.war�ŵ�D:\tomcat-6.0.28\webappsĿ¼�£�����tomcat���Զ���ѹ������Ȼ����Ҳ�����ֶ���ѹ�ŵ�wabappsĿ¼�£�
��Ȼ��Ҳ��������contextָ�����solr���̣���D:\tomcat-6.0.28\conf\Catalina\localhostĿ¼����solr.xml���ã��������£�
<Context docBase="D:\solr.war" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="D:\solr" override="true" />
</Context> |
�����2������һ���ģ�������û���ꡣ����������ܻῴ�����´���

������Ҫ��һЩ���ú�index���ļ�Ҳ�ŵ���ѹ�õ�solr�����¡����ǵ���ѹ��apache-solr-3.4.0\example\solrĿ¼�£��������conf��dataĿ¼copy���ղ����Dz����D:\tomcat-6.0.28\webapps\solr����Ŀ¼�¡�����copy�����solr.xml�е�contextָ����·���¹���Ŀ¼�С�
����tomcat��ok�ˡ�
4�� ���ʱ����Ϳ��Է���http://localhost:8983/solr/admin/��Ϳ��Կ������½��棺
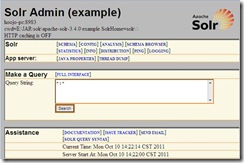
��Query String������solr�����Search�Ϳ��Բ�ѯ����Ӧ�Ľ���������xml��ʽ���ء���Ȼ��Ҳ�������÷�����������Ϊjson��
����Solr����
1�� solr����
��Ϊ Solr ��װ����չ�� Lucene����������ʹ�úܶ���ͬ���������Ҫ���ǣ�Solr ������������
Lucene �����������ȫ���ݡ�ͨ���� Solr �����ʵ������ã�ijЩ����¿�����Ҫ���б��룬Solr
�����Ķ���ʹ�ù��������� Lucene Ӧ�ó����е�������
�� Solr �� Lucene �У�ʹ��һ������ Document ������������Document
����һ������ Field��Field �������ơ������Լ����� Solr ��δ������ݵ�Ԫ���ݡ����磬Field
�������ַ��������֡�����ֵ�������ڣ�Ҳ�������������ӵ��κ����ͣ�ֻ������solr�������ļ��н�����Ӧ�����ü��ɡ�Field
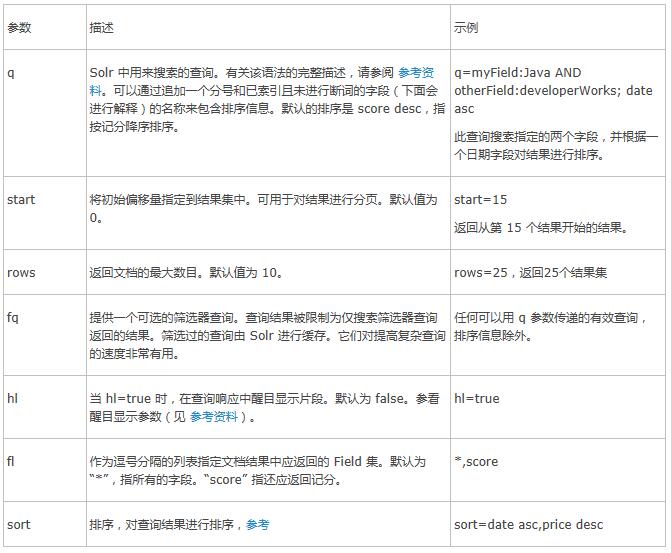
����ʹ�ô�����ѡ������������Щѡ����� Solr �������������ڼ���δ������ݡ����ڣ��鿴һ�±� 1 ���г�����Ҫ���Ե��Ӽ���

2�� solr��������
�� Solr �У�ͨ�������� servlet �����е� Solr Web Ӧ�ó����� HTTP ����������������������Solr
��������ȷ��Ҫʹ�õ��ʵ� SolrRequestHandler��Ȼ��������ͨ�� HTTP ��ͬ���ķ�ʽ������Ӧ��Ĭ�����÷���
Solr �ı� XML ��Ӧ����Ҳ�������� Solr �ı�����Ӧ��ʽ����json��csv��ʽ���ı���
�������ǽ�������Ԫ���ݣ����ݸ�ʽ��schema.xml�н������ã��������Ǵ��ݸ� Solr���Ӷ��� HTTP
Post XML ��Ϣ�н��������Ĺ��̡�������� Solr ���� servlet �����ĸ���ͬ����������
add/update �������� Solr �����ĵ�������ĵ���ֱ���ύ�������������Щ���Ӻ��¡�
commit ���� Solr��Ӧ��ʹ�ϴ��ύ�������������и��Ķ�������������
optimize �ع� Lucene ���ļ��ԸĽ��������ܡ�������ɺ�ִ��һ���Ż�ͨ���ȽϺá�������±Ƚ�Ƶ������Ӧ����ʹ���ʽϵ͵�ʱ�����Ż���һ�����������Ż�Ҳ�������������С��Ż���һ����ʱ�϶�Ĺ��̡�
delete ����ͨ�� id ���ѯ��ָ������ id ɾ����ɾ������ָ�� id ���ĵ�������ѯɾ����ɾ����ѯ���ص������ĵ���
Lucene�в�������Ҳ���⼸�����裬����û�и��¡�Lucene��������ɾ����Ȼ��������������Ϊ����������һ������£�Ч��û����ɾ�������ӵ�Ч�ʺá�
3�� ����
�����ĵ��Ϳ���������Щ�ĵ��ˡ�Solr ���� HTTP GET �� HTTP POST ��ѯ��Ϣ���յ��IJ�ѯ����Ӧ��
SolrRequestHandler �������
solr��ѯ����������
4�� solrģʽ
