|
摘要:在Java20岁生日这年,我们用这篇文章记录蚂蚁金服内部,在金融云环境下Java系统的Profiling和Debugging经验与实践,与大家分享交流,有非常特别的意义。希望读者能够从中借鉴到一些解决问题的思路。
从1995年Java1.0beta发布到现在,整整过去了20年。Java的发明源于嵌入式领域,不过后来Java的发展,出乎意料地在企业级应用领域占据了几乎统治的地位。阿里巴巴以及支付宝(就是后来的蚂蚁金服),绝大部分的业务代码都是Java编写的。在Java20岁生日这年,我们用这篇文章记录蚂蚁金服内部,在金融云环境下Java系统的Profiling和Debugging经验与实践,与大家分享交流,有非常特别的意义。希望读者能够从中借鉴到一些解决问题的思路。

线上Profiling/Debugging难点
在集中式架构的时代,应用按照大的业务功能划分为不同的模块或者系统,无论在系统类型、数量还是依赖上,均相对可控,一旦出现线上问题也容易在线下模拟分析。但建立在分布式架构体系上的应用具有数量多、规模大、环境复杂的特点。这些特点带来了很多问题,不是单一的工具和系统能解决的。这里仅着重讲述给Profiling和Debugging工作带来的挑战。
因安全问题增加的权限控制。在SOA架构下,系统间通过服务进行通信,但不是所有服务都可以公开暴露,不是所有客户端都是可信的。于是系统中增加各种管控和权限设置。这些安全措施给Profiling和Debugging工作带来很大的麻烦。比如网络隔离,导致无法直接使用有简便图形界面的Eclipse去远程调试线上服务器。即使登录到服务器上使用命令行工具,也面临着登录账户权限、sudo权限以及源码查看权限等一系列权限申请问题,极大地降低了问题定位效率。
类库依赖复杂,版本碎片化。类库的复用是系统设计的经典法则,但随着系统规模增加到百甚至千级规模时,每个系统对类库的依赖就会形成多种排列组合,而且类库的版本分布也呈碎片化。Profiling和Debugging时需要针对具体的系统查找相关类库的版本号,然后再找对应的代码,比较繁琐。
架构规范易制定难保持:架构规范在单体数量众多且相对不可控的情况下显得尤为重要,但又因为系统分散,规模庞大,架构规范的保持将会十分困难,每次引入系统变更的同时就会引入新复杂度和破坏架构规范的风险,代码也会随之产生一些“badsmell”。因此在分布式环境下,问题的长尾效应非常明显。一个系统发现的Bug或者性能问题,可能在后续比较长的一段时间会在不同的系统中重复出现。反过来,一些通常认为出现概率很低的问题,在机器数量大的情况下,出现的机会还是很大的。
请求调用链路跟踪困难。模块和系统拆解得越细,服务就越多,系统间的依赖关系就越复杂,在SOA架构下,随着系统规模的增加,服务的上下游依赖将错综复杂,系统间的依赖和平台之间的依赖复杂度也将急剧增加。一个分布式下的请求从用户点击到收到响应,途中往往会经过N个系统,或者说N台运行着不同系统的服务器,每台服务器同一时刻都并发处理着很多请求。这需要Profiling和Debugging系统简洁明了地展示分析结果,让开发人员能够快速判断出其中某个节点是否有问题,以及问题的严重程度,将更多的精力放在调用链路在各集群中的走向等更上层信息的分析上。毕竟在大规模分布式系统中,保证系统的可用率是第一位的,而不应该在一个细节的问题上纠缠很久。
线上问题难以重现:线上问题有时与环境有关,线下难以复现,有时又是偶发性出现,难以捕捉。随着系统复杂度的增加,线上问题的快速定位和实时分析将是一项巨大挑战,一般只能靠人来解决,但人的问题排查能力的提升需要一次次的故障来换取,需要长期的经验积累,而且经验还很难传承,一旦关键人员流失,整个团队的问题解决能力就下降了,这个代价也让人难以接受。需要有一个方便的沉淀经验的地方,更好的做法是将这种宝贵的经验沉淀到Profiling和Debugging工具中。
