| 了解
Java 8 功能如何让并发性编程变得更容易
Java? 8 包含新的语言功能,添加了让编程变得更加简便的类,包括并发性编程。了解
Java 8 扩展提供的全新的、功能强大的并行处理语言支持,其中包括 CompletableFuture
和流。您可以看到,这些新功能与本系列的 首篇文章 中探讨的某些 Scala 功能有相似之处。
在期待已久的 Java 8 版本中,并发性方面已实现了许多改进,其中包括在
java.util.concurrent 层级中增加新的类和强大的新并行流 功能。设计流的目的是与 lambda
表达式 共同使用,Java 8 的这项增强也使得日常编程的其他很多方面变得更加简便。(参见介绍 Java
8 语言的 指南文章,了解对于 lambda 表达式的介绍及相关 interface 改动。)
本文首先介绍了新的 CompletableFuture 类如何更好地协调异步操作。接下来,我将介绍如何使用并行流(Java
8 中在并发性方面最大的亮点)在值集上并行地执行操作。最后,我探讨了 Java 8 新功能的执行方法,并与此系列
首篇文章 中的一些代码进行了比较。(参见 参考资料 中的本文完整示例代码的链接。)
回到 Future
此系列中的 首篇文章 简要介绍了 Java 和 Scala Future。Java
8 之前的 Java 版本功能较弱,仅支持两种用法:要么检查 future 是否已经完成,要么等待 future
完成。Scala 版本要灵活得多:可以在 future 完成时执行回调函数,并以 Throwable 的形式处理异常的完成。
Java 8 增加了 CompletableFuture<T> 类,它实现了新的 CompletionStage<T>
接口,并对 Future<T> 进行了扩展。(本节中讨论的所有并发性类与接口全都包含在 java.util.concurrent
包中。)CompletionStage 代表异步计算中的一个阶段或步骤。该接口定义了多种不同的方式,将
CompletionStage 实例与其他实例或代码链接在一起,比如完成时调用的方法(一共 59 种方法,比
Future 接口中的 5 种方法要多得多。)
清单 1 显示了 ChunkDistanceChecker 类,它基于
首篇文章 中的编辑距离比较代码。
清单 1. ChunkDistanceChecker
public class ChunkDistanceChecker {
private final String[] knownWords;
public ChunkDistanceChecker(String[] knowns)
{
knownWords = knowns;
}
/**
* Build list of checkers spanning word list.
*
* @param words
* @param block
* @return checkers
*/
public static List<ChunkDistanceChecker>
buildCheckers(String[] words, int block) {
List<ChunkDistanceChecker> checkers = new
ArrayList<>();
for (int base = 0; base < words.length; base
+= block) {
int length = Math.min(block, words.length - base);
checkers.add(new ChunkDistanceChecker(Arrays.copyOfRange(words,
base, base + length)));
}
return checkers;
}
...
/**
* Find best distance from target to any known
word.
*
* @param target
* @return best
*/
public DistancePair bestDistance(String target)
{
int[] v0 = new int[target.length() + 1];
int[] v1 = new int[target.length() + 1];
int bestIndex = -1;
int bestDistance = Integer.MAX_VALUE;
boolean single = false;
for (int i = 0; i < knownWords.length; i++)
{
int distance = editDistance(target, knownWords[i],
v0, v1);
if (bestDistance > distance) {
bestDistance = distance;
bestIndex = i;
single = true;
} else if (bestDistance == distance) {
single = false;
}
}
return single ? new DistancePair(bestDistance,
knownWords[bestIndex]) :
new DistancePair(bestDistance);
}
} |
ChunkDistanceChecker 类的每个实例负责根据一个已知单词数组来检查目标单词,从而找出最佳匹配。静态的
buildCheckers() 方法从整个已知单词数组创建一个 List<ChunkDistanceChecker>
和一个合适的块大小。这个 ChunkDistanceChecker 类是本文中几种并发实现的基础,第一种实现就是清单
2 中的 CompletableFutureDistance0 类。
清单 2. 使用 CompletableFuture 的编辑距离计算
public class CompletableFutureDistance0 extends TimingTestBase {
private final List<ChunkDistanceChecker> chunkCheckers;
private final int blockSize;
public CompletableFutureDistance0(String[] words,
int block) {
blockSize = block;
chunkCheckers = ChunkDistanceChecker.buildCheckers(words,
block);
}
...