�������ᵽschema.xml������ã�������ÿ�����������solr���İ�װ��ѹĿ¼��apache-solr-3.4.0\example\solr\conf���ҵ���������solrģʽ�������ļ�������������ļ�����ᷢ������ϸ��ע�͡�
ģʽ��֯��Ҫ��Ϊ������Ҫ����
types ������һЩ�����Ŀ����ö��壬������ Solr���� Lucene����δ��� Field��Ҳ�������ӵ������е�xml�ļ������е����ͣ���int��text��date��
fileds�������ӵ������ļ��г��ֵ��������ƣ����������;���Ҫ�õ������types
����������
uniqueKey Ψһ�����������õ���������ֵ�fileds��һ����id��url�Ȳ��ظ��ġ��ڸ��¡�ɾ����ʱ������õ���
defaultSearchFieldĬ���������ԣ���q=solr����Ĭ�ϵ������Ǹ��ֶ�
solrQueryParser��ѯת��ģʽ���Dz��һ��ǻ��ߣ�and/or��
schema��������
<fieldType name="text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt" />
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1" catenateWords="1"
catenateNumbers="1" catenateAll="0" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt" />
<filter class="solr.RemoveDuplicatesTokenFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="true" />
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt" />
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1" catenateWords="0"
catenateNumbers="0" catenateAll="0" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt" />
<filter class="solr.RemoveDuplicatesTokenFilterFactory" />
</analyzer>
</fieldType>
|
�������һ��type�ˣ�Ȼ������fields����field��ʱ��Ϳ��������type��
���ȣ������fieldType��������������analyzer�����Ƿִ�������Ҫ�����ǵ����ݽ��зָ��һ�����Ĵ���ʸ���ȡ��ֹͣ��ɾ���Լ����ƵIJ�������Ӧ���ڱ�ǣ�Ȼ��Ž�������������������ʹ����ͬ���͵ı�ǡ�
�����Ӧ�ó���� Solr ��fieldType���ð����²���������ã�
���ݿհ��жϴʣ�Ȼ��ɾ�����еĹ����ʣ�StopFilterFactory��
ʹ�����ۺŴ�������Ĵ�Сд����Сдת���ȵȡ���WordDelimiterFilterFactory������������Ŀ����ΪСд��LowerCaseFilterFactory��
ʹ�� Porter Stemming �㷨���дʸ���ȡ��EnglishPorterFilterFactory��
ɾ�����еĸ�����RemoveDuplicatesTokenFilterFactory��
Schema���ԡ��ֶ�
<field name="id" type="string" indexed="true" stored="true"
required="true" />
<field name="sku" type="text_en_splitting_tight" indexed="true"
stored="true" omitNorms="true" />
<field name="name" type="text_general" indexed="true" stored="true" />
<field name="alphaNameSort" type="alphaOnlySort" indexed="true"
stored="false" />
<field name="manu" type="text_general" indexed="true" stored="true"
omitNorms="true" />
<field name="cat" type="string" indexed="true" stored="true"
multiValued="true" />
<field name="features" type="text_general" indexed="true" stored="true"
multiValued="true" />
<field name="includes" type="text_general" indexed="true" stored="true"
termVectors="true" termPositions="true" termOffsets="true" />
|
