|
解释器模式是平时工作当中相对冷门的一个设计模式,也非常的难于理解,百度百科上的解释也非常之少,只是简单的介绍了一下,并且说了一句,可以参考正则表达式为一个实际的应用例子。
不过资料的匮乏并不能阻止我们对真理的探索,下面LZ先将百度百科上的定义以及解决的问题拔到这里,方便各位观看。
定义:给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
使用场景:解释器模式需要解决的是,如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
LZ先给各位解释一下定义当中所提到的文法。文法也称为语法,指的是语言的结构方式。包括词的构成和变化,词组和句子的组织。对于文法来说,我们可以简单的理解为一种语言的规则,那么从解释器模式的定义可以看出,首先我们要先设计一种语言,然后给出语言的文法的表示,而在此基础上,我们采用解释器模式去解释语言中的句子。
要想彻底的理解解释器模式,LZ必须要先普及一下文法的定义,请各位暂且忍受住枯燥的理论知识,后面LZ会将这些理论用各位熟悉的代码诠释一遍。
首先我们来讨论一下上下文无关文法的组成,有四种组成部分。
1,非终结符号集(LZ标注:像JAVA语言中的表达式,程序语句,标识符等)
2,终结符号集(LZ标注:类似JAVA语言中的+,-,*,\,=等)
3,产生式集合,也可以称为规则集合(LZ标注:假设我们记JAVA中的标识符为id,那么下面这句话可以被成视为一条规则
id->a|b...|z|0..|9|_,其中|是或者的意思)
4,一个起始符号,这个符号是非终结符号集的一个元素(LZ标注:JAVA语言使用CompilationUnit(编译单元)作为起始符号。)
上面所说的定义有些抽象,所以LZ在后面加了一些标注,那么上下文无关文法的作用是什么呢?
它可以生成一组由文法导出的语句,这些语句可以根据文法的产生式进行分析,下面LZ给一个《编译原理》一书中的简单例子,为了方便理解,LZ将符号稍微更改了一下。
假设有一上下文无关文法如下:
arithmetic -> arithmetic + number
| arithmetic - number | number
number -> 0 | 1 | 2 | 3 | 4 | 5 |
6 | 7 | 8 | 9
我们根据这个文法可以得到所有个位数的加减表达式,比如对于 9 + 2 -
1 ,我们可以通过以下步骤推导出来。
arithmetic - >arithmetic - number
-> arithmetic + number - number -> number + number
- number -> 9 + number -number -> 9 + 2 - number
-> 9 + 2 - 1
对于文法来说,一个语句如果能够按照产生式推导出该语句,就称该语句是符合文法的,所以9
+ 2 - 1是符合上述文法的一个语句。
在这个文法当中,其中非终结者符号是 arithmetic 和 number,
而终结者符号是 0 - 9 、-、+ 。
我们从文法中可以得知由该文法组成的语句有以下规则。
1、operator的右边必须是一个number。
2、operator的左边必须是一个arithmetic。
3、arithmetic的最右边一定是一个number。
4、由2和3,operator的左边必须是number。
5、由4,number的右边必须是空或者operator。
6、number只能是 0 和 1 - 9 的正整数。
7、operator只能是 - 和 + 。
针对这个文法,我们可以写一个解释器,去计算表达式的结果,而这个解释器就可以使用解释器模式编写。而在编写的过程中,我们需要验证以上的规则,如果违反了规则,则表达式是非法的。为了便于使用程序语言表示,我们只验证以上的后四条规则,这也是由原本的产生式推算出来的规则。
我们先来看下解释器模式的类图,引自《大话设计模式》。
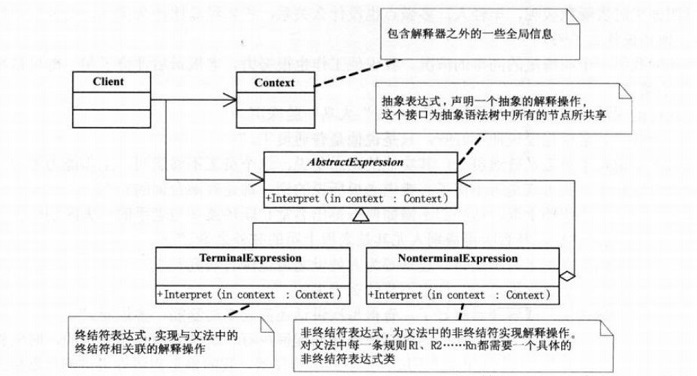
可以看到类图中有四个角色,抽象表达式(AbstractExpression)、终结符表达式(TerminalExpression)、非终结符表达式(NonterminalExpression)以及上下文(Context)。
四个角色所负责的任务在类图中已有解释,LZ这里不再重复,这里要说的是,这里具体的表达式类个数是不定的。
换句话说,终结符表达式(TerminalExpression)和非终结符表达式(NonterminalExpression)的个数都是根据文法需要而定的,并非是一成不变。
下面我们就使用上述的解释器模式的结构去写一个解释器,用于解释上面的加减表达式,首先我们先写一个上下文,它记录了一些全局信息,提供给表达式类使用,如下。
package com.interpreter;
import java.util.ArrayList;
import java.util.List;
//上下文
public class Context {
private int result;//结果
private int index;//当前位置
private int mark;//标志位
private char[] inputChars;//输入的字符数组
private List operateNumbers = new ArrayList(2);//操作数
private char operator;//运算符
public Context(char[] inputChars) {
super();