public DistancePair bestMatch(String target) {
List<CompletableFuture<DistancePair>>
futures = new ArrayList<>();
for (ChunkDistanceChecker checker: chunkCheckers)
{
CompletableFuture<DistancePair> future =
CompletableFuture.supplyAsync(() -> checker.bestDistance(target));
futures.add(future);
}
DistancePair best = DistancePair.worstMatch();
for (CompletableFuture<DistancePair> future:
futures) {
best = DistancePair.best(best, future.join());
}
return best;
}
} |
清单 2 CompletableFutureDistance0 类显示了使用
CompletableFuture 进行并发计算的一种方式。supplyAsync() 方法使用一个 Supplier<T>
实例(一个带有返回 T 类型值的方法的函数式接口),并在对 Supplier 进行排队以便异步运行它时返回
CompletableFuture<T>。我向第一个 for 循环中的 supplyAsync()
方法传递了一个 lambda 表达式,目的是构建一个与 ChunkDistanceChecker 数组相匹配的
future 列表。第二个 for 循环等待每个 future 完成(但大多数会在循环到达之前完成,因为它们是异步执行的),然后从所有结果中收集最佳匹配。
在 CompletableFuture 上进行构建
在本系列的 首篇文章 中您已经看到,使用 Scala Future 可以通过各种方式附加完成处理程序和组合
future。CompletableFuture 为 Java 8 提供了类似的灵活性。在这一小节中,您将在编辑距离检查的上下文中学习使用这些功能的一些方式。
清单 3 显示了 清单 2 中 bestMatch() 方法的另一个版本。该版本使用一个带
CompletableFuture 的完成处理程序,以及一些较老的并发性类。
清单 3. 完成处理程序的 CompletableFuture
public DistancePair bestMatch(String target) {
AtomicReference<DistancePair> best = new AtomicReference<>(DistancePair.worstMatch());
CountDownLatch latch = new CountDownLatch(chunkCheckers.size());
for (ChunkDistanceChecker checker: chunkCheckers) {
CompletableFuture.supplyAsync(() -> checker.bestDistance(target))
.thenAccept(result -> {
best.accumulateAndGet(result, DistancePair::best);
latch.countDown();
});
}
try {
latch.await();
} catch (InterruptedException e) {
throw new RuntimeException("Interrupted during calculations", e);
}
return best.get();
} |
在 清单 3 中,CountDownLatch 被初始化为代码中创建的
futures 的数量。创建每个 future 时,我使用 CompletableFuture.thenAccept()
方法附加了一个处理器(以 java.util.function.Consumer<T> 函数式接口的一个
lambda 实例的形式)。该处理器在 future 正常完成时执行,它使用 AtomicReference.accumulateAndGet()
方法(Java 8 中增加的)来更新找到的最佳值,然后将闩锁 (latch) 递减。与此同时,执行的主线程进入了
try-catch 块,并等待闩锁释放。当所有 futures 完成后,主线程会继续,然后返回找到的最后一个最佳值。
清单 4 显示了 清单 2 中 bestMatch() 方法的另一个版本。
清单 4. 组合使用 CompletableFuture
public DistancePair bestMatch(String target) {
CompletableFuture<DistancePair> last =
CompletableFuture.supplyAsync(bestDistanceLambda(0, target));
for (int i = 1; i < chunkCheckers.size(); i++) {
last = CompletableFuture.supplyAsync(bestDistanceLambda(i, target))
.thenCombine(last, DistancePair::best);
}
return last.join();
}