��������������������ѯ��ʱ���������ã�����㲻����Щ���á�������������Ĵ����ġ�
����id������δ���������ַ������ͣ��ǿ����������洢�ģ�������Ψһ�ġ�
sku��һ�������ִ�������������Ӣ���и�������ַ��������������洢����Ҫ�洢�淶
multiValued ������һ����������ӣ�ָ Document ����ӵ��һ����ͬ���������˶�ε�
Field��
omitNorms ���Ը��� Solr���� Lucene����Ҫ�洢�淶��
����һ���ֶ������·��� <dynamicField> ��������̬�ֶ���һЩ�������͵��ֶΣ��������κ�ʱ����Щ�ֶ����ӵ��κ��ĵ��У����ֶ������������ǵ����ԡ���̬�ֶκ���ͨ�ֶ�֮��Ĺؼ���������ǰ�߲���Ҫ��
schema.xml ����ǰ�������ơ�Solr �����������е� glob-like ģʽӦ�õ�������δ������������ֶ����ƣ���������
<dynamicField> ��������������������ֶΡ����磬<dynamicField
name="*_i" type="sint" indexed="true"
stored="true"/> ָһ�� myRating_i �ֶα� Solr
����Ϊ sint�����ܲ�δ��������Ϊ�ֶΡ����ִ����ȽϷ��㣬���磬����Ҫ�û�������������ݵ�ʱ��
5�� ��������
Solr �������أ����˽�����ָ�����ص�����Ȩ�⡣
�� 1 �����˿ɿ��� Solr ���������ĸ������أ�

6�� ��ѯ��������
<maxBooleanClauses> ��Ƕ����˿������һ���γ�һ����ѯ���Ӿ����������ޡ����ڴ����Ӧ�ó�����ԣ�Ĭ�ϵ�
1024 ��Ӧ���Ѿ��㹻��Ȼ�������Ӧ�ó������ʹ����ͨ�����Χ��ѯ�����������ֵ���ܱ��ֵ����ʱ���׳�
TooManyClausesException��
��Ӧ�ó���Ԥ��ֻ����� Document ���������� Field����ô���Խ� <enableLazyFieldLoading>
��������Ϊ true����ɢ���ص�һ����������������Ӧ�ó��غ���ʾһϵ�����������ʱ���û������ᵥ�����е�һ�����鿴�洢�ڴ������е�ԭʼ�ĵ�����ʼ����ʾ����ֻ��Ҫ��ʾ�̵ܶ�һ����Ϣ�������ǵ���������
Document �Ĵ��ۣ����DZ��裬�����Ӧ�ñ�����������ĵ���
<query> ���ָ��������� Solr �з������¼���صļ���ѡ�Searcher
�� Java �������� Query ʵ����Ҫ�Ľ���һ��ƺ�����������ܣ�����Щ�µ� Searcher �����Ա�Ϊ�ֳ��û��ṩ��ѯ����֮ǰ���ȶ����ǽ���
����������<query> �����е� <listener> ѡ��� newSearcher
�� firstSearcher �¼���������ʹ����Щ�¼���ָ��ʵ����������������һ����������ʱӦ��ִ����Щ��ѯ�����Ӧ�ó�����������ijЩ�ض��IJ�ѯ����ô�ڴ���������������һ����������ʱ��Ӧ�÷�ע����Щ���ֲ�ִ���ʵ��IJ�ѯ��
solrconfig.xml �ļ���ʣ�ಿ�֣��� <admin>
֮�⣬�������� ���桢���� �� ��չ���� Solr �йص���Ŀ��admin �����������Զ��ƹ������档�й�����
admin �ڵĸ�����Ϣ����ο�solrconfig.xml �ļ��е�ע�͡�
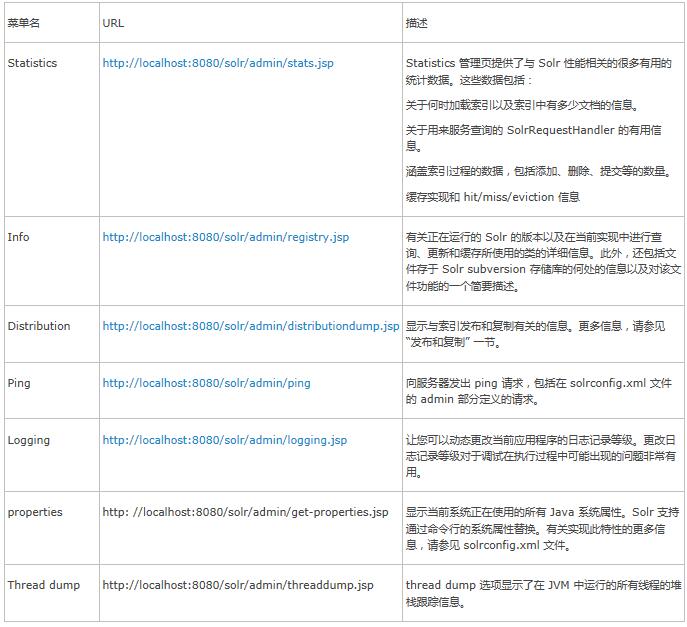
7�� ���ӡ���¼��ͳ������
���ڼ��ӡ���¼��ͳ�����ݵ� Solr ����ѡ��
8�� ���ܻ���
���ܻ������� Solr ���Գ�Ϊ������Ŀ��������������һ���ؼ�����������Solr
�ṩ�����ֲ�ͬ�Ļ������ͣ������������Ͷ����� solrconfig.xml �� <query>
���������á�solrconfig.xml �ļ������õı�����г�����Щ�������ͣ�

ÿ��������������������ĸ����ԣ�
class �ǻ���ʵ�ֵ� Java ����
size ��������Ŀ����
initialSize �ǻ���ij�ʼ��С��
autoWarmCount ��ȡ�Ծɻ�����Ԥ���»������Ŀ���������Ŀ�ܶ࣬����ζ�Ż����
hit ����ֻ࣬������Ҫ��������Ԥ��ʱ�䡣
��������SolrJ����solr API�����index����
ʹ��SolrJ����Solr�������httpClient������SolrҪ��SolrJ�Ƿ�װ��httpClient������������solr��API�ġ�SolrJ�ײ㻹��ͨ��ʹ��httpClient�еķ��������Solr�IJ�����
1�� ���ȣ�����Ҫ��������jar��
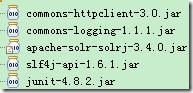
����apache-solr-solrj-3.4.0.jar��slf4j-api-1.6.1.jar���������ص�apache-solr-3.4.0��ѹ�����е�dist�����ҵ���
2�� ��Σ�����һ���IJ����࣬���Server�������ط����IJ��Թ������������£�
package com.hoo.test;
import java.io.IOException;
import java.net.MalformedURLException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.solr.common.params.ModifiableSolrParams;
import org.apache.solr.common.params.SolrParams;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import com.hoo.entity.Index;
/**
* <b>function:</b> Server TestCase
* @author hoojo
* @createDate 2011-10-19 ����01:49:07
* @file ServerTest.java
* @package com.hoo.test
* @project SolrExample
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class ServerTest {
private SolrServer server;
private CommonsHttpSolrServer httpServer;
private static final String DEFAULT_URL = "http://localhost:8983/solr/";
@Before
public void init() {
try {
server = new CommonsHttpSolrServer(DEFAULT_URL);
httpServer = new CommonsHttpSolrServer(DEFAULT_URL);
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
@After
public void destory() {
server = null;
httpServer = null;
System.runFinalization();
System.gc();
}
public final void fail(Object o) {
System.out.println(o);
}
/**
* <b>function:</b> �����Ƿ�server����ɹ�
* @author hoojo
* @createDate 2011-10-21 ����09:48:18
*/
@Test
public void server() {
fail(server);
fail(httpServer);
}
/**
* <b>function:</b> ����query������ѯ����
* @author hoojo
* @createDate 2011-10-21 ����10:06:39
* @param query
*/
public void query(String query) {
SolrParams params = new SolrQuery(query);
try {
QueryResponse response = server.query(params);
SolrDocumentList list = response.getResults();
for (int i = 0; i < list.size(); i++) {
fail(list.get(i));
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
}
|
��������server case����������ɹ�������������ͳɹ������ӵ���
ע�⣺�����б�����֮ǰ�����������solr�ٷ��Զ�����Ŀ��http://localhost:8983/solr/��֤�ܹ��ɹ�����������̡���Ϊ�����������й�������Χ�����solr������ɵġ���������ڻ���֪������ô���𡢷����ٷ�solr���̣���ο�ǰ��ľ����½ڡ�
3�� Server���й�����ѡ�������server��CommonsHttpSolrServer��ʵ��
server.setSoTimeout(1000); // socket read timeout
server.setConnectionTimeout(100);
server.setDefaultMaxConnectionsPerHost(100);
server.setMaxTotalConnections(100);
server.setFollowRedirects(false); // defaults to false
// allowCompression defaults to false.