与Profiling和Debugging相关的,蚂蚁金服内部开发使用有两款产品:ZProflier与ZDebugger。顾名思义,ZProfiler主要用于Profling,而ZDebugger主要用于Debugging。蚂蚁金服也有自己基于OpenJDK定制,ZProflier和ZDebugger的大多数功能是可以直接在标准的JDK上运行的,只是一些高级特性需要配合我们定制的JDK使用,这个我们后面也会谈到。针对前面提到的挑战,我们的产品有如下特点。
- 作为蚂蚁金服金融云的一部分,与服务器一起运行在隔离的网络中,解决网络隔离问题。
-
部分功能作为JVMTi扩展,直接集成在金融云生产环境使用的JDK里,不需要繁琐的权限申请。
-
让Profiling和Debugging支持LateAttach,这意味着用户不需要重启应用,随时可以对任何一台服务器进行问题定位和分析。
-
整合各种常用和不常用的Profiling/Debugging功能,并尽量打通功能之间的联系,提供一站式的服务,不需要开发人员在不同的工具间切换。
-
集成源码管理功能,自动下载目标系统对应的源代码到ZDebugger服务器,不占用开发人员的硬盘和时间。
-
集成权限管理,用户只要在登录ZProflier与ZDebugger系统时进行一次认证,后续各项操作(比如拷贝heapdump文件)的权限问题由系统代为处理。
-
集成问题对比、关键词查找、案例分享等功能,方便重复问题查找和经验传承。
常见问题解决思路
下面介绍一下处理一些常见的问题时,使用ZProflier和ZDebugger系统与使用传统工具在流程和思路上的一些区别。一个新上线的系统如果处理能力达不到我们的预期,或者一个老的系统处理速度突然下降了,抑或频繁抛出异常,这些都促使我们去思考系统存在性能问题该优化了,那我们通常会碰到的性能问题有OOM、CPU占用率高、Load高、频繁GC等。OOM的现象为Java进程直接退出,出错日志里可以看到OutOfMemoryError的异常。如果发现频繁的做MajorGC甚至是FullGC,一般也是OOM的前兆。解决此类问题的主要手段是分析heapdump。
JDK自带jmap工具,使用命令jmap-dump:live,format=b,file=heap.bin即可将Java进程的heap内存按照HPROFBinaryFormat的格式dump
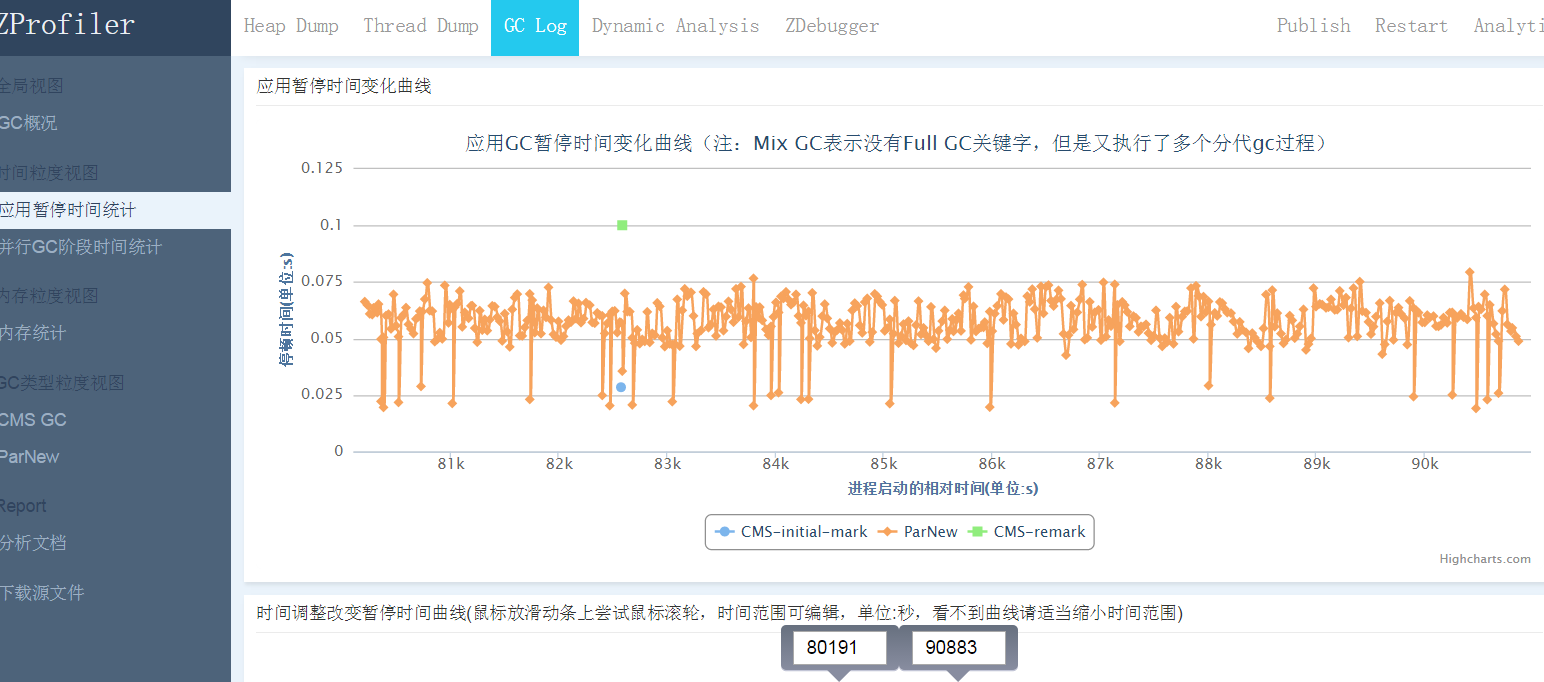
图1ZProfiler
到名字为heap.bin的文件里。命令中的live参数,意味在dump之前会做一次FullGC,保证dump出来的对象都尽量是活的对象,减少heap.bin的大小,降低工具的分析时间。是否要设置这个参数要视具体问题,比如想知道old区到底为什么会增长这么快,都增加了些什么对象呢?这个时候你可能没必要去加live参数了,只要连续做两次heapdump,然后做一次内存对比,就知道这段时间内增加了哪些对象。但如果你想找出一些长时间不释放的对象,分析其根引用树是怎样的,这时加上live参数来dump就比较合理。
常用的heapdump分析工具是EclipseMemoryAnalyzerTool,简称MAT。这款工具功能很强大,但正由于它过于强大,因此给初学者带来的学习成本也比较高。其次它是一个客户端程序,需要安装在本地,因此它也受限于本地的机器性能,比如本机内存就4GB,而heap文件大小为8GB,这时MAT就无法完成分析工作了。因为MAT本身也是Java程序,它在分析大heap时会出现不断做GC,甚至fullgc等异常情况,导致分析没有结果。针对这些问题,我们的性能分析产品ZProfiler精减了部分不常用的功能,保证绝大部分用户使用上的简便性。另外ZProfiler是个Web系统,运行在一台服务器上,分析能力不再受限于开发人员的机器性能,而WebUI操作的方式也大大减轻了开发人员的工作量。