private Supplier<DistancePair> bestDistanceLambda(int
i, String target) {
return () -> chunkCheckers.get(i).bestDistance(target);
} |
这段代码使用了 CompletableFuture.thenCombine
() 方法将两个 future 合并,具体做法是对两个结果使用一个 java.util.function.BiFunction
方法(在这个例子中为 DistancePair.best() 方法),然后返回一个 future 作为函数的结果。
清单 4 是最简洁和最干净的代码版本,但它有一个缺点,就是创建了一个额外的
CompletableFuture 层来表示每次批量操作与之前操作的组合使用。作为最初的 Java 8
版本,这有可能导致 StackOverflowException(在此代码中未包含该异常),从而导致最后一个
future 永远无法完成。这个 bug 正在被解决,在近期的版本中会得到修正。
CompletableFuture 定义了这些例子中所用方法的多个变体。当您对您的应用程序使用
CompletableFuture 时,可以检查完成方法的完整列表,然后结合使用多种方法来找出您需要的最佳匹配。
当您执行各种类型的操作并且必须调整结果时,CompletableFuture
是最佳选择。当在很多不同的数据值上运行相同计算过程时,并行流将为您提供一个更简单的方法和更好的性能。编辑距离检查的例子更适合并行流方法。
流
流是 Java 8 的主要特色之一,可与 lambda 表达式结合使用。从根本上讲,流就是基于一个值序列的推送迭代器。流可以与适配器链接在一起,以便执行诸如过滤与映射之类的操作,这一点与
Scala 序列很像。流还有串行和并行的变体,这也和 Scala 序列很像(但 Scala 有一个用于并行序列的单独的类层级,而
Java 8 使用一个内部标记来指示串行或并行)。流的变体包括原始的 int、long 和 double
类型,以及类型化的对象流。
新的流 API 过于复杂,本文很难完整地讲述它们,因此我将重点放在了并发性方面。参见
参考资料 部分中关于流的更加详细的说明。
清单 5 显示了编辑距离最佳匹配代码的另一种变体。这个版本使用了 清单
1 中的 ChunkDistanceChecker 来进行距离计算,并像 清单 2 示例中的那样使用了
CompletableFuture,但这次我使用了流来获得最佳的匹配结果。
清单 5. 使用流的 CompletableFuture
public class CompletableFutureStreamDistance extends TimingTestBase {
private final List<ChunkDistanceChecker> chunkCheckers;
...
public DistancePair bestMatch(String target) {
return chunkCheckers.stream()
.map(checker -> CompletableFuture.supplyAsync(()
-> checker.bestDistance(target)))
.collect(Collectors.toList())
.stream()
.map(future -> future.join())
.reduce(DistancePair.worstMatch(), (a, b) ->
DistancePair.best(a, b));
}
} |
位于清单 5 底部的多行语句使用了简便的流 API 来完成所有工作:
chunkCheckers.stream() 从 List<ChunkDistanceChecker>
创建一个流。
1、.map(checker -> ... 对流中的值使用映射,这个例子中,使用了与
清单 2 例子中相同的技术来构造一个针对 ChunkDistanceChecker.bestDistance()
方法的异步执行结果的 CompletableFuture。
2、.collect(Collectors.toList()) 将值收集到一个列表中,然后用
.stream() 将它转换回为流。
3、.map(future -> future.join()) 等待每个
future 的结果变为可用,而 .reduce(... 通过对前最佳结果与最新结果反复应用 DistancePair.best()
方法来找出最佳值。
无可否认,这让人感到有些混乱。在您不想读下去之前,我向您保证下一版一定会更简单、更清晰。清单
5 的目的是让您了解如何使用流来代替普通循环。
清单 5 的代码会更简单,因为它没有进行多次转换(从流到列表再回到流)。在这个例子中需要转换,否则在创建
future 后,代码就会立刻开始等待 CompletableFuture.join() 方法。
并行流
幸运的是,存在着比 清单 5 更简单的在流上实现并行操作的方法。顺序流可以变为并行流,而并行流可自动跨多个线程共享工作,并在稍后收集结果。清单
6 显示了如何使用这种方法从 List<ChunkDistanceChecker> 中找到最佳匹配项。
清单 6. 使用批量并行流的最佳匹配
public class ChunkedParallelDistance extends TimingTestBase {
private final List<ChunkDistanceChecker> chunkCheckers;
...