// Server side must support gzip or deflate for this to have any effect.
server.setAllowCompression(true);
server.setMaxRetries(1); // defaults to 0. > 1 not recommended.
//sorlr J Ŀǰʹ�ö����Ƶĸ�ʽ��ΪĬ�ϵĸ�ʽ������solr1.2���û�ͨ����ʾ�����ò���ʹ��XML��ʽ��
server.setParser(new XMLResponseParser());
//�������������ʽ
//server.setRequestWriter(new BinaryRequestWriter());
|
4�� ����SolrJ���Index Document�����Ӳ���
/**
* <b>function:</b> ����doc�ĵ�
* @author hoojo
* @createDate 2011-10-21 ����09:49:10
*/
@Test
public void addDoc() {
//����doc�ĵ�
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", 1);
doc.addField("name", "Solr Input Document");
doc.addField("manu", "this is SolrInputDocument content");
try {
//����һ��doc�ĵ�
UpdateResponse response = server.add(doc);
fail(server.commit());//commit��ű��浽������
fail(response);
fail("query time��" + response.getQTime());
fail("Elapsed Time��" + response.getElapsedTime());
fail("status��" + response.getStatus());
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
query("name:solr");
}
|
��apache-solr-3.4.0\example\solr\confĿ¼�µ�schema.xml�п����ҵ��й���field���Ե����ã�schema.xml�е�field�ͺ�����Document�ĵ��е�field��id��name��manu����Ӧ���������ERROR:unknown
field 'xxxx'�ͱ�ʾ�����õ����field��schema.xml�в����ڡ����һ��Ҫʹ�����field��������schema.xml�н���filedԪ�ص����á�������ο�ǰ����½ڡ�
ע�⣺��schema.xml��������uniqueKeyΪid���ͱ�ʾid��Ψһ�ġ����������Document��ʱ��id�ظ����ӡ���ô�������ӵ���ͬid��doc�Ḳ��ǰ���doc��������update���²���������������ظ������ݡ�
5�� ����SolrJ���Ӷ��Document���������ĵ�����
/**
* <b>function:</b> ����docs�ĵ�����
* @author hoojo
* @createDate 2011-10-21 ����09:55:01
*/
@Test
public void addDocs() {
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", 2);
doc.addField("name", "Solr Input Documents 1");
doc.addField("manu", "this is SolrInputDocuments 1 content");
docs.add(doc);
doc = new SolrInputDocument();
doc.addField("id", 3);
doc.addField("name", "Solr Input Documents 2");
doc.addField("manu", "this is SolrInputDocuments 3 content");
docs.add(doc);
try {
//add docs
UpdateResponse response = server.add(docs);
//commit��ű��浽������
fail(server.commit());
fail(response);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
query("solr");
}
|
��������һ��List����
6�� ����JavaEntity Bean�������Ҫ�ȴ���һ��JavaBean��Ȼ����������Ӳ�����
JavaBean��Index�Ĵ���
/**
* <b>function:</b> JavaEntity Bean��Index��Ҫ������ص�Annotationע�⣬���ڸ���solr��Щ���Բ��뵽index��
* @author hoojo
* @createDate 2011-10-19 ����05:33:27
* @file Index.java
* @package com.hoo.entity
* @project SolrExample
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class Index {
//@Field setter����������AnnotationҲ�ǿ��Ե�
private String id;
@Field
private String name;
@Field
private String manu;
@Field
private String[] cat;
@Field
private String[] features;
@Field
private float price;
@Field
private int popularity;
@Field
private boolean inStock;
public String getId() {
return id;
}
@Field
public void setId(String id) {
this.id = id;
}
//getter��setter����
public String toString() {
return this.id + "#" + this.name + "#" + this.manu + "#" + this.cat;
}
}
|
ע������������Ǻ���apache-solr-3.4.0\example\solr\confĿ¼�µ�schema.xml�п����ҵ��й���field���Ե����ö�Ӧ�ġ������Index
JavaBean�г��ֵ�������schema.xml��field�������ҵ�����ô������unknown filed����
����Bean���doc���Ӳ���
/**
* <b>function:</b> ����JavaEntity Bean
* @author hoojo
* @createDate 2011-10-21 ����09:55:37
*/
@Test
public void addBean() {
//Index��Ҫ������ص�Annotationע�⣬���ڸ���solr��Щ���Բ��뵽index��
Index index = new Index();
index.setId("4");
index.setName("add bean index");
index.setManu("index bean manu");
index.setCat(new String[] { "a1", "b2" });
try {