this.inputChars = inputChars;
}
public int getResult() {
return result;
}
public void setResult(int result) {
this.result = result;
}
public boolean hasNext(){
return index != inputChars.length;
}
public char next() {
return inputChars[index++];
}
public char current(){
return inputChars[index];
}
public List getOperateNumbers() {
return operateNumbers;
}
public void setLeftOperateNumber(int operateNumber) {
this.operateNumbers.add(0, operateNumber);
}
public void setRightOperateNumber(int operateNumber) {
this.operateNumbers.add(1, operateNumber);
}
public char getOperator() {
return operator;
}
public void setOperator(char operator) {
this.operator = operator;
}
public void mark(){
mark = index;
}
public void reset(){
index = mark;
}
}
|
上下文的各个属性,都是表达式在计算过程中需要使用的,也就是类图中所说的全局信息,其中的操作数和运算符是模拟的计算机中寄存器加减指令的执行方式。下面我们给出抽象的表达式,它只是定义一个解释操作。
package com.interpreter;
//抽象表达式,定义一个解释操作
public interface Expression {
void interpreter(Context context);
}
|
下面便是最重要的四个具体表达式了,这其中对应于上面文法提到的终结符和非终结符,如下。
package com.interpreter;
//算数表达式(非终结符表达式,对应arithmetic)
public class ArithmeticExpression implements Expression {
public void interpreter(Context context) {
context.setResult(getResult(context));//计算结果
context.getOperateNumbers().clear();//清空操作数
context.setLeftOperateNumber(context.getResult());//将结果压入左操作数
}
private int getResult(Context context){
int result = 0;
switch (context.getOperator()) {
case '+':
result = context.getOperateNumbers().get(0) + context.getOperateNumbers().get(1);
break;
case '-':
result = context.getOperateNumbers().get(0) - context.getOperateNumbers().get(1);
break;
default:
break;
}
return result;
}
}
|
package com.interpreter;
//非终结符表达式,对应number
public class NumberExpression implements Expression{
public void interpreter(Context context) {
//设置操作数
Integer operateNumber = Integer.valueOf(String.valueOf(context.current()));
if (context.getOperateNumbers().size() == 0) {
context.setLeftOperateNumber(operateNumber);
context.setResult(operateNumber);
}else {
context.setRightOperateNumber(operateNumber);
Expression expression = new ArithmeticExpression();//转换成算数表达式
expression.interpreter(context);
}
}
}
|
package com.interpreter;
//终结符表达式,对应-、+
public class OperatorExpression implements Expression{
public void interpreter(Context context) {
context.setOperator(context.current());//设置运算符
}
}
|
package com.interpreter;
//终结符表达式,对应0、1、2、3、4、5、6、7、8、9