public DistancePair bestMatch(String target) {
return chunkCheckers.parallelStream()
.map(checker -> checker.bestDistance(target))
.reduce(DistancePair.worstMatch(), (a, b) -> DistancePair.best(a, b));
}
} |
再次申明,位于末尾的多行语句完成了所有工作。和在 清单 5 中一样,语句一开始从列表创建流,但这个版本使用了
parallelStream() 方法来获取用于并行处理的流。(您还可以将普通流转换为并行处理的流,只需在流上调用
parallel() 方法即可。)接下来的部分是 .map(checker -> checker.bestDistance(target)),用于在大量已知单词中找到最佳匹配。最后一部分是
.reduce(...,用于在所有数据块中收集最佳结果,这一点也和 清单 5 中相同。
并行流会并行执行某些步骤,比如 map 和 filter 操作。因此在后台,清单
6 代码在减数步骤中整合结果之前,会将映射步骤分散到多个线程上(不一定要按照特定的顺序,因为结果的到来和产生结果的操作是并行的)。
在流中,对要完成的工作进行分解的能力取决于流中使用的 java.util.Spliterator<T>
新接口。从名称可以看出来,Spliterator 类似于 Iterator。和 Iterator 一样,使用
Spliterator 每次可以处理某个元素集合中的一个元素 ― 不是从 Spliterator 中获取元素,而是使用
tryAdvance() 或 forEachRemaining() 方法对元素应用操作。但 Spliterator
还可以用于估计其中保存的元素数量,而且还可以像细胞分裂一样变为一分为二。这些新增加的能力让流并行处理代码可以很方便地将工作分布到多个可用线程上完成。
清单 6 中的代码可能让您觉得似曾相识,这是因为它与此系列 首篇文章 中的
Scala 并行集合例子非常相似:
def bestMatch(target: String) =
matchers.par.map(m => m.bestMatch(target)).
foldLeft(DistancePair.worstMatch)((a, m) => DistancePair.best(a, m)) |
无论语法还是操作都存在一些差别,但实际上,Java 8 并行流代码和 Scala
并行集合代码是在以相同的方式做着同样的事情。
全程使用流
迄今为止,所有例子均保留了此系列 首篇文章 中比较任务使用的分块结构,在老版本的
Java 中,这种结构是高效处理并行任务所必需的。Java 8 并行流设计用于处理它们自己的的工作分工,因此您能够以流的形式传递一个要处理的值集,然后内置的并发处理机制会将这个集合分解到各个可用的处理器进行处理。
如果尝试将这种方法用于编辑距离任务,则会出现很多问题。如果将处理步骤全部链接到一个管道(流操作序列的官方叫法)中,那么可以只将每个步骤的结果传给管道的下一阶段。如果想获得多个结果(比如最佳距离值和编辑距离任务中使用的对应已知单词),则必须以对象的形式传递它们。但是与分块方法相比,为每次比较的结果创建一个对象将会损害直接流方法的性能。甚至更糟的情况是,编辑距离计算会重用一对已分配的数组。这对数组无法在并行计算之间共享,因此需要为每次计算重新分配数组。
幸运的是,流 API 支持您有效地应对这种情况,但还需要另外做一些工作。清单
7 演示了如何使用流来处理整个计算过程,同时不会创建中间对象或额外的工作数组。
清单 7. 每次编辑距离比较的流处理
public class NonchunkedParallelDistance extends TimingTestBase
{
private final String[] knownWords;
...
private static int editDistance(String target, String known, int[] v0, int[] v1) {
...
}
public DistancePair bestMatch(String target) {
int size = target.length() + 1;
Supplier<WordChecker> supplier = () -> new WordChecker(size);
ObjIntConsumer<WordChecker> accumulator = (t, value) -> t.checkWord(target, knownWords[value]);
BiConsumer<WordChecker, WordChecker> combiner = (t, u) -> t.merge(u);
return IntStream.range(0, knownWords.length).parallel()
.collect(supplier, accumulator, combiner).result();
}
private static class WordChecker {
protected final int[] v0;
protected final int[] v1;
protected int bestDistance = Integer.MAX_VALUE;
protected String bestKnown = null;
public WordChecker(int length) {