CPU高的问题需要分层来考虑,首先检查操作系统层面的一些原因,比如频繁的memorypaging,可能导致Java应用在内核态花费的时间较多。也可以使用perftop检查JVM内部比如JIT,GC线程的CPU使用情况。如果JIT线程使用的CPU较高,就需要看看codecache或者其他JIT相关参数是否设置合理;如果是gc线程,就需要进一步分析gclog,然后调整GC相关的参数等。
排除以上原因之后,基本可以确认是Java代码的问题,可以使用ZProfiler提供了HotMethodProfiling功能查看热点方法,这个后面有详细描述。
Load高意味着运行的线程或者运行队列里的线程比较多,此时可以通过线程dump进行排查。线程dump,可以使用JDK自带的工具jstack,执行命令jstack即可,会将进程的所有Java线程给dump出来。如果还想跟踪native的堆栈,需要增加-m参数。当拿到线程dump之后,按照线程状态进行归类【注:JVM里dump出来的线程日志,线程的状态并不是100%的准确,细节可以参考JVMBug:多个线程持有一把锁?】。对于同一个系统,Load高的机器RUNNABLE态的线程数目一定比Load低的机器多。我们可以通过threaddump来分析这些多出的线程都在干嘛,从而找到Load高的原因。
针对线程分析,ZProfiler不仅仅从状态粒度提供了分析,还从锁粒度以及热点栈粒度做了统计分析,ZProfiler可以帮助用户看到一把锁影响到了哪些线程,哪个线程持有这把锁,那些线程正在等待这把锁,对于线程数因为同步锁的问题突然大增基本可以通过ZProifiler的分析结果看出问题在哪里。同样的,对于某个方法在哪些线程里或者运行态的线程里正在栈上执行,ZProfiler也提供了统计,方便用户排查Load高等问题。 
图2 ZDebugger
GC频繁是Java程序最常见的问题之一,大多数情况下都是由于相关参数配置不合理导致的。HotSpotGC相关的设置参数比较多,要找到比较合理的参数设置,首先要对应用的内存情况有一个总体的了解:比如应用运行稳定后,LiveDataSize大概是多少,这个会影响到-Xmx/-Xms/-Xmn的设置大小【注:CharlieHunt/BinuJohn合写的JavaPerformance提供了很好的Guide】;运行过程中创建的对象temp对象和longlived对象的大概比率,这个会影响到heap老区新区的设置比例。
查看GC情况通常有两种方式,一种是打开gclog相关的参数,事后分析gclog;另外一种是实时获取GC信息,可以打开JMX接口通过相关的MXbean获取,或者通过jstat命令。
gclog分析是个苦差,因为gclog输出的信息非常多,但是很多时候我们需要关注的是长期的趋势和整体的统计信息,人工分析太耗时间。目前也有一些不错的gclog分析工具,比如GCViewer。ZProfiler除了做了和GCViewer类似的工作之外,前面谈到过,ZProfiler系统本身就是部署在金融云里的,这意味着用户可以非常方便地通过简单的WebUI操作把gclog直接复制到ZProfiler上来分析。另外,我们也正在开发一些更高级的一些功能,在gclog分析完成后,给用户一些直接的建议,比如是否GCPause的时间过长,设置的GC参数应该如何调整,GC花费的CPU时间是不是过长等。
实时获取GC信息方面,VisualVM的VisualGC插件做的不错,非常直观地显示出当前应用的GC情况,但是分析方面做的不够。ZProfiler同样使用MXBean的方式获取实时的GC信息,将更有价值和更具统计意义的信息展示出来。而对于云上难以复现、偶发性的问题,我们推荐使用在线调试平台ZDebugger对运行中的程序进行在线调试。在线调试的原则是方便用户简单快速地打开调试器,且不能影响应用的正常运行。基于此思路,ZDebugger设计为基于Jetty的Web服务器,用户使用浏览器即可发送调试命令。调试器使用JDWP协议通过网络与被调试的JVM后端连接,在不重启JVM的情况下动态打开JVM调试功能,JVM在不阻断应用运行的前提下即时抓取断点处的运行信息并将其返回。