//����Index Bean��������
UpdateResponse response = server.addBean(index);
fail(server.commit());//commit��ű��浽������
fail(response);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
queryAll();
}
|
7�� ����Bean����
/**
* <b>function:</b> ����Entity Bean���ϵ�������
* @author hoojo
* @createDate 2011-10-21 ����10:00:55
*/
@Test
public void addBeans() {
Index index = new Index();
index.setId("6");
index.setName("add beans index 1");
index.setManu("index beans manu 1");
index.setCat(new String[] { "a", "b" });
List<Index> indexs = new ArrayList<Index>();
indexs.add(index);
index = new Index();
index.setId("5");
index.setName("add beans index 2");
index.setManu("index beans manu 2");
index.setCat(new String[] { "aaa", "bbbb" });
indexs.add(index);
try {
//����������
UpdateResponse response = server.addBeans(indexs);
fail(server.commit());//commit��ű��浽������
fail(response);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
queryAll();
}
|
8�� ɾ������Document
/**
* <b>function:</b> ɾ����������
* @author hoojo
* @createDate 2011-10-21 ����10:04:28
*/
@Test
public void remove() {
try {
//ɾ��idΪ1������
server.deleteById("1");
server.commit();
query("id:1");
//����id���ϣ�ɾ���������
List<String> ids = new ArrayList<String>();
ids.add("2");
ids.add("3");
server.deleteById(ids);
server.commit(true, true);
query("id:3 id:2");
//ɾ����ѯ����������Ϣ
server.deleteByQuery("id:4 id:6");
server.commit(true, true);
queryAll();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
|
9�� ��ѯ����
/**
* <b>function:</b> ��ѯ����������Ϣ
* @author hoojo
* @createDate 2011-10-21 ����10:05:38
*/
@Test
public void queryAll() {
ModifiableSolrParams params = new ModifiableSolrParams();
// ��ѯ�ؼ��ʣ�*:*�����������ԡ�����ֵ��������index
params.set("q", "*:*");
// ��ҳ��start=0���Ǵ�0��ʼ����rows=5��ǰ����5����¼���ڶ�ҳ���DZ仯start���ֵΪ5�Ϳ����ˡ�
params.set("start", 0);
params.set("rows", Integer.MAX_VALUE);
// �����������id ������ô��score desc �ij� id desc(or asc)
params.set("sort", "score desc");
// ������Ϣ * Ϊȫ�� ������ȫ������score�������������Ͳ���ʹ��score
params.set("fl", "*,score");
try {
QueryResponse response = server.query(params);
SolrDocumentList list = response.getResults();
for (int i = 0; i < list.size(); i++) {
fail(list.get(i));
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
|
10�� ������Server�йط���
/**
* <b>function:</b> ����server��ط�������
* @author hoojo
* @createDate 2011-10-21 ����10:02:03
*/
@Test
public void otherMethod() {
fail(server.getBinder());
try {
fail(server.optimize());//�ϲ������ļ��������Ż��������ṩ���ܣ�����Ҫһ����ʱ��
fail(server.ping());//ping�������Ƿ����ӳɹ�
Index index = new Index();
index.setId("299");
index.setName("add bean index199");
index.setManu("index bean manu199");
index.setCat(new String[] { "a199", "b199" });
UpdateResponse response = server.addBean(index);
fail("response: " + response);
queryAll();
//�ع���֮ǰ�IJ�����rollback addBean operation
fail("rollback: " + server.rollback());
//�ύ�������ύ�����ع�֮ǰ����������addBeanû�гɹ���������
fail("commit: " + server.commit());
queryAll();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
|
11�� �ĵ���ѯ
/**
* <b>function:</b> query �����÷�����
* @author hoojo
* @createDate 2011-10-20 ����04:44:28
*/
@Test
public void queryCase() {
//AND ����
SolrQuery params = new SolrQuery("name:apple AND manu:inc");
//OR ����
params.setQuery("name:apple OR manu:apache");
//�ո� ��ͬ�� OR
params.setQuery("name:server manu:dell");
//params.setQuery("name:solr - manu:inc");
//params.setQuery("name:server + manu:dell");
//��ѯname����solr apple
params.setQuery("name:solr,apple");
//manu������inc
params.setQuery("name:solr,apple NOT manu:inc");
//50 <= price <= 200