v0 = new int[length];
v1 = new int[length];
}
protected void checkWord(String target, String known) {
int distance = editDistance(target, known, v0, v1);
if (bestDistance > distance) {
bestDistance = distance;
bestKnown = known;
} else if (bestDistance == distance) {
bestKnown = null;
}
}
protected void merge(WordChecker other) {
if (bestDistance > other.bestDistance) {
bestDistance = other.bestDistance;
bestKnown = other.bestKnown;
} else if (bestDistance == other.bestDistance) {
bestKnown = null;
}
}
protected DistancePair result() {
return (bestKnown == null) ? new DistancePair(bestDistance) : new
DistancePair(bestDistance, bestKnown);
}
}
} |
清单 7 使用一个可变的结果容器类(这里使用的是 WordChecker
类)来整合结果。bestMatch() 方法使用三个 lambdas 形式的活动部分实现了比较。
Supplier<WordChecker> supplier
lambda 提供结果容器的实例。
ObjIntConsumer<WordChecker> accumulator
lambda 将一个新值收集到结果容器中。
BiConsumer<WordChecker, WordChecker>
combiner lambda 将两个结果容器合并,从而实现值的整合。定义了这三个 lambdas 之后,最后一条
bestMatch() 语句将为已知单词数组中的索引创建一个 int 值的并行流,并将流传递给 IntStream.collect()
方法。collect() 方法使用三个 lambdas 来完成实际的工作。
Java 8 并发性能
图 1 显示了在我使用 Oracle's Java 8 for 64-bit
Linux? 的四核 AMD 系统上运行测试代码时,对不同大小的块测量性能时的性能变化。与本系列 首篇文章
中的定时测试一样,将每个输入的单词依次与 12,564 个已知单词进行比较,而每个任务都会在已知单词的范围内找到最佳匹配。所有
933 个拼写错误的输入单词将被反复运行,但在每次传递给 JVM 进行处理的间隙会出现暂停。图 1 中使用了
10 次传递后的最佳时间。最终的块大小 16,384 大于已知单词的数量,因此这个例子显示的是单线程的性能。定时测试中包含的实现是本文中的四种主要变体和首篇文章中的总体最佳变体:
CompFuture:清单 2 中的 CompletableFutureDistance0
CompFutStr:清单 5 中的 CompletableFutureStreamDistance
ChunkPar:清单 6 中的 ChunkedParallelDistance
ForkJoin:首篇文章 中清单 3 中的 ForkJoinDistance
NchunkPar:清单 7 中的 NonchunkedParallelDistance
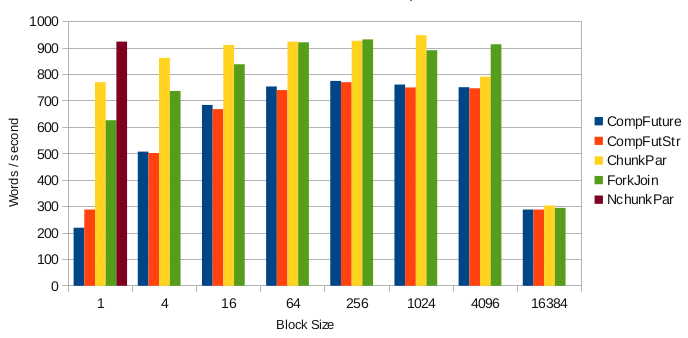
图 1. Java 8 性能
图 1 显示新的 Java 8 并行流方法的性能非常突出,特别是完全流化的
清单 7 NchunkPar。定时测试结果表现出用于消除对象创建的优化效果(只有图表中的一个值,因为这种方法不使用块大小),这与其他任何方法的最佳效果相当。CompletableFuture
方法在性能方面表现稍弱,但这并不意外,因为这个例子并未真正体现出该类的强大功能。清单 5 ChunkPar
时间大致与 首篇文章 中 ForkJoin 代码相当,但对块大小的敏感性有所降低。对于一次性测试大量单词的所有变体,您会看到块大小较小时性能更差,因为创建对象的开销较之实际的计算工作更高。
和 首篇文章 中的定时测试结果相同,这些结果只能用作性能参考,具体性能应当以您自己的应用程序为准。这里最重要的一条经验是,只有正确使用新的
Java 8 并行流,它才能表现出优异的性能。将优异性能与流的功能性编码方式的开发优点结合起来,就能在值集上进行计算时获得成功。
结束语
Java 8 为开发人员提供一些重要的新功能。并行流实现走在并发性领域前沿,速度更快且易于使用,特别是在与用于功能性编程风格的
lambda 表达式(它能够清晰而准确地表达用户意图)结合使用时。当处理独立操作时,新的 CompletableFuture
类还可以降低并发性编程的难度,在这种情况下不宜使用流模型。
下一篇 JVM 并发性 文章将会转而介绍 Scala,并探讨处理异步计算的另一种有趣方式。借助
async 宏,您可以写出与进行顺序分块操作相似的代码,并通过 Scala 将代码转换为完全非分块的结构。我将给出一些例子来说明这种功能的用处和实现。谁知道呢
― 也许这些来自 Scala 的新功能将会包含在 Java 9 中。 |






