| 一、引言
本文的读者是技术支持人员。阅读本文后,你将理解jboss的启动脚本文件(run.sh)中有一系列的JVM配置参数的含义,以及如何调整它们,从而使得MegaEyes中心管理服务器的性能得到优化。
MegaEyes中心管理服务器的性能调优涉及到系统的多个方面,包括MegaEyes应用本身、应用服务器(jboss)、数据库和java虚拟机(JVM)等等。本文重点介绍JVM的性能优化。
需要注意的是,JVM性能调优具有应用独特性(application specific),就是说,不同的应用情形应该有不同的调整方案,这就要求你首先要观察JVM的运行状态,然后根据观察结果调整参数。没有一个通用的调优方案可以适用于所有的MegaEyes应用。
什么是性能调优
对性能调优,不同的人有不同的理解,本文是指对下列指标最大化:
n并发用户(concurrent users),在服务请求失败或请求响应超过预期时间之前,系统支持的最大并发用户数量。
n系统容量(throughput),可以用每秒处理的事务(transaction)数量计算。
n可靠性(reliability)
换句话说,我们想对更多的用户提供更快捷的、不会中断的服务。
JVM性能调优的重点
JVM的性能调优的重点是垃圾回收(gc,garbage collection)和内存管理。垃圾回收的时候会导致整个虚拟机暂停服务,因此,应该尽可能地缩短垃圾回收的处理时间。
JVM内存
JVM占用的内存称为堆(heap),它被分为三个区:年轻(young,又称为new)、老(tenured,又称为old)和永生(perm)。这三个区是按照java对象的生存期划分的,在new区的对象生存期最短,很快就会被gc回收;perm区的对象生存期最长,与JVM同生死。Perm区的对象不会被gc回收。
new区又被分为三个部分:伊甸园(eden)和两个幸存者(survivor)。对象的创建总是在eden部分(这大概就是命名该部分为eden的原因吧)。两个survivor中总有一个是空的,它作为另一个survivor的缓冲区。当gc发生时,所有eden和survivor中活下来的对象被移动到另一个survivor中。对象会在两个survivor之间不断移动,直到活得足够久,然后移动到old区。我们可以猜想,之所以如此划分使用内存,肯定是为了缩短gc的执行时间,提高gc的执行效率。
垃圾回收算法
除了默认的垃圾回收算法外,JVM还提供了两个:并行(parallel)和并发(concurrent),前者作用在new区,后者作用在old区。两者可以同时使用。
并行算法会产生多个线程以提高执行效率。当有多个cpu的时候,它会显著缩短gc的工作时间。
并发算法可以在JVM不中断对应用的服务的情况下执行(通常情况下,在gc工作的时候JVM停止对应用的服务)。
二、性能参数
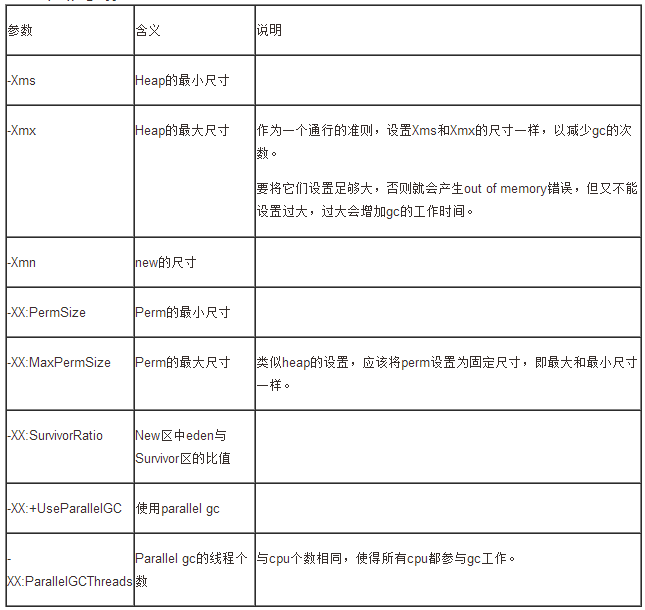
JVM的参数主要由-X和-XX类型的选项组成,上边列出了一些对内存和gc的性能影响比较大的。
三、性能参数调优
要调整参数首先要观察它们。观察JVM内存和gc的工具很多,jdk本身也提供了一些,这些工具简单、实用,而且不需要安装。其中,最常用的是jps和jstat,前者用来查看JVM的进程id(pid),后者用这个pid作为参数来得到内存和gc的状态,就是说,在执行jstat之前必须用jps得到JVM的pid。Jstat的例子:
jstat -gcutil 21308 250 10 |
其中,21308是(运行jboss)的JVM的pid;250是采样间隔,单位是毫秒,即250毫秒采集一次数据;10是采样次数。
上述命令的执行结果如下:
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081
0.00 0.00 11.39 5.29 13.57 328 1.955 327 133.126
135.081 |
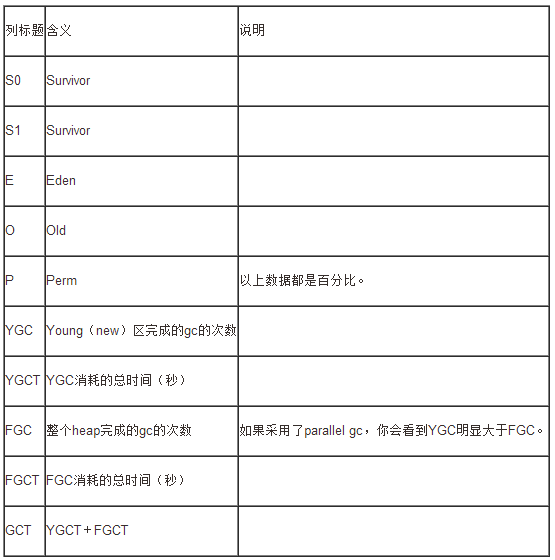
我们可以将采样次数设置足够大,这样就可以看到内存和gc的变化了。
从上述数据可以看出,内存各区域的占用率都不高,gc的执行时间都不长,不过,perm区有些太大,太浪费了。因为perm区的对象与JVM的生命周期是一样的,对象数量不会动态变化,所以,我们可以把这个区域的尺寸设置为原尺寸的二分之一,这样,perm的占用率将从13%左右增加到26%左右。
从上述数据还可以看出,new区的gc明显比真个heap的gc快得多。通常,FGC应该不超过400毫秒,否则,将严重影响java应用的正常运行。
一、JVM内存模型及垃圾收集算法
1.根据Java虚拟机规范,JVM将内存划分为:
New(年轻代)
Tenured(年老代)
永久代(Perm)
其中New和Tenured属于堆内存,堆内存会从JVM启动参数(-Xmx:3G)指定的内存中分配,Perm不属于堆内存,有虚拟机直接分配,但可以通过-XX:PermSize
-XX:MaxPermSize 等参数调整其大小。
年轻代(New):年轻代用来存放JVM刚分配的Java对象
年老代(Tenured):年轻代中经过垃圾回收没有回收掉的对象将被Copy到年老代
永久代(Perm):永久代存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间。
New又分为几个部分:
Eden:Eden用来存放JVM刚分配的对象
Survivor1
Survivro2:两个Survivor空间一样大,当Eden中的对象经过垃圾回收没有被回收掉时,会在两个Survivor之间来回
Copy,当满足某个条件,比如Copy次数,就会被Copy到Tenured。显然,Survivor只是增加了对象在年轻代中的逗留时间,增加了被垃
圾回收的可能性。
2.垃圾回收算法
垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
Serial算法(单线程)
并行算法
并发算法
JVM会根据机器的硬件配置对每个内存代选择适合的回收算法,比如,如果机器多于1个核,会对年轻代选择并行算法,关于选择细节请参考JVM调优文档。
稍微解释下的是,并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行,而并发算法,也是多线程回收,但期间不停止应用执行。所以,并发算法适用于
交互性高的一些程序。经过观察,并发算法会减少年轻代的大小,其实就是使用了一个大的年老代,这反过来跟并行算法相比吞吐量相对较低。
还有一个问题是,垃圾回收动作何时执行?