params.setQuery("price:[50 TO 200]");
params.setQuery("popularity:[5 TO 6]");
//params.setQuery("price:[50 TO 200] - popularity:[5 TO 6]");
//params.setQuery("price:[50 TO 200] + popularity:[5 TO 6]");
//50 <= price <= 200 AND 5 <= popularity <= 6
params.setQuery("price:[50 TO 200] AND popularity:[5 TO 6]");
params.setQuery("price:[50 TO 200] OR popularity:[5 TO 6]");
//��������ѯ������������� filter ���ƶ��������ϣ���and
//params.addFilterQuery("id:VA902B");
//params.addFilterQuery("price:[50 TO 200]");
//params.addFilterQuery("popularity:[* TO 5]");
//params.addFilterQuery("weight:*");
//0 < popularity < 6 û�е���
//params.addFilterQuery("popularity:{0 TO 6}");
//����
params.addSortField("id", ORDER.asc);
//��ҳ��start��ʼҳ��rowsÿҳ��ʾ��¼����
//params.add("start", "0");
//params.add("rows", "200");
//params.setStart(0);
//params.setRows(200);
//���ø���
params.setHighlight(true); // �����������
params.addHighlightField("name");// �����ֶ�
params.setHighlightSimplePre("<font color='red'>");//��ǣ������ؼ���ǰ
params.setHighlightSimplePost("</font>");//��
params.setHighlightSnippets(1);//�����Ƭ����Ĭ��Ϊ1
params.setHighlightFragsize(1000);//ÿ����Ƭ����ȣ�Ĭ��Ϊ100
//��Ƭ��Ϣ
params.setFacet(true)
.setFacetMinCount(1)
.setFacetLimit(5)//��
.addFacetField("name")//��Ƭ�ֶ�
.addFacetField("inStock");
//params.setQueryType("");
try {
QueryResponse response = server.query(params);
/*List<Index> indexs = response.getBeans(Index.class);
for (int i = 0; i < indexs.size(); i++) {
fail(indexs.get(i));
}*/
//�����ѯ�����
SolrDocumentList list = response.getResults();
fail("query result nums: " + list.getNumFound());
for (int i = 0; i < list.size(); i++) {
fail(list.get(i));
}
//�����Ƭ��Ϣ
List<FacetField> facets = response.getFacetFields();
for (FacetField facet : facets) {
fail(facet);
List<Count> facetCounts = facet.getValues();
for (FacetField.Count count : facetCounts) {
System.out.println(count.getName() + ": " + count.getCount());
}
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
|
12�� ��Ƭ��ѯ��ͳ��
/**
* <b>function:</b> ��Ƭ��ѯ�� ����ͳ�ƹؼ��ּ����ֵĴ������������Զ���ȫ��ʾ
* @author hoojo
* @createDate 2011-10-20 ����04:54:25
*/
@Test
public void facetQueryCase() {
SolrQuery params = new SolrQuery("*:*");
//����
params.addSortField("id", ORDER.asc);
params.setStart(0);
params.setRows(200);
//FacetΪsolr�еIJ�η����ѯ
//��Ƭ��Ϣ
params.setFacet(true)
.setQuery("*:*")
.setFacetMinCount(1)
.setFacetLimit(5)//��
//.setFacetPrefix("electronics", "cat")
.setFacetPrefix("cor")//��ѯmanu��name�йؼ���ǰ��cor��
.addFacetField("manu")
.addFacetField("name");//��Ƭ�ֶ�
try {
QueryResponse response = server.query(params);
//�����ѯ�����
SolrDocumentList list = response.getResults();
fail("Query result nums: " + list.getNumFound());
for (int i = 0; i < list.size(); i++) {
fail(list.get(i));
}
fail("All facet filed result: ");
//�����Ƭ��Ϣ
List<FacetField> facets = response.getFacetFields();
for (FacetField facet : facets) {
fail(facet);
List<Count> facetCounts = facet.getValues();
for (FacetField.Count count : facetCounts) {
//�ؼ��� - ���ִ���
fail(count.getName() + ": " + count.getCount());
}
}
fail("Search facet [name] filed result: ");
//�����Ƭ��Ϣ
FacetField facetField = response.getFacetField("name");
List<Count> facetFields = facetField.getValues();
for (Count count : facetFields) {
//�ؼ��� - ���ִ���
fail(count.getName() + ": " + count.getCount());
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
|
��Ƭ��ѯ��ijЩͳ�ƹؼ��ֵ�ʱ���Ǻ����õģ�����ͳ�ƹؼ��ֳ��ֵĴ���������ͨ��ͳ�ƵĹؼ�������������ĵ�����Ϣ��
�ġ�Document�ĵ���JavaBean�ת��
����ת����Bean��һ����User����
package com.hoo.entity;
import java.io.Serializable;
import org.apache.solr.client.solrj.beans.Field;
/**