JDK定制
最后谈一下我们在OpenJDK中的一些定制。主要加入了Debug-on-Late-Attach(aka.DOLA)、Fast-SnapshotAt-Breakpoint(aka.FSAB)以及HotMethodProfiling等功能【注:后续我们也会和OpenJDK社区讨论怎么能把这些改动标准化,并贡献到社区,其中的一些部分已经开始了讨论】。
DOLA即在不重新启动JVM的情况下,可以把“有限的”的Java调试功能打开。这个功能对于生产环境的调试来说非常有意义。尽管目前主流的商业JVM基本都宣称“full-speeddebugging”,但在实际的使用中,我们没有多少人直接把JVM的调试能力在生产环境直接打开【注:在JVM启动时加-agentlib:jdwp设置参数,就可以打开JVM调试】,因为事实上还是对应用的性能有影响的。比如,对于JIT的影响,调试模式下EscapeAnalysis功能是被自动关掉的,而且一些解释器的fastpath也可会受到影响,而走slowpath。所以当线上问题出现时,往往要求重新启动问题JVM,把Debug功能打开调试,而尴尬在于,重启JVM往往会导致很难再现问题场景。这个是我们改造JDK,加入DOLA的初衷。
DOLA允许用户通过jcmd命令动态把JVM的“有限的”调试功能打开,通过ZDebugger,用户可以对被调试的JVM设置断点以及查看变量的值,这两个功能对我们来说已经足够帮助我们发现和诊断线上的大部分问题。
DOLA定制解决的难点主要在这么几个方面。
- jdwpagent改造,支持Agent_OnAttach接口,这样可以通过扩展的jcmd命令把jdwpagent在运行时加载到TargetJVM。
-
Interpreter改造,在Bytecodepatch路径上支持断点设置逻辑【注:关于HotSpotBytecodepatch,感兴趣的读者可以参考RewriteBytecodes/RewriteFrequentPairs等相关实现机制】。
-
方法De-optimization机制改造:标准的HotSpotJVM实现,用户设置断点,设置断点的当前方法被deoptimize到解释器版本。而我们定制的HotSpot会把所有的方法在这个点上都de-optimize掉,这是由于我们在JVM启动的时候没有开启调试,JIT就没有记录用于设置断点的方法dependency信息,De-optimize所有的方法会帮助JIT在后续的编译版本里记录下dependency信息。
FSAB的作用是配合Zdebugger系统的watchpoint调试模式。这种模式借鉴自Google的clouddebugger,其应用场景是:在云环境中,传统的SingleStep调试模式根本不可行,因为设置断点并单步调试,会造成线程阻塞,导致系统出现超时等各种无关的错误,甚至威胁整个系统正常运行。
而watchpoint调试模式是在断点停住之后,自动将调用堆栈、各层的局部变量,以及用户设置的表达式的值快速地取出来,然后Disable断点,并Continue当前执行。断点需要用户主动Enable,才会再次生效。这种模式可以尽量减少调试动作对运行系统的影响。
取局部变量最早是直接使用jdi接口实现的。为了一次断点触发能给用户提供足够的信息,会递归地将每个局部变量的成员都取出来。当设置为递归四层的时候,jdi的性能问题暴露了出来,断点触发之后停顿时间长达几秒钟。因此我们扩展了jdwp,增加了FSAB,使用Native方法直接批量获取数据。