当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
另一个问题是,何时会抛出OutOfMemoryException,并不是内存被耗空的时候才抛出
JVM98%的时间都花费在内存回收
每次回收的内存小于2%
满足这两个条件将触发OutOfMemoryException,这将会留给系统一个微小的间隙以做一些Down之前的操作,比如手动打印Heap
Dump。
二、内存泄漏及解决方法
1.系统崩溃前的一些现象:
每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
2.生成堆的dump文件
通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
3.分析dump文件
下面要考虑的是如何打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux。当然我们可以借助X-Window把Linux上的图形导入到Window。我们考虑用下面几种工具打开该文件:
1.Visual VM
2.IBM HeapAnalyzer
3.JDK 自带的Hprof工具
使用这些工具时为了确保加载速度,建议设置最大内存为6G。使用后发现,这些工具都无法直观地观察到内存泄漏,Visual
VM虽能观察到对象大小,但看不到调用堆栈;HeapAnalyzer虽然能看到调用堆栈,却无法正确打开一个3G的文件。因此,我们又选用了
Eclipse专门的静态内存分析工具:Mat。
4.分析内存泄漏
通过Mat我们能清楚地看到,哪些对象被怀疑为内存泄漏,哪些对象占的空间最大及对象的调用关系。针对本案,在ThreadLocal中有很多的JbpmContext实例,经过调查是JBPM的Context没有关闭所致。
另,通过Mat或JMX我们还可以分析线程状态,可以观察到线程被阻塞在哪个对象上,从而判断系统的瓶颈。
5.回归问题
Q:为什么崩溃前垃圾回收的时间越来越长?
A:根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
Q:为什么Full GC的次数越来越多?
A:因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
Q:为什么年老代占用的内存越来越大?
A:因为年轻代的内存无法被回收,越来越多地被Copy到年老代
三、性能调优
除了上述内存泄漏外,我们还发现CPU长期不足3%,系统吞吐量不够,针对8core×16G、64bit的Linux服务器来说,是严重的资源浪费。
在CPU负载不足的同时,偶尔会有用户反映请求的时间过长,我们意识到必须对程序及JVM进行调优。从以下几个方面进行:
线程池:解决用户响应时间长的问题
连接池
JVM启动参数:调整各代的内存比例和垃圾回收算法,提高吞吐量
程序算法:改进程序逻辑算法提高性能
1.Java线程池(java.util.concurrent.ThreadPoolExecutor)
大多数JVM6上的应用采用的线程池都是JDK自带的线程池,之所以把成熟的Java线程池进行罗嗦说明,是因为该线程池的行为与我们想象的有点出入。Java线程池有几个重要的配置参数:
corePoolSize:核心线程数(最新线程数)
maximumPoolSize:最大线程数,超过这个数量的任务会被拒绝,用户可以通过RejectedExecutionHandler接口自定义处理方式
keepAliveTime:线程保持活动的时间
workQueue:工作队列,存放执行的任务
Java线程池需要传入一个Queue参数(workQueue)用来存放执行的任务,而对Queue的不同选择,线程池有完全不同的行为:
SynchronousQueue: 一个无容量的等待队列,一个线程的insert操作必须等待另一线程的remove操作,采用这个Queue线程池将会为每个任务分配一个新线程
LinkedBlockingQueue : 无界队列,采用该Queue,线程池将忽略
maximumPoolSize参数,仅用corePoolSize的线程处理所有的任务,未处理的任务便在LinkedBlockingQueue中排队
ArrayBlockingQueue: 有界队列,在有界队列和 maximumPoolSize的作用下,程序将很难被调优:更大的Queue和小的maximumPoolSize将导致CPU的低负载;小的Queue和大的池,Queue就没起动应有的作用。
其实我们的要求很简单,希望线程池能跟连接池一样,能设置最小线程数、最大线程数,当最小数<任务<最大数时,应该分配新的线程处理;当任务>最大数时,应该等待有空闲线程再处理该任务。
但线程池的设计思路是,任务应该放到Queue中,当Queue放不下时再考虑用新线程处理,如果Queue满且无法派生新线程,就拒绝该任务。设计导致
“先放等执行”、“放不下再执行”、“拒绝不等待”。所以,根据不同的Queue参数,要提高吞吐量不能一味地增大maximumPoolSize。
当然,要达到我们的目标,必须对线程池进行一定的封装,幸运的是ThreadPoolExecutor中留了足够的自定义接口以帮助我们达到目标。我们封装的方式是:
以SynchronousQueue作为参数,使maximumPoolSize发挥作用,以防止线程被无限制的分配,同时可以通过提高maximumPoolSize来提高系统吞吐量
自定义一个RejectedExecutionHandler,当线程数超过maximumPoolSize时进行处理,处理方式为隔一段时间检
查线程池是否可以执行新Task,如果可以把拒绝的Task重新放入到线程池,检查的时间依赖keepAliveTime的大小。
2.连接池(org.apache.commons.dbcp.BasicDataSource)