* <b>function:</b> User Entity Bean�����б�����Annotation @Field ע������Խ�����index����
* @author hoojo
* @createDate 2011-10-19 ����04:16:00
* @file User.java
* @package com.hoo.entity
* @project SolrExample
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class User implements Serializable {
/**
* @author Hoojo
*/
private static final long serialVersionUID = 8606788203814942679L;
//@Field
private int id;
@Field
private String name;
@Field
private int age;
/**
* ���Ը�ij��������������likes����solr index�����ԣ���solrIndex�н���ʾlikeΪlikes
*/
@Field("likes")
private String[] like;
@Field
private String address;
@Field
private String sex;
@Field
private String remark;
public int getId() {
return id;
}
//setter ��������Ҳ����
@Field
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
//getter��setter
@Override
public String toString() {
return this.id + "#" + this.name + "#" + this.age + "#" + this.like + "#" + this.address + "#" + this.sex + "#" + this.remark;
}
}
|
�������������
package com.hoo.test;
import org.apache.solr.client.solrj.beans.DocumentObjectBinder;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.solr.common.SolrInputField;
import org.junit.Test;
import com.hoo.entity.User;
/**
* <b>function:</b>SolrInputDocument implements Map, Iterable
* @author hoojo
* @createDate 2011-10-19 ����03:54:54
* @file SolrInputDocumentTest.java
* @package com.hoo.test
* @project SolrExample
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class SolrInputDocumentTest {
public final void fail(Object o) {
System.out.println(o);
}
/**
* <b>function:</b> ����SolrInputDocument
* @author hoojo
* @createDate 2011-10-21 ����03:38:20
*/
@Test
public void createDoc() {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", System.currentTimeMillis());
doc.addField("name", "SolrInputDocument");
doc.addField("age", 22, 2.0f);
doc.addField("like", new String[] { "music", "book", "sport" });
doc.put("address", new SolrInputField("guangzhou"));
doc.setField("sex", "man");
doc.setField("remark", "china people", 2.0f);
fail(doc);
}
/**
* <b>function:</b> ����DocumentObjectBinder����SolrInputDocument �� User�����ת��
* @author hoojo
* @createDate 2011-10-21 ����03:38:40
*/
@Test
public void docAndBean4Binder() {
SolrDocument doc = new SolrDocument();
doc.addField("id", 456);
doc.addField("name", "SolrInputDocument");
doc.addField("likes", new String[] { "music", "book", "sport" });
doc.put("address", "guangzhou");
doc.setField("sex", "man");
doc.setField("remark", "china people");
DocumentObjectBinder binder = new DocumentObjectBinder();
User user = new User();
user.setId(222);
user.setName("JavaBean");
user.setLike(new String[] { "music", "book", "sport" });
user.setAddress("guangdong");
fail(doc);
// User ->> SolrInputDocument
fail(binder.toSolrInputDocument(user));
// SolrDocument ->> User
fail(binder.getBean(User.class, doc));
SolrDocumentList list = new SolrDocumentList();
list.add(doc);
list.add(doc);
//SolrDocumentList ->> List
fail(binder.getBeans(User.class, list));
}
/**
* <b>function:</b> SolrInputDocument����ط���
* @author hoojo
* @createDate 2011-10-21 ����03:44:30
*/
@Test
public void docMethod() {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", System.currentTimeMillis());
doc.addField("name", "SolrInputDocument");
doc.addField("age", 23, 1.0f);
doc.addField("age", 22, 2.0f);
doc.addField("age", 24, 0f);
fail(doc.entrySet());
fail(doc.get("age"));
//�������ã����ưٶȾ�������
doc.setDocumentBoost(2.0f);
fail(doc.getDocumentBoost());
fail(doc.getField("name"));
fail(doc.getFieldNames());//keys
fail(doc.getFieldValues("age"));
fail(doc.getFieldValues("id"));
fail(doc.values());
}
}
|
|