public class DigitExpression implements Expression{
public void interpreter(Context context) {
Expression expression = new NumberExpression();//如果是数字,则直接转为number表达式
expression.interpreter(context);
}
}
|
这四个类就是简单的解释操作,值得一提的就是其中的两次转换,这个在稍后LZ会解释一下。
下面本来该是客户端程序了,不过由于我们的例子较为复杂,客户端的代码会比较臃肿,所以LZ抽出了一个语法分析类,分担了一些客户端的任务,在标准解释器模式的类图中是没有这个类的。
各位可以把它的代码想象成在客户端里面就好,这并不影响各位理解解释器模式本身,语法分析器的代码如下。
package com.interpreter;
//语法解析器(如果按照解释器模式的设计,这些代码应该是在客户端,为了更加清晰,我们添加一个语法解析器)
public class GrammarParser {
//语法解析
public void parse(Context context) throws Exception{
while (context.hasNext()) {
Expression expression = null;
switch (context.current()) {
case '+':
case '-':
checkGrammar(context);
expression = new OperatorExpression();
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
context.mark();
checkGrammar(context, context.current());
context.reset();
expression = new DigitExpression();
break;
default:
throw new RuntimeException("语法错误!");//无效符号
}
expression.interpreter(context);
context.next();
}
}
//检查语法
private void checkGrammar(Context context,char current){
context.next();
if (context.hasNext() && context.current() != '+' && context.current() != '-') {
throw new RuntimeException("语法错误!");//第5条
}
try {
Integer.valueOf(String.valueOf(current));
} catch (Exception e) {
throw new RuntimeException("语法错误!");//第6条
}
}
//检查语法
private void checkGrammar(Context context){
if (context.getOperateNumbers().size() == 0) {//第4条
throw new RuntimeException("语法错误!");
}
if (context.current() != '+' && context.current() != '-') {//第7条
throw new RuntimeException("语法错误!");
}
}
}
|
可以看到,我们的语法分析器不仅做了简单的分析语句,从而得出相应表达式的工作,还做了一个工作,就是语法的正确性检查。
下面我们写个客户端去计算几个表达式试一下。
package com.interpreter;
import java.util.ArrayList;
import java.util.List;
public class Client {
public static void main(String[] args) {
List inputList = new ArrayList();
//三个正确的,三个错误的
inputList.add("1+2+3+4+5+6+7+8+9");
inputList.add("1-2+3-4+5-6+7-8+9");
inputList.add("9");
inputList.add("-1+2+3+5");
inputList.add("1*2");
inputList.add("11+2+3+9");
GrammarParser grammarParser = new GrammarParser();//语法分析器
for (String input : inputList) {
Context context = new Context(input.toCharArray());
try {
grammarParser.parse(context);//语法分析器会调用解释器解释表达式
System.out.println(input + "=" + context.getResult());
} catch (Exception e) {
System.out.println("语法错误,请输入正确的表达式!");
}
}
}
}
|
输出结果:
1+2+3+4+5+6+7+8+9=45
1-2+3-4+5-6+7-8+9=5
9=9
语法错误,请输入正确的表达式!
语法错误,请输入正确的表达式!
语法错误,请输入正确的表达式!