另外我们还提供了两项比较独特的功能。一个是基于watchpoint调试模式的“多人在线调试”,即ZDebugger可以让用户创建或者订阅自己感兴趣的断点,当断点触发时将相关信息推送给订阅该断点的用户。这样多个用户可以互不干扰地对同一个运行系统进行调试。另一个是自动跟踪用户关注的数据。首次断点触发后,通过FSAB获取局部变量成员数据的时候默认是广度遍历。最终在用户界面上的展示是一颗可以展开的树,用户展开去查看自己关注的成员。这时系统会记录下用户关注的是哪个成员,下次断点触发通过FSAB获取数据时,会根据用户关注成员的路径进行深度遍历。获取更多用户关注的路径上的数据,而忽略其他分支。
HotMethodProfiling顾名思义就是热点函数剖析。热点函数统计剖析是性能分析中很重要的一项工作。因为按照已有的经验,程序运行过程中大部分时间都花费在少量的代码上。为了优化工作的投入产出比,应该先考虑优化程序中的热点函数。
热点函数统计有两种方法,一种是插桩,一种是采样。前者的例子有gprof,通过编译时增加一个特殊的编译选项,在所有函数的入口和出口插桩。运行时,在桩函数中记录时间等信息,输出到结果文件。事后可以得到每个函数精确的调用次数、执行时长以及整个函数调用关系图。其缺点是需要重新编译,而且要程序运行结束后才能拿到结果。后者的例子如perf,通过高频率的定时中断去打断运行中的程序,并在中断处理中记录当前程序运行的上下文信息。这样的结果显然是一种统计意义上的结果。如果采样频率不够高(出于性能考虑,一般也不会特别高),有可能会漏掉一些频繁执行,但每次执行时间短于采样间隔的代码。但其优点是不用重编程序,随时动态开关,马上就能得到结果。
ZProfiler采用是后一种方法。因为在用户态程序中,无法像perf一样采用硬件中断,而是采用了定时信号(linux系统提供了一种SIGPROF定时器)。我们提供了start和stop两个jmx命令,其实就是启动和停止一个定时器。在定时器信号的处理函数中去回溯Java调用栈。
回溯Java调用栈,ZProfiler使用了HotSpotJVM的一个非标准接口AsyncGetCallTrace(据说Oracle商业软件JavaMissionControl的MethodProfiling也是用的这个接口)。通过调用这个接口可以获得当前被定时器信号打断的线程的Java调用栈,而不需要等到JVM的safepoint才能收集线程堆栈。依赖safepoint来收集堆栈(比如通过调用Thread.getAllStackTraces)的profiling机制是有缺陷的,往往收集到的热点堆栈并不精确。在运行JITed的代码情况下,safepoint的时机往往是由JIT来决定的,比如在执行一些非常Hot的循环时,为了保证执行效率,JIT生成的代码就不会插入safepoint的轮询。这样的情况下,依赖safepoint的profiling机制就不会profiling到这些热点。有关AsyncGetCallTrace的使用,感兴趣的读者可以在网上找到更多的资料,或者可以直接阅读HotSpot的源代码,理解它的原理和用法。
结语
相比于传统的Java应用的Profiling以及调试,云计算环境线上系统有着其相对独特的地方,正如文章中提到,从内部来说,你可能需要与运维打交道,可能需要与不同的系统对接,比如Profiling/调试需要的源码就需要与SCM(sourcecontrolmanagement)对接等,我们需要把这些都无缝地连接起来,做成一站式的解决方案,方便攻城狮高效地发现、定位、解决问题,从而提高整个的生产效率。而从外部来说,对正在运行的系统进行Profiling/Debugging又有着非常高的性能上的要求,对程序的正常运行的影响一定要在可接受的范围内,这也是我们为什么做了这么多定制的原因。希望我们得到的这些观察体验以及实践经验,对于读者在相似的环境下,碰到类似问题时,能够借鉴到一些解决问题的思路。 |