在使用org.apache.commons.dbcp.BasicDataSource的时候,因为之前采用了默认配置,所以当访问量大时,通过JMX
观察到很多Tomcat线程都阻塞在BasicDataSource使用的Apache ObjectPool的锁上,直接原因当时是因为BasicDataSource连接池的最大连接数设置的太小,默认的BasicDataSource配
置,仅使用8个最大连接。
我还观察到一个问题,当较长的时间不访问系统,比如2天,DB上的Mysql会断掉所以的连接,导致连接池中缓存的连接不能用。为了解决这些问题,我们充分研究了BasicDataSource,发现了一些优化的点:
Mysql默认支持100个链接,所以每个连接池的配置要根据集群中的机器数进行,如有2台服务器,可每个设置为60
initialSize:参数是一直打开的连接数
minEvictableIdleTimeMillis:该参数设置每个连接的空闲时间,超过这个时间连接将被关闭
timeBetweenEvictionRunsMillis:后台线程的运行周期,用来检测过期连接
maxActive:最大能分配的连接数
maxIdle:最大空闲数,当连接使用完毕后发现连接数大于maxIdle,连接将被直接关闭。只有initialSize
< x < maxIdle的连接将被定期检测是否超期。这个参数主要用来在峰值访问时提高吞吐量。
initialSize是如何保持的?经过研究代码发现,BasicDataSource会关闭所有超期的连接,然后再打开
initialSize数量的连接,这个特性与minEvictableIdleTimeMillis、 timeBetweenEvictionRunsMillis一起保证了所有超期的initialSize连接都会被重新连接,从而避免了Mysql长时
间无动作会断掉连接的问题。
3.JVM参数
在JVM启动参数中,可以设置跟内存、垃圾回收相关的一些参数设置,默认情况不做任何设置JVM会工作的很好,但对一些配置很好的Server和具体的应用必须仔细调优才能获得最佳性能。通过设置我们希望达到一些目标:
GC的时间足够的小
GC的次数足够的少
发生Full GC的周期足够的长
前两个目前是相悖的,要想GC时间小必须要一个更小的堆,要保证GC次数足够少,必须保证一个更大的堆,我们只能取其平衡。
(1)针对JVM堆的设置一般,可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值
(2)年轻代和年老代将根据默认的比例(1:2)分配堆内存,可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代,比如
年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize
-XX:MaxNewSize设置为同样大小
(3)年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。我们观察一下二者大小变化有哪些影响
更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full
GC
更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full
GC的频率
如何选择应该依赖应用程序对象生命周期的分布情况:如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该
适当增大。但很多应用都没有这样明显的特性,在抉择时应该根据以下两点:(A)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理
(B)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间
(4)在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法:
-XX:+UseParallelOldGC,默认为Serial收集
(5)线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
(4)可以通过下面的参数打Heap Dump信息
-XX:HeapDumpPath
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:/usr/aaa/dump/heap_trace.txt |
通过下面参数可以控制OutOfMemoryError时打印堆的信息
-XX:+HeapDumpOnOutOfMemoryError
请看一下一个时间的Java参数配置:(服务器:Linux 64Bit,8Core×16G)
JAVA_OPTS="$JAVA_OPTS -server -Xms3G -Xmx3G -Xss256k
-XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseParallelOldGC
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/aaa/dump
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/aaa/dump/heap_trace.txt
-XX:NewSize=1G -XX:MaxNewSize=1G"
经过观察该配置非常稳定,每次普通GC的时间在10ms左右,Full GC基本不发生,或隔很长很长的时间才发生一次
通过分析dump文件可以发现,每个1小时都会发生一次Full GC,经过多方求证,只要在JVM中开启了JMX服务,JMX将会1小时执行一次Full
GC以清除引用,关于这点请参考附件文档。
4.程序算法调优:本次不作为重点
|