可以看到,前三个表达式是符合我们的文法规则的,而后三个都不符合规则,所以提示了错误,这样的结果,与我们文法所表述的规则是相符的。
LZ需要提示的是,这里面本来是客户端使用解释器来解释语句的,不过由于我们抽离出了语法分析器,所以由语法分析器调用解释器来解释语句,这消除了客户端对解释器的关联,与标准类图不符,不过这其实只是我们所做的简单的改善而已,并不影响解释器模式的结构。
另外,上面的例子当中,还有两点是LZ要提一下的。LZ为了方便理解,已经尽量的将例子简化,不过其中有两个地方的转换是值得注意的。
1、一个是操作数满足条件时,会产生一个ArithmeticExpression表达式。
2、另外一个是从DigitExpression直接转换成NumberExpression的地方,这其实和第1点一样,都是对文法规则的使用,不过这个更加清晰。我们可以清楚的看到,0-9的数字或者说DigitExpression只对应唯一一种方式的非终结者符号,就是number,所以我们直接转换成NumberExpression。
不过我们的转换是由终结者符号反向转换成非终结者符号的顺序,也就是相当于从抽象语法树的低端向上转换的顺序。其实相当于LZ省去了抽象语法树的潜在构建过程,直接开始解释表达式。
我们看上面的类图中,非终结者表达式有一条到抽象表达式的聚合线,那其实是将非终结者表达式按照产生式分解的过程,这会是一个递归的过程,而我们省去了这一步,直接采用反向计算的方式。
然后再说说我们的语法分析器,它的工作就是将终结者符号对应上对应的表达式,可以看到它里面的swich结构就是用来选取表达式的。实际当中,我们当然不会写这么糟糕的swich结构,我们可以使用很多方式优化它。当然,语法分析器的另外一个工作就是检查语法的正确性,这点可以从两个check方法明显的看到。
不过很遗憾,在日常工作当中,我们使用到解释器模式的概率几乎为0,因为写一个解释器就基本相当于创造了一种语言,这对于大多数人来说,是几乎不可能接到的工作。不过我们了解一下解释器模式,还是对我们有好处的。
前面已经提到过解释器模式适用的场景,我们这里结合上面的例子总结一下解释器模式的优点:
1、由于我们使用具体的终止符和非终止符去解释文法,所以会比较易于编写。
2、可以比较方便的修改和扩展文法规则。
相对于优点来说,它的缺点也非常明显,那就是由于我们几乎针对每一个规则都定义了一个类,所以如果一个文法的规则比较多,那对于文法的维护工作也会变得非常困难。
下面LZ将我们例子的类图贴上来,各位参考一下。
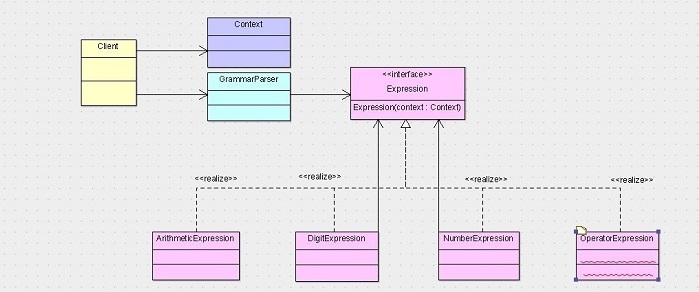
针对这个类图,LZ简单的说两点。
1、Client本来是关联的Expression接口,不过由于中间加了个语法分析器(GrammerParser),所以变成了Client关联语法分析器,语法分析器再关联Expression接口。
2、由于我们采用反向计算的方式,所以非终结者表达式没有到Expression接口的聚合线,而是由两条关联线代替了两条聚合线。
解释器模式的分享就到此结束了,各位只要大致了解一下即可,如果实在理解不了,也不必死抠这个模式。
学习设计模式,有时候就像追女生一样,如果你怎么追都追不上,那说明缘分未到,该放弃的时候就得放弃,说不定哪天缘分到了,不需要你追,你心中的她自然就上钩了。所以如果有哪一个设计模式一时半会理解不了,请不要着急去理解它,不理解的原因是因为你的积累还不够,如果霸王硬上弓的话,往往会被设计模式暴揍一顿,最后还得自己付医药费。
LZ只想说,何必呢?
到这篇文章为止,LZ已经将所有24种设计模式全部讲解了一遍,其中有好有坏,有对有错。不过不管怎样,LZ本人的收获还是很大的,也很感谢这当中支持LZ的猿友。设计模式系列或许还会有最后一篇,内容自然是对24种设计模式的总结,LZ最近也在为此而准备着,敬请各位猿友擦亮双眼期待吧。
一个系列结束了,不代表LZ的学习之路结束了,在上一章已经提到过,LZ最近在研究虚拟机源码,在接下来的时间里,LZ或许会写一些与虚拟机相关的内容,如果有哪位猿友对虚拟机有兴趣的话,可以继续关注下LZ。
感谢各位的收看,我们下次再见。
|


